深入探索机器学习中的梯度下降法:从理论到实践
原创深入探索机器学习中的梯度下降法:从理论到实践
原创
深入探索机器学习中的梯度下降法:从理论到实践
在当今的科技领域,机器学习作为推动创新的核心动力之一,其影响力遍布于自动驾驶、推荐系统、医疗诊断等多个重要领域。而在机器学习的众多算法中,梯度下降法作为一种基础而强大的优化技术,几乎贯穿了所有监督学习模型的训练过程。本文旨在深入探讨梯度下降法的理论基础、不同变体及其在实际应用中的实现细节,通过代码示例加深理解,并从笔者视角出发,评价其优势与局限。
一、梯度下降法基础
梯度下降法是一种迭代优化算法,其核心思想是沿着目标函数梯度(即函数在某一点上的最速下降方向)的反方向逐步调整参数,直至找到函数的局部最小值或全局最小值。设有一个可微分的目标函数 𝑓(𝜃)f(θ),其中 𝜃θ 是模型参数向量,梯度下降的目标是通过迭代更新 𝜃θ 来最小化 𝑓(𝜃)f(θ):
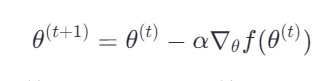
其中,𝛼α 是学习率,控制每一步的下降幅度;∇𝜃𝑓(𝜃(𝑡))∇θf(θ(t)) 表示函数 𝑓f 在 𝜃(𝑡)θ(t) 处的梯度。
代码示例: 假设我们有一个简单的线性回归问题,目标是最小化平方损失函数。以下是使用梯度下降法的Python实现:
import numpy as np
2
3# 定义数据集
4X = np.random.rand(100, 1)
5y = 2 + 3 * X + np.random.randn(100, 1)
6
7# 初始化参数
8theta = np.zeros((2, 1))
9
10# 设置学习率和迭代次数
11alpha = 0.01
12iterations = 1000
13
14# 梯度下降循环
15for i in range(iterations):
16 gradients = (1/len(X)) * X.T.dot(X.dot(theta) - y)
17 theta -= alpha * gradients
18
19print("Estimated parameters:", theta)二、梯度下降的变体
- 批量梯度下降(BGD): 如上代码所示,每次迭代时使用整个数据集来计算梯度,适合数据量不大且追求精确解的场景,但计算量大,速度慢。
- 随机梯度下降(SGD): 每次迭代仅用一个样本来更新参数,大大加快了收敛速度,但路径波动较大,可能不直接到达最优解。
1for i in range(iterations):
2 for x, y_actual in zip(X, y):
3 gradient = (x.dot(theta) - y_actual) * x
4 theta -= alpha * gradient- 小批量梯度下降(Mini-batch GD): 折衷方案,每次迭代使用数据集中的一部分子集(例如32个样本),平衡了计算效率和收敛稳定性。
1batch_size = 8
2for i in range(iterations):
3 indices = np.random.choice(len(X), size=batch_size, replace=False)
4 X_batch, y_batch = X[indices], y[indices]
5 gradients = (1/batch_size) * X_batch.T.dot(X_batch.dot(theta) - y_batch)
6 theta -= alpha * gradients三、梯度下降的挑战与优化
- 局部最小问题: 对于非凸函数,梯度下降可能陷入局部最小。解决方法包括初始化多个点并选择最佳解,或使用更复杂的优化算法如模拟退火、遗传算法等。 而解决局部最小问题的一个策略是实施随机重启,即从多个随机初始化点开始执行梯度下降,并选取获得最优解的那个点。以下是这个策略的简化Python代码示例:
import numpy as np
2
3def gradient_descent_with_restart(objective_function, gradient_function, n_restarts=10, init_range=(-10, 10), iterations=1000, learning_rate=0.01):
4 best_solution = None
5 best_cost = np.inf
6
7 for _ in range(n_restarts):
8 # 随机初始化参数
9 params = np.random.uniform(init_range[0], init_range[1], size=(2,))
10
11 for _ in range(iterations):
12 # 计算梯度并更新参数
13 grad = gradient_function(params)
14 params -= learning_rate * grad
15
16 # 计算当前解的成本
17 current_cost = objective_function(params)
18
19 # 更新最佳解
20 if current_cost < best_cost:
21 best_cost = current_cost
22 best_solution = params
23
24 return best_solution, best_cost
25
26# 假设有一个目标函数和对应的梯度函数
27def objective_function(x):
28 return x[0]**2 + x[1]**2 + np.sin(5*x[0]) * np.sin(3*x[1])
