初探linux 革命性技术eBPF
原创

在排查网络问题与深入了解网络协议的工作原理的时候,sre最常使用tcpdump。但是实际上tcpdump只能告诉你网络上传输了哪些包,没有体现为什么这么传输,在排查网络丢包问题的时候是存在一定的局限性的。这时候就需要依赖BCC这个工具来深入地排查网络的问题了。(对于tcpdump与bcc的使用后续可以单独介绍)。
实际上tcpdump与bcc能够很高效与强大,都是得益于eBPF技术。
微服务潮流下linux内核的问题
在介绍eBPF之前,我们先来看下微服务潮流下linux内核的问题。
一,抽象
在另外一一篇文章<<Linux网络简介>>中我们介绍linux网络最后提及到linux网络相关的抽象
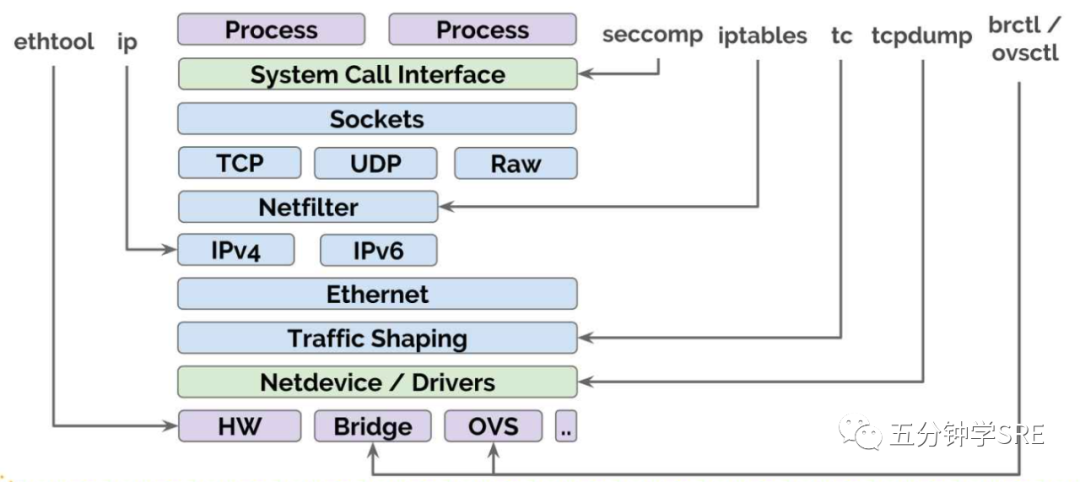
因为每个抽象模块都有自己的api,在做自动化工具的时候,就必须去了解每一层的工作原理以及对应的api,会带来几个问题:
- 巨大的性能开销(massive performance overhead)
- 很难绕过(bypass)这些层:虽然有一些场景可以做到 bypass,但大部分都是 bypass 不掉的。
二,Linux感知不到容器
内核知道的是:
进程和线程
cgroups
Namespaces
IP 地址和端口号
系统调用和 SELinux 上下文Cgroups是一个逻辑结构,sre可以将一个进程关联到一个group,然后指定该group的资源限制,例如:group可以使用的CPU,内存,IOPS等。
Namespace是一种隔离技术,例如给上面的group的进程指定namespace限制的虚拟地址空间,使得该group只能看到这个namespace的进程。网络 namespace 的网络设备只能看到这个 namespace 内的网络设备。
内核知道IP地址与系统调用,因此应用发起系统调用时,内核可以对它进行跟踪和过滤。内核还知道 SELinux 上下文,因此有过滤网络安全相关的功能,例如控制进程是否/如何与 其他进程通信。
内核不知道的是:
容器或 K8S pods
暴露(到宿主机外面)的需求
容器/Pods 之间的 API 调用
service mesh内核无法感觉到(作为一个整体的)容器:我们可以在cgroup文件中找到容器的ID,但内核本身并不知道容器是什么,内核看到的是sgroups里面的namespace。
