OpenAI发布全新Agent工具,加速智能体开发
原创OpenAI发布全新Agent工具,加速智能体开发
原创
这次OpenAI发布的Agent工具,比之前的GPT-4.5有诚意许多。发布了共五个工具,太长不看版:
- 网页搜索工具:基于GPT-4o模型,实时抓取互联网信息并标注引用来源。
- 文件搜索工具:支持PDF、Excel等格式的元数据过滤与向量检索,帮助企业快速定位知识库内容
- 计算机使用工具(CUA):就是之前的Operator,可以通过调用屏幕截图,看到当前的浏览器的信息,然后通过控制鼠标和键盘操作浏览器,使得能够在网络上进行查询和点击,从而有效完成任务。
- Responses API:OpenAI构建Agent的新基础框架,整合了Chat Completions API的简洁性和Assistants API的外部工具调用能力。
- Agents SDK:开源框架支持多Agent协作,可定义角色、工具链及安全策略,适用于客户支持、代码审查等场景。
这些Agent工具,本质上可以让开发者能够快速自定义自己的Agent智能体。此外,OpenAI 还为这些 Agent 工具提供了更强的可扩展性和可配置性,使开发者能够结合自身业务需求,构建更加智能化的自动化助手。
网页搜索工具
网络搜索工具基于GPT-4o或GPT-4o mini微调模型驱动,可实时抓取互联网最新信息,还会像ChatGPT使用网页搜索一样,给出具体的引用网页。
在OpenAI开源的SimpleQA基准测试(评估大模型事实性回答能力)中,网络搜索工具的准确率达90%(GPT-4o)和88%(GPT-4o mini),明显优于传统检索方法。
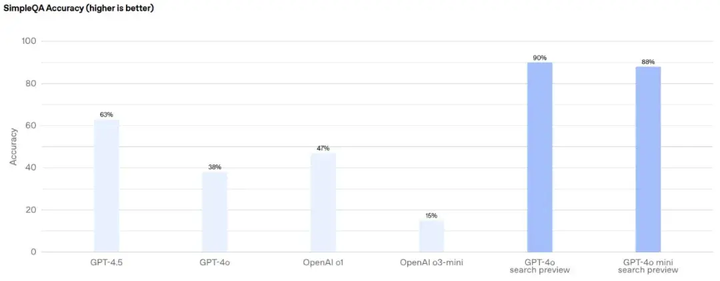
官网给出了具体的代码案例,模型调用的费用中,GPT-4o搜索预览版每千次查询30美元,GPT-4o mini搜索预览版25美元
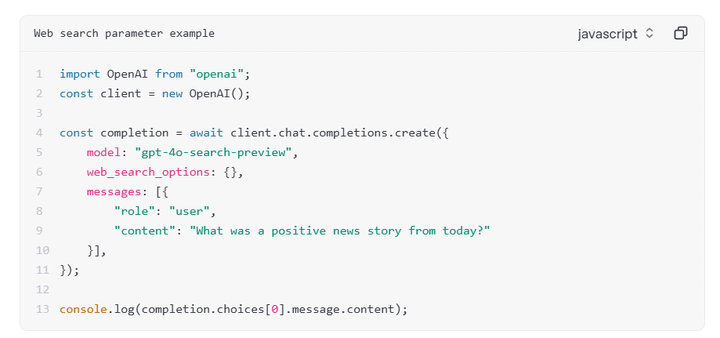
文件搜索工具
文件搜索工具支持PDF、Excel、Word等多种格式,同时允许开发者通过自定义属性(如文档分类、创建时间)筛选内容,并结合向量检索优化查询相关性。举个例子,企业可为合同文档添加“客户名称”“签署日期”等元数据标签,快速定位目标文件。
其每千次搜索请求为2.50美元。文件存储费用中,每日每GB存储0.10美元(首GB免费),适合中小规模文档库。
在将文件搜索与响应 API 结合使用之前,需要在矢量存储中设置知识库并将文件上传到该存储库。
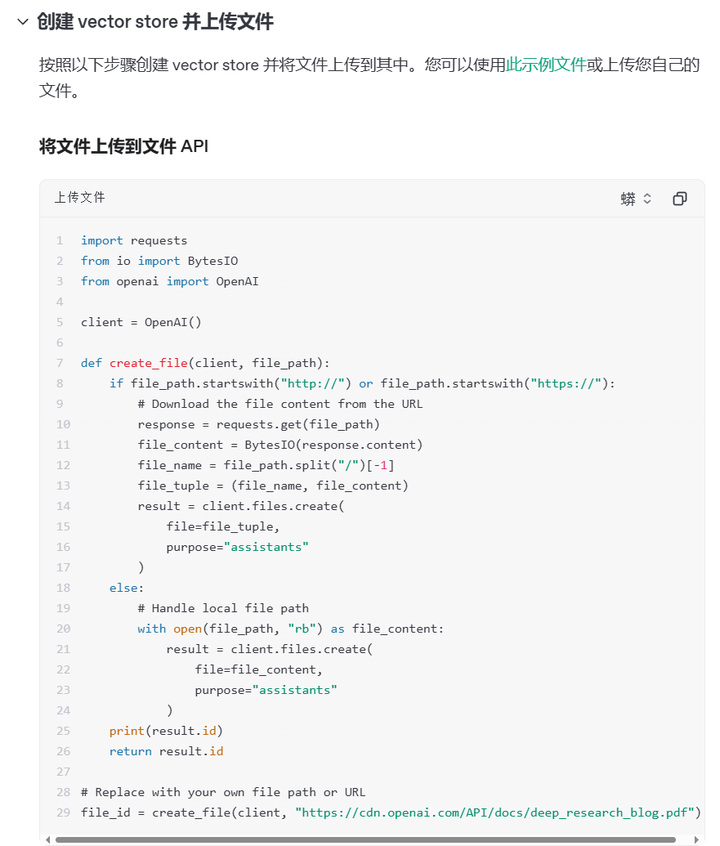
然后把向量输入到client中:

计算机使用工具(CUA)
这个功能其实就是之前发布过的Operator。它使用了一个新模型叫computer-using agent(CUA)。CUA结合了GPT-4o的视觉能力和通过强化学习的高级推理,经过训练,可以与图形用户界面(GUI)进行交互——即人们在屏幕上看到的按钮、菜单和文本字段。
Operator可以通过调用屏幕截图,看到当前的浏览器的信息,然后通过控制鼠标和键盘操作浏览器,使得能够在网络上进行查询和点击,从而有效完成任务。
它还有一个自我纠正的能力。比如在官方演示的过程当中,设定了一个任务:
让它订一张今晚7点在Beretta的两人位子。
接受到命令后,Operator会实例化指令,然后操作浏览器。
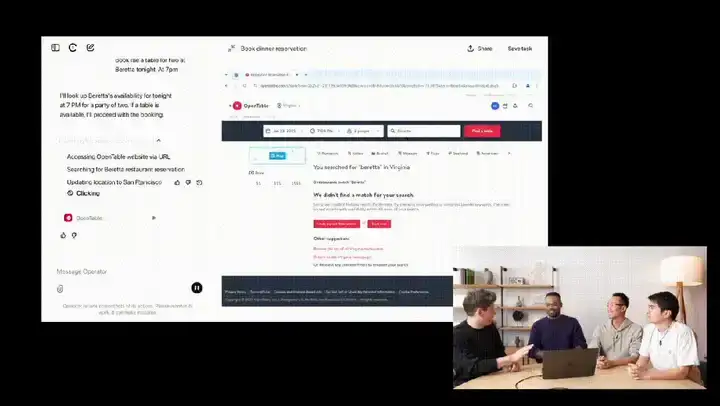
随后,Operator转到了搜索Beretta的URL。虽然OpenTable默认的地址是弗吉尼亚,但operator学会自动纠正为旧金山的地址。
CUA其背后的流程如下所示。本质上就是通过处理原始像素数据理解屏幕状态,同时利用鼠标和键盘执行相应的命令。能够执行多步骤任务,处理错误,并适应意外变化,使其能够在多种数字环境中运行,无需专门的 API 支持即可完成诸如填写表单、浏览网页等任务。
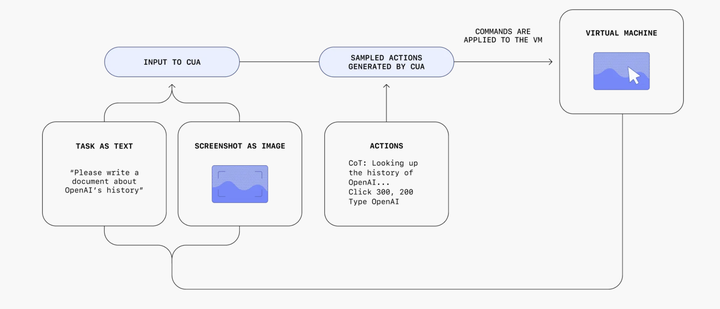
从图上看,它的输入包含了用户的命令输入和当前扫描到的屏幕状态信息。然后利用COT思维链的方式总结出需要执行的步骤,最后操作浏览器执行相应的步骤信息。
整体的工作流程像这样:
- 感知(Perception):CUA 通过截取屏幕截图,将当前计算机状态的视觉快照纳入模型的上下文。
这些截图为其提供环境信息,使其能够实时了解任务进展。
- 推理(Reasoning):利用链式思维(chain-of-thought),结合当前与过往的截图和操作步骤进行推理。这种“内部独白”帮助模型评估观察结果、追踪中间步骤,并动态调整操作策略,提高任务完成的准确性和灵活性。
- 操作(Action):行点击、滚动、输入等操作,直到判断任务完成或需要用户进一步指令。对于敏感操作(如输入登录信息或处理 CAPTCHA),CUA 会寻求用户确认,确保安全性和隐私保护。
我们知道,传统的要执行这样步骤的操作,往往需要调用相关的API进行相应的命令。但是Operator通过结合 GPT-4o 的视觉能力和强化学习驱动的高级推理功能,为用户执行网页任务。其核心模型 CUA能够像人类一样与图形用户界面(GUI)交互,而无需依赖特定的操作系统或网页 API,从而实现灵活的数字任务处理。
