腾讯山海网关:P4可编程交换机的实践与总结

腾讯山海网关:P4可编程交换机的实践与总结

关于本文
本文为腾讯研发工程师张军伟的大作。
项目背景和收益
随着5G应用的发展,高带宽低延迟的诉求会越来越强烈,网关设备作为流量汇聚点,更能深刻感受到这种压力。发展了近十年的CPU+DPDK模式,在性能和成本双重压力下,也面临越来越大的挑战。在这样的背景下,各种智能硬件随之登场,提供各种各样的硬件offload方案。
Region EIP网关是TGW(注:Tencent GateWay)的一部分。TGW承载着公网弹性IP和负载均衡业务,负责公网和vpc网络的转换的同时,还要承担起带宽限速和流量计费的功能。我们结合Region EIP业务需求,经过技术调研,最后采用了P4+Tofino芯片可编程交换机作为Region EIP的下一代网关。
Region EIP X86网络架构
Region EIP网关一边与IDC内的vpc网络互联,一边与公网网络相连,是内外网转换的桥头堡。Region EIP之前的网关使用的是X86服务器,其网络拓扑如下图所示。
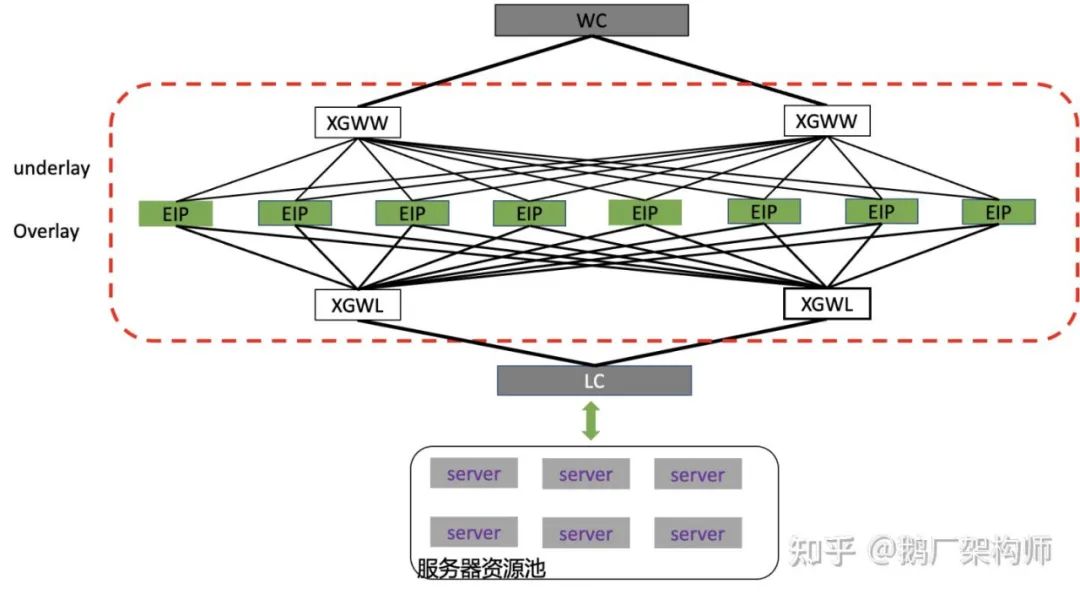
这种集群的架构设计有几个特点:
- 水平扩展:集群的机器是对等的,每台机器上都有整个集群的全量配置信息,因此可以做到流量走任意一台设备,都能够被正确的转发。注,这里的正确转发,是指跟状态无关的处理;
- 容灾备份:为了支持跨AZ机房容灾,每个集群8台机器,会被分成两组,每组4台放到一个机房里。这两组机器通过发布大小网段实现相互容灾备份。正常情况下,一个EIP的流量只会走一个机房的4台服务器,当机房网络异常时候,通过bgp把流量引导集群的另一个机房的4台服务器上去;
下面结合region EIP的业务,介绍下我们在P4可编程交换机网关上的一些实践和总结。
P4简介
网上关于P4入门的介绍材料很多,这里只做原理性的介绍。(参考阅读:P4语言教学视频和P4系列教程)P4是一种网络数据面编程语言的格式,其目的是统一数据面的编程结构,屏蔽不同硬件制造商间的差异。Tofino是目前比较成熟的P4芯片,是由Barefoot这家公司生产的,目前已经被Intel收购。我们常用的Tofino交换机是设备制造商提供的。
1. P4开发流程:
- 编写P4程序:根据P4语言标准的要求,定义数据包解析流程,定义报文处理控制程序(转发,封装等)。这里的逻辑主要依赖match-action-table的基本形式实现;
