[ibd2sql] mysql frm 文件结构解析
原创
[ibd2sql] mysql frm 文件结构解析
原创
导读
准备给ibd2sql加个解析 mysql 5.7 的ibd文件功能. mysql 8.0的元数据信息是存储在ibd文件的sdi page里面的. 但是mysql 5.7 的表结构信息是存储在 frm 文件的, 所以就得解析下这个frm文件了. 本以为它是文本文件, 很遗憾, 还是二进制的....

好在 mysql官方有个工具 mysqlfrm 来解析frm文件. 而且是使用python写的(尽管是py2). 这就方便很多了, 就不需要去源码里面一个个找了. 由于我们的ibd2sql是使用python3写的, 所以需要转换下. 干脆重写吧(还是太年轻了.jpg). python2转python3的注意事项见文末
mysql-utilities
mysql-utilities 是mysql官方提供的一套运维工具, 使用python2编写的. 很好用. 这里就只看其中的 mysqlfrm工具了
下载地址: https://downloads.mysql.com/archives/utilities/
项目地址: https://github.com/mysql/mysql-utilities
我们可以使用mysqlfrm工具解析frm文件得到ddl信息. 例子:
mysqlfrm --diagnostic /data/mysql_3308/mysqldata/db1/t1.frm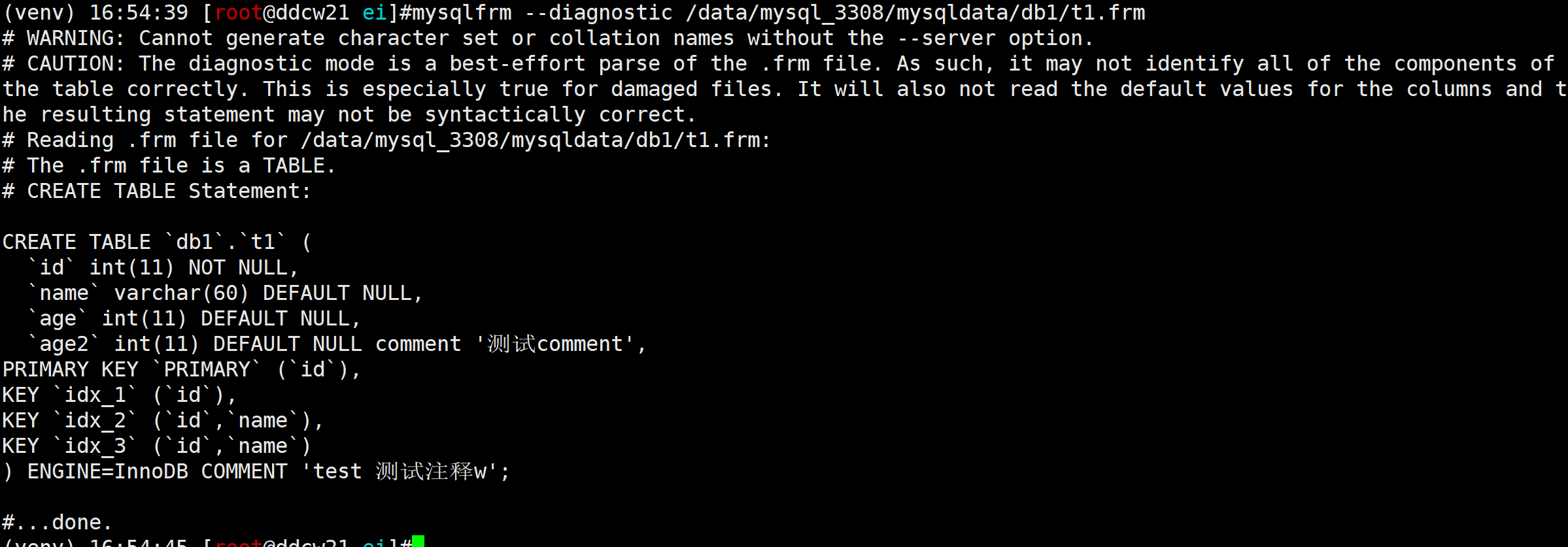
挺好用的.
mysql frm结构解析
重点来了, 我们要自己来解析frm文件结构.
对象 | 大小(字节) | 描述 |
|---|---|---|
frm_type | 2 | frm类型, 510 是表 22868 是视图 |
HEADER_FORMAT | 64 | 文件头, |
KEY | 索引信息 | |
default | 默认值 | |
engine | 存储引擎(HEADER_FORMAT也有) | |
comment | 表的注释 | |
record | 字段信息 |
看起来还是比较简单的. 接下来我们来看看详情.
frm_type就不看了, 没啥好说的, 就2字节, 510 是表 22868 是视图 .
