使用 RDMA 提升微软 Azure 云的存储性能 [NSDI'23]

使用 RDMA 提升微软 Azure 云的存储性能 [NSDI'23]

Flowlet
发布于 2024-01-29 15:25:45
发布于 2024-01-29 15:25:45
鉴于公共云中广泛采用存算分离架构(Disaggregated Storage),网络是云存储服务实现高性能和高可靠性的关键。在 Azure 云中,我们在存储前端流量(计算 VM 和存储集群之间)和后端流量(存储集群内)之间启用 RDMA(Remote Direct Memory Access)作为我们的传输层。由于计算集群和存储集群可能位于 Azure 云 region 内的不同 dc 中,因此我们需要在 region 范围内支持 RDMA。
这项工作展示了我们通过在 region 内部署 RDMA 以承载 Azure 中的存储工作负载方面的经验。Azure 中的基础设施的高度复杂性和异构性同时带来了一系列新的挑战,例如不同类型的 RDMA 网卡之间的互操作性问题。我们对网络基础设施进行了多项更改以应对这些挑战。如今,在 Azure 中大约 70% 的流量是 RDMA 流量,并且在 Azure 的所有公有云 region 都支持 region 内 RDMA。RDMA 帮助我们显着的提升磁盘 I/O 性能并节省 CPU 资源。
1、介绍
高性能、高可靠的存储服务是公有云最基础的服务之一。近年来,我们见证了存储介质和技术的显着改进,客户也希望能在云中能获得类似的性能提升。鉴于云中广泛采用存算分离架构,互连计算集群和存储集群的网络成为云存储的关键性能瓶颈。尽管基于 Clos 的网络架构提供了足够的网络带宽,但传统的 TCP/IP 协议栈仍面临高延迟、单核吞吐量低,CPU 消耗高等问题,使其并不适合这种存算分离的场景。
鉴于这些限制,RDMA(Remote Direct Memory Access) 提供了一种很有前景的解决方案。通过将网络协议栈卸载到网卡(NIC)硬件上,RDMA 在 CPU 接近零开销的情况下,实现了超低处理延迟和超高吞吐。除了性能改进之外,RDMA 还减少了每台服务器上专为网络协议栈处理报文所预留的 CPU 核数。这些节省下来的 CPU 核可以作为 VM 进行出售或被用于应用程序。
为了充分利用 RDMA 的优势,我们的目标是在存储前端流量(VM 计算集群和存储集群之间)和后端流量(存储集群内)中启用 RDMA。这与之前的工作不同,之前的工作仅仅是针对存储后端流量启用 RDMA。在 Azure 云中,由于受容量问题的影响,计算集群和存储集群可能位于同一 region 内的不同数据中心。这就要求我们必须具有 region 规模支持 RDMA 的能力。
在本文中,我们总结了在 region 规模部署 RDMA 以支持 Azure 存储工作负载的经验。与之前的 RDMA 部署相比,由于 Azure region 内的高度复杂性和异构性,region 规模 RDMA 部署引入了许多新的挑战。随着 Azure 基础设施的不断发展,不同的集群可能会部署不同的 RDMA NIC。虽然所有 NIC 都支持 DCQCN,但不同厂商 NIC 的实现方式不同。当不同厂商的 NIC 互通时,这会导致许多不可预期的行为。同样的,来自多个供应商的异构交换机软硬件显着增加了我们的运营工作量。此外,互连数据中心的长距离电缆会导致 region 内较大的传播时延和较大的往返时间(RTT)的变化,这给拥塞控制带来了新的挑战。
为了安全地在 region 内为 Azure 存储流量启用 RDMA,我们从应用层协议到链路层流量控制等方面对网络基础设施进行了多项改进。我们基于 RDMA 开发了具有许多优化和 failover 支持的全新存储协议,并能在传统存储协议栈中进行无缝集成。我们构建了 RDMA Estats 工具用来监控主机网络协议栈的状态。我们通过 SONiC 在不同交换机平台上实施统一的软件栈部署。我们更新了 NIC 的固件以统一其 DCQCN 行为,并结合使用 PFC 和 DCQCN 来实现网络的高吞吐、低延迟和近乎零丢包。
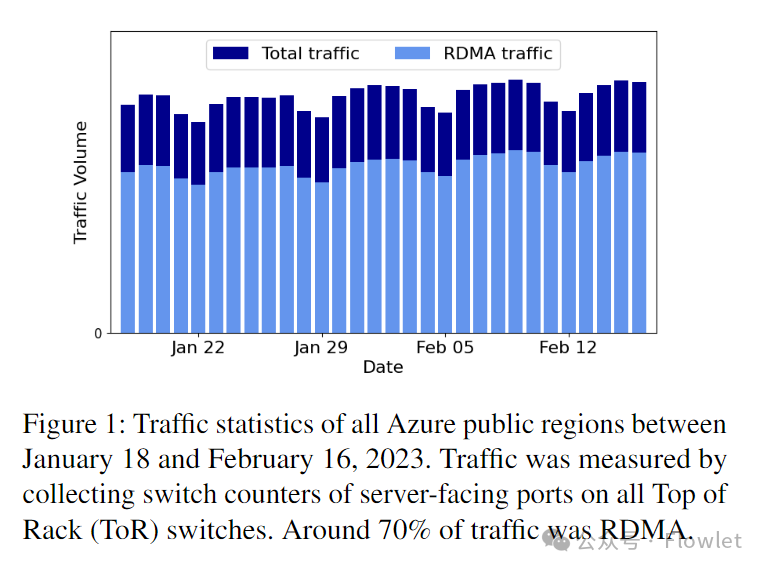
图 1:2023 年 1 月 18 日至 2 月 16 日期间 Azure 公有云所有 region 的流量统计数据。流量是通过收集所有 ToR 交换机上面向服务器一次的交换机端口计数器测量得到的,大约 70% 的流量是 RDMA 流量。
2018 年,我们开始为后端存储流量启用 RDMA。2019 年,我们开始为客户前端存储流量启用 RDMA 。图 1 给出了 2023 年 1 月 18 日至 2 月 16 日期间 Azure 公有云所有 region 的流量统计数据。截至 2023 年 2 月,Azure 云中大约 70% 的流量是 RDMA 流量,并且 Azure 公有云所有 region 都支持 region 内 RDMA。RDMA 帮助我们显着提高磁盘 I/O 性能并节省 CPU 资源。
2、背景
在本节中,我们首先介绍 Azure 网络和存储架构的背景知识。然后,我们介绍一下 region 内实现 RDMA 网络的动机和挑战。
2.1 Azure region 的网络架构

在云计算中,region 是部署在延迟定义的边界内的一组数据中心。图 2 显示了一个 Azure region 的简化拓扑。region 内的服务器通过基于以太网的 Clos 网络进行连接,该 Clos 网络具有四级(four tiers)交换架构:第 0 层(T0)、第 1 层(T1)、第 2 层(T2)和 region 枢纽层 (RH/region hub)。我们使用 eBGP 进行路由学习,使用 ECMP 进行负载平衡。我们部署以下四种类型的组件:
- Rack(机架):T0 交换机和连接到它的服务器。
- Cluster(集群):连接到同一组 T1 交换机的一组机架。
- Datacenter(数据中心):连接到同一组 T2 交换机的一组集群。
- Region(地域):连接到同一组 RH 交换机的数据中心。与数据中心中的短链路(几米到数百米)相比,T2 和 RH 交换机通过长度可达数十公里的长距离链路进行连接。