内核理解应用是否需要暴露给外部。在多任务时代,内核其实知道一个应用绑定了哪个 IP 和 port,以及是否对外暴露。例如如果一个 web server 运行在 localhost 的 80 端口,内核就理解它不应该被暴露到外部。在容器时代,内核已经不清楚什么应该被暴露, 什么不应该被暴露了。
另外一个大问题:以前通过 IPC 或 Linux domain socket pipe 方式的通信,现在换成 REST、GRPC 等方式了。内核无法感知到后者。
内核知道的仅仅是网络包、端口号等, 内核会知道:“嘿,这里有一个进程,它监听在 80 端口,运行在自己的 namespace 内。” 除此之外的(更上层)东西,内核就不知道了,例如跑在这个端口上的是什么服务。在之前,内核还知道这是一个正在通过 IPC 和其他进程通信的进程,这种情况是简单的进 程到进程、服务到服务通信。而 service mesh —— 我不知道在座有多少人正在关注 service mesh—— 内核无法感知到 service mesh。很多东西都是内核不知道的。
什么是eBPF
eBPF 是一个解决所有这些问题的方案
eBPF全称为拓展的伯克利数据包过滤器(Extended Berkeley Packet Filter),是一种数据包过滤技术。eBPF 的概念最早源自于 BSD 操作系统中的 BPF(Berkeley Packet Filter),1992 伯克利实验室的一篇论文 “The BSD Packet Filter: A New Architecture for User-level Packet Capture”。这篇论文描述了,BPF 是如何更加高效灵活地从操作系统内核中抓取网络数据包的。
BPF 提供了一种在内核事件和用户程序事件发生时安全注入代码的机制, 是 Linux 内核中的一个高性能沙盒虚拟机(sandbox virtual machine),它将内 核变成了可编程的(programmable)使得非内核开发人员也可以对内核进行控制。
随着内核的发展,BPF 逐步从最初的数据包过滤扩展到了网络、内核、安全、跟踪等,且功能特性还在快速发展中,这种扩展后的 BPF 被简称为 eBPF。
eBPF 则借助即时编译器(JIT:Just-In-Time),在内核中运行了一个虚拟机,保证只有被验证安全的 eBPF 指令才会被内核执行。同时,因为 eBPF 指令依然运行在内核中,无需向用户态复制数据,这就大大提高了事件处理的效率。
eBPF的工作原理
