【零绘画基础程序员必学】AI绘画入门笔记01—Stable Diffusion上手体验
原创
【零绘画基础程序员必学】AI绘画入门笔记01—Stable Diffusion上手体验
原创
CS逍遥剑仙
修改于 2025-04-18 09:43:22
修改于 2025-04-18 09:43:22
【零绘画基础程序员必学】AI绘画入门笔记01—Stable Diffusion上手体验
前几年火爆全球的AI图像生成如今已经成为了设计师的必备工作流,作为不会绘画的程序员,平时做PPT、写文档也常常被插图困扰,是时候系统地学习下AI生图工具Stable Diffusion了。
传统的本地安装方式,为了更高效的出图效率,需要额外配置一台性能不错的机器和显卡,环境安装和低效的出图等待让很多新手的SD学习生涯折戟。
腾讯云高性能应用服务HAI 以极简安装、高性能、低价格成为 AIGC 新手福音!
1. SD安装和汉化
Stable Diffusion WebUI 是 SD 的可视化操作界面,建议在英伟达显卡的 windows 系统机器上安装,有一键整合包和官方版本安装两种传统方式。
更推荐新手小白使用腾讯云高性能应用服务HAI方式,一键化部署,配置简单易于上手:
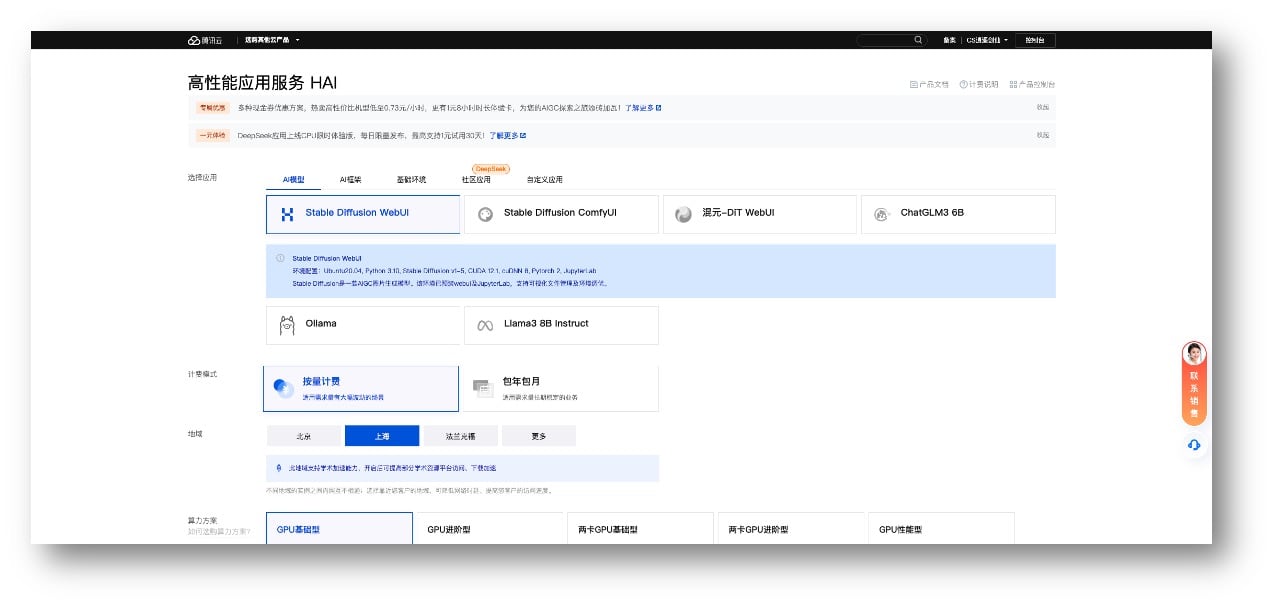
免去了下面这些本地安装步骤:
使用官方版本的安装方式可以安装最纯正的程序,但按需一个个安装模型和插件。 环境准备:Python + Git,预留100G空间安装 Stable Diffusion WebUI: $ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 下载结束后在
stable-diffusion-webui文件夹中双击打开webui-user.bat,完成安装后会自动启动服务,浏览器打开127.0.0.1:7860就可以看到 Stable Diffusion WebUI 界面了。
初次启动 WebUI 后,推荐安装汉化语言包、双语翻译扩展,点击 "extensions"=>"Available"=>"Load from" 加载插件。
- 搜索 "zh_Hans" 安装汉化语言包;
- 搜索 "bilingual" 安装双语翻译;
- 点击 "Installed"=>"Apply and restart UI" 重启UI界面;
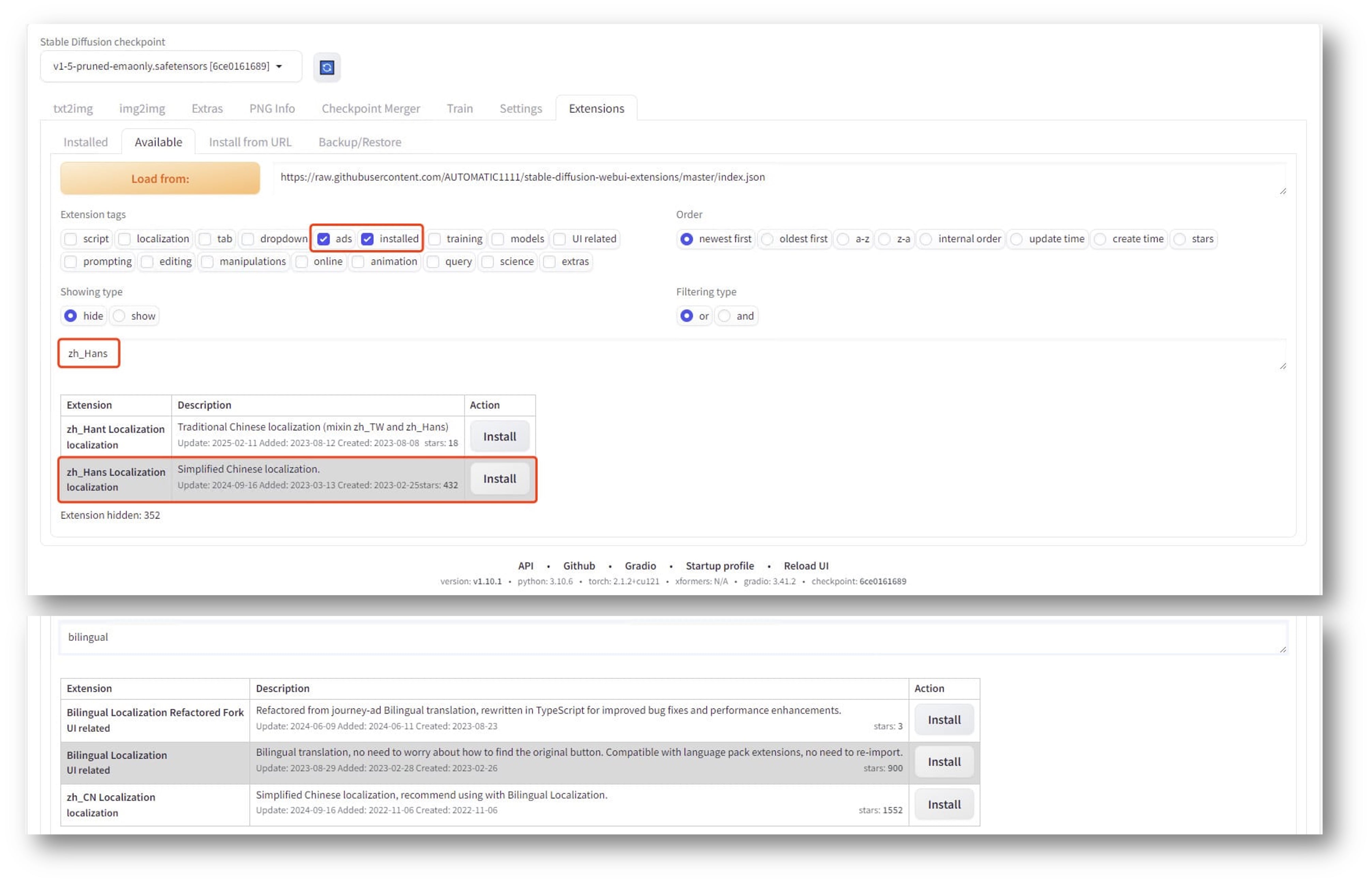
- "Settings"=>"User interface"=>"Localization" 选择汉化包后 "Apply settings" 并 Reload 即可看到中文界面。

2. Prompt 提示词技巧
AI图像生成并非一笔一笔地去绘画,而是经过"扩散"的方式,从模糊的图像一步步到清晰。
SD支持两种绘制方式:"文生图" 和 "图生图",需要用户输入文本或图像信息,也就是 Prompt(提示词) 来指导模型根据一些特定的需求生成艺术作品。提示词分为:正向提示词(想要的内容),负向提示词(不想要的内容)。
