idapython使用笔记


idapython的学习资料推荐
- 《ida权威指南第二版》
- [https://wooyun.js.org/drops/IDAPython%20%E8%AE%A9%E4%BD%A0%E7%9A%84%E7%94%9F%E6%B4%BB%E6%9B%B4%E6%BB%8B%E6%B6%A6%20part1%20and%20part2.html](https://wooyun.js.org/drops/IDAPython 让你的生活更滋润 part1 and part2.html)
- https://cartermgj.github.io/2017/10/10/ida-python/
- https://www.hex-rays.com/products/ida/support/idapython_docs/
- 《idapython book》有中文版本的翻译
- https://bbs.pediy.com/thread-225091.htm python模拟执行x86,基于idapython
- 《The Beginner’s Guide to IDAPython version 6.0》
ida python2 and python3 switch
You have chosen to enable IDAPython 2. The IDAPython 3 plugins have been renamed to idapython.3.disabled and idapython64.3.disabled in the plugins subdirectory. If you want to switch to IDAPython 3, proceed as follows:
- Rename idapython[64].dll to idapython[64].2.disabled.
- Rename idapython[64].3.disabled to idapython[64].dll.
- Make sure a 64-bit Python 3 interpreter is installed.
- Run the command-line tool idapyswitch to configure IDAPython 3 for your Python interpreter.
简介
IDAPython核心有如下3个python模块:
- idc模块负责提供IDC中所有的函数功能。
- idautils提供大量的实用函数,其中许多函数可生成各种数据库相关对象(如函数或交叉引用)的python列表。
- idaapi 允许使用者通过类的形式,访问更多底层的数据 。
需要注意的是IDAPython会自动导入idc和idautils模块,idaapi模块需要自己手工导入。
为了使用的清晰性,建议在开头都进行手工的import这三个模块。
注意事项
由于idaPython的升级,导致一些函数给改没了,文档中不再对之前版本的函数进行说明,但是这些函数都用新函数进行了实现,新旧关系的对应在文件 idc_bc695.py,可以进行对照说明。
基本操作
获取当前地址
idc.here()
idc.get_screen_ea()获取当前地址空间的最小地址和最大地址
idc.get_inf_attr(INF_MIN_EA)
idc.get_inf_attr(INF_MAX_EA)在ida的反汇编窗口中,下面的每一个信息都可以用函数获取到
.text:00012529 mov esi, [esp+4+arg_0]Python> idc.get_segm_name(here())
'.text'
Python> idc.GetDisasm(here())
'call sub_405060'
Python>idc.print_insn_mnem(here())
'call'
Python>idc.print_operand(here(),0)
'sub_405060'
Python>idc.print_operand(here(),1)
''段操作
打印一行数据好像并没什么卵用,但是 IDAPython 的强大之处在于它能遍历所有的指 令,所有的交叉引用地址,还有搜索所有的代码和数据。后面两项功能稍后再做介绍。我们 先从遍历所有段的指令开始讲起。
import idc
import idautils
import idaapi
for seg in idautils.Segments():
print(idc.get_segm_name(seg),idc.get_segm_start(seg),idc.get_segm_end(seg))函数
遍历所有函数:
for func in idautils.Functions():
print(func,idc.get_func_name(func))Functions()将返回一个保存着已知函数首地址的数组,同样此函数也可以用来查找在指定地址范围的函数列表。
get_func_name(ea)用来获取函数名,ea这个参数可以是处于函数中的任何地址。
idaapi.get_func_qty() 获取此binary中识别的函数的个数。
idaapi.getn_func(1)获取第1个函数的对象。
获取函数的边界信息:
Python>idaapi.get_func(here())
<ida_funcs.func_t; proxy of <Swig Object of type 'func_t *' at 0x000001711FC33C00> >
Python>idaapi.get_func(here()).start_ea
0x40573c
Python>idaapi.get_func(here()).end_ea
0x405918同时也可以使用 idc.get_next_func(ea)和get_prev_func(ea)获取ea地址的后一个函数和前一个函数。ea 的值需要在被分析的函数地址之内。在枚举函数的时候,只有 IDA 将这段代码标记为函数的时候才行,不然会在枚举的过程中被跳过。没有被标记为函数的代码将在图例(ida 顶部的彩色条)中标为红色。当然我们可以手工的修复这些无法被标记为函数的代码。
还可以使用如下两个api来获取函数的边界地址:
Python>idc.get_func_attr(here(), FUNCATTR_START)
0x404c90
Python>idc.get_func_attr(here(), FUNCATTR_END)
0x405055get_func_attr的第二个参数有如下值:
FUNCATTR_START = 0 # function start address
FUNCATTR_END = 4 # function end address
FUNCATTR_FLAGS = 8 # function flags
FUNCATTR_FRAME = 10 # function frame id
FUNCATTR_FRSIZE = 14 # size of local variables
FUNCATTR_FRREGS = 18 # size of saved registers area
FUNCATTR_ARGSIZE = 20 # number of bytes purged from the stack
FUNCATTR_FPD = 24 # frame pointer delta
FUNCATTR_COLOR = 28 # function color code
FUNCATTR_OWNER = 10 # chunk owner (valid only for tail chunks)
FUNCATTR_REFQTY = 14 # number of chunk parents (valid only for tail chunks)idc.get_name_ea_simple("runtime_concatstring3") 利用函数名获取一个函数的地址。