要理解 eBPF 首先要意识到:Linux 内核本质上是事件驱动的。
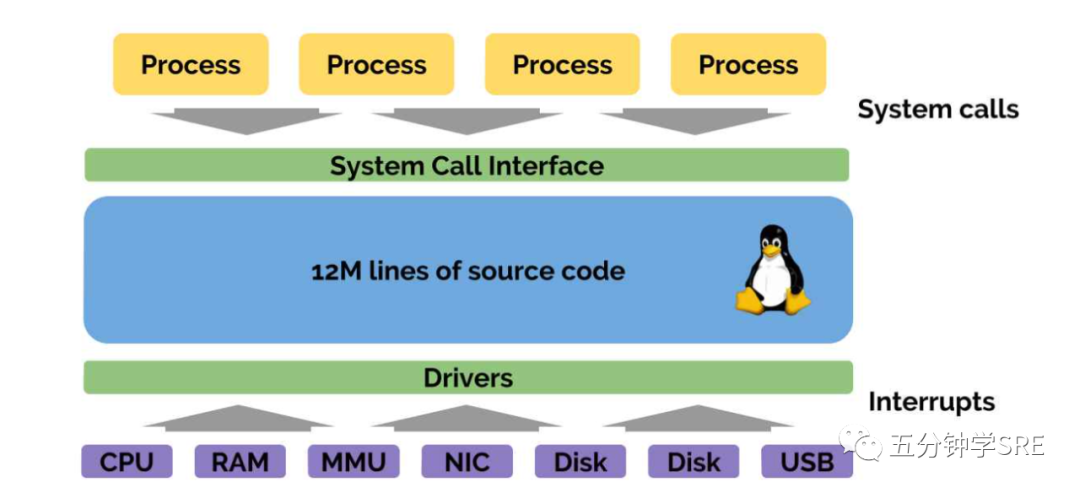
在图中最上面,有进程进行系统调用,它们会连接到其他应用,写数据到磁盘,读写 socket,请求定时器等等。这些都是事件驱动的。这些过程都是系统调用。
在图最下面,是硬件层。这些可以是真实的硬件,也可以是虚拟的硬件,它们会处理中断事 件,例如:“嗨,我收到了一个网络包”,“嗨,你在这个设备上请求的数据现在可以读了”, 等等。因此,内核所作的一切事情都是事件驱动的。
在图中间,是 12 million 行巨型单体应用(Linux Kernel)的代码,这些代码处理 各种事件。
eBPF 给我们提供了在事件发生时运行指定的 eBPF 程序的能力。
eBPF程序是在特定的事件被触发后才会执行,而不像常规线程启动后一直运行着。这些事件包括系统调用,内核跟踪点,内核函数和用户态函数的调用退出,网络事件等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF的程序几乎是可以在内核和应用的所有位置进行插桩运行。
例如,我们可以在以下事件发生时运行我们的 BPF 程序:
应用发起 read/write/connect 等系统调用
TCP 发生重传
网络包达到网卡eBPF的安全机制
为了保证一个eBPF程序的异常不会破坏整个内核的稳定性,Linux 对eBPF调用会有一定的校验规则。
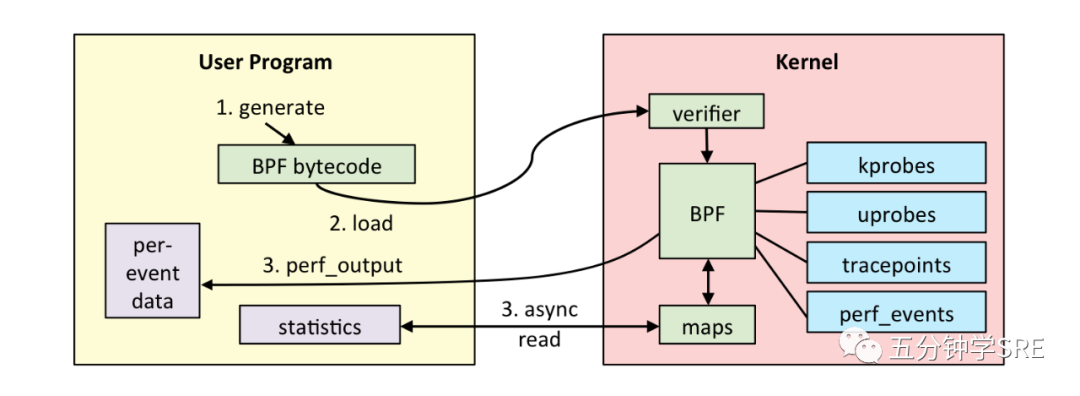
上面的图片是eBPF程序的执行流程。执行eBPF程序需要借助LLVM(LLVM 项目是模块化和可重用的编译器和工具链技术的集合,并不是首字母的缩写,LLVM是这个项目的全程)把编写的eBPF程序转化为BPF字节码,然后通过bpf系统调用提交给内核执行。内核在接受BPF字节码的之前,会先通过校验器对字节码进行校验,只有经过校验才会把BPF字节码提交到即时编译器执行。
如果 BPF 字节码被接受,那么它可以附加到不同的事件源:
kprobes:内核动态跟踪。
uprobes:用户级动态跟踪。
tracepoints:内核静态跟踪。
perf_events:定时采样和 PMC。校验器一些典型的验证过程:
只有特权进程才可以执行 bpf 系统调用;
BPF 程序不能包含无限循环;
BPF 程序不能导致内核崩溃;