提示词必须是英文,使用英文逗号分隔,一般多写的效果优于少写。
2.1 内容型提示词分类
【人物及主体特征】
服饰穿搭 white dress
发型发色 blonde hair, long hair
五官特点 small eyes, big mouth
面部表情 smiling
肢体动作 stretching arms
【场景特征】
室内室外 indoor / outdoor
大场景 forest, city, street
小细节 tree, bush, white flower
【环境光照】
白天黑夜 day / night
特定时段 morning, sunset
光环境 sunlight, bright, dark
天空 blue sky, starry sky
【画幅视角】
距离 close-up, distant
人物比例 full body, upper body
观察视角 from above, view of back
镜头类型 wide angle, Sony A7 Ⅲ2.2 标准化提示词
还有一些标准化的提示词,通常固定添加在提示词末尾:
【画质】
通用高画质 best quality, ultra-detailed, masterpiece, hires, 8k
特定高分辨类型 extremely detailed CG unity 8k wallpaper (超精细的8K Unity游戏CG) / unreal engine rendered (虚幻引擎渲染)
【画风】
插画风 illustration, painting, paintbrush
二次元 anime, comic, game CG
写实系 photorealistic, realistic, photograph2.3 基本框架模板
书写提示词的基本框架和通用模板推荐:
步骤 | 提示词demo |
|---|---|
描述人物 | (1 girl:2.0), solo, nilou (genshin impact), solo, long hair, jewelry, blue gemstone, earrings, horns, crown, cyan satin strapless dress, white veil, neck ring, red hair, {green eyes}, |
描述场景 | indoor, room, house, sofa, wooden floor, plant, flowers, trees, windows, |
描述环境(时间、光照) | day, morning, sunlight, dappled sunlight, backlight, light rays, cloudy sky, |
描述画幅视角 | full body, wide angle shot, depth of field, |
其他画面要素 | light particles, fantasy, wind blow, maple leaf, dusty, ... |
