Hive数据仓库DDL应用
原创

Hive数据仓库DDL应用
假设张三是xx公司的大数据开发工程师,现在xx Music有一千万用户在每天播放音乐和收藏音乐,那么张三要如何设计音乐榜单数据仓库来进行数据分析呢。
定义数据表
create database z3music;
use z3music;创建一个用于存储音乐榜单数据的表。考虑到音乐榜单可能包含歌曲的标题、演唱者、发行时间、播放量等信息,张三可以这样定义表结构:
CREATE TABLE music_charts (
id INT,
title STRING,
artist STRING,
release_date DATE,
plays INT
)
STORED AS ORC;分析:这里使用了ORC文件格式,它提供了高效的压缩和编码机制,适合存储大量数据
查看表结构:
desc music_charts;
desc formatted music_charts;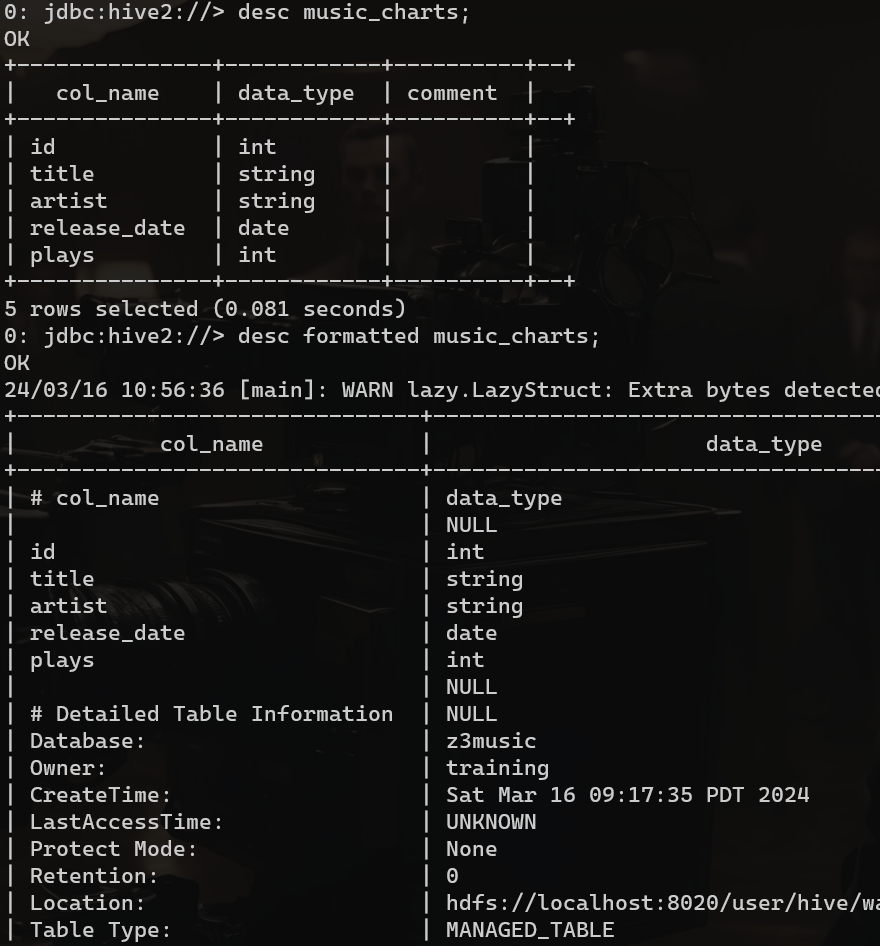
使用分区表
为了提高查询效率,张三可以根据实际需求对音乐榜单数据进行分区。例如,可以按照年份进行分区:
CREATE TABLE partitioned_music_charts (
id INT,
title STRING,
artist STRING,
release_date DATE,
plays INT
)
PARTITIONED BY (year INT)
STORED AS ORC;查看分区表结构:
desc partitioned_music_charts;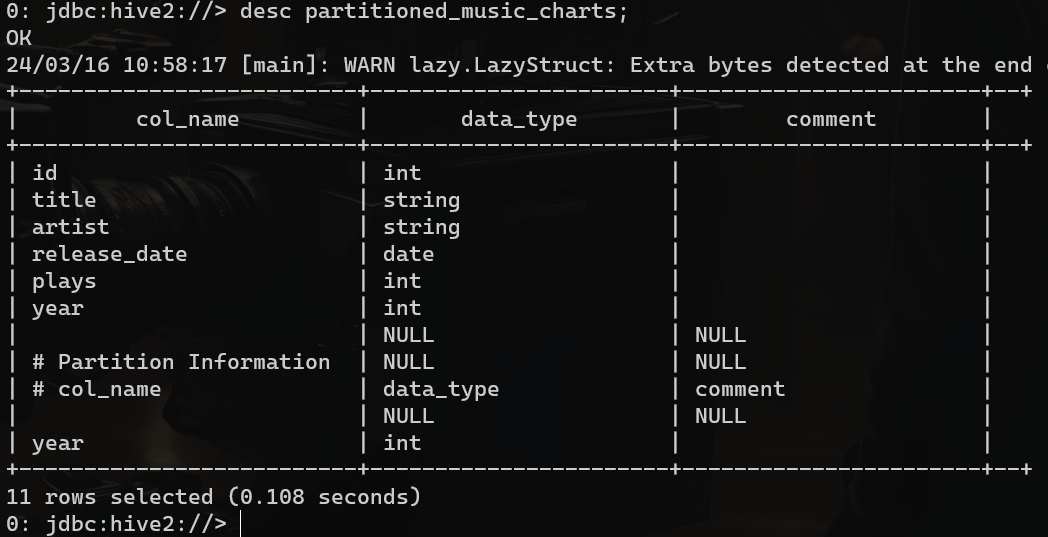
在插入数据时,指定分区字段的值:
INSERT INTO TABLE partitioned_music_charts PARTITION (year=2020)
VALUES (1, '喜羊羊与灰太狼', '张三', '2020-01-01', 9999);
INSERT INTO TABLE partitioned_music_charts PARTITION (year=2020)
VALUES (2, '美羊羊', '张三', '2020-01-01', 10000);查看表中分区:
show partitions partitioned_music_charts;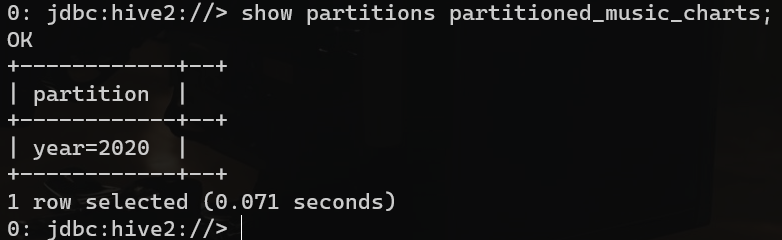
这样,Hive会根据分区字段的值将数据存储在相应的目录下,查询时也可以只扫描指定的分区,从而提高查询速度。
使用外部表
如果音乐榜单数据存储在HDFS或其他存储系统上,张三可以使用外部表来直接访问这些数据,而不需要将数据导入Hive中。外部表的定义与普通表类似,但需要在CREATE TABLE语句中加上EXTERNAL关键字:
CREATE EXTERNAL TABLE external_test (
id INT,
title STRING,
artist STRING,
release_date DATE,
plays INT
)
LOCATION '/path/to/hdfs/data';这样,Hive会直接读取HDFS中指定路径下的数据,而不会将其存储在Hive的默认仓库中。
使用视图
为了简化复杂的查询逻辑,张三可以创建视图来封装一些常用的查询操作。例如,可以创建一个视图来展示每年播放量最高的歌曲:
CREATE VIEW top_songs_per_year AS
SELECT year, title, artist, plays
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY year ORDER BY plays DESC) AS rank
FROM partitioned_music_charts
) t
WHERE t.rank = 1;分析:这个视图使用了窗口函数来计算每年每首歌曲的排名,并通过子查询和WHERE子句筛选出每年播放量最高的歌曲。
通过视图统计数据:
select * from top_songs_per_year;
补充练习:导入数据
分析表和查询视图都已经定义好了,那么现在张三需要很多数据来测试效果。
尝试在MySQL中生成模拟数据并将其导入到music_charts表中
步骤 1: 定义数据表
在MySQL中定义数据表music_charts且具有适当的列和数据类型:
create database music_data;
use music_data;