- 编译:P4程序经过芯片厂商提供的编译器,编译后输出JSON格式的交换机配置文件和运行时的API。这些编译器和设备是配套的,都是由芯片厂商自己提供的;
- 加载:编译出来的配置文件和二进制文件加载入到交换芯片;
- 配置管理:根据需要通过P4-runtime接口,对加载到芯片里的table进行遍历,对表项进行更新(增删改)和查询,比如增加一个转发规则、获取counter统计值等;
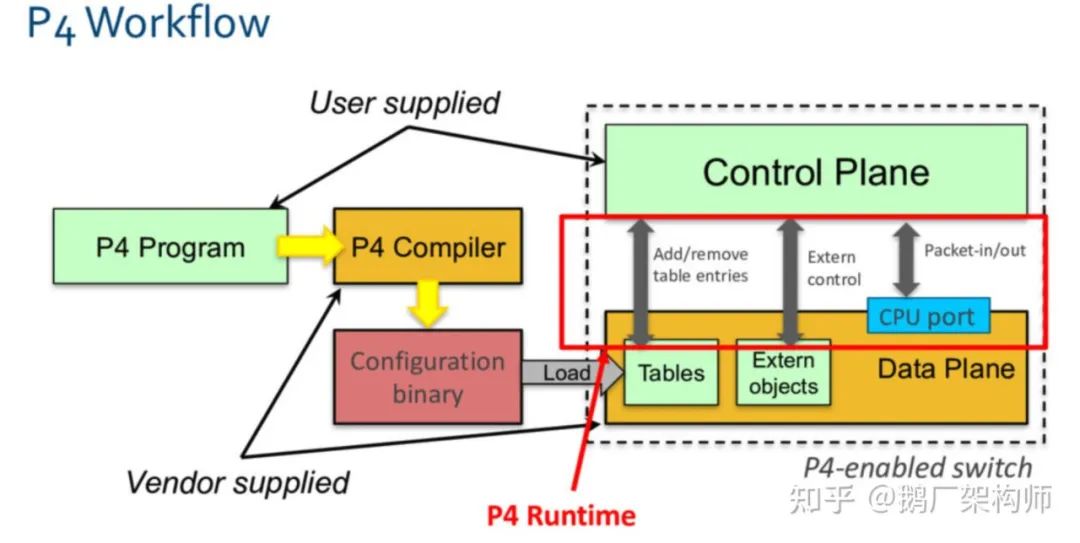
2. Pipeline:
Tofino芯片也有流水线(pipeline)的概念,一条流水线表示一组完整的数据处理流程,这一概念和传统交换机中的的流水线是相似的。如下图所示,一个pipeline包含两个阶段:ingress和egress。
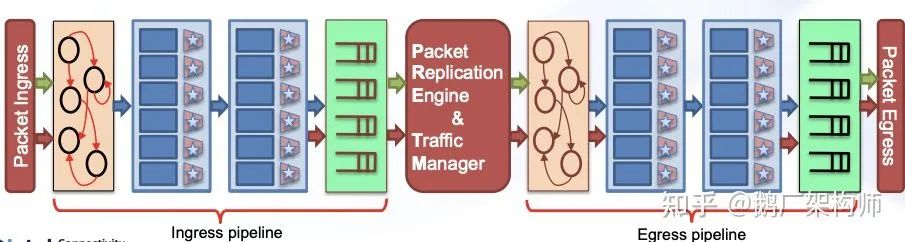
3. 可编程的Ingress/Egress:
Ingress/Egress每个阶段都可被划分成三个可编程模块:parser、ingress/egress、deparser。P4程序也基本是针对这六个模块进行编程的。每个报文经过这些处理单元时候,始终都有一块内存用于存放metadata数据,缓存中间处理数据和结果,这些meta信息可以是action的输出结果,也可以是下一个table里match的输入。
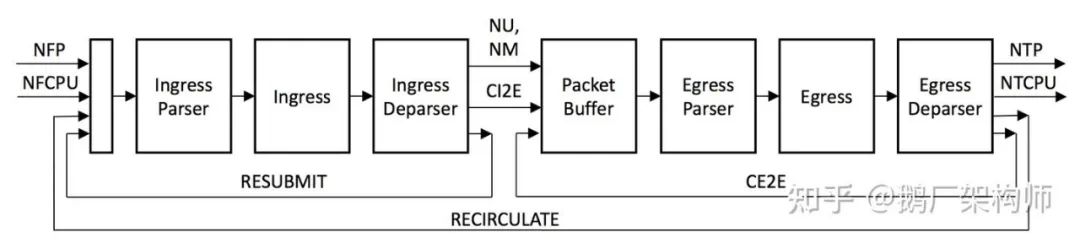
实践中,有时候会通过不同pipeline还有两种不同的用法,一类是不同pipeline承载不同功能,类似nfv的想法。另一种方法是"折叠",通过多个pipeline接力,串联使用。前者可以承载更大的带宽和网口,后者可以实现更复杂的功能逻辑,也可以获取更大的表容量。具体P4技术细节,推荐大家看一下Tofino的培训文档(见上)。
设备简介
我们目前使用的P4交换机其芯片是Tofino1代,我们有时候简称TF。交换机端口可以用被分为两类:管理口和数据口。

- 2个管理口
管理口用来链接带外和管理网,这两个口对内直接连通交换机上的CPU。带外口主要是用来做服务器设备硬件管理,上架初始化等工作的。通过管理口,交换机跟region EIP管控系统进行交互,接受下发的管理命令、业务变更等消息,并及时上报设备状态、端口流量、业务统计等数据。
- 32个流量口
