视频技术快览 0x0 - 图像基础和前处理

视频技术快览 0x0 - 图像基础和前处理

Cellinlab
发布于 2023-05-17 16:55:38
发布于 2023-05-17 16:55:38
# 基本概念
# 像素
像素是图像的基本单元,一个个像素就组成了图像。可以认为像素就是图像中的一个点。
下面图片中的一个个小方块就是像素:

# 分辨率
图像(或视频)的分辨率是指图像的大小或尺寸,一般用像素个数来表示图像的尺寸。
视频行业常见的分辨率有 QCIF(176x144)、CIF(352x288)、D1(704x576 或 720x576),还有 360P(640x360)、720P(1280x720)、1080P(1920x1080)、4K(3840x2160)、8K(7680x4320)等。
同样一张图像用不同的分辨率表示会有什么不同?可以通过以下这组图片来直观感受一下。

不难看出:
- 像素就只是一个带有颜色的小块
- 分辨率越高,图像越清晰,细节越丰富
- 注意:对于原始图像分辨率越高确实会越清晰,但是通常见到的图像都是经过处理的,如进行缩放、或美颜,经过处理后的图像分辨率很高,但是清晰度却不一定高
# 位深
通常,彩色图像中都有 R 、G、B 三个通道,即每个像素有三个颜色值,分别是红、蓝、绿。
一般 R 、G、B 各占 8 个位,即一个字节。8 位可以表示 256 中颜色值,所以一个像素的颜色值可以有 256x256x256 种,即 16777216 种。这种图像称 8bit 图像,此处的 8bit 就是位深。
可以看出,位深越高,能够表示的颜色值就越多,图像就可以更精确展示色彩。
当然,图像的位深越大,需要的存储空间就越大,传输过程中需要的带宽也就越大。目前大部分情况下,图像的位深都是 8bit。
# Stride
Stride 不是图像本身的属性,在视频中会经常遇到。Stride 可以称为跨距,指图像存储时,内存中每行像素所占用的空间。
为了能快速读取一行像素,一般会对内存中的图像实现内存对齐,如 16 字节对齐。这样,每行像素的字节数就不一定是图像宽度 x 位深,而是图像宽度 x 位深 + 内存对齐的字节数。
