【杂谈】聊聊我们关于网络拥塞与控制优化的一些技术方案
原创【杂谈】聊聊我们关于网络拥塞与控制优化的一些技术方案
原创
何为拥塞控制算法?
想要理解拥塞控制算法,我们首先要对网络为什么会出现丢包卡顿进行一个简单的解释。
互联网上的两点通信时,每经过一个路由设备叫一跳(Hop)。而每一跳都有不同的带宽,两点之间的可用带宽是每一跳中的最小值,被称为“Bottleneck BW”。
因为是公共链路,它们拥挤、丢包和排队难以避免,可用带宽也时大时小,这便是网络卡顿的根本原因之一。
但网络通信有一个补救机制,即使排队和路由抖动产生了丢包或者数据错误,4层的TCP协议也会处理,它会重传并进行带宽控制,以保证数据的完整性,这便是拥塞控制算法的核心。
早期的Cubic拥塞控制算法
1980年代的互联网崩溃,促成了TCP拥塞控制的落地。经过十多年的发展,Cubic出现并延续至今。目前它仍然是互联网主流的拥塞控制算法,基于著名的“加性增,乘性减”(AIMD)控制律,将丢包作为网络链路拥塞的指示。
当发送端感知到丢包时,传统的TCP拥塞控制算法会减小发送端的拥塞窗口 Cwnd,限制报文的发送。这类拥塞控制算法也被称为基于丢包(Loss-based)的拥塞控制算法。同类算法有几个,例如更早前的Reno,BIC等。
由于只有当路由器的队列满了以后才会有丢包,因此,这类算法倾向于快速填满瓶颈路由器的缓存,然后急剧降低发包(比如减少50%),当队列空闲后又慢慢填满,周而复始。
Cubic算法的正常运行对链路的丢包率有一定的要求,在丢包率较高的长肥管道环境下,其发送窗口会迅速收敛到很小。另一方面,当实际可用带宽增大时,它总是会花固定的时间去探测然后慢慢增大,效率是相对低下的。
同时,Cubic在拥塞避免阶段会逐渐加大发送窗口直至填满瓶颈队列,这种机制加速了拥塞的形成,造成了网络延时的波动。
