Redis常见面试题(一):Redis使用场景,缓存、分布式锁;缓存穿透、缓存击穿、缓存雪崩;双写一致,Canal,Redis持久化,数据过期策略,数据淘汰策略
原创
Redis常见面试题(一):Redis使用场景,缓存、分布式锁;缓存穿透、缓存击穿、缓存雪崩;双写一致,Canal,Redis持久化,数据过期策略,数据淘汰策略
原创
寻求出路的程序媛
发布于 2024-07-16 20:25:21
发布于 2024-07-16 20:25:21
文章目录
一、Redis使用场景
二、缓存穿透
三、缓存击穿
四、缓存雪崩
五、先删除缓存,还是先修改数据库
- 5.1 存在问题
- 5.2 双写一致
- 5.2.1 分布式锁
- 5.2.2 异步通知
- 5.3 总结
六、Redis持久化——redis作为缓存,数据的持久化是怎么做的
- 6.1 RDB
- 6.1.1 RDB简介
- 6.1 2 RDB的执行原理
- 6.2 AOF
- 6.3 RDB与AOF对比
- 6.4 总结
七、Redis数据过期策略
- 7.1 惰性删除
- 7.2 定期删除
- 7.3 总结
八、Redis数据淘汰策略
- 8.1 八种数据淘汰策略
- 8.2 数据淘汰策略——使用建议
- 8.3 关于数据淘汰策略其他的面试问题
- 8.4 总结
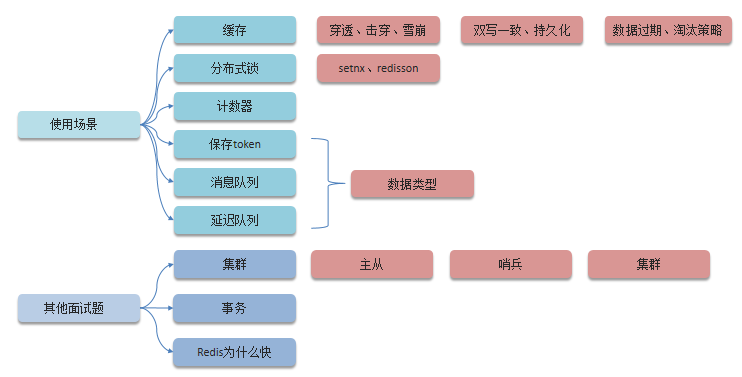

一、Redis使用场景

如果发生了缓存穿透、击穿、雪崩,该如何解决?
二、缓存穿透
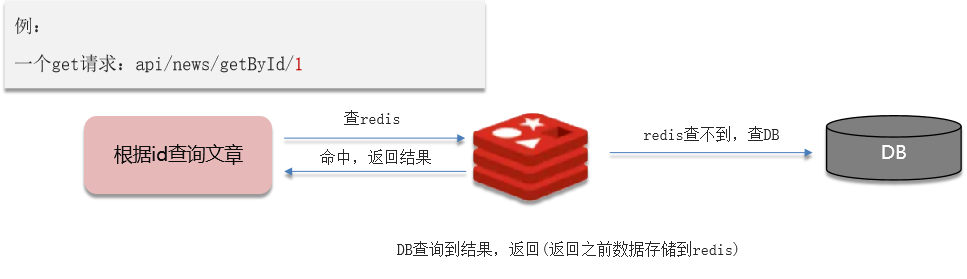
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存。{key:1, value:null}
