MySQL 不同存储引擎下 count(星) count(1) count(field) 结果集和性能上的差异,不要再听网上乱说了
原创
MySQL 不同存储引擎下 count(星) count(1) count(field) 结果集和性能上的差异,不要再听网上乱说了
原创
Lorin 洛林
修改于 2023-11-19 22:06:35
修改于 2023-11-19 22:06:35
前言
- hello,大家好,我是 Lorin,不知道大家面试或者日常使用中是不是经常遇到这个问题,count(*)、count(1)、count(field) 执行结果集有什么区别?性能上有差异,今天我将从官网文档、实践、原理三个方面来分享三者的区别,废话不多说,开始发车:

认真听课.png
前期准备
- MySQL 版本:5.7.36-log
SELECT VERSION();- 我们先建一个测试用的 student 表,并插入 10 条测试数据
- 我们实际开发中使用主要是 InnoDB,偶尔使用 MyISAM 因此下面重点分析一下两种存储引擎的表现。
InnoDB
CREATE TABLE `student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(2) DEFAULT NULL,
`class_no` varchar(50) DEFAULT NULL COMMENT '班级号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米', 18, 2);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米1', 18, 2);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米2', 18, 2);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米3', 18, 2);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米4', 18, "");
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米5', 18, NULL);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米6', 18, NULL);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米7', 18, NULL);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米8', 18, NULL);
INSERT INTO `test`.`student` (`name`, `age`, `class_no`) VALUES ('小米9', 18, NULL);MyISAM
CREATE TABLE `student_myisam` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(2) DEFAULT NULL,
`class_no` varchar(50) DEFAULT NULL COMMENT '班级号',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米', 18, 2);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米1', 18, 2);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米2', 18, 2);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米3', 18, 2);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米4', 18, "");
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米5', 18, NULL);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米6', 18, NULL);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米7', 18, NULL);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米8', 18, NULL);
INSERT INTO `test`.`student_myisam` (`name`, `age`, `class_no`) VALUES ('小米9', 18, NULL);结果集的差异
- 实际上可以理解 count(*)、count(1)、count(field) 为上层的标准结果,不同存储引擎的底层实现方式可以不相同,但是结果是一样的,因此主要比较三种查询方式查询结果。
InnoDB vs MyISAM
count(field)
- 我们看看一下官方的说明:
COUNT(expr) [over_clause]
Returns a count of the number of non-NULL values of expr in the rows retrieved by a SELECT statement. The result is a BIGINT value.
If there are no matching rows, COUNT() returns 0. COUNT(NULL) returns 0.
统计返回非NULL行的行数,返回结果是一个BIGINT类型。
如果没有匹配行, COUNT() 返回 0. COUNT(NULL) 返回 0.- 实践
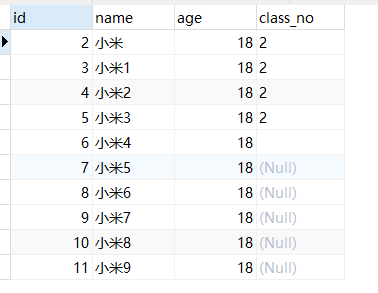
// 返回不为 null 的行 预期结果 5 行
SELECT COUNT(class_no) FROM student;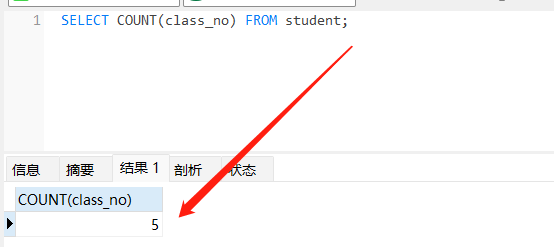
count(*)、count(1)、count(2)...count(n)
- count(*) 和 count(1)、count(2)...count(n) 语义上略有区别,但它们的执行结果集一致。
- 先看一下官方说明
COUNT(*) is somewhat different in that it returns a count of the number of rows retrieved, whether or not they contain NULL values.
For transactional storage engines such as InnoDB, storing an exact row count is problematic. Multiple transactions may be occurring at the same time, each of which may affect the count.
