AI 创作日记 | 图解DeepSeek知识增强,从向量检索到思维链的进化之路
原创AI 创作日记 | 图解DeepSeek知识增强,从向量检索到思维链的进化之路
原创
一、引言
在人工智能的快速发展浪潮中,大语言模型(LLM)已经成为了各个领域的核心驱动力。然而,传统的大语言模型在处理复杂知识和长文本推理时,往往面临着信息检索不准确、推理能力不足等问题。DeepSeek作为一款新兴的大语言模型,通过知识增强技术,实现了从向量检索到思维链的进化,为解决这些问题提供了新的思路和方法。本文将以图解的方式,深入剖析DeepSeek知识增强的核心机制,带领读者一起探索其从向量检索到思维链的进化之路。
二、典型场景
2.1 智能客服
在电商、金融、电信等行业,智能客服系统已经成为了企业与客户沟通的重要渠道。智能客服需要能够快速准确地回答客户的问题,提供相关的产品信息和解决方案。例如,在电商平台上,客户可能会询问某款产品的库存情况、价格、售后服务等问题。智能客服需要能够从海量的商品信息和知识库中快速检索到相关的答案,并以自然语言的方式回复给客户。
2.2 智能写作
在新闻媒体、广告营销、内容创作等领域,智能写作工具可以帮助作者快速生成高质量的文章、报告、文案等内容。例如,在新闻媒体行业,记者需要在短时间内撰写大量的新闻报道。智能写作工具可以根据记者提供的主题和关键词,从海量的新闻素材和知识库中快速检索到相关的信息,并生成一篇完整的新闻报道。
2.3 智能问答
在教育、医疗、科研等领域,智能问答系统可以帮助用户快速获取相关的知识和信息。例如,在教育领域,学生可能会在学习过程中遇到各种问题,需要向老师或同学请教。智能问答系统可以根据学生提出的问题,从海量的教材、课件、学术论文等知识库中快速检索到相关的答案,并以自然语言的方式回复给学生。
三、痛点分析
3.1 信息检索不准确
传统的信息检索方法主要基于关键词匹配,这种方法在处理复杂的自然语言问题时,往往会出现检索结果不准确、不相关的问题。例如,在智能客服场景中,客户可能会用不同的表达方式询问同一个问题,如“这款产品还有库存吗?”和“这款产品是否有货?”。传统的关键词匹配方法可能无法识别这两个问题的语义等价性,从而导致检索结果不准确。
3.2 推理能力不足
传统的大语言模型在处理复杂的推理问题时,往往会出现推理能力不足的问题。例如,在智能问答场景中,用户可能会提出一些需要进行推理和判断的问题,如“如果A大于B,B大于C,那么A和C哪个大?”。传统的大语言模型可能无法理解问题的语义,也无法进行有效的推理和判断,从而导致回答错误。
3.3 知识更新不及时
随着时间的推移,知识库中的知识和信息会不断更新和变化。传统的信息检索方法和大语言模型往往无法及时更新和同步知识库中的知识和信息,从而导致检索结果和回答内容过时、不准确。例如,在电商平台上,商品的库存情况、价格等信息会随时发生变化。传统的智能客服系统可能无法及时更新这些信息,从而导致回答客户的问题时出现错误。
