怎么获取第一步请求响应的Cookies呢?

怎么获取第一步请求响应的Cookies呢?

Python进阶者
发布于 2024-05-10 14:44:33
发布于 2024-05-10 14:44:33
大家好,我是Python进阶者。
一、前言
前几天在Python白银交流群【暮雨和】问了一个Python网络爬虫Cookies参数获取的问题,问题如下:怎么获取响应的Cookies呢?第二步的请求cookie是第一步的响应cookie 这步不对 服务器就不会正常响应。
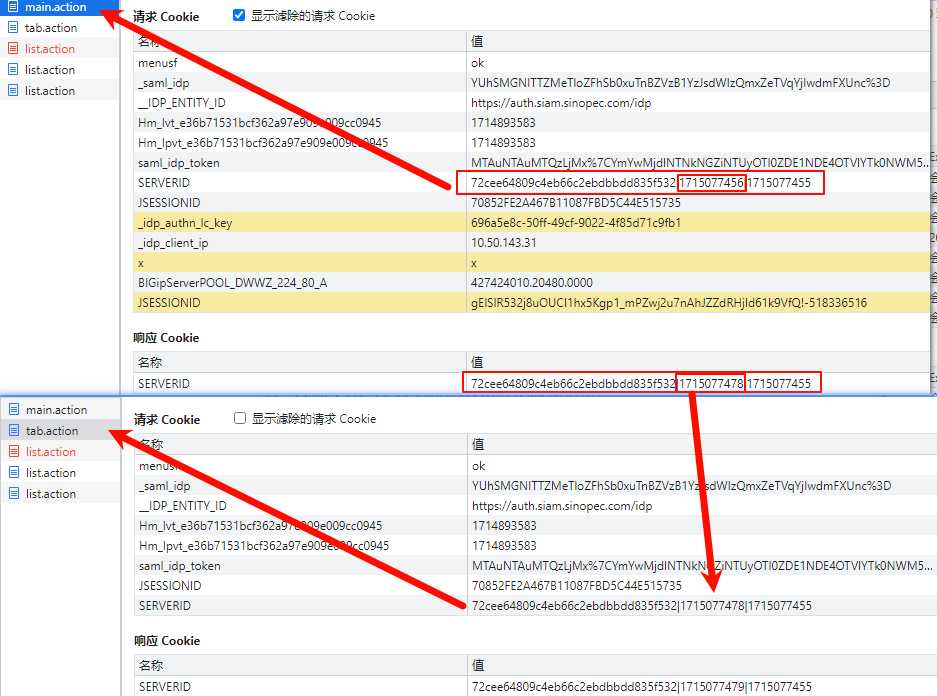
二、实现过程
这里【莫生气】给了一个指导:
在Python中进行网络爬虫时,通常使用requests库来发送HTTP请求。如果你需要在第二步请求中使用第一步请求的响应cookie,可以通过以下步骤实现:
- 发送第一步请求,并获取响应。
- 从响应对象中提取cookie。
- 将提取的cookie应用到第二步请求中。
下面是一个简单的示例:
import requests
# 第一步:发送请求并获取响应
url_first = 'http://example.com/login'
payload_first = {'username': 'your_username', 'password': 'your_password'}
response_first = requests.post(url_first, data=payload_first)
# 第二步:从响应对象中提取cookie
cookies = response_first.cookies
# 第三步:使用提取的cookie进行第二步请求
url_second = 'http://example.com/some_protected_resource'
