通过Python爬虫获取【小说网站GUI】数据,保姆级教学
通过Python爬虫获取【小说网站GUI】数据,保姆级教学

通过Python爬虫获取【小说网站GUI】数据,保姆级教学
目录
通过Python爬虫获取【小说网站GUI】数据,保姆级教学
前言
示例环境
爬取目标:
爬取代码
核心技术点:
注意点:
源码:
爬取结果:
前言
所有的前置环境以及需要学习的基础我都放置在【Python基础(适合初学-完整教程-学习时间一周左右-节约您的时间)】中,学完基础咱们再配置一下Python爬虫的基础环境【看完这个,还不会【Python爬虫环境】,请你吃瓜】,搞定了基础和环境,我们就可以相对的随心所欲的获取想要的数据了,所有的代码都是我一点点写的,都细心的测试过,如果某个博客爬取的内容失效,私聊我即可,留言太多了,很难看得到,本系列的文章意在于帮助大家节约工作时间,希望能给大家带来一定的价值。
示例环境
系统环境:win11 开发工具:PyCharm Community Edition 2022.3.1 Python版本:Python 3.9.6 资源地址:链接:https://pan.baidu.com/s/1UZA8AAbygpP7Dv0dYFTFFA 提取码:7m3e MySQL:5.7,url=【rm-bp1zq3879r28p726lco.mysql.rds.aliyuncs.com】,user=【qwe8403000】,pwd=【Qwe8403000】,库比较多,自己建好自己的,别跟别人冲突。

爬取目标:
输入对应的id就行直接获取其内容,保存在项目执行的位置。
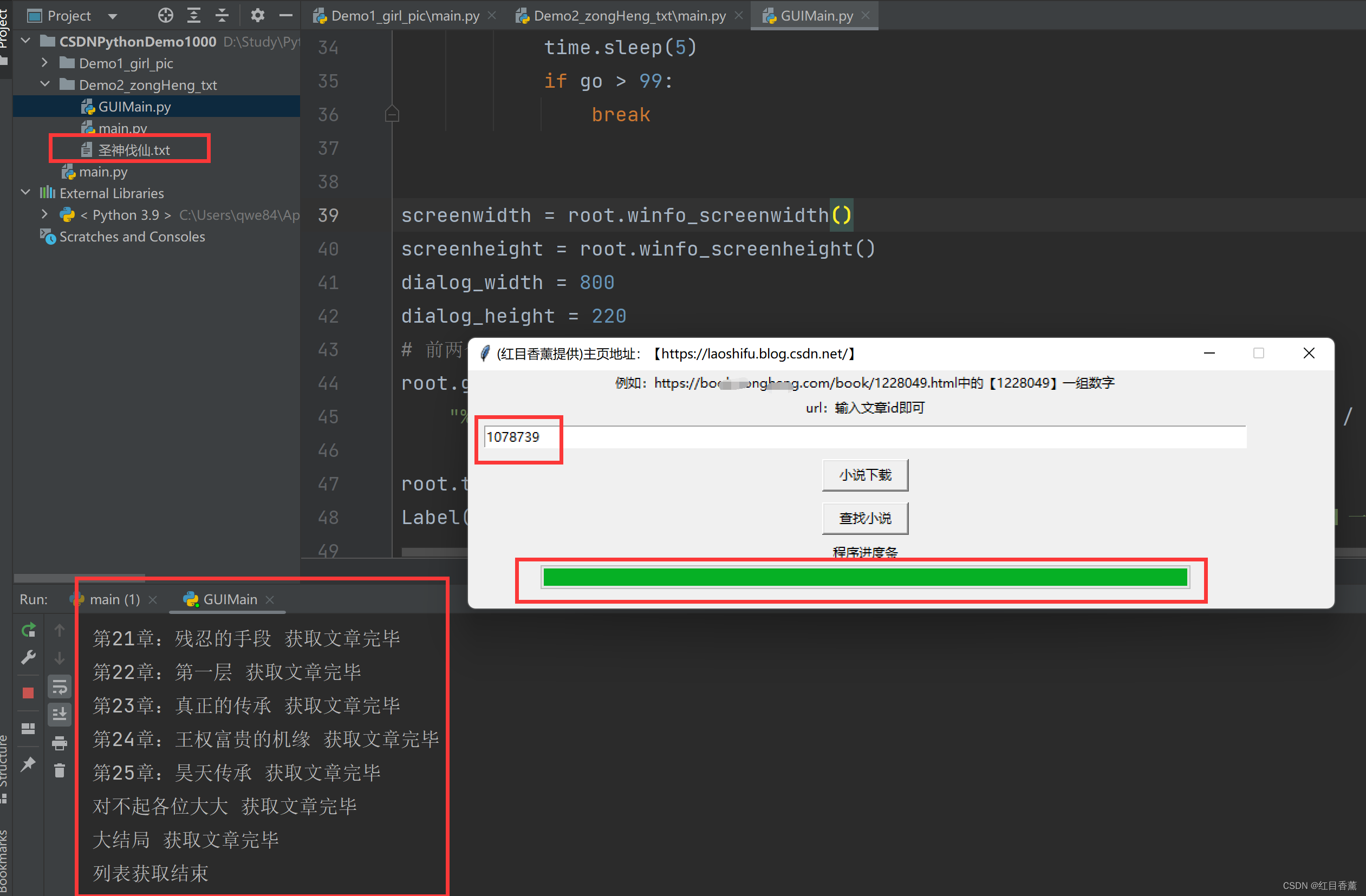
爬取代码
核心技术点:
1、requests返回的数据格式需要看网页的具体编码 2、parsel根据接口返回数据结构来选择对应的解析方案 3、Progressbar进度条控制
注意点:
1、多线程执行的时候只填写函数名称即可,不需要写括号 2、不需要使用bar.start(),直接进行bar"value"值修改后进行root.update()即可刷新页面。
源码:
import requests
import parsel
import uuid
import time
import random
import os
from tkinter import *
import threading
import tkinter.messagebox as messagebox
import tkinter as tk
from tkinter import ttk
root = Tk()
# 进度条count
barCount = []
screenwidth = root.winfo_screenwidth()
screenheight = root.winfo_screenheight()
dialog_width = 800
dialog_height = 220
# 前两个参数是窗口的大小,后面两个参数是窗口的位置
root.geometry(
"%dx%d+%d+%d" % (dialog_width, dialog_height, (screenwidth - dialog_width) / 2, (screenheight - dialog_height) / 2))
root.title("(红目香薰提供)主页地址:【https://laoshifu.blog.csdn.net/】")
Label(root, text='例如:https://book.zongheng.com/book/1228049.html中的【1228049】一组数字').grid(row=0, column=0)