高品质标准化 | {{masterpiece}}, {best quality}, {highres}, original, reflection, unreal engine, body shadow, artstationextremely detailed CG unity 8k wallpaper |
画风标准化 | (illustration), (painting), (sketch), anime coloring, fantasy, |
其他特殊要求 | exaggerated body proportions, greasy skin, realistic and delicate facial features, SFW, |
在正面提示词后添加:
(masterpiece:1,2), best quality, masterpiece, highres, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2), drawing, paintbrush,负面提示词后添加:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),2.4 提示词权重
提示词默认权重1,有两种修改权重的方式:
- 括号加数组:如
(white flower:1.5) - 套括号:
(1) 圆括号,每套一层x1.1倍,如 (((white flower))) 权重为 1.1x1.1x1.1=1.331
(2) 大括号,每套一层x1.05倍,如 {{{white flower}}} 权重为 1.05x1.05x1.05=1.158
(3) 方括号,每套一层x0.9倍,如 [[[white flower]]] 权重为 0.9x0.9x0.9=0.729
2.5 其他说明
- 可以尝试使用 AI 大模型,如 deepseek 生成提示词;
- 在 civitai.com 中学习和模仿优秀作品的提示词;
- 出图参数中设置总批次数、单批数量可以提高出图效率;
- 随机数种子 (Seed) 参数,唯一id+固定参数可以重现图片,可以固定seed用于在保留主体人物的基础上添加背景提示词修改背景。
3. 模型介绍
3.1 Checkpoint 检查点模型
也称关键点模型或大模型。
Checkpoint存放目录路径 |
| |
|---|---|---|
后缀类型1 |
| 通常大小几GB |
后缀类型2 |
| 通常大小1-2GB |
3.2 VAE 变分自解码器
一般作为检查点模型的外挂模型,可以粗略看成 AI 绘图的"调色滤镜",最直观影响的是画面的色彩质感。
VAE存放目录路径 |
| |
|---|---|---|
后缀类型1 |
| |
后缀类型2 |
|
3.3 Embeddings & LoRa & Hypernetwork
Embeddings 嵌入式向量
- 目录位置
<root>/embeddings/; - 指向某一特定形象(按书签翻字典),所以模型体积很小只有几十k,在深度学习领域全称 "嵌入式向量";