下面遍历函数的所有指令:
import idc
import idautils
import idaapi
start = idc.get_func_attr(here(),FUNCATTR_START)
end = idc.get_func_attr(here(), FUNCATTR_END)
curr_addr = start
while curr_addr <= end:
print(hex(curr_addr),idc.GetDisasm(curr_addr))
curr_addr = idc.next_head(curr_addr,end)idc.next_head(curr_addr,end)返回处于curr_addr和end之间的下一条指令的地址,如果没有指令则返回 idc.BADADDR。这种方法的一个缺陷是它依赖于指令被包含在函数开始和结束的边界内。打个比方说,函数内有个 jmp 指令,它跳转到比这个函数结束地址还要高的地址中去,意思是这个函数的所有指令可能并不是线性的,它可能会通过jmp 跳出函数边界(起始地址和结束地址),但其实这段指令仍是属于这个函数的,那么我们使用上述的方法就不能够遍历到该函数要执行的所有指令。这种跳转在代码混淆中非常的常见,所以说我们最好还是使用 idautils.FuncItems(ea)来循环函数内的指令。
idc.prev_head(ea)获取ea地址的上一条指令的地址。
关于函数的详细信息有如下几个函数:
def GetFrame(ea): return get_func_attr(ea, FUNCATTR_FRAME)
def GetFrameLvarSize(ea): return get_func_attr(ea, FUNCATTR_FRSIZE)
def GetFrameRegsSize(ea): return get_func_attr(ea, FUNCATTR_FRREGS)
def GetFrameArgsSize(ea): return get_func_attr(ea, FUNCATTR_ARGSIZE)
def GetFunctionFlags(ea): return get_func_attr(ea, FUNCATTR_FLAGS)例如用如下代码获取函数的标志:
#coding:utf-8
import idc
import idautils
import idaapi
for func in idautils.Functions():
flags = idc.get_func_attr(func, FUNCATTR_FLAGS)
if flags & FUNC_NORET:
print(hex(func), "FUNC_NORET")
if flags & FUNC_FAR:
print(hex(func), "FUNC_FAR")
if flags & FUNC_LIB:
print(hex(func), "FUNC_LIB")
if flags & FUNC_STATIC:
print(hex(func), "FUNC_STATIC")
if flags & FUNC_FRAME:
print(hex(func), "FUNC_FRAME")
if flags & FUNC_USERFAR:
print(hex(func), "FUNC_USERFAR")
if flags & FUNC_HIDDEN:
print(hex(func), "FUNC_HIDDEN")
if flags & FUNC_THUNK:
print(hex(func), "FUNC_THUNK")
if flags & FUNC_LIB:
print(hex(func), "FUNC_BOTTOMBP")各种标志的含义如下:
FUNC_NORET: 这个标志表示某个函数是否有返回值,它本身的值是 1,下面是一个没有返回值的函数,
注意它没有函数的最后并不是 ret 或者 leave 指令
FUNC_FAR: 这个标志非常少的出现,标志程序是否使用分段内存,它的值为 2。
FUNC_USERFAR: 这个标志也非常少见,也很少有文档,HexRays 把它描述为“user has specified far-ness
of the function”,它的值是 32.
FUNC_LIB: 这个表示用于寻找库函数的代码。识别库函数代码是非常有必要的,因为我们在分析的
时候一般将其跳过,它的值是 4。下面的例子展示了如何使用这个标志。
for func in idautils.Functions():
flags = idc.get_func_attr(func, FUNCATTR_FLAGS)
if flags & FUNC_LIB:
print(hex(func), "FUNC_LIB",get_func_name(func))
FUNC_STATIC: 这个标志作用在于识别该函数在编译的是否是一个静态函数。在 c 语言中静态函数被默
认为是全局的。如果作者把这个函数定义为静态函数,那么这个函数在只能被本文件中的函
数访问。利用静态函数的判定我们可以更好的理解源代码的结构。
FUNC_FRAME: 这个标志表示函数是否使用了 ebp 寄存器(帧指针),使用 ebp 寄存器的函数通常有如
下的语法设定,目的是为了保存栈帧。
.text:00404C90 push ebp
.text:00404C91 mov ebp, esp
.text:00404C96 sub esp, 65Ch
FUNC_BOTTOMBP: 和 FUNC_FRAME 一样,该标志用于跟踪帧指针(ebp)。它作用是识别函数中帧指针是
否等于堆栈指针(esp)。
FUNC_HIDDEN: 带有 FUNC_HIDDEN 标志的函数意味着它们是隐藏的,这个函数需要展开才能查看。如
果我们跳转到一个标记为 HIDDEN 的地址的话,它会自动的展开。
FUNC_THUNK: 表示这个函数是否是一个 thunk 函数,thunk 函数表示的是一个简单的跳转函数。
.text:1A710606 Process32Next proc near
.text:1A710606 jmp ds:__imp_Process32Next
.text:1A710606 Process32Next endp
需要注意的是一个函数可能拥有多个标志的组合。指令
如果我们拥有一个函数中的指令地址,我们可以使用 idautils.FuncItems(ea)来获取该函数中所有指令地址的集合。
#coding:utf-8
import idc
import idautils
import idaapi
items = idautils.FuncItems(here())
for item in items:
print(hex(item),idc.GetDisasm(item))idautils.FuncItems(ea)会获取ea这个地址所在函数的所有指令的地址,返回一个迭代器。
现在我们已经完全掌握了如何循环遍历程序中的段,函数和指令,那我们就开始 show 一个非常有用的例子。有时候我们会逆向一个加壳的代码,这时知道代码中哪里进行了动态调用对分析是非常有帮助的。一个动态 的调用可能是由 call 或者 jump 加上一个操作数来实现的,比如说 call eax,或者 jmp edi。
#coding:utf-8
import idc
import idautils
import idaapi
for func in idautils.Functions():
flags = idc.get_func_attr(func, FUNCATTR_FLAGS)
if flags & FUNC_LIB or flags & FUNC_THUNK:
continue
dism_addr = idautils.FuncItems(func)
for line in dism_addr:
m = idc.print_insn_mnem(line)
