MongoDB删除数据空间没有释放原因分析-碎片
原创
MongoDB删除数据空间没有释放原因分析-碎片
原创
一、现象简介
我们在做MongoDB数据库运维的时候,经常会发现数据库批量删除数据之后,磁盘空间并没有立即释放的场景。接下来我们就针对该场景进行分析。
二、问题复现
2.1 环境和数据准备
(1)初始指标记录
[root@10-27-0-224 ~]# du -h --max-depth=1 /data/db # 查看初始MongoDB数据目录文件大小
32K /data/db/journal
0 /data/db/_tmp
81M /data/db
[root@10-27-0-224 ~]# df -TH # 查看初始磁盘使用率
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 22G 2.0G 20G 10% /
devtmpfs devtmpfs 960M 0 960M 0% /dev
tmpfs tmpfs 971M 0 971M 0% /dev/shm
tmpfs tmpfs 971M 19M 953M 2% /run
tmpfs tmpfs 971M 0 971M 0% /sys/fs/cgroup
tmpfs tmpfs 195M 0 195M 0% /run/user/0
> db.serverStatus().mem # 查看mongo内存使用情况
{
"bits" : 64,
"resident" : 51,
"virtual" : 472,
"supported" : true,
"mapped" : 80,
"mappedWithJournal" : 160
}
[root@10-27-0-224 ~]# mongostat
insert query update delete getmore command flushes mapped vsize res faults idx miss % qr|qw ar|aw netIn netOut conn time
*0 *0 *0 *0 0 1|0 1 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:16
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:17
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:18
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:19
*0 *0 *0 *0 0 2|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 133b 10k 1 02:28:20
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:21
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:22
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:23
*0 *0 *0 *0 0 1|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 79b 10k 1 02:28:24
*0 *0 *0 *0 0 2|0 0 80.0M 472.0M 51.0M 0 0 0|0 0|0 133b 10k 1 02:28:25
# 其中内存相关字段的含义是:
- mapped:映射到内存的数据大小
- visze:占用的虚拟内存大小
- res:占用的物理内存大小
【注】如果操作不能在内存中完成,结果faults列的数值不会是0,视大小可能有性能问题。(2)批量插入100w测试数据
> for (var i = 1; i <= 1000000; i++) {
db.starcto.insert( { x : i , name: "A", name1:"B", name2:"C", name3:"D"} )
}
> db.starcto.count()
1000000(3)导入数据后的指标记录
[root@10-27-0-224 ~]# du -h --max-depth=1 /data/db
76M /data/db/journal
0 /data/db/_tmp
620M /data/db
[root@10-27-0-224 ~]# df -TH
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 22G 2.6G 19G 12% /
devtmpfs devtmpfs 960M 0 960M 0% /dev
tmpfs tmpfs 971M 0 971M 0% /dev/shm
tmpfs tmpfs 971M 19M 953M 2% /run
tmpfs tmpfs 971M 0 971M 0% /sys/fs/cgroup
tmpfs tmpfs 195M 0 195M 0% /run/user/0
> db.serverStatus().mem
{
"bits" : 64,
"resident" : 225,
"virtual" : 1401,
"supported" : true,
"mapped" : 544,
"mappedWithJournal" : 1088
}
[root@10-27-0-224 ~]# mongostat
insert query update delete getmore command flushes mapped vsize res faults idx miss % qr|qw ar|aw netIn netOut conn time
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:38
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:39
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:40
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:41
*0 *0 *0 *0 0 2|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 133b 10k 2 02:40:42
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:43
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:44
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:45
*0 *0 *0 *0 0 1|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 79b 10k 2 02:40:46
*0 *0 *0 *0 0 2|0 0 544.0M 1.4G 225.0M 0 0 0|0 0|0 133b 10k 2 02:40:472.2 删除插入的100w测试数据
(1)删除集合数据
> use test
switched to db test
> show collections
starcto
system.indexes
> db.starcto.drop()
