一键获取GPL注释文件
原创
引言
GEO 官网中 GPL 的注释文件大概有三种表现形式,一是 soft 文件,二是由 soft 文件进行提取整理的 annot 文件,三是直接抽取 soft 文件形成的的 table 文件。
实际使用的情况下, soft 文件由于体积过大不适合使用,如 GPL570 的 soft 文件足足有64G。而很多平台没有提供 annot 文件,所以,使用 full table 进行注释也是一个比较常用的途径。
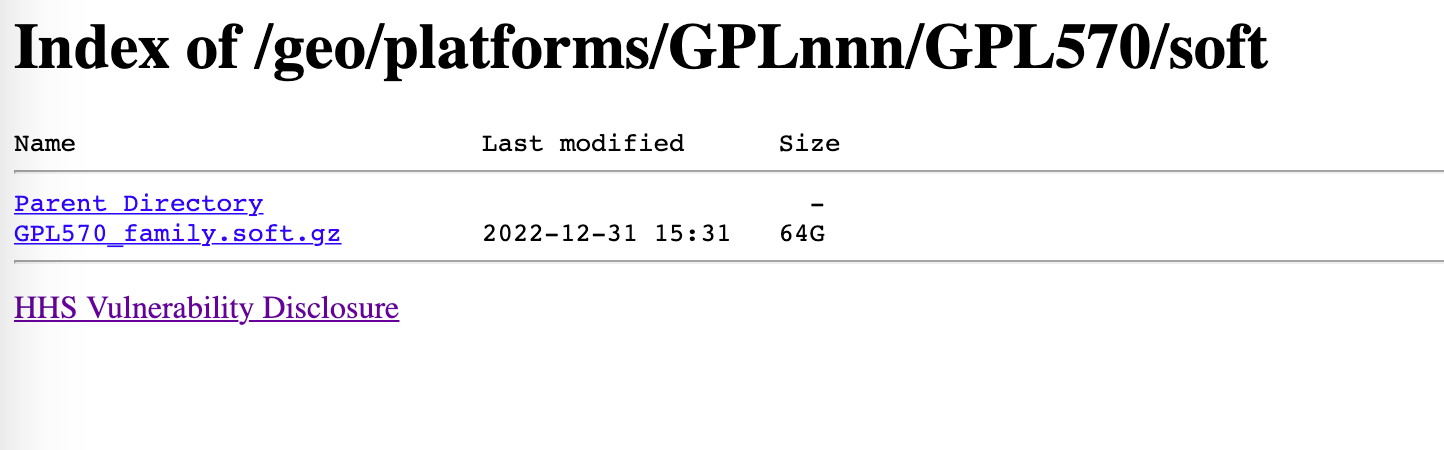
然而,下载 full table 的时候,偶尔会碰见下方写的只有 View full table。。。 而没有 Download full table。。。 的情况,这种情况直接点击查看然后复制粘贴就有了丢失数据的风险,有时甚至有程序崩溃的风险,文件的编码转换也是一个问题。所以,用爬虫代码爬取表格也有了一试的价值。
而爬虫代码可以托管在服务器上, 实现GPL注释文件的一键获取.
效果展示
过程
可以看到 GPL10687 平台未提供可下载的 full table 链接.