该架构有两点需要注意:首先,由于 T2 和 RH 之间通过长距离链路进行连接,基本 RTT 从数据中心内的几微秒到 region 内的 2 毫秒进行变化。其次,我们使用两种类型的交换机:用于 T0 和 T1 的盒式交换机(pizza box switch),以及用于 T2 和 RH 的框式交换机(chassis switch)。盒式交换机已被学术界广泛研究并使用,该交换机通常带有一颗浅 buffer 的 ASIC 交换芯片。相比之下,框式交换机具有多颗基于虚拟输出队列 (VoQ) 架构的深 buffer ASIC 交换芯片。
2.2 Azure 存储的高层级架构
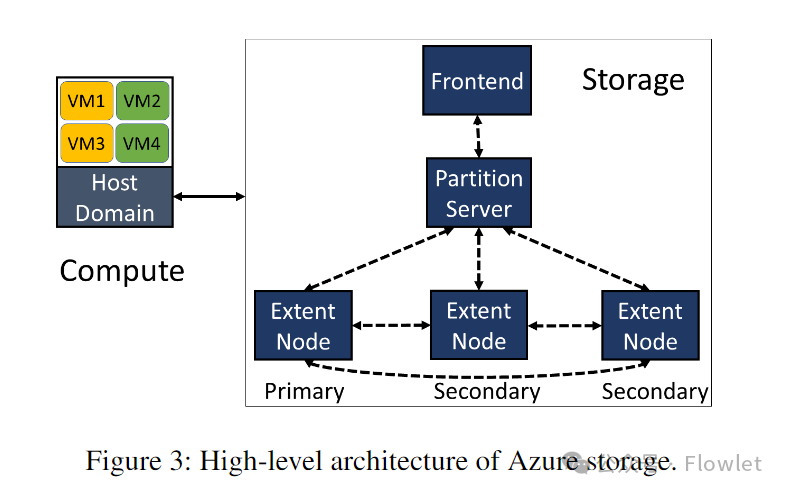
在 Azure 云中,我们计算集群与存储资源进行分离以节省成本并支持自动扩展。在 Azure 云中主要有两种类型的集群:计算集群和存储集群。在计算集群中创建 VM ,但是其虚拟硬盘 (VHD) 实际存储在存储集群中。
图 3 显示了 Azure 云存储的高层级架构。Azure 云存储分为三层:前端层(Front-End Layer)、分区层(Partition Layer)和文件流层(Stream Layer)。文件流层:是一个附加的分布式文件系统。在该层中信息 bit 位存储在磁盘上并进行复制存储以实现信息持久化,但在这一层它并不理解更高层级的存储抽象,例如 Blob、Table 和 VHD。分区层:负责理解不同的存储抽象,管理存储集群中的所有数据对象分区,并将对象数据存储在文件流层之上。分区层和文件流层的守护进程分别称为分区服务器(PS:Partition Server)和扩展节点(EN:Extent Node)。PS 和 EN 共同位于每个存储服务器上。前端层(FE)由一组服务器组成,用于验证传入请求并将其转发到相应的 PS。在某些情况下,FE 服务器也可以直接访问文件流层以提高效率。
当 VM 想要对其磁盘进行写入时,运行在计算服务器主机域中的磁盘驱动程序向相应的存储集群发送 I/O 请求。FE 或 PS 解析并验证请求,生成请求到相应的位于文件流层的 EN 去进行写入数据。在文件流层,文件本质上是称为“extern”的大型存储块(chunk)的有序列表。要写入文件,数据会附加到 active extern 的末尾,该 active extern 会在存储集群中被复制 3 份以确保数据的高可用。只有在收到所有主数据与副本数据的 EN 写入成功的响应后,FE 或 PS 才会将最终响应发送回磁盘驱动器。相比之下,磁盘读取则不同。FE 或 PS 从任何 EN 副本读取数据并将响应发送回磁盘驱动器。
除了面向用户的工作负载之外,存储集群中还存在许多后台工作负载,例如垃圾收集和纠删码。我们将存储流量分为两类:前端流量(VM 和存储服务器之间的流量,例如 VHD 写入和读取请求)和后端流量(存储服务器之间的流量,例如复制和磁盘重建)。我们的存储流量具有类似 incast 的特征。最典型的例子就是在文件流层中实现的数据重建。文件流层纠删码将一个密封的 extent 分割成若干个分片,然后将编码后的分片发送到不同的存储服务器进行存储。当用户想要读取的某个分片由于故障而无法获取时,文件流层会从多个存储服务器中读取其他分片来重建该目标分片。
2.3 Region 内开启 RDMA 的动机
近年来,存储技术有了显着的进步。例如,NVMe 的固态硬盘 (SSD) 可以在请求延迟为数百微秒的前提下提供数十 Gbps 的吞吐。许多客户要求在云中也要有类似的性能。由于云中存算分离(Disaggregated Storage)和分布式存储架构(Distributed Storage)的原因,高性能云存储解决方案对底层网络提出了严格的性能要求。虽然数据中心网络提供了足够的网络带宽,但操作系统内核中的传统 TCP/IP 协议栈由于其高处理延迟和低单核吞吐而成为性能瓶颈。更糟糕的是,传统 TCP/IP 协议栈的性能还取决于操作系统的调度。为了提供可预测的存储性能,我们必须在计算和存储节点上预留足够的 CPU,以便 TCP/IP 协议栈能够处理峰值时的存储工作负载。这些预留的 CPU 原本可以作为客户 VM 进行售卖,这增加了云服务的总体成本。
鉴于这些限制,通过 RDMA 提供了一个有效的解决方案。通过将网络协议栈卸载到网卡(NIC)硬件上,RDMA 在 CPU 接近零开销的情况下,实现了超低处理延迟(几微秒)和超高吞吐(单流线速)。除了性能优势之外,RDMA 还减少了每台服务器上为网络协议栈处理所预留的 CPU 个数。这些原本预留用作网络处理的 CPU 可以作为客户 VM 进行售卖或用于存储请求处理。
为了充分发挥 RDMA 的优势,我们为存储前端流量和后端流量都启用了 RDMA。为存储后端流量启用 RDMA 相对容易,因为几乎所有后端流量都在存储集群内部。相比之下,前端流量需要跨越 Region 内的不同集群。尽管我们尝试将相应的计算集群和存储集群放在同一位置以最大程度地减少延迟,但有时由于容量的原因,它们最终仍可能位于同一 region 内的不同 dc。这就要求我们必须在 region 规模内支持 RDMA,才能满足我们的存储工作负载的要求。
2.4 挑战
在 region 内启用 RDMA 时,我们面临许多挑战:
现实考量: 我们的目标是在现有 region 内基础设施上启用 RDMA。虽然我们可以灵活地重新配置和升级软件协议栈,例如网卡驱动、交换机操作系统和存储协议栈,但是更换底层硬件(例如网卡和交换机)是不可行的。因此,为了保持与 IP 路由网络的兼容性,我们采用了基于 RoCEv2 的 RDMA 技术。在开始这个项目之前,我们已经部署了大量的第一代 RDMA NIC,它们在 NIC 固件中实现了 go-back-N 重传。我们的测量数据表明,该固件丢包恢复时间需要数百微秒,这甚至比 TCP/IP 协议栈还要糟糕。鉴于如此之大的性能下降,我们决定采用基于 PFC 的流控来消除由于网络拥塞导致的报文丢失。
挑战: 在此项目之前,我们已经在一些集群中部署了 RDMA 以支持 Bing 服务,我们从这次部署中吸取了一些教训。与在一个集群内部署 RDMA 相比,region 范围内部署 RDMA 由于基础设施的高度复杂性和异构性,引入了许多新的挑战。
- NIC 差异:云基础设施不断发展,通常最新一代的服务器一次一个集群或一个机架进行部署。region 内的不同集群可能使用不同的 NIC。我们的部署的服务器包含三代 RDMA NIC:Gen1、Gen2 和 Gen3。每代 NIC 的 DCQCN 都有不同实现方式。当具有不同代差的 NIC 相互通信时,这会导致许多无法预期的行为。
- 交换机差异:与服务器基础设施类似,我们部署新一代交换机以降低运营成本并增加网络带宽。我们部署了来自多个不同供应商的多款 ASIC 交换机和多种交换机操作系统。由于诸如:buffer 大小、分配机制、监控和配置等许多方面都是厂商绑定的,这显着增加了我们的运营工作量。