BPF 程序必须在有限时间内完成。BPF 程序之间可以通信,使用 BPF maps 保存状态信息
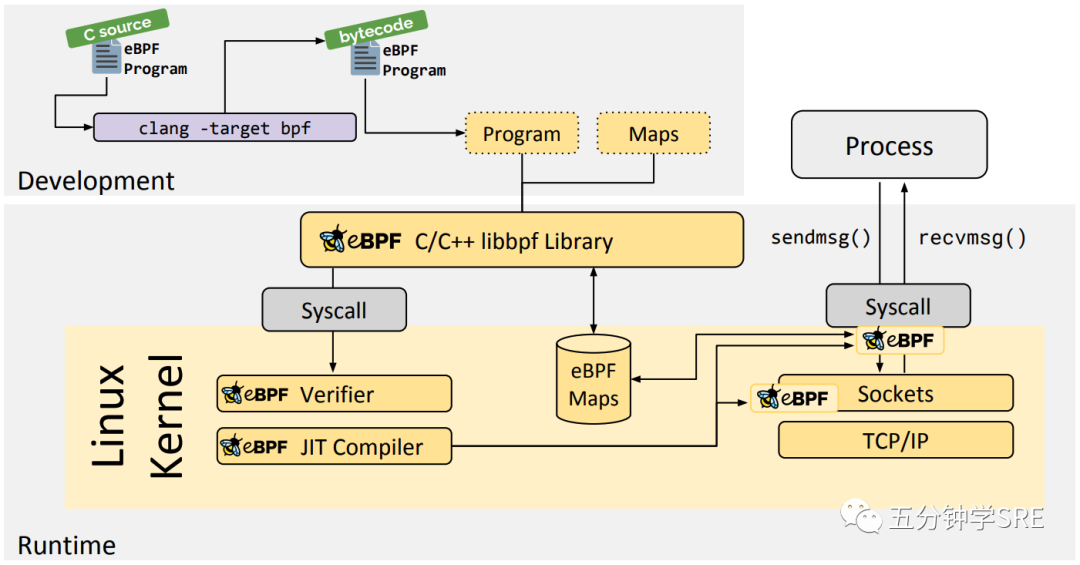
BPF程序可以使用BPF 映射(map)进行存储,BPF maps 数据可以通过 BPF 程序访问,也可以从用户空间访问。因此可以在 BPF 程序中向 BPF maps 写数据,然后从用户空间读取,例如导出一些采集数据。或者,可以将 配置信息写入 maps,然后从 BPF 程序读取配置。
BPF maps 支持哈希表、数组、LRU、Ring Buffer、Stack trace、LPM 等等。其中一些支持 per-CPU variant,性能更高。
eBPF的应用
eBPF 现如今已经在故障诊断、网络优化、安全控制、性能监控等领域获得大量应用。除了开头提到的tcpdump,bcc等小工具。还有:
Facebook 开源的高性能网络负载均衡器 Katran、和用 BPF 替换了 iptables 和 network filter
Google 已经开始用 BPF 做 profiling,找出在分布式系统中应用消耗多少 CPU。而且,他 们也开始将 BPF 的使用范围扩展到流量优化和网络安全。
Redhat 正在开发一个叫 bpffilter 的上游项目,将来会替换掉内核里的 iptables,也 就是说,内核里基于 iptables 做包过滤的功能,以后都会用 BPF 替换。另外还有一些论文 和项目,关于 XDP 和 BPF+NFV 的场景。
Isovalent 开源的容器网络方案 Cilium (设计解决上面提到的内核存在的问题)
以及著名的内核跟踪排错工具 BCC 和 bpftrace 等,都是基于 eBPF 技术实现的。下面这张图是eBPF的 技术概览
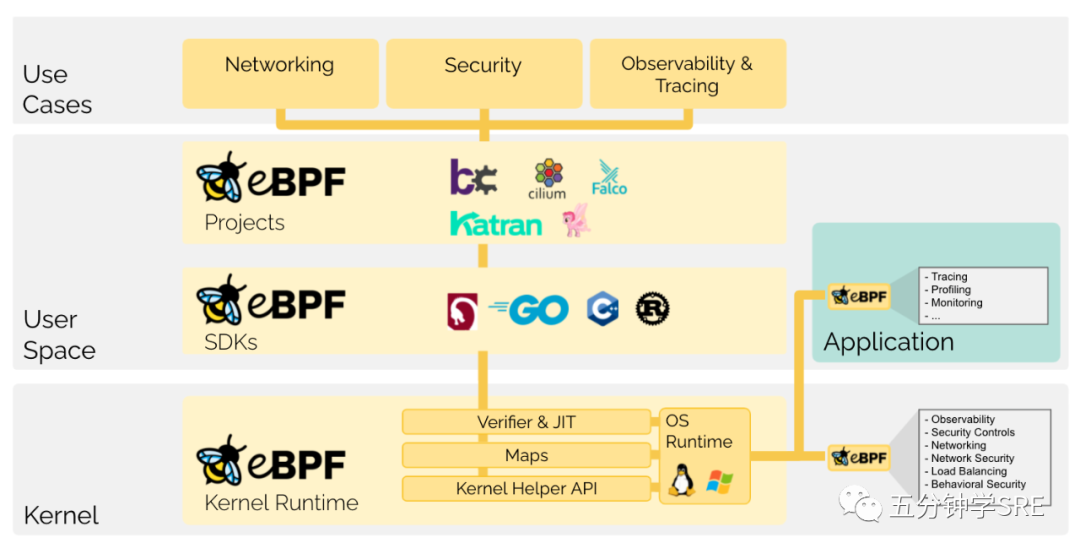
推荐与参考文章
https://www.infoq.com/presentations/linux-cilium-ebpf/(How to Make Linux Microservice-Aware with Cilium and eBPF)
极客时间:eBPF 核心技术与实战
https://ebpf.io/what-is-ebpf/(eBPF 官方文档)
可以查看原文:
关注公众号获取更多sre博文:五分钟学SRE
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