HEADER_FORMAT
文件头信息, 记录的信息多得很. 来看看结构吧 _HEADER_FORMAT = "<BBBBHHIHHIHHHHHBBIBBBBBIIIIBBBHH"
贼长, 我们只解析其中的一部分信息.
假设我们使用 header = self.read_format(_HEADER_FORMAT,64) 解析出来了相应的结构
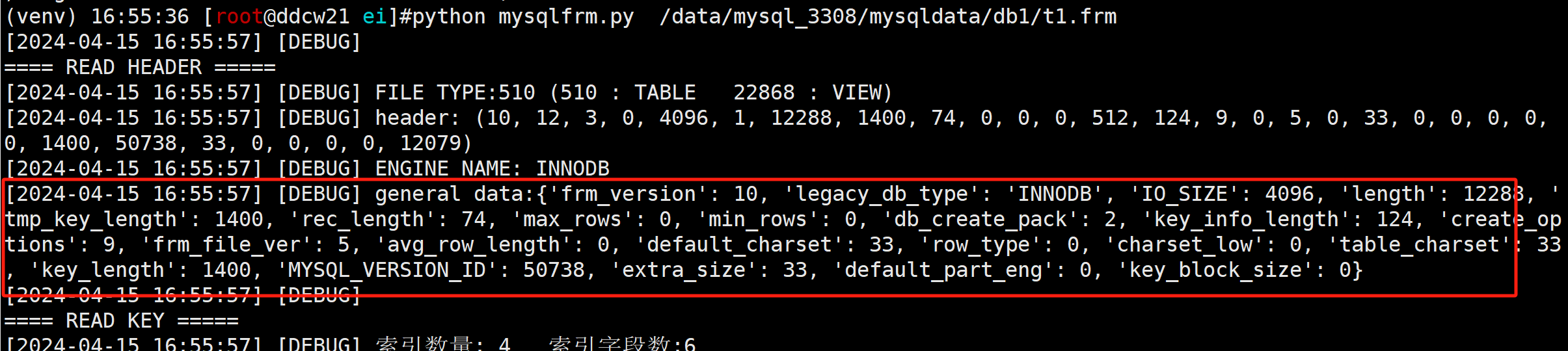
对象 | 大小(字节) | 描述 |
|---|---|---|
frm_version | 1 | frm的版本信息, file命令也是读的这个值 |
legacy_db_type | 1 | 存储引擎 |
IO_SIZE | 2 | |
tmp_key_length | 2 | key长度 |
rec_length | 2 | 字段长度 |
default_charset | 1 | 默认字符集 |
MYSQL_VERSION_ID | 4 | mysql版本 |
我们不详细解析frm文件, 所以很多信息其实是不需要的. 字符集的号可以去数据库里面查(看之前的文章就可以)
KEY
我们再来看索引信息.
索引是其实位置是 IO_SIZE 也就是4096字节的位置开始
对象 | 大小(字节) | 描述 |
|---|---|---|
num_keys | 1 | 索引数量 |
num_key_parts | 1 if um_keys & 0x80 else 2 | 索引字段数量 |
key_info | 索引详情(哪些字段, 无name) | |
key_name | 索引名字 | |
comment | 索引注释 |
很多大小都是要计算的, 无法直接给出来. 索引的注释我们这里就不解析了.
先来看看key_info
key_info
对象 | 大小(字节) |
|---|---|
flags | 2 |
key_length | 2 |
num_parts | 1 |
algorithm | 1 |
block_size | 2 |
key_parts | |
comment |
key_parts里面记录了这个索引有哪些具体的字段, 结构如下
对象 | 大小(字节) |
|---|---|
field_num | 2 |
offset | 2 |
key_type | 2 |
key_part_flag | 1 |
length | 2 |
key_name
索引名字就比较简单了, 就是一个字符串, 不记录大小, 读完key_info后的第一字节就是终止字符
terminator = self.f.read(1)
default
默认值, 我们这里只是简单解析下frm文件, 就不看默认值了.
engine
我们已经在header里面找到了存储引擎的信息, 这里也跳过了.
comment
表的注释. 结构很简单, 就是大小加上值就可以了.
对象 | 大小 |
|---|---|
size | 1 |
data | size |
record
字段信息, 这个才是我们着重看的, 也比较复杂....
