开源神器来袭:Markdown 转 PDF,从此不再求人!
原创
开源神器来袭:Markdown 转 PDF,从此不再求人!
原创
1、前言
最近在整理整套的《Java体系》相关的电子书籍,面试题集,基础知识,进阶知识以及AI相关的学习手册。整理过程中发现,需要进行Markdown文件转PDF文件。于是乎顺便水一篇文章好了。
2、主流工具对比
网上其实也有了很多现成可用的工具。这里顺便整理了一下。但是大部分都存在一些通病:
当然这里仅限于个人观点,可能找的工具不全;也可能自己不知道有这些好用的工具。
- 无法批量生成文章,很多只能一篇一篇传,就算可以批量上传,也不能批量下载
- 生成的PDF都带有广告水印,有洁癖的人果断选择不要
- 大小限制
2.1、Pandoc + LaTeX
- 核心能力:支持多格式互转(Markdown、PDF、HTML等),通过 LaTeX 模板实现高度自定义排版(如页眉页脚、数学公式)。
- 中文支持:需搭配 XeLaTeX 引擎和 TinyTeX 等轻量级 TeX 发行版,并配置中文字体(如 SimSun)。
- 适用场景:学术文档、批量转换(需结合 Python 脚本)。
- 示例命令:
pandoc input.md -o output.pdf --pdf-engine=xelatex -V mainfont="SimSun"但是也存在一定的局限性,无法提供友好的页眉页脚生成方式,需要编写复杂的LaTeX模板实现页眉页脚。WTF?我就转换个文档,还得多学一门语言?
2.2、Typora
这款工具在1.0版本版本以前是免费使用的,现在是属于买不起系列了。起初给人的感觉确实是挺惊艳的一款产品,收费后,用户量也下降了好多。
- 核心能力:所见即所得编辑,一键导出 PDF,支持基础页眉页脚(静态文本)。
- 局限:高级排版需付费版本,无法通过命令行批量处理。
- 适用场景:个人用户快速生成简单 PDF。
2.3、VS Code + Markdown Preview Enhanced
- 核心能力:通过浏览器打印功能生成 PDF,支持自定义 CSS 调整打印样式(如页边距、分页控制)。
- 扩展性:需熟悉 CSS 打印媒体查询语法,复杂排版需手动调试。
- 示例代码:
@page { @top-center { content: "页眉内容"; } }局限性是需要一定的CSS基础,对于复杂排版需要手动调试。更多的是面对开发者使用。
2.4、在线转换工具
当然除了上述一些以外,还有一些在线转换工具。如易转换,Dillinger / StackEdit 等。在线网站转换的普遍会有几个通病,比如大小限制,水印,注册会员,关注公众号等等。
3、自己撸一个
找了一圈,发现大多数都不满足自己的使用需求。于是乎,突发奇想,要不自己生一个?生一个吧。
3.1、技术栈
- Python 3.11
- PyQt5:用于构建现代化的图形用户界面
- markdown2:提供Markdown到HTML的转换功能
- pdfkit: 提供HTML到PDF的转换功能
- wkhtmltopdf: PDF生成引擎
3.2、功能特性
- 批量转换:支持将整个文件夹的Markdown文件批量转换为PDF
- 自定义页眉页脚:可以为生成的PDF文件添加自定义的页眉和页脚
- 实时进度显示:转换过程中显示实时进度
- 自动页码:自动在PDF文件中添加页码
- 优雅的界面:简洁直观的用户界面,易于操作
- 智能路径检测:自动检测和配置wkhtmltopdf工具路径
3.3、环境要求
- Windows操作系统(已在Windows 10/11上测试)
- Python 3.6+
- wkhtmltopdf(程序会自动安装或使用系统已安装的版本)
3.4、核心代码
其实代码不难,得益于Python强大的库,核心逻辑+QT不到400行代码就能搞定。其核心代码如下:
获取windows安装的wkhtmltopdf进程:
def find_wkhtmltopdf():
# 首先检查程序目录下的bin文件夹
program_dir = os.path.dirname(os.path.abspath(__file__))
bin_path = os.path.join(program_dir, 'bin', 'wkhtmltopdf.exe')
if os.path.exists(bin_path):
return bin_path
# 检查程序目录
program_dir_path = os.path.join(program_dir, 'wkhtmltopdf.exe')
if os.path.exists(program_dir_path):
return program_dir_path
# 如果程序目录中不存在,尝试解压
if extract_wkhtmltopdf():
return program_dir_path
# 如果解压失败,检查其他可能的安装路径
possible_paths = [
'C:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe', # 默认64位安装路径
'C:\\Program Files (x86)\\wkhtmltopdf\\bin\\wkhtmltopdf.exe', # 默认32位安装路径
]
# 检查环境变量
if 'PATH' in os.environ:
for path_dir in os.environ['PATH'].split(os.pathsep):
wk_path = os.path.join(path_dir, 'wkhtmltopdf.exe')
if os.path.exists(wk_path):
return wk_path
# 检查可能的安装路径
for path in possible_paths:
if os.path.exists(path):
return path
return None动态生成页眉页脚:
class ConvertThread(QThread):
progress = pyqtSignal(int)
finished = pyqtSignal()
error = pyqtSignal(str)
def __init__(self, input_dir, output_dir, header_edit, footer_edit):
super().__init__()
self.input_dir = input_dir
self.output_dir = output_dir
self.header_edit = header_edit
self.footer_edit = footer_edit
def run(self):
try:
# 检查wkhtmltopdf是否可用
if not os.path.exists(WKHTMLTOPDF_PATH):
self.error.emit('未找到wkhtmltopdf,请确保已正确安装wkhtmltopdf工具!')
