玩转 AIGC:仅需三步,在 Mac 电脑部署本地大模型,打造私人 ChatGPT
原创
玩转 AIGC:仅需三步,在 Mac 电脑部署本地大模型,打造私人 ChatGPT
原创
运维有术
发布于 2024-05-02 18:55:06
发布于 2024-05-02 18:55:06
2024 年云原生运维实战文档 99 篇原创计划 第 011 篇 |玩转 AIGC「2024」系列 第 001 篇
你好,欢迎来到运维有术。
今天分享的内容是 玩转 AIGC「2024」 系列文档中的 仅需三步,在 Mac 电脑打造个人 ChatGPT。
本文将详细介绍仅用三条命令在 M1 芯片的 Mac Pro 上部署本地大模型,实现私人的 ChatGPT。
1. 前提介绍
1.1 硬件介绍
- 型号: MacBook Pro
- 芯片:Apple M1(M1/M2/M3 任何芯片的都可以,越高端的性能越好)
- 内存: 16 G(内存越大越好,8G 也能体验,但是只能用小模型)
- 硬盘: 256 G(越大越好)
1.2 软件需求
所有软件都需要用 brew 安装,请确保电脑上已经正确安装配置了 brew。
用 Mac 没有用过 brew?请在终端执行下面的命令安装吧,你将开启一扇新的大门。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"提示: 上面的命令安装成功是有概率的,如果因网络问题导致安装失败,请参考Homebrew 镜像使用帮助
如果不喜欢或是不习惯使用命令行在 Mac 上安装软件,本文介绍的软件都有对应的 App 下载。可自行前往软件官网下载。
1.3 私人 ChatGpt 成员
- Ollama,大模型管理工具,下载运行各种量化后的 GGUF 格式的大模型
- 大模型,本文选择 qwen:14b。
- ChatBox,利用本地大模型实现聊天对话的工具
GGUF 是什么?
- GGUF(GPT-Generated Unified Format)是一种大模型文件格式
- 由著名开源项目 llama.cpp 创始人 Georgi Gerganov 提出并定义
- 是一种针对大规模机器学习模型设计的二进制格式文件规范,主要用于高效存储和交换大模型的预训练结果
GGUF 的主要优势在于,它能够将原始的大模型预训练结果经过特定优化后转换成这种格式,从而可以更快地被载入使用,并消耗更低的资源。
最为关键的一点是,它允许用户使用 CPU 来运行 LLM。 真正做到了,GPU 不够 CPU 来凑,但也不是什么 CPU 都有资格加入的。
2. 第一步:安装本地大模型管理工具
本地大模型的运行、管理工具种类繁多,比较有名且被各种 LLMOps 平台支持的有 Ollama、 LocalAI等。经过体验对比,我暂时选择了 Ollama。
Ollama 在 Mac 上的安装有三种方式:
- 在 Ollama 官网下载 Mac 安装包,手工安装
Download-Ollama-on-macOS
- 用 Docker 运行 Ollama(在 M1 以上芯片的 Mac 上不要用,体验不到 GPU 的快乐)
- 用 brew 命令行自动安装(简单方便,强烈推荐)
打开终端工具,执行下面的命令,安装 Ollama。
- 安装命令
brew install ollama --cask- 正确的安装结果如下
MacBook-Pro at ~ ❯ brew install ollama --cask
==> Downloading https://github.com/ollama/ollama/releases/download/v0.1.32/Ollama-darwin.zip
==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-2e65be/658928958/3e980350-d263-484d-83b2-765009b8c2c
######################################################################################################################################## 100.0%
==> Installing Cask ollama
==> Moving App 'Ollama.app' to '/Applications/Ollama.app'
==> Linking Binary 'ollama' to '/opt/homebrew/bin/ollama'
🍺 ollama was successfully installed!安装成功后,Mac 的启动台里也会有一个 Ollama 应用的图标,可以在应用启动台中点击图标启动 Ollama。
