并发编程 之 Fork/Join 框架


- 1. 简介
- Fork/Join框架原理
- 2. 示例
- 3. API
- 4. 原理分析
- 工作队列(双端队列)
- 工作窃取(队尾取未执行任务)
- 5. 应用场景实战模拟
- 信息模型定义
- 定义数据加载处理器抽象行为
- 定义数据加载模板方法
- 定义商品数据加载器分层
- 定义子任务
- 运行结果
- 6. 小结
1. 简介
Fork/Join框架原理
ForkJoin框架是从jdk1.7中引入的新特性,它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入指定的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要使用 分治法(Divide-and-Conquer Algorithm) 来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool能够使用相对较少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概200万+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法向任务队列中再添加一个任务并在等待该任务完成之后再继续执行。而使用ForkJoinPool就能够解决这个问题,它就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
那么使用ThreadPoolExecutor或者ForkJoinPool,性能上会有什么差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,很显然这是不可行的,也是很不合理的!!
2. 示例
此处使用Fork/Join 框架,结合二分法演示一个 1+2+3....+10000 的求和。
/*
* @ProjectName: 编程学习
* @Copyright: 2022 HangZhou Yiyuery Dev, Ltd. All Right Reserved.
* @address: 微信搜索公众号「架构探险之道」获取更多资源。
* @date: 2022/6/11 3:11 PM
* @blog: https://yiyuery.blog.csdn.net/
* @description: 本内容仅限于编程技术学习使用,转发请注明出处.
*/
package com.example.gp2022_example.chapter_05;
import java.text.MessageFormat;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* <p>
*
* </p>
*
* @author Yiyuery
* @date 2022/6/11 3:11 PM
* @sine 1.0
*/
public class ForkJoinExample {
/**
* 每 200 个进行一次任务分割,每一个子任务处理 200 个数字的相加
*/
public static final int MAX_SUB_TASK_HANDLE_RANGE = 200;
static class CalcForkJoinTask extends RecursiveTask<Integer> {
private int start; // 子任务开始位置
private int end; // 子任务结束位置
public CalcForkJoinTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start < MAX_SUB_TASK_HANDLE_RANGE) {
int result = 0;
for (int i = this.start; i <= this.end; i++) {
result += i;
}
System.out.println(MessageFormat.format("开始计算起始值:{0},结束值{1},得出结果{2}", start, end, result));
return result;
}
// 否则使用二分法继续拆分进行计算
CalcForkJoinTask subTask1 = new CalcForkJoinTask(start, (start + end) / 2);
subTask1.fork();
CalcForkJoinTask subTask2 = new CalcForkJoinTask((start + end) / 2+1, end);
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> submit = forkJoinPool.submit(new CalcForkJoinTask(1, 10000));
try {
Integer integer = submit.get();
System.out.println("result:" + integer);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
“输出结果 ”
开始计算起始值:1,720,结束值1,875,得出结果280,410
开始计算起始值:6,095,结束值6,250,得出结果962,910
开始计算起始值:5,783,结束值5,938,得出结果914,238
result:50005000
“整体思想其实就是拆分与合并。 ”