29
30def gradient_function(x):
31 # 目标函数的梯度,这里需要根据实际情况计算
32 pass # 实现梯度计算逻辑
33
34best_params, min_cost = gradient_descent_with_restart(objective_function, gradient_function)
35print(f"Best parameters found: {best_params}, with cost: {min_cost}")- 学习率选择: 过大的学习率可能导致振荡甚至发散;过小则收敛缓慢。自适应学习率方法如Adagrad、RMSprop、Adam等能动态调整学习率,加速收敛。Adam优化器是一种自适应学习率的方法,能够有效地解决学习率选择问题。以下是如何使用Keras(TensorFlow的一个高级API)实现Adam优化的示例:
from tensorflow import keras
2from tensorflow.keras.models import Sequential
3from tensorflow.keras.layers import Dense
4from tensorflow.keras.optimizers import Adam
5
6# 构建简单的神经网络模型
7model = Sequential()
8model.add(Dense(32, input_dim=8, activation='relu'))
9model.add(Dense(1, activation='sigmoid'))
10
11# 编译模型,指定损失函数、优化器和评估指标
12model.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['accuracy'])
13
14# 假设x_train, y_train是训练数据
15history = model.fit(x_train, y_train, epochs=100, batch_size=32, validation_data=(x_val, y_val))- 梯度消失/爆炸: 在深度神经网络中尤为常见,可通过权重初始化技巧(如Xavier初始化、He初始化)和正则化(L1/L2)缓解。为了解决梯度消失或爆炸问题,可以通过适当的权重初始化和正则化技术。下面是使用Xavier初始化(也称为Glorot初始化)和L2正则化的代码示例:
from tensorflow.keras.models import Sequential
2from tensorflow.keras.layers import Dense
3from tensorflow.keras.initializers import glorot_uniform
4
5# Xavier 初始化
6init = glorot_uniform()
7
8# 构建模型并使用L2正则化
9model = Sequential()
10model.add(Dense(64, input_dim=8, kernel_initializer=init, kernel_regularizer=keras.regularizers.l2(0.01), activation='relu'))
11model.add(Dense(1, activation='sigmoid'))
12
13# 编译模型
14model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])四、梯度下降法的实际应用考量
在实际应用中,梯度下降法的选择与优化不仅限于上述讨论的技术层面,还需综合考虑以下几个方面:
- 数据预处理:高质量的数据预处理是成功应用梯度下降的关键。这包括数据清洗、标准化或归一化、处理缺失值和异常值等,以确保模型训练的稳定性和准确性。
- 特征工程:精心设计的特征往往能显著提升模型性能。特征选择、构造和变换(如 PCA 降维、特征编码等)对减少梯度下降的复杂度和避免过拟合至关重要。
- 模型评估与选择:利用交叉验证、A/B 测试等方法评估不同梯度下降策略下模型的表现,选择最优模型配置。这有助于在实际部署前确保模型的泛化能力和稳定性。
- 并行与分布式计算:对于大规模数据集,利用 GPU 加速、多核 CPU 并行处理或分布式计算框架(如 Apache Spark、Google TensorFlow 分布式策略)可以显著提高梯度下降的效率。
- 在线学习与持续优化:在需要实时更新模型的场景中,采用在线梯度下降或增量学习策略,允许模型随着新数据的到来不断自我优化,保持模型的时效性。
五、结论
梯度下降法作为机器学习领域的基石,其理论的深入理解和实际应用的灵活掌握是每位从业者必备的技能。从基础的批量梯度下降到随机梯度下降、小批量梯度下降,再到各种优化策略和实际考量,这一系列的探索展示了梯度下降法的广泛应用潜力及其在面对现实挑战时的应对之策。然而,没有一种方法是万能的,选择最适合问题场景的优化策略,结合良好的工程实践,才能充分发挥梯度下降法在推动技术创新中的作用。未来,随着机器学习理论的进一步发展,梯度下降法及其变种也将不断演进,以适应更加复杂多变的应用需求。
[ 我正在参与2024腾讯技术创作特训营最新征文,快来和我瓜分大奖!](https://cloud.tencent.com/developer/article/2408033)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。