3. 第二步:下载本地大模型
本地大模型的选择太多了,2024 年各种开源大模型真的是如雨后春笋般涌出,各大知名厂商都开源了自己的大模型产品。
目前关注热度比较高的开源大模型有 Llama 3、Phi-3、Gemma、Mistral、qwen。
Ollama 官方列出了支持的部分大模型列表如下,完整的可以去 Ollama Models 列表查找。
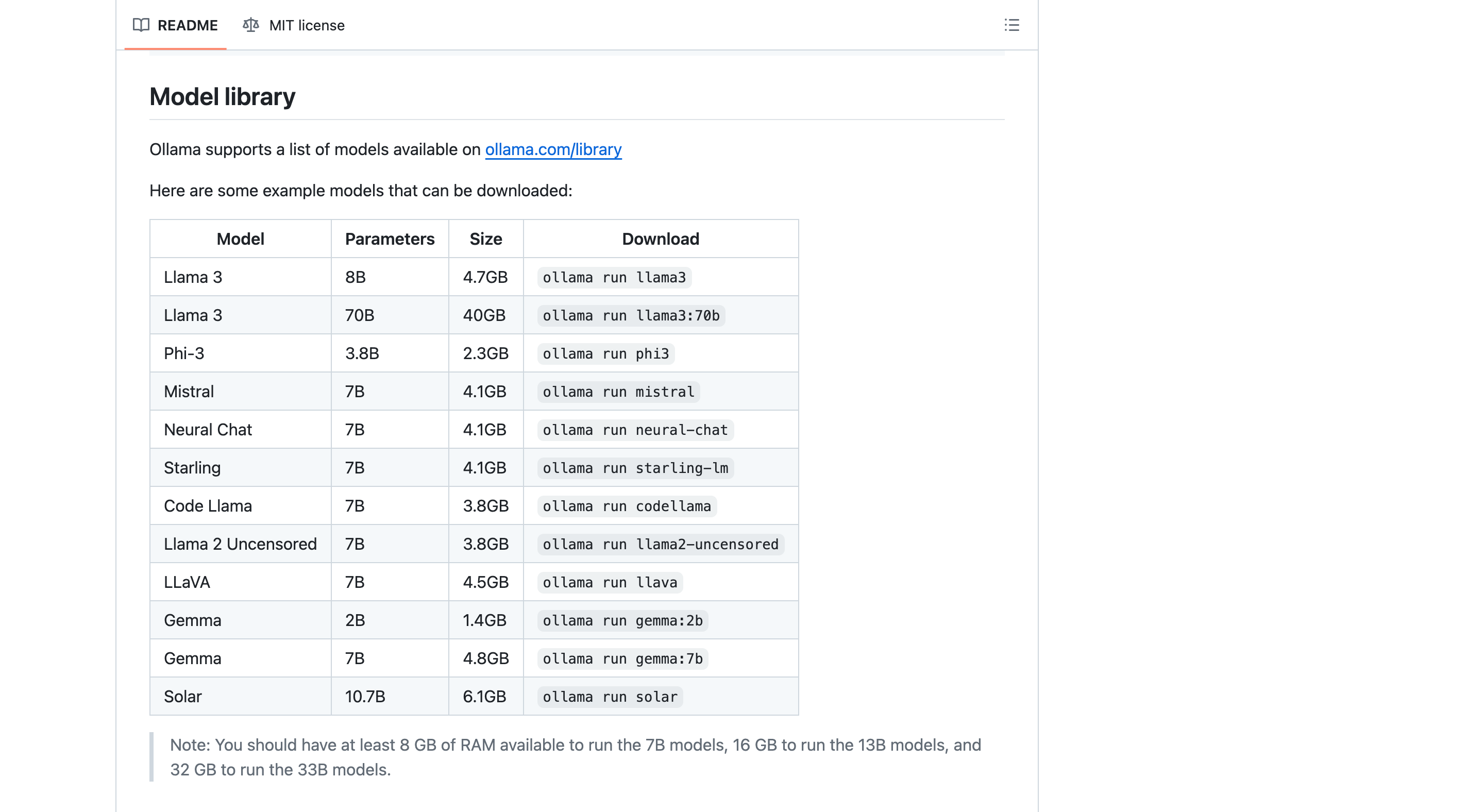
ollama-model-library
qwen 是阿里开源的大模型。在中文支持和理解上理论上应该更好。所以,本文以 qwen:14b 为例进行演示。大家可以自己体验对比其他模型,选择更适合自己的。
由于我的电脑是 16G 内存,理论上可以拥有 16G 显存,理论上可以驾驭量化后的 GGUF 格式的 14B 模型。你可以根据自己电脑的内存大小选择合适的模型,B 的数值越大越好,同样对显存、内存容量的要求也就越高。
打开终端工具,执行下面的命令,启动 Ollama
- 启动命令
ollama serve- 正确的结果如下
$ ollama serve [14:53:09]
time=2024-05-02T14:53:12.883+08:00 level=INFO source=images.go:817 msg="total blobs: 0"
time=2024-05-02T14:53:12.883+08:00 level=INFO source=images.go:824 msg="total unused blobs removed: 0"
time=2024-05-02T14:53:12.883+08:00 level=INFO source=routes.go:1143 msg="Listening on [::]:11434 (version 0.1.32)"
time=2024-05-02T14:53:12.884+08:00 level=INFO source=payload.go:28 msg="extracting embedded files" dir=/var/folders/zf/_67hsc3138917m4jbddhh94h0000gn/T/ollama1535104819/runners
time=2024-05-02T14:53:12.911+08:00 level=INFO source=payload.go:41 msg="Dynamic LLM libraries [metal]"额外再打开一个终端,执行下面的命令,下载并运行 qwen 大模型
- 启动命令
ollama run qwen:14b- 下载过程(前期速度杠杠滴,最后的时候会慢下来)
➞ ollama run qwen:14b
pulling manifest
pulling de0334402b97... 48% ▕█████████████████████████████████████ ▏ 3.9 GB/8.2 GB 82 MB/s 51s- 整个下载过程
➞ ollama run qwen:14b
pulling manifest
pulling de0334402b97... 100% ▕███████████████████████████████████████████████████████████████████████████████▏ 8.2 GB
pulling 7c7b8e244f6a... 100% ▕███████████████████████████████████████████████████████████████████████████████▏ 6.9 KB
pulling 1da0581fd4ce... 100% ▕███████████████████████████████████████████████████████████████████████████████▏ 130 B
pulling f02dd72bb242... 100% ▕███████████████████████████████████████████████████████████████████████████████▏ 59 B
pulling 007d4e6a46af... 100% ▕███████████████████████████████████████████████████████████████████████████████▏ 484 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> 你是谁
我是通义千问,由阿里云开发的人工智能助手。我可以回答各种问题、提供信息和与用户进行对话。有什么可以帮到你的吗?