- 延迟差异:如 2.1 所示,由于 T2 和 RH 之间的长距离链路,一个 region 内的 RTT 变化很大,从几微秒到2毫秒不等。因此,RTT 的公平性成为了一个关键挑战。此外,长距离链路带来的较大传播时延也对 PFC headroom 造成了较大压力。
与公共云中的其他服务一样,可靠性(availability)、可维护性(diagnosis)和可用性(serviceability)是我们的 RDMA 存储系统的关键指标。为了实现高可用,尽管我们已在测试方面投入了大量资金,但我们始终为可能突发的 0day 问题做好准备。我们的系统必须检测设备的性能异常状况并在必要时执行自动故障转移。为了了解设备故障状况和进行故障调试,我们必须构建细粒度的遥测系统,以便于为端到端路径中的每个组件提供网络转发的可视化(clear visibility)。我们的系统还必须具备可维护性:在设备 NIC 驱动更新和交换机软件更新后能够继续承载存储工作负载。
3、概述
为了安全地在 region 内为 Azure 存储流量启用 RDMA,我们从应用层协议到链路层流量控制等方面对网络基础设施进行了多项改进。我们开发了两种基于 RDMA 的协议:sU-RDMA 和 sK-RDMA,分别用于支持存储后端通信和存储前端通信,并将其无缝集成到传统存储协议栈中。在存储协议和 NIC 之间,我们部署了一个监控系统 RDMA Estats,它能使我们了解主机网络协议栈为每次 RDMA 操作所消耗的代价。
我们通过 PFC 和 DCQCN 的组合来实现高吞吐、低延迟的网络,即是在拥塞情况下也能带来近乎零丢包网络体验。在启动该项目时,DCQCN 和 PFC 是当时最先进的商业解决方案。为了优化用户体验,我们使用两个优先级来隔离存储前端流量和存储后端流量。为了解决交换机的差异性问题,我们开发并部署了 SONiC 系统,以提供跨交换机平台的统一软件栈。为了解决不同类型 NIC 的互操作性问题,我们更新了 NIC 的固件以统一其 DCQCN 行为。我们仔细调整了 DCQCN 和交换机的 buffer 参数,以优化不同场景下的网络性能。
3.1 使用 Watchdog 缓解 PFC 风暴
我们通过 PFC 来防止拥塞丢包。然而,发生故障的 NIC 和交换机可能会在没有发生拥塞的情况下持续发送 PFC 暂停帧,从而导致长时间完全阻塞对端设备。此外,这些无休止的 PFC 暂停帧最终会传播到整个转发网络,从而对无辜设备造成附带损害。这种无休止的 PFC 暂停帧被称为 PFC 风暴。相反,正常由于拥塞而触发的 PFC 暂停帧仅通过间歇性暂停和恢复减慢对端设备的数据传输速率。
为了检测和缓解 PFC 风暴,我们在 T0 交换机和服务器之间的每台交换机和 FPGA 卡上设计并部署了 PFC 看门狗。当 PFC 看门狗检测到某个队列处于暂停状态的时间异常长时(例如数百毫秒),它会禁用 PFC 并丢弃该队列上的所有数据包,从而防止 PFC 风暴传播到整个网络。
3.2 安全
我们使用 RDMA 在可信环境中支持第一方(first-party)的存储流量,包括存储服务器、计算服务器的主机域、交换机和链路。
4、基于RDMA的存储协议
在本节中,我们介绍两种构建在 RDMA 可靠连接 (RC) 之上的存储协议:sU-RDMA 和 sK-RDMA。这两种协议都旨在优化性能的同时保证了与传统协议栈的良好兼容性。
4.1 sU-RDMA
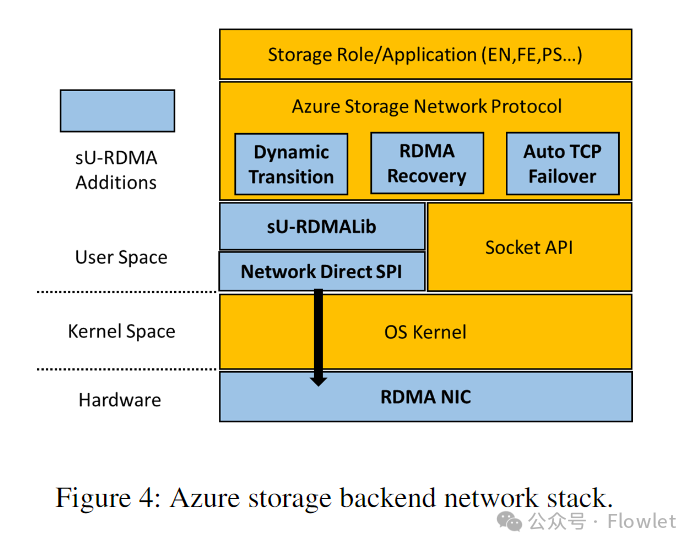
sU-RDMA 用于存储后端(存储到存储)通信。图 4 展示了我们存储后端网络协议栈架构。Azure 存储网络协议是应用程序可以直接使用的 RPC 协议,应用程序可以直接使用它发送请求和接收响应。它使用 socket API 来实现连接管理、消息的发送和接收。
为了简化 RDMA 与存储协议栈的集成难度,我们构建了用户空间的 sU-RDMA Lib 库,向上层应用公开类似于 socket 的字节流 API。为了将类似的 socket API 映射到 RDMA 操作,sU-RDMA Lib 需要应对以下挑战:
- 当 RDMA 应用无法直接向现有 MR(Memory Region)写入数据时,它必须将应用程序的 buffer 注册为新的 MR 或将其数据复制到现有 MR 中。这两种操作都会带来巨大的延迟,我们应该尽量减少这类开销。
- 如果我们使用 RDMA 发送和接收数据,接收方必须预先发布足够的接收请求。
- RDMA 发送方和接收方必须就传输的数据大小达成一致。
为了减少内存注册(这对于小消息来说尤为重要),sU-RDMA Lib 维护一个基于预注册内存机制的跨多个连接共享的公共 buffer 池。sU-RDMA Lib 还提供 API 来允许应用程序请求和释放已注册的缓冲区。为了避免 NIC 上的 MTT(Memory Translation Table)缓存 miss,sU-RDMA Lib 从内核中分配大内存块,并在这些块上注册内存。该缓存池还可以根据运行时的使用情况进行自动缩放。为了避免淹没(overwhelming)接收方,sU-RDMA Lib 实现了基于信用的 receiver 流制驱动,其中信用代表 receiver 分配的资源(例如,可用缓冲区和发布的接收请求)。接收方定期将信用更新消息发送回发送方。当我们开始设计 sU-RDMA Lib 时,我们考虑为每个 RDMA 传输数据的发送/接收请求使用大小为 S 的固定缓冲区。然而,这种设计却带来一个问题。如果我们使用一个较大的 S 缓冲区,我们可能会浪费很多内存空间,因为无论实际消息大小如何,发送请求都会完全使用接收请求的接收缓冲区。相反,较小的 S 缓冲区会造成较大的数据碎片。因此,sU-RDMA Lib 根据消息大小使用三种传输模式。
- 小消息:使用 RDMA 发送和接收传输数据。
- 中消息:发送方通过发布 RDMA 写入请求以传输数据,并发送带有“写入完成”的发送请求以通知接收方。
- 大消息:发送方首先向接收方发布携带本地数据缓冲区描述的 RDMA 发送请求。然后接收方发出读取请求来拉取数据。最后,接收方发布带有“Read Done”的发送请求来通知发送方。
在 sU-RDMA Lib 之上,我们构建模块来实现 TCP 和 RDMA 之间的动态转换,这对于故障转移和业务恢复来说至关重要。过渡过程是渐进式的,我们定期关闭所有连接的一小部分并使用所需的传输方式建立新的连接。