它的优势在于,对于多模态能力的理解能够更加准确,同时在多项的基准测试中完成了令人惊讶的成绩。
比如在计算机使用(computer user)测试中,CUA 的成功率为 38.1%,远高于之前的最优方法 (22.0%)。而在浏览器使用(Browser Use)测试中,CUA 的成功率为 58.1%,相较于之前的最优方法 (36.2%) 提升显著。
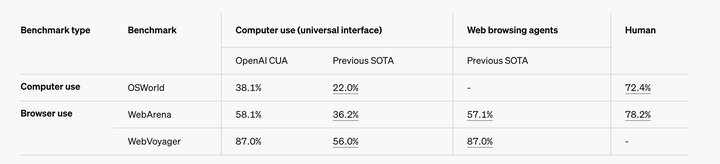
但值得一体的是,OpenAI其实在对于CUA评估的时候,有测试过在浏览器模拟和操作系统模拟的成绩,说明OpenAI也做过操作系统的Agent,只是目前成绩只有38.1%,远远达不到可用的地步,所以目前还只是基于浏览器模拟的方法给用户进行开放测试使用。
执行步数对Operator的成功率也有一定的影响。从下面图中可以看到,在10到100执行步数中,整体的测试成功率有一个比较明显的提高。从10%成功率提升到了38%。但是,与人类的 72.4% 成功率相比,仍存在较大改进空间。
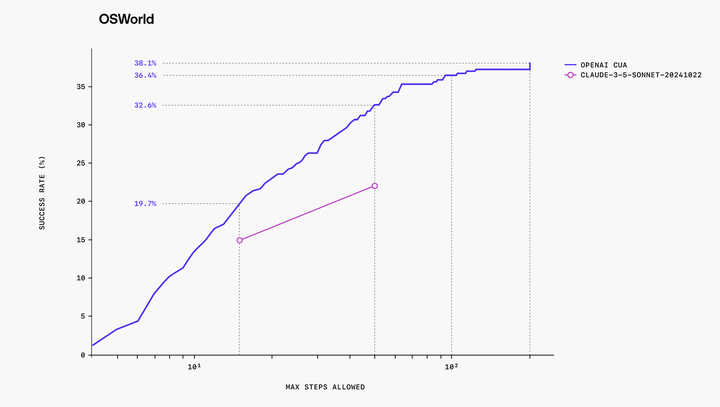
另一方面,过大的执行步数需要消耗更多的时间,如果在实际使用过程中有时候步数过多会让人看着很烦。这个其实还有很大的优化空间,比如是不是可以针对一些常见的任务进行强化学习对其优化,然后进一步提升成功率的同时减少执行步数。
Responses API
其特性就是把多种API进行合并:能够在单个 API 调用中轻松执行多轮模型交互,然后减少辅助的操作。
这些API其实就是上面所介绍的网页搜索工具、文件搜索工具和计算机使用工具(CUA)。
Responses API 本身支持文本、图像和音频模式。将所有这些结合在一起,可以通过 responses API 调用一次 API 来构建完全多模式、工具增强的交互。
下面这张图对比了以前的Completions API和现有的Responses API的区别。在以前,整体的过程比较复杂:
- 开发者提供函数定义和消息:例如,定义 web_search(string) 作为一个可用的函数,并输入请求(如“这张图片中的关键词相关新闻”)。
- 模型调用函数:模型决定调用 web_search 并传入参数(如 "cat, feline...")。
- 执行函数代码:API 实际执行 web_search 并返回搜索结果,如 { "article": "a cat miraculously..." }。
- 处理结果:结果被整合到所有历史消息中,供模型参考。
- 最终响应:模型基于所有消息生成最终回答,例如 “Here are the news: 1. A cat miraculously...”