Label(root, text='url:输入文章id即可').grid(row=1, column=0)
e = Entry(root, width=100)
e.grid(row=3, column=0, padx=15, pady=5)
root.resizable(height=False, width=False)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
listChild = []
listDate = []
mTitle = []
# 文章链接与标题独立列表
a_href_list = ["", ""]
# 存放文章链接与标题数组列表
a_href_arr = []
# 存放文章全文
infoDate = []
def GetUrl(url):
try:
html = requests.get(url, headers=headers)
sel = parsel.Selector(html.text)
# 获取主Title
mTitle.append(sel.css(".book-meta h1::text").getall()[0])
href = sel.css(".volume-list ul a::attr(href)").getall()
# 获取标题
text = sel.css(".volume-list ul a::text").getall()
for item1, item2 in zip(href, text):
a_href_list = ["", ""]
a_href_list[0] = item1
a_href_list[1] = item2
a_href_arr.append(a_href_list)
print("列表获取完毕")
except:
print("解析异常")
def GetTxt(url, title):
html = requests.get(url, headers=headers)
sel = parsel.Selector(html.text)
# 文章
info = sel.css(".content p::text").getall()
infoDate.append(title + "\r\n")
for item in info:
infoDate.append(item + "\r\n")
def show():
"""
开启线程1,2
:return:
"""
t1 = threading.Thread(target=showFun, name="T1")
t2 = threading.Thread(target=startThread, name="T2")
t1.start()
t2.start()
def showFun():
try:
# 获取的文本
oldUrl = e.get()
# 1159606
bookIdDir = "https://book.zongheng.com/showchapter/{0}.html".format(oldUrl)
GetUrl(bookIdDir)
for item in a_href_arr:
barCount.append("1")
GetTxt(item[0], item[1])
print(item[1], "获取文章完毕")
time.sleep(random.uniform(0.5, 1.5))
with open(str.format("{0}.txt", mTitle[0]), "w+", encoding="utf-8") as f:
f.write("".join(infoDate))
f.close()
os.system("explorer .")