对象 | 大小 | 描述 |
|---|---|---|
rec_header | 26 | 字段头(13*2) |
flag | 7 | |
fields_per_screen | 1 | |
flag | 46 | |
col_names | 字段名字 | |
column_data | 字段信息 | |
comment | 注释 | |
又是一大堆. 我们先看看rec_header部分. 都是2字节的对象, 比较方便解析. 我们主要看字段数量, 和哪些能为空的字段

col_names
字段名字存储结构也很简单, 就是1字节大小,然后加数据即可
对象 | 大小 |
|---|---|
size | 1 |
data | size |
column_data
字段元数据信息, 比较多, 我们挑一挑

对象 | 大小 | 描述 |
|---|---|---|
field_length | 1 | 字段长度 |
field_type | 1 | 字段类型 |
comment | 1 | 注释 |
default | 2 | 默认值 |
结构差不多就是这样, 这里省去了很多细节.
演示
按照上面的结构, 我们来解析下frm文件, 我这里就提前写好了脚本, 很多信息是复用的mysql-utilities的代码. 我加了个debug功能, 方便查看解析过程. 这个脚本的目的也是仅供学习, 实际要解析的话, 还是使用官方那个.
注: 我这里把stderr给过滤掉了, 那是debug信息.
python mysqlfrm.py /data/mysql_3308/mysqldata/db1/t1.frm 2>/dev/null
我们把拿到的结构去数据库里面执行看下
CREATE TABLE IF NOT EXISTS `t1`(
`id` int ,
`name` varchar (20),
`age` int ,
`age2` int COMMENT '测试comment',
PRIMARY KEY (`id`),
KEY `idx_1` (`id`),
KEY `idx_2` (`id`,`name`),
KEY `idx_3` (`id`,`name`)
) engine=INNODB COMMENT 'test 测试注释w';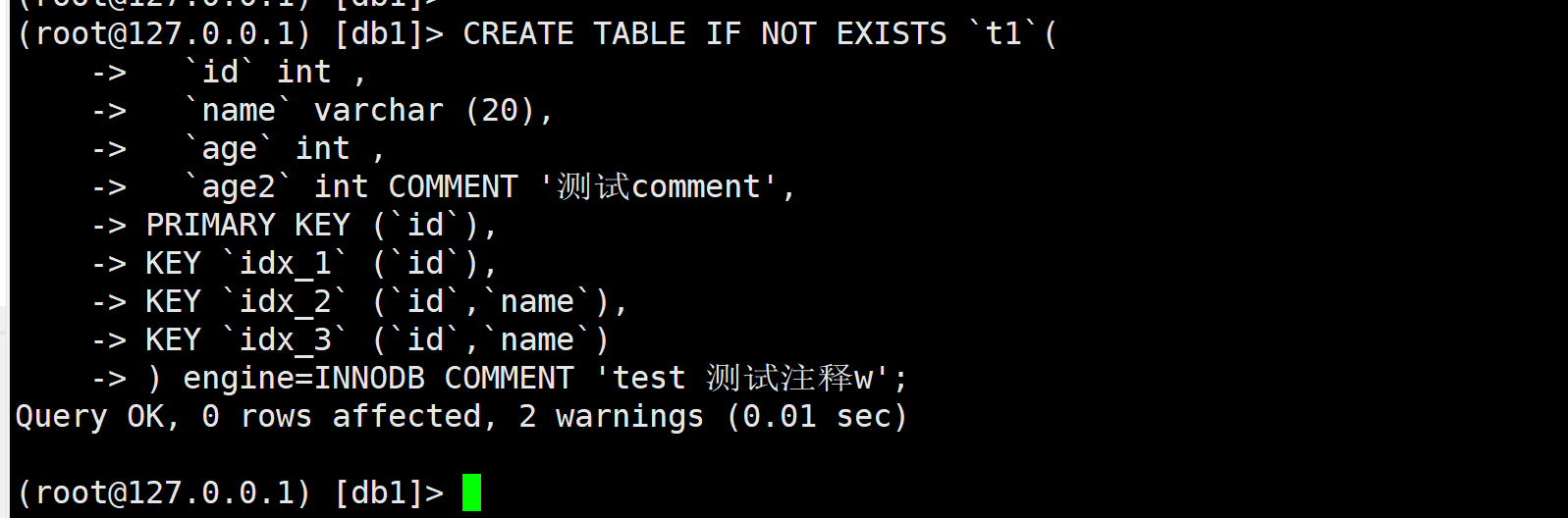
看起来是没毛病的.
