Python 机器学习库入门实践
原创
为什么要选择 Python 进行机器学习入门,因为这个是最最直接的方式,大神吴恩达的教学也是使用 Python 进行机器学习的,那么 Python 机器学习常用的库有哪些呢?
背景补充
我接触过的,整理一下主要包括以下几种,并且每一种相关的简介也稍微说一说:
- Scikit-learn:这是最常用的通用机器学习库。它包括许多监督和无监督的学习算法,如分类、回归、聚类和降维。它还提供了一些用于预处理数据、评估模型和优化参数的工具。
- TensorFlow:这是一个用于深度学习的库,由Google开发。它提供了一个灵活的平台,用于设计和实施各种深度学习模型。
- Keras:这是一个用于深度学习的高级API,可以用TensorFlow、Theano或CNTK作为后端。它的目标是使深度学习模型的开发变得更快,更容易。
- PyTorch:这是一个由Facebook开发的深度学习库。它提供了一个灵活且直观的接口,使得实现复杂的深度学习模型变得更简单。
- Pandas:这是一个用于数据处理和分析的库。虽然它不是一个机器学习库,但是在机器学习项目中经常用到,因为它可以方便地处理和清洗数据。
- NumPy:这是一个用于数值计算的库。它提供了一些高级的数学函数和数据结构,如矩阵和多维数组,这在机器学习中非常有用。
- Matplotlib:这是一个用于数据可视化的库。在机器学习项目中,可视化是理解数据和模型性能的关键工具。
- SciPy:这是一个用于科学计算的库,它提供了很多用于优化、线性代数、积分和插值的函数,这些在机器学习中都有应用。
- XGBoost/LightGBM/CatBoost:这些都是用于梯度提升机(Gradient Boosting Machines)的库,它们在各种机器学习任务中都表现出色,特别是在处理结构化数据和建立决策树模型时。
那如果让我选一个作为今天 demo 的入门教程,我会毫不犹豫选择**Keras,**因为他更加符合初学者,因为越是上层的东西,初学者越容易找到成就感。OK:
在开始机器学习项目之前,我们需要明确我们希望解决的问题。问题定义将影响我们选择哪种类型的模型,以及我们如何准备和处理数据。
例如,我们可能希望解决以下类型的问题:
- 分类问题:我们有一些数据,并且我们希望预测数据属于哪个类别。例如,我们可能有一些电子邮件,并且我们希望预测哪些邮件是垃圾邮件。这是一个二元分类问题。如果有多个类别,那么它就是一个多元分类问题。
- 回归问题:我们有一些数据,并且我们希望预测一个连续的输出值。例如,我们可能有一些房屋的特征(如面积,卧室数量等),并且我们希望预测房屋的价格。
- 聚类问题:我们有一些数据,并且我们希望找出数据中的群体。例如,我们可能有一些客户数据,并且我们希望找出相似客户的群体。
今天的 demo 中,我们决定使用了鸢尾花数据集,这是一个经典的多元分类问题。我们有一些鸢尾花的测量数据(如花瓣长度和宽度),我们的目标是预测鸢尾花的种类。
实际操作
下面,我们以一个完整的使用 Keras 和 TensorFlow 进行机器学习的流程来讲解,步骤如下:
1. 安装相关库
复制我的就好,废话不多说了
pip3.11 install tensorflow keras sklearn matplotlib numpy pandas2. 准备数据
在这个例子中,我将使用 sklearn 的内置数据集,例如鸢尾花数据集,这是因为我很懒的,有数据不用白不用。
from sklearn.model_selection import train_test_split
from sklearn import datasets
import numpy as np
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = (iris.target != 0) * 1 # 将问题转化为二分类问题
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)3. 创建模型
然后,我们可以创建一个简单的神经网络模型。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu')) # 输入维度为4
