Mojo-一门为 AI 而生的语言
原创
toc
前言
Python 因其灵活性和易用性而成为全球最受欢迎的编程语言之一,但是其缓慢的性能和速度是开发人员面临的两个最重大的挑战,已经有开发人员开始用 C++ 重写 Python 开发的模型了,以获得更好的性能。但是,对于人工智能开发者来说,C++和Python这俩种语言并不能有效的发挥其优势,C++和Python语言本身所应用的场景是不一样的,这也是目前人工智能所面对的, Mojo 就是被设计来解决这个问题的,Mojo是由 Swift 编程语言和 LLVM 编译器基础设施的创建者 Chris Lattner 设计,为 Python 的速度限制提供了一种新颖的解决方案。
本节我们将学习Mojo 语言以及Mojo语言为什么被誉为专门为AI设计的语言,学完本节,你将对Mojo有一个更加深入的了解。

一、Mojo 简介
Mojo 是Modular 推出的一种新的人工智能编程语言,你可以理解为是Python 的高级版本,同时,它还具备了 C++ 和 Rust 等编程语言的核心功能,可以提供更好的性能和控制力。Mojo将友好性和高性能高效的结合起来,从而兼顾了俩种好语言各自的优势,弥补了相互的不足。Mojo能够构建复杂的可扩展且高效的人工智能模型,同时开发人员还不必从头开始学习新语言,如果您熟悉 Python和 C 编程语言,您可以轻松学习Mojo 。
Mojo 是 Python 的超集,就像 TypeScript 是 JavaScript 的超集一样。除了新的关键字和函数之外,任何 Python 程序员都可以使用它来理解和构建程序。Mojo通过集成缓存、多线程和分布式计算等技术实现了高性能编译器技术,同时Mojo通过自动调整和元编程实现了对各种硬件的代码优化。

Mojo 具有如下高级特性:
- 支持类 Python 语法:Python 开发人员可以轻松学习 Mojo,因为 Python 是现代 AI/ML 开发背后的主要编程语言。
- 支持直接使用 Python 库:确保Mojo与 Python 的完全互操作性。
- 支持JIT(just-in-time)和AOT(ahead-of-time)编译:Mojo 编译器通过高级优化技术,能够直接生成 GPU/TPU 代码。
- 支持全控制内存布局、并发性等低层技术:Mojo极大的提升了运行性能。
二、Mojo 核心技术
Mojo具备如下核心特性:
- 底层编程:Mojo 是一种高级编程语言,它通过 MLIR(多级中间表示)(一种可扩展的中间表示格式)提供对低级原语的访问,这使得 Mojo 程序员能够实现零成本抽象,同时仍然利用强大的编译器优化。
- 切片优化和自动调整: Mojo 通过内置的切片优化工具,可通过将计算划分为适合快速缓存的较小切片来改进缓存局部性和内存访问模式,Mojo 中的 Autotune 模块提供了自适应编译的接口,同时Mojo支持通过自动调整代码来帮助您找到目标硬件的最佳参数。
- 所有权和借用者技术: Mojo 使用所有权和借用者系统来管理内存,无需垃圾收集器,并确保一致的运行时性能,Mojo 的编译器通过静态分析变量的生命周期,并在不再使用数据时立即释放数据。
- 内存管理: Mojo提供了类似于C++和Rust的使用指针的手动管理系统。
三、Mojo 技术优势
- 速度增强:虽然 Python 最大的障碍是其性能速度,但 Mojo 的设计就是为了规避这一挑战。与 Python、Scala 和 C++ 相比,Mojo 的速度呈指数级增长,数字表明它比 Python 快 35,000 倍。
- 兼容AI 硬件:Mojo 是专为在 AI 硬件(例如CUDA 的 GPU)上编程而精心设计,通过使用 MLIR 来管理不同的硬件类型,但是不会增加代码及计算的复杂性。
- Python超集:作为Python的超集,Mojo不需要学习全新的编程语言,因为它与Python完全兼容。
- 自动调整:Mojo 的自动调整功能可优化代码以确保更好的性能,它会自动找到人工智能开发人员输入的参数的最佳值,从而大大简化编程过程,充分利用人工智能硬件。
- 平铺优化:Mojo 包含一个内置的平铺优化工具,可以有效地缓存和重用数据,这有助于通过在给定时间使用彼此靠近的内存并重用来优化性能。