CREATE TABLE IF NOT EXISTS music_charts (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
artist VARCHAR(255) NOT NULL,
release_date DATE NOT NULL,
plays INT NOT NULL
);步骤 2: 生成模拟数据
使用MySQL的内置函数来生成10000行模拟数据:
DELIMITER //
CREATE PROCEDURE InsertRandomMusicData(IN rowCount INT)
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < rowCount DO
INSERT INTO music_charts (title, artist, release_date, plays)
VALUES (
CONCAT('Song Title ', FLOOR(RAND() * 1000)),
CONCAT('Artist Name ', FLOOR(RAND() * 1000)),
DATE_ADD('2000-01-01', INTERVAL FLOOR(RAND() * 30000) DAY),
FLOOR(RAND() * 1000000)
);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL InsertRandomMusicData(10000);分析:存储过程InsertRandomMusicData接受一个参数rowCount,表示要插入的行数。存储过程内部使用WHILE循环重复插入数据行,每一行由生成随机的歌曲标题、艺术家名称、发布日期和播放次数组成。
步骤 3: 检查数据
执行存储过程后查询music_charts表来检查数据是否已经成功插入:
select count(*) from music_charts;
select * from music_charts limit 20;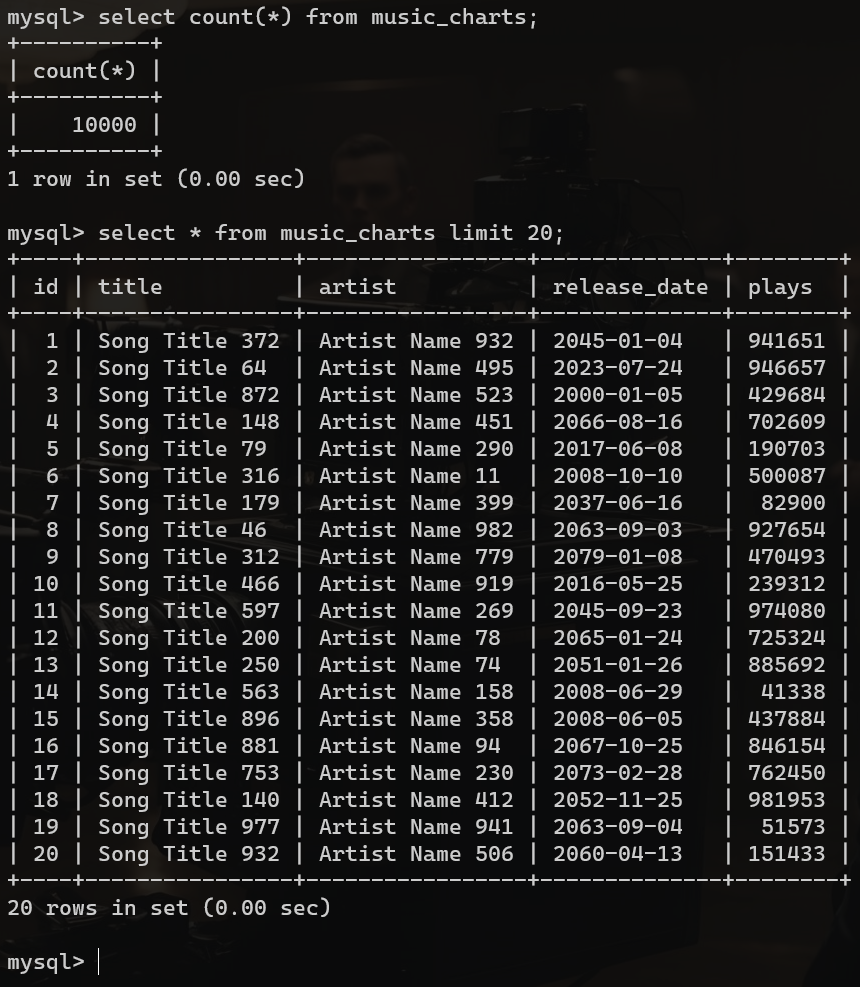
步骤 4: 导出到csv文件
SELECT *
INTO OUTFILE '/tmp/music_charts.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM music_charts;分析:csv文件中字段(也就是列)之间用逗号分隔,行之间用换行符分隔。