四、方案对比
4.1 传统向量检索
传统的向量检索方法主要基于向量空间模型,将文本数据转换为向量表示,然后通过计算向量之间的相似度来进行信息检索。这种方法在处理大规模文本数据时具有较高的效率和准确性,但在处理复杂的自然语言问题时,仍然存在着信息检索不准确、推理能力不足等问题。
4.2 DeepSeek知识增强
DeepSeek知识增强技术通过引入知识图谱、思维链等技术,实现了从向量检索到思维链的进化。具体来说,DeepSeek知识增强技术主要包括以下几个方面:
- 知识图谱嵌入:将知识图谱中的实体和关系嵌入到向量空间中,使得模型能够更好地理解和利用知识图谱中的知识和信息。
- 思维链推理:引入思维链的概念,将复杂的推理问题分解为多个简单的子问题,然后通过逐步推理和求解这些子问题,最终得到问题的答案。
- 知识更新机制:建立知识更新机制,及时更新和同步知识库中的知识和信息,确保模型能够获取到最新的知识和信息。
4.3 对比总结
与传统向量检索方法相比,DeepSeek知识增强技术具有以下几个优点:
- 信息检索更准确:通过引入知识图谱嵌入和思维链推理技术,DeepSeek知识增强技术能够更好地理解和利用知识图谱中的知识和信息,从而提高信息检索的准确性和相关性。
- 推理能力更强:通过引入思维链推理技术,DeepSeek知识增强技术能够将复杂的推理问题分解为多个简单的子问题,然后通过逐步推理和求解这些子问题,最终得到问题的答案,从而提高模型的推理能力和解决问题的能力。
- 知识更新更及时:通过建立知识更新机制,DeepSeek知识增强技术能够及时更新和同步知识库中的知识和信息,确保模型能够获取到最新的知识和信息,从而提高模型的准确性和可靠性。
五、实施路线图
5.1 数据准备
在实施DeepSeek知识增强技术之前,需要准备好相关的数据,包括文本数据、知识图谱数据等。具体来说,数据准备工作主要包括以下几个方面:
- 文本数据收集:收集与业务相关的文本数据,如产品信息、客户服务记录、新闻报道等。
- 知识图谱构建:构建与业务相关的知识图谱,包括实体、关系、属性等信息。
- 数据预处理:对收集到的文本数据和知识图谱数据进行预处理,如分词、词性标注、命名实体识别等。
5.2 模型训练
在数据准备工作完成后,需要使用准备好的数据对DeepSeek模型进行训练。具体来说,模型训练工作主要包括以下几个方面:
- 模型选择:选择合适的DeepSeek模型,如DeepSeek-Large、DeepSeek-XL等。
- 训练参数设置:设置训练参数,如学习率、批次大小、训练轮数等。
- 模型训练:使用准备好的数据对DeepSeek模型进行训练,直到模型收敛。