if m == "call" or m == "jmp":
op = idc.get_operand_type(line,0)
if op == o_reg:
print(hex(line),idc.GetDisasm(line))get_operand_type(ea,n)获取操作数类型,n=0表示第一个操作数,n=1表示第二个操作数。
关于类型的定义请看下一节。
获取当前指令的下一个指令的地址和上一个指令的地址,idc.next_head和idc.prev_head,这两个函数的功能获取的是下一条指令的地址而不是下一个地址,如果要获取下一个地址或者上一个的话,我们使用的是
idc.next_addr和idc.prev_addr。
操作数
操作数在逆向分析中经常被使用,所以说了解所有的操作数类型对逆向分析是非常有帮助的。在前面文中提到我们可以使用 idc.get_operand_type(ea,n)来获取操作数类型,ea 是一个地址,n 是一个索引。操作数总共有八种不同的类型。
o_void: 如果指令没有任何操作数,它将返回 0。
o_reg: 如果操作数是寄存器,则返回这种类型,它的值为 1
o_mem: 如果操作数是直接寻址的内存,那么返回这种类型,它的值是 2,这种类型对寻找 DATA
的引用非常有帮助。
Python>print hex(ea), idc.GetDisasm(ea)
0xa05d86 cmp ds:dword_A152B8, 0
Python>print idc.GetOpType(ea,0)
2
o_phrase: 如果操作数是利用基址寄存器和变址寄存器的寻址操作的话,那么返回该类型,值为3
Python>print hex(ea), idc.GetDisasm(ea)
0x1000b8c2 mov [edi+ecx], eax
Python>print idc.GetOpType(ea,0)
3
o_displ: 如果操作数是利用寄存器和位移的寻址操作的话,返回该类型,值为 4,位移指的是像如下代码中的 0x18,这在获取结构体中的某个数据是非常常见的。
Python>print hex(ea), idc.GetDisasm(ea)
0xa05dc1 mov eax, [edi+18h]
Python>print idc.GetOpType(ea,1)
4
o_imm: 如果操作数是一个确定的数值的话,那么返回类型,值为 5
-------------------------------------------
Python>print hex(ea), idc.GetDisasm(ea)
0xa05da1 add esp, 0Ch
Python>print idc.get_operand_type(ea,1)
5
-------------------------------------------
o_far: 这种返回类型在 x86 和 x86_64 的逆向中不常见。它用来判断直接访问远端地址的操作数,值为6
o_near: 这种返回类型在 x86 和 x86_64 的逆向中不常见。它用来判断直接访问近端地址的操作数,值为 7例子1
当我们在逆向一个可执行文件的时候,我们可能会注意到一些代码会不断的重复使用某 个偏移量。这种操作感觉上是代码在传递某个结构体给不同的函数使用。接下来的这个例子 的目的是创建一个 python 的字典,字典包含了可执行文件中使用的所有偏移量,让偏移量 作为字典的 key,而每个 key 对应的 value 存储着所有使用该偏移量的地址。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
displace = defaultdict(list)
for func in idautils.Functions():
flags = idc.get_func_attr(func, FUNCATTR_FLAGS)
if flags & FUNC_LIB or flags & FUNC_THUNK:
continue
dism_addr = idautils.FuncItems(func)
for line in dism_addr:
op = None
index = None
# 定义结果结构来解析当前的指令
tmp = idaapi.insn_t()
idaapi.decode_insn(tmp,line)
if tmp.Op1.type == idaapi.o_displ:
op = 1
if tmp.Op2.type == idaapi.o_displ:
op = 2
if op == None:
continue
if "bp" in idc.print_operand(line,0) or "bp" in idc.print_operand(line,1):
if op == 1:
index = (~(int(tmp.Op1.addr) - 1) & 0xFFFFFFFF)
else:
index = (~(int(tmp.Op2.addr) - 1) & 0xFFFFFFFF)
else:
if op ==1 :
index = int(tmp.Op1.addr)
else:
index = int(tmp.Op2.addr)
if index:
displace[index].append( hex(line) )
print(displace)idaapi.decode_insn(tmp,line)是解析指令的另一种底层的方法,但是 表示偏移的意思。详细可以看这个文档。
我们已经获取了操作符的字符串表示,那么我们检查操作符中是否包含了“bp”字符串,这是一个快速判断操作符的中寄存器是否为 bp,ebp 或者 rbp 的方法。检查”bp”字符串的目的在于确定偏移量是否是一个负数。我们使用idaapi.cmd.Op1.addr 来获取偏移量,这个方法会返回一个字符串。然后我们把他转换成为一个 integer 类型,如果需要的话把它转换为正数,然后我们把它放进脚本最开始定义的字典 display 中去。这样就完成了我们的操作,之后如果你想要查找使用某个偏移量的所有地址,直接读取就可以了。
例子2
有时候我们在逆向分析一个可执行文件的内存转储的时候,有些操作数就不是一个偏移量了。看如下代码:
push 0Ch
push 0BC10B8h
push [esp+10h+arg_0]
call ds:_strnicmp第二个被 push 的值是一个存在内存中的偏移。如果我们通过右键把这个偏移定义为data 类型,我们可以看到这个偏移其实是一个字符串,当然完成这个定义操作很简单,但是,有时候这种操作太多了话就需要写一个脚本来自动完成这件事情。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
min = idc.get_inf_attr(INF_MIN_EA)
max = idc.get_inf_attr(INF_MAX_EA)
# for each known function
for func in idautils.Functions():
flags = idc.get_func_attr(func, FUNCATTR_FLAGS)
# skip library & thunk functions
if flags & FUNC_LIB or flags & FUNC_THUNK:
continue
dism_addr = list(idautils.FuncItems(func))
for curr_addr in dism_addr:
if idc.get_operand_type(curr_addr, 0) == 5 and \
(min < idc.get_operand_value(curr_addr,0) < max):
idc.op_plain_offset(curr_addr, 0, 0)