- WebUI 中使用时自动添加到提示词中;
Negative Embeddings: 如 EasyNegative 是一种综合的、全方位的基于负面样本的提炼,可以用于解决大部分肢体错乱、颜色混杂、噪点和灰度异常等,如负向提示词中添加(easynegative:1.2)轻松解决手部错误问题。
Q: 不知道如何调节 Embeddings 形象的细节? A: 尝试使用"图生图"的反推提示词功能找到样图的可用提示词
LoRa 低秩适应模型
- 目录位置
<root>/models/Lora/; - 全称:Low-Rank Adaptation Model 大模型的低秩适应,和 Checkpoint 模型格式一致,一般为
.skpt或.safetensors,大约100~200M,但相对 Checkpoint 也很小了,可以通过体积大小区分开。需要配合大模型使用,类似字典里的夹页,提供更多信息。用于向AI传递、描述某一特征准确、主体清晰的形象,主要应用于各种游戏、动漫角色的二次创作构建,需要各种角度特征的素材进行训练; - WebUI 中使用时添加到提示词中,如
<Lora:xxxx:0.8>。搭配Additional Network扩展后 LoRa 可以多个一起混合使用,如下图所示:
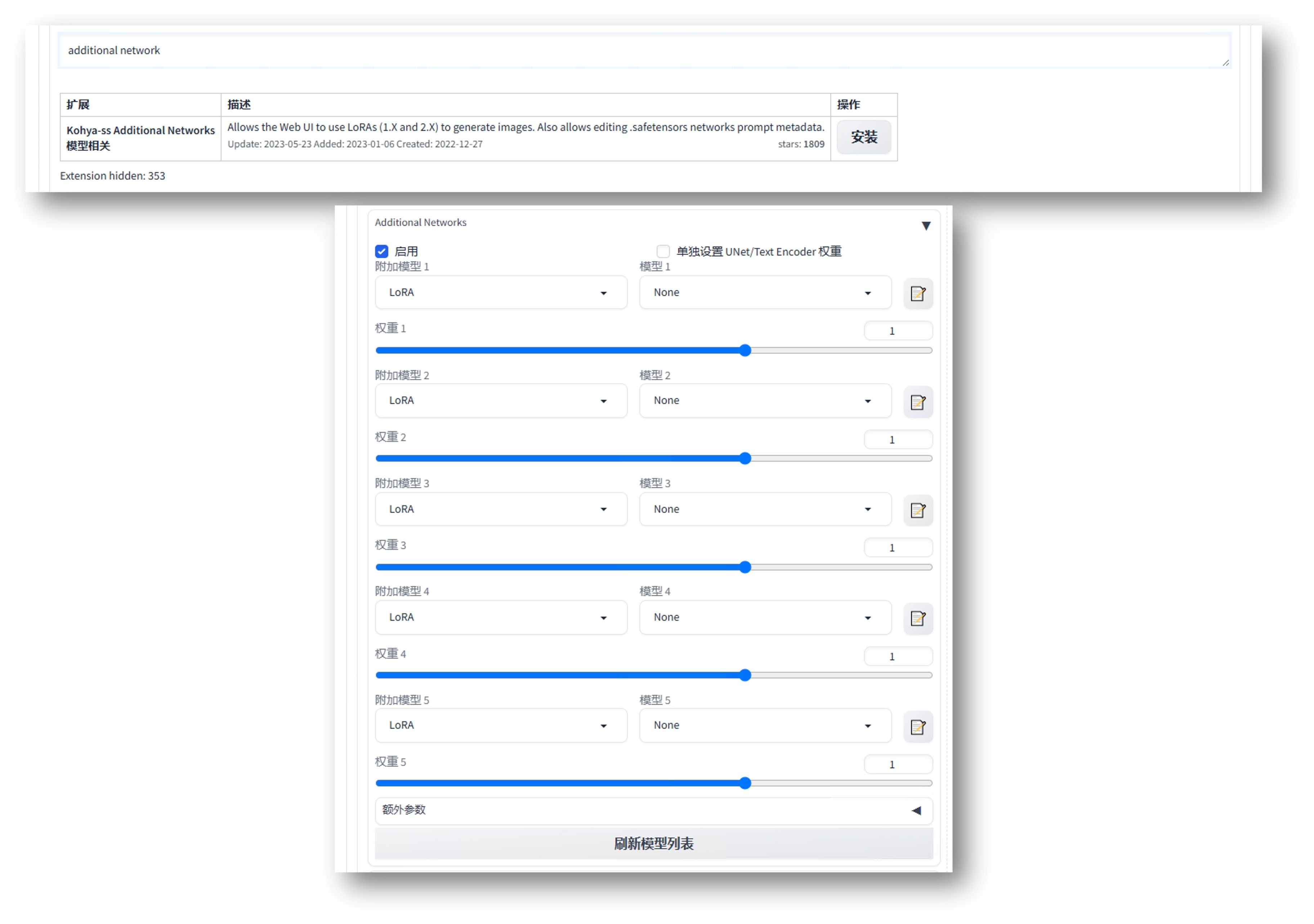
5个LoRa的实际应用为:
- character(人物角色形象):如塞尔达公主形象;
- style(画风或风格):如宫崎骏的吉卜力风格;
- concept(概念):如档案照片、梗图复现;
- cloth(服饰):概念的延展,如赛博机甲(Mecha);
- object(物体/特定元素):可以使用局部重绘将特定元素引入画面中;
Hypernetwork 超网络
- 目录位置
<root>/models/hypernetworks/; - 最终实现的效果和 LoRa 类似,区别在于一般用于改善生成图像的整体风格,即 "画风",比 Checkpoint 定义的画风更为精细,目前由于部分功能可由 LoRa 替代,实用性不强;
- WebUI 中使用繁琐,需要在
Settings面板的Extra Networks(附加网络) 选项中选择并设置Add hypernetwork to prompt。
3.4 模型下载
推荐两个模型下载网站:
3.5 模型推荐
大模型类型 | |||
|---|---|---|---|
二次元 | Anything V5 | Counterfeit V2.5 | Dreamlike Diffusion |
真实 | Deliberate | Realistic Vision | LOFI |
2.5D风 | Never Ending Dream (NED) | Protogen (Realistic) | 国风3(GuoFeng3) |
万象熔炉 | Anything XL https://civitai.com/models/9409
Counterfeit-V3.0 https://civitai.com/models/4468