- 优点:简单
- 缺点:消耗内存,可能会发生不一致的问题
解决方案二:布隆过滤器
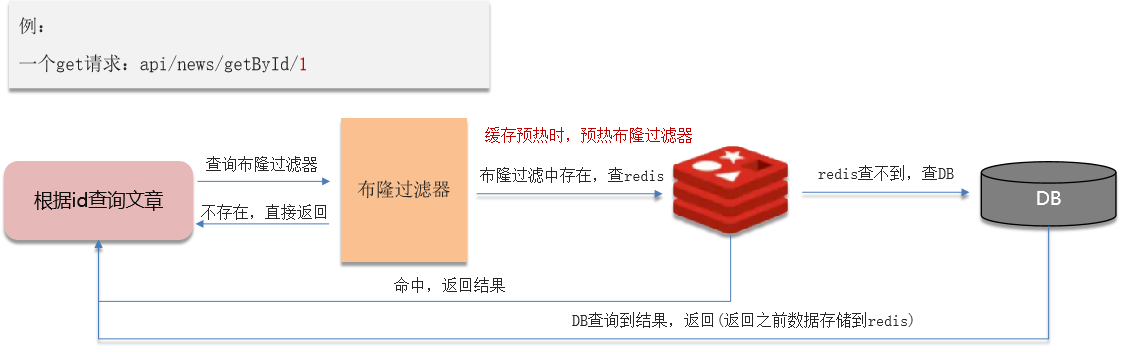

- 优点:内存占用较少,没有多余key
- 缺点:实现复杂,存在误判
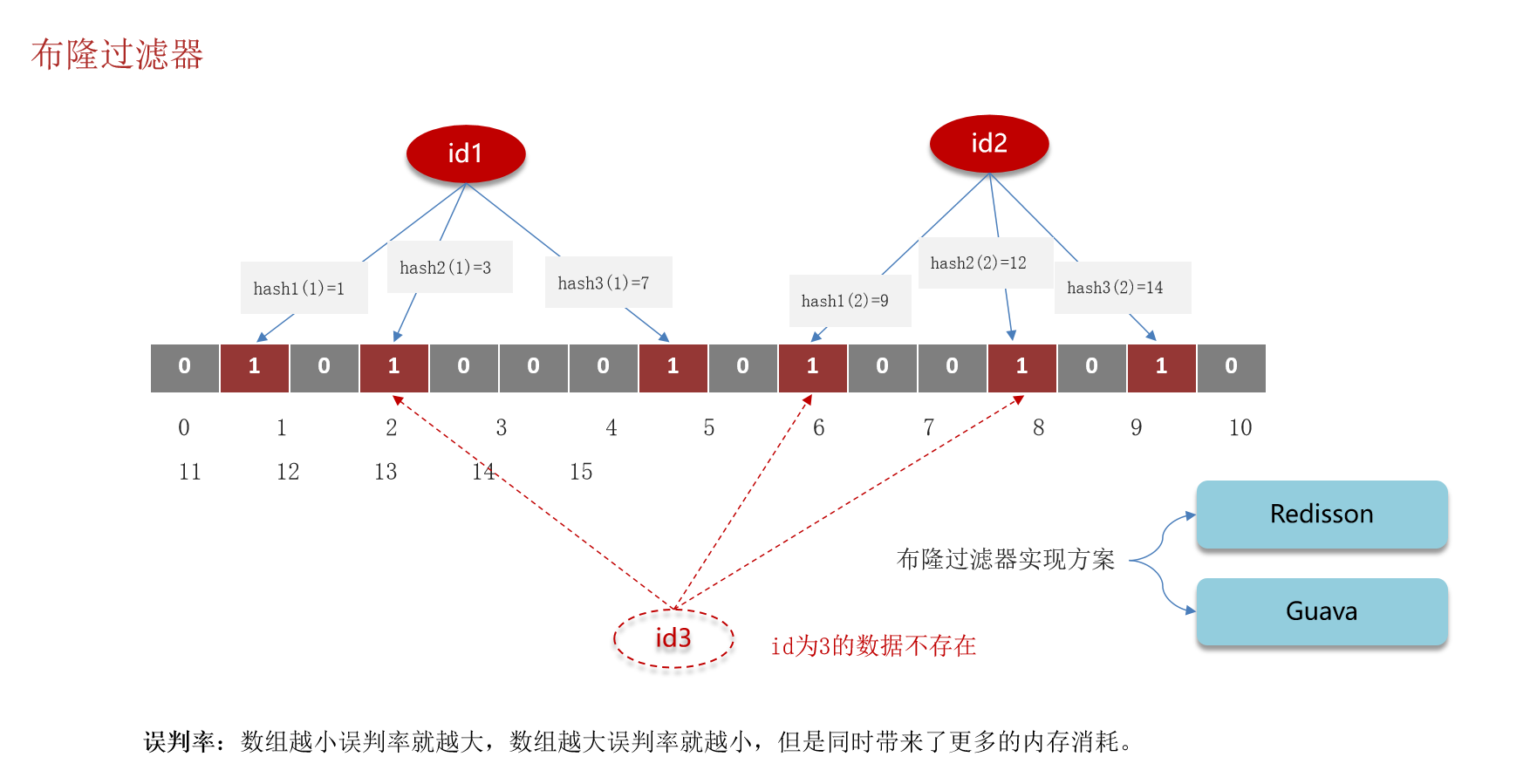
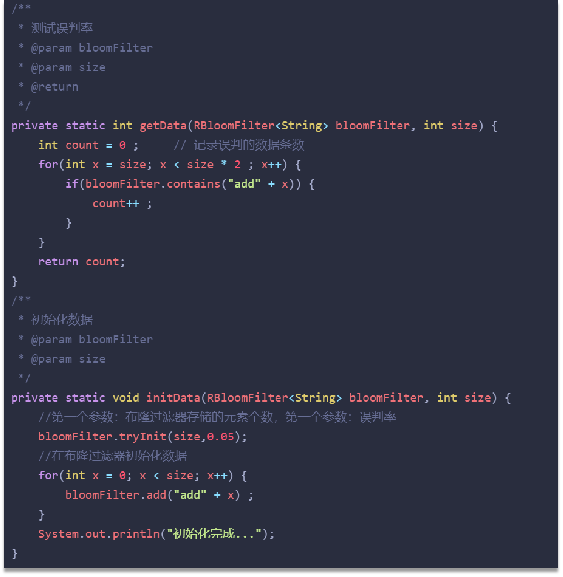
布隆过滤器
bitmap(位图):相当于是一个以**(bit)位为单位的数组,数组中每个单元只能存储二进制数0或1**
布隆过滤器作用:布隆过滤器可以用于检索一个元素是否在一个集合中。

总结
1.Redis的使用场景
- 根据自己简历上的业务进行回答
- 缓存——穿透、击穿、雪崩、双写一致、持久化、数据过期、淘汰策略
- 分布式锁——setnx、redisson
2.什么是缓存穿透,怎么解决
- 缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库,可能导致DB挂掉,这种情况大概率是遭到了攻击
- 解决方案一:缓存空数据
- 解决方案二:布隆过滤器
3.介绍一下布隆过滤器
- 布隆过滤器主要是用于检索一个元素是否在一个集合中,我们当时使用的是redisson实现的布隆过滤器。
- 它的底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。
- 当然是有缺点的,布降过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,其实已经算是很划分了,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