- 并行计算:Mojo 支持并行和并发编程,允许函数独立运行,并且不会影响程序的整体流程,人工智能开发人员可以利用它来执行复杂的计算,而不会影响人工智能程序的速度,可将执行速度提高2,000倍。
四、Mojo 语法学习
Mojo 的语法深受 Python 的影响,被誉为 Python 的超集,其语法与 Python 非常类似,同时还引入了新功能,如let、var、struct、 和fn来定义变量、结构和函数。例如,“你好,世界!” Mojo 中的程序看起来与 Python 中的程序一模一样:
print("Hello Mojo!")1.变量
Mojo 支持let和var声明,在编写Mojo 代码时,我们可以使用关键字let声明特定变量,var与 Rust 中声明变量的方式类似,关键字let表示变量不可更改,而var表示可以修改,Mojo通过在编译时实施限制来提高性能。
以下是如何使用这些声明的基本示例:
def addNumbers(num1, num2):
let sum = num1
if sum != num2:
let newNum = num2
print(newNum)
addNumbers(2, 3)我们还可以指定变量类型,一个包含多种数据类型的示例:
def guessLuckyNumber(guess) -> Bool:
let luckyNumber: Int = 37
var result: StringLiteral = ""
if guess == luckyNumber:
result = "You guessed right!"
print(result)
return True
else:
result = "You guessed wrong!"
print(result)
return False
guessLuckyNumber(37)
2.struct
Mojo 中的struct类似 Python 的关键字class,Python 中的类的创建时间动态且缓慢的,而Mojo中的struct类型则类似于 C/C++ 和 Rust中的对象构建过程,它们具有在编译时确定的固定内存布局,它们被直接插入或内联到其容器中,而不需要单独的内存引用,从而实现了运行时的极致性能。
结构体的简单定义如下:
struct MyPair:
var first: Int
var second: Int
fn __init__(inout self, first: Int, second: Int):
self.first = first
self.second = second3.Mojo示例
- 1) 通过
struct创建CAR类。 - 2) 定义变量类型, “speed”是 Float32,“model”是String, String 不是内置类型,因此我们必须导入它。
- 3) 初始化变量,类似于 Python 的初始化函数,通过
fn函数定义,一种仅包含车速,另一种包含车速和车型。 - 4) 创建对象,以
CAR300 的速度创建一个对象。 - 5) 打印汽车的型号。
from String import String
struct CAR:
var speed: Float32
var model: String
fn __init__(inout self, x: Float32):
"""Car with only speed"""
self.speed = x
self.model = 'Base'
fn __init__(inout self, r: Float32, i: String):
"""Car with Speed and model"""
self.speed = r
self.model = i
my_car=CAR(300)
print(my_car.model)
>>> Base观察上述示例,Mojo 的编程风格和功能与 Python 非常类似,作为 Python 的扩展,Mojo增强了其性能和内存管理功能。通过Mojo,我们可以快速训练模型、实现更快的模型推理(即使使用 CPU)、在几秒钟内分析海量数据集并进行实时模拟。
4.集成Python示例
Mojo 并没有放弃 Python 的特性,我们可以将任何 Python 模块导入到 Mojo 程序中,并从 Mojo 类型创建 Python 类型,这使得 Mojo 成为一种强大的语言,并且结合了 C 的性能和 Python 庞大的生态系统。