InnoDB does not keep an internal count of rows in a table because concurrent transactions might “see” different numbers of rows at the same time. Consequently, SELECT COUNT(*) statements only count rows visible to the current transacti
COUNT(*)有些不同,因为它返回检索到的行数的计数,无论它们是否包含NULL值。
对于InnoDB这样的事务性存储引擎,存储精确的行数是有问题的。多个事务可能同时发生,每个事务都可能影响计数。
InnoDB不保留表的内部行数,因为并发事务可能同时看到不同的行数。因此,SELECT COUNT(*)语句只对当前事务可见的行进行计数。- 实践
// 总行数 10 行 预期返回 10
SELECT COUNT(*) FROM student;
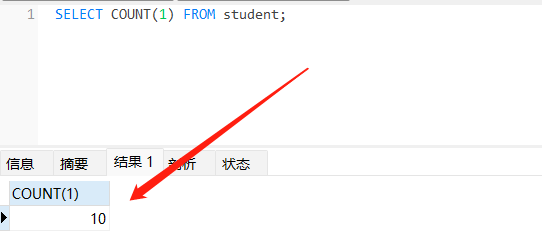
SELECT COUNT(1) FROM student;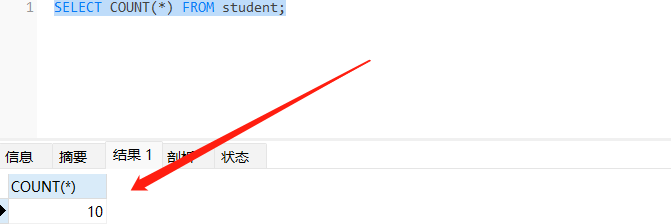
性能上的差异
- 上面我们聊完了结果集上的差异,下面我们来看看性能、SQL 语句底层运行上的差异。
InnoDB
count(field)
- 当前列如果有索引,则使用索引进行计数,如果没有索引则进行全表扫描。
- 实践
// 没有索引 进行全表扫描
explain SELECT COUNT(class_no) FROM student;
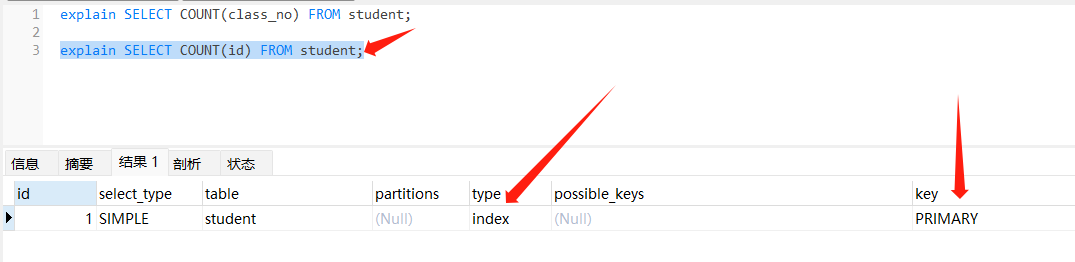
// 有索引 使用索引进行计数
explain SELECT COUNT(id) FROM student;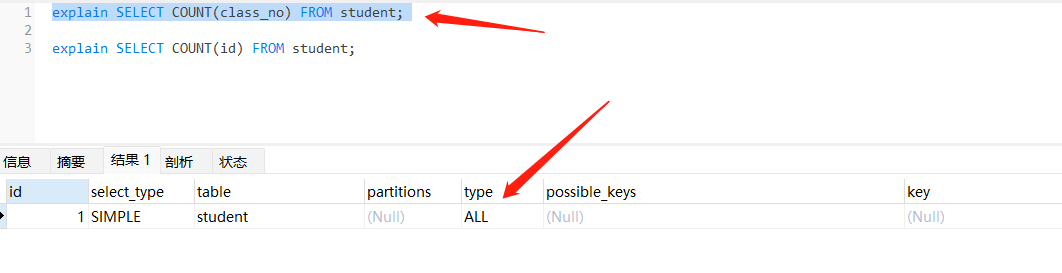
count(*)、count(1)、count(2)...count(n)
- 先看一下官网说明:
InnoDB processes SELECT COUNT(*) statements by traversing the smallest available secondary index unless an index or optimizer hint directs the optimizer to use a different index.
If a secondary index is not present, InnoDB processes SELECT COUNT(*) statements by scanning the clustered index.