交换机还提供了32个100G的网口。这些口是从Tofino交换芯片上引出来的,也正是我们可编程的部分网口。
项目收益
作为新技术的探索性项目, 我们使用P4可编程交换机从成本和性能两个维度带来了很大的收益。
- 成本:采用可编程交换机后,成本大约是原来服务器的成本60%。目前一台可编程交换机的带宽容量相当四台服务器带宽容量。32口交换机规则容量是服务器的50%,后续采用64口交换机后, 容量与x86服务器持平。集群建设方面原来8台服务器可以用4台交换机等量替换,规则容量能力不变,带宽容量是原来的2倍;
- 性能:TF芯片转发性能可以达到256字节小包限速,整机大约1Tpps的转发能力。这个性能是远高于基于CPU的软件实现的性能。

业务流程
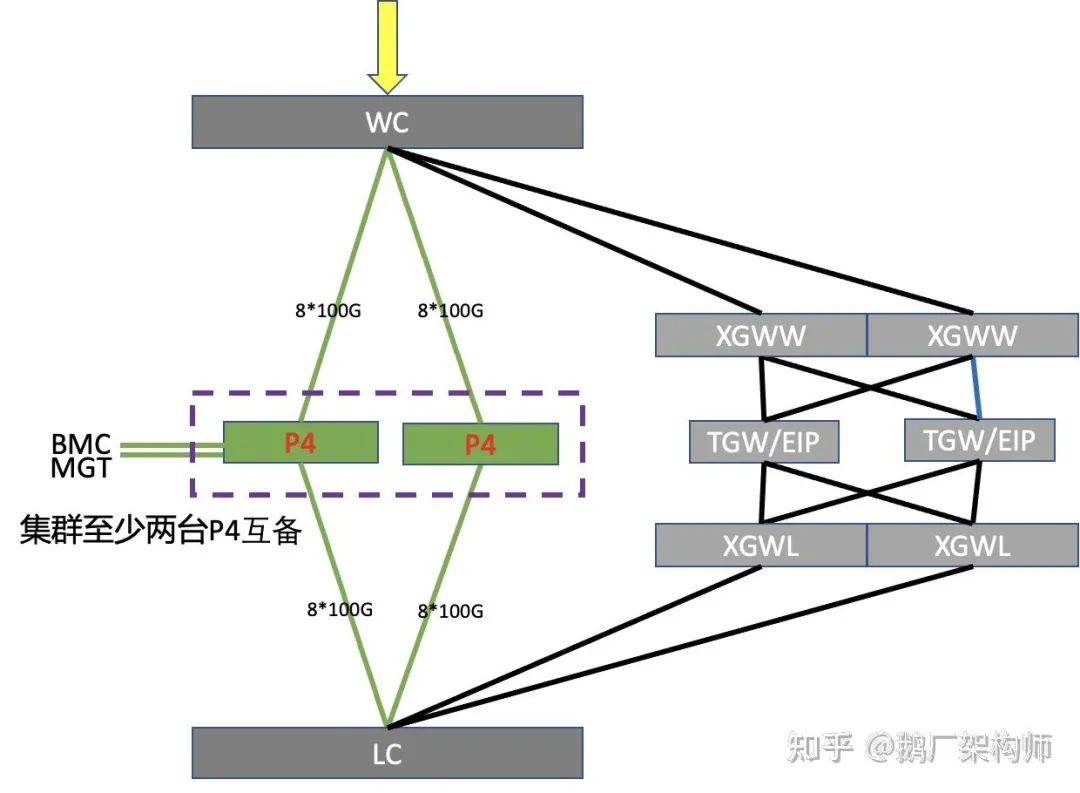
Region EIP P4的网络架构
相比x86网关设备,P4可编程交换机网关的架构相对简单些。主要区别是:
- 直接连接内外网的核心交换机(WC和LC),跳过接入交换机(WW和WL)。
- 8*100G上联4台WC交换机
- 8*100G下联4台LC交换机
- 单机800G的业务转发能力
目前交换机有32个100G口,可以支持3.2T到6.4T的转发能力。我们仅使用其中16个口,主要是为了让规则容量和带宽相匹配。目前交换机规则容量是瓶颈,带宽很富余。当规则容量达到瓶颈后,再增加网口去扩带宽,不仅没法提升整体收益的,反而造成网络端口的浪费。
P4可编程交换机网关,省略XGWW和XGWL,减少网络层级,降低网络复杂度,节约建设成本,相同规格下,机器成本可节省一半。与此同时保留了原有x86集群的可扩展性和容灾备份的能力。具体集群容量可以根据业务和容灾备份要求,进行按需扩展,可以两台或者多台,组成一个集群。
Region EIP的处理流程
网关设备可以被分为有状态网关和无状态网关两类。经常有同学问怎么算无状态的?这个我也没找到标准的出处,结合我个人理解做个解释。
相同的一个网络报文,在任何时间,经过任一台设备(集群里有多台设备)处理后,结果相同,就可以算是无状态的逻辑。比如tunnel封装,路由查找都是无状态的,而full nat则是有状态。限速是一个例外,限速导致的丢包,不能算有状态的。一个网关设备上的处理逻辑全部是无状态的,那就是个无状态的网关,否则就是个有状态的。所以,我们把Region EIP的归为无状态的网关。
控制面逻辑