以下是在 Mojo 中导入 Python 模块的方法:
from PythonInterface import Python
let np = Python.import_module("numpy") 此示例从PythonInterface模块导入Python,并使用它来访问numpy模块。凭借这种灵活性,Python 开发人员可以轻松使用 Mojo,因为他们可以利用 Python 生态系统和现有的 Python 知识。但是,由于 Mojo 专注于性能,因此它可能不支持 Python 的所有动态功能,并非所有 Python 库都保证与 Mojo 无缝协作。
5.Mojo与Python语法比较
下面示例中,我们将分别编写Python代码和Mojo代码,来学习他们之间的异同。
在示例中,我们将创建一个 Mojo 函数,该函数将添加两个参数,我们需要为函数的参数指定类型,需要使用箭头声明返回类型。
fn add(x: Int, y: Int) -> Int:
return x + y
z = add(3, 5)
print(z)
>>> 8但是在 Python 中编程时,我们可以选择定义函数而无需显式声明参数和输出类型,Python使的该过程更加动态和直接。
def add(x, y):
return x + y
z = add(3, 5)
print(z)
>>> 8五、Mojo 性能比较及测试
Mojo 的速度比 Python 快出惊人的 35,000 倍,大大超过了 PyPy、Scala 和 C++ 等竞争对手,以下是 Mojo 与其他语言的基准测试结果:
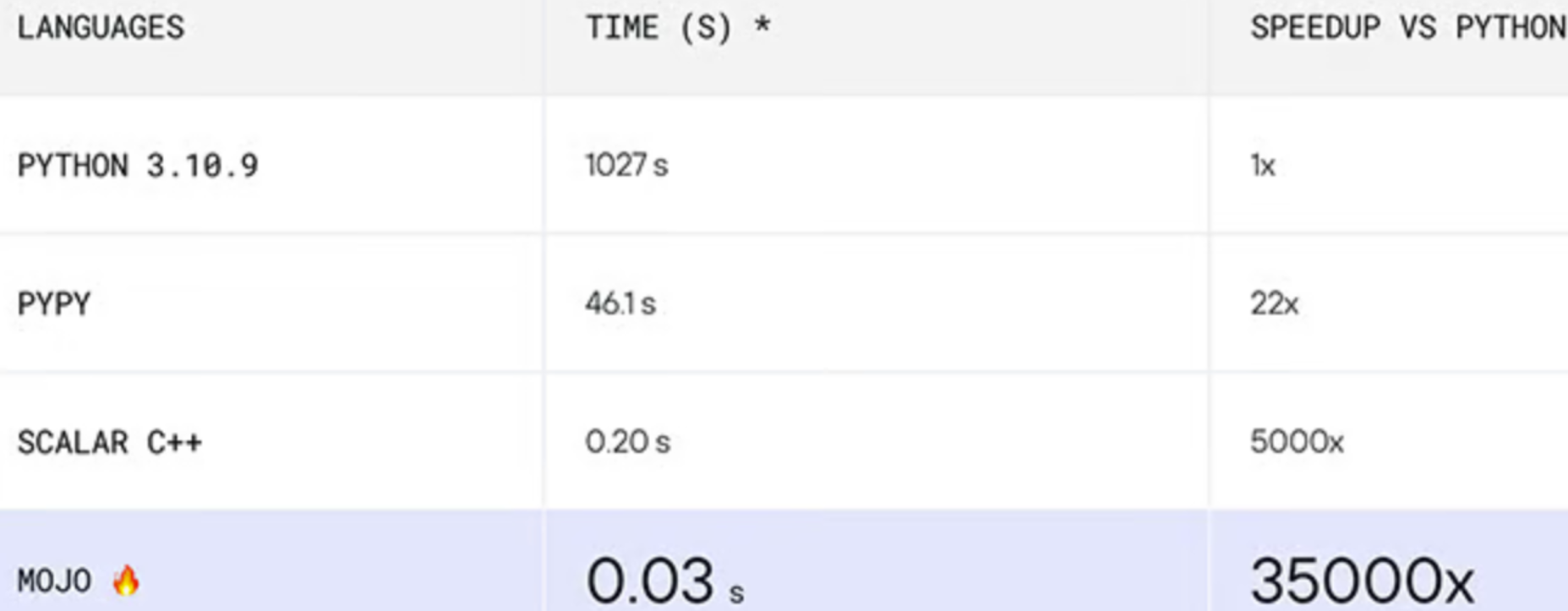
这里我们通过矩阵乘法示例来对比Python与Mojo的性能,看看Mojo到底能比Python快多少。
1.Python 矩阵算法
from timeit import timeit
import numpy as np
class Matrix:
def __init__(self, value, rows, cols):
self.value = value
self.rows = rows
self.cols = cols
def __getitem__(self, idxs):
return self.value[idxs[0]][idxs[1]]
def __setitem__(self, idxs, value):
self.value[idxs[0]][idxs[1]] = value
def benchmark_matmul_python(M, N, K):
A = Matrix(list(np.random.rand(M, K)), M, K)
B = Matrix(list(np.random.rand(K, N)), K, N)
C = Matrix(list(np.zeros((M, N))), M, N)
secs = timeit(lambda: matmul_python(C, A, B), number=2)/2
gflops = ((2*M*N*K)/secs) / 1e9
print(gflops, "GFLOP/s")
return gflops
python_gflops = benchmark_matmul_python(128, 128, 128).to_float64()
>>> 0.0022564560694965834 GFLOP/s2.Mojo代码的实现
//忽略非核心代码
//......
fn matrix_getitem(self: object, i: object) raises -> object:
return self.value[i]
fn matrix_setitem(self: object, i: object, value: object) raises -> object:
self.value[i] = value
return None
fn matrix_append(self: object, value: object) raises -> object:
self.value.append(value)