与 TCP 使用跟踪传输中的数据包数量(窗口大小)的拥塞控制算法不同,RDMA 使用基于速率的拥塞控制算法。因此,RDMA 往往会由于发送了过多的数据包,从而触发 PFC。为了缓解这个问题,我们在 Azure 存储网络协议中实现了静态流量控制机制,将消息划分为固定(fixed-sized)大小的块(chunk),并且每个连接只允许一个正在发送(in-flight)的块。分块可以在 CPU 开销可以忽略不计的条件下显着的提高 incast 场景下的性能。
4.2 sK-RDMA
sK-RDMA 用于存储前端(计算集群到存储集群之间)的通信。与通过 sU-RDMA 在用户空间运行 RDMA 相比,sK-RDMA 在内核空间运行 RDMA。这使得在计算服务器主机域内核空间中运行的磁盘驱动能够直接使用 sK-RDMA 发出网络 I/O 请求。sK-RDMA 直接通过服务器消息块 (SMB:Server Message Block) 提供类似套接字的内核模式 RDMA 接口。与 sU-RDMA 类似,sK-RDMA 也提供了基于信用的流量控制以及 RDMA 和 TCP 之间的动态转换。

图 5 显示了 sK-RDMA 读写磁盘的数据流过程。计算服务器首先向注册数据缓冲区发布快速内存注册(FMR)请求。然后,发布 RDMA 发送请求以将请求消息传送到存储服务器。该请求携带磁盘 I/O 命令以及可用于 RDMA 访问的 FMR 注册缓冲区的描述。根据 InfiniBand (IB) 规范,NIC 应等待 FMR 请求完成,然后再处理任何后续发布的请求。因此,请求消息实际上是在内存注册之后才被推送到链路上。数据传输由存储服务器使用 RDMA 读取或写入发起。数据传输后,存储服务器使用 RDMA Send With Invalidate 向计算服务器发送响应消息。
为了检测由于路径上的各种软件和硬件错误而发生的数据损坏,sK-RDMA 和 sU-RDMA 都对所有应用数据实施 CRC 校验。在 sK-RDMA 中,计算服务器计算磁盘写入数据的 CRC。这些计算出的 CRC 包含在请求消息中,并由存储服务器用来验证数据。对于磁盘读取,存储服务器执行 CRC 计算并将其包含在响应消息中,计算服务器使用它来校验数据。
5、RDMA Estats
为了更好的调试故障,需要有一个细粒度的遥测工具来捕获端到端路径中每个组件的行为。虽然许多现有工具可以用于诊断交换机和链路故障,但这些工具都不能提供端点 Host 上 RDMA 网络协议栈的良好可观测性。
受 TCP 诊断工具的启发,为了诊断网络和主机的性能问题我们开发了 RDMA Estats(Extended Statistics)工具。当 RDMA 应用性能不佳时,RDMA Estats 可以让我们判断出性能瓶颈是在发送方、接收方还是传输网络中。
为了实现这一目标,RDMA Estats 除了收集诸如发送/接收的字节数和 NACK 数等常规计数外,还为每个 RDMA 操作提供细粒度的延迟分解。当 WQE 穿过传输 pipeline 时,请求方 NIC 会在一个或多个观测点记录时间戳。当收到响应(ACK 或读取响应)时,NIC 会在接收 pipeline 沿线的测量点记录附加时间戳。在 Azure 中实施 RDMA Estats 需要提供以下测量点:
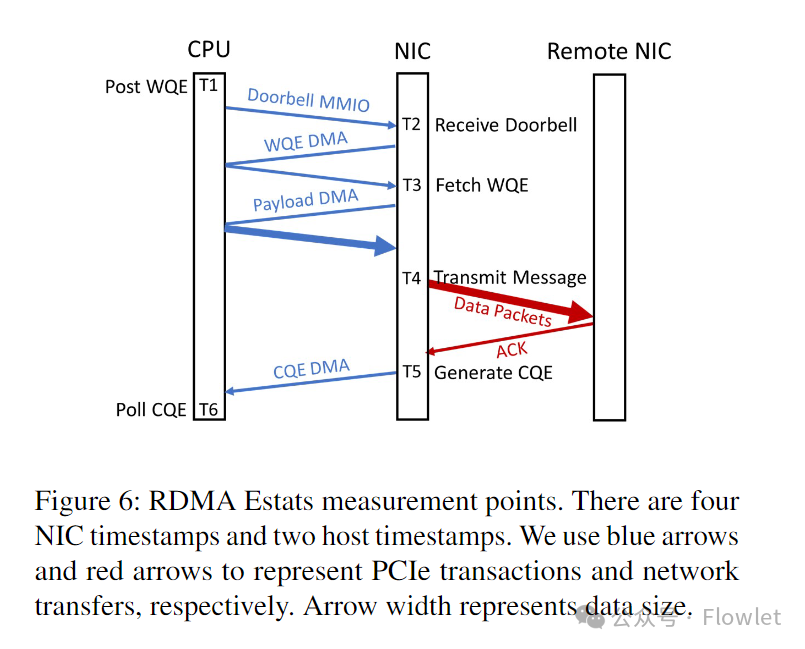
T1:WQE posting:WQE 发布到提交队列时的 Host 处理时间戳。T5:CQE generation:NIC 中生成 CQE 时的 NIC 时间戳。T6:CQE polling:软件轮询 CQE 时的 Host 时间戳。
在 Azure 中,NIC 驱动通过上述时间戳上报各种时延统计。例如,T6 - T1 是 RDMA 消费者看到的操作时延,而 T5 - T1 是 NIC 看到的时延。用户态 agent 按连接、操作类型和(成功/失败)状态对时延样本进行分组,以便为每个分组创建时延直方图。直方图的默认时延采集间隔为一分钟。每个直方图的分位数和汇总统计都会输入到 Azure 的遥测 pipeline 中。随着诊断技术的发展,在高时延事件中我们为用户态 agent 添加了收集和上传 NIC 和 QP 状态 dump 的功能。最后,为了以防非特定于 RDMA 事件的服务操作影响连接,我们扩展了用户态 agent 的事件触发的数据收集范围,以包括 NIC 统计和状态 dump。
时延样本的收集增加了 WQE 发布和处理代码的路径开销,此开销主要是为了保持 NIC 和主机时间戳的同步。为了减少该开销,我们开发了一种时钟同步程序,在保持较低的偏差的同时最大限度地降低读取 NIC 时钟寄存器的频率。
RDMA Estats 可以通过快速消除网络时延来显着减少调试时间并缓解影响存储性能的事件。在第 8.3 节中,我们分享了使用 RDMA Estats 诊断 FMR 隐藏栅栏错误方面的经验。
6、交换机管理
6.1 通过 SONic 屏蔽交换机的厂商差异
我们部署 RDMA 很大程度上依赖于交换机的支持。然而,来自多个供应商的不同交换机 ASIC 和操作系统给网络管理带来了巨大的挑战。例如,商业交换机操作系统为了满足所有客户的不同需求,导致软件复杂功能演进缓慢。此外,不同的交换机 ASIC 提供不同的 buffer 架构和机制,从而增加了针对 Azure RDMA 部署对其进行测试的工作量。
针对上述挑战我们提出了两个解决方案。一方面,我们与供应商密切合作,定义具体的功能需求和测试计划,并了解他们的底层实现细节。另一方面,我们合作伙伴进行合作,开发并部署了一个称为 SONiC 的跨平台交换机操作系统。SONiC 基于交换机抽象接口(SAI),能够通过简化且统一的软件栈管理来自多个供应商的异构交换机。SONiC 将整体交换机软件分解为多个容器化组件,容器化提供隔离性与开发敏捷性。网络运营商可以仅使用他们需要的功能来对 SONiC 进行定制。从而创建精简软件栈(lean stack)。
6.2 SONiC 在盒式交换机上的 Buffer Model 及配置实践
SONiC 提供了 RDMA 部署所需要的所有功能,例如 ECN 标记、PFC、PFC watchdog 和共享缓冲区模型。篇幅有限,我们简单介绍下 SONiC 用于 T0 和 T1 的盒式交换机上的缓冲区模型及配置实践。
我们通常在盒式交换机上分配三个 buffer 池:(1)ingress_pool 用于所有数据包的 ingress 访问控制。(2)egress_lossy_pool 用于有损数据包的 egress 访问控制。(3)egress_lossless_pool 用于无损数据包的 egress 访问控制。