Dreamlike Diffusion 1.0 https://civitai.com/models/1274
deliberate-for-invoke https://civitai.com/models/5585/deliberate-for-invoke
Realistic Vision V6.0 B1 https://civitai.com/models/4201
LOFI https://civitai.com/models/9052
NeverEnding Dream (NED) https://civitai.com/models/10028
Protogen x3.4 (Photorealism) Official Release https://civitai.com/models/3666
国风3 GuoFeng3 https://civitai.com/models/10415
词嵌入(Embeddings)模型 | |
|---|---|
easynegative.safetensors |
低秩适应(LoRa)模型 | |
|---|---|
2bNierAutomataLora_v2b |
4. 扩展安装
扩展查阅地址:
https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json
常用扩展推荐:
1. 中文语言包
搜索:zh
https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans.git
2. 图库浏览器
搜索:image browser
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
3. 提示词补全
搜索:tag complete
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
4. 提示词反推
搜索:tagger
https://github.com/toriato/stable-diffusion-webui-wd14-tagger.git
5. Ultimate Upscale脚本
搜索:ultimate upscale
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
6. Local Latent Couple
搜索:llul
https://github.com/hnmr293/sd-webui-llul
7. Cutoff
搜索:cut off
https://github.com/hnmr293/sd-webui-cutoff.git
8. Infinite Zoom
搜索:Infinite Zoom
https://github.com/v8hid/infinite-zoom-automatic1111-webui.git5. SD的放大修复手段
5.1 文生图【高清修复】选项
