盘点一个pandas.merge的问题
盘点一个pandas.merge的问题

Python进阶者
发布于 2023-03-02 17:49:22
发布于 2023-03-02 17:49:22
一、前言
前几天在Python最强王者交流群【粉丝】问了一个pandas数据处理的问题,提问截图如下:
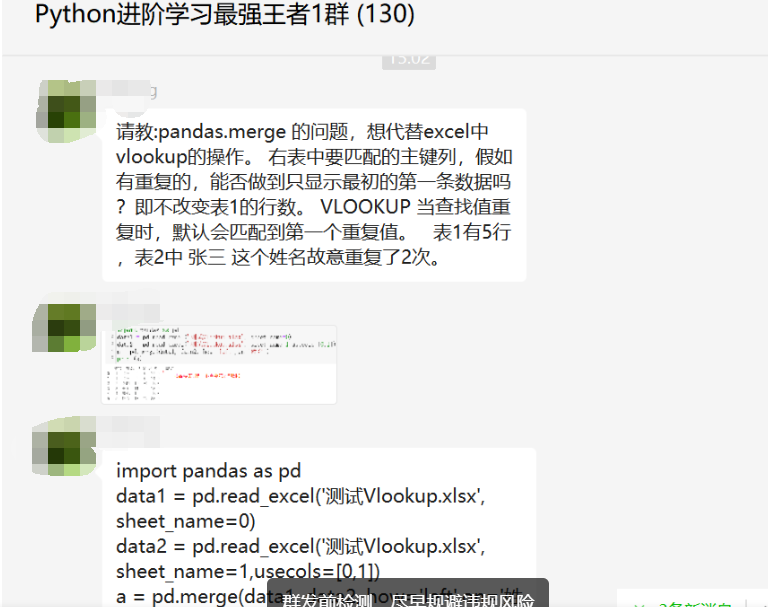
下图是他的代码:
import pandas as pd
data1 = pd.read_excel('测试Vlookup.xlsx', sheet_name=0)
data2 = pd.read_excel('测试Vlookup.xlsx', sheet_name=1,usecols=[0,1])
a = pd.merge(data1, data2, how='left',on='姓名')
print(a)
二、实现过程
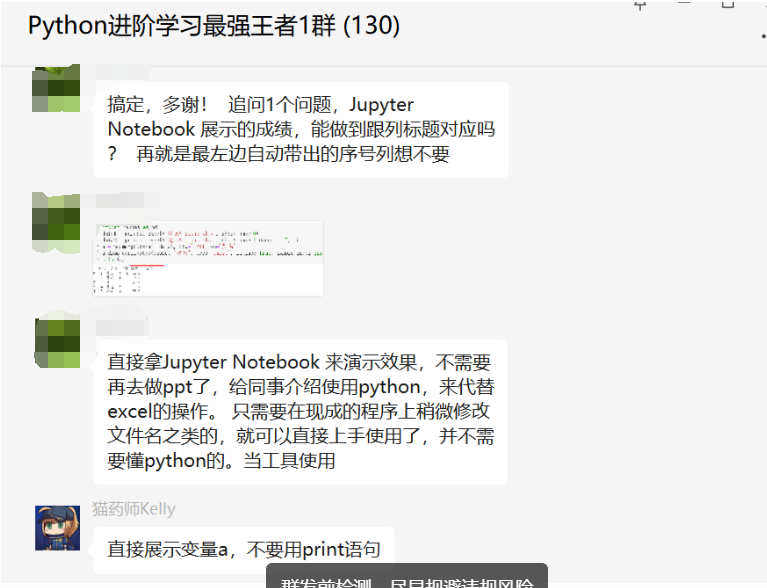
后来【猫药师Kelly】给了一个思路,先针对姓名列去重即可,后来【瑜亮老师】给了一个代码,如下所示:
a.drop_duplicates(subset="姓名", keep='first', inplace=True, ignore_index=True)
顺利地解决了粉丝的问题。后面追加的小问题,就不再赘述了。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝提问,感谢【猫药师Kelly】、【瑜亮老师】给出的思路和代码解析,感谢【皮皮】等人参与学习交流。
本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2022-12-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录