我们再来看看debug信息, 较多
(venv) 17:37:53 [root@ddcw21 ei]#python mysqlfrm.py /data/mysql_3308/mysqldata/db1/t1.frm
[2024-04-15 17:40:34] [DEBUG]
==== READ HEADER =====
[2024-04-15 17:40:34] [DEBUG] FILE TYPE:510 (510 : TABLE 22868 : VIEW)
[2024-04-15 17:40:34] [DEBUG] header: (10, 12, 3, 0, 4096, 1, 12288, 1400, 74, 0, 0, 0, 512, 124, 9, 0, 5, 0, 33, 0, 0, 0, 0, 0, 1400, 50738, 33, 0, 0, 0, 0, 12079)
[2024-04-15 17:40:34] [DEBUG] ENGINE NAME: INNODB
[2024-04-15 17:40:34] [DEBUG] general data:{'frm_version': 10, 'legacy_db_type': 'INNODB', 'IO_SIZE': 4096, 'length': 12288, 'tmp_key_length': 1400, 'rec_length': 74, 'max_rows': 0, 'min_rows': 0, 'db_create_pack': 2, 'key_info_length': 124, 'create_options': 9, 'frm_file_ver': 5, 'avg_row_length': 0, 'default_charset': 33, 'row_type': 0, 'charset_low': 0, 'table_charset': 33, 'key_length': 1400, 'MYSQL_VERSION_ID': 50738, 'extra_size': 33, 'default_part_eng': 0, 'key_block_size': 0}
[2024-04-15 17:40:34] [DEBUG]
==== READ KEY =====
[2024-04-15 17:40:34] [DEBUG] 索引数量: 4 索引字段数:6
[2024-04-15 17:40:34] [DEBUG] KEY INFO: {'flags': 0, 'key_length': 4, 'num_parts': 1, 'algorithm': 0, 'block_size': 0, 'key_parts': [], 'comment': ''}
[2024-04-15 17:40:34] [DEBUG] key_part_info {'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}
[2024-04-15 17:40:34] [DEBUG] KEY INFO: {'flags': 1, 'key_length': 4, 'num_parts': 1, 'algorithm': 0, 'block_size': 0, 'key_parts': [], 'comment': ''}
[2024-04-15 17:40:34] [DEBUG] key_part_info {'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}
[2024-04-15 17:40:34] [DEBUG] KEY INFO: {'flags': 65, 'key_length': 64, 'num_parts': 2, 'algorithm': 0, 'block_size': 0, 'key_parts': [], 'comment': ''}
[2024-04-15 17:40:34] [DEBUG] key_part_info {'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}
[2024-04-15 17:40:34] [DEBUG] key_part_info {'field_num': 2, 'offset': 5, 'key_type': 0, 'key_part_flag': 128, 'length': 60}
[2024-04-15 17:40:34] [DEBUG] KEY INFO: {'flags': 4161, 'key_length': 64, 'num_parts': 2, 'algorithm': 0, 'block_size': 0, 'key_parts': [], 'comment': ''}
[2024-04-15 17:40:34] [DEBUG] key_part_info {'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}
[2024-04-15 17:40:34] [DEBUG] key_part_info {'field_num': 2, 'offset': 5, 'key_type': 0, 'key_part_flag': 128, 'length': 60}
[2024-04-15 17:40:34] [DEBUG] terminator:b'\xff'
[2024-04-15 17:40:34] [DEBUG] KEY_DATA: {'num_keys': 4, 'num_key_parts': 6, 'key_names': ['PRIMARY', 'idx_1', 'idx_2', 'idx_3'], 'keys': [{'flags': 0, 'key_length': 4, 'num_parts': 1, 'algorithm': 0, 'block_size': 0, 'key_parts': [{'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}], 'comment': ''}, {'flags': 1, 'key_length': 4, 'num_parts': 1, 'algorithm': 0, 'block_size': 0, 'key_parts': [{'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}], 'comment': ''}, {'flags': 65, 'key_length': 64, 'num_parts': 2, 'algorithm': 0, 'block_size': 0, 'key_parts': [{'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}, {'field_num': 2, 'offset': 5, 'key_type': 0, 'key_part_flag': 128, 'length': 60}], 'comment': ''}, {'flags': 4161, 'key_length': 64, 'num_parts': 2, 'algorithm': 0, 'block_size': 0, 'key_parts': [{'field_num': 1, 'offset': 1, 'key_type': 6912, 'key_part_flag': 64, 'length': 4}, {'field_num': 2, 'offset': 5, 'key_type': 0, 'key_part_flag': 128, 'length': 60}], 'comment': ''}]}
[2024-04-15 17:40:34] [DEBUG]
==== READ DEFAULT VALUE =====
[2024-04-15 17:40:34] [DEBUG] OFFSET : 4216
[2024-04-15 17:40:34] [DEBUG] OFFSET : 5497