# print(hex(curr_addr))
if idc.get_operand_type(curr_addr, 1) == 5 and (min < idc.get_operand_value(curr_addr,1) < max):
idc.op_plain_offset(curr_addr, 1, 0)
# print( hex(curr_addr) )idc.get_operand_value(ea,n)获取操作数的值。
idc.op_plain_offset(ea,n,base),将操作数转换为一个偏移地址,该函数的第一个参数为地址,第二个参数为操作数的索引,第三个参数是基地址,该例子中只需要设置为0即可。
交叉引用(Xrefs)
能够定位data段和code段的交叉引用非常重要,交叉引用的重要性在于它能够提供某个确定的数据或者某个函数被调用的位置。举个栗子,如果我们想要知道哪些地址调用了 WriteFile()函数,我们所要做的就是在导入表中找到 WriteFile()函数,然后查看其交叉引用即可。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
addr = idc.get_name_ea_simple("StartServiceCtrlDispatcherW")
print( idc.GetDisasm(addr) )
for i in idautils.CodeRefsTo(addr,0):
print( hex(i),idc.GetDisasm(i) )idc.get_name_ea_simple("StartServiceCtrlDispatcherW")来获取API函数的地址,然后使用idautils.CodeRefsTo(ea,flow)来获取该API的所有交叉引用,在函数中,ea 参数是我们想要寻找交叉引用的地址,flow 参数是一个 bool 值,它用于指定是否遵循正常的代码流。
也可以调用 idautils.Names()函数来获取在 IDA 中任何 API 和被重命名的函数的相关信息,该函数将返回一个类型为(ea, str_name)的元组。
我们同样可以利用 idautisl.CodeRefsFrom(ea,flow)该函数来获取任意地址所引用的代码,下面的例子展示获取某地址的引用信息。
Python>addr = here()
Python>idautils.CodeRefsFrom(addr,0)
Python>for i in idautils.CodeRefsFrom(addr,0):print(hex(i),idc.GetDisasm(i))
0x40a008 extrn StartServiceCtrlDispatcherW:dword但有一点要注意:使用 idautils.CodeRefsTo(ea,flow)的限制是,动态导入并手动重命名的 API 不会 显示为代码交叉引用。比如下面我们利用 idc.MakeName(ea, name)将一个 dword 的地址重 命名为”RtlCompareMemory”。
>hex(ea)
0xa26c78
>set_name(ea, "RtlCompareMemory", SN_CHECK)
True
>for addr in idautils.CodeRefsTo(ea,0):print(hex(addr),idc.GetDisasm(addr))IDA 并不会将这些 API 标记为交叉引用代码。稍后我们将会使用一个通用的技术来获得所有的交叉引用。
如果我们想要查找数据的交叉引用或者调用,我们使用 idautils.DataRefsTo(e) 或者 idautils.DataRefsFrom(ea)。
idautils.DataRefsTo(ea)函数只有一个地址参数,它返回该数据地址的所有交叉引用(迭代器)。
idautils.DataRefsFrom(ea)只携带一个地址作为参数,它返回改、该地址所引用的数据地址。
在查找数据和代码的交叉引用的时候可能会有一些困惑,这里我们使用前面所提到的有一种更加通用的方法来获取交叉引用,该方法调用两个函数就能完成获取所有交叉引用地址和调用地址的效果,这两个函数就是 idautils.XrefsTo(ea, flags=0)和 idautils.XrefsFrom(ea,flags=0)。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
addr = here()
print(hex(addr),idc.GetDisasm(addr))
for xref in idautils.XrefsTo(addr,1):
print(xref.type,idautils.XrefTypeName(xref.type),hex(xref.frm),hex(xref.to),xref.iscode)idautils.XrefsTo(ea,flags=0)ida_xref.XREF_ALL=0 (default), ida_xref.XREF_FAR=1, ida_xref.XREF_DATA=2
xref.type来指明该交叉引用的类型,idautils.XrefTypeName(xref.t ype)用来打印表示该类型的含义,这其中有十二种不同的类型。
0= 'Unknown'
1= 'Offset'
2= 'Write'
3= 'Read'
4= 'Text'
5 = 'Data_Informational'
16= 'Far_Call'
17= 'Near_Call'
18= 'Far_Jump'
19= 'Near_Jump'
20= 'Code_User'
21 = 'Ordinary_Flow'xref.frm 打印出该地址的交叉引用,xref.to 打印出改地址本身,xref.iscode 打印出该交叉引用是否在代码段中,上述的代码我们使用了 idautils.XrefsTo(ea, 1)并将其 flag 位设为了1,如果我们将 flag 设为 0 的话,那么它将会显示该地址的任意交叉引用。设置flag为0获取的交叉引用不只是来自于分支跳转指令,同时还会来自正常的指令流程,设置flag为1可以略过正常指令流程造成的交叉引用。
搜索
我们其实已经能够通过遍历所有已知的函数及其指令来达到一种基本的搜索效果,这当然很有用,但是有时候我们需要搜索一些特定的字节,比如说 0x55,0x8b,0xec 这种字节序列,这 3 个字节其实代表的汇编代码为 push ebp, mov ebp, esp。所以我们可以使用idc.find_binary(ea,flag,searchstr,radix=16)来实行字节或者二进制的搜索。ea代表啥就不说了,flag代表搜索方向或者条件。flag有好几种不同的类型:
SEARCH_UP = 0
SEARCH_DOWN = 1
SEARCH_NEXT = 2
SEARCH_CASE = 4
SEARCH_REGEX = 8
SEARCH_NOBRK = 16
SEARCH_NOSHOW = 32
SEARCH_IDENT = 128
SEARCH_BRK = 256上面的类型不必要都看一遍,但是还是要看看一些常用的类型:
- SEARCH_UP 和 SEARCH_DOWN 用来指明搜索的方向
- SEARCH_NEXT 用来获取下一个已经找到的对象
- SEARCH_CASE 用来指明是否区分大小写
- SEARCH_NOSHOW 用来指明是否显示搜索的进度
searchstr 是我们要查找的形态,radix 参数在写处理器模块时使用,这超出本书要讲解的范围,所以我推荐你去看一看 Chris Eagle 的“The IDA Pro Book”的第 19 章,所以这里我们把 radix 参数留空。现在让我们来实现刚才提到的那三个字节的搜索好了:
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
pattern = "55 8B EC"