比如,有一张 RGB 图像,分辨率是 1278x720,将其存储在内存中,一行像素需要 1278x3 = 3834 字节,如果内存对齐是 16 字节,那么一行像素需要 3840 字节,需要填充 6 个字节。此时,Stride 就是 3840。

这种情况下,每读取一行数据的时候需要跳过这多余的 6 个字节。如果没有跳过的话,填充的 6 个字节的像素就会被误认为是下一行开始的 2 个像素(每个像素 R、G、B 各占 1 个字节,2 个像素共 6 个字节)。那这样得到的图像就完全错了,显示出来的就是“花屏”现象,屏幕会出现一条条的斜线。
# 帧率
视频是由一系列图像组成的,即“连续”的一帧帧图像就可以组成视频。但事实上,视频中的图像并不是真正意义上的连续。也就是说,在 1 秒钟之内,图像的数量是有限的。只是当数量达到一定值之后,人的眼睛的灵敏度就察觉不出来了,看起来就是连续的视频了。
1 秒钟内图像的数量就是帧率。据研究表明,一般帧率达到 10 ~ 12 帧每秒,人眼就会认为是流畅的了。
通常,在电影院看的电影帧率一般是 24fps(帧每秒),监控行业常用 25fps,可以根据自己的使用场景来具体设定帧率值。
选择帧率的时候还需要考虑设备处理性能的问题,尤其是实时视频通话场景。帧率高,代表着每秒钟处理的图像数量会很高,从而需要的设备性能就比较高。如果是含有多个图像处理过程,比如人脸识别、美颜等算法的时候,就更需要考虑帧率大小和设备性能的问题。同样,也要考虑带宽流量的问题。帧率越大,对带宽的要求也会越高。
# 码率
视频的帧率越高,1 秒钟内的图像数据量就会越大。通常存储视频的时候需要对图像进行压缩之后再存储,否则视频会非常大。
码率是指视频在单位时间内的数据量的大小,一般是 1 秒钟内的数据量,其单位一般是 Kb/s 或者 Mb/s。通常,用压缩工具压缩同一个原始视频的时候,码率越高,图像的失真就会越小,视频画面就会越清晰。但同时,码率越高,存储时占用的内存空间就会越大,传输时需要的带宽也会越大。
并不是码率越高,清晰度就会越高。和压缩算法有关,有些算法可以在保证清晰度的情况下,减小码率。