三、缓存击穿
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮

- 解决方案一:互斥锁
- 解决方案二:逻辑过期
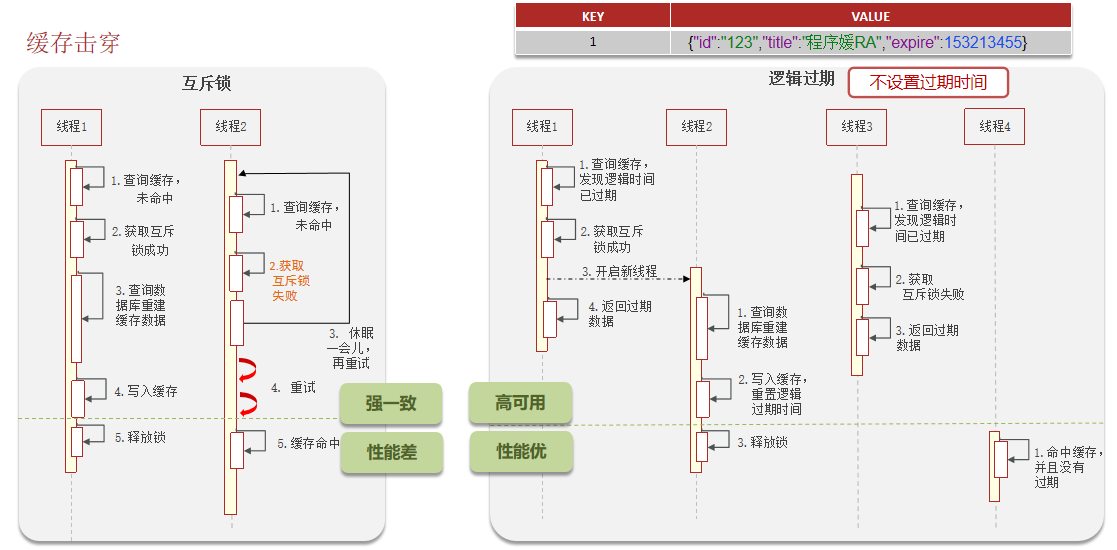
总结:
- 缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
- 解决方案一:互斥锁,强一致,性能差。当缓存失效时,不立即去load db,先使用如Redis的setnx去设置一个互斥锁,当操作成功返回时再进行load db的操作并回设缓存,否则重试get缓存的方法
- 解决方案二:逻辑过期,高可用,性能优,不能保证数据绝对一致。设置当前key逻辑过期,大概是思路如下:
①在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间
②当查询的时候,从redis取出数据后判断时间是否过期
③如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
当然两种方案各有利弊:如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题;如果选择key的逻辑别除,则优先考虑高可用性,性能比较高,但是数据同步这块做不到强一致。
四、缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。

解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性 哨兵模式、集群模式
- 给缓存业务添加降级限流策略 nginx或spring cloud gateway