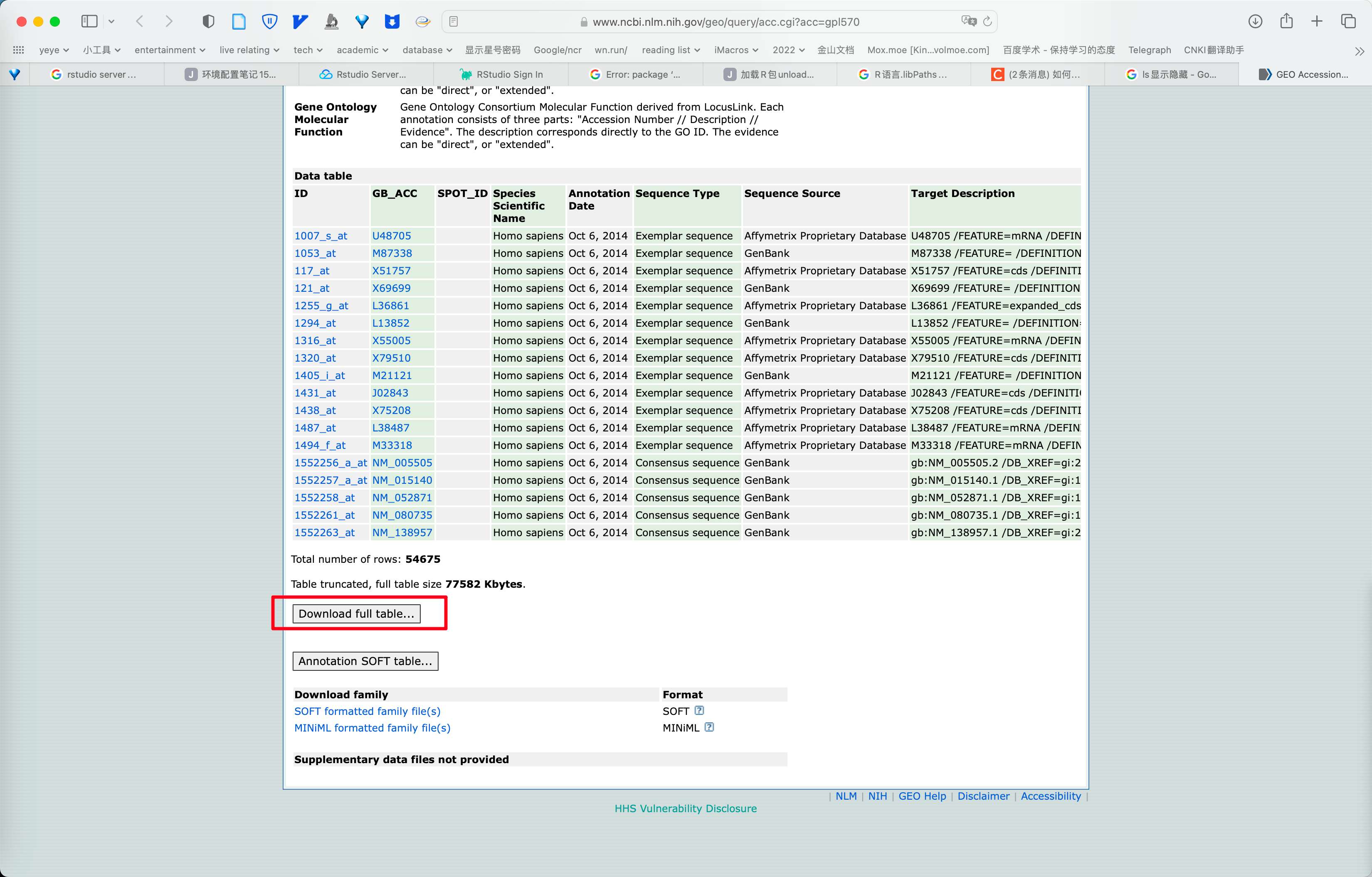
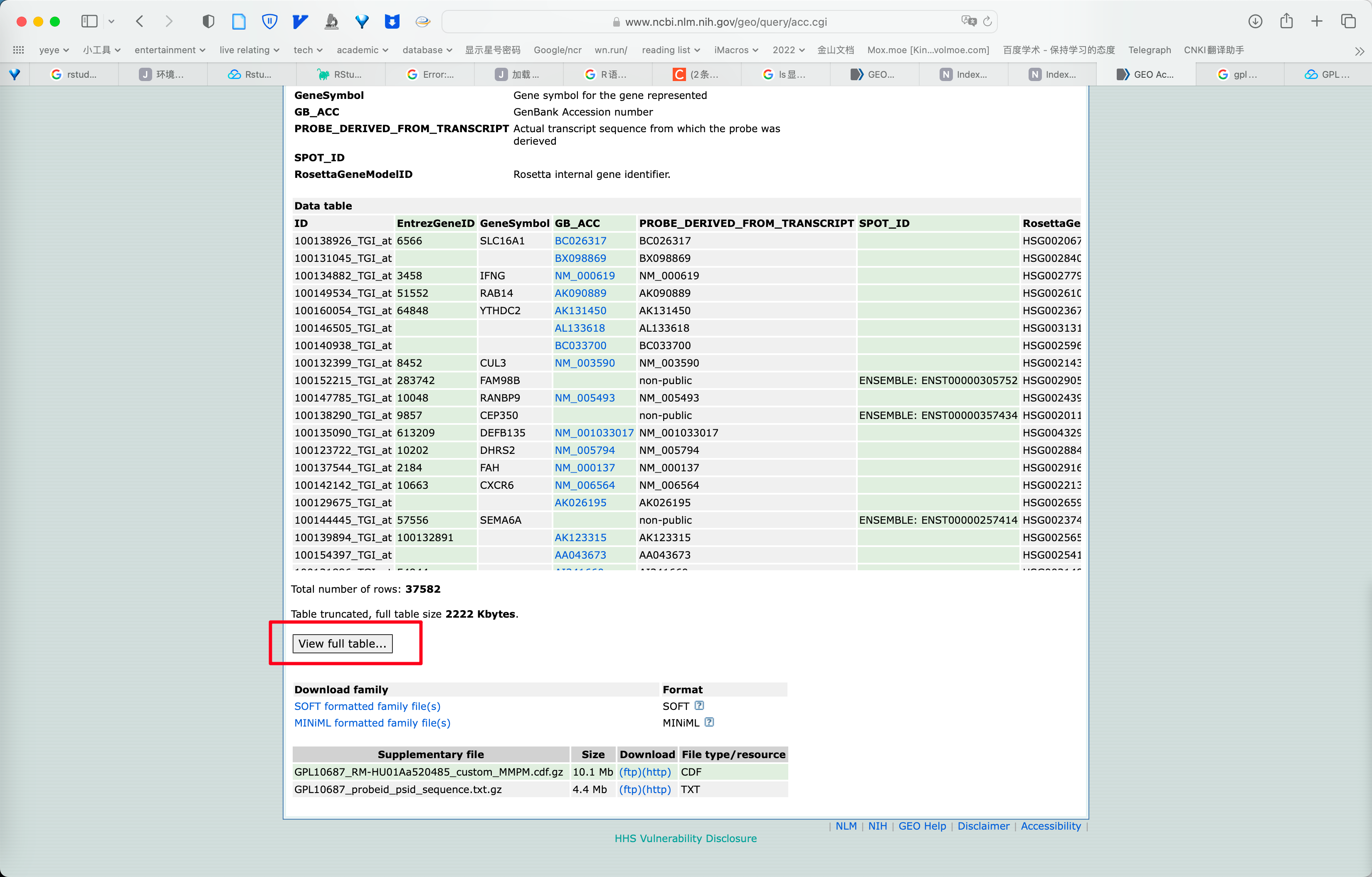
点击 View full table。。。 可以看到该文件的链接,即 https:、、www。