由此,我们知道,在链路瓶颈处保持最大带宽和最小延时的状态是拥塞控制的目标,但明显Cubic在目前的互联网环境中已经不能很好地胜任。
Google BBR 的设计思路
基于上述Cubic算法的短板,谷歌提出一种基于延时带宽积的算法BBR (Bottleneck Bandwidth and RTT),使用了交替测试链路的最大带宽与最小的RTT的方法,来寻找名为Kleinrock的最佳操作点。如下图所示,Cubic的拥塞控制点是排队并且缓存已经满了。
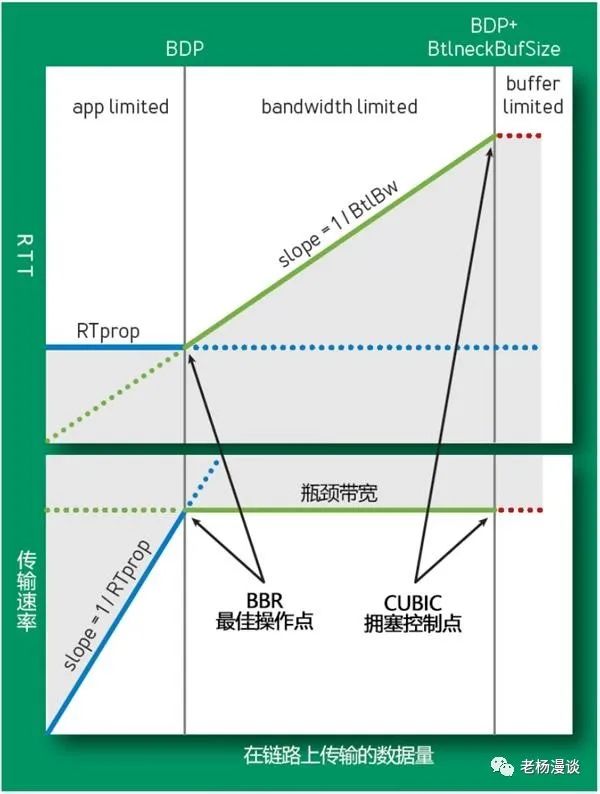
BBR的总体设计思路是:控制时机提前,不再等到丢包时再进行暴力限制,而是控制稳定的发包速度,尽量榨干带宽,却又不让报文在中间设备的缓存队列上累积。
为了得到稳定的发包速度,BBR 使用 TCP Pacing 进行发包控制,因此 BBR 的实现也需要底层支持 TCP Pacing; 为了榨干带宽,BBR 会周期性地去探测是否链路条件变好了,如果是,则加大发送速率; 为了不让报文在中间设备的缓存队列上累积,BBR 会周期性地探测链路的最小 RTT,并使用该最小 RTT 计算发包速率。
具体来说是将最近10次往返中测得的最大带宽视为Bmax,将过去10s中测得的最小RTT视为Tprop,然后根据这两个值估算BDP。
BDP = Bmax × Tprop
BBR分别通过窗口增益和起搏增益来调整CWND和发送速率,进而控制其发送行为,将拥塞快速收敛到最佳控制点。
BBR算法的带宽敏感性
BBR算法最终会稳定在Steady-state,即其PROBE_BW的状态,该状态内置了一个小循环,BBR在这个循环中不停运转:
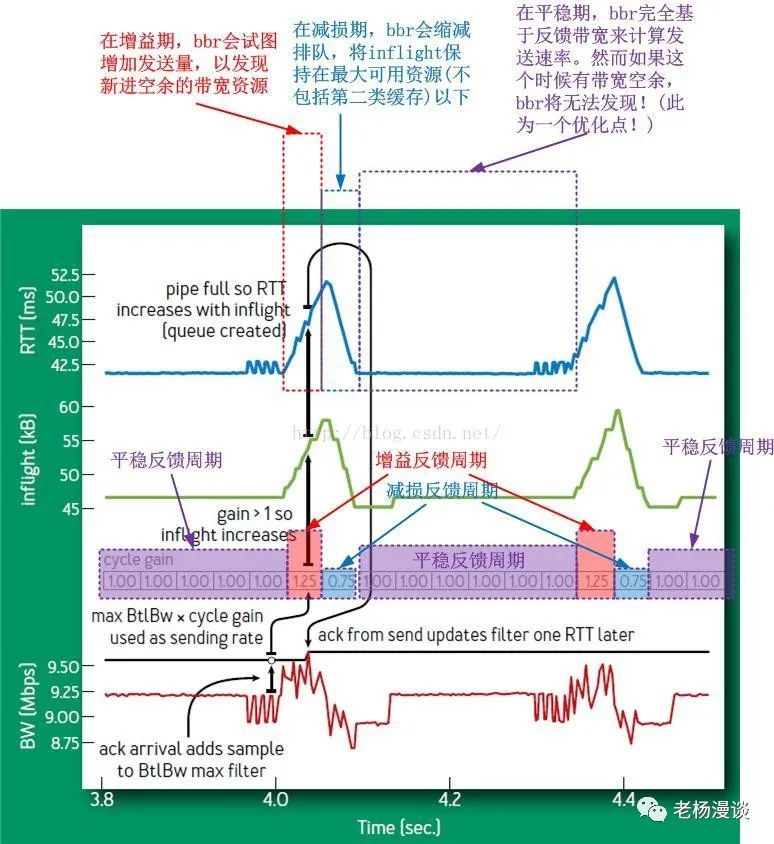
注意其中的速率增益:1|1|1|1|1|1|1.25|0.75|1|1|1|1|1|1|1.25|0.75|1|...