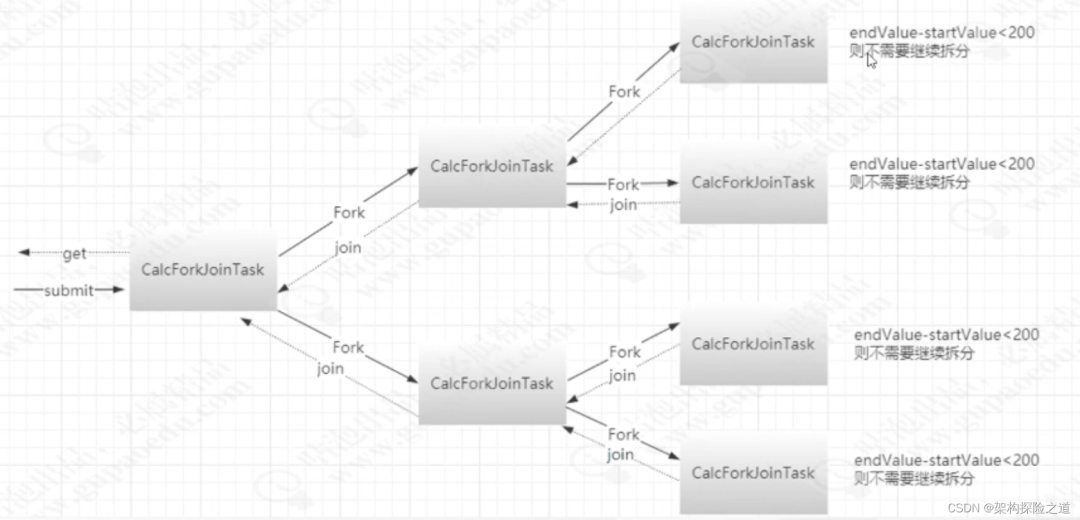
图中最顶层的任务使用 submit 方式被提交到 Fork/Join 框架中,Fork/Join把这个任务放入到某个线程 中运行,工作任务中的 compute 方法的代码开始对这个任务T1进行分析。如果当前任务需要累加的数字范围过大(代码中设定的是大于200),则将这个计算任务拆分成两个子任务(T1.1和T1.2),每个 子任务各自负责计算一半的数据累加,请参见代码中的 fork 方法。如果当前子任务中需要累加的数字范围足够小(小于等于200),就进行累加然后返回到上层任务中。
3. API
“ForkJoinTask 有三个子类 ”
- RecursiveAction:有返回结果
- RecursiveTask:没有返回结果
- CountedCompleter:没有返回值,任务完成后触发一个回调
“方法 ”
- fork:让 task 异步执行
- join:让 task 同步执行,等待获得返回值
避免无限创建线程,内部有线程池控制
- ForkJoinPool
4. 原理分析
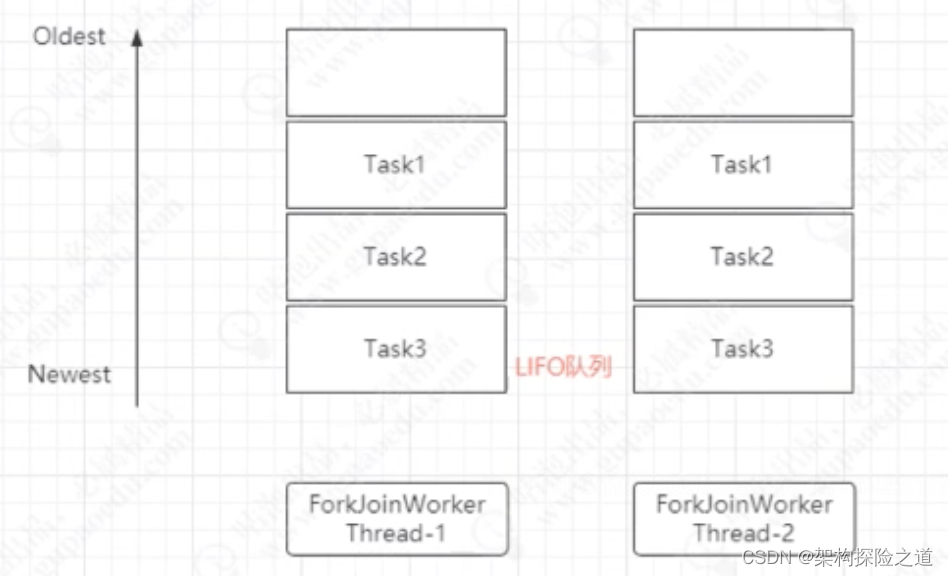
工作队列(双端队列)
java.util.concurrent.ForkJoinTask#fork
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
每个线程内部私有队列,从队尾往里加入元素,后进先出
工作窃取(队尾取未执行任务)
先完成的线程从其他未完成的线程的队尾取未执行的任务,为什么从队尾取呢?避免线程竞争
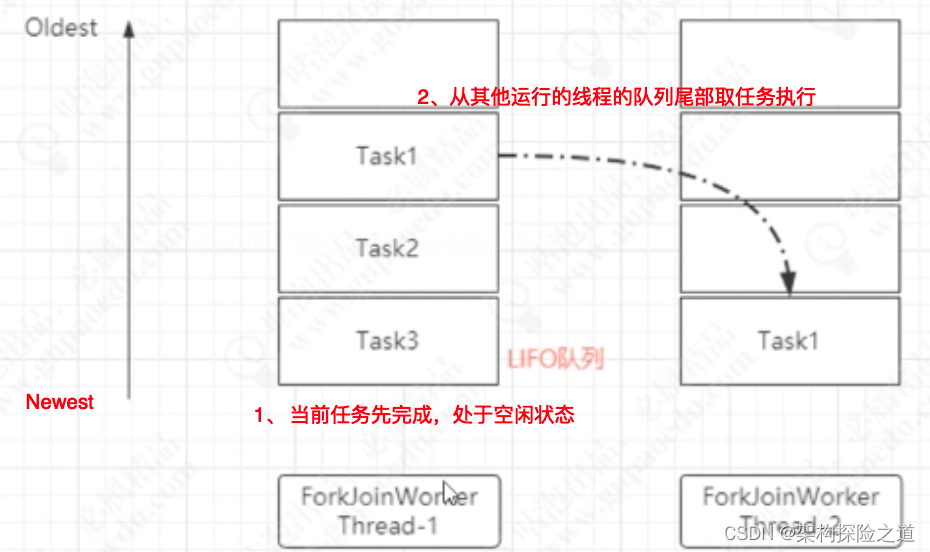
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。
但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点:
充分利用线程进行并行计算,并减少了线程间的竞争。
工作窃取算法的缺点:
在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
Fork/Join框架局限性:
对于Fork/Join框架而言,当一个任务使用 Join 操作阻塞,正在等待的子任务结束时,执行这个任务的工作线程查找其他未被执行的任务,并开始执行这些未被执行的任务,通过这种方式,线程充分利用它们的运行时间来提高应用程序的性能。为了实现这个目标,Fork/Join框架执行的任务有一些局限性。
(1)任务只能使用 Fork 和 Join 操作来进行同步机制,如果使用了其他同步机制,则在同步操作时,工作线程就不能执行其他任务了。比如,在Fork/Join框架中,使任务进行了睡眠,那么,在睡眠期间内,正在执行这个任务的工作线程将不会执行其他任务了。
(2)在 Fork/Join 框架中,所拆分的任务不应该去执行IO操作,比如:读写数据文件。
(3)任务不能抛出检查异常,必须通过必要的代码来处理这些异常。
5. 应用场景实战模拟
“电商系统中,涉及商品信息查询,我们来写个 demo 实际使用下 ForkJoin ”
- 商品基本信息(RPC)
- 商品评价信息(RPC)
- 店铺信息(RPC)
-
- 销售信息(RPC)
- 店铺基本信息(RPC)
=> 汇总结果
信息模型定义
@Data
@AllArgsConstructor
class ShopInfo {
private String id;
private String name;
private String goodsCnt;
private String topGoods;
}
@Data
@AllArgsConstructor
class SellerInfo {
private String id;
private String name;
}
@Data
@AllArgsConstructor
class ItemComment {
private String id;
private String userName;
private String content;
}
@Data
@AllArgsConstructor
class ItemInfo {
private String id;
private String name;
}
@Data
class TradeQueryContext {
private ItemInfo itemInfo;
private ItemComment itemComment;
private ShopInfo shopInfo;
private SellerInfo sellerInfo;
}
通过交易上下文管理所有商品相关信息的汇聚。
定义数据加载处理器抽象行为
interface ILoadDataProcessor<T> {
/**
* 加载业务上下文
*
* @param context
*/
void load(T context);
/**
* 分发子任务
*
* @return
*/
default void dispatch() {
}
}
定义数据加载模板方法
abstract class AbstractLoadDataProcessor extends RecursiveAction implements ILoadDataProcessor<TradeQueryContext> {
protected TradeQueryContext tradeQueryContext;
@Override