# 颜色空间
# RGB
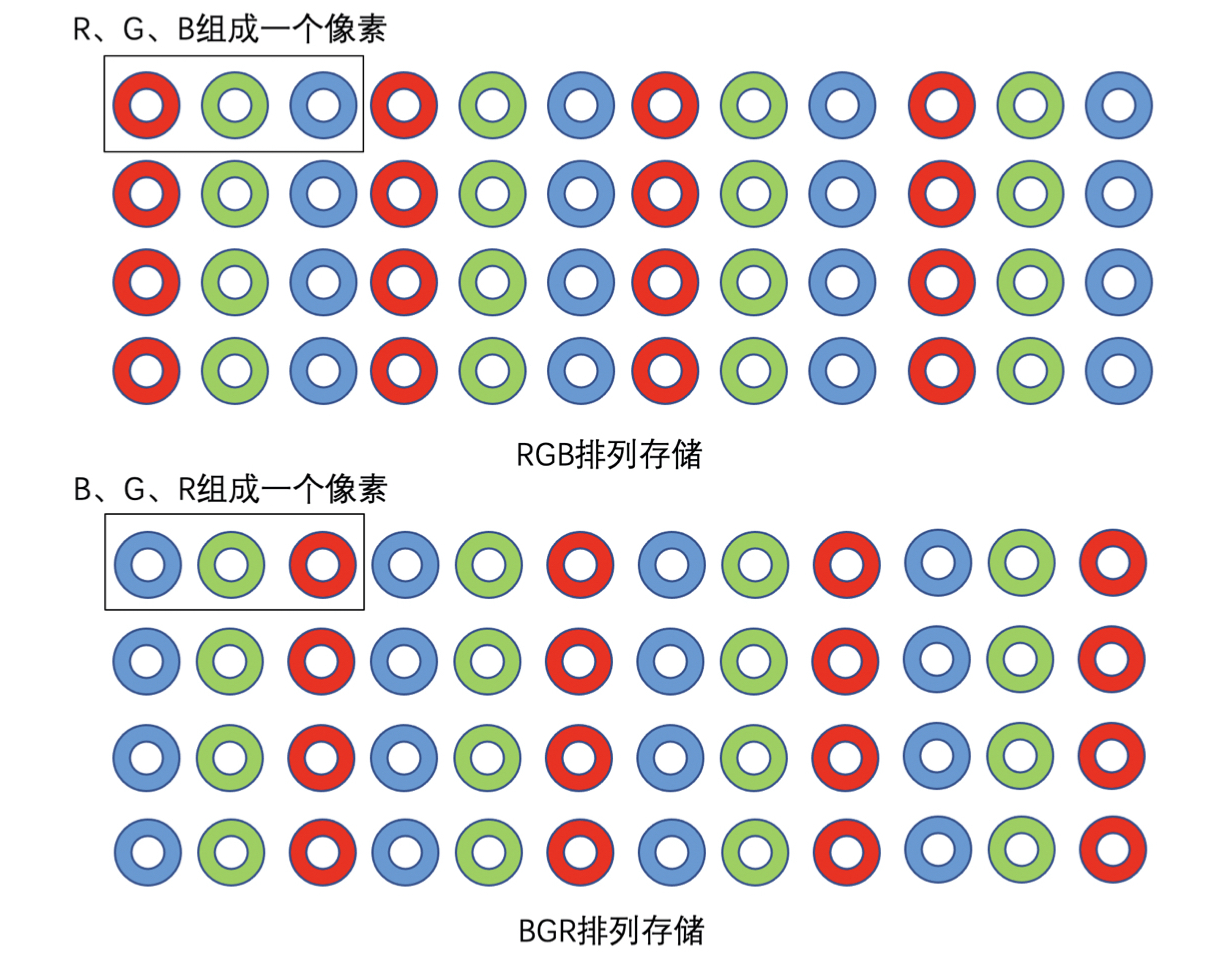
通常,RGB 图像每一个像素都是分别存储 R、G、B 三个值,且三个值依次排列存储。如一张 8 bit 位深的 RGB 图,每个值占用一个字节。但是,需要注意,不一定按照 RGB 的顺序存储,也可能是 BGR 的顺序。
比如,OpenCV 经常使用 BGR 格式存储图像:
虽然 RGB 比较简单,同时在图像处理的时候也经常会用到。但是在视频领域,更多地是使用 YUV 颜色空间来表示图像的。这是因为 R、G、B 三个颜色是有相关性的,所以不太方便做图像压缩编码。
# YUV
YUV 最早主要是用于电视系统与模拟视频领域,现在视频领域基本都是使用 YUV 颜色空间。
跟 RGB 图像中 R、G、B 三个通道都跟色彩信息相关这种特点不同,YUV 图像将亮度信息 Y 与色彩信息 U、V 分离开来。Y 表示亮度,是图像的总体轮廓,称之为 Y 分量。U、V 表示色度,主要描绘图像的色彩等信息,分别称为 U 分量和 V 分量。这样一张图像如果没有了色度信息 U、V,只剩下亮度 Y,则依旧是一张图像,只不过是一张黑白图像。
使用 YUV 的好处
以前只有黑白电视机,每一帧电视画面都是黑白的,没有色彩信息。当然黑白电视机也不支持显示彩色图像。后来随着技术的发展,出现了彩色电视机,每一帧画面都是有颜色信息的,那当然可以使用 RGB、YUV 等颜色空间来表示一帧图像。
但是考虑到兼容老的黑白电视机,如果使用 RGB 表示图像,那么黑白电视机无法播放。因为 R、G、B 三个通道都是彩色的,而 Y、U、V 就可以。因为黑白电视机可以使用 Y 分量,Y 分量就是黑白图像,而且包含了图像的总体轮廓信息,只是没有色彩信息而已。
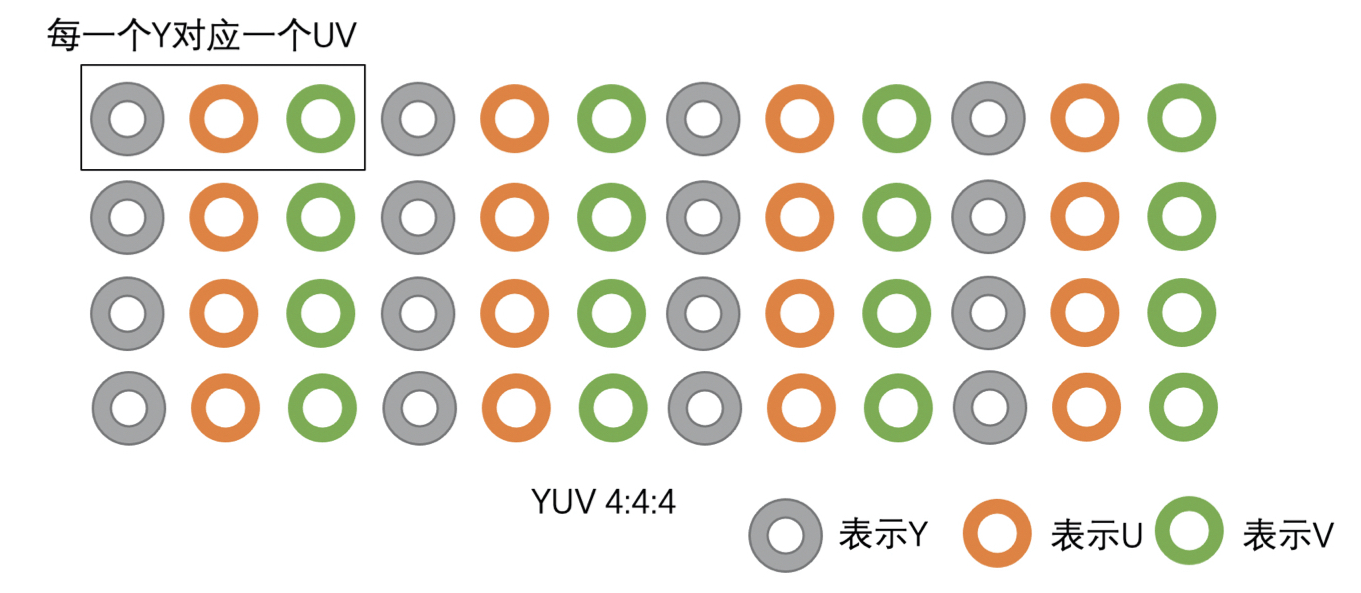
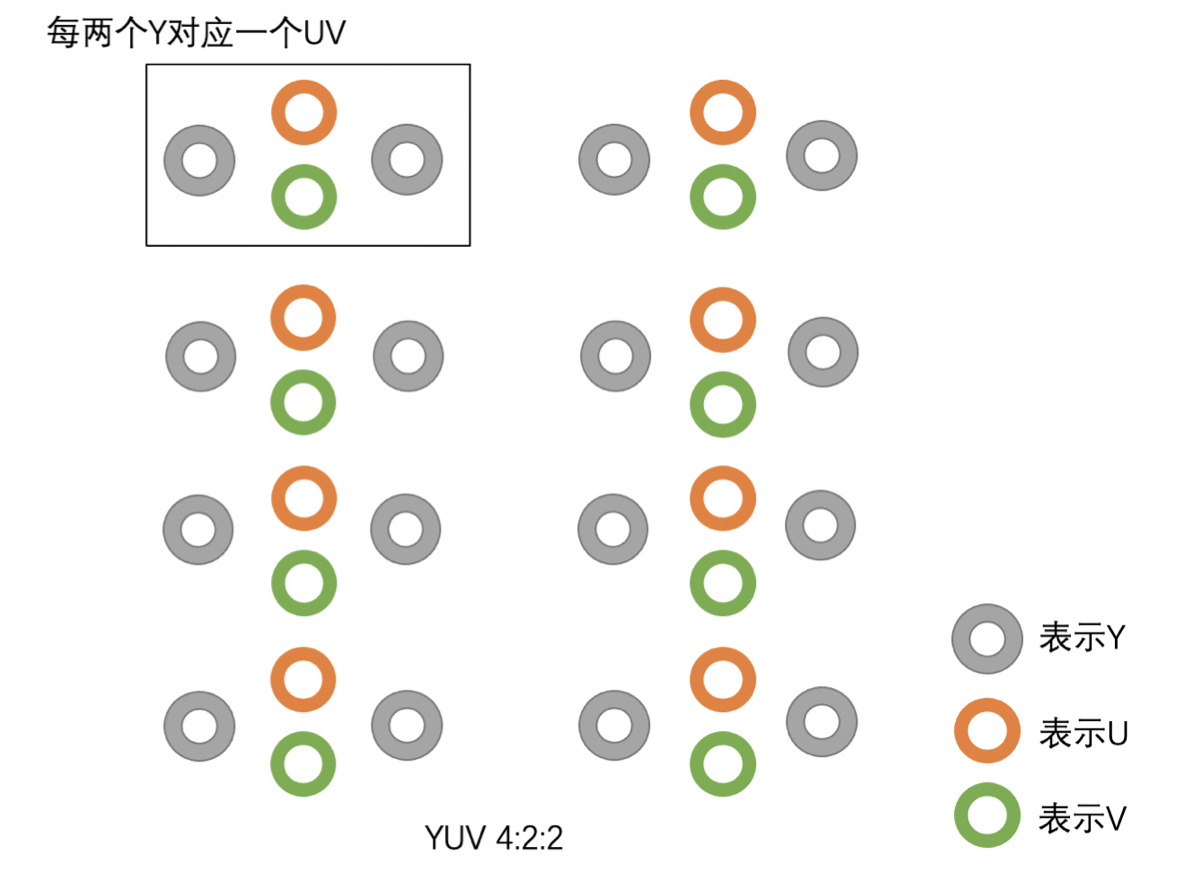
YUV 主要分为 YUV 4:4:4、YUV 4:2:2、YUV 4:2:0 几种常用的类型。其中最常用的又是 YUV 4:2:0。这三种类型的 YUV 主要的区别就是 U、V 分量像素点的个数和采集方式。