return None
fn matrix_init(rows: Int, cols: Int) raises -> object:
var value = object([])
return object(
Attr("value", value), Attr("__getitem__", matrix_getitem), Attr("__setitem__", matrix_setitem),
Attr("rows", rows), Attr("cols", cols), Attr("append", matrix_append),
)
def benchmark_matmul_untyped(M: Int, N: Int, K: Int, python_gflops: Float64):
C = matrix_init(M, N)
A = matrix_init(M, K)
B = matrix_init(K, N)
for i in range(M):
c_row = object([])
b_row = object([])
a_row = object([])
for j in range(N):
c_row.append(0.0)
b_row.append(random_float64(-5, 5))
a_row.append(random_float64(-5, 5))
C.append(c_row)
B.append(b_row)
A.append(a_row)
@parameter
fn test_fn():
try:
_ = matmul_untyped(C, A, B)
except:
pass
var secs = benchmark.run[test_fn](max_runtime_secs=0.5).mean()
_ = (A, B, C)
var gflops = ((2*M*N*K)/secs) / 1e9
var speedup : Float64 = gflops / python_gflops
print(gflops, "GFLOP/s, a", speedup, "x speedup over Python")
benchmark_matmul_untyped(128, 128, 128, python_gflops)
>>> 0.019322323885887414 GFLOP/s, a 8.563128769530282 x speedup over Python我们毫不费力的获得了8倍的速度
3.为Mojo指定入参类型
此处我们忽略Matrix 定义以及matmul_naive定义,只列最核心的代码:
//忽略非核心代码
//......
lias M = 1024
alias N = 1024
alias K = 1024
@always_inline
fn bench[
func: fn (Matrix, Matrix, Matrix) -> None](base_gflops: Float64):
var C = Matrix[M, N]()
var A = Matrix[M, K].rand()
var B = Matrix[K, N].rand()
@always_inline
@parameter
fn test_fn():
_ = func(C, A, B)
var secs = benchmark.run[test_fn](max_runtime_secs=1).mean()
A.data.free()
B.data.free()
C.data.free()
var gflops = ((2 * M * N * K) / secs) / 1e9
var speedup: Float64 = gflops / base_gflops
print(gflops, "GFLOP/s, a", speedup, "x speedup over Python")
bench[matmul_naive](python_gflops)
>>> 5.3335685138294373 GFLOP/s, a 2363.6926000599515 x speedup over Python4.引入向量化
//忽略非核心代码
//......