这些 buffer 池和队列并不是单独的专用缓冲区,而是在单个物理共享缓冲区上用于访问控制目的的计数器。每个计数器由映射到它的数据包进行更新,并且同一个数据包可以同时映射到多个队列和 buffer 池。例如,从源端口 s 到目标端口 d 的优先级为 p 的无损(有损)数据包会更新 ingress queue(s,p)、egress queue(d,p)、ingress_pool 和 egress_lossless_pool(egress_lossy_pool)。仅当数据包通过入口和出口访问控制时才会被接收。计数器按通过访问控制的包的大小递增,并按发出去的包的大小递减。我们通过使用动态阈值和静态阈值来限制队列的长度。
我们仅对无损流量使用 ingress 访问控制,并且仅对有损流量使用 egress 访问控制。如果交换机缓冲区大小为 B,则 ingress_pool 的大小必须小于 B,以便为 PFC headroom buffer 预留足够的空间。当 ingress 无损队列达到动态阈值时,队列进入“paused”状态,交换机向上游设备发送 PFC 暂停帧。此后进入此入口无损队列上的数据包将会使用 PFC headroom buffer 而不是 ingress_pool。相反,对于 ingress 有损队列,我们配置一个等于交换机缓冲区大小 B 的静态阈值。由于 ingress 有损队列长度无法达到交换机缓冲区的大小,因此有损数据包可以 bypass ingress 访问控制。
在 egress 处,有损和无损数据包分别映射到 egress_lossy_pool 和 egress_lossless_pool。我们将 egress_lossless_pool 的大小和 egress 无损队列的静态阈值均配置为 B,以便无损数据包能够 bypass egress 访问控制。相反,egress_lossy_pool 的大小必须不大于 ingress_pool 的大小,因为有损数据包不应在 ingress 使用任何 PFC headroom buffer。egress 有损队列配置为通过动态阈值丢弃数据包。
6.3 使用 SONiC 测试 RDMA 特性
在本节中,我们将简要介绍使用 SONiC 交换机测试 RDMA 特性的方法。
基于软件的测试:我们通过 PTF(Packet Testing Framework)开发 SONiC 的一般测试用例。PTF 主要用于测试数据包转发行为,而测试 RDMA 功能则需要额外的工作。
我们受到软件调试方法中设置断点的启发。要为交换机设置“断点”,我们首先使用 SAI API block 交换机端口进行转发。然后,我们生成一系列数据包发往被阻止端口,并捕获一个或多个交换机状态快照。例如,缓冲区水位(buffer watermark),类似于在软件调试中 dump 变量的值。接下来,我们取消 block 端口并 dump 收到的数据包。我们通过分析捕获的交换机状态快照和接收到的数据包来确定测试是否通过。我们使用这种方法来测试 buffer 管理机制、buffer 计数器以及报文调度。
基于硬件的测试:虽然上述方法能够使我们很好地了解交换机的状态和数据包转发的微行为(micro-behaviors),但它无法满足某些测试的严格性能要求。例如,为了测试 PFC watchdog,需要连续高速的生成 PFC 暂停帧,由于每个 PFC 帧暂停持续时间短而精确的控制其间隔。
为了进行此类性能敏感性的测试,我们需要以 μs 甚至 ns 的时间间隔控制流量的生成,并对数据面行为进行高精度测量。这促使我们利用硬件可编程流量生成器构建基于硬件的测试系统。我们基于硬件的测试系统专注于 PFC、PFC watchdog、RED/ECN 标记等功能的测试。
截至 2023 年 2 月,我们为 RDMA 特性构建了 32 个软件测试用例和 50 个硬件测试用例。
7、拥塞控制
我们通过结合 PFC 和 DCQCN 2种技术来缓解链路拥塞。在本节中,我们讨论如何在 region 范围内使用两种技术。
7.1 在长距离链路中使用 PFC
一旦 ingress 队列暂停上游设备,在 PFC 暂停帧对上游设备生效之前,它需要一个专用的 headroom buffer 来吸收传输中的数据包。理想的 PFC headroom buffer 取值取决于许多因素,例如链路容量和传播延迟。交换机 headroom buffer 的大小与无损优先级的数量成正比。
为了将 RDMA 从集群规模扩展到 region 规模,我们必须处理 T2 和 RH(数十公里)之间以及 T1 和 T2(数百米)之间的长链路,这比集群内链路需要更大的 PFC headroom buffer。乍一看,我们生产环境中的 T1 交换机似乎可以为 PFC headroom buffer 和其他使用用途预留总 buffer 的一半。在 T2 和 RH 交换机中,考虑到框式交换机的高端口密度(100 个)和长距离链路,我们需要预留数 GB 的 PFC headroom buffer。
为了在长距离链路上使用 PFC,我们利用了这样一个事实:病态情况(pathological case)(例如,所有端口同时拥塞,以及端口的 ingress 无损队列暂停对等点发送)可能很少见。我们的解决方案有两个方面。首先,在 T2 和 RH 的框式交换机上,我们使用片外 DRAM 的深度数据包缓冲区来存储 RDMA 数据包。我们的分析表明,我们生产的框式交换机可以为 PFC headroom 提供充足的 DRAM 缓冲区。其次,我们并不是为每个队列预留 PFC headroom,而是分配一个由交换机上所有 ingress 无损队列共享的 PFC headroom 池。每个 ingress 无损队列都有一个静态阈值,以限制其在 headroom 池中的最大使用量。我们以合理的比例超额订阅(oversubscribed) headroom 池的大小,从而留下更多的共享缓冲区空间来吸收网络突发。我们的生产经验表明,超额订阅的 PFC headroom 池可以有效消除网络拥塞带来的损失,提高应对网络突发的容忍度。
7.2 DCQCN 实现差异性带来的挑战