response_second = requests.get(url_second, cookies=cookies)
# 现在response_second包含了使用了第一步请求cookie的响应数据
在这个示例中:
url_first是登录页面的URL。payload_first是登录所需的用户名和密码。response_first是登录请求的响应。cookies变量存储了从response_first中提取的cookie。url_second是需要使用登录后的cookie进行访问的受保护资源的URL。response_second是使用提取的cookie进行的第二步请求的响应。
请注意,根据网站的安全机制,可能还需要处理其他的安全措施,如CSRF令牌、动态生成的登录表单字段等。此外,确保遵守目标网站的robots.txt文件和使用条款,合法地进行网络爬虫操作。
不过【论草莓如何成为冻干莓】指导说粉丝这里是selenium。
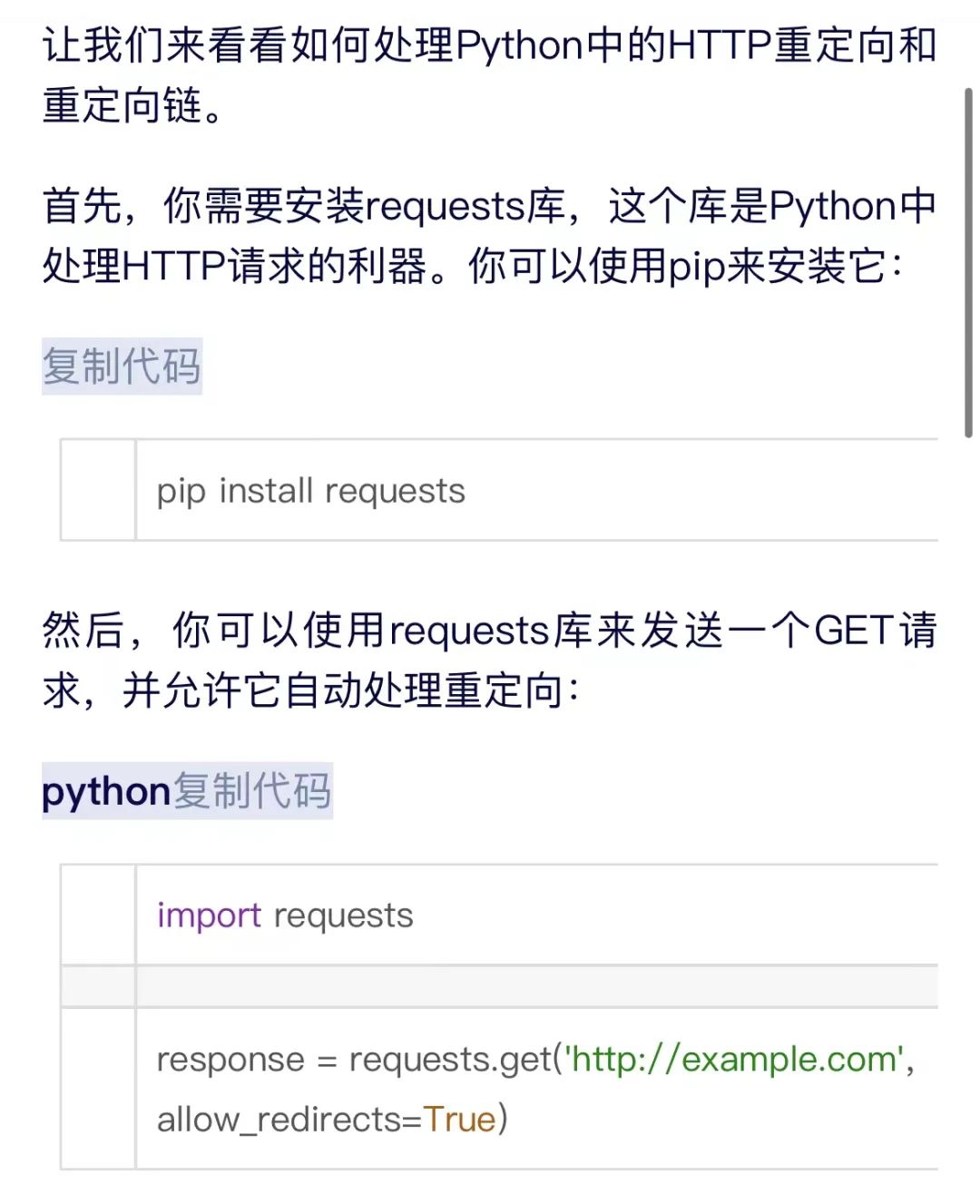
上图这个是requests自动处理重定向,selenium应该不用处理重定向,打开自动跳。
顺利地解决了粉丝的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python网络爬虫Cookies参数获取的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【暮雨和】提出的问题,感谢【论草莓如何成为冻干莓】给出的思路,感谢【莫生气】等人参与学习交流。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Python爬虫与数据挖掘 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号