将云原生进行到底:腾讯百万级别容器云平台实践揭秘

林沐,腾讯云高级工程师,负责腾讯自研业务上云平台的建设和有状态服务容器化标准的制定,专注于大规模服务场景云原生实践的推广。
导读|基于 K8s 的云原生容器化已经在腾讯内部海量业务中大范围落地实践。业务从传统的虚拟机部署形态无缝切换到容器部署形态,运行在 K8s 上的应用从无状态服务扩展到有状态服务,这个过程经历了哪些改造?同时,K8s 如何经受住业务形态复杂多样、模块数量庞大的考验?遇到哪些新的挑战?如何优化?效果怎么样?腾讯云高级工程师林沐将为你解答。

在线业务资源容器化部署的问题与优化方案
腾讯平台的业务基本都属于在线业务。这些业务以前在虚拟机部署时,是通过物理机操办的方式生产出很多虚拟机,对于业务来说是不感知的。当业务发现虚拟机负载较低时,可将多个在线业务混部来提高资源利用率。
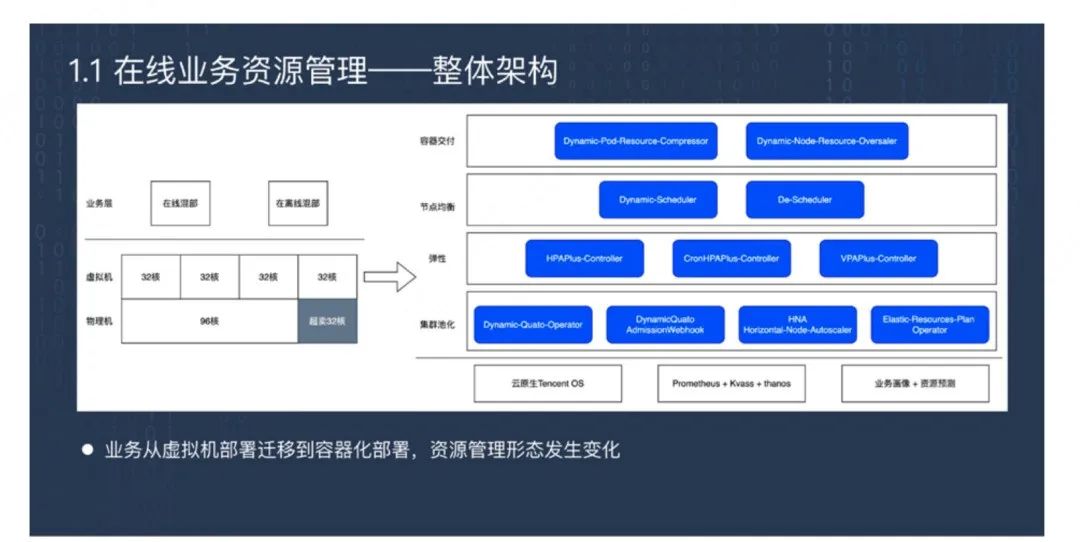
这种资源管理方式到容器化部署时发生了一些变化,主要有四方面的内容。
容器交付。每个 Pod 在交付的同时需要声明规格大小,规格大小要改变时 Pod 必须销毁重建,无法通过混部来新增业务。节点均衡。K8s 每个节点上部署多个 Pod,每个节点上的 Pod 类型、数量也都不相同,要保证节点均衡是一个挑战。K8s 的云原生特性,也就是弹性,是否能够符合在线业务在生产环境中的需求?集群池化。K8s 是按集群维度管理,而平台有上万个业务,这么多业务如何映射到不同的集群实现条带化管理?