我们使用 DCQCN 来控制每个 QP(queue pair)的发送速率。DCQCN 由三个实体组成:发送方或反应点 (RP/reaction point)、交换机或拥塞点 (CP/congestion point) 以及接收方或通知点 (NP/notification point)。CP 基于 RED 算法在 egress 队列处执行 ECN 标记。当 NP 收到带有 ECN 标记的数据包时,会发送拥塞通知数据包 (CNP)。当 RP 收到 CNP 时,它会降低其发送速率。否则,它会利用字节计数器和定时器来提高发送速率。
我们为不同类型的集群总共部署了供应商的三代商用 NIC:Gen1、Gen2 和 Gen3。虽然它们都支持 DCQCN,但它们的实现细节却有很大差异。当不同代的 NIC 相互通信时,会导致互操作性问题。
DCQCN 实现差异: 在 Gen1 上,大多数 DCQCN 功能(例如 NP 和 RP 状态机)在固件中实现。鉴于固件的处理能力有限,Gen1 通过 NP 侧的报文合并最大限度地减少 CNP 的数量。如果在一条流的时间窗口内所有数据包都被 ECN 标记,则 NP 最多生成一个 CNP。相应地,RP 在收到 CNP 后降低发送速率。此外,Gen1 的 cache 资源有限。cache 未命中会显着影响 RDMA 的性能。为了减少 cache 未命中的情况,我们将 Gen1 基于的单个数据包的限速变为基于 burst 数据包的限速。burst 传输可以有效减少固定时间间隔内的活跃 QP 数量,从而减轻 Gen1 网卡缓存资源方面的压力。
相比之下,Gen2 和 Gen3 基于硬件实现 DCQCN,并采用基于 RP 的 CNP 合并机制,这与 Gen1 使用的基于 NP 的 CNP 合并机制完全相反。在 Gen2 和 Gen3 中,NP 为每个到达的带有 ECN 标记的数据包发送一个 CNP。然而,如果 RP 在某个时间窗口内收到任何 CNP,则它最多只会在该时间窗口内降低一次流的发送速率。值得注意的是,基于 RP 和基于 NP 的 CNP 合并机制本质上提供相同的拥塞通知粒度。Gen2 和 Gen3 上的速率限制是针对每个包粒度的。
互操作性挑战: 跨不同集群的存储前端流量可能会导致不同代差 NIC 之间进行通信。在这种情况下,DCQCN 的实现差异会导致不可预期的行为。首先,当 Gen2/Gen3 节点向 Gen1 节点发送流量时,由于其基于每包的速率限制往往会导致在 Gen1 节点上触发许多 cache miss,从而使 receiver pipeline 减速。其次,当 Gen1 节点通过拥塞路径向 Gen2/Gen3 节点发送流量时,Gen2/Gen3 NP 往往会向 Gen1 RP 发送过多的 CNP,从而导致降速过度和吞吐损失。
解决方案: 鉴于 Gen1 的资源和处理能力有限,我们无法使其表现得像 Gen2 和 Gen3。相反,我们尝试让 Gen2 和 Gen3 的行为尽可能像 Gen1。我们的解决方案有两个方面。首先,我们将 Gen2 和 Gen3 上的 CNP 合并从 RP 侧移至 NP 侧。在 Gen2/Gen3 NP 方面,我们添加了 per-QP CNP 限速器,并将两个连续 CNP 之间的最小发送间隔设置为 Gen1 NP 进行 CNP 合并定时器的值。在 Gen2/Gen3 RP 方面,我们最大限度减小速率降低的时间窗口,以便 RP 几乎总是在收到 CNP 时才进行降速。其次,我们对 Gen2 和 Gen3 启用了 per-burst 限速。
7.3 DCQCN 调优
当我们在 Azure 中调整 DCQCN 时,存在某些实际限制。首先,我们的网卡只支持全局 DCQCN 参数设置。其次,为了优化用户体验,我们根据应用程序语义而不是 RTT 将 RDMA 流量分类为两个交换队列。因此,我们没有对数据中心间(inter-datacenter)和数据中心内(intra-datacenter)流量使用不同的 DCQCN 参数,而是在 NIC 和交换机上使用全局 DCQCN 参数设置,该设置能够在 region 内 RTT 变化较大时运行良好。
我们采用以下三步调整 DCQCN 参数。首先,我们利用流体模型(Fluid model)来理解 DCQCN 的理论特性。其次,我们在实验平台上进行了流量实验,以评估互操作性问题的解决方案并提供合理的参数设置。最后,我们最终确定了测试集群中的参数设置,测试集群使用与承载客户流量的生产集群配置相同。我们对真实存储应用程序进行了压力测试,并根据应用程序性能调整了 DCQCN 参数。
为了说明我们的发现,我们使用 Kmin、Kmax 和 Pmax 分别表示 RED/ECN 的最小阈值、最大阈值和最大标记概率。我们通过观察获得以下三个关键结果:
- DCQCN 不会受到 RTT 不公平的影响,因为它是基于速率的协议,其速率调整独立于 RTT。
- 为了 RTT 时延大的 DCQCN 流提供高吞吐,我们使用具有大 Kmax − Kmin 和小 Pmax 的稀疏 ECN 标记。
- DCQCN 和交换机 buffer 应该共同调整。例如,在增加 Kmin 之前,我们确保无损流量的 ingress 阈值足够大。否则,PFC 可能会在 ECN 标记之前触发。
8、经验
2018 年,我们开始在客户的后端流量中启用 RDMA。2019 年,我们开始在存储和计算集群位于同一数据中心场景下,启用 RDMA 来服务客户的前端流量。2020 年,我们开始在 Azure 的 region 内启用 RDMA。截至 2023 年 2 月,Azure region 中大约 70% 的流量是 RDMA 流量,并且所有的 Azure region 都支持 region 内 RDMA。
8.1 部署和服务
我们通过三步逐渐在生产环境中启用 RDMA。首先,我们利用实验平台开发和测试每个单独的组件。其次,我们在测试集群中进行了端到端压力测试,其软硬件设置与生产集群完全相同。除了正常的工作负载之外,我们还通过注入常见错误,例如:随机丢包,来评估系统的稳定性。最后,我们谨慎的控制生产环境中 RDMA 的部署规模。在我们的部署过程中,NIC 驱动程序/固件和交换机操作系统更新很常见。因此,尽量减少此类更新对客户流量的影响至关重要。
交换机维修: 与 T1 或以上层中的交换机相比,T0 交换机(尤其是计算集群中的交换机)的维护更具有挑战性,因为它们可能会成为客户 VM 的单点故障 (SPOF)。在这种情况下,我们利用快速重启和热重启将数据面的中断时间从几分钟减少到不到一秒。
NIC 维修: 在某些情况下,维修 NIC 驱动或固件需要卸载 NIC 驱动。只有在所有网卡资源都被释放后,驱动才能够被安全卸载。为此,我们需要向消费者(例如:磁盘驱动)发送信号,关闭 RDMA 连接并将流量转移到 TCP。一旦 RDMA 和其他具有类似问题的 NIC 功能被禁用,我们就可以重新加载驱动。