[2024-04-15 17:40:34] [DEBUG] num_bytes:74
default_values:b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00{\x00\x00\x00{\x00\x00\x00\x00'
[2024-04-15 17:40:34] [DEBUG]
==== READ ENGINE DATA =====
[2024-04-15 17:40:34] [DEBUG] OFFSET : 5571
[2024-04-15 17:40:34] [DEBUG] OFFSET : 5572
[2024-04-15 17:40:34] [DEBUG] ENGINE LEN:6 ENGINE NAME:InnoDB
[2024-04-15 17:40:34] [DEBUG]
==== READ COLUMN DATA =====
[2024-04-15 17:40:34] [DEBUG] OFFSET : 5580
[2024-04-15 17:40:34] [DEBUG] OFFSET : 8450
[2024-04-15 17:40:34] [DEBUG] 字段数量: 4
[2024-04-15 17:40:34] [DEBUG] COL METADATA: {'num_cols': 4, 'pos': 77, 'unknown': 93, 'n_length': 0, 'interval_count': 74, 'interval_parts': 19, 'int_length': 0, 'com_length': 0, 'null_fields': 3}
[2024-04-15 17:40:34] [DEBUG] fields_per_screen:4
[2024-04-15 17:40:34] [DEBUG] COLNO:1 COLNAME:id
[2024-04-15 17:40:34] [DEBUG] COLNO:2 COLNAME:name
[2024-04-15 17:40:34] [DEBUG] COLNO:3 COLNAME:age
[2024-04-15 17:40:34] [DEBUG] COLNO:4 COLNAME:age2
[2024-04-15 17:40:34] [DEBUG] COL NAME: ['id', 'name', 'age', 'age2']
[2024-04-15 17:40:34] [DEBUG] DATA TYPE: ('int', 4)
[2024-04-15 17:40:34] [DEBUG] col_def: {'field_length': 11, 'bytes_in_col': 11, 'recpos': 2, 'unireg': 0, 'flags': 27, 'flags_extra': 64, 'unireg_type': 0, 'charset_low': 0, 'interval_nr': 0, 'field_type': 3, 'field_type_name': ('int', 4), 'charset': 8, 'comment_length': 0, 'enums': [], 'comment': '', 'default': None}
[2024-04-15 17:40:34] [DEBUG] DATA TYPE: ('varchar', -1)
[2024-04-15 17:40:34] [DEBUG] col_def: {'field_length': 60, 'bytes_in_col': 60, 'recpos': 6, 'unireg': 0, 'flags': 0, 'flags_extra': 128, 'unireg_type': 0, 'charset_low': 0, 'interval_nr': 0, 'field_type': 15, 'field_type_name': ('varchar', -1), 'charset': 33, 'comment_length': 0, 'enums': [], 'comment': '', 'default': None}
[2024-04-15 17:40:34] [DEBUG] DATA TYPE: ('int', 4)
[2024-04-15 17:40:34] [DEBUG] col_def: {'field_length': 11, 'bytes_in_col': 11, 'recpos': 67, 'unireg': 0, 'flags': 27, 'flags_extra': 128, 'unireg_type': 0, 'charset_low': 0, 'interval_nr': 0, 'field_type': 3, 'field_type_name': ('int', 4), 'charset': 8, 'comment_length': 0, 'enums': [], 'comment': '', 'default': None}
[2024-04-15 17:40:34] [DEBUG] DATA TYPE: ('int', 4)
[2024-04-15 17:40:34] [DEBUG] col_def: {'field_length': 11, 'bytes_in_col': 11, 'recpos': 71, 'unireg': 0, 'flags': 27, 'flags_extra': 128, 'unireg_type': 0, 'charset_low': 0, 'interval_nr': 0, 'field_type': 3, 'field_type_name': ('int', 4), 'charset': 8, 'comment_length': 13, 'enums': [], 'comment': '', 'default': None}
[2024-04-15 17:40:34] [DEBUG] SKIP: b'\xffid\xffname\xffage\xffage2'
[2024-04-15 17:40:34] [DEBUG] age2 COMMENT: 测试comment
[2024-04-15 17:40:34] [DEBUG]
==== READ COMMENT =====
[2024-04-15 17:40:34] [DEBUG] OFFSET : 8657
[2024-04-15 17:40:34] [DEBUG] OFFSET : 8238
[2024-04-15 17:40:34] [DEBUG] TABLE COMMENT: test 测试注释w
[2024-04-15 17:40:34] [DEBUG]
==== TO DDL =====
CREATE TABLE IF NOT EXISTS `t1`(
`id` int ,
`name` varchar (20),
`age` int ,
`age2` int COMMENT '测试comment',
PRIMARY KEY (`id`),
KEY `idx_1` (`id`),
KEY `idx_2` (`id`,`name`),
KEY `idx_3` (`id`,`name`)
) engine=INNODB COMMENT 'test 测试注释w';
到此, 我们就能简单的解析frm文件了. 但ibd2sql不打算使用这个frm来实现对5.7的支持, 还是解析sdi方便点.
python2转python3注意事项
python2没得语法糖( f"{xx}") 但基本上都能直接转为python3. 存在部分需要注意的地方, 比如:
1. print 可以不用加括号
如果加括号的话, 对于使用中文的多个汉字的时候不会正常展示

2. int类型做除法计算的时候, 结果也是int
咋一看好像没毛病, 但实际上损失了精度. 如果默认这一特性的话, 在python3里面就要加int来强制转换

附源码
不推荐实际使用, 仅供学习使用. 所以就不放github了.