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 输出维度为1,因为是二分类问题4. 编译模型
接下来,你需要编译模型,并指定损失函数和优化器。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])5. 训练模型
然后,你可以使用你的数据来训练模型。
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=32)6. 评估模型
你可以使用测试数据来评估模型的性能。
loss, accuracy = model.evaluate(X_test, y_test)
print('Accuracy: %.2f' % (accuracy*100))以下是我运行过程中的截图:
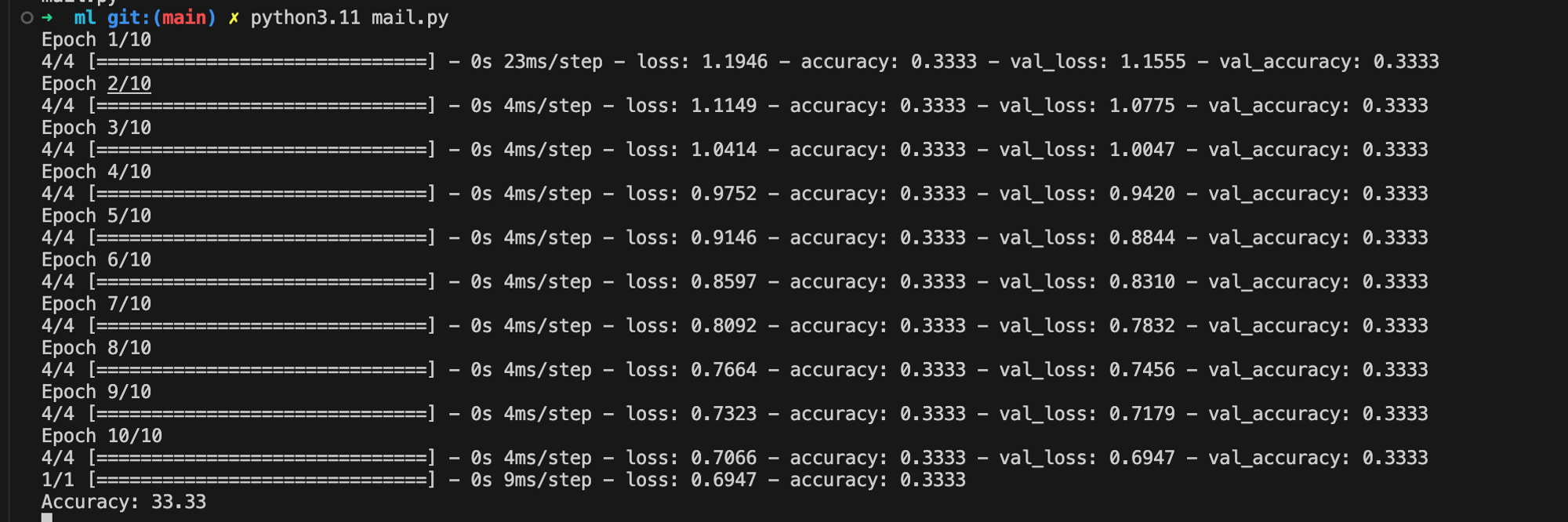
7. 可能需要绘制点图片才显得高大上点
这个简单,比如你可以使用 matplotlib 来绘制训练过程中的损失和准确率。
import matplotlib.pyplot as plt
# 绘制训练 & 验证的准确率值
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()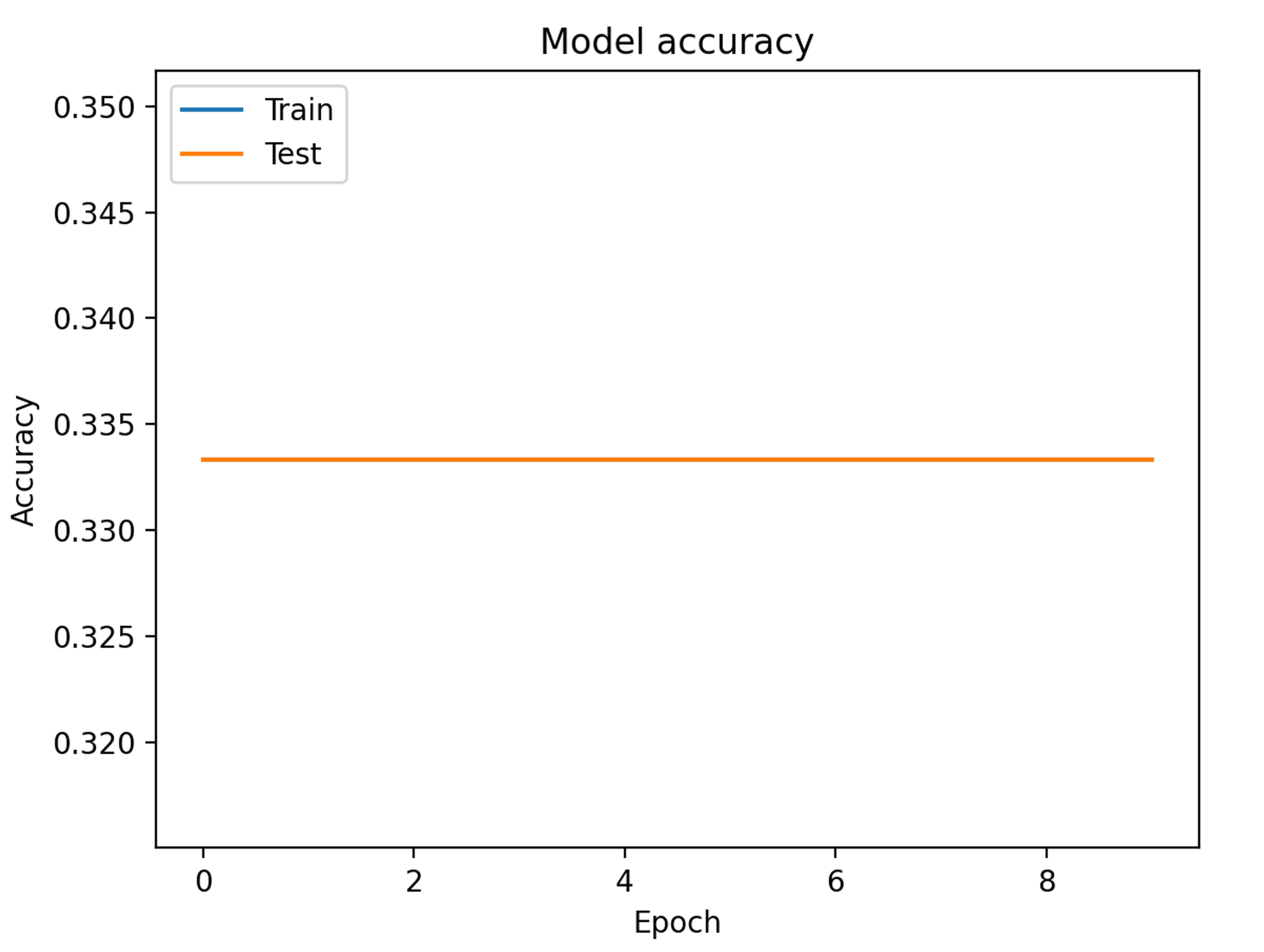
# 绘制训练 & 验证的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()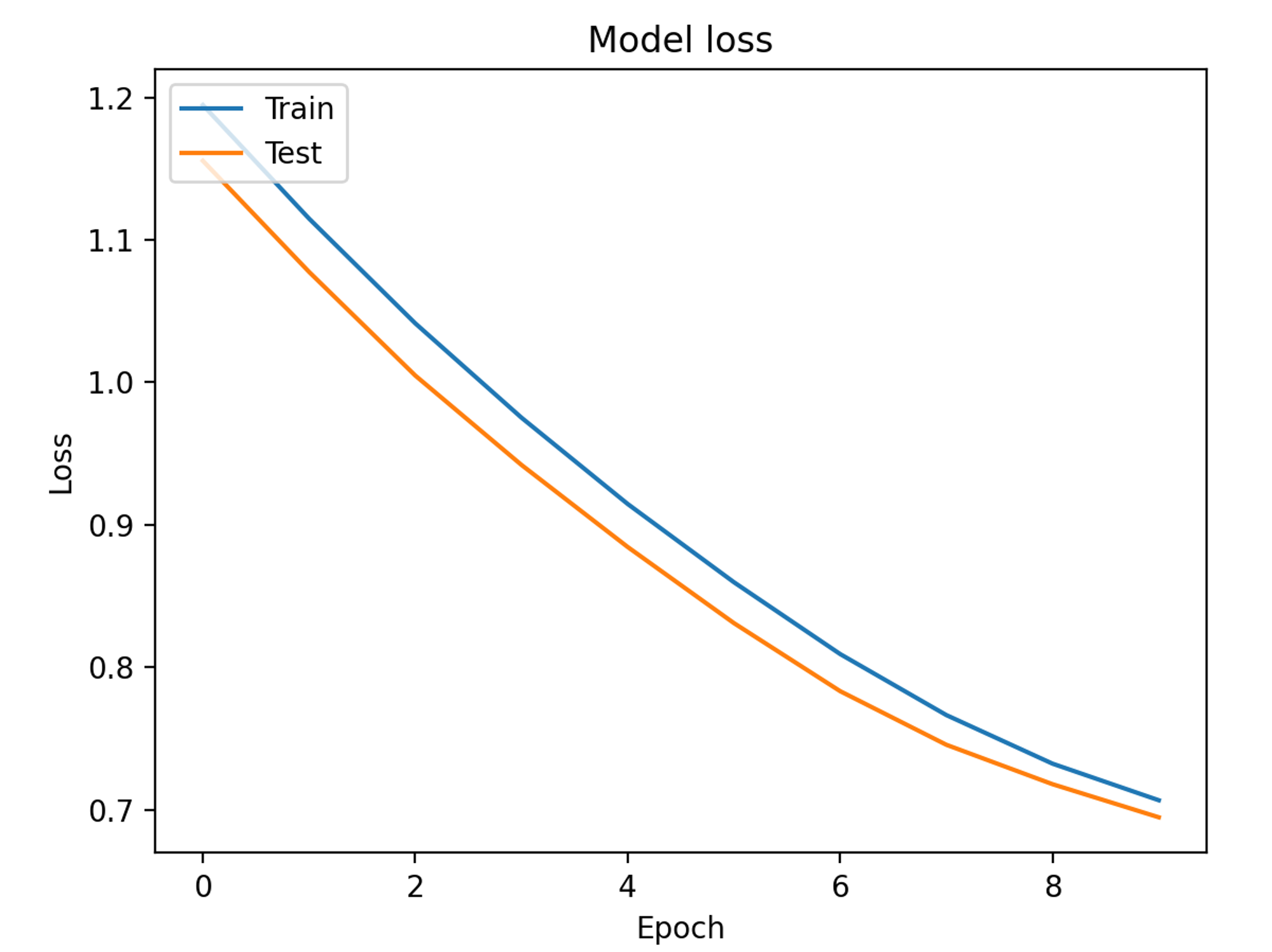
以上就是一个完整的使用 Keras 和 TensorFlow 进行机器学习的流程。当然,我也是一个还没太入门的菜鸟,主要是数学太菜了,说实话搞机器学习还是需要数学天赋的…,请多包涵指教。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。