- 给业务添加多级缓存 Guava或Caffeine
总结
- 缓存雪崩是指在同一时段大量的缓存key同时失效(设置缓存时采用了相同的过期时间 所导致)或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。与缓存击穿的区别:雪崩是很多key,击穿是某一个key缓存
- 解决方案:
- 给不同的Key的TTL添加随机值,将缓存失效时间分散开
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略 降级可作为系统的保底策略,适用于穿透、击穿、雪崩
- 给业务添加多级缓存
缓存三兄弟
穿透无中生有key,布隆过滤null隔离。
缓存击穿过期key, 锁与非期解难题。
雪崩大量过期key,过期时间要随机。
面试必考三兄弟,可用限流来保底。
五、先删除缓存,还是先修改数据库
5.1 存在问题
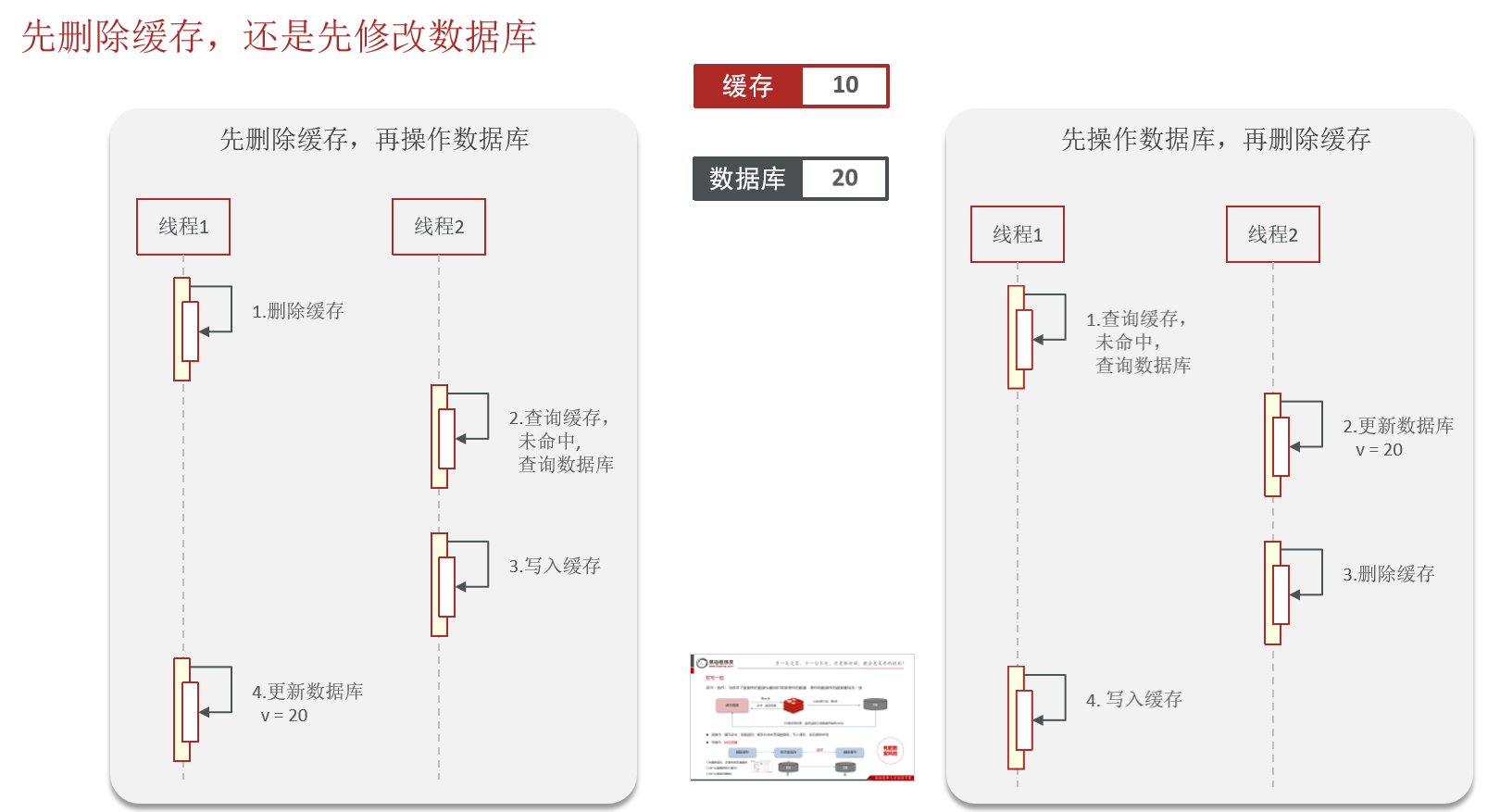
redis作为缓存,mysql的数据如何与redis进行同步呢(双写一致性)
一定、一定、一定要设置前提,先介绍自己的业务背景 一致性要求高、允许延迟一致
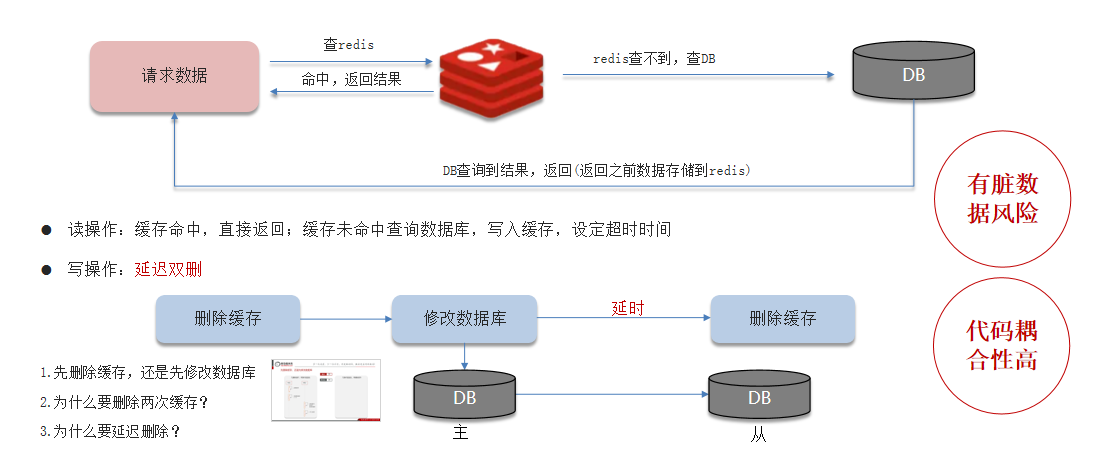
5.2 双写一致
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
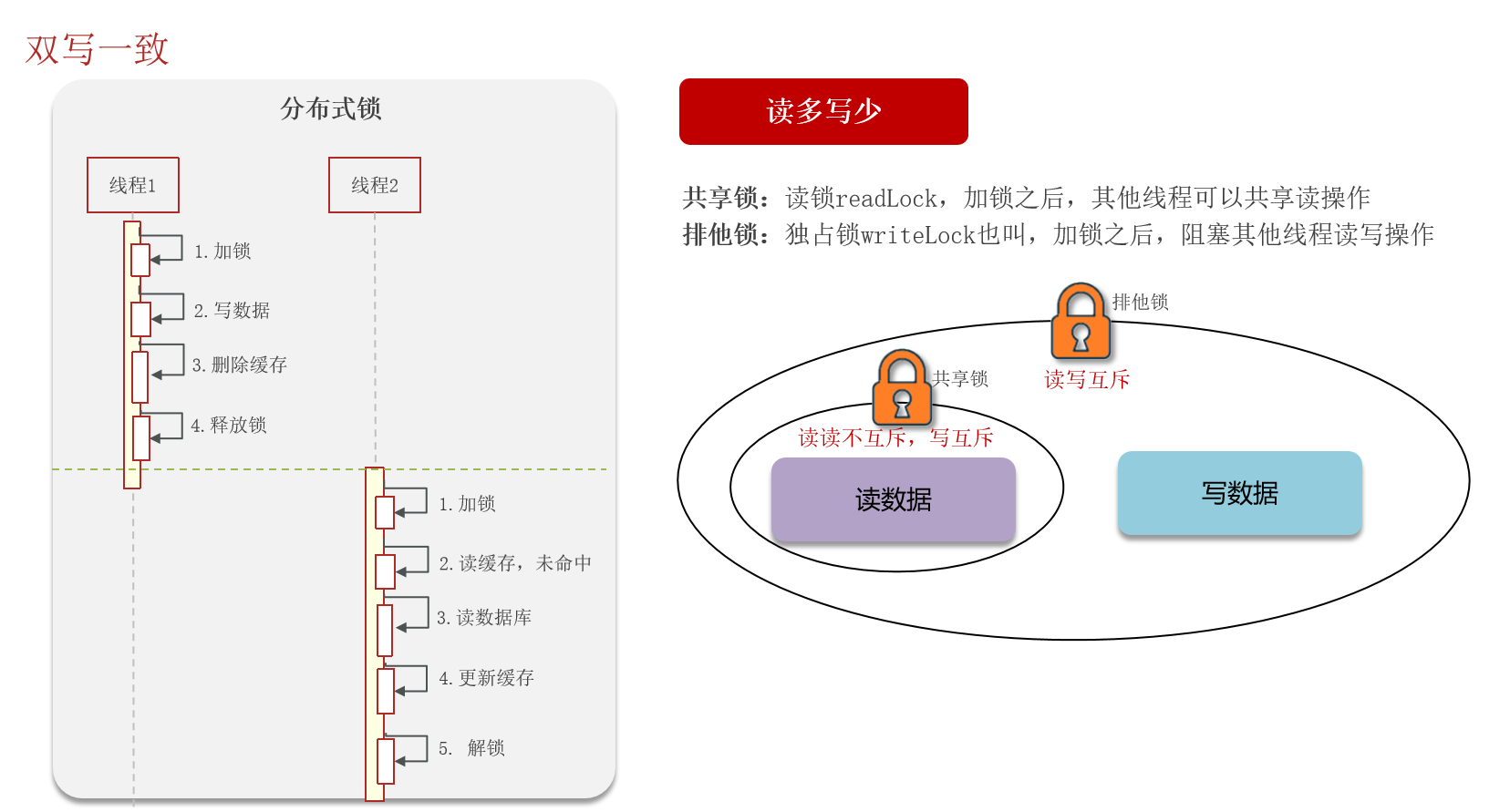
5.2.1 分布式锁
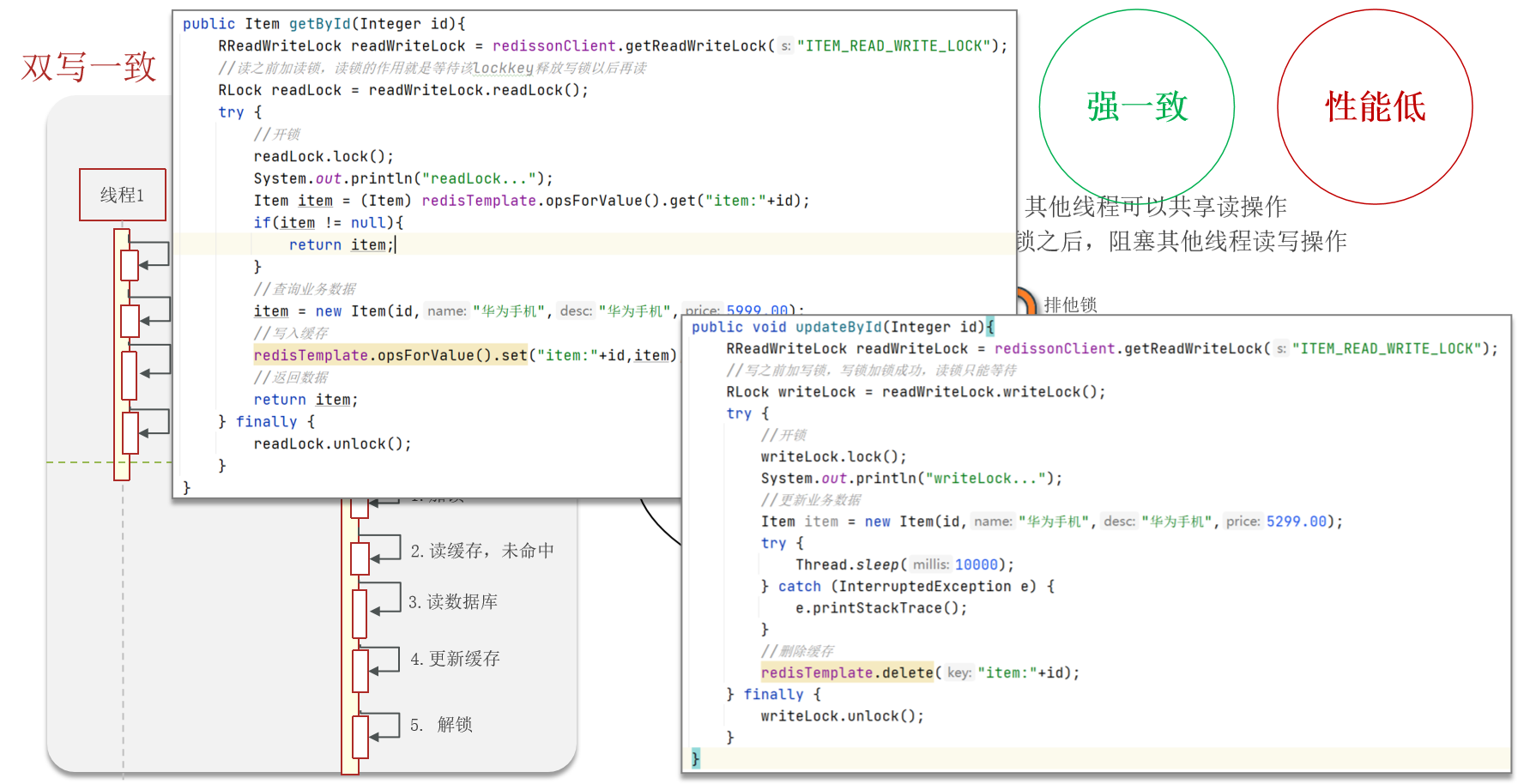
Redisson分布式锁实现数据的一致性,强一致、性能低。