#!/usr/bin/env python3
# 参考的mysql的 mysqlfrm
# 要求python3 原版是python2就行的(注意python2 的 int/int = int).
import sys,os,struct
import datetime
try:
filename = sys.argv[1] #懒得判断了
except:
print(f"python3 {sys.argv[0]} xxxx.frm")
sys.exit(1)
# 一堆常量....
ENGINE_LIST = ["UNKNOWN","ISAM","HASH","MISAM","PISAM","RMS_ISAM","HEAP","ISAM","MERGE","MYISAM","MERGE","BDB","INNODB","GEMINI","NDBCLUSTER","EXAMPLE","ARCHIVE","CSV","FEDERATED","BLACKHOLE","PARTITION","BINLOG","SOLID","PBXT","FUNCTION","MEMCACHE","FALCON","MARIA","PERFORMANCE_SCHEMA"]
COL_TYPE = {0: ('decimal', None), 1: ('tinyint', 1), 2: ('smallint', 2), 3: ('int', 4), 4: ('float', 4), 5: ('double', 8), 6: ('NULL', 0), 7: ('timestamp', 4), 8: ('bigint', 8), 9: ('mediumint', 3), 10: ('date', 4), 11: ('time', 3), 12: ('datetime', 8), 13: ('year', 1), 14: ('date', 3), 15: ('varchar', -1), 16: ('bit', -2), 17: ('timestamp', 4), 18: ('datetime', 8), 19: ('time', 3), 246: ('decimal', None), 247: ('enum', 0), 248: ('set', 0), 249: ('tinyblob', 9), 250: ('mediumblob', 11), 251: ('longblob', 12), 252: ('blob', 10), 253: ('varchar', -1), 254: ('char', None), 255: ('geometry', 12)}
_TABLE_TYPE = 0x01fe # Magic number for table .frm files
_VIEW_TYPE = 0x5954 # Magic number for view .frm files
_FIELD_NR_MASK = 16383
_HA_USES_COMMENT = 4096
_HEADER_FORMAT = "<BBBBHHIHHIHHHHHBBIBBBBBIIIIBBBHH"
_COL_DATA = "<BBBBBBBBBBBBBBBH"
_KEY_ALG = ['UNDEFINED', 'BTREE', 'RTREE', 'HASH', 'FULLTEXT']
class mysqlfrm(object):
def __init__(self,):
self.offset = 0
self.bdata = b""
self.filename = ""
self.f = None
self.DEBUG = True
def debug(self,*argv,):
if self.DEBUG:
msg = f"[{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] [DEBUG] {' '.join([ str(x) for x in argv ])}\n"
sys.stderr.write(msg)
def open(self,filename):
self.filename = filename
try:
self.f = open(filename,'rb')
except Exception as e:
self.debug(str(e))
return False
return True
def close(self,):
try:
self.f.close()
except:
pass
def _read_header(self):
self.debug("\n==== READ HEADER =====")
file_type = self.read(2)
self.file_type = file_type
self.debug(f"FILE TYPE:{file_type} (510 : TABLE 22868 : VIEW)")
if file_type != _TABLE_TYPE:
self.debug("仅支持 表")
sys.exit(1) # raise mysqlfrm_error not_support
header = self.read_format(_HEADER_FORMAT,64)
self.debug(f"header: {header}")
engine_name = ENGINE_LIST[header[1]]
self.debug(f"ENGINE NAME: {engine_name}")
self.engine_name = engine_name
self.general_data = {
'frm_version': header[0],
'legacy_db_type': engine_name,
'IO_SIZE': header[4],
'length': header[6],
'tmp_key_length': header[7],
'rec_length': header[8],
'max_rows': header[10],
'min_rows': header[11],
'db_create_pack': header[12] >> 8, # only want 1 byte
'key_info_length': header[13],
'create_options': header[14],
'frm_file_ver': header[16],
'avg_row_length': header[17],
'default_charset': header[18],
'row_type': header[20],
'charset_low': header[21],
'table_charset': (header[21] << 8) + header[18],
'key_length': header[24],
'MYSQL_VERSION_ID': header[25],
'extra_size': header[26],
'default_part_eng': header[29],
'key_block_size': header[30],
}
self.debug(f"general data:{self.general_data}")
def _read_keys(self):
self.debug("\n==== READ KEY =====")
self.f.seek(self.general_data['IO_SIZE'])
num_keys = self.read(1)
if num_keys & 0x80:
next_byte = self.read(1)
num_keys = (next_byte << 7) | (num_keys & 0x7f)
low = self.read(1)
high = self.read(1)
num_key_parts = low + (high << 8)
self.read(2)
else:
num_key_parts = self.read(1)
self.read(4)