8.2 性能表现
存储后端: 目前 Azure 中几乎所有的存储后端流量都是 RDMA。利用客户流量进行大规模 A/B 测试是不可行的,因为 RDMA 节省的 CPU 核心已被用于其他目的,更不用说客户体验会下降。因此,我们展示了 2018 年在测试集群中进行的 A/B 测试的结果。在此测试中,我们运行高 TPS(transactions per second)的存储工作负载,并在 RDMA 和 TCP 之间切换。

图 7 绘制了两次传输切换期间存储服务器的标准化 CPU 利用率。值得注意的是,这里的 CPU 利用率包括所有类型的处理开销,例如:存储应用、Azure 存储网络协议和 TCP/IP 协议栈。
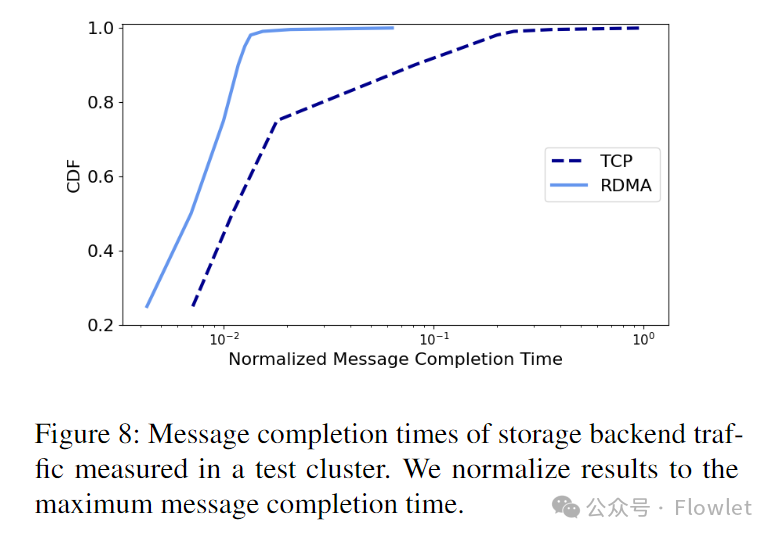
图 8 给出了在 Azure 存储网络协议层(图 4)中测量的消息完成时间,其中不包括应用程序的处理开销。与 TCP 相比,RDMA 明显节省 CPU 并显着的加速网络数据传输。
存储前端: 由于我们无法对客户流量进行大规模 A/B 测试,因此我们展示了 2018 年在测试集群中进行的 A/B 测试的结果。在本次测试中,我们使用 DiskSpd 生成 A IOPS 和 B IOPS (A < B) 的读写工作负载。I/O 大小为 8 KB。

图 9 给出了测试期间主机域的平均 CPU 利用率。与 TCP 相比,RDMA 可以降低高达 34.5% 的 CPU 利用率。
为了了解 RDMA 带来的性能提升,我们利用存储监控服务。该服务在每个 region 分配一些 VM ,使用它们定期生成磁盘读写工作负载,并采集端到端的性能结果。监控服务涵盖不同的 I/O 大小、磁盘类型和存储前端流量。

图 10 显示了监控服务一年来收集的所有 Azure region 中某类 SSD 的总体平均访问延迟。请注意,该图中的 RDMA 和 TCP 仅指测试 VM 生成的前端流量。我们将 RDMA 结果标准化为相应的 TCP 结果。与 TCP 相比,RDMA 对于每种 I/O 大小都产生了更小的访问时延。特别是,1 MB I/O 请求从 RDMA 中获益最多,读取和写入延迟分别减少了 23.8% 和 15.6%。这是因为,较大的 I/O 请求比较小的 I/O 请求对吞吐更加敏感,而 RDMA 可以极大地提高吞吐量,因为它可以使用单个连接以线速运行,而无需经过慢启动。
拥塞控制: 我们在测试集群中运行压力测试,以便找出即使在峰值工作负载下也能实现合理性能的 DCQCN 设置参数。
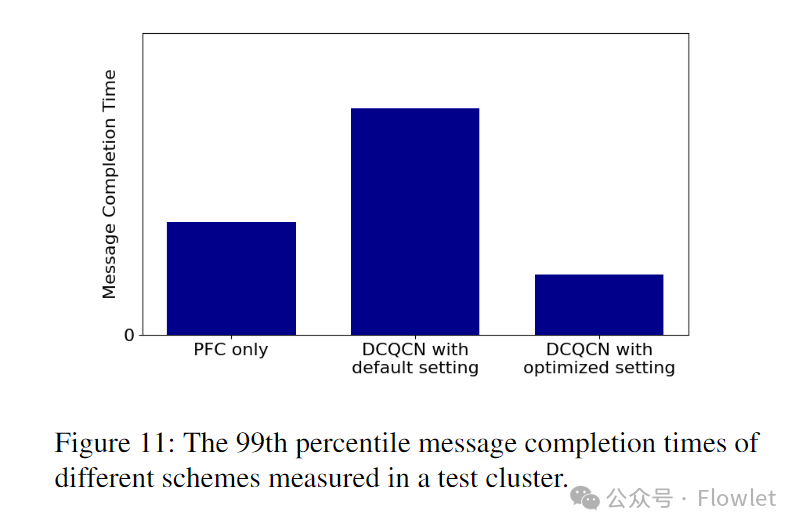
图 11 给出了第 99 个百分位消息完成时间的结果,这是我们用来指导参数配置调整的关键指标。
一开始,我们禁用了 DCQCN,只调整了交换机 buffer 参数。例如,ingress 无损队列的动态阈值,以探索仅通过 PFC 实现最佳性能。在达到 PFC 的最佳性能后,我们使用默认参数设置启用 DCQCN,虽然 DCQCN 减少了 PFC pause 帧的数量,但它降低了尾部消息的完成时间,因为 DCQCN 的默认设置参数过于激进的降低了发送速率。因此,我们调整了 ECN 标记参数以提高 DCQCN 的吞吐量。通过优化设置,DCQCN 的性能优于单独使用 PFC。我们从这次优化经验中得出的结论是,应该共同调整 DCQCN 和交换机 buffer 来优化应用程序的性能,而不是仅仅是通过调整 PFC 的暂停持续时间。
8.3 发现并解决的问题
在测试和部署过程中,我们发现并修复了网卡、交换机和 RDMA 应用程序中的一系列问题。
FMR隐藏栅栏: 在 sK-RDMA 中,从计算服务器发送到存储服务器的每个 I/O 请求都需要一个 FMR 请求,随后再跟一个发送请求,其中包含 FMR 注册内存和存储命令的描述。因此,发送队列由许多 FMR/send 对组成。
当我们在位于不同数据中心的计算和存储集群部署 sK-RDMA 时,我们发现前端流量显示出极低的吞吐量,即使我们在发送队列中保留了许多未完成的 FMR/send 对。为了调试这个问题,我们使用 RDMA Estats 收集每个发送请求 T5 − T1 的延迟。我们发现 T5 – T1 和数据中心间 RTT 之间存在很强的相关性,并注意到每个 RTT 只有一个未完成的 send 请求。在我们与 NIC 供货商分享这些发现后,他们确定了根本原因:为了简化实施,NIC 仅在完成之前发布的请求后才处理 FMR 请求。在 sK-RDMA 中,FMR 请求在两个 send 请求之间创建了一个隐藏的栅栏,因此同一时刻只允许发送一个 send 请求,但这无法填满数据中心之间的大带宽。我们已与 NIC 供应商合作,在新的 NIC 驱动中修复了此问题。
PFC 和 MACsec: 在 T2 和 RH 之间的长链路上启用 PFC 后,许多长链路包损率较高,从而触发告警上报。MACSec 标准并没有规定 PFC 帧是否应该加密。因此,不同的供应商对于发送的 PFC 帧是否应该加密以及如何处理到达的加密 PFC 帧没有达成一致。例如,交换机 A 可能会向交换机 B 发送未加密的 PFC 帧,而交换机 B 期望加密的 PFC 帧。因此,交换机 B 会将这些 PFC 帧视为损坏帧并上报错误。我们与交换机供应商合作,对启用 MACsec 的交换机端口处理 PFC 帧的方式进行标准化。
拥塞泄漏: 当我们在 Gen2 NIC 上启用互操作时,我们发现它们的吞吐量会下降。为了深入研究这个问题,我们使用注水算法来计算 per-QP 的理论吞吐量,并将其与测试环境测量的实际吞吐量进行比较。在比较时,我们发现两个有趣的现象。首先,无论拥塞程度如何,Gen2 NIC 的发送流始终具有相同的发送速率。其次,实际发送速率非常接近网卡理论上发送的最慢流的发送速率。似乎来自 Gen2 NIC 的所有流量都受到最慢流的限制。我们向 NIC 供应商报告了这些观察结果,他们发现 NIC 固件中存在队头阻塞(head-of-line blocking)。我们已在所有互操作的 NIC 上修复了此问题。
由于 loopback RDMA,receiver 速率缓慢: 在压测中,我们发现大量服务器向 T0 交换机发送 PFC pause 帧。然而,与之前发现的慢速 receiver 不同,任何 T0 交换机都没有触发 PFC watchdog。看起来这些服务器只是优雅地减慢了来自 T0 交换机的流量,而不是长时间完全阻塞 T0 交换机。此外,在 Azure 这么大的规模,慢速 receiver 很常见,集群中大部分服务器同时发生拥塞的可能性很小。