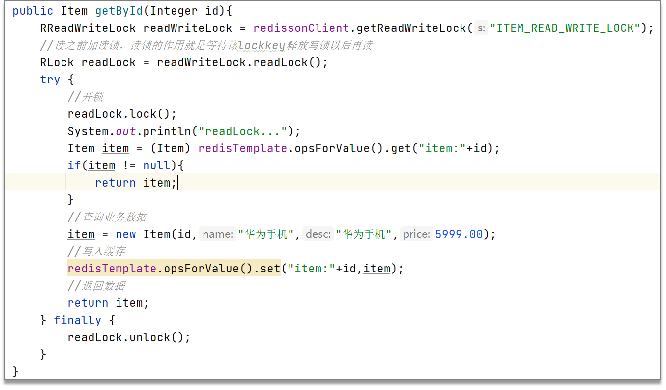
- 共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
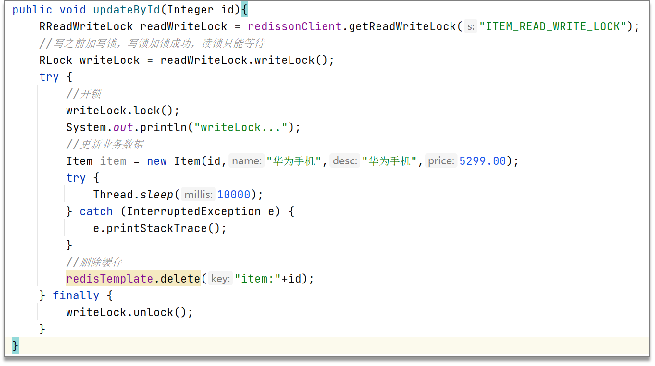
- 排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作
5.2.2 异步通知
异步通知保证数据的最终一致性。
基于MQ的异步通知:
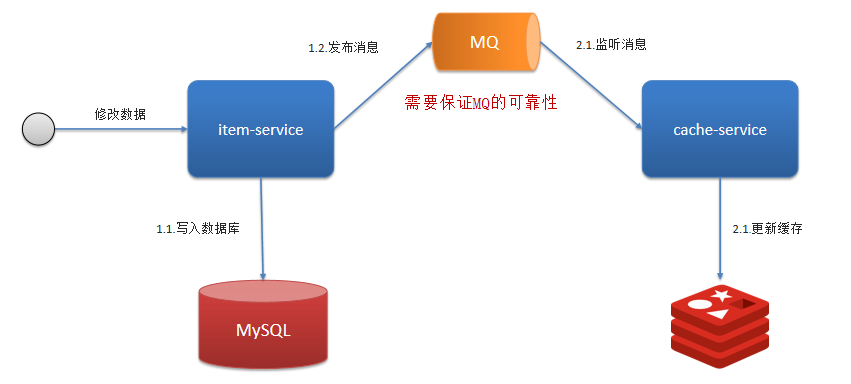
基于Canal的异步通知:
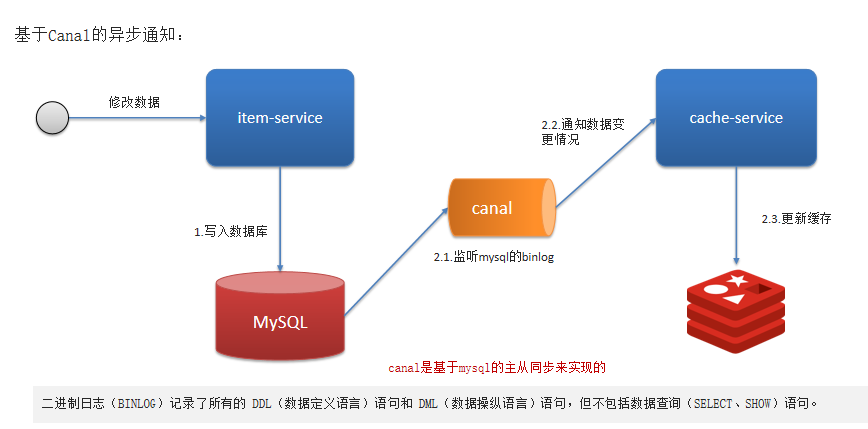
- canal是基于mysql的主从同步来实现的
- 二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
5.3 总结
redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
- 介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高、数据同步可以有一定的延时(符合大部分业务),所以我们当时采用的是异步的方案同步的数据(我们当时采用阿里的canal组件来实现数据同步:不需要更改业务代码,部署一个canal服务。canal服务把自己伪装成mysql的一个从节点,当mysql数据更新以后,canal会读取binlog数据,然后再通过canal的客户端获取到数据,更新缓存即可)