我们把网关从功能处理上,可以被划分为控制面和数据面两个大模块。
控制面主要负责交换机上业务的配置管理、状态转换等,不处理具体的报文。数据面根据业务面下发的规则,对具体的报文进行转换和过滤,侧重报文转发的功能和性能。
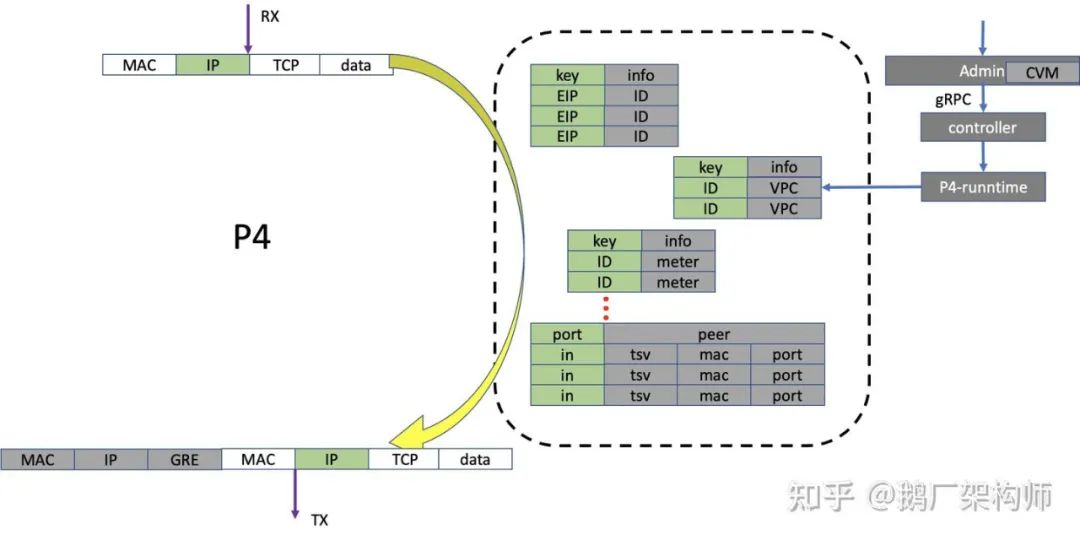
Region EIP的控制面可以分为两部分,一部分集中部署,另外一部分分布在每台设备上。在接收到网关集群控制系统下发的业务规则后,会在交换机上做一些规则转换,把业务规则转换为一系列TF上的表项和命令,下发到TF芯片上,同时也根据控制系统要求主动或者被动采集、汇总、转换设备上的统计信息(如EIP流量,端口状态,资源利用率等)发送给指定的服务(如监控,计费等)去处理。整个逻辑如下图,灰色框图部分所示。
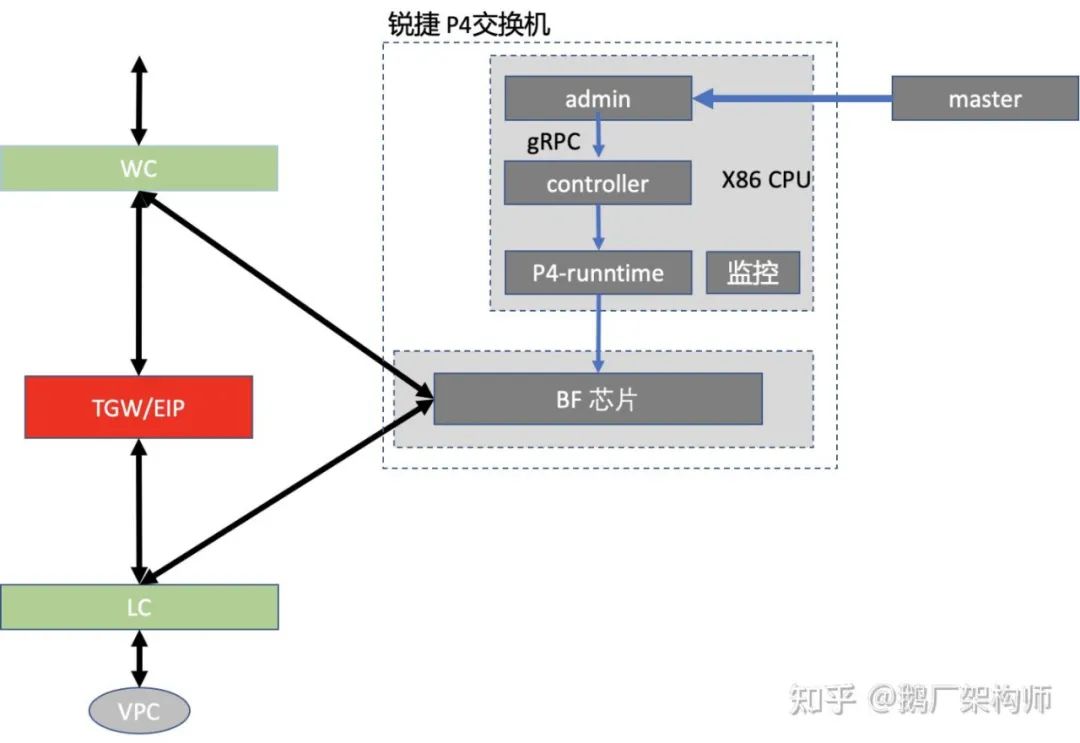
- master代表网关的控制系统(真实系统会远比这个复杂,这里用master代指整体)。master下发的是业务规则,比如创建一个新的EIP,指定其绑定的cvm(cvm的vpc id,母机,cvm vpc ip地址等);
- admin/controller/P4-runntime是工作在X86 cpu上的控制逻辑,通过P4-runntime通过的接口下发到BF芯片里。把控制逻辑划分为这三层,是为了兼容现有设计和扩展新硬件。admin层复用原有X86服务器上的逻辑和代码,并保持API一致;
- P4-runtime是P4标准的一部分,可以看做不同P4芯片的驱动接口,后续采用不同厂家的P4芯片时候,采用各自的P4-runtime模块;
- controller作为中间层,对接原有admin接口和P4 runtime接口。主要是规则和资源管理。比如芯片上meter、counter等资源的管理。跟进admin下发的EIP规则转换成芯片上对应的表项等;
数据面逻辑
从业务使用角度,我们把交换机的流量分为4类场景:
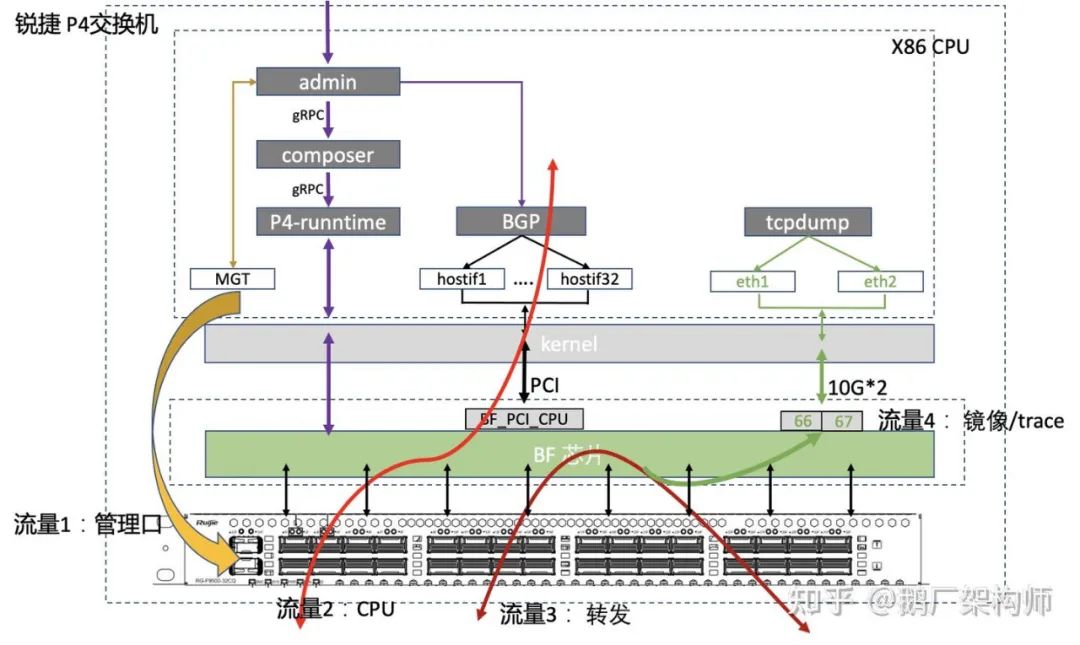
- 管理口流量:这部分流量是通过前面板的管理口,直接进入交换机上的X86 cpu系统进行处理,不经过TF交换芯片。这部分的流量处理流程跟服务器上的流量没有太大区别,只是设备形态从服务器换成了交换机。交换机的缺省路由也是配置在这个口上的;
- CPU流量:部分CPU上的流量,需要经过TF口收发。比如我们通过BGP声明EIP网段,TSV网段的报文;