return
md_files = [f for f in os.listdir(self.input_dir) if f.endswith('.md')]
total_files = len(md_files)
if total_files == 0:
self.error.emit('所选文件夹中没有找到.md文件!')
return
for i, md_file in enumerate(md_files, 1):
input_path = os.path.abspath(os.path.join(self.input_dir, md_file))
output_path = os.path.abspath(os.path.join(self.output_dir, f'{os.path.splitext(md_file)[0]}.pdf'))
with open(input_path, 'r', encoding='utf-8') as f:
markdown_content = f.read()
# 转换Markdown为HTML
html_content = markdown2.markdown(markdown_content)
# 添加页眉页脚
header = self.header_edit.text()
footer = self.footer_edit.text()
# 创建页眉HTML
header_html = ""
if header:
header_html = f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
body {{ margin: 0; padding: 0; }}
.header {{
text-align: left;
font-size: 14px;
color: #333333;
padding: 5px 10px;
border-bottom: 1px solid #cccccc;
background: linear-gradient(to right, #FFA500, #FFE4B5);
margin: 0 0 10px 0;
width: 100%;
box-sizing: border-box;
height: 30px;
line-height: 22px;
}}
</style>
</head>
<body>
<div class="header">{header}</div>
</body>
</html>
"""
# 创建页脚HTML
footer_html = ""
if footer:
footer_html = f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
body {{ margin: 0; padding: 0; }}
.footer {{
text-align: left;
font-size: 14px;
color: #333333;
padding: 5px 10px;
border-top: 1px solid #cccccc;
background: linear-gradient(to right, #FFA500, #FFE4B5);
margin: 0;
width: 100%;
box-sizing: border-box;
height: 30px;
line-height: 22px;
}}
</style>
</head>
<body>
<div class="footer">{footer}</div>
</body>
</html>
"""
# 创建临时文件保存页眉页脚HTML
header_path = os.path.join(self.output_dir, f'header_{os.path.splitext(md_file)[0]}.html')
footer_path = os.path.join(self.output_dir, f'footer_{os.path.splitext(md_file)[0]}.html')
try:
with open(header_path, 'w', encoding='utf-8') as f:
f.write(header_html)
with open(footer_path, 'w', encoding='utf-8') as f:
f.write(footer_html)
html_template = f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
body {{ margin: 40px; }}
</style>
</head>
<body>
{html_content}
</body>
</html>
"""
# 配置PDF选项
options = {
'page-size': 'A4',
'margin-top': '25mm',
'margin-right': '15mm',
'margin-bottom': '25mm',
'margin-left': '15mm',
'encoding': "UTF-8",
'enable-local-file-access': True,
'header-spacing': '10',
'footer-spacing': '10',
'header-html': header_path if header else None,
'footer-html': footer_path if footer else None,
'footer-right': '[page]'
}
# 执行转换
pdfkit.from_string(html_template, output_path, options=options, configuration=config)
finally:
# 清理临时文件
if os.path.exists(header_path):
os.remove(header_path)
if os.path.exists(footer_path):
os.remove(footer_path)
progress = int((i / total_files) * 100)
self.progress.emit(progress)
self.finished.emit()
except Exception as e:
self.error.emit(str(e))3.5、演示
代码撸完后,运行如下命令打包:
pyinstaller --name="Markdown2PDF" --windowed --icon=icon/logo.png --add-data="wkhtmltox-0.12.6-1.msvc2015-win64.exe;." main.py
接着双击运行该程序:
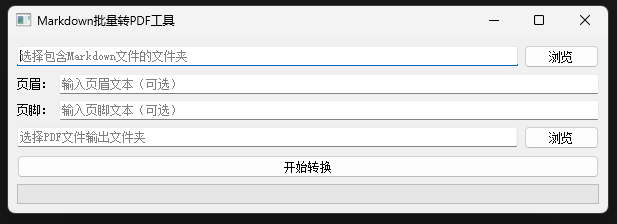
选择我们需要转换的存放md文件的路径,输入我们的想要插入的页眉页脚内容,再选择我们要输出的存放pdf的目录,点击转换即可。转换成功后的pdf:

页眉页脚:

速度还是可以的。不过这里还有一些毛病,比如代码块的格式化,水印等等。后续持续完善......