- 我们当时是把抢券的库存存入到了缓存中,这个需要实时地进行数据同步,为了保证数据的强一致,我们当时采用的是redisson提供的读写锁来保证数据的同步(在读的时候添加共享锁,可以保证读读不互斥、读写互斥;更新数据的时候,添加排他锁,读写、读读都互斥,可以保证在写数据的同时其他线程无法读数据,从而避免了脏数据。这里需要注意的是 读方法和写方法上需要使用同一把锁才行)
补充:
这个排他锁是如何保证读写、读读互斥的呢?—— 其实排他锁底层是使用setnx,保证了同时只能有一个线程操作锁住的方法
你听过延时双删吗,为什么不用它呢?—— 延迟双删,如果是写操作,我们先把缓存中的数据删除、然后更新数据库、最后再延时删除缓存中的数据,其中这个延时多久不太好确定;在延时的过程中可能会出现脏数据,并不能保证强一致性,所以没有采用它。
那你来介绍一下异步的方案(你来介绍一下redisson读写锁的这种方案)
- 允许延时一致的业务,采用异步通知
- 使用MQ中间中间件,更新数据之后,通知缓存删除
- 利用阿里canal中间件,不需要修改业务代码,伪装为mysql的一个从节点,canal通过读取binlog数据更新缓存
- 强一致性的,采用Redisson提供的读写锁
- 共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
- 排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作
六、Redis持久化——redis作为缓存,数据的持久化是怎么做的
在Redis中提供了两种数据持久化的方式:1.RDB 2.AOF
6.1 RDB
6.1.1 RDB简介
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
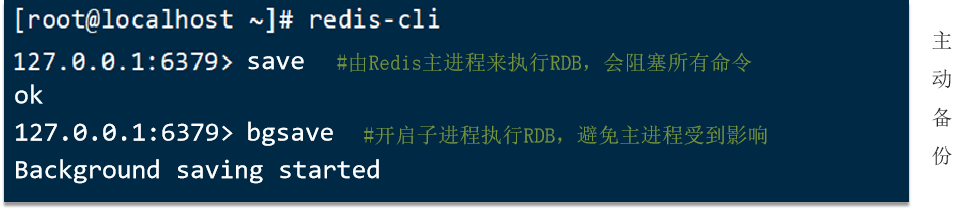