self.key_data = {
'num_keys': num_keys, #索引数量
'num_key_parts': num_key_parts, #索引相关的字段
'key_names': [],
'keys': [],
}
self.debug(f"索引数量: {self.key_data['num_keys']} 索引字段数:{self.key_data['num_key_parts']}")
for i in range(0, self.key_data['num_keys']):
key_info = {
'flags': self.read(2),
'key_length': self.read(2),
'num_parts': self.read(1),
'algorithm': self.read(1),
'block_size': self.read(2),
'key_parts': [],
'comment': "",
}
self.debug(f"KEY INFO: {key_info}")
for j in range(0, key_info['num_parts']):
key_part_info = {
'field_num' : self.read(2) & _FIELD_NR_MASK,
'offset' : self.read(2) - 1,
'key_type' : self.read(2) ,
'key_part_flag' : self.read(1) ,
'length' : self.read(2) ,
}
key_info['key_parts'].append(key_part_info)
self.debug("key_part_info",key_part_info)
self.key_data['keys'].append(key_info)
terminator = self.f.read(1) #终止符. 不知道长度, 就这样读
self.debug(f"terminator:{terminator}")
for i in range(0, self.key_data['num_keys']):
key_name = b""
char_read = b""
while char_read != terminator:
char_read = struct.unpack("c", self.f.read(1))[0]
if char_read != terminator:
key_name += char_read
self.key_data['key_names'].append(key_name.decode())
self.debug(f"KEY_DATA: {self.key_data}")
# 读注释
# 索引就先不读注释了吧...
self.f.read(1)
def _read_default_values(self):
self.debug("\n==== READ DEFAULT VALUE =====")
self.debug(f"OFFSET : {self.f.tell()}")
self.f.seek(self.general_data['IO_SIZE'] + self.general_data['tmp_key_length'] + 1,0)
self.debug(f"OFFSET : {self.f.tell()}")
num_bytes = self.general_data['rec_length']
self.default_values = self.f.read(num_bytes)
self.debug(f"num_bytes:{num_bytes}\n default_values:{self.default_values}")
def _read_engine_data(self):
self.debug("\n==== READ ENGINE DATA =====")
offset = self.general_data['IO_SIZE'] + self.general_data['tmp_key_length'] + self.general_data['rec_length']
self.debug(f"OFFSET : {self.f.tell()}")
self.f.seek(offset+2,0)
self.debug(f"OFFSET : {self.f.tell()}")
engine_len = self.read(2)
engine_str = self.read_char(engine_len)
self.debug(f"ENGINE LEN:{engine_len} ENGINE NAME:{engine_str}")
self.engine_str = engine_str
def _read_column_data(self):
self.debug("\n==== READ COLUMN DATA =====")
io_size = self.general_data['IO_SIZE']
record_offset = io_size + self.general_data['tmp_key_length'] + self.general_data['rec_length']
offset = ((int((record_offset + self.general_data['key_info_length']) / io_size) + 1) * io_size) + 258
self.debug(f"OFFSET : {self.f.tell()}")
self.f.seek(offset,0)
self.debug(f"OFFSET : {self.f.tell()}")
data = self.read_format("<HHHHHHHHHHHHH",26)
self.num_cols = data[0]
self.debug(f"字段数量: {self.num_cols}")
self.col_metadata = {
'num_cols': data[0],
'pos': data[1],
'unknown': data[2],
'n_length': data[3],
'interval_count': data[4],
'interval_parts': data[5],
'int_length': data[6],
'com_length': data[8],
'null_fields': data[12],
}
self.debug(f"COL METADATA: {self.col_metadata}")
self.f.read(7)
fields_per_screen = self.read(1)
self.debug(f"fields_per_screen:{fields_per_screen}")
self.f.read(46)
col_names = self._read_column_names(fields_per_screen)
self.col_names = col_names
self.debug(f"COL NAME: {col_names}")
self.f.read(1)
self.column_data = self._read_column_metadata()
#读注释:
col_len = 0
for colname in col_names:
col_len += len(colname) + 1
self.debug("SKIP: ",self.f.read(col_len))
self.f.read(2)
for i in range(0, len(col_names)):
if self.column_data[i]['comment_length'] > 0:
self.column_data[i]['comment'] = self.read_char(self.column_data[i]['comment_length'])