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
大致的意思是说,优先遍历最小的可用二级索引来进行计数,除非查询优化器提示使用不同索引。如果二级索引不存在,则扫描聚簇索引处理。
InnoDB 使用相同的方式处理 count(*)、count(1)、count(2)...count(n)- 实践
无可用二级索引
// 无最小可用二级索引 因为只有主键聚簇索引 使用聚簇索引计数
explain SELECT COUNT(1) FROM student;
explain SELECT COUNT(*) FROM student;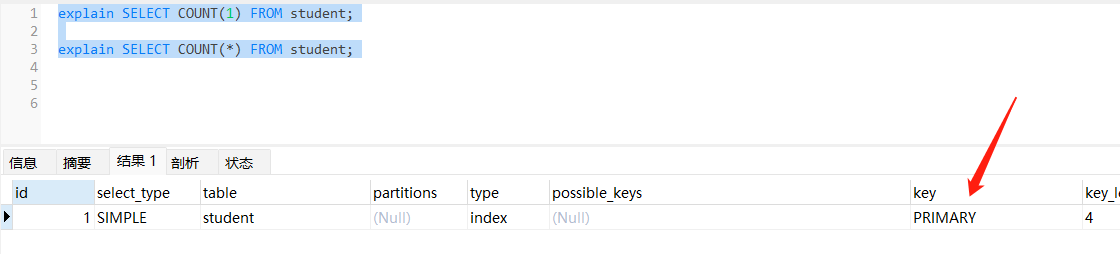
存在可用二级索引
- 为了满足这个条件我们在原有的表上新增一个字段,并建立一个二级索引,存在二级索引的情况下,使用二级索引进行计数;若存在多个二级索引选择二级索引中的最小索引。
注:实际使用中不要在这种区分度比较的字段上加索引 基本没有意义
ALTER TABLE student ADD COLUMN `sex` int(2) NOT NULL COMMENT '1 - 男 2 -女';
ALTER TABLE student ADD INDEX sex_indx (sex);
// 再次执行 上面两条语句 使用sex_indx计数
explain SELECT COUNT(1) FROM student;
explain SELECT COUNT(*) FROM student;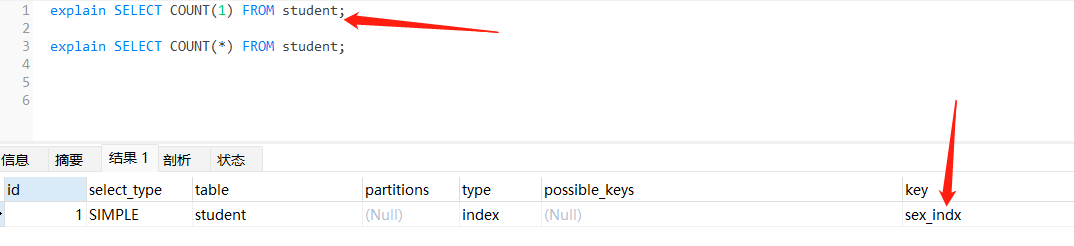
MyISAM
count(field)
- 当前列如果有索引,则使用索引进行计数,如果没有索引则进行全表扫描。
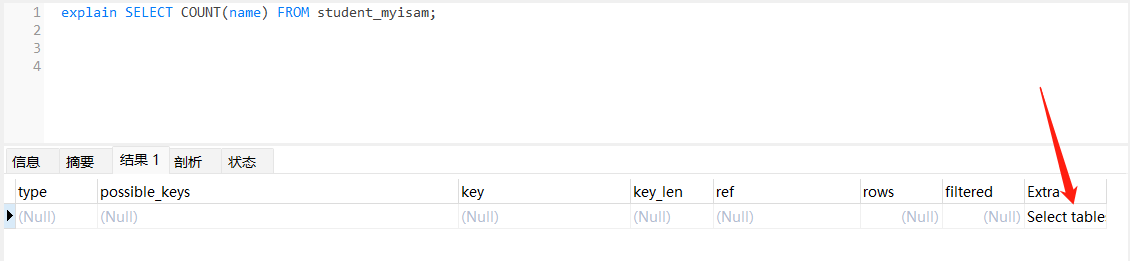
- 命中下文特殊优化规则除外:即对应的列不为 NULL 则直接查询表的统计信息获取。
// 无索引且未命中特殊优化规则 使用全表扫描
explain SELECT COUNT(class_no) FROM student_myisam;
// 命中特殊规则 name 不为 NULL
explain SELECT COUNT(name) FROM student_myisam;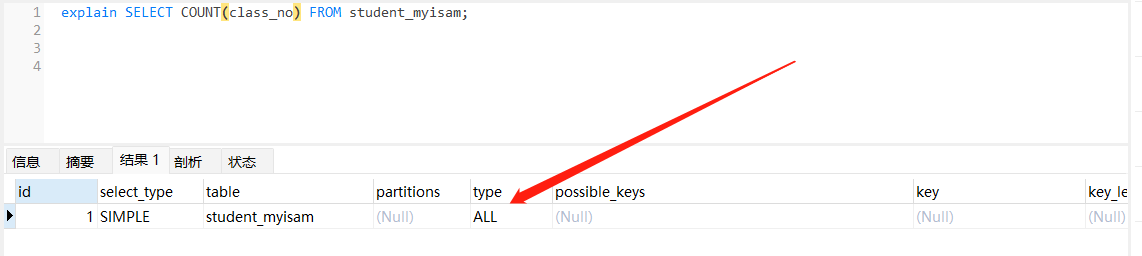
count(*)、count(1)、count(2)...count(n)
- 直接查询表统计信息获取。
MyISAM 中的特殊优化
For MyISAM tables, COUNT(*) is optimized to return very quickly if the SELECT retrieves from one table,
no other columns are retrieved, and there is no WHERE clause. For example:
mysql> SELECT COUNT(*) FROM student;
This optimization only applies to MyISAM tables, because an exact row count is stored for this storage engine and can be accessed very quickly.