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:

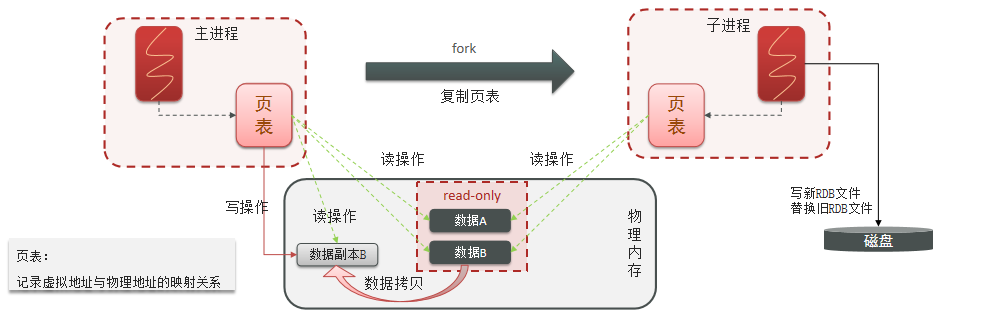
6.1 2 RDB的执行原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
6.2 AOF
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。

AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:

AOF文件一般存储在redis服务器的工作目录下,文件名为 appendonly.aof。
AOF的命令记录的频率也可以通过redis.conf文件来配:

配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:

6.3 RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
RDB | AOF | |
|---|---|---|
持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
宕机恢复速度 | 很快 | 慢 |
数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源,但AOF重写时会占用大量CPU和内存资源 |
使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高,常见 |
6.4 总结
redis作为缓存,数据的持久化是怎么做的?
