Kaggle Feedback Prize金牌思路赛后总结

Kaggle Feedback Prize金牌思路赛后总结

lyhue1991
发布于 2023-02-23 12:03:21
发布于 2023-02-23 12:03:21
近期刚结束Kaggle Feedback Prize比赛,第四范式AutoX团队获得金牌。

同时,团队成员poteman晋升Kaggle Grandmaster。截止目前共斩获8金16银10铜,最高排名全球第11。
本文将介绍Feedback的赛题任务和前排解决方案,文中不足之处,还望批评指正。
赛题介绍
评估议论文中写作元素的有效性,写作元素包含: Lead, Position, Claim, Counterclaim, Rebuttal, Evidence, Concluding Statement。
每篇议论文中的写作元素已经被标记出来,需要判断该写作元素的有效性(Ineffective, Adequate, Effective)。
赛题链接
https://www.kaggle.com/competitions/feedback-prize-effectiveness/
评价指标
multi-class logarithmic loss
TOP方案介绍
整理了一个架构图如下,整体方案介绍也会围绕这张架构图展开。
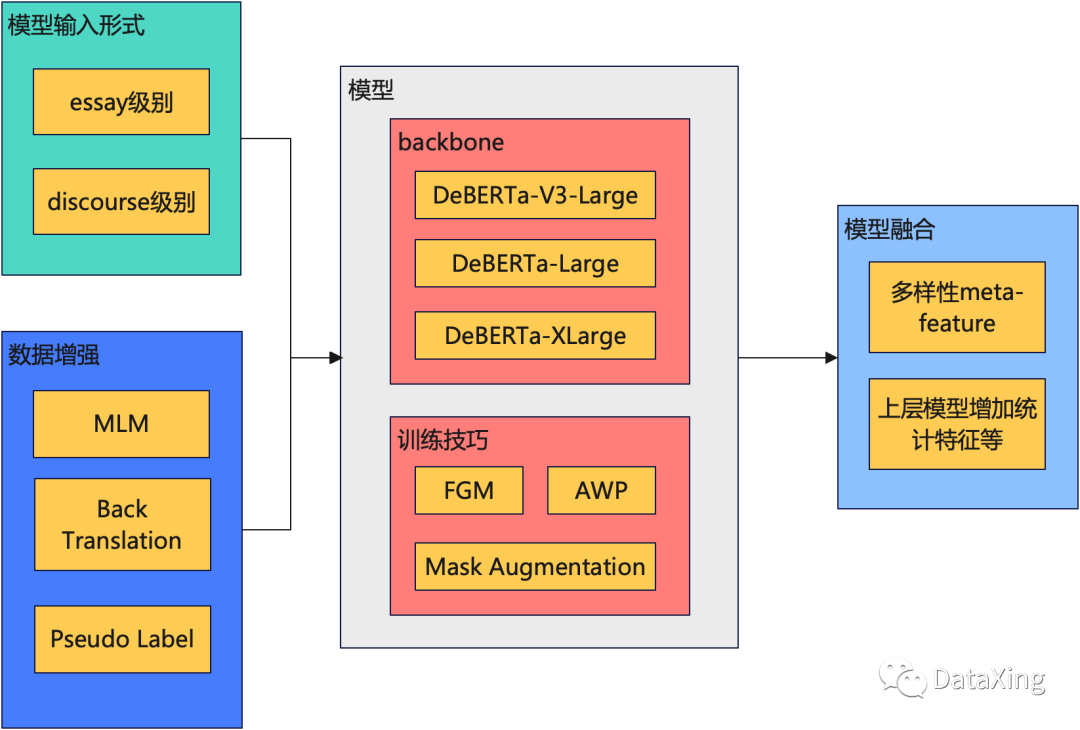
1. 模型输入形式
1.1 disourse级别
这是直接能想到的一种输入方式,每条样本是需要预测的discourse,并将对应的essay、discourse type等信息拼接到这条discourse上进行预测。
1.2 essay级别
同时预测一个essay中的多个discourses,这种方法准确率和效率都能得到提高。
具体做法: 在essay中将要预测discourse的标记出来,常见的做法是使用[start]和[end]标识符标记discourse的开始和结束。同时,将discourse type的信息也嵌入到essay中,处理方式包括将[discourse_type]直接嵌入,或者以[discourse_type start]和[discourse_type end]的形式嵌入。
这种处理方法中,在模型输出部分可以有多种方式:第一种是在输入的时候,每个discourse对应的位置嵌入一个[cls],经过transformer之后,对[cls]的表征做预测;第二种是在discourse tokens的pooling表征之后加上GRU/LSTM等进行预测。
2. 数据增强
2.1 MLM
使用上一次举办的feedback比赛数据(打标签方式不一样,可以理解为无标记数据)进行预训练。
2.2 Pseudo Labal
第二名的PL策略:
第一步, 使用ground truth训练模型;
第二步, 对无标记数据进行预测;
第三步, 利用无标记数据集的预测结果(概率值),通过crossentropy loss更新模型,再用ground truth训练模型;
第四步, 重复第二步和第三步。
2.3 Back Translation
将样本翻译成其他语音(例如中文),再翻译回英文,进行样本扩充。
3. 模型部分
3.1 backbone
前排常见的backbone包括:DeBERTa-V3-large、DeBERTa-Large、DeBERTa-XLarge。
3.2 训练技巧
3.2.1 对抗训练
通过模型求取特定扰动并混入到样本中,再在加噪样本下学习正确的标签。
3.2.1.1 对抗训练-FGM(Fast Gradient Method)
来自论文Adversarial Training Methods for Semi-Supervised TextClassification。
3.2.1.2 对抗训练-AWP(Adversial Weight Perturbation)
来自论文Adversarial Weight Perturbation HelpsRobust Generalization,与FGM只对输入施加扰动不同,AWP的思想是同时对输入和模型参数施加扰动。
3.2.2 Mask augmentation
按一定比例对输入句子里面的token随机进行mask,增加噪音,增加模型鲁棒性。
3.2.3
第二名的方案中建议采用StratifiedGroupKFold,能提高cv和lb的一致性。
4. 模型融合
前几名的方案都使用了两层甚至三层模型融合策略,而且都得到了不小的收益。最下面一层的模型使用多样性的bert产生metafature(包括discourse的分类概率、token的表征等)。上层的模型采用包括如lightgbm,xgboost, lstm等,同时建模过程中也增加了一些特征,例如一些disourse和essay的统计信息。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-09-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号