true
> db.starcto.count()
0(2)查看删除集合后的指标记录
[root@10-27-0-224 ~]# du -h --max-depth=1 /data/db
76M /data/db/journal
0 /data/db/_tmp
620M /data/db
[root@10-27-0-224 ~]# df -TH
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 22G 2.6G 19G 12% /
devtmpfs devtmpfs 960M 0 960M 0% /dev
tmpfs tmpfs 971M 0 971M 0% /dev/shm
tmpfs tmpfs 971M 19M 953M 2% /run
tmpfs tmpfs 971M 0 971M 0% /sys/fs/cgroup
tmpfs tmpfs 195M 0 195M 0% /run/user/0
> db.serverStatus().mem
{
"bits" : 64,
"resident" : 225,
"virtual" : 1402,
"supported" : true,
"mapped" : 544,
"mappedWithJournal" : 1088
}
【注】由此可见MongoDB物理空间没有丝毫变化。三、问题分析
3.1 查询官网资料
MongoDB4.0及以下:https://docs.mongodb.com/v4.0/reference/method/db.repairDatabase/index.html
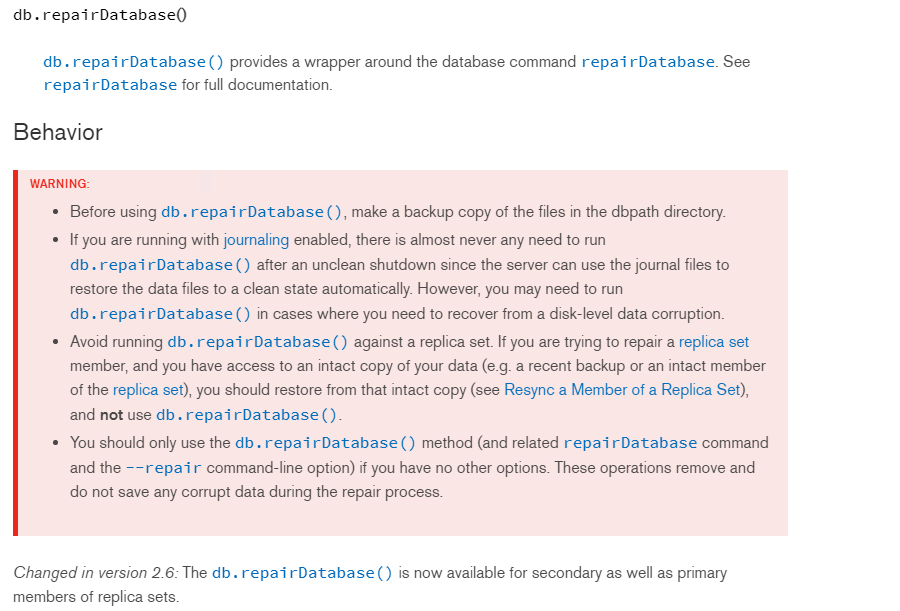
MongoDB4.2及以上 :https://docs.mongodb.com/v4.2/release-notes/4.2-compatibility/index.html
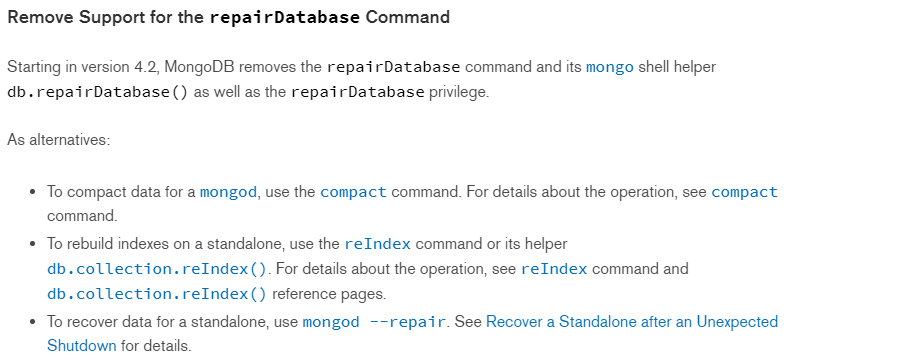
【注】通过对官网的文档查阅不难发现,MongoDB删除集合数据,物理磁盘空间不会直接释放,即使drop collections也无济于事。除非drop databases。在MongoDB4.0及以下,官网提供了一种回收MongoDB磁盘空间的方法,即 db.repairDatabase(),但该操作有一定的风险性,如上图。注意MongoDB4.0以上版本 db.repairDatabase()方法已经被废弃。
3.2 repairDatabase()回收磁盘空间
> db.repairDatabase()
{ "ok" : 1 }
> show dbs # 空间已经释放
local 0.078GB
test 0.078GB
[root@10-27-0-224 ~]# du -h --max-depth=1 /data/db
0 /data/db/journal
0 /data/db/_tmp
0 /data/db/test
161M /data/db
[root@10-27-0-224 ~]# df -TH
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 22G 2.3G 20G 11% /
devtmpfs devtmpfs 960M 0 960M 0% /dev
tmpfs tmpfs 971M 0 971M 0% /dev/shm
tmpfs tmpfs 971M 19M 953M 2% /run
tmpfs tmpfs 971M 0 971M 0% /sys/fs/cgroup
tmpfs tmpfs 195M 0 195M 0% /run/user/0
[root@10-27-0-224 ~]# mongostat
insert query update delete getmore command flushes mapped vsize res faults idx miss % qr|qw ar|aw netIn netOut conn time
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:36
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:37
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:38
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:39
*0 *0 *0 *0 0 2|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 133b 10k 2 03:32:40
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:41
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:42
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:43
*0 *0 *0 *0 0 1|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 79b 10k 2 03:32:44
*0 *0 *0 *0 0 2|0 0 160.0M 634.0M 71.0M 0 0 0|0 0|0 133b 10k 2 03:32:45
> db.serverStatus().mem
{
"bits" : 64,
"resident" : 71,
"virtual" : 634,
"supported" : true,
"mapped" : 160,
"mappedWithJournal" : 320
}四、总结
为解决MongoDB删除集合空间不释放的问题,总结以下方案:
4.1 数据导出再导入dump & restore
通过mongodump备份数据,mongorestore恢复数据,mongodump备份时间与数据大小成正比,所以该方案只适用实例数据比较少的情况,如果数据量非常大,该方法就需要长时间停业务,对于线上业务是不可接受的。
4.2 修复数据库repairDatabase()
db.repairDatabase()操作需要停业务进行,因为MongoDB会锁库直到 repair 操作完成。另外,必须注意预留足够的磁盘空间,需要额外一倍的空间,如果MongoDB 占用数据磁盘了100G,那么 repair 时还需要额外的100G+2G 空间。也可以追加磁盘,然后将目标目录指向新加的磁盘。
(1)操作方法一
mongod --dbpath /data/db --repair --repairpath /data/dbrepair(2)操作方法二
db.repairDatabase()
或
db.runCommand({ repairDatabase: 1 })【注意】在生产上操作如果意外停止可能会造成数据无法恢复的危险。
4.3 复制数据库 db.copydatabase
db.copyDatabase("db1","db2","127.0.0.1:27017");复制出一个新的db2数据库,这个已经是最小数据占用的数据。会在数据目录下产生db2的相关数据文件。127.0.0.1:27017是db1的数据库所在的地址和端口号。copy完成后,可以删除db1,然后将db2修改回db1。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