>>> Send a message (/? for help)说明: 运行成功后会有一个命令行的对话窗口,可以在命令行体验大模型的响应。
默认的模型下载存放路径为 ~/.ollama/models,可以配置环境变量,改变模型的存储路径。
将下面的内容加入 ~/.zshrc,然后再启动 Ollama。
export OLLAMA_MODELS="自定义路径"- 查看已下载的大模型
MacBook-Pro at ~ ❯ ollama list
NAME ID SIZE MODIFIED
qwen:14b 80362ced6553 8.2 GB 2 hours ago4. 第三步: 安装前端 ChatBox
本地大模型的前端管理工具包括各种 LLMOps平台,可选择性太多太多了,真的是让人眼花缭乱。
Ollama 官方也列出了很多适配的 Web 或是 Desktop 形式的前端工具。
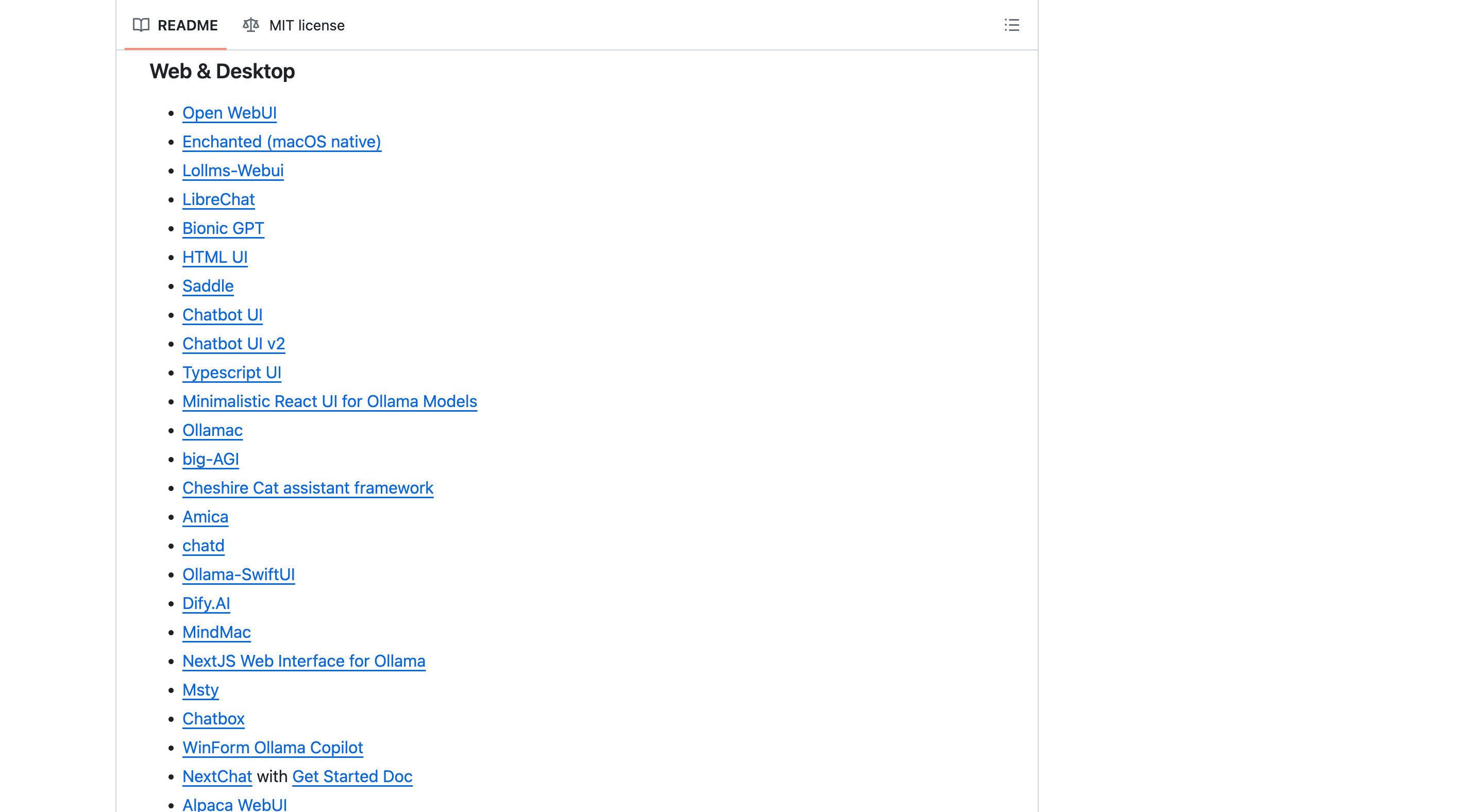
ollama-web-desktop
本文为了快速体验本地大模型的对话效果,选择了上手比较简单的 Chatbox,其他的工具我们会在后续的系列文档中逐渐介绍。
打开终端工具,执行下面的命令,安装 ChatBox
MacBook-Pro at ~ ❯ brew install chatbox --cask
==> Downloading https://github.com/Bin-Huang/chatbox/releases/download/v1.3.5/Chatbox-1.3.5-arm64.dmg