针对上述问题,腾讯采取的优化手段是:
第一,资源利用率提升——动态压缩和超卖。我们面临一个痛点是用户配置的容器规模不合理,普遍偏大,这样节点装箱率和负载比较低。所以第一个优化方式就是 Pod 资源动态压缩,Pod 请求双核处理器 4G 内存,在调度时压缩成单核 4G 内存。因为 CPU 属于可压缩资源,内存属于不可压缩资源。这里修改的只是 Request 大小,并不修改 Limit,所以不影响容器实际能使用的上限值。这样能提高节点的装箱率。接下来是 Node 资源动态超卖,根据负载情况超卖更多 CPU 核心。
第二,节点负载均衡——动态调度和重调度。资源压缩超卖能提高节点的装箱率和负载使用率,但 Pod 是共享Node 的,压缩和超卖会加剧它们之间的干扰。于是我们开发了动态调度器,当每一个 Pod 调度时,能够感知存量 Node 当前的实时负载情况,从而对增量 Pod 在 Node 当中均衡处理,掉到一个低负载的节点上。存量 Pod 在节点上也有可能发生高负载,这时我们在节点上部署 Pod-Problem-Detecor、NodeProblem-Detecor,检测出哪个 Pod 会导致节点高负载,哪些 Pod 属于敏感 Pod,通过事件上报告诉API Server,让调度器将异常 Pod、敏感 Pod 重新调度到空闲节点。
第三,K8s 业务弹性伸缩——协同弹性。在线业务最关心业务稳定性。有时业务负载超出预期时,因为最大负载数配置过低,导致业务雪崩。所以我们对 HPA 进行优化,加入 HPAPlus-Controller,除了支持弹性最大副本策略之外,还能够支持业务自定义配置进行伸缩。第二个是 VPAPlus-Controller,可以 Pod 突发高负载进行快速扩容,对有状态的服务也可以进行无感知扩缩容。
第四,集群资源管理——动态配额和资源腾挪。从平台的角度,K8s 集群也是一个重要的维护对象。平台通过动态 Operator 的方式控制业务对集群的可见性以及配额大小,使得各个集群的业务是分布均匀的。集群本身也有规模大小,有节点伸缩,叫做 HNA。HNA 能够根据集群负载情况自动补充资源或释放资源。生产环境中一种情况是,有时候突发活动,在公共资源池里没有特定资源,需要从其他系统里腾挪资源。所以我们开发了弹性资源计划 Operator,它会给每个节点、每个集群下发任务,要求每个集群释放一些Node 出来。这批节点的数量要尽可能符合业务的数量要求,同时要对存量业务的负载质量不产生影响。我们的方式是通过动态规划的方式解决问题,从而在业务做活动,或者紧急情况下,能够使集群之间的资源也能够流转。

容器化对动态路由同步的挑战与解决方案
每一个 Pod 在销毁重建的时候会动态添加或提取路由。一般来说,生产环节中的路由是第三方系统负责,当 Pod 正常的时候系统给它转发流量,或者做名词解析,当它摘除时就从名词服务里剔除。
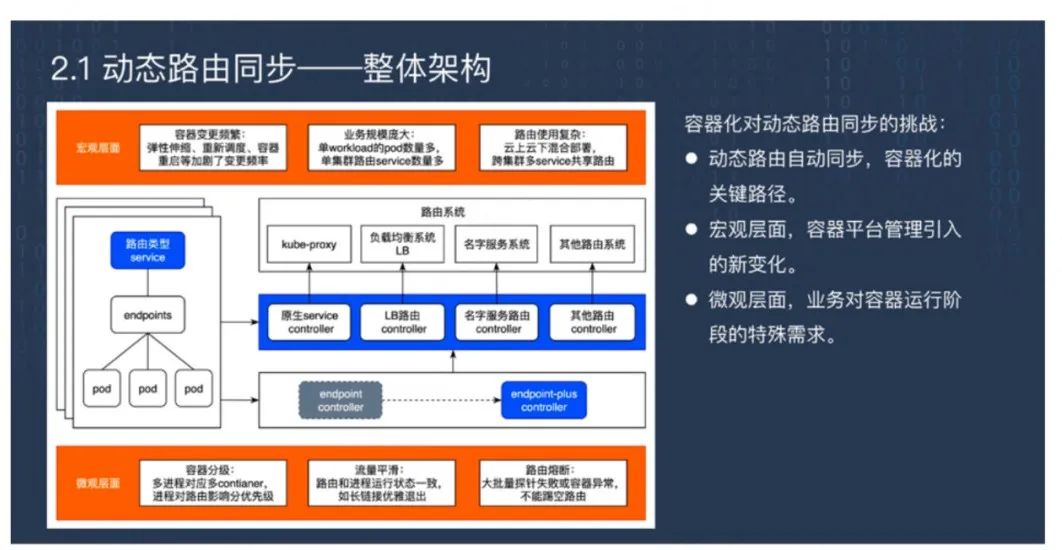
但我们的平台在生产环节中会遇到一些特殊情况。第一个情况就是容器化之后容器的变更更加频繁。第二个变化在于业务规模非常庞大,单个负载的 Pod 可能成千上万。第三是业务层面的变化,云原生的方式是一个集群对一个路由入口,但在生产环节又是第三方路由系统,允许云上云下混合部署,跨集群多路由服务共享路由。动态路由是容器化的关键路径,是要解决的核心问题。