- 业务转发流量:EIP的收发,转换,封装都是经过TF进行的;
- 业务的监控镜像流量:运营和监控对某个EIP进行跟踪时,把镜像流量转发到对应的镜像口上;
BF芯片上承载着后面三种场景的业务流量,其处理流程,被分成两部分:平台支撑和EIP业务。
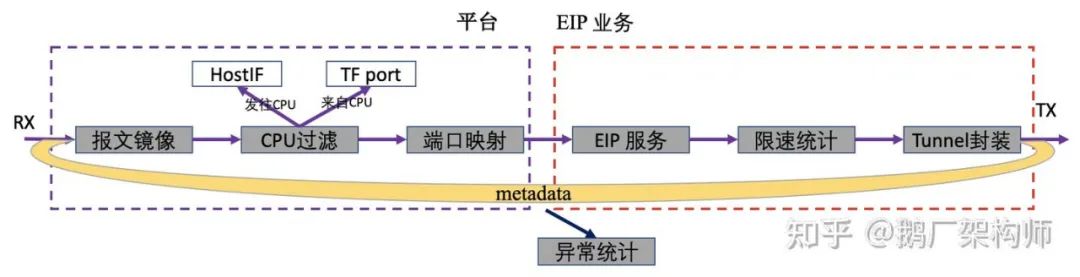
EIP业务模块是指Region EIP独有的那部分业务逻辑。比如EIP转换(overlay信息和underlay信息)功能。这个模块不仅仅要求功能,同时对容量和性能也有很高的要求。Region EIP的主要的业务逻辑,可以分为三部分:
- EIP服务:对入方向报文,根据目的IP,也就是EIP找到对应cvm的vpc信息,并存放到metadata里。对出方向报文,检查封装是否正确,去除外层GRE tunnel;
- 限速统计:对入方向报文,根据EIP进行限速并统计流量。对出方向报文,先根据tunnel信息和内层源IP查找EIP,再进行报文限速和统计;
- tunnel封装:跟传统交换机不一样的地方,我们这里没有使用完整的路由表和邻居转发表。而是使用了一个端口映射表,将出入方向的端口做一对一的映射,并根据metadata数据构造GRE头。这些映射关系在系统初始化的时候,由CPU根据系统邻居表信息填入到端口映射表里;
平台支撑模块跟业务相对比较松散,将来可以供其他网关设备复用。这部分功能有报文镜像,CPU报文处理等。以CPU处理为例,既要转发CPU发往TF端口的,也要处理反向报文。把TF端口上收到的报文,进行分类过滤,把发往CPU的报文识别出来,并转发给CPU口。这部分功能是TGW的代码库里的一部分,目前正在OTeam(注:腾讯内部开源协同小组)的协助下,进行技术方案讨论,后续会贡献到公司可编程交换机(TF)平台上,并与其他平台功能进行融合和集成。
整个流程中,每个报文都有一个预定义的metadata信息,用来缓存一些查询结果,比如output口序号,GRE报文字段等,最后tunnel模块会根据metadata里的数据,封装外层GRE头并发送。有时候异常报文或者配置错误,导致报文查找失败或者超过限速丢包时,会统计各类异常,然后再丢弃报文。

P4编程的一点变化
硬件是把双刃剑:硬件offload能够实现软件无法达到的性能和低延迟,同时也在软件设计方面带来了一些变化。在我们方案设计时,需要兼顾这些变化。有时候,还需要我们做比较大的调整,才能把硬件的优势完全体现出来。下面结合两个比较有代表性的方法,解释一下。