这个循环增益完全是BBR自主的循环增益,不受任何外界控制,而是否进入下一个增益则取决于以下的判断:
1.正增益周期,是否在不丢包情况下已经填满了可用带宽,这个旨在提高资源利用率(效率因素)
2.减损周期内,是否已经腾出了部分可用资源,这个旨在满足公平性(公平因素)
3.平稳反馈周期是否足够久,使得共享资源的TCP连接有时间收敛到一个公平的位置(公平因素)
这是个典型的效率优先兼顾公平的实例,但是我们可以看到,如果上述的第三点,即平稳反馈周期太久会怎样?很显然,这样的话会降低BBR的抢占性和灵活性,bbr发现带宽富余的最短时间就是6个RTT,这对于某些场景而言显然是不足的。
因此,我们可以得出第一个结论:
1.PROBE_BW状态中平稳反馈周期的长度决定了BBR的抢占敏感性。
我们知道,Reno/CUBIC直接在膝点处采取措施,使得拥塞得以避免,即便是持续保持慢速,也不会到达崖点,Reno/CUBIC将丢包作为到达膝点的标志,然后退出拥塞控制算法,进入拥塞恢复阶段,直到拥塞被认为缓解恢复正常,是不会把控制权再度交给拥塞控制算法的。
这也是经典的拥塞控制风格作风,本质就是在膝点采取措施,避免从崖点跌落,这便是经典的锯齿之由来!锯齿尖的位置,那是膝点,而不是崖点!
那么BBR是不是也类似呢?并不是!因为BBR不会被接管,BBR自己全程负责所有的拥塞处理.事实上,BBR根本不管什么拥塞不拥塞,它只是单纯的根据自己收到的带宽反馈来计算下面发送的带宽。
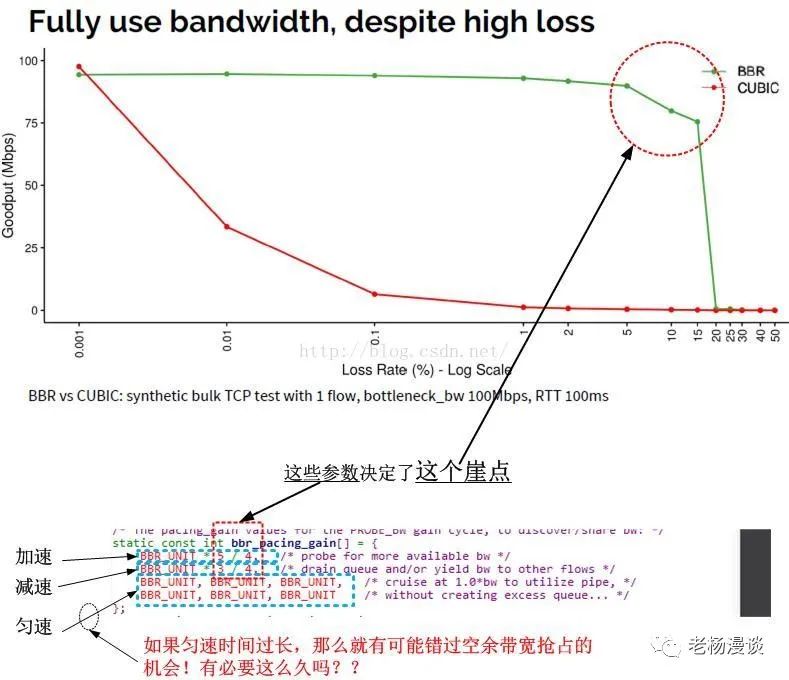
为什么BBR会面临一个崖点?
崖点的存在,正是因为bbr_pacing_gain数组的固定配置。
崖点的存在是一种”资不抵债“的退避措施。我们看到在bbr_pacing_gain数组中,其增益元素的增益比是1/4,也就是25%,可以简单理解为,在增益周期,BBR可以多发送25%的数据!
注意看上面的图的横轴丢包率,当丢包率接近25%的时候,曲线从崖点跌落,这并不是偶然的。过程很容易理解,首先,在增益期,x%的丢包率是否抵消了增益比25%?也就是说,x是否大于25。
我们假设x就是25。那么可想而知,25%的收益完全被25%的丢包所抵消,相当于没有收益,接下来的减损周期,又减少了25%的发送数据,同时丢包率依然是25%...