完成导出后,回到Linux的命令行,使用命令查看文件的前20行数据:
head -20 /tmp/music_charts.csv
# tail -20 /tmp/music_charts.csv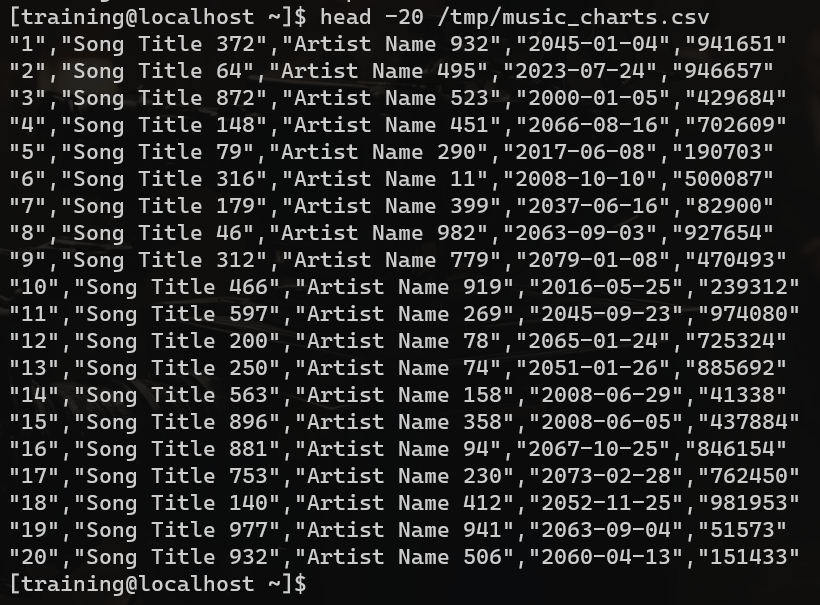
分析:导出的数据中每一列上都使用引号引起来,所以第一列和第五列可以使用awk脚本来处理去掉引号,此处略去该操作过程
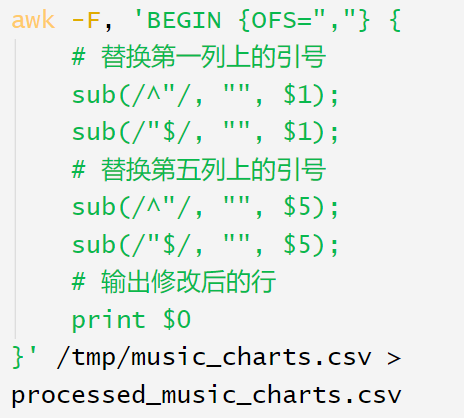
步骤 5: 在Hive中加载数据
此处可以尝试将csv文件导入到HDFS中,然后在Hive中创建外部表直接引用这个csv文件(否则也可以使用别的方式加载数据):
hadoop fs -mkdir /user/hive/csv_data
hadoop fs -put /tmp/music_charts.csv /user/hive/csv_data/
hadoop fs -ls /user/hive/csv_data/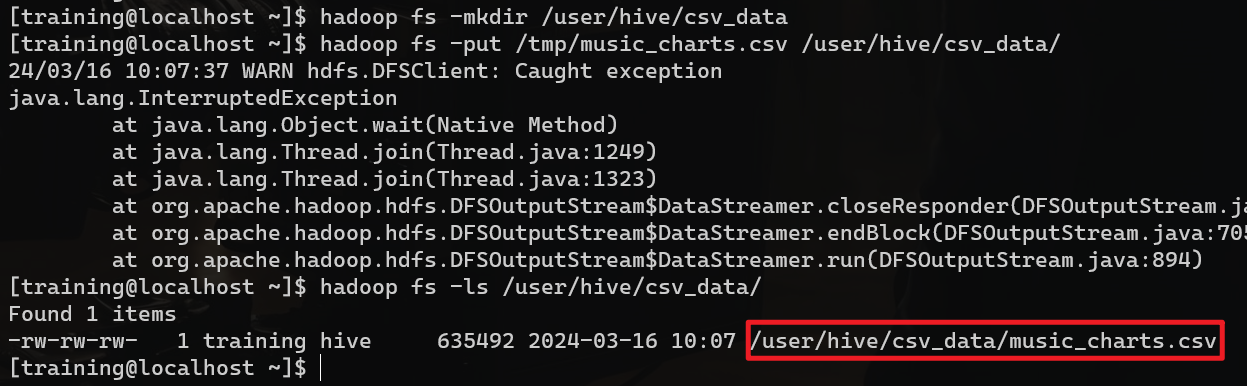
CREATE EXTERNAL TABLE IF NOT EXISTS music_charts_external (
id INT,
title STRING,
artist STRING,
release_date STRING,
plays INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/csv_data/';这样数据已经全部存在外部表music_charts_external中了。
desc formatted music_charts_external;select count(*) from music_charts_external;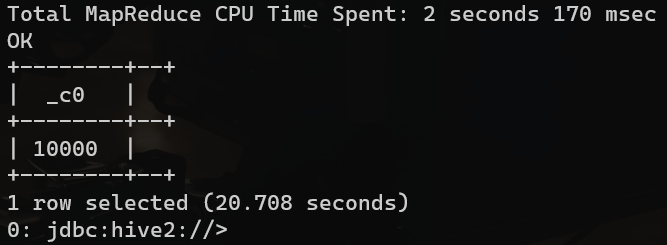
分析:在真实的数据仓库应用中,通常整个过程通过编写Java或者Scala程序完成。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号