在Redis中提供了两种数据持久化的方式:1.RDB 2.AOF
RDB与AOF这两种持久化方式有什么区别
- RDB是一个快照文件,它是把redis内存存储的数据写到磁盘上,当redis实例岩机恢复数据的时候,方便从RDB的快照文件中恢复数据。
- AOF的含义是追加文件,当redis操作写命令的时候,都会存储这个文件中(一般存储在redis服务器的工作目录下,文件名为 appendonly.aof),当redis实例岩机恢复数据的时候,会从这个文件中再次执行一遍命令来恢复数据
这两种方式,哪种恢复得比较快呢
RDB因为是二进制文件,在保存的时候体积也是比较小的,它恢复的比较快,但是它有可能会丢数据;我们在项目中通常也会使用AOF来恢复数据,虽然AOF恢复的速度慢一些,但是它丢数据的风险要小很多,在AOF文件中可以设置刷盘策略,我们当时设置的就是每秒批量写入一次命令
七、Redis数据过期策略
假如redis的key过期之后,会立即删除吗
set key value [EX seconds] [PX milliseconds] [NX|XX]
set name jw 10Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。 惰性删除、定期删除
7.1 惰性删除
惰性删除:设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key

- 优点 :对CPU友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查
- 缺点 :对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放
7.2 定期删除
定期删除:每隔一段时间,我们就对一些key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)。
定期清理有两种模式:
- SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的hz 选项来调整这个次数
- FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。
Redis的过期删除策略:惰性删除 + 定期删除 两种策略进行配合使用
7.3 总结
Redis的数据过期策略有哪些?
在redis中提供了两种数据过期删除策略:
- 第一种是情性删除,在设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
- 第二种是定期删除,就是说每隔一段时间,我们就对一些key进行检查,删除里面过期的key
定期清理的两种模式:
- SL0W模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf的hz选项来调整这个次数
- FAST模式执行频率不固定,每次事件循环会尝试执行,但两次间隔不低于2ms,每次耗时不超过1ms
Redis的过期删除策略:惰性删除 + 定期删除 两种策略进行配合使用。
八、Redis数据淘汰策略
假如缓存过多,内存是有限的,内存被占满了怎么办? —— 其实就是想问redis的数据淘汰策略是什么?
数据的淘汰策略:当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
8.1 八种数据淘汰策略
Redis支持8种不同策略来选择要删除的key:
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰
- volatile-random:对设置了TTL的key ,随机进行淘汰
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
redis.conf文件
# The default is:
#
# maxmemory-policy noevictionLRU(Least Recently Used)最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高
LFU(Least Frequently Used)最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
LRU:key1是在3s之前访问的, key2是在9s之前访问的,删除的就是key2
LFU:key1最近5s访问了4次, key2最近5s访问了9次, 删除的就是key1
8.2 数据淘汰策略——使用建议
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
8.3 关于数据淘汰策略其他的面试问题
1)数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据 ?
使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据
2)Redis的内存用完了会发生什么?
主要看数据淘汰策略是什么?如果是默认的配置( noeviction ),会直接报错
8.4 总结
1)Redis的数据淘汰策略有哪些?
Redis提供了8种数据淘汰策略(noeviction、volatile-ttl、allkeys-random、allkeys-random、allkeys-lru、volatile-lru、allkeys-lfu、volatile-lfu),默认是noeviction,不删除任何数据,内部不足直接报错;可以在redis的配置文件中进行设置。
里面有两个非常重要的概念,一个是LRU,另外一个是LFU。
- LRU的意思就是最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU的意思是最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
平时开发过程中用的比较多的就是allkeys-lru(结合自己的业务场景)。
我们在项目设置的是allkeys-lru,挑选最近最少使用的数据淘汰,把一些经常访问的key留在redis中。
2)数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据 ?
使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据。
3)Redis的内存用完了会发生什么?
主要看数据淘汰策略是什么?如果是默认的配置( noeviction ),会直接报错。
参考 黑马程序员相关视频与笔记
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号