protected void compute() {
load(tradeQueryContext);
}
// 由于任务嵌套,每一个任务必须等待其子任务完全执行结束,汇总结果后才可以返回,定义 block 方法用于阻塞等待子任务
public void block() {
// 等待执行结束
this.join();
}
// 通过指定数据加载处理器获取数据时一定是解除阻塞状态下
public TradeQueryContext getTradeQueryContext() {
this.block();
return tradeQueryContext;
}
public void setTradeQueryContext(TradeQueryContext tradeQueryContext) {
this.tradeQueryContext = tradeQueryContext;
// 如果有子任务,则在传入交易上下文时进行初始化
dispatch();
}
}
定义商品数据加载器分层
“最外层加载商品所有数据的总任务 ”
/**
* 商品相关信息聚合
*/
class ItemDataLoadForkJoinProcessor extends AbstractLoadDataProcessor {
@Setter
private List<AbstractLoadDataProcessor> itemLoadDataProcessors = new ArrayList<>();
@Override
public void load(TradeQueryContext context) {
itemLoadDataProcessors.forEach(abstractLoadDataProcessor -> {
abstractLoadDataProcessor.setTradeQueryContext(context);
// 触发子任务执行
abstractLoadDataProcessor.fork();
});
}
@Override
public void dispatch() {
// 分别对应 商品基础信息、商品评价、商户汇聚信息
this.itemLoadDataProcessors.add(new ItemInfoLoadForkJoinProcessor());
this.itemLoadDataProcessors.add(new ItemCommentLoadForkJoinProcessor());
this.itemLoadDataProcessors.add(new SellerDataComplexLoadForkJoinProcessor());
}
@Override
public TradeQueryContext getTradeQueryContext() {
block();
return super.getTradeQueryContext();
}
// 对于汇聚任务,自己必须先执行完,然后等待子任务完成
public void block() {
this.join();
itemLoadDataProcessors.forEach(AbstractLoadDataProcessor::block);
}
}
“内部嵌套复合任务:商户信息汇聚任务(包含店铺信息和商户基础信息) ”
/**
* 商户相关信息聚合
*/
class SellerDataComplexLoadForkJoinProcessor extends AbstractLoadDataProcessor {
private List<AbstractLoadDataProcessor> sellerLoadDataProcessors = new ArrayList<>();
@Override
public void load(TradeQueryContext context) {
sellerLoadDataProcessors.forEach(abstractLoadDataProcessor -> {
abstractLoadDataProcessor.setTradeQueryContext(context);
abstractLoadDataProcessor.fork();
});
}
@Override
public TradeQueryContext getTradeQueryContext() {
return super.getTradeQueryContext();
}
public void block() {
this.join();
sellerLoadDataProcessors.forEach(AbstractLoadDataProcessor::block);
}
public void dispatch() {
this.sellerLoadDataProcessors.add(new SellerInfoLoadForkJoinProcessor());
this.sellerLoadDataProcessors.add(new ShopInfoLoadForkJoinProcessor());
}
}
定义子任务
“通过延迟等待模拟 Rpc 的不同耗时 ”
abstract class RpcQuery<T, R> {
/**
* 模拟 Rpc 请求
*
* @param waitTime
* @param result
* @return
*/
R mockRpc(int waitTime, Supplier<R> result) {
try {