"傻快”
虽然大家都习惯称各种offload方案为智能网卡,智能(可编程)交换机,可以达到10倍甚至100倍的性能提升,能做到us级别的延迟,性能很强,经常被称为高性能的实现方案。但相比软件来说,他们只能实现些简单逻辑,因为我称他们为"傻快"。那我们应该怎么设计P4处理逻辑,才能更好的发挥硬件"傻快"的优势?我们采用“拆”:拆分功能表,让每个表功能单一,利用性能优势,提高灵活性。
使用软件(DPDK)处理时候,我们为了追求高性能,充分利用cache的性能,往往做尽可能减少表的数量和查找。简单说,就是"拿内存换性能”。一般把多个逻辑整合到一张大的会话表里,把必需的信息放到一个大而全的结构体里,通过一次查找,找到这个结构体。比如EIP的vpc信息,统计,限速等汇聚在一个结构体里,根据EIP进行一次查找,就把主要的信息获取到,然后对报文进行处理。避免多次查找,降低查找和cache更新造成的性能损耗。
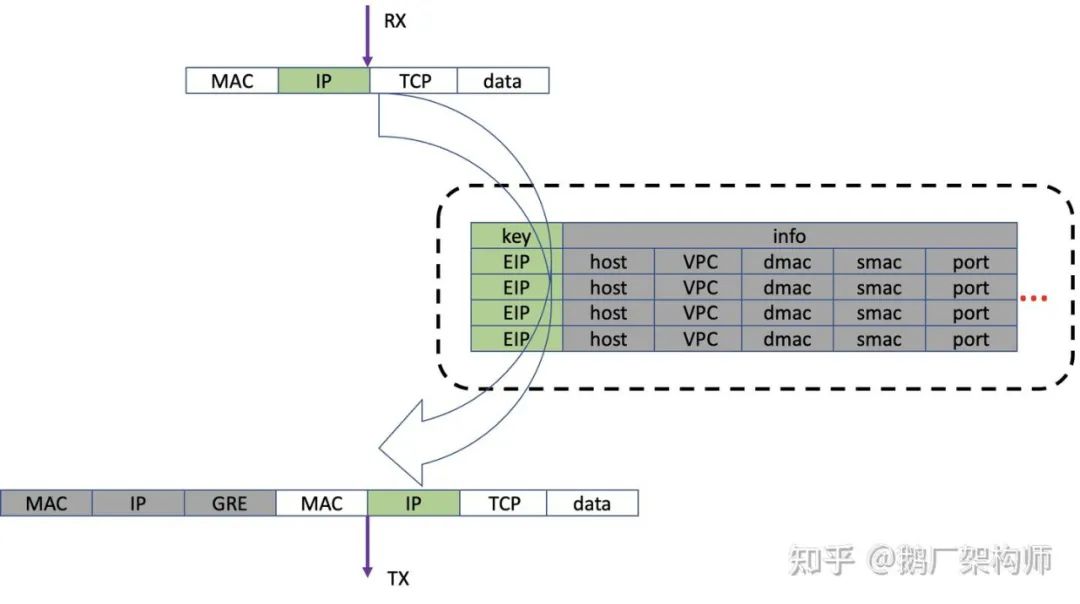
在P4编程时候,这样的设计的劣势会因为硬件的特性被放大。因为:
- 内存消耗大:这种cache往往会有大量冗余信息,造成内存浪费。相比服务器动辄几百G的内存的土豪模式,Tofino内存少的可怜。每个pipeline只有10+M SRAM内存,TCAM内存更少。交换机一般只有2个或者4个pipeline。
- 更新速度慢:硬件上内存的更新不如x86主机内存的更新速度快。一个大而全的结构体,任何一个field变化时候,都需要更新整个结构体。
我们把小的功能单元拆成多个单独的table,利用多级table进行匹配查找。利用硬件的高性能,抵消掉多次查找的损耗。因为硬件table查找延迟是ns级别,增加的延迟可以忽略不计。这样使得系统保持高性能的同时,还能做的更灵活,减少信息的冗余,使用10M左右的内存,存放了6W个EIP的规则,相比x86节省了不少内存。
数据面自学习和硬件offload
“自学习”一直以来都是很有争议的话题。就像“tab宽度是到底应该几个字节一样”,公说公有理婆说婆有理。先举个例子,出于容灾和调度的考虑,有时候我们需要把一个cvm从一台母机热迁移到另一台母机。CVM热迁移时候如何保证外网通信平滑顺畅,需要网关和母机侧协同处理。一般有"自学习"和"延迟代转"两类方法。