ncbi。nlm。nih。gov、geo、query、acc。cgi?view=data&acc=GPL10687&id=11880&db=GeoDb_blob47 ,实验可知 https:、、www。ncbi。nlm。nih。gov、geo、query、acc。cgi?view=data&acc=GPL10687 可获得同样的结果。
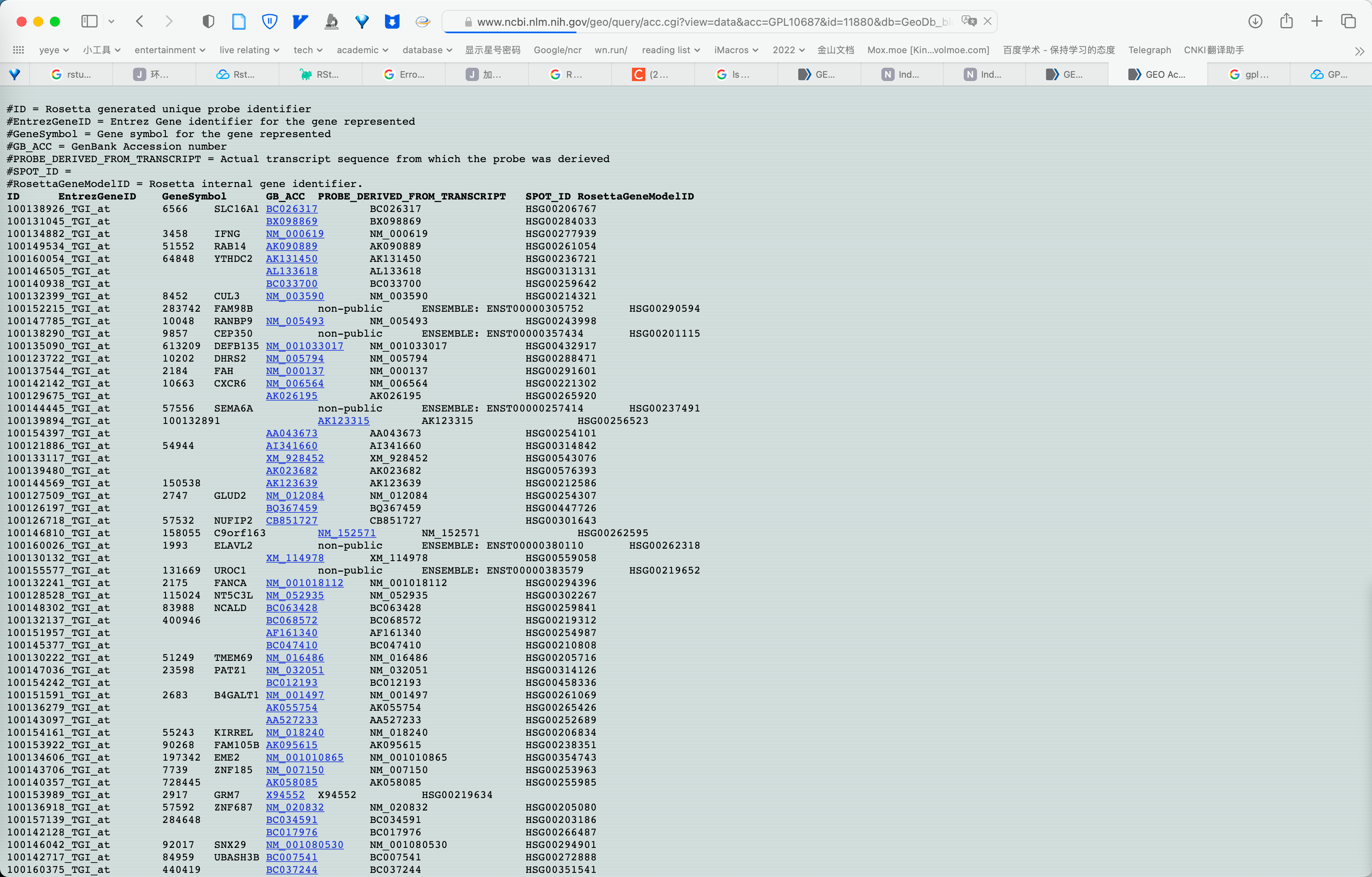
于是, 只需要读取网页 html 后整理即可.