YUV 4:4:4 就是每一个 Y 就对应一个 U 和一个 V;
而 YUV 4:2:2 则是每两个 Y 共用一个 U、一个 V;
YUV 4:2:0 则是每四个 Y 共用一个 U、V。
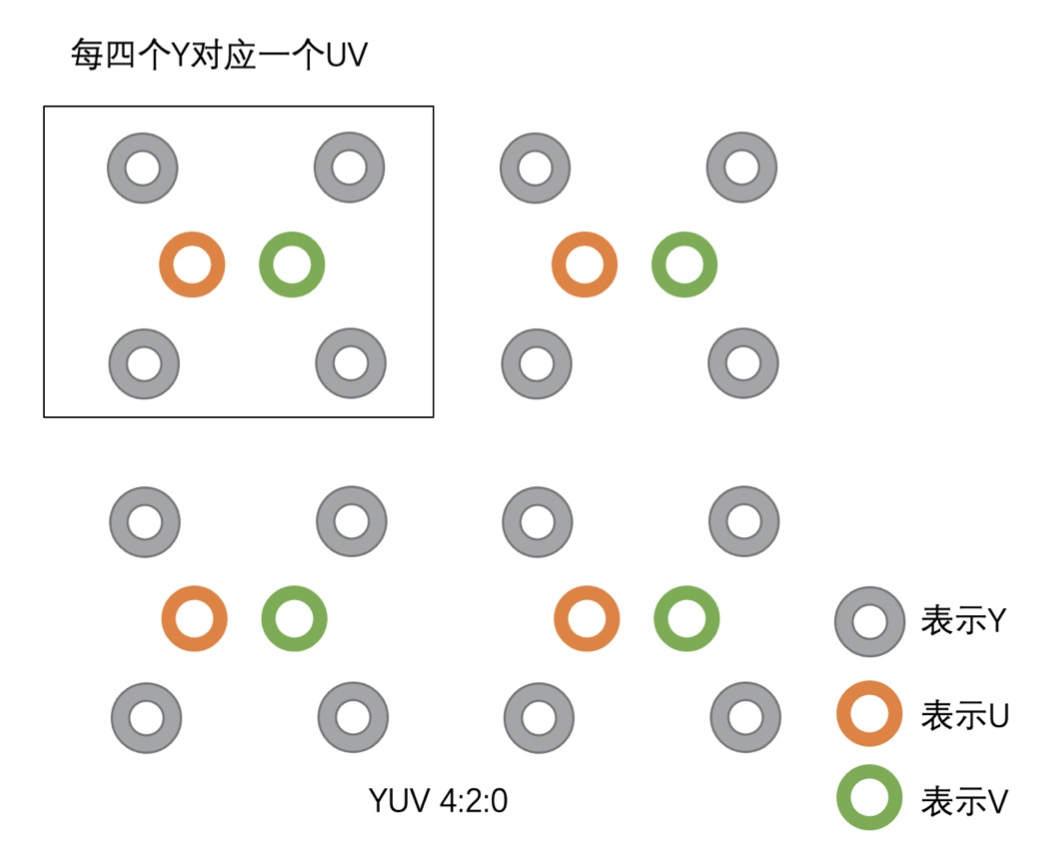
总的来说:
- YUV 4:4:4,每一个 Y 对应一组 UV
- YUV 4:2:2,每两个 Y 共用一组 UV
- YUV 4:2:0,每四个 Y 共用一组 UV
YUV 存储方式主要分为两大类:Planar 和 Packed 两种。Planar 格式的 YUV 是先连续存储所有像素点的 Y,然后接着存储所有像素点的 U,之后再存储所有像素点的 V,也可以是先连续存储所有像素点的 Y,然后接着存储所有像素点的 V,之后再存储所有像素点的 U。Packed 格式的 YUV 是先存储完所有像素的 Y,然后 U、V 连续的交错存储。
- YUV 4:4:4
- 如 4x2 像素的 YUV 4:4:4 存储
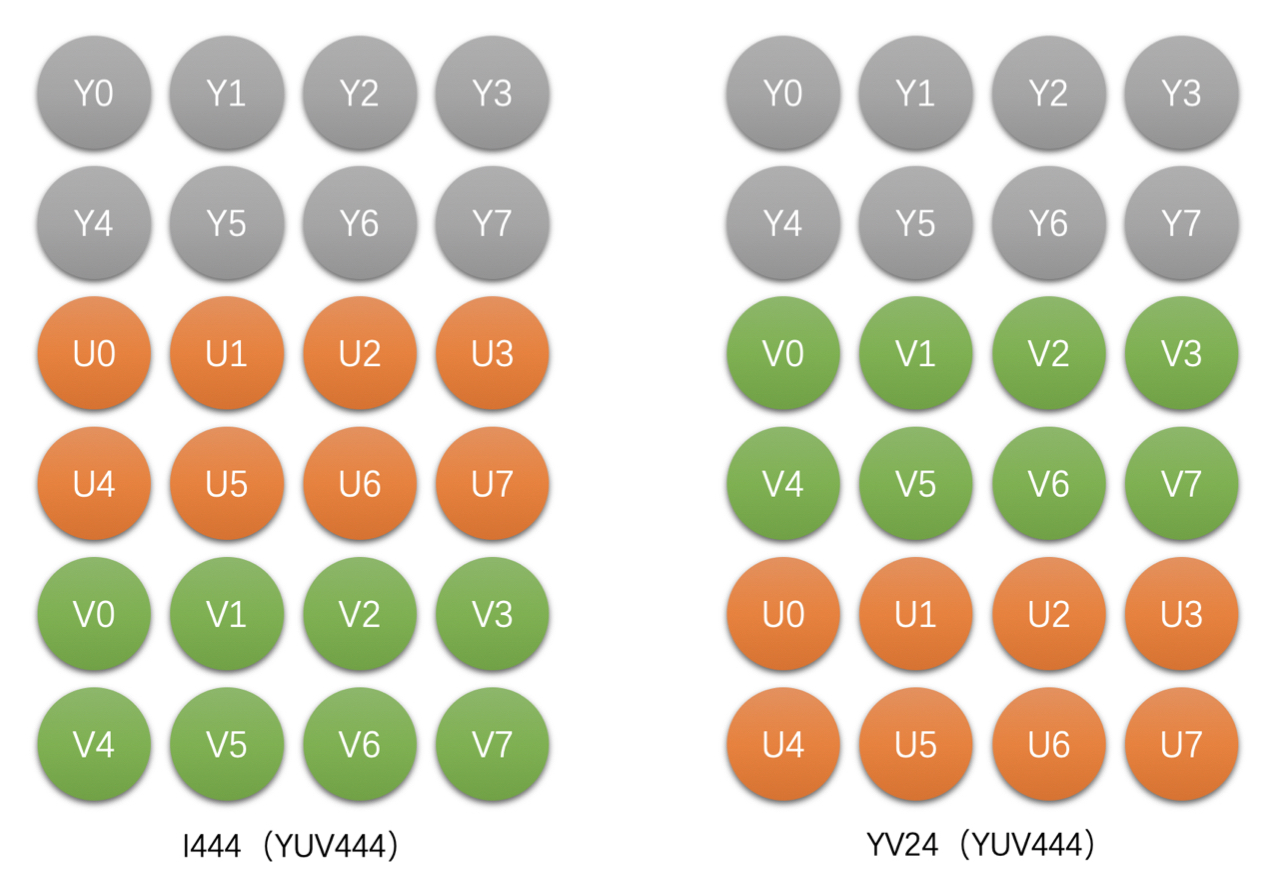
- YUV 4:4:4 和 RGB 图像存储之后的大小是一样的,如果是 8bit 图像,每个像素占 3 个字节
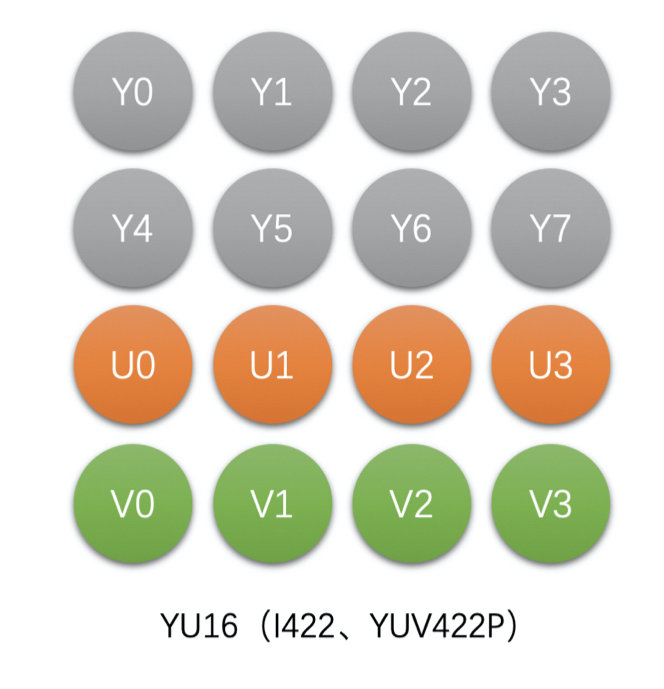
- YUV 4:2:2
- YU16(或称 I422、YUV422P),Planar 格式
- 如 4x2 像素的 YU16 存储
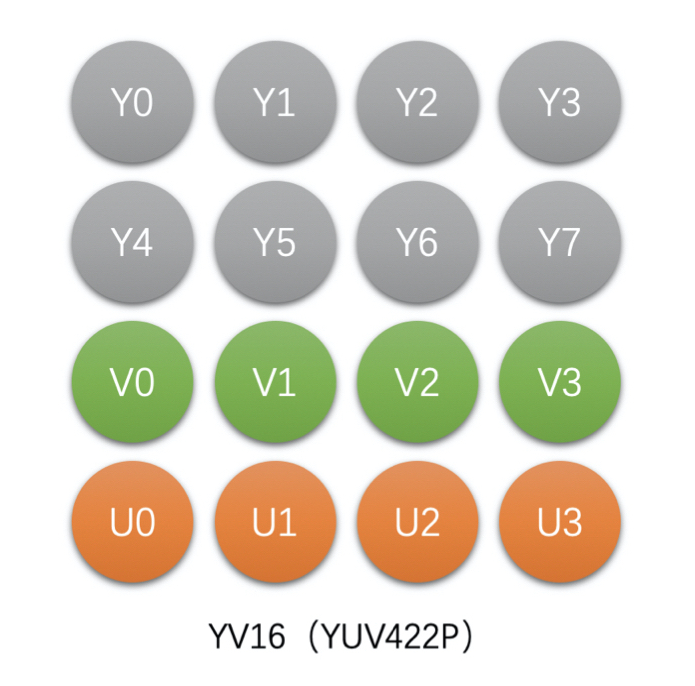
- YV16(YUV422P),Planar 格式
- 如 4x2 像素的 YV16 存储
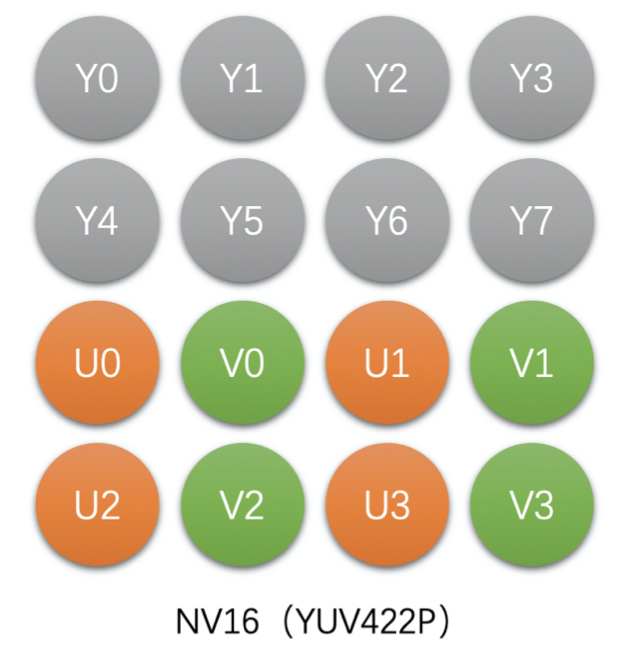
- NV16(YUV422SP),Packed 格式
- 如 4x2 像素的 NV16 存储
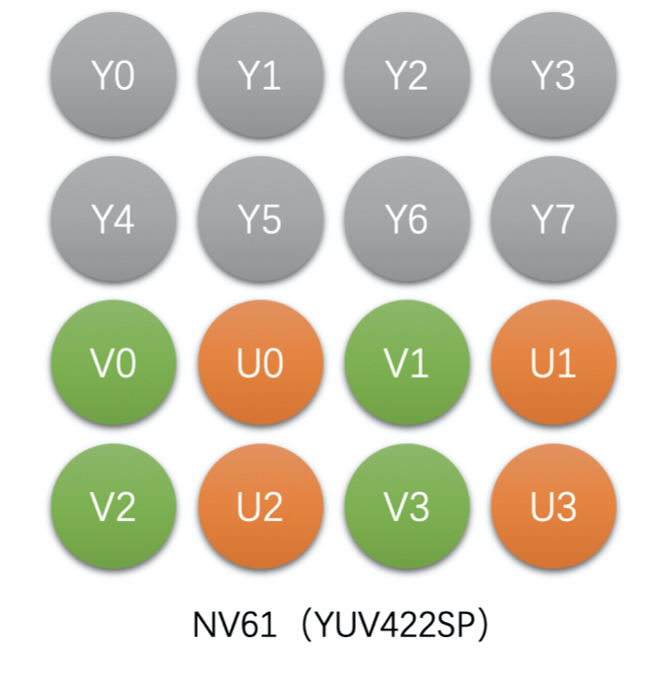
- NV61(YUV422SP),Packed 格式
- 如 4x2 像素的 NV61 存储
- YU16(或称 I422、YUV422P),Planar 格式