5.3 模型部署
在模型训练工作完成后,需要将训练好的模型部署到生产环境中。具体来说,模型部署工作主要包括以下几个方面:
- 模型打包:将训练好的模型打包成可部署的格式,如Docker镜像、TensorFlow Serving模型等。
- 部署环境搭建:搭建模型部署环境,如服务器、云计算平台等。
- 模型部署:将打包好的模型部署到搭建好的部署环境中,并进行测试和验证。
5.4 系统集成
在模型部署工作完成后,需要将部署好的模型集成到业务系统中。具体来说,系统集成工作主要包括以下几个方面:
- 接口开发:开发与业务系统集成的接口,如RESTful API、gRPC接口等。
- 系统对接:将开发好的接口与业务系统进行对接,实现模型与业务系统的交互。
- 系统测试:对集成后的系统进行测试和验证,确保系统的稳定性和可靠性。
六、边界条件说明
6.1 数据质量
DeepSeek知识增强技术的效果很大程度上取决于数据的质量。如果数据存在噪声、错误、缺失等问题,会影响模型的训练和推理效果。因此,在实施DeepSeek知识增强技术之前,需要确保数据的质量。
6.2 计算资源
DeepSeek知识增强技术需要大量的计算资源来进行模型训练和推理。如果计算资源不足,会影响模型的训练和推理速度。因此,在实施DeepSeek知识增强技术之前,需要确保有足够的计算资源。
6.3 知识图谱构建
DeepSeek知识增强技术需要使用知识图谱来进行知识嵌入和推理。如果知识图谱构建不准确、不完整,会影响模型的训练和推理效果。因此,在实施DeepSeek知识增强技术之前,需要确保知识图谱的构建质量。
6.4 模型可解释性
DeepSeek知识增强技术是一种基于深度学习的技术,模型的可解释性较差。在一些对模型可解释性要求较高的场景中,如医疗、金融等领域,需要谨慎使用DeepSeek知识增强技术。
七、伪代码及代码说明
7.1 知识图谱嵌入
1、定义知识图谱嵌入函数
def knowledge_graph_embedding(knowledge_graph):
# 初始化嵌入模型
embedding_model = EmbeddingModel()
# 对知识图谱中的实体和关系进行嵌入
entity_embeddings = embedding_model.embed_entities(knowledge_graph.entities)
relation_embeddings = embedding_model.embed_relations(knowledge_graph.relations)
# 返回嵌入结果
return entity_embeddings, relation_embeddings