addr = idc.get_inf_attr(INF_MIN_EA)
for x in range(0,5):
addr = idc.find_binary(addr,SEARCH_DOWN,pattern)
if addr!= idc.BADADDR:
print(hex(addr),idc.GetDisasm(addr))第一行我们定义了要搜索的形式,搜索形式可以是 16 进制格式,比如 0x55 0x8B 0xEC和 55 8B EC 都是可以的,\x55\x8B\xEC 这种格式可不行,除非你使用 idc.find_text(ea, flag,y, x, searchstr)这个函数。
但是我们搜索的时候,地址并没有增长,那是因为我们写程序的时候没有增加SEARCH_NEXT这个标记。正确的写法如下:
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
pattern = "55 8B EC"
addr = idc.get_inf_attr(INF_MIN_EA)
for x in range(0,5):
addr = idc.find_binary(addr,SEARCH_DOWN|SEARCH_NEXT,pattern)
if addr!= idc.BADADDR:
print(hex(addr),idc.GetDisasm(addr))搜索字符串使用函数idc.find_text(ea, flag, y, x, searchstr, from_bc695=False)ea参数是地址,flag参数是搜索方向和搜索类型。y是从ea开始搜索的行数,x 是行中的坐标。这两个参数通常置 0,现在我们开始查找字符串“Accept”的出现的次数。当然你可以换换其他的字符串,可以从字符串窗口(shift+F12)获得。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
addr = idc.get_inf_attr(INF_MIN_EA)
end = idc.get_inf_attr(INF_MAX_EA)
while addr < end:
addr = idc.find_text(addr,SEARCH_DOWN,0,0,"accept")
if addr == idc.BADADDR:
break
else:
print(hex(addr),idc.GetDisasm(addr))
addr = idc.next_head(addr)因为我们利用了 idc.NextHead(ea)使当前地址不断增长,所以就不需要在 idc. FindText()中添加 SEARCH_NEXT 的标志。为什么我们要手动的增加地址呢,因为一行字符串中可能出现多次要查找的字符串,往上翻认真阅读 SEARCH_NEXT的标志的意思。
IDApython用如下函数来判断一个地址的类型,这些api返回bool值,true或者false
idc.is_code(f) # 判断是否是代码
idc.is_data(f) # 判断是否是数据
idc.is_tail(f) # 判断 IDA 是否将其判定为尾部。
idc.is_unknown(f) # 判断 IDA 是否将其判定为未知,即既不是数据,也不是代码。
idc.is_head(f) # 判断 IDA 是否将其判定为头部。f 这个参数是新出现的,相比起于传递地址,我们还要先通过 idc.get_full_flags(ea)获取地址的内部标志表示,然后再传给 idc.is 系列函数当参数,代码如下:
Python>idc.get_full_flags(here())
0x4001078d
Python>idc.is_code( idc.get_full_flags(here()))
Trueidc.find_code(ea,flag)该函数用来寻找被标志为代码的下一个地址。这对我们想要查找数据块的末尾是很有帮助的。如果 ea 是代码地址,那么该函数返回下一个代码地址,flag 参数看前面的 idc.find_text就可以了。
Python>addr = idc.find_code(addr,SEARCH_DOWN|SEARCH_NEXT)
Python>print(hex(addr),idc.GetDisasm(addr))
0x404d70 lea ecx, [esp+668h+phkResult]这个函数会跳过一些数据段的地址,得到最近的一个代码端的首地址。
idc.find_data(ea,flag)和上面的find_code函数差不多,不过它返回的是数据段的地址。
idc.find_unknown(ea,flag)该功能用于查找 IDA 未识别为代码或数据的字节地址。未知类型需要通过观察或脚本进一步手动分析。
idc.find_defined(ea, flag)它用于查找 IDA 标识为代码或数据的地址。
idc.find_imm(ea, flag, value)用来寻找立即数。例如:相比于寻找一些类型,我们有些时候其实更希望能够找到特定的值,举个栗子,你感觉代码里面肯定是用了 rand()函数来产生随机数的,但是你就是找不到它,咋办?如果我们知道这个 rand()函数采用了 0x343fd 作为种子那么我们就可以去寻找这个数值:
idc.imm函数返回一个元组,元组的第一项为地址,第二项为标识是第几个操作数。这里操作数的算法和 idc.print_operand一样,也是从 0 开始的。循环使用搜索需要添加SEARCH_ DOWN|SEARCH_NEXT 标志。
数据提取
ida可以获取到用户使用鼠标选中高亮的部分的代码,可以使用如下两个函数获取到选中部分的起始地址。
Python>idc.read_selection_start()
0x404cdb
Python>idc.read_selection_end()
0x404d70注意idc.read_selection_end()获取的的并不是这一段代码的末尾地址,选中部分的最后一条指令的下一条指令的起始地址。
函数idaapi.read_selection()也可以实现上面的效果:
p0 = idaapi.twinpos_t()
p1 = idaapi.twinpos_t()
view = idaapi.get_current_viewer()
idaapi.read_selection(view, p0, p1)注释和重命名
注释一共有两种,第一种是常规注释,第二种是重复性注释。重复性注释会因为某些地址引用了当前地址的内容,而会自动添加上注释。
使用注释idc.set_cmt(ea, cmt, 0)来增加注释,使用idc.set_cmt(ea, cmt, 1)来增加重复性地址。
ea是要添加注释的地址,cmt是要添加的注释。
idc.get_cmt(ea, 0)获取常规注释,idc.get_cmt(ea, 1)获取重复性注释。
当然不止指令可以添加注释,函数也可以添加注释,利用idc.set_func_cmt(ea, cmt, repeatable)来添加注释,利用idc.get_func_cmt(ea, repeatable)来获取函数的注释。ea可以是函数中的任何地址,cmt就是我们需要添加的注释,repeatable 同上面一样。将函数的注释标记为可重复性的话,那么它会在任何调用该函数的地方增加注释。
重命名函数和地址是一项非常常见的自动化任务,特别是在一些地址无关的代码(PIC),加壳或者封装函数中,因为在 PIC 代码和脱壳代码中,导入表可能并不存在于转储中。而封装函数的功能只是简单的调用 API 而已。
idc.set_name(ea, name, SN_CHECK)用来重命名某个地址的函数。
值得注意的是 rename_wrapper 中的 idc.MakeNameEx(ea,name, flag)用法,因为使用 idc.MakeName 的话,如果某一个函数名称已经被使用了,那么ida 会抛出一个警告的对话。为了跳过该对话框,我们将 flag 的值设置为 256 或者SN_NOWARN 即可。我们可以应用一些逻辑来将函数重命名为 w_HeapFree_1 等,但为简洁起见,我们会将其忽略。