- YUV 4:2:0
- 是最常用的 YUV 类型,通常视频压缩都是 YUV 4:2:0 格式的
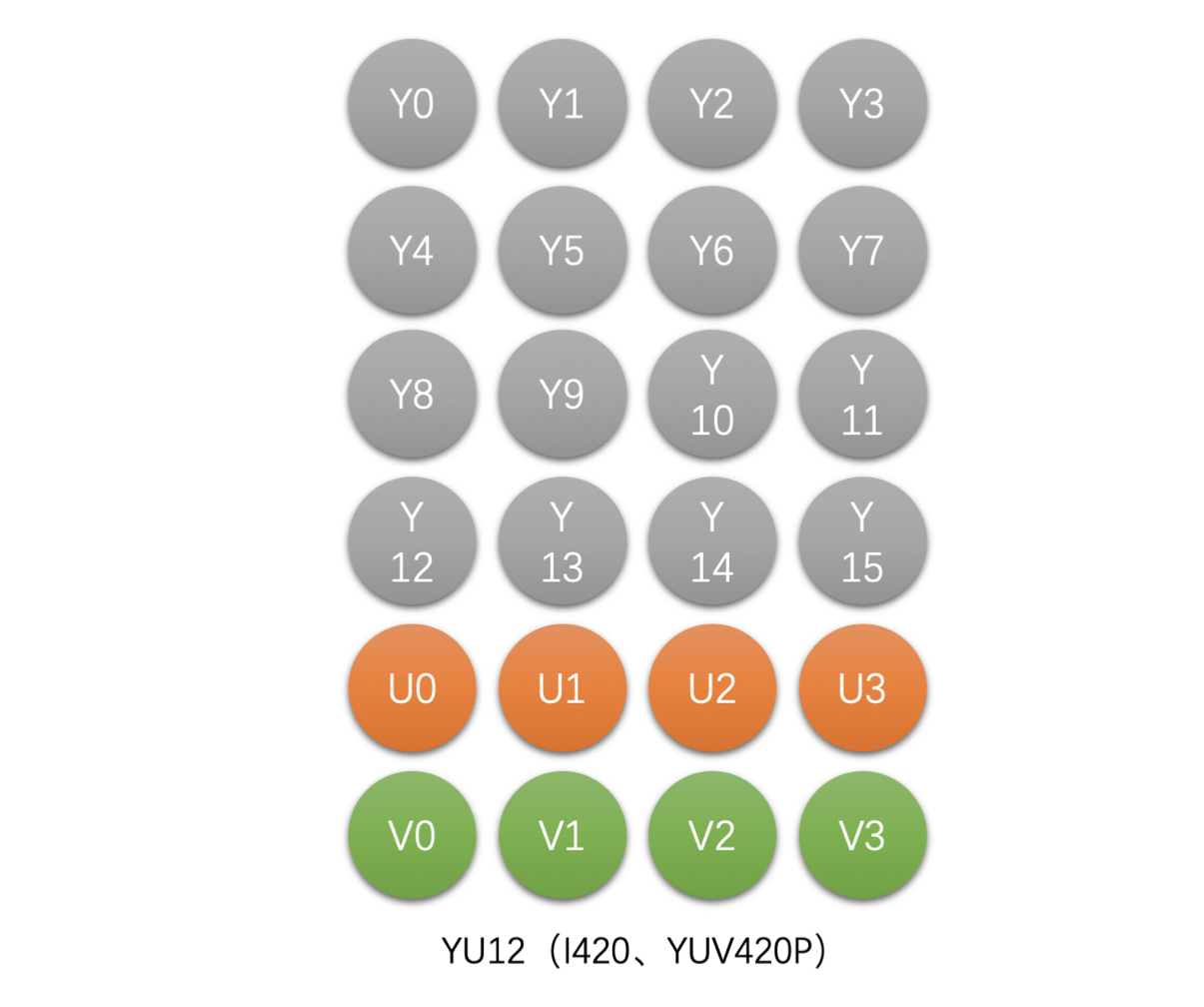
- YU12(I420、YUV420P),Planar 格式
- 如 4x4 像素的 YU12 存储
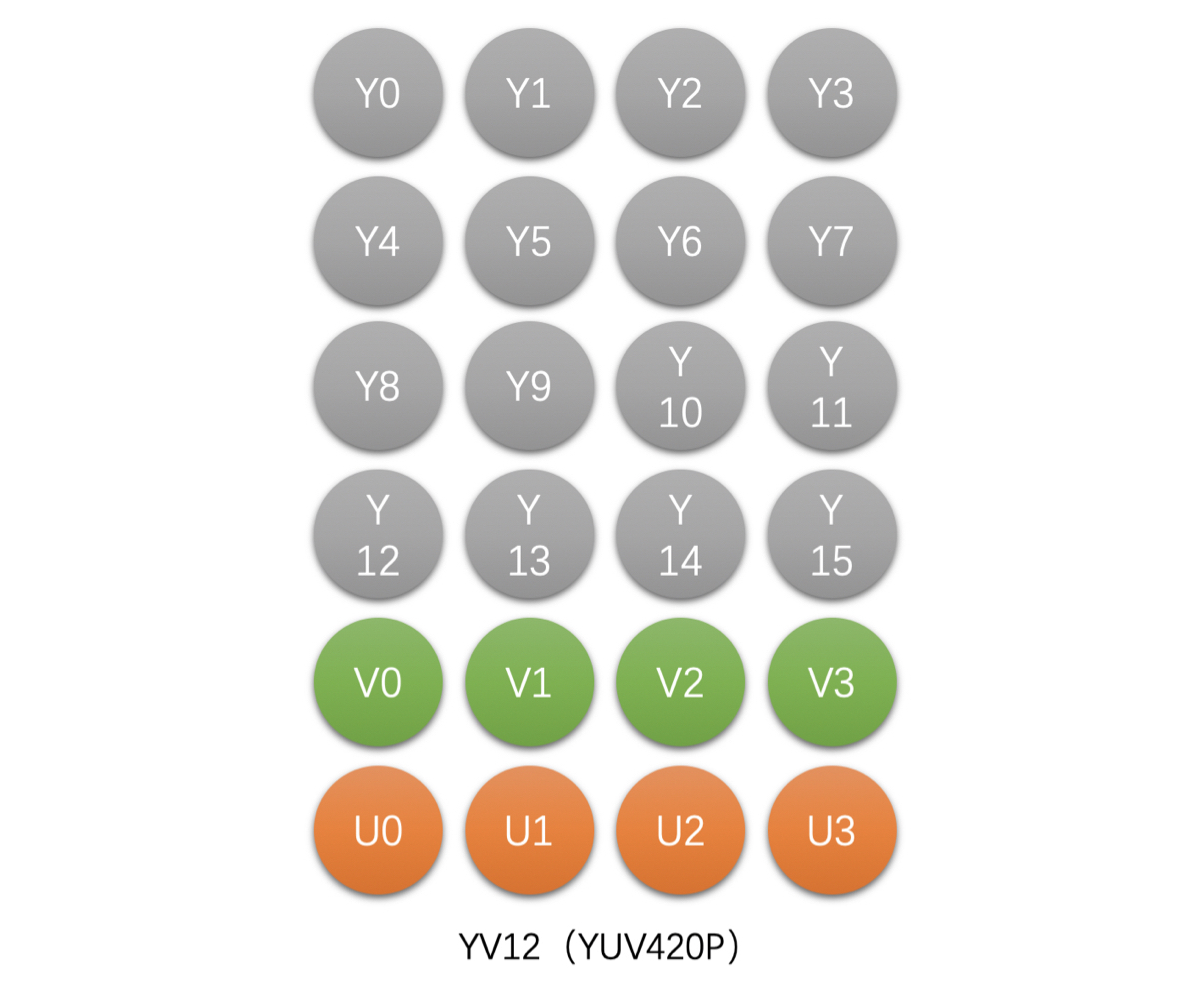
- YV12(YUV420P),Planar 格式
- 如 4x4 像素的 YV12 存储
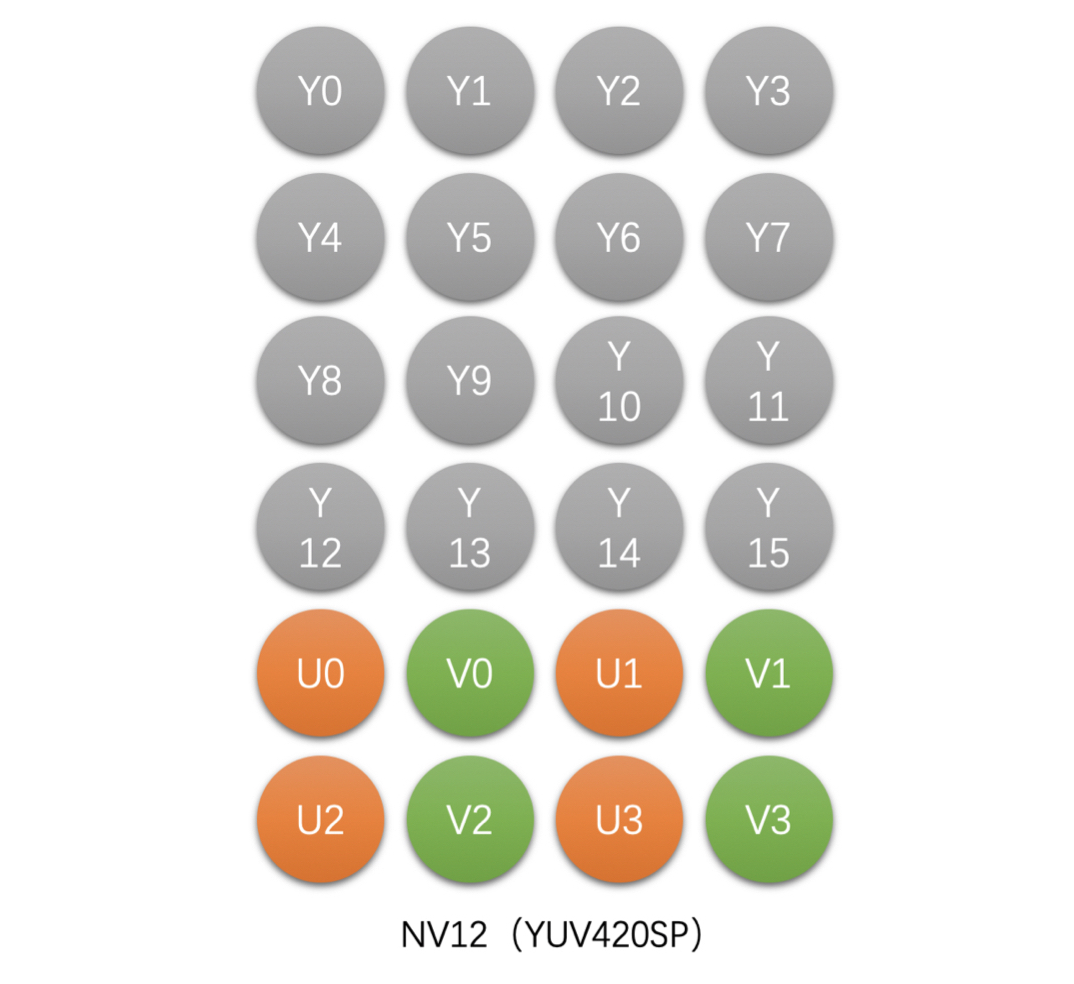
- NV12(YUV420SP),Packed 格式
- 如 4x4 像素的 NV12 存储
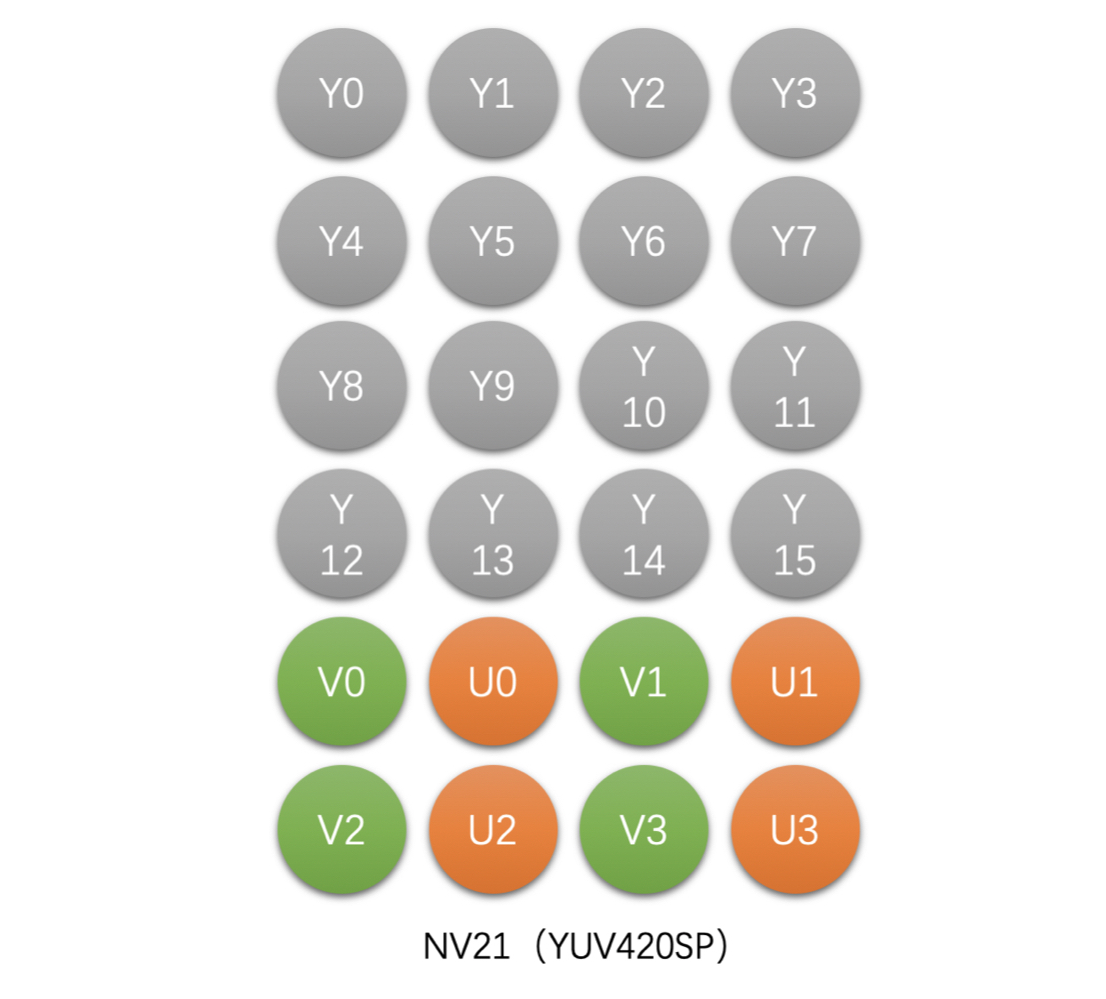
- NV21(YUV420SP),Packed 格式
- 如 4x4 像素的 NV21 存储
YUV 类型 | 存储类型 | |
|---|---|---|
YUV 4:4:4 | I444 | |
YV24 | ||
YUV 4:2:2 | Packed | NV16 |
NV61 | ||
Planar | YU16 | |
YV16 | ||
YUV 4:2:0 | Packed | NV12 |
NV21 | ||
Planar | YU12 | |
YV12 | ||
# RGB 与 YUV 的转换
Color Range
对于一个 8bit 的 RGB 图像,它的每一个 R、G、B 分量的取值理论是 0~255 的。但是真的是这样的吗?其实不是的。这里就涉及到 Color Range 这个概念。Color Range 分为 Full Range 和 Limited Range。Full Range 的 R、G、B 取值范围都是 0 ~ 255。而 Limited Range 的 R、G、B 取值范围是 16 ~ 235。
BT709 和 BT601 定义了一个 RGB 和 YUV 互转的标准规范,BT601 是标清的标准,而 BT709 是高清的标准。