# 调用知识图谱嵌入函数
entity_embeddings, relation_embeddings = knowledge_graph_embedding(knowledge_graph)代码说明:
knowledge_graph_embedding函数用于对知识图谱中的实体和关系进行嵌入。EmbeddingModel是一个嵌入模型,用于将实体和关系转换为向量表示。embed_entities方法用于对知识图谱中的实体进行嵌入。embed_relations方法用于对知识图谱中的关系进行嵌入。
2、流程图
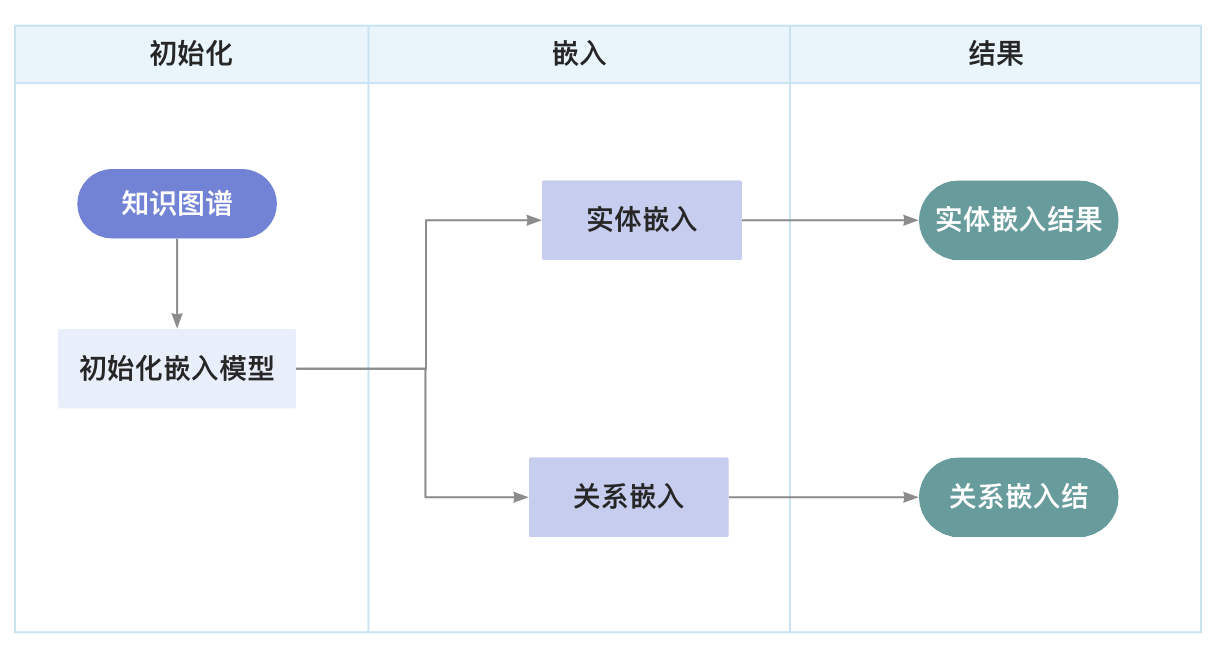
7.2 思维链推理
1、定义思维链推理函数
# 定义思维链推理函数
def thinking_chain_reasoning(question, knowledge_graph, entity_embeddings, relation_embeddings):
# 初始化推理模型
reasoning_model = ReasoningModel()
# 将问题转换为向量表示
question_embedding = reasoning_model.embed_question(question)
# 进行思维链推理
answer = reasoning_model.reason(question_embedding, knowledge_graph, entity_embeddings, relation_embeddings)
# 返回推理结果
return answer
# 调用思维链推理函数
answer = thinking_chain_reasoning(question, knowledge_graph, entity_embeddings, relation_embeddings)代码说明:
thinking_chain_reasoning函数用于进行思维链推理。ReasoningModel是一个推理模型,用于根据问题和知识图谱进行推理。embed_question方法用于将问题转换为向量表示。reason方法用于根据问题向量、知识图谱、实体嵌入和关系嵌入进行推理。
2、流程图
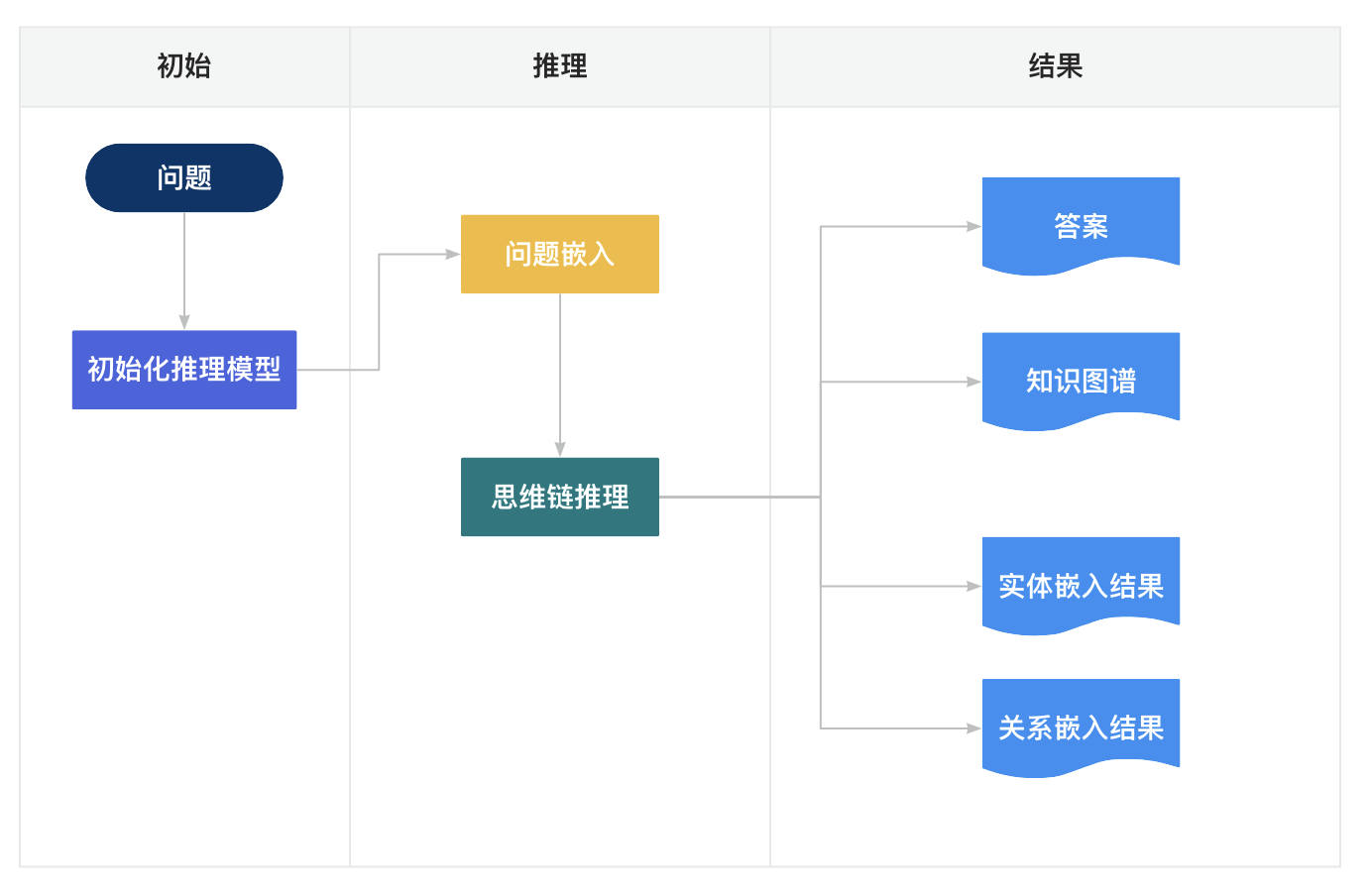
九、总结
DeepSeek知识增强技术通过引入知识图谱、思维链等技术,实现了从向量检索到思维链的进化,为解决传统大语言模型在处理复杂知识和长文本推理时面临的问题提供了新的思路和方法。
本文以图解的方式,深入剖析了DeepSeek知识增强的核心机制,详细介绍了其实施路线图和边界条件。
希望本文能够帮助读者更好地理解和应用DeepSeek知识增强技术,推动人工智能技术在各个领域的发展和应用。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
