ChatGLM2 源码解析:`MLP`

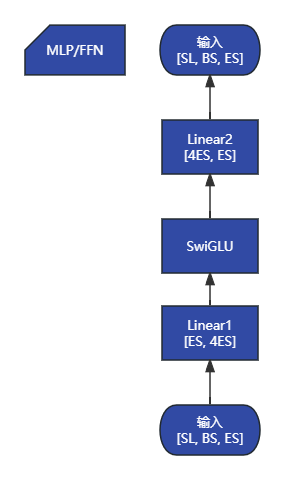
class MLP(torch.nn.Module):
"""MLP.
MLP will take the input with h hidden state, project it to 4*h
hidden dimension, perform nonlinear transformation, and project the
state back into h hidden dimension.
"""
def __init__(self, config: ChatGLMConfig, device=None):
super(MLP, self).__init__()
self.add_bias = config.add_bias_linear
# Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
# LL1,最后一维 ES => 4ES
self.dense_h_to_4h = nn.Linear(
config.hidden_size,
config.ffn_hidden_size * 2,
bias=self.add_bias,
device=device,
**_config_to_kwargs(config)
)
def swiglu(x):
x = torch.chunk(x, 2, dim=-1)
return F.silu(x[0]) * x[1]
self.activation_func = swiglu
# LL2,最后一维 4ES => ES
self.dense_4h_to_h = nn.Linear(
config.ffn_hidden_size,
config.hidden_size,
bias=self.add_bias,
device=device,
**_config_to_kwargs(config)
)
def forward(self, hidden_states):
# 输入 -> LL1 -> swiglu -> LL2 -> 输出
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = self.activation_func(intermediate_parallel)
output = self.dense_4h_to_h(intermediate_parallel)
return output本文参与 腾讯云自媒体分享计划,分享自作者个人站点/博客。
原始发表:2023-10-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读