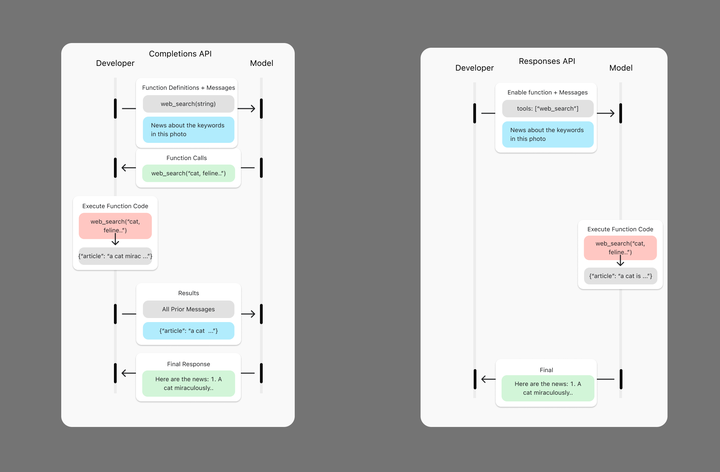
新的API过程减少了很多复杂的步骤
- 发者启用工具:只需启用 tools: ["web_search"],无需单独定义函数。
- 模型自动调用函数:模型识别任务并直接执行 web_search("cat, feline...")。
- 执行函数代码:web_search 运行并返回 { "article": "a cat is ..." }。
- 最终响应:直接生成回答,无需额外处理所有历史消息。
从整体来看,Responses API 更简洁,减少了中间步骤,不再需要显式定义函数调用,而是直接启用工具。有更加智能的函数调用:模型可以自动识别何时使用工具,并直接返回结果。同时减少开发者的复杂度:开发者不必手动管理所有历史消息,API 处理更加流畅。
写在最后
这次,OpenAI这么快的发布全新的Agent工具,被视为对国产Agent产品Manus的回应。由于Manus因在GAIA测试中超越OpenAI的DeepResearch。导致OpenAI真的急了,所以立刻发布了全套的Agent制作工具。不得不说,AI前沿技术圈真的太卷了~
更有意思的是,OpenAI 这次的发布不仅仅是常规的技术更新,而是直接给开发者提供了一整套 Agent 训练、微调、部署和交互的完整生态。相比之下,Manus 在 GAIA 测试中的优势主要体现在推理速度和跨模态理解能力,而 OpenAI 这次的新工具则在开放性和生态整合方面更胜一筹。
不少业内人士分析,OpenAI 这波操作明显是希望通过降低 Agent 开发门槛,吸引更多开发者和企业使用其生态,从而在市场上抢占更大份额。而 Manus 作为近年来国产 AI 突围的重要代表,一直强调自研底座和端侧部署优化,因此两者的路线其实有所不同。
当然,这场竞争的火药味也越来越浓了。毕竟,Manus 在 GAIA 测试中的超越已经引发了全球 AI 界的震动,而 OpenAI 迅速跟进的策略也说明了他们对此事的高度重视。接下来,就看 Manus 是否会迅速做出回应,或者继续深耕自己的技术路线,以保持领先优势。
AI 领域的技术竞赛越来越精彩,最终谁能在这场 Agent 之战中胜出,还要看接下来双方的实际应用表现和市场反馈。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