import os
import requests
from bs4 import BeautifulSoup
proxies = {
'http': 'http://127.0.0.1:7890',
'https': 'http://127.0.0.1:7890'
}
def download_gpl_data(gpl_id):
# 检测gpl_id格式,如果不是GPLXXXXX格式则转换为该格式
if not gpl_id.startswith('GPL'):
gpl_id = 'GPL' + gpl_id
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
}
# 获取初始页面
url = f'https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?view=data&acc={gpl_id}'
response = requests.get(url, headers=headers, proxies=proxies)
soup = BeautifulSoup(response.content, 'html.parser')
# 获取表头
header_tags = soup.find('pre').find_all('strong')
header = [tag.text for tag in header_tags]
header = [h.replace('\t', '') for h in header]
# 找到pre标签中的文本内容
pre_tag = soup.find('pre')
table_data = pre_tag.get_text()
# 创建以gpl_id命名的文件夹
folder_path = os.path.join(os.getcwd(), gpl_id)
os.makedirs(folder_path, exist_ok=True)
# 将数据写入TXT文件
file_path = os.path.join(folder_path, 'gpl_full_table.txt')
with open(file_path, 'w', encoding='utf-8') as file:
# 写入表头
file.write('\t'.join(header) + '\n')
for row in table_data.split('\n')[1:]:
if not row.strip(): # 跳过空行
continue
data = row.split('\t')
file.write('\t'.join(data) + '\n')
print(f'{gpl_id} data has been downloaded and saved to {file_path}.')
if __name__ == '__main__':
gpl_id = input('Please enter the GPL ID: ').strip()
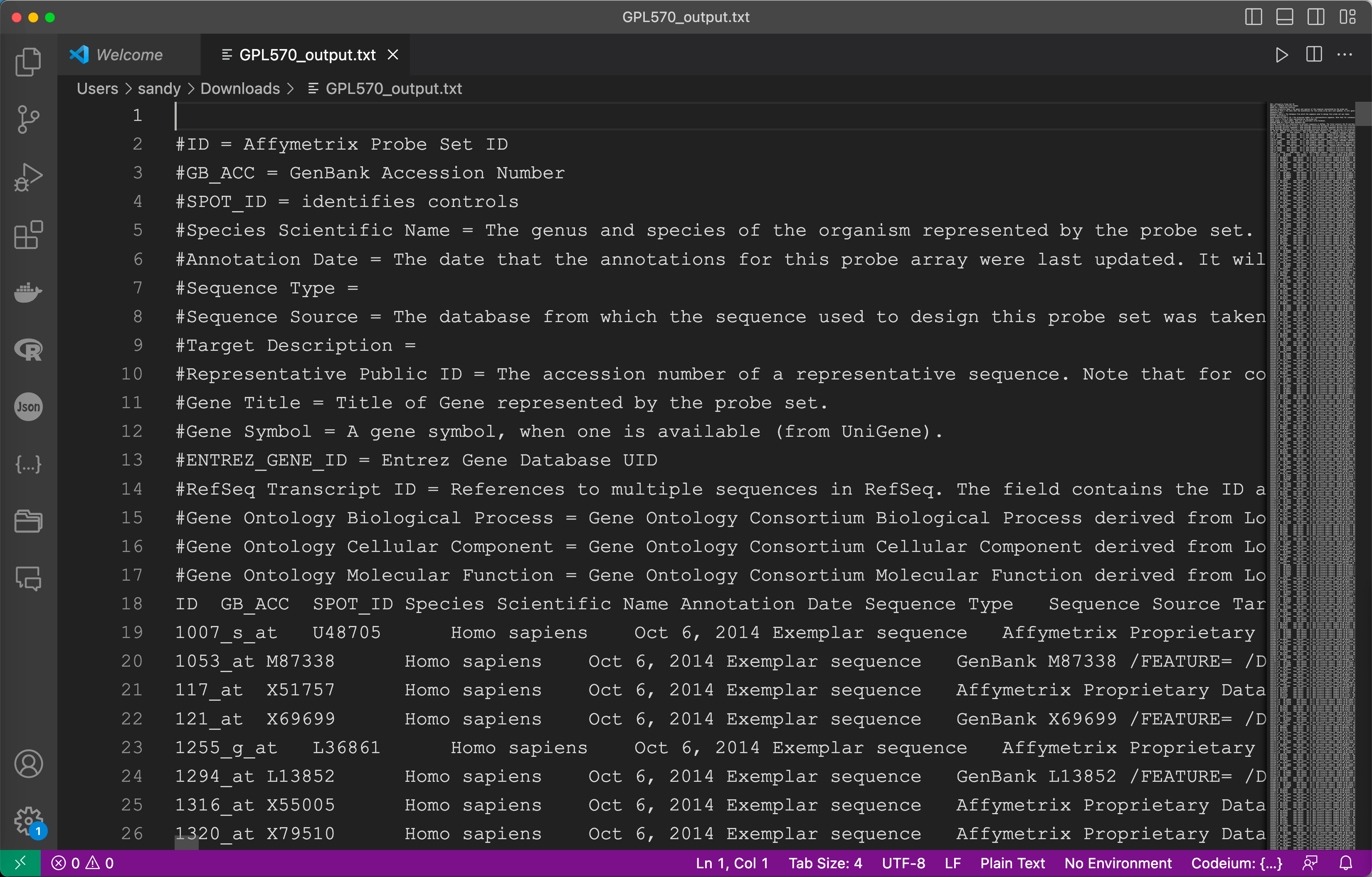
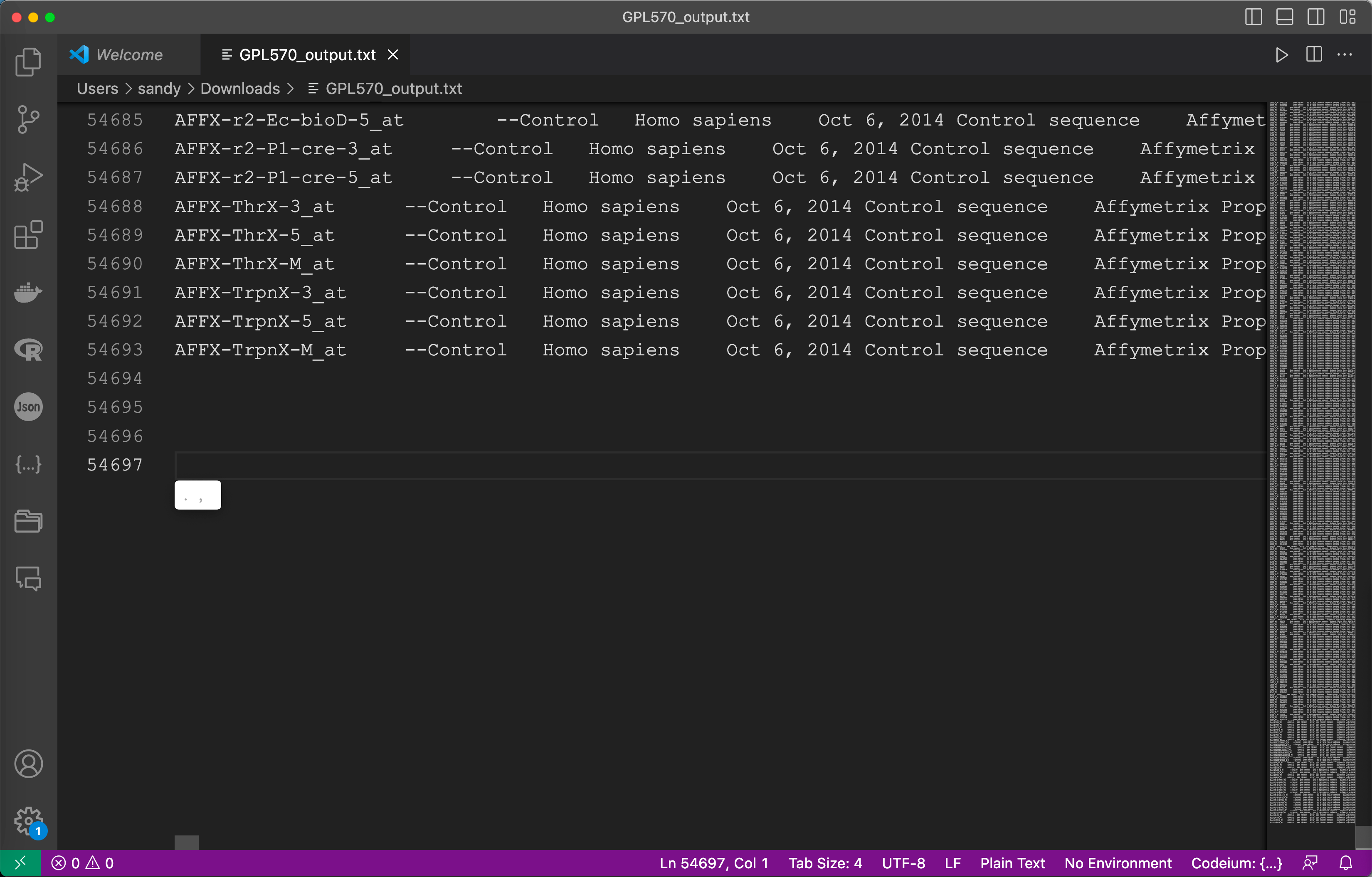
download_gpl_data(gpl_id)以GPL570为例, 查看文件行列数(54693-18)和网页显示(54675)相同后说明实验成功, 为方便使用可使用 flask 框架制作网页, 实现网页一键下载.
from flask import Flask, request, Response, render_template
import requests