- 自学习:网关数据面根据收到的cvm报文封装信息,与原有信息比对,如果发现母机地址不一致,则会把网关的信息更新到本地。后续发往cvm的报文,使用新母机地址发包;
- 延迟代转:网关侧数据面不处理母机变化信息,报文仍然发往原有母机。原母机把报文转发到新的母机上。待网关管控系统处理完cvm迁移消息,下发新的母机地址到网关数据面,之后报文就被转发到新的母机上。等待一段时间,原母机上停止代转;
"自学习"让切换变得更顺畅, 特别是在一些灾备场景下,能够做到极快的切换时间。但同时也增加了系统之间的相互依赖。在可编程硬件场景下会让这个矛盾更突出。
硬件的特点是“傻快”。目前的硬件能够识别解析报文,但是很难做到根据报文特定字段去更新硬件表项内容。个别FPGA可能通过定制化开发实现一些简单的学习功能,很难做到比较普适。此外也有些软硬件结合的方案来实现自学习功能。比如:
- 把要学习的字段当做key的一部分下发到table里,当做key的一部分。这样当有变更时候,报文就会miss,进而通过upcall上送给CPU。
软硬件学习的方案有一个潜在的风险就是upcall的流量瞬间太大,产生成为瓶颈。在一些极端异常情况下,考虑不周或者控制不细致,可能会造成”雪崩“。
相对这些方案,“延迟代转“的方式对硬件基本无依赖,更容易在可编程硬件上落地。

P4交换机的优势和局限
1、TF芯片的优势
在P4的开发过程中,随着对芯片熟悉程度的深入,我们也逐渐意识到到芯片的优势和一些缺陷。P4带来的优势在一些大带宽的场景下体现的更明显。
a. 大带宽&高性能:
目前基于Tofino芯片的100G端口交换机,单机有3.2T到6.4T带宽,小包线速(这里的小包是套用厂家的宣传词而已,特指256字节,不是通常的64字节:)报文转发。相当于单颗芯片大约1GPPS的转发性能,跟x86服务器相比,单核大约有近百倍的提升,整机性能有数倍提升。
b. 编码更简洁
使用DPDK编写数据面转发的时候, 经常使用一些优化的方法,如 :
- 无锁设计,避免全局锁
- 规则表和统计尽量per cpu化
- 减少核间通讯
- 内存预取
- 避免跨numa的访问
通过这些方法的优化,提升了性能,也给开发设置了很多限制,增加开发的难度。在考虑业务处理逻辑时,还要兼顾优化性能。通过多核线性扩展支持更高性能,同时又要尽量避免核和核之间的交互,往往最后还要做些妥协。比如一个EIP的流量我们分到多个CPU上处理, 限速的时候就很难做到很精准。相比之下,P4的编程是单线程模型,限制也少了很多。P4编程更多关注的功能实现,通过match-action-table的模式实现数据转发功能。