在微观层面,业务对容器运行阶段有特殊需求,包括容器分级、路由和进程的运行状态一致、大批量探针失败时要实现路由熔断。
生产环节中路由系统是非常多的,每个路由系统会对应一种控制组件。所以我们需要路由同步 Controller的统一框架。这个框架理论上是一个旁路 Controller,因此存在不可靠的问题。例如在 Pod 下线前,销毁的时候不保证已经剔除路由;又比如在滚动更新时,可能上一批还没有添加路由,下一批就开始销毁重建。由于有些业务又比较敏感,必须要求绝对保证线下和滚动的时候路由的正确性,于是我们利用了 K8s 云原生的删除保护、滚动更新机制来实现这一需求。当业务在销毁之前先剔除路由,业务在滚动更新的时候先保
证上一批添加。通过这种方式将路由融入到 Pod 生命周期里,来实现业务的可靠性。
对于运行阶段,例如容器异常自动重启,或者 Pod 其中一个容器通过原地生成的方式启动,这些场景就会绕过前面提到的滚动更新和删除保护。所以还要在运行阶段保证业务之间的快速同步。业务大批量变更又会产生大量事件,导致 Controller 积压问题。
对此我们第一个优化方式是使用 Service 粒度事件合并,将事件数量成数量级减少来提高速度。第二个是双队列模型。K8s 的 Controller 里有定时历史对账机制,会将所有的 Pod 对象全部入队列。我们需要将实时和定时的事件分开,这样既能够解决定时对账,又能解决实时处理需求。
这里面有一个细节问题,两个不同队列可能在同一个时刻会有同一个事件要处理,这就需要相互感知的能力避免这种情况发生。
下一个 Controller 框架的核心点在于支持共享路由。但云原生的 K8s 机制里是一个集群对应一个路由入口,所以我们在 Controller 框架里增加一个路由同步记录,也是按照 Service 的粒度去记录的。如果业务系统产生脏数据,例如触发一个剔除操作,但是路由系统返回成功了,实际上没有剔除,那么下一次它去同步处理这个事件的时候发现它没有被剔除,那么还是会再重新剔除一遍。也就是说路由操作等于期望值去 Diff当前值,而它的期望值就等于 Endpoint 和 Pod 生命周期的交集,当前值就是路由系统里面的情况加上路由记录,二者再取差积就是要做的路由操作。
旁路 Controller 作为一个组件会有异常的时候,虽然 K8s 提供 Leader 机制,但这个机制被 Controller拉起时需要预加载存量 service 数据,如果数据量非常大需要很久时间。我们的解决方式是,每一个Controller 运行的时候属于主备模式,这样当主容器挂掉的时候,备容器获得锁,之间的间隔就是整个Controller 同步中断的最长时间,之后备容器就可以快速接管路由通路服务。中断期间可能发生事件丢失问题,我们通过定时历史对账机制解决这个问题。
我们还有特殊需求,是业务为了兼容虚拟机部署的一种管理方式,主要针对容器的运行阶段以及特殊处理。这里的需求包括容器分级、流量平衡、路由熔断。这些需求对传统的 Endpoint Controller 而言是不感知的,原来只维护 Ready 和 Not Ready 的状态,没有感知更细分的状态去维护容器的角色和状态。如果这是由路由 Controller 来实现,那么对这些特殊场景来说是牵一发而动全身的,每一个组件都得同时开发,修改一遍,维护成本是很高的。