根据上述观察,我们怀疑这些慢速 receiver 是由我们的应用程序引起的。我们发现每台服务器上运行了多个 RDMA 应用实例。这些实例无论其位置如何,所有实例间流量都运行在 RDMA 上。因此,loopback 流量和外部流量在每个网卡上共存,从而在网卡 PCIe 通道上造成 2:1 的拥塞。由于网卡无法标记 ECN,只能通过 PCIe 反压和 PFC pause 帧来限制 loopback 流量和外部流量。为了验证上述分析,我们在一些服务器上禁用了 RDMA 的 loopback 流量,然后发现这些服务器停止发送 PFC 帧。
9、经验教训与未解决的问题
在本节中,我们总结我们的经验教训,并讨论了未来需要进行探索的开放问题。
对于 RDMA 来说,故障转移的成本非常高。 虽然我们在 sU-RDMA 和 sK-RDMA 中都将故障转移解决方案作为恢复业务的最后手段,但我们发现故障转移对于 RDMA 来说特别昂贵,应尽可能避免。云供应商采用 RDMA 来节省 CPU 资源,然后将释放的 CPU 资源用于其他目的。为了将流量从 RDMA 中移走,我们需要分配额外的 CPU 资源来承载这些流量。这会增大 CPU 使用率,甚至在高负载时耗尽 CPU 资源。因此,大规模执行 RDMA 故障转移是有风险的,我们将其视为 Azure 中的严重事件。考虑到该风险,只有在所有测试都通过之后,我们才会逐步扩大 RDMA 的部署规模。在推出 RDMA 期间,我们将持续监控网络性能,在检测到异常后立即停止使用 RDMA。当不可避免的执行发生故障转移后,我们应该尽可能切换回 RDMA。
主机网络和物理网络应该融合。 在 8.3 中,我们提出了一种新型的慢速 receiver,这本质上是由于主机内部的拥塞造成的。我们认为这个问题只是冰山一角,主机网络和物理网络之间的许多问题仍未暴露。在传统观念中,主机网络和物理网络是分离的实体,NIC 是它们的边界。如果我们研究主机,它本质上是一个连接异构节点(例如 CPU、GPU、DPU)与专有高速链路(例如 PCIe 链路和 NVLink)和交换机(例如 PCIe 交换机和 NVSwitch)的网络。主机间流量可以视为主机的南北向流量。随着数据中心链路容量的增加以及硬件卸载和设备直接访问技术(例如 GPU Direct RDMA)的广泛采用,主机间流量往往会消耗主机内部更大、更多样化的资源,从而导致更多与主机内流量的复杂交互。
我们认为未来主机网络和物理网络应该融合。我们预计这个融合网络将是迈向分布式云(disaggregated cloud)的重要一步。
交换机 buffer 越来越重要,需要更多创新。 传统观点表明低延迟数据中心拥塞控制可以减轻对大型交换机 buffer 的需求,因为它们可以保留较短的队列。然而,我们在生产环境中发现交换机 buffer 和 RDMA 性能之间存在很强的相关性。交换机 buffer 较小的集群往往会出现更多性能问题。无需改动 DCQCN,只需调整交换机 buffer 参数即可缓解许多性能问题。这就是为什么我们在调整 DCQCN 之前调整交换机 buffer。交换机 buffer 的重要性在于数据中心普遍存在突发流量和短暂拥塞。传统的拥塞控制解决方案,由于反应慢,并不适合此类场景,相反,交换机 buffer 是吸收流量突发并提供快速响应的首选手段。
随着数据中心链路速率的提高,我们相信交换机 buffer 变得越来越重要。首先,盒式交换机上每端口每 Gbps 的缓冲区大小近年来不断减少。一些交换机 ASIC 甚至将数据包内存分割成多个分区,从而减少了有效的 buffer 资源。我们鼓励投入更多精力开发具有更深数据包 buffer 和更统一架构的 ASIC。其次,当今商用交换机 ASIC 仅提供几十年前设计的 buffer 管理机制,从而限制了解决拥塞的方案范围。遵循可编程数据面的趋势,我们预计未来的交换机 ASIC 将在 buffer 模型和接口上提供更多的可编程性,从而实现更有效的 buffer 管理解决方案。
云需要网络设备统一的行为模型和接口。 软件和硬件的多样性给云规模的网络运营带来了巨大的挑战。来自同一供应商的不同 NIC 都可能具有不同的行为,从而导致 NIC 的互操作性问题,更不用说来自不同供应商的设备了。尽管我们在统一交换机软件和 NIC 拥塞控制方面做出了很多努力,但由于设备多样性,我们仍然遇到了很多问题,例如 PFC 和 MACsec 之间的不可预期的交互问题。我们预计将会出现更加统一的模型和接口,以简化云中的操作并加速创新。
**测试新的网络设备至关重要且具有挑战性。**从该项目的第一天起,我们就投入了大量资金来构建各种测试工具并在测试环境和测试集群中运行严格的测试。尽管在测试过程中发现了大量问题,但我们在部署过程中仍然发现了一些问题(第 8.3 节),这主要是由于微行为和被忽视的极端情况造成的。一些紧迫的问题如下:
- 如何精准捕捉在各种场景下 RDMA 网卡的微行为?
- 尽管我们付出了很多努力来测量交换机的微观行为(第 6.3 节),但我们仍然依赖领域知识来设计测试用例。如何系统地测试交换机行为的正确性和转发性能这个是一个问题?
这些问题促使我们重新思考并重新测试具有越来越多功能的新兴网络设备。首先,许多功能缺乏明确的规范,而这是系统测试的先决条件。许多看似简单的功能实际上与软件和硬件之间复杂的交互纠缠在一起。我们相信上面讨论的统一行为模型和接口可以帮助解决这个问题。其次,测试系统应能够与网络设备高速交互,并精确捕获微行为。我们相信可编程硬件可以在这方面提供帮助。
10、结论与未来的工作
在本文中,我们总结了 region 内部署 RDMA 以支持 Azure 中的存储工作负载的相关经验。由于 Azure 的基础设施的高度复杂性和异构性带来了一系列新的挑战。为了应对这些挑战,我们对网络基础设施进行了多项更改。如今,Azure 中大约 70% 的流量是 RDMA,并且所有 Azure region 都支持 region 内 RDMA。RDMA 帮助我们显着提高磁盘 I/O 性能并节省 CPU 资源。
未来,我们计划通过系统架构、硬件加速、拥塞控制等方面的创新,进一步完善我们的存储系统,我们还计划将 RDMA 带到更多场景.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号