messagebox.showinfo("提示", str.format("{0}.txt", mTitle[0]), "保存完毕")
except:
print("列表获取结束")
def find():
"""打开默认页面"""
os.system(
'"C:/Program Files/Internet Explorer/iexplore.exe" https://book.zongheng.com/store/c0/c0/b0/u21/p1/v0/s1/t0/u0/i1/ALL.html')
def startThread():
"""进度条读条"""
time.sleep(2)
bar["value"] = 0
while True:
if len(a_href_arr) > 1:
go = (float(len(barCount)) / len(a_href_arr)) * 100
bar["value"] = go
bar.Progress = "{0}%".format(go)
root.update()
time.sleep(5)
if go > 99:
break
Button(root, text='小说下载', width=10, command=show).grid(row=4, column=0, padx=10, pady=5)
Button(root, text='查找小说', width=10, command=find).grid(row=5, column=0, padx=10, pady=5)
Label(root, text='程序进度条').grid(row=6, column=0)
bar = ttk.Progressbar(root, length=600, cursor='spider', mode="determinate", maximum=100, orient=tk.HORIZONTAL)
bar.grid(row=7, column=0)
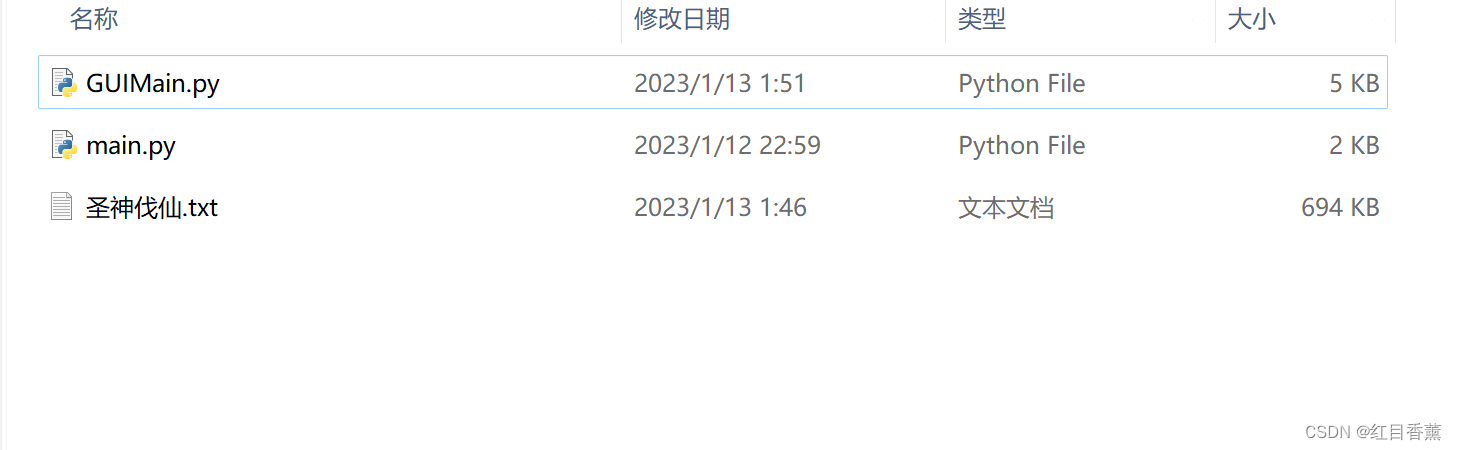
mainloop()爬取结果:
都放在一个txt文档中了。
后续我会打包生成下载GUI工具直接下载即可使用。
下载地址:【方便下载小说,小说都是公开免费的,放心下载】