访问原始数据
在逆向工程中获取原始数据是非常重要的,原始数据是16进制的字节,它们被解释为数据或代码,ida中我们可以在反汇编代码窗口的左侧看到这些原始数据。(IDA中显示的设置方法: 菜单栏–>选项–>常规–>反汇编–>机器码字节数,填入一个数就ok了–>确定 )
要获取原始数据的话我们首先要指定获取的单元大小,这些获取原始数据 API 的命名规则就是以单元大小。
idc.get_wide_byte(ea) // 获取单字节
idc.get_wide_word(ea) // 获取一个字
idc.get_wide_dword(ea) // 获取双字
idc.get_qword(ea) // 获取四字
idc.GetFloat(ea)
idc.GetDouble(ea)在编写解码脚本是获取单个字节或者单个字并没有太多卵用,所以我们可以使用 idc.get_bytes(ea, size, use_dbg = False)来获取某个地址开始的更多的字节。最后一个参 数是可选的,用来指定是否正在调试内存。
idc.get_bytes返回的是bytes类型,跟idc.get_wide_byte(ea)返回的整型有区别。
补丁
有时候我们在逆向一个恶意软件的时候,样本会有被加密的字符串。这会阻碍我们分析的过程和组织我们通过字符串来定位关键点。这种情况下给 idb 文件打补丁就很有用了。重命名地址但是好像并没有卵用,因为命名是有约束限制的,所以我们需要给某些地址做patch了,我们可以使用如下的函数来 patch:
patch_byte(ea, value)
patch_word(ea, value)
patch_dword(ea, value)
patch_qword(ea, value)ea 是地址,value 是值,注意值要和你选择的函数相对应即可。
输入和输出
在 IDAPython 中当我们并不知道文件的位置或者并不知道用户想要把他们的数据存储在什么地方,输入输出文件就很重要了。导入导出文件我们可以使用 ida_kernwin.ask_file(for_saving, mask, prompt)这个函数,当 forsave 参数为 0,打开一个文件对话框,当 forsave 的参数为 1,打开一个文件保存对话框,mask 用来指定文件后缀或者模式,比如我只想打开.dll 文件的话就可已使用“*.dll”作为 mask 的参数,prompt 是窗口的名称。
批生成文件
有时,为目录中的所有文件创建 IDB 或 ASM 可能很有用。 在分析属于同一系列恶意软件的一组样本时,这可以帮助节省时间。比起手工做这件事情,写一个批处理文件会容易许多,我们只需要将-B 该参数传给 idaw.exe 即可,下面的代码可以被复制到包含我们想为其生成文件的所有文件的目录中。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
import os
import subprocess
import glob
paths = glob.glob("*")
ida_path = os.path.join(os.environ['PROGRAMFILES'], "IDA","idaw.exe")
for file_path in paths:
if file_path.endswith(".py"):
continue
subprocess.call([ida_path, "-B", file_path])脚本运行完成后,会在当前目录下生成ASM文件和IDB文件。
可执行脚本
ipapython脚本可以在命令行中执行,我们也可以使用下面计算 IDB 拥有指令个数的脚 本,然后将其个数写进一个叫做“instru_count.txt”文件中。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
idaapi.auto_wait()
count = 0
for func in idautils.Functions():
flags = idc.get_func_attr(func, FUNCATTR_FLAGS)
if flags & idc.FUNC_LIB:
continue
for instru in idautils.FuncItems(func):
count += 1
f = open("instru_count.t",'w')
writeContent = "Instruction count is {}".format(count)
print(writeContent)
f.write(writeContent)
f.close()
idc.qexit(0)上面两个十分重要的函数,一个是idaapi.auto_wait(),一个是idc.qexit(0),当ida打开一个文件的时候,等待IDA分析完成是很重要的,因为 IDA 分析一个文件需要花大量的时间。这时候你不能执行 IDAPython 脚本,所以你可使用idaapi.auto_wait()来等待IDA文件分析结束,它会在 IDA 分析完成之前一直等待,一旦分析完成,控制权就会交到脚本身上。然后我们同样需要使用 idc.qexit(0)来结束脚本的执行,如果不这么做的话,IDB 可以会在关闭的时候出问题。
如果我们想要计算IDB包含的多少行的话,我们可以使用以下的指令完成。
idat.exe -A -S"test.py" .\Trojan.Win32.AntiAV.aaa.json.idb-A表示自动化分析,-S表示idb被打开之后立即执行的脚本。
同时自动化脚本也是支持参数的:
idat.exe -A -S"test.py test" .\Trojan.Win32.AntiAV.aaa.json.idb就能够向脚本中传参数test,可以使用idc.ARGV获取。
流程图
使用ida python生成CFG图。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
def cls_main(p=True):
f = idaapi.FlowChart(idaapi.get_func(here()))
for block in f:
if p:
print("%x - %x [%d]:" % (block.start_ea, block.end_ea, block.id))
for succ_block in block.succs(): # 获取后继节点
if p:
print(" succs: %x - %x [%d]:" % (succ_block.start_ea, succ_block.end_ea, succ_block.id))
for pred_block in block.preds(): # 获取前驱节点
if p:
print(" preds:%x - %x [%d]:" % (pred_block.start_ea, pred_block.end_ea, pred_block.id))
cls_main()函数栈帧的访问
在x86程序中,EBP寄存器通常专门用做栈帧指针,例外 gun/g++提供 -fomit-frame-pointer编译选项,可以生成不依赖于固定帧指针寄存器的函数。
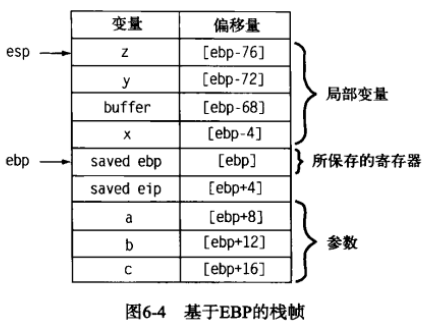
基于ebp做栈帧指针的函数,正偏移是函数参数,负偏移是则用于访问函数的局部变量。
很明显函数的栈帧是一个运行时的概念,没有栈和运行时的程序,栈帧就不可能存在。话虽如此,但是并不意味者ida在做静态的分析的时候就会忽略掉栈帧的概念。二进制文件中包含配置每个函数栈帧所需的所有代码,通过仔细分析这些代码,我们就可以深入了解任何函数的栈帧结构,即使这个函数并未运行。在IDA中也会有一些复杂的分析来确定IDA反汇编的每个函数的栈帧布局。在分析的过程中,IDA会记住每一次push/pop操作,以及其他的任何可能改变栈指针的运算,如增加或者减去常量,尽可能的去观察栈指针在函数执行时的行为。