3.6、开源
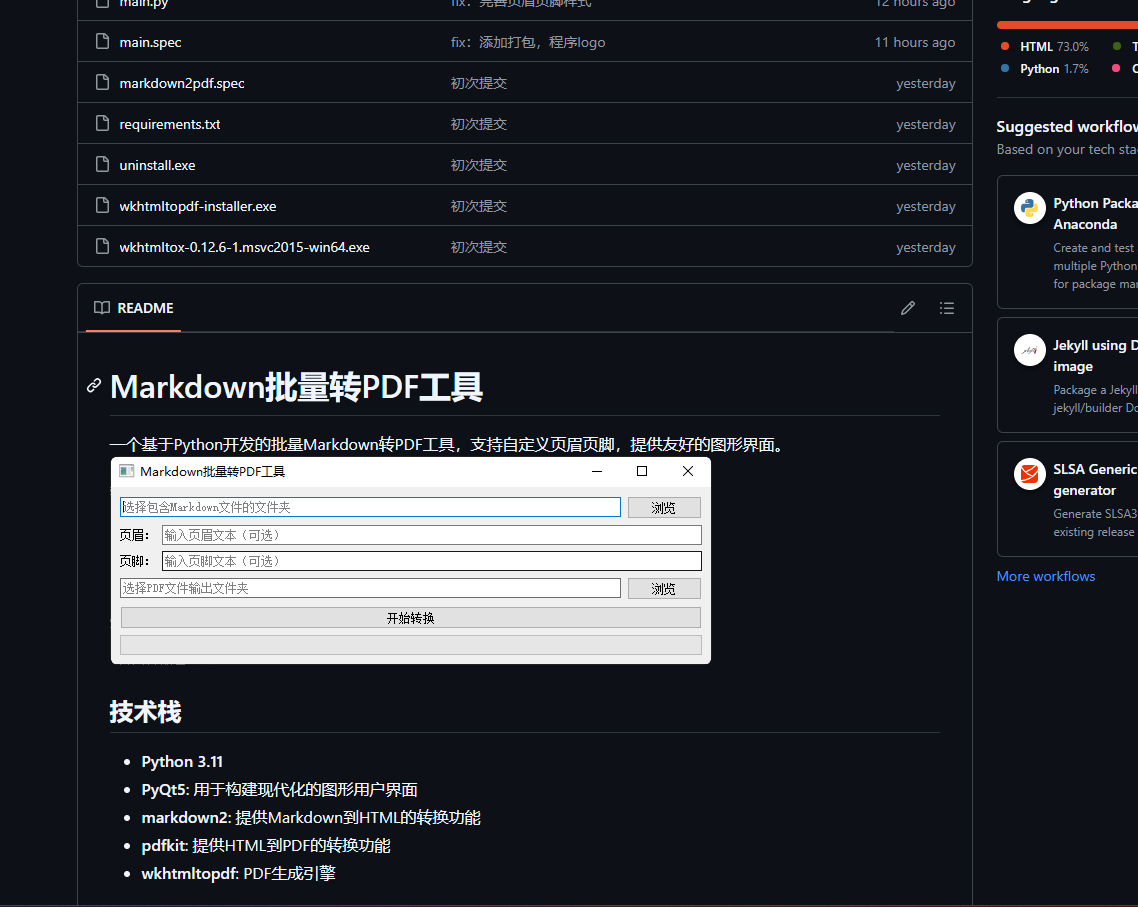
该项目代码已经上传到github:https://github.com/Shamee99/Markdown2PDF。有需要的可以自行下载,因为时间有限,后续更新可能比较缓慢。有兴趣的可以创建分支一起持续迭代。
4、最近在做的事
最近也在整理一些关于《Java体系》的相关知识内容和书籍,涵盖了Java、Spring、数据库、AI、Linux等一系列使用到的相关内容。目前已经整理一部分,等我整理完也会同步到Git上,有使用到的朋友们可以自行获取。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