文生图不推荐直接设置高分辨率,否则出图内容极易出现多人多头等错误,可以勾选文生图中的"高清修复"(Hi-Res Fix)选项。
高清修复比较消耗资源,SD先绘制一张低分辨率图片,再基于此图生成一张高分辨率图。
关于放大算法选项,网络流传无脑选择 R-ESRGAN 4x+,二次元选择 R-ESRGAN 4x+ Anime6B,实测各类算法差别不大,建议多尝试几种对比使用。
图生图则可以直接调高分辨率实现高清修复,原理和文生图一致。
5.2 图生图【优化细节】插件
在图生图插件中选择 SD upscale,通过分割几块绘制再拼到一起的方式实现放大,适用于图生图的普遍细节优化,但细节较"不可控"。
- 优势:可以突破内存限制获得更高分辨率,最高可达4倍宽高,且画面精细度高,对细节的丰富效果出色;
- 缺陷:分割重绘的过程较不可控(语义误导和分割线割裂,需要使用分界线缓冲区缓解),操作繁琐且相对不直观,偶尔"加戏"出现莫名的额外元素。
5.3 后期附加功能中的【无损放大】
简单方便,完全不改变图片内容,随时可以调用,计算速度快,但效果一般,建议在前面的放大方式基础之上再执行一次这种简单放大。
6. 局部重绘
局部重绘属于图生图的一个分支功能,通过蒙版重绘部分内容。
- 局部重绘:手动绘制蒙版执行重绘
- 涂鸦重绘:画笔涂鸦不仅划出范围,而是能传递信息,包括内容形状和颜色
- 上传重绘蒙版:可以上传在ps里精确处理后的蒙版图执行重绘
7. ControlNet
ControlNet 插件是 SD 中的一个非常关键的工具,核心作用是帮助用户对 AI 施加一些难以用语言文字描述的精准控制。
- 扩展中搜索 "sd-webui-controlnet" 安装插件并重启;
- 除插件主体外,还需安装模型,链接:github 和 huggingface;
- 下载的模型存放目录:
<root>/models/ControlNet/; - 模型后缀格式:
.pth+.yaml; - 可以在设置中修改开启的 controlnet 单元数量,数量越多,资源消耗越大;
5个应用最为广泛的控制模型:
- Openpose(动作姿势):上传图片分析人物姿势、手指、表情等,如下图所示;
- Depth(深度):如教堂建筑透视关系、人物手臂交叉时的前后关系等;
- Canny(边缘检测(线稿)):来自图像处理领域的边缘处理算法,生成需要还原外形特征的场景,以及需要确保不变形的文字和标识,生成黑底白线,从线稿生图;
- Softedge(柔和边缘):和Canny类似描述边缘特征,但边缘更加模糊(边缘约束弱于Canny),带来更大的发挥空间;
- Scribble(涂鸦乱画):比Softedge更自由、奔放的描摹,做一位"灵魂画手"!

在实际应用时可以多个 ControlNet 同时使用,如 Openpose + Depth 能够很好地识别手臂的前后、交叉关系,这是因为不同的 ControlNet 控制的内容实现了互补。
下一篇将进入SD的深度学习。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号