IDA提供一个摘要视图,列出了栈帧内被直接引用的每一个变量,以及变量的大小和与它们与帧指针的偏移距离。
404C90 ; int __stdcall WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nShowCmd)
.text:00404C90 _WinMain@16 proc near ; CODE XREF: start+186↓p
.text:00404C90
.text:00404C90 phkResult = dword ptr -658h
.text:00404C90 Data = byte ptr -654h
.text:00404C90 var_650 = WNDCLASSEXW ptr -650h
.text:00404C90 String1 = word ptr -620h
.text:00404C90 var_61E = byte ptr -61Eh
.text:00404C90 anonymous_0 = byte ptr -41Ah
.text:00404C90 var_418 = word ptr -418h
.text:00404C90 var_416 = byte ptr -416h
.text:00404C90 anonymous_1 = byte ptr -212h
.text:00404C90 String2 = word ptr -210h
.text:00404C90 var_20E = byte ptr -20Eh
.text:00404C90 anonymous_2 = byte ptr -0Ah
.text:00404C90 StackCookie = dword ptr -4
.text:00404C90 hInstance = dword ptr 8
.text:00404C90 hPrevInstance = dword ptr 0Ch
.text:00404C90 lpCmdLine = dword ptr 10h
.text:00404C90 nShowCmd = dword ptr 14h但是需要注意的是 arg_0 对应的偏移是 ebp+0x4,arg_4对应的偏移是ebp+0x8。
idapython也提供获取此函数栈帧的api,获取到之后是一个结构体,操作结构体成员就可以获取到函数栈帧内的所有变量。相关的函数说明如下:
- idaapi.get_func(ea): retrieves the
func_tstructure for the function atea idaapi.get_frame(func_t foo): returns thestruct_tstructure for the function frame specified byfooidautils.DecodeInstruction(ea): returns theinst_trepresenting instruction atea,和函数idaapi.decode_insn功能相同。- idaapi.get_stkvar(op_t op, sval_t v):
opis a reference to an instruction,vis the immediate value in the operand. Usually you just useop.addr. It returns a tuple,(member_t, val).member_tis a pointer to the stack variable, which is what we need.valis the same value as thesofffield in themember_tfor the stack var. More on this later. - idaapi.xreflist_t()
: creates a newxreflistofxreflist_entry_t` - idaapi.build_stkvar_xrefs(xreflist_t xrefs, func_t func, member_t member): fills xrefs with
xreflist_entry_t‘s that represent the stack var xrefs given bymemberinfunc. struct_t.get_member(x): You can use this method to iterate all stack variables in a frame to retrieve allmember_t‘s. If you want to build xrefs for all stack variables, this is usually easier.idc.get_member_name(id, member_offset): id is the struct sid,member_offset. get the member name defined in the name.idc.get_member_offset(id,name): 获取偏移。
下面对iautils.DecodeInstruction(ea)指令进行一个简单的说明,这是一个指令解码的API,如果解码失败返回None,否则将返回一个包含该指令及其操作数的指令对象。
比较重要的指令属性如下:
inst.itype标志当前指令的类型,是一个整数,不同的opcode可能有相同的itype,但是opcode不是itype。inst.size: 表示解码后的指令长度inst.ops[]:以0为索引的数组,用来保存操作数的相关信息inst.Op1...inst.OpN: 以1位索引起始操作数组别名,和inst.ops[n+1]等价。inst.ea: 指令的线性地址。 你可能会想知道opcode和它的itype之间到底是什么关系。其实很简单,在IDA中,开源数据库处理器模块负责根据opcode来填充itype字段。在IDA SDK中,你可以找到一个allins.hpp的头文件。该头文件包含了所有支持的处理器模块的枚举数据其中包含了受支持的所有指令:
// Excerpt from allins.hpp
// x86/x64 itypes
enum
{
NN_null = 0, // Unknown Operation
NN_aaa, // ASCII Adjust after Addition
NN_aad, // ASCII Adjust AX before Division
NN_aam, // ASCII Adjust AX after Multiply
NN_aas, // ASCII Adjust AL after Subtraction
.
.
.
NN_jz, // Jump if Zero (ZF=1)
NN_jmp, // Jump
NN_jmpfi, // Indirect Far Jump
NN_jmpni, // Indirect Near Jump
NN_jmpshort, // Jump Short (not used)
NN_lahf, // Load Flags into AH Register
.
.
.
// Pentium III Pseudo instructions
NN_cmpeqps, // Packed Single-FP Compare EQ
NN_cmpltps, // Packed Single-FP Compare LT
NN_cmpleps, // Packed Single-FP Compare LE
NN_cmpunordps, // Packed Single-FP Compare UNORD
.
.
.