再接下来的6个RTT,持续保持25%的丢包率,而发送率却仅仅基于反馈,即每次递减25%,我们可以看到,在bbr_pacing_gain标识的所有8周期,数据的发送量是只减不增的,并且会一直持续下去,这就是崖点!
我们得到的新结论是:
2.bbr_pacing_gain数组的bbr_pacing_gain0系数(当前是5/4),决定了抗丢包能力。
3.bbr_pacing_gain数组中系数为1(即平稳反馈周期)的元素的多少,决定了抗丢包能力(太久,则会持续衰减,太短,则比较颠簸)。
这是BBR不如CUBIC的地方,BBR事实上完全基于反馈,正常来讲按照数据守恒规则,一个包离开另一个方可进入的情况下,丢包率本身就会持续拉低带宽,BBR有一个5/4的增益,这可能会弥补丢包带来的反馈减损,然而增益系数5/4却是一个配置参数,当丢包率大于25%的时候,就会资不抵债!甚至丢包率在10%~15%的时候,BBR的表现就开始不佳。
BBR算法在高丢包率下的优化
请注意,任何优化都只针对特定场景的特定业务,不存在一种通用的算法优化。
Google在BBR的部署说明里的原话是:
CUBIC’s loss tolerance is a structural property of the algorithm, while BBR’s is a configuration parameter.
As BBR’s loss rate approaches the ProbeBW peak gain, the probability of measuring a delivery rate of the true BtlBworops sharply, causing the max filter to underestimate.
其中为什么会有”causing the max filter to underestimate“呢?
因为max filter是基于时间窗口的,随着时间的流逝,BBR会忘掉之前的大带宽,只记着现在由于丢包持续减少的小带宽。要注意,其实只要有丢包,在6个平稳反馈周期内,带宽就是持续减少的,然而,问题是,这些减少的量能不能通过增益周期,即bbr_pacing_gain0的收益一次性补偿,如果不能,那么跌入崖点就是必然的。
因此,拿什么来抵抗丢包呢?答案是损失一点公平性,用增益系数去换。
在这里提供我应用于AeroFlight航空飞行网和航空飞行社区的配置以供参考:
参数调整:1 Startup:快速增速,使管道充满数据。3次增速不超过50%,进入Drain。static const u32 bbr_full_bw_thresh = BBR_UNIT * 3 / 2;2 Drain:清空Startup阶段多余的队列数据。inflight<=BDP,进入Probe_BW。3 Probe_BW:大部分处于这个稳定状态,10s,min_rtt不变,进入Probe_RTT。4 Probe_RTT:探测带宽是最大值,回到Probe_BW。持续200ms,snd_cwnd=4。static const u32 bbr_cwnd_min_target = 4;static const u32 bbr_probe_rtt_mode_ms = 200;static const u32 bbr_min_rtt_win_sec = 10;
pacing_gain=2Startup:pacing_gain= cwnd_gain=2.89。Drain:pacing_gain =0.35,cwnd_gain=2.89。Probe_bw:pacing_gain =[1.25,0.75,1,1,1,1,1,1,1],cwnd_gain=2。Probe_rtt:pacing_gain= cwnd_gain=1,cwnd固定为4。
探测Probe_bw:pacing_gain=1.25,RTT没变大,BltBW更新为更大的速率。RTT变大,BltBW不变。pacing_gain=0.75,0.75倍BDP,放空管道的buffer。bbr_is_next_cycle_phase(struct sock *sk,const struct rate_sample *rs)满足条件,cycle_idx+1,bbr_check_full_bw_reached、bbr_check_drain、bbr_update_min_rtt、bbr_update_gains。
Pacing:tcp主动pacing,设置为SK_PACING_NEEDED。耗cpu,默认方式。cmpxchg(&sk->sk_pacing_status, SK_PACING_NONE, SK_PACING_NEEDED);依赖tc-fq的pacing。
其他:RTT状态下不参与BW最大值计算。当监测到使用令牌桶算法时,直接使用长期采样,避免频繁采样。函数是bbr_lt_bw_sampling。原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。