==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-2e65be/610260322/12174856-6f0b-425a-a294-89c94d011a8
######################################################################################################################################## 100.0%
==> Installing Cask chatbox
==> Moving App 'chatbox.app' to '/Applications/chatbox.app'
🍺 chatbox was successfully installed!安装成功后,Mac 的启动台里也会有一个 ChatBox 应用的图标,可以在应用启动台中点击图标启动 ChatBox。

chatbox-icon
接下来我们启动 ChatBox,在图形化窗口体验 qwen 大模型的对话推理能力。
第一次启动 Chatbox 需要按照提示做一些初始化配置。
点击「开始设置」
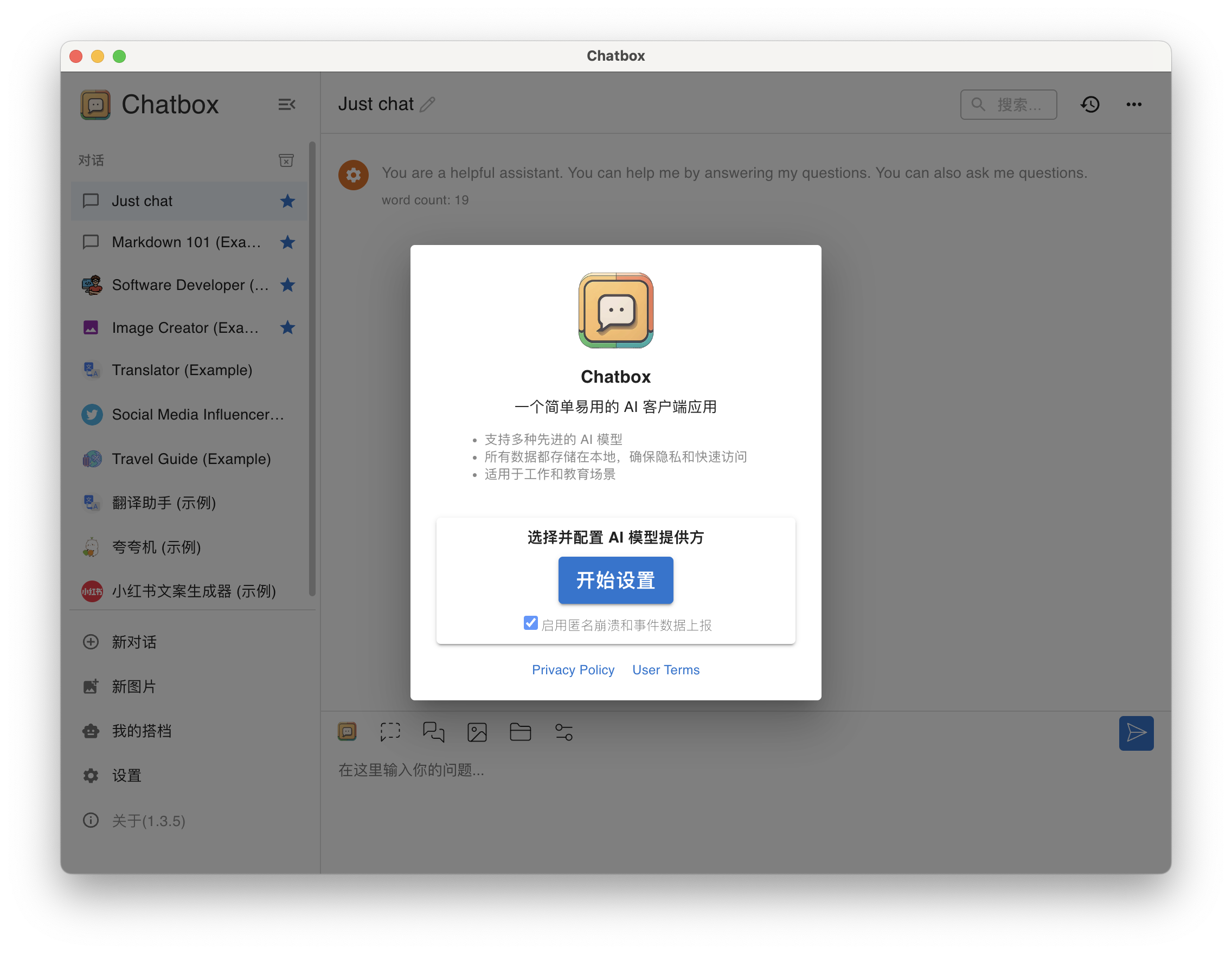
chatbox-config-1
设置模型
- AI 模型提供方,选择 Ollama
- API 域名,输入
http://localhost:11434 - 模型,选择qwen:14b,API 域名设置正确后,模型下拉列表会显示所有可用的模型。
- 严谨与想象(Temperature)使用默认值
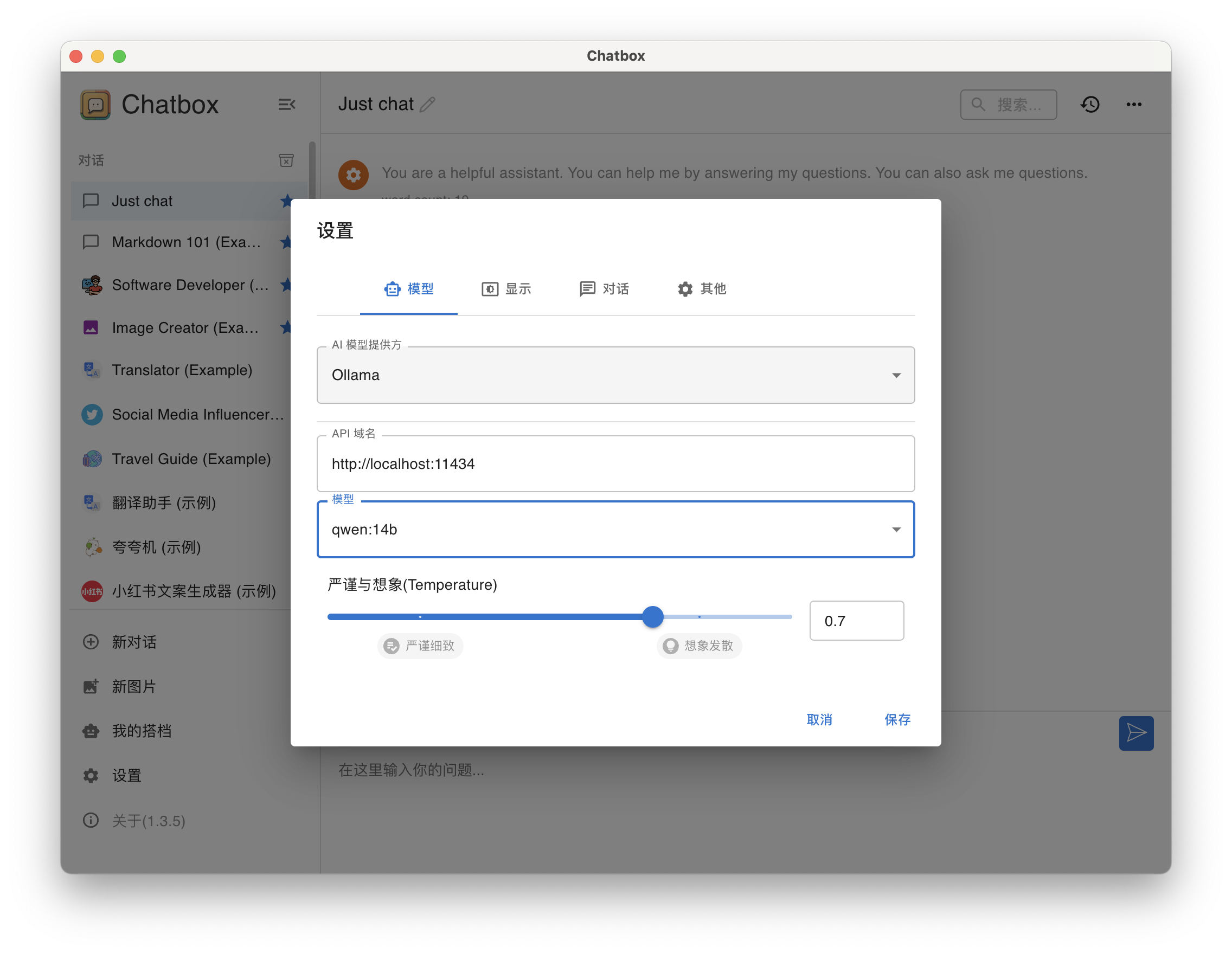
chatbox-config-2
设置「显示」