} 不知道为什么,反正NN_前缀用来表示x86/x64处理器上的指令。
# .text:00402085 74 09 jz short loc_402090
inst = idautils.DecodeInstruction(0x402085)
print("YES" if inst.itype == idaapi.NN_jz else "NO") 至于操作数,可以通过访问inst.Operands[]或者inst.OpN来访问。要获取被解码指令使用的操作数数量不应依赖Operands数组的长度,因为它总是被解析成UA_MAXOP==8(参阅ida.hpp)。因此应该使用遍历每个操作数并检查操作数的类型是否是o_void类型。
操作数的定义是ua.hpp中的op_t结构。
op.flags:操作数的标志op.dtype:操作数的长度类型。idaapi.dt_xxx常量,可以通过该常量来获取操作数的字节大小(1 == idaapi.dt_byte,2 == idaapi.dt_word等等)。op.type:操作数类型。idc.o_xxx常量。specflags1…specflags4:处理器相关标志。 以下是受支持的操作数类型(o_xxx):
o_void:没有该操作数。
o_reg:该操作数是寄存器(ax,al,es,ds等等)
o_mem:直接寻址(数据)
o_phrase:[基址+变址]寻址
o_displ:[基址+变址+偏移]寻址
o_imm:立即数
o_far:直接远地址(far address,代码)
o_near:直接近地址(near address,代码)
o_dispspec0...o_dispspec5:处理器相关标志。还有一些操作数成员的含义因操作数的类型而异:
op_reg:寄存器编号(o_reg)
op_phrase:内存访问中的索引寄存器(o_phrase)
op_value:立即数(o_imm)或偏移(o_displ)
op_addr: 操作数使用的内存地址(o_mem,o_far,o_displ,o_near) 当操作数的类型是o_reg或者o_phrase的时候,op_reg/op_phrase值包含了对应寄存器的枚举值。就像NN_xxx专有标签,IDA SDK同样提供了寄存器的名称常量,以及其对应的值;但是,这只适用于x86/x64处理器模块。我从intel.hpp中摘抄了一部分:
enum RegNo
{
R_ax = 0,
R_cx,
R_dx,
R_bx,
R_sp,
R_bp,
R_si,
R_di
}不幸的是,这些值并没有被IDAPython导出,但是至少我们知道了足够多的信息来定义下边的一些数据:
REG_EAX = 0
REG_EDX = 2
REG_EBP = 5
.
.
.
REG_NAMES = { REG_EAX: 'eax', REG_EDX: 'edx', REG_EBP: 'ebp' ...}可以利用如下代码获取某个函数栈帧的所有成员以及偏移。注意获取的frame不仅包括函数栈帧还包括返回地址以及形参。
#coding:utf-8
import idc
import idautils
import idaapi
from collections import defaultdict
addr = here()
func = idaapi.get_func(addr)
frame = idaapi.get_frame(func)
print(frame)
x = 0
dictMem = {}
while(x < frame.memqty):
name = idc.get_member_name(frame.id, frame.get_member(x).soff)
dictMem[name] = hex(idc.get_member_offset(frame.id,name))
x = x+1
print(dictMem)获得的结果如下:
{'phkResult': '0x10',
'Data': '0x14',
'var_650': '0x18',
'String1': '0x48',
'var_61E': '0x4a',
'anonymous_0': '0x24e',
'var_418': '0x250',
'var_416': '0x252',
'anonymous_1': '0x456',
'String2': '0x458',
'var_20E': '0x45a',
'anonymous_2': '0x65e',
'StackCookie': '0x664',
' s': '0x668',
' r': '0x66c',
'hInstance': '0x670',
'hPrevInstance': '0x674',
'lpCmdLine': '0x678',
'nShowCmd': '0x67c'
}注意此偏移都是相对于当前栈帧的栈底(也就是esp)来说的。注意两个非常重要的成员” r”和” s”,其中” r”代表返回地址存储的偏移,” s”代表当前函数栈帧中ebp距离esp的位置(也就是函数栈帧的大小)。注意有个空格
也可以利用此frame的结构来获取x86中当前函数参数的字节数。
ret_off = idc.get_member_offset(frame.id," r")
first_arg_off = ret_off + 4
args_size = idc.get_struc_size(frame.id) - first_arg_off
print(args_size)获取某个函数的某一条指令中引用的函数栈帧变量的名字以及在frame中的偏移,并获取其他地方引用此变量的地址。
# 0x00404C90 is the function address
# 0x00404CA4 is an instruction address referencing
# a stack variable. It looks like:
# .text:00404CA4 mov [esp+668h+StackCookie], eax
# .text:00404CBF mov ecx, [esp+668h+StackCookie] ; StackCookie
pFunc = idaapi.get_func(0x00404C90)
pFrame = idaapi.get_frame(pFunc)
inst = idautils.DecodeInstruction(0x00404CA4)
op = inst[0] #获取第一个操作数,注意此操作数必须有栈帧变量的引用,否则下条指令会报错
pMember, val = idaapi.get_stkvar(inst,op, op.addr) # pMember 是frame结构体中的成员,val是在frame中的偏移量
xrefs = idaapi.xreflist_t()
idaapi.build_stkvar_xrefs(xrefs, pFunc, pMember)
for xref in xrefs:
print(hex(xref.ea)) #print xref address也可以使用如下代码找具体的某个栈帧变量在函数中的引用。
pFunc = idaapi.get_func(0x00404C90)
pFrame = idaapi.get_frame(pFunc)
dictMem = dict()
x = 0
while(x < pFrame.memqty):
dictMem[idc.get_member_name(pFrame.id, pFrame.get_member(x).soff)] = pFrame.get_member(x)
x = x+1
# given var name you can now use the
# dictionary to grab the member_t to pass
# to build_stkvar_xrefs
pMem = dictMem["hInstance"]
xrefs = idaapi.xreflist_t()
idaapi.build_stkvar_xrefs(xrefs, pFunc, pMem)
for xref in xrefs:
print(hex(xref.ea)) #print xrefs to var_4程序入口点
idc.get_entry_qty() 获取入口点个数
idc.get_entry_ordinal(index) 获取入口点地址
idc.get_entry_name(ordinal) 入口名调试
安装调试的hook使用如下api:
debugger = idaapi.DBG_Hooks()
debugger.hook()现在运行调试器,hook 会捕捉所有的调试事件,这样就能非常精确的控制 IDA 调试器。 下面的函数在调试的时候非常有用:
idc.add_bpt( long Address ) # 在指定的地点设置软件断点。
idc.get_bpt_qty() #返回当前设置的断点数量。
idc.get_reg_value(string Register) # 获取寄存器的值 ,dbg必须处于运行状态
idc.set_reg_Value(long Value, string Register) # 通过寄存器名获得寄存器值。本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2020-12-112,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号