每种标准下不同 Color Range 的转换公式是不同的,在做 RGB 往 YUV 转换的时候需要知道是使用的哪个标准的哪种 Range 做的转换,并告知对方。这样对方使用同样的标准和 Range 才可以正确的将 YUV 转换到 RGB。
# 图像缩放算法
# 缩放的基本原理
图像的缩放就是将原图像的已有像素经过加权运算得到目标图像的目标像素。
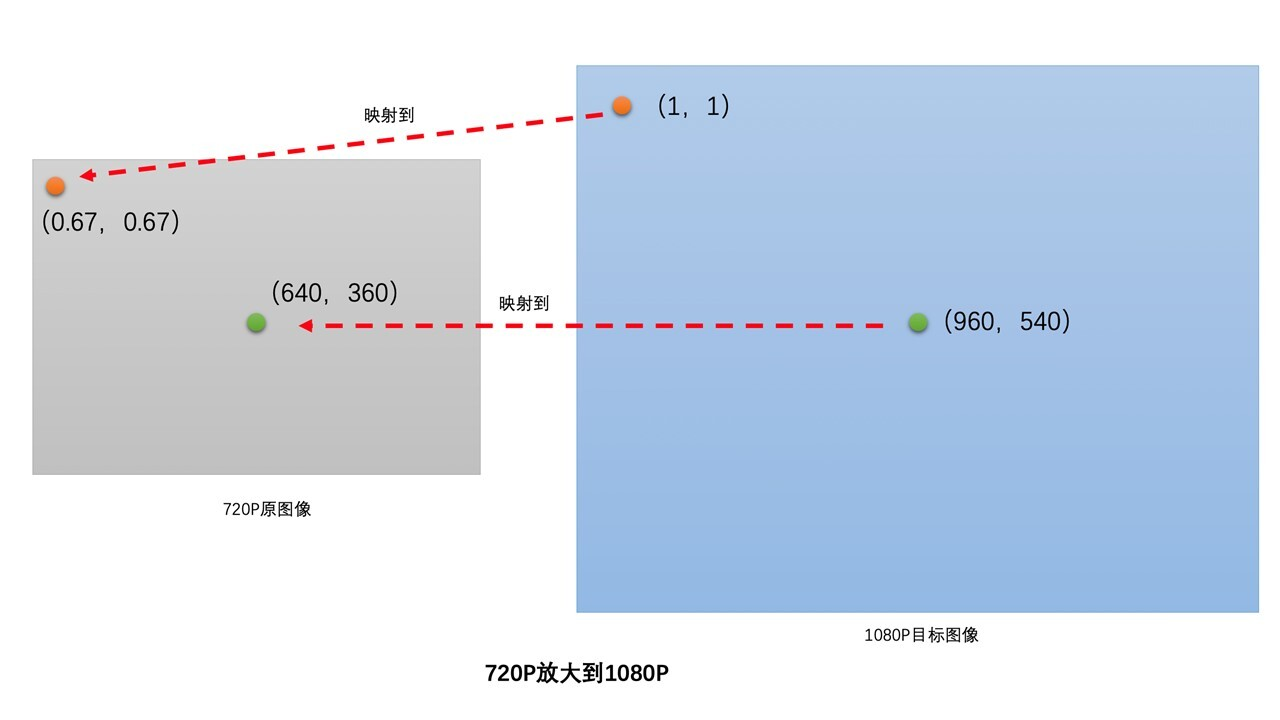
比如,已有图像是 720P 的分辨率,称为原图像,需要放大到 1080P,称 1080P 图像是目标图像。目标图像在宽度方向上放大了 1920 / 1280 = 1.5 倍,高度方向上也放大了 1080 / 720 = 1.5 倍。
那怎么通过 720P 的原图像生成 1080P 的目标图像呢?先将目标图像的像素位置映射到原图像的对应位置上,然后把通过插值计算得到的原图像对应位置的像素值作为目标图像相应位置的像素值。
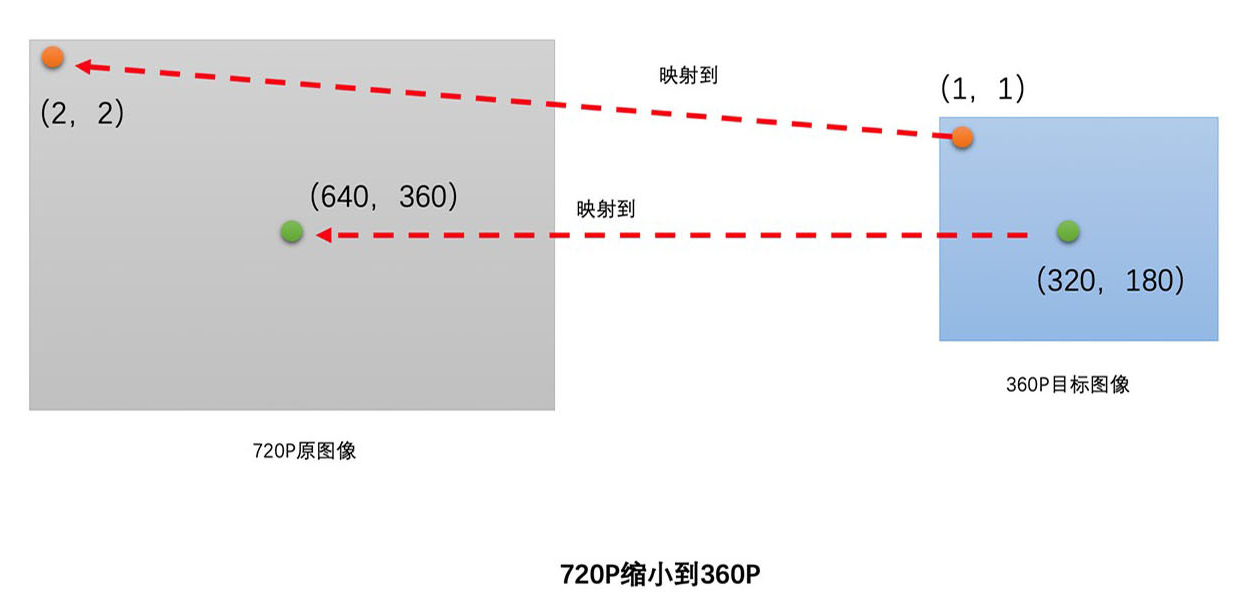
同样的以 720P 作为原图像,那么 720P 缩小到目标图像 360P 的过程也是类似于图像放大的过程的。
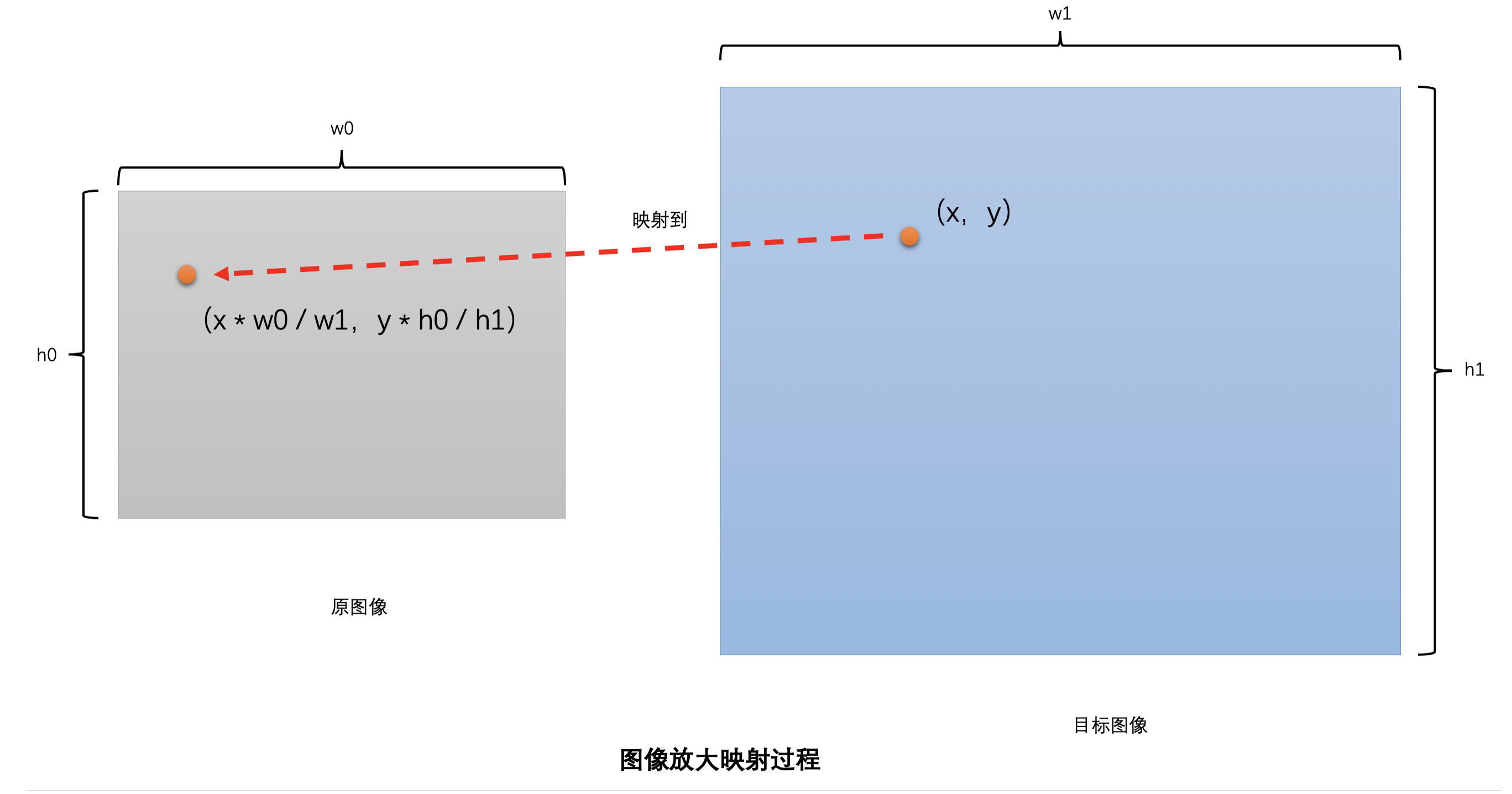
使用更通用的表达式表示:假设原图像的分辨率是 w0 x h0,需要缩放到 w1 x h1。那只需要将目标图像中的像素位置(x,y)映射到原图像的(x * w0 / w1,y * h0 / h1),再插值得到这个像素值就可以了,这个插值得到的像素值就是目标图像像素点(x,y)的像素值。注意,(x* w0 / w1,y * h0 / h1)绝大多数时候是小数。这就是图像缩放算法原理的通用表达。
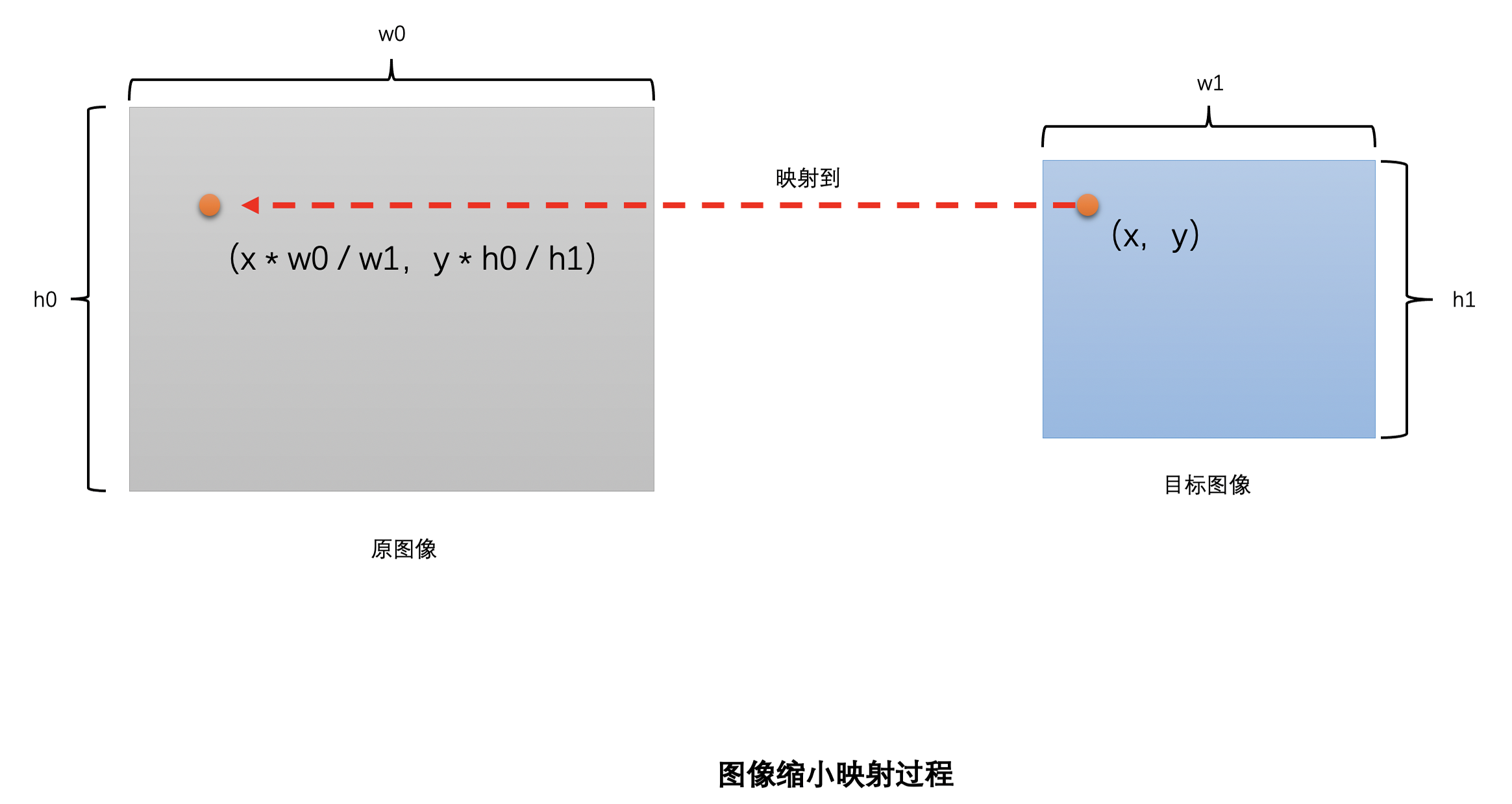
# 最近邻插值算法
- 原理
- 将目标图像中的目标像素位置,映射到原图像的映射位置
- 找到原图像中映射位置周围的 4 个像素
- 取离映射位置最近的像素点的像素值作为目标像素
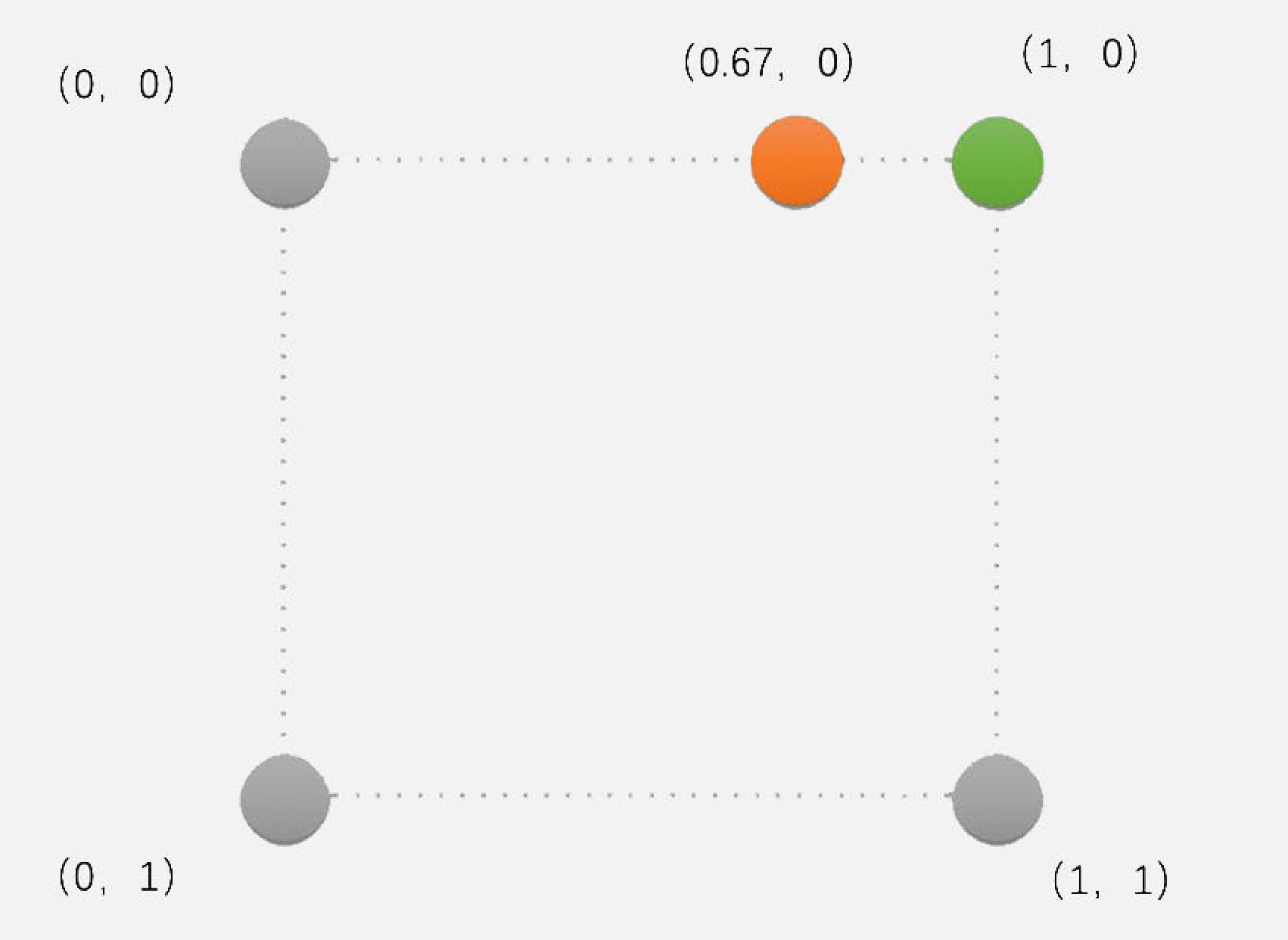
- 优点
- 计算简单,处理速度快
- 缺点