2、TF芯片的局限
在Tonifo芯片编程中,我们也遇到过一些TF本身设计上的局限。这些局限需要我们在设计方案时候有所了解,避免踩坑。
- 内存少:不论是SRAM还是TCAM的容量,跟x86服务器不具有可比性。SRAM单pipeline 10+MB的内存容量。这些容量还分散在不同的stage里,不能动态共享;
- stage:当table产生依赖时候,就会被放在不同的stage里。一个pipeline里的12个stage,处理太复杂的逻辑,会出现stage不够用的风险。通过pipeline折叠,可缓解这个不足,但在控制管理上会变得不太友好;
- parse解析条件单一:只能根据报文格式进行解析,没法结合业务场景做灵活限制。比如不能只解析特定网口(内网口)的vxlan报文,没法对外网口的vxlan报文不解析;
- parse对变长的TLV结构体支持的不友好:没法做到根据length值灵活的分配内存,在解析IPv6和IPv4的option时候会比较麻烦;
- 容量有一定的缩水:当定义一个table的容量一般可以做到95%的使用量。因为硬件实现使用了4路硬件hash,会存在小概率的碰撞,导致表格容量没法做到100%的利用率;
- 报文长度只能在egress阶段获得:这是硬件设计上的限制,导致一些限速和统计逻辑只能放到egress过程处理;
- counter统计不灵活:counter统计的时候只能根据TF定义的字段和偏移值去统计,没法根据业务自定义值统计。比如有的tcp链接需要统计ETH头长度,有的不需要统计;
- 报文分片支持不友好:报文截断的功能只能通过mirror实现,没法动态指定截断长度。使用mirror做规避会造成第一个分片比第二片报文长度小,不符合习惯用法;
- 报文分片重组功能不支持, 目前需要上送cpu或者其他设备配合。
最后作为一种新的设备形态,在引入到生产环境中,还经常会遇到一些流程和管理方面的问题,需要多部门协同,打通流程规范。比如经常被问到的:P4设备是交换机还是服务器?以往网关设备都是服务器,现在用交换机做网关,如何对设备进行管理?IP地址分配、机器交付和维修、成本核算等,都经常被问到这个问题。这些问题不同于高难度的技术问题,但也很重要,会影响产品的上线和运营。目前Oteam团队在着手推动这些问题的解决。
腾讯云开发者