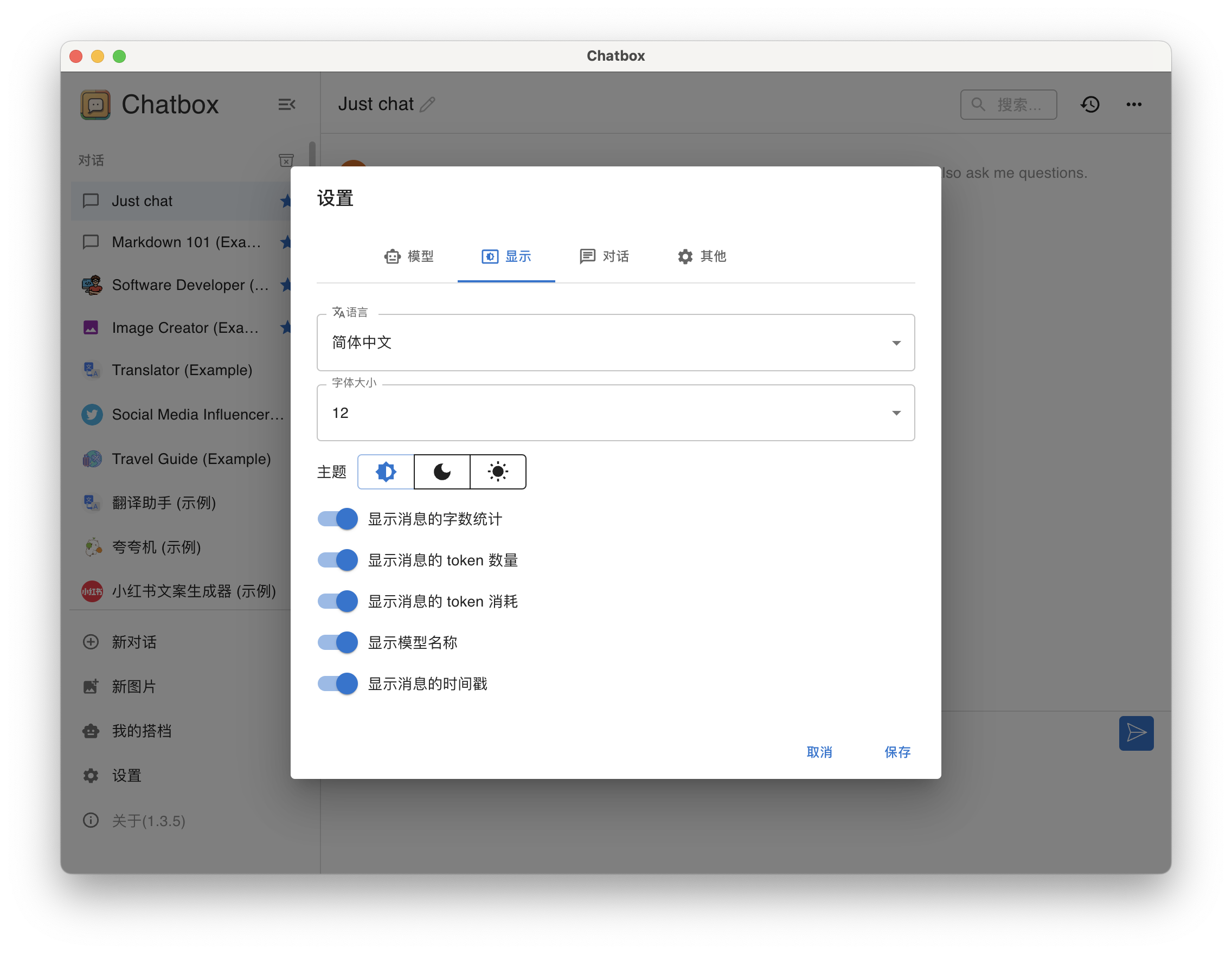
chatbox-config-3
全部设置完成后点击「保存」按钮。
接下来我们使用几个测试题,考验一下 qwen:14b 的推理能力。
在 Chatbox 的 Just chat 对话窗口中提问。
问题1:鲁迅为什么打周树人。
答:貌似还可以。
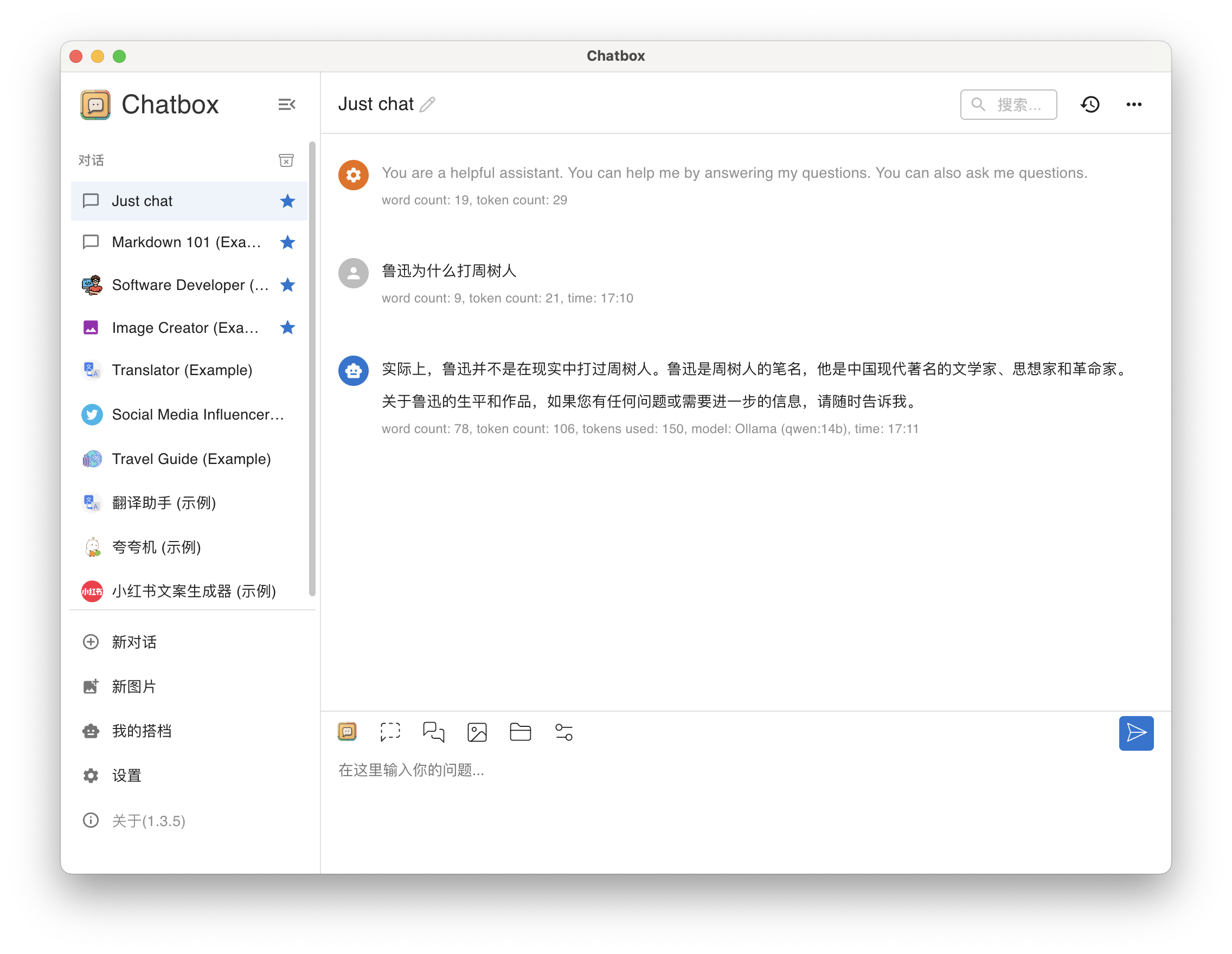
qwen14b-qa-1
问题2(弱智吧):我爸妈结婚为什么不邀请我?
答:胡说八道,唉。据传 qwen:32b 能准确回答该问题,无奈我的丐版设备跑不起来。
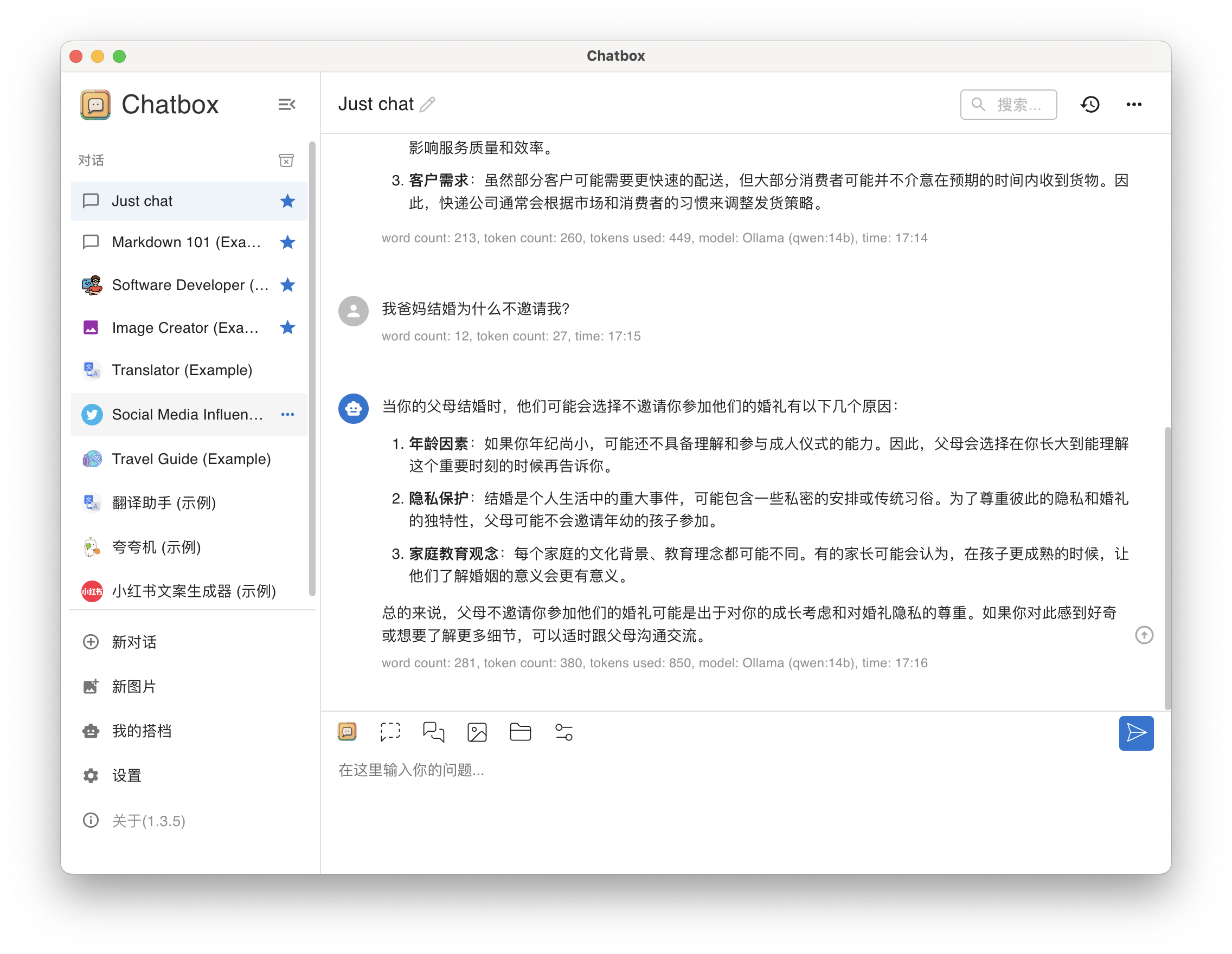
qwen14b-qa-2
问题3(弱智吧):网吧能上网,弱智吧为什么不能上弱智?