from bs4 import BeautifulSoup
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/data')
def get_data():
# 获取请求参数
gpl_id = request.args.get('gpl_id')
# 检查 gpl_id 是否以 "GPL" 开头
if not gpl_id.startswith('GPL'):
gpl_id = 'GPL' + gpl_id
# 获取数据
url = f'https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?view=data&acc={gpl_id}'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
pre_tag = soup.find('pre')
# 生成输出文件
output_file = f"{gpl_id}/output.txt"
with open(output_file, 'w') as file:
file.write(pre_tag.get_text())
# 返回响应
return Response(
open(output_file, 'rb'),
mimetype='text/plain',
headers={'Content-Disposition': f'attachment;filename={output_file}'}
)
if __name__ == '__main__':
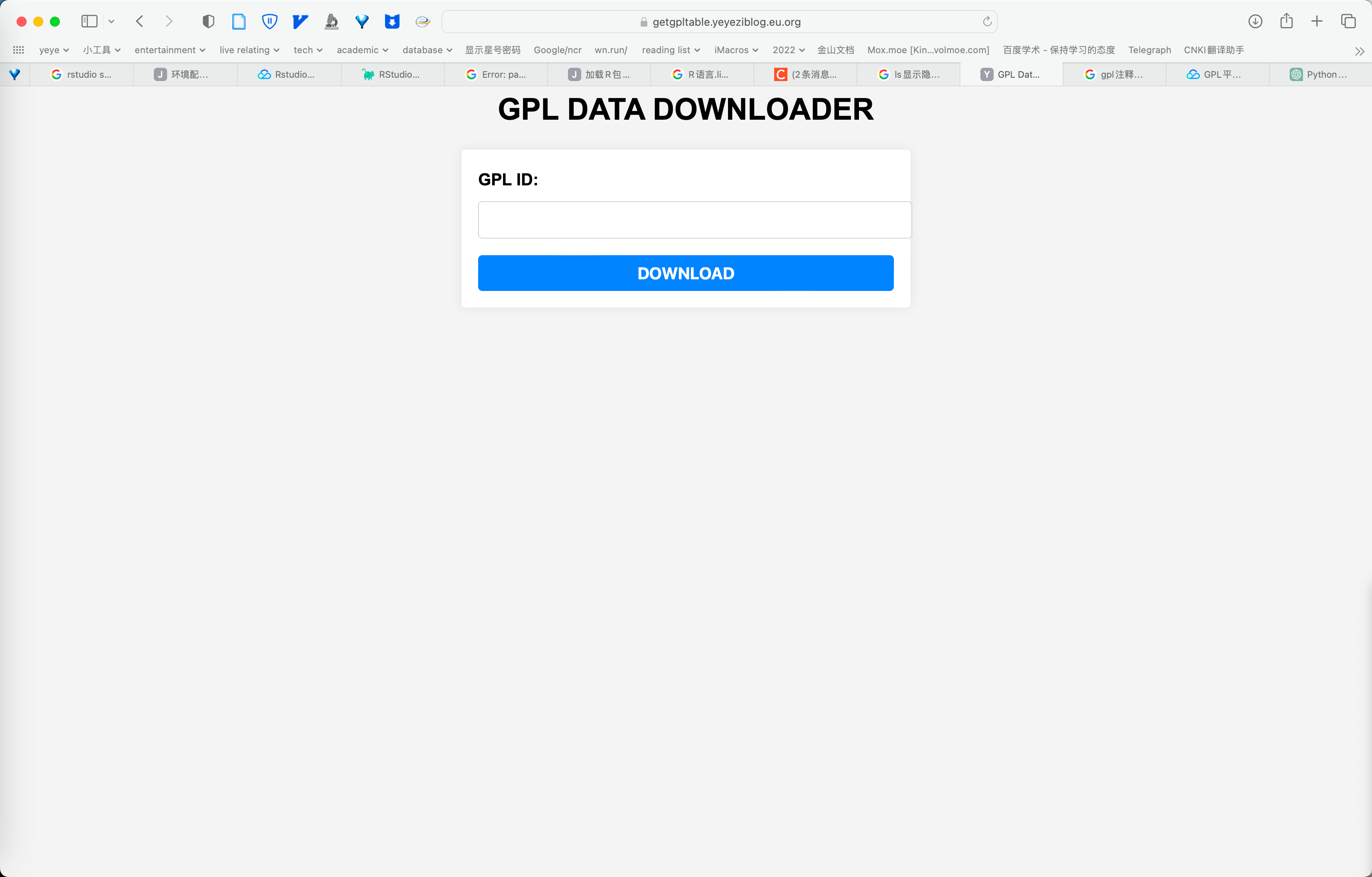
app.run()其中, index.html 需要放在根目录的 templates 文件夹下.
<!DOCTYPE html>
<html>
<head>
<title>GPL Data Downloader</title>
</head>
<body>
<h1>GPL Data Downloader</h1>
<form action="/data">
<label for="gpl_id">GPL ID:</label>
<input type="text" name="gpl_id" id="gpl_id">
<button type="submit">Download</button>
</form>
</body>
</html>网页链接为:
https://getgpltable.yeyeziblog.eu.org
题外话
annnot 文件的读取命令格式如下<sup>2</sup>:
read.delim("GPL570.annot", stringsAsFactors=FALSE, skip = 27 ) 其中, skip = 27 是从27行开始读取的意思, 因为 annot 文件都是处理过的, 所以一般不用动.
txt 文件也就是下载下来的 full table 的读取命令是:
tem <- read.table(fileNameRead,
sep = "\t", quote = "", fill = TRUE, header = TRUE, check.names = F
)当然, 除了一开始提到的三种来自 GEO 平台的注释方法外, 还有来自于 bioconductor 或 pipe 的方式, 但是不属于本文重点, 所以不表.
结语
祝大家生活愉快, 万事顺利, 身体建康! 开心! 快乐! 一定要活着!
引用
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。