- 直接使用离插值位置最近的整数位置的像素作为插值像素,这样会导致相邻两个插值像素有很大的概率是相同的
- 放大图像大概率会出现块状效应,而缩小图像容易出现锯齿
# 双线性插值算法
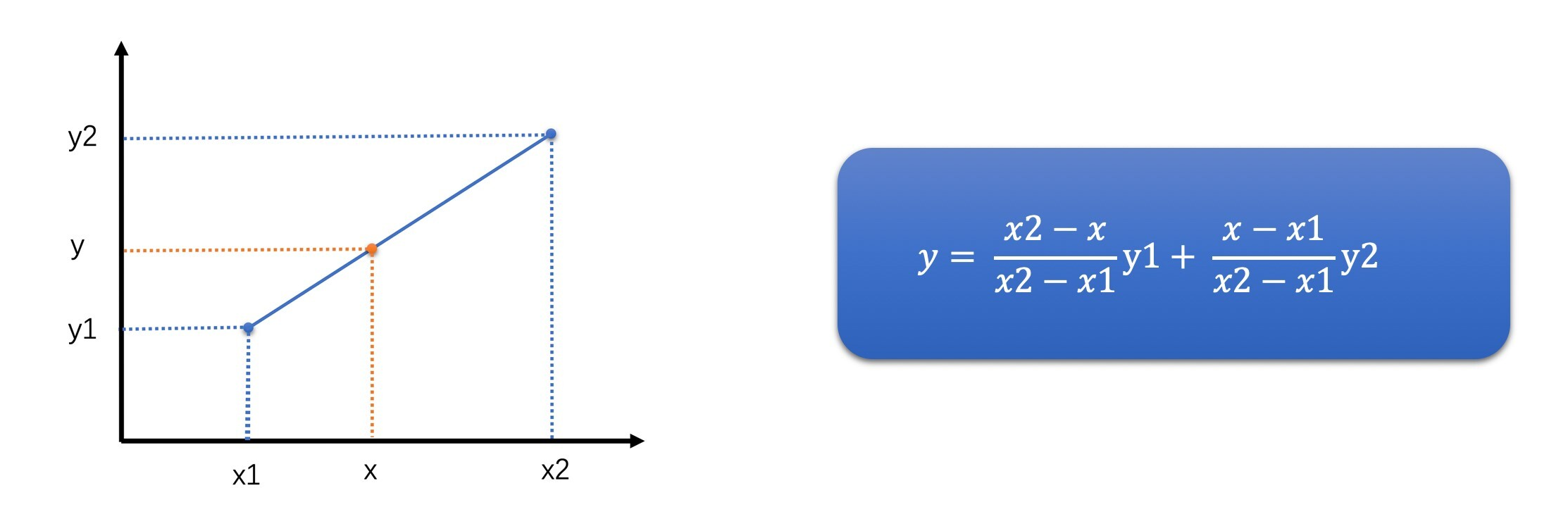
- 线性插值
- 线性插值是在两个点中间的某一个位置插值得到一个新的值
- 线性插值认为,这个需要插值得到的点跟这两个已知点都有一定的关系,并且,待插值点与离它近的那个点更相似
- 线性插值是一种以距离作为权重的插值方式,距离越近权重越大,距离越远权重越小
- 双线性插值
- 双线性插值本质上就是在两个方向上做线性插值
- 双线性插值其实就是三次线性插值的过程,先通过两次线性插值得到两个中间值,然后再通过对这两个中间值进行一次插值得到最终的结果
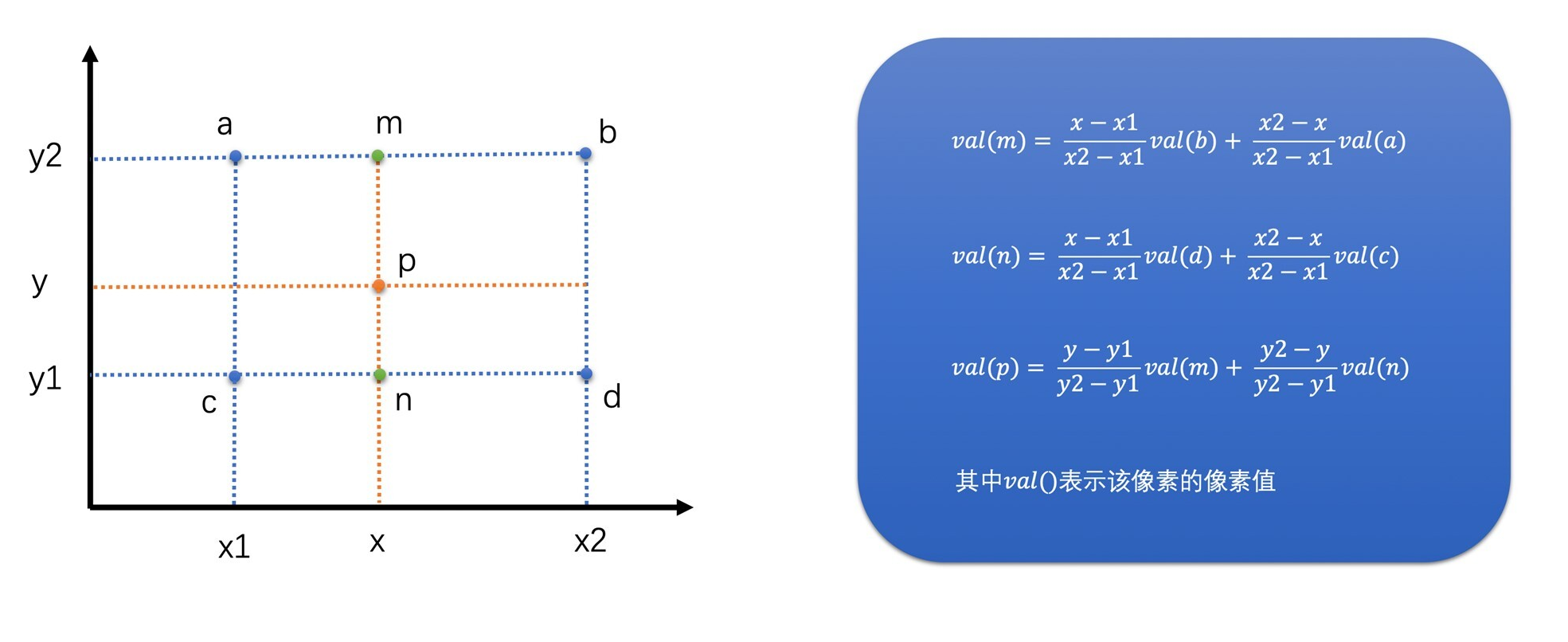
- 示例:是以 720P 放大到 1080P 为例,计算 1080P 图像中的目标像素点(2,2)的双线性插值
- 首先,将目标像素点(2,2)映射到原图像的(1.33,1.33)位置,对应下面图中的点 p
- 然后找到(1.33,1.33)周围的 4 个像素(1,1)、(2,1)、(1,2)和(2,2),分别对应图中的点a、b、c和d
- 再通过这 4 个像素插值得到中间像素 m 和 n 的像素值。m 和 n 的坐标分别为(1.33,1)和(1.33,2)
- 最后,通过上面的公式可以求得点 p(1.33,1.33)的像素值
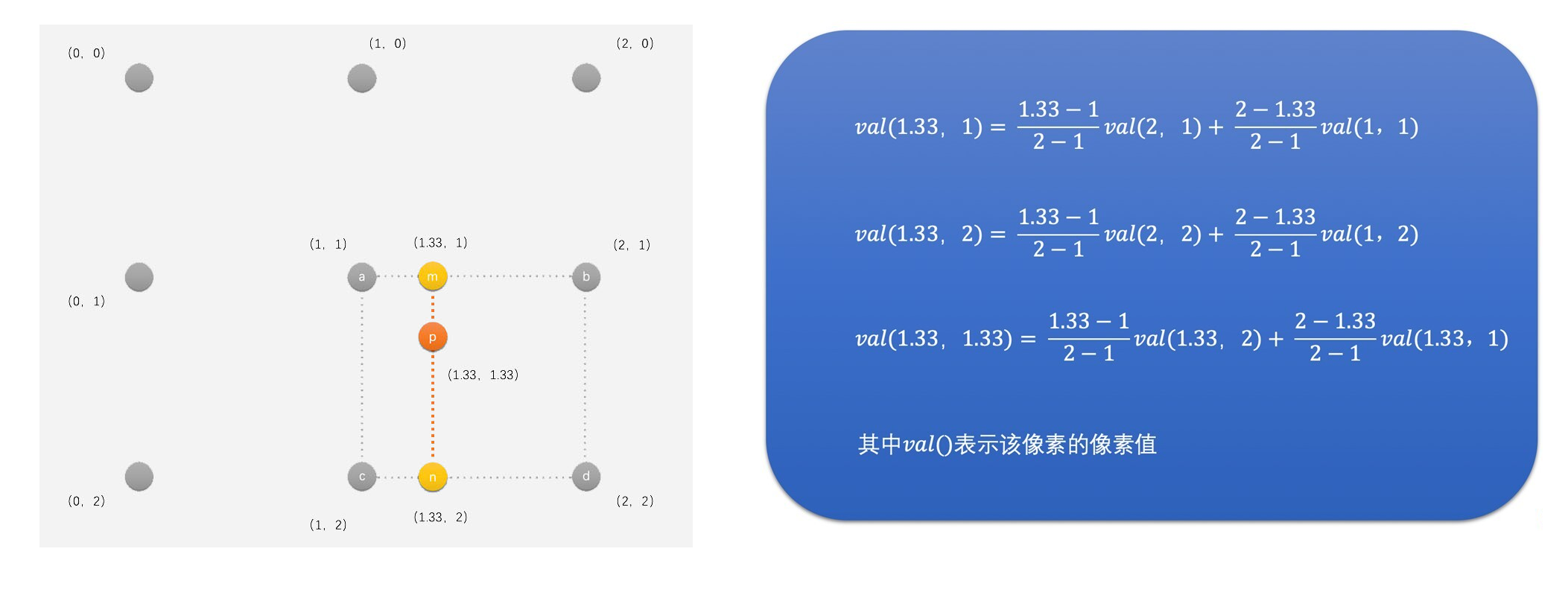
- 双线性插值相比最近邻插值运算要多一些,因此运行时间要长一些,但是相比而言,插值之后图像效果会好于最近邻插值
# 双三次插值算法
- 原理
- 双三次插值算法和之前两种插值算法差不多,不同的是:
- 双三次插值选取的是周围的 16 个像素,比前两种插值算法多了 3 倍
- 双三次插值算法的周围像素的权重计算是使用一个特殊的 BiCubic 基函数来计算

- 双三次插值算法和之前两种插值算法差不多,不同的是:
- 计算过程:
- 双三次插值的权重值是分水平和垂直两个方向分别求得的