self.debug(f"{col_names[i]} COMMENT: ",self.column_data[i]['comment'])
def _read_column_names(self, fields_per_screen):
screens_read = 1
cols = []
col_in_screen = 0
for i in range(0, self.num_cols):
if (col_in_screen == fields_per_screen):
pass
else:
col_in_screen += 1
col_len = self.read(1)
col_data = self.read_char(col_len-1)
self.debug(f"COLNO:{col_in_screen} COLNAME:{col_data}")
if (i < self.num_cols - 1):
self.f.read(3)
cols.append(col_data)
return cols
def _read_column_metadata(self,):
column_data = []
for i in range(0, self.num_cols):
data = self.read_format(_COL_DATA, 17)
data_type = COL_TYPE[data[13]]
self.debug(f"DATA TYPE: {data_type}")
col_def = {
'field_length': data[2], # 1, +3
'bytes_in_col': int(data[3]) + (int(data[4]) << 8),
'recpos': (int(data[6]) << 8) + (int(data[5])) + (int(data[4]) << 16),
'unireg': data[7], # 1, +8
'flags': data[8], # 1, +9
'flags_extra': data[9], # 1, +10
'unireg_type': data[10], # 1, +11
'charset_low': data[11], # 1, +12
'interval_nr': data[12], # 1, +13
'field_type': data[13], # 1, +14
'field_type_name': data_type,
'charset': data[14], # 1, +15
'comment_length': data[15], # 2, +17
'enums': [],
'comment': "",
'default': None,
}
self.debug(f"col_def: {col_def}")
column_data.append(col_def)
return column_data
def _read_comment(self):
self.debug("\n==== READ COMMENT =====")
io_size = self.general_data['IO_SIZE']
record_offset = io_size + self.general_data['tmp_key_length'] + self.general_data['rec_length']
offset = ((int(record_offset / io_size) + 1) * io_size) + 46
self.debug(f"OFFSET : {self.f.tell()}")
self.f.seek(offset,0)
self.debug(f"OFFSET : {self.f.tell()}")
com_chars = self.read_char(self.read(1))
self.debug(f"TABLE COMMENT: {com_chars}")
self.comment_str = com_chars
def _build_create_statement(self):
self.debug("\n==== TO DDL =====")
ddl = f"CREATE TABLE IF NOT EXISTS `{self.table_name}`(\n"
#字段信息
col = ""
i = 0
for x in self.column_data:
col += f" `{self.col_names[i]}` {x['field_type_name'][0]} "
if x['field_type_name'][0] == "varchar":
col += f"({int(x['field_length']/3)})" #都当作mb3
col += f"{ 'COMMENT '+ repr(x['comment']) if x['comment_length'] > 0 else ''}"
col += ",\n"
i += 1
col = col[:-2]
ddl += col
#索引信息
idx = ",\n"
for x in range(len(self.key_data['key_names'])):
keyname = self.key_data['key_names'][x]
if keyname == "PRIMARY":
keyname = "PRIMARY KEY "
else:
keyname = f"KEY `{keyname}` "
idx += f"{keyname}("
idx += ",".join([ f"`{self.col_names[keypart['field_num']-1]}`" for keypart in self.key_data['keys'][x]['key_parts'] ])
idx += "),\n"
idx = idx[:-2]
ddl += idx
#存储引擎等
ddl += f"\n) engine={self.engine_name} "
ddl += f"COMMENT {repr(self.comment_str)}" if self.comment_str != "" else ""
ddl += ";"
return ddl
def getddl(self,):
self.table_name = os.path.basename(self.filename).split(".frm")[0]
self._read_header()
self._read_keys()
self._read_default_values()
self._read_engine_data()
self._read_column_data()
self._read_comment()
return self._build_create_statement()
def read(self,n, bt='little'): #int 不对外的, 但自己调用起来方便, 就不加_了.
return int.from_bytes(self.f.read(n), bt)
def read_format(self,ff,n):
return struct.unpack(ff,self._read(n))
def _read(self,n): #binary
return self.f.read(n)
def read_char(self,n): #char
ff = f"{n}s"
return struct.unpack(ff,self.f.read(n))[0].decode()
# for test
#filename = "/data/mysql_3308/mysqldata/db1/t1.frm"
aa = mysqlfrm()
aa.open(filename)
aa.DEBUG = True
print(aa.getddl())原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