Thread.sleep(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
return result.get();
}
}
“子任务定义,分别耗时 1s、2s、3s、4s ”
class SellerInfoLoadForkJoinProcessor extends AbstractLoadDataProcessor {
@Override
public void load(TradeQueryContext context) {
/**
* 等待4秒后返回结果
*/
context.setSellerInfo(new RpcQuery<Void, SellerInfo>() {
}.mockRpc(4000, () -> new SellerInfo("1", "小米旗舰店商户李四")));
}
}
class ShopInfoLoadForkJoinProcessor extends AbstractLoadDataProcessor {
@Override
public void load(TradeQueryContext context) {
/**
* 等待3秒后返回结果
*/
context.setShopInfo(new RpcQuery<Void, ShopInfo>() {
}.mockRpc(3000, () -> new ShopInfo("1", "小米旗舰店", "商品数:30", "主打商品:小米 Pro6")));
}
}
class ItemInfoLoadForkJoinProcessor extends AbstractLoadDataProcessor {
@Override
public void load(TradeQueryContext context) {
/**
* 等待2秒后返回结果
*/
context.setItemInfo(new RpcQuery<Void, ItemInfo>() {
}.mockRpc(2000, () -> new ItemInfo("1", "小米手机")));
}
}
class ItemCommentLoadForkJoinProcessor extends AbstractLoadDataProcessor {
@Override
public void load(TradeQueryContext context) {
/**
* 等待1秒后返回结果
*/
context.setItemComment(new RpcQuery<Void, ItemComment>() {
}.mockRpc(1000, () -> new ItemComment("1", "张三", "手机不错")));
}
}
运行结果
private static ForkJoinPool forkJoinPool = new ForkJoinPool();
public static void main(String[] args) {
// 初始化任务发起
ItemDataLoadForkJoinProcessor itemDataLoadForkJoinProcessor = new ItemDataLoadForkJoinProcessor();
// 设置全局业务上下文
itemDataLoadForkJoinProcessor.setTradeQueryContext(new TradeQueryContext());
// 记录开始时间
long st = System.currentTimeMillis();
// 提交任务
forkJoinPool.submit(itemDataLoadForkJoinProcessor);
// 获取任务结果
System.out.println(itemDataLoadForkJoinProcessor.getTradeQueryContext());
System.out.println("请求累计耗时: " + ((System.currentTimeMillis() - st) / 1000));
}
// 打印
TradeQueryContext(itemInfo=ItemInfo(id=1, name=小米手机),
itemComment=ItemComment(id=1, userName=张三, content=手机不错),
shopInfo=ShopInfo(id=1, name=小米旗舰店, goodsCnt=商品数:30, topGoods=主打商品:小米 Pro6),
sellerInfo=SellerInfo(id=1, name=小米旗舰店商户李四))
请求累计耗时: 4
6. 小结
“应用场景 ”
- 二分搜索
- 大整数乘法
- Strassen 矩阵乘法
- 棋盘覆盖
- 合并排序
- 快速排序
- 线性时间选择
- 汉诺塔
“基本思想: 分治法 ”
把一个规模大的问题划分为规模较小的子问题,然后分而治之,最后合并子问题的解得到原问题的解。操作步骤拆解如下:
- 分割原问题;
- 求解子问题;
- 合并子问题的解为原问题的解。
我们可以使用如下伪代码来表示这个步骤。
if(任务很小){
直接计算得到结果
}else{
分拆成N个子任务
调用子任务的fork()进行计算
调用子任务的join()合并计算结果
}
在分治法中,子问题一般是相互独立的,因此,经常通过递归调用算法来求解子问题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-06-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