COUNT(1) is only subject to the same optimization if the first column is defined as NOT NULL.
大致的意思是说,对于使用 MyISAM 存储引擎的表,如果一个COUNT(*) COUNT(n) 没有其它查询条件,或COUNT(field) 对应的列不为 NULL,则会很快返回计数结果。
其实这是因为 MyISAM 表的统计信息中有表的实际行数统计信息。不同于InnoDB中的字段只是一个估计值。总结
- 上文中讨论了一些 count 函数的一些表现,并没有涉及 where 条件的使用,因为一旦引入 where 条件就会引入多个字段和多个字段的索引进行成本分析:
- 上面的规则虽然看着很多,但实际上结合结果集和MySQL底层索引的实现很好理解,比如:
// 首先我们需要基本记住的是:
count(*) count(n) 查询的是所有的数据。
count(field) 查询的是 field 列不为 NULL 的数据。
以 InnoDB 引擎为例:
如果我使用 SELECT COUNT(*) FROM student
说明我需要查询表中所有的行数,如何最快的查出,毫无疑问当然是走索引,但是由于存在二级索引时只能选择二级索引最小的一个索引(索引更小产生的IO次数就更小):
CREATE TABLE `student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(12) DEFAULT NULL,
`class_no` varchar(50) DEFAULT NULL COMMENT '班级号',
`sex` bigint(20) NOT NULL COMMENT '1 - 男 2 -女',
PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4;
// 当仅有主键索引时 使用主键索引
CREATE TABLE `student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(12) DEFAULT NULL,
`class_no` varchar(50) DEFAULT NULL COMMENT '班级号',
`sex` bigint(20) NOT NULL COMMENT '1 - 男 2 -女',
PRIMARY KEY (`id`),
KEY `sex_indx` (`sex`) USING BTREE,
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4;
// 当存在二级索引时 使用二级索引
CREATE TABLE `student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(12) DEFAULT NULL,
`class_no` varchar(50) DEFAULT NULL COMMENT '班级号',
`sex` bigint(20) NOT NULL COMMENT '1 - 男 2 -女',
PRIMARY KEY (`id`),
KEY `sex_indx` (`sex`) USING BTREE,
KEY `age_index` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4;
// 当存在多个二级索引时,使用索引大小更小的索引
如果使用 SELECT COUNT(field) FROM student
因为需要查询出字段每一行是否为 NULL,所有只能使用该列的索引,若无索引,则进行全表扫描。一些实践建议
尽量不要使用 COUNT 函数
- InnoDB 下无论是哪个 count 函数性能都比较低,如果对数据准确度要求不是很高可以使用表统计中的估计值;如有准确度要求,可以考虑单独使用表统计。
不要使用 COUNT(n) 代替 count(*)
- COUNT(*)是SQL92定义的标准统计行数的语法,COUNT(n)则是非标准语法,可能存在兼容性问题。
参考
个人简介
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
🚀 我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。
🧠 作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。
💡 在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。
🌐 我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。
📖 保持关注我的博客,让我们共同追求技术卓越。
我正在参与2023腾讯技术创作特训营第三期有奖征文,组队打卡瓜分大奖!
“邀请人:“繁依Fanyi”
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