alias nelts = simdwidthof[DType.float32]() * 2
fn matmul_vectorized_0(C: Matrix, A: Matrix, B: Matrix):
for m in range(C.rows):
for k in range(A.cols):
for nv in range(0, C.cols, nelts):
C.store(m, nv, C.load[nelts](m, nv) + A[m, k] * B.load[nelts](k, nv))
# Handle remaining elements with scalars.
for n in range(nelts * (C.cols // nelts), C.cols):
C[m, n] += A[m, k] * B[k, n]
bench[matmul_vectorized_0](python_gflops)
>>> 27.943656514151261 GFLOP/s, a 12383.869064371152 x speedup over Python5.并行化引入
//忽略非核心代码
//......
from algorithm import parallelize
fn matmul_parallelized(C: Matrix, A: Matrix, B: Matrix):
@parameter
fn calc_row(m: Int):
for k in range(A.cols):
@parameter
fn dot[nelts : Int](n : Int):
C.store[nelts](m,n, C.load[nelts](m,n) + A[m,k] * B.load[nelts](k,n))
vectorize[dot, nelts, size = C.cols]()
parallelize[calc_row](C.rows, C.rows)
bench[matmul_parallelized](python_gflops)
>>> 860.6608444221323 GFLOP/s, a 381421.49366734456 x speedup over Python我们观察到将 Python 代码导入 Mojo 导致性能提升8 倍。通过在 Python 实现中引入类型,性能进一步增强,高达2363倍。我们还可以利用矢量化、并行化、平铺和自动调整等技术实现了381421 倍的性能提升。
小结
本节我们学习了Mojo语言,介绍了Mojo的核心技术,Mojo的技术优势,Mojo的语法学习,并且对Mojo与其他语言进行了性能测试。
有的同学可能会问,Mojo性能及兼容性这么好,Mojo对AI开发人员要求一定很高吧,其实不然,Mojo 是一种一体化人工智能编程语言,是 Python 的超集,语法与Python类似。它可以导入Python模块、库和框架来使用Python的能力。因此,它既适合初学者,也适合经验丰富的程序员。但是,开发人员必须了解 Python 基础知识及其生态系统才能开始在 Mojo 上进行编程。此外,他们还需要学习 C++ 和 Rust 等高控制语言的基础知识。
可能又有同学要问了,Mojo这么友好,会取代Python吗?其实不会,由于 Mojo 处于早期开发阶段并且缺乏必要的功能,因此很难确定 Mojo 作为通用编程语言的潜力。Mojo 专为机器学习应用程序而设计,不适用于其他领域,例如 Web 后端、流程自动化或网页设计,虽然开发人员未来可能会扩展其功能,但 Mojo 目前的重点是针对机器学习应用程序进行优化。在机器学习和人工智能领域,它可能有能力超越Python,但是不太可能很快完全取代 Python 在数据科学和其他软件开发领域的主导地位。此外,与 Python 相比,Mojo 的模块和库选择有限,Mojo 可能需要数年时间才能赶上 Python 的开发水平。所以同学们也不要过于担心了。
写到最后:Mojo,一门像 Python 一样简单、像 C++ 一样快速的新编程语言,一门用于构建人工智能应用程序的革命性新编程语言,Mojo 正在为人工智能开发者带来了高效和稳健的新时代,躁动起来吧,同学们,现在正是我们开启人工智能开发未来之旅的最佳时机,让我们一起走进它,了解它,学习它,融入它,开启我们的AI时代。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。