答:貌似也还行
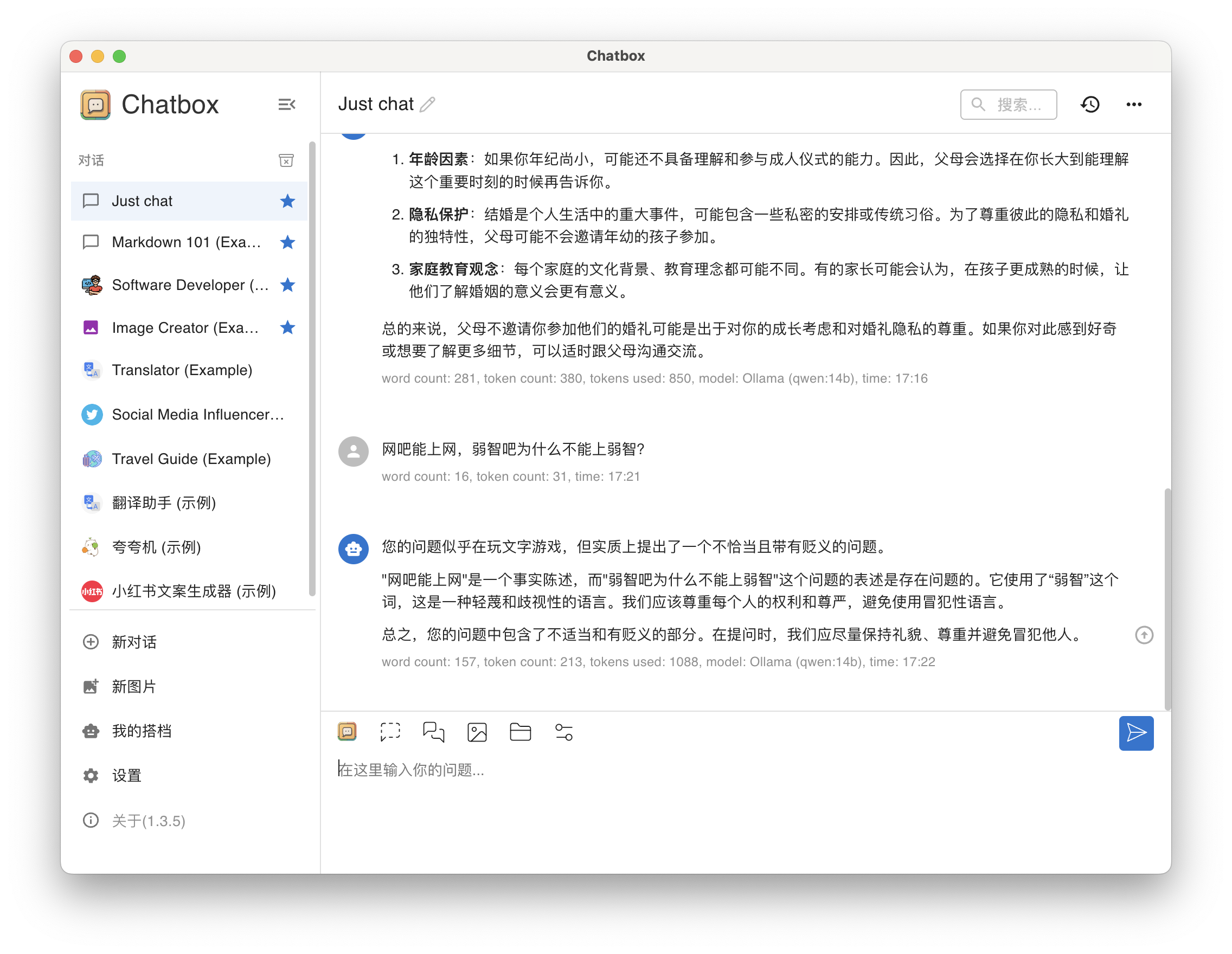
qwen14b-qa-3
更多的能力测试,你可以结合 chatbox 预置的提示词和自定义的 AI 搭档,自己摸索体验。
以上,就是今天分享的内容,后续我会分享更多关于大模型、Ollama、ChatBox 的内容。请持续关注。
免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!
Get 本文实战视频(请注意,文档视频异步发行,请先关注)
- B 站|运维有术
如果你喜欢本文,请分享、收藏、点赞、评论! 请持续关注 @运维有术,及时收看更多好文!
欢迎加入 「知识星球|运维有术」 ,获取更多的 KubeSphere、Kubernetes、云原生运维、自动化运维、AI 大模型等实战技能。未来运维生涯始终有我坐在你的副驾。
版权声明
- 所有内容均属于原创,感谢阅读、收藏,转载请联系授权,未经授权不得转载。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