所以我们提供了一种解决方案——Endpoint-Plus Controller。它将维护容器角色和状态的能力下沉到 Endpoint 来实现。它与 Endpoint 和路由同步 Controller 之间建立一种交互协议,就是 Endpoint Ready 时添加路由,Not Ready 时禁用路由,不在 Endpoint 里删除路由。这样所有组件都是统一的,而且每次业务的新需求只要修改 Endpoint 就对全部生效,这样实现了动态路由同步的桥梁作用。

一种全新的容器销毁失败自愈机制探索
最后一个话题是关于容器销毁失败自愈的。前面提到了动态调度、弹性伸缩、容灾迁移、流水线发布,这些操作都有一个前提,就是容器销毁重建时老的容器要销毁,新的容器能创建出来。但实际上在生产环境中这并不是 100% 能保证的。因为容器是共享的,多个容器在同一个节点上,卡住的时候会涉及到很多原因:
调用链很长,只要其中任何软件出现 BUG 都会卡住;管理容器对业务容器有侵入,造成卡顿;业务容器之间互相干扰;共享内核、Cgroup、Namespace,并不保证所有资源绝对完全隔离;共享节点资源,当 CPU、磁盘 IO 高负载时会影响整个节点上的所有 Pod。
K8s 发展到现在已经有了一套很完善的自愈机制。对容器异常来说,云原生 K8s 提供一个暴力解决方案就是强删机制。该机制只是删除这个数据对象的数据,并不是销毁这个容器。这样导致一个问题,如果进行强制销毁,可能老容器会残留,新容器又起来了,这时老的容器会影响节点。
所以容器销毁阶段卡住会影响容器销毁重建这个基本需求,而且它的原因是复杂多样的,在大规模系统环境中更容易出现,而已有的自愈机制是没有涵盖这种场景的,所以我们就需要提供一种全新的自愈机制。传统的解决方案是通过脚本扫描到它,对于定位到的问题,没有解决方案的需要临时隔离,已有解决方案的就要明确修复。但这并不是一个闭环方案,因为还有很多未知问题,对未知问题来说业务关心的是尽可能恢复,而对平台来说为了保证稳定性,需要尽可能知道这些根因,去收敛这类问题。
所以我们兼顾这两个需求,要缩小定位范围、缩短定位周期,提高定位效率。对定位到根因的我们要去评估它的影响面,防止增量发生。而已经有解决方案的,我们需要有全网修复能力,出现异常的时候要告警,从而实现闭环解决方案。
我们想到了是智能运维的方法,它依靠大规模训练样本,关注相关性。而故障处理一般是小样本量,强调专业和因果性,所以它并不很适合这种场景。但在智能运维的决策树模型里有些概念可以拿来参考,譬如基尼系数、信息熵、剪枝等。
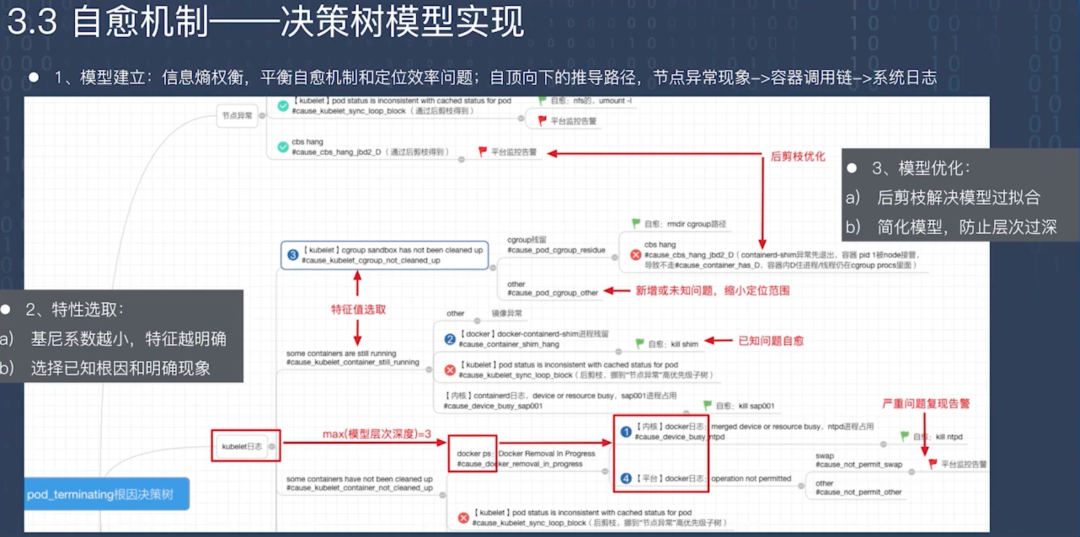
最后简单介绍一下决策树模型的实现。
第一步需要建立模型,是关于信息熵的权衡,要平衡自愈机制和定位效率。我们在选择信息熵的时候是自顶向下的推导路径,从节点异常再到容器调用链异常,再到具体系统日志。
第二步是特征选取,基尼系数越小特征越明确,所以我们选择共同特征作为一个特征值。同时选择一些已知问题或者根因比较明确的作为叶子节点。
最后一步是模型优化,例如剪枝优化,通过后剪枝的方式解决过拟合现象。同时简化模型。通过这种方式,
当容器发生销毁失败时,能够触发自愈路径。同时,对于新增问题,我们可以缩短问题范围,提高定位效率。
通过以上三步,最终我们探索出了这样一种全新的容器销毁失败自愈机制。期望本文思路对你有帮助~