- 对于周围 16 个点中的每一个点,其坐标值为(x,y),而目标图像中的目标像素在原图像中的映射坐标为 p(u,v)
- 通过上面公式可以求得其水平权重 W(u - x),垂直权重 W(v - y),将 W(u - x)乘以 W(v - y)得到最终权重值,然后再用最终权重值乘以该点的像素值,并对 16 个点分别做同样的操作并求和,就得到待插值的像素值了

- 示例:以 720P 放大到 1080P 为例,计算 1080P 图像中的目标像素点(2,2)的双三 次插值
- 首先,将目标像素点(2,2)映射到原图像的(1.33,1.33)位置,对应下面图中的点 p,找到(1.33,1.33)周围的 16 个像素(0,0)、(1,0)一直到(3,3)
- 然后,通过 BiCubic 函数求得每一个点的水平和垂直权重
- 求出这 16 个点的水平和垂直权重,两者相乘得到最终的权重值,之后每一个像素用自己的最终权重乘以自己的像素值再求和就是(1.33,1.33)的插值像素值

三种算法对比
双三次插值需要计算 16 个点的权重再乘以像素值求和,相较于前面的最近邻插值和双线性插值计算量较大,但插值后的图像效果最好。

插值算法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
最近邻插值 | 取待插值周围 4 个像素点中距离最近的像素值 | 计算量小,速度快 | 图像效果不好,容易产生锯齿 |
双线性插值 | 先通过在周围 4 个像素水平线性插值得到中间像素,再对中间像素垂直线性插值得到待插值像素值 | 效果比邻近插值好 | 速度比邻近插值慢 |
双三次插值 | 通过周围 16 个像素点求得各个水平和垂直权重,将水平和垂直权重相乘得到最终权重,将 16 个点按自己的权重加权求和得到待插值像素值 | 图像效果最好 | 计算量最大,速度最慢 |
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2021/12/6,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号