golang库源码学习——Pond,小而精的工作池库
原创
pond 是一个轻量级的 Goroutine 池库,用于高效管理并发任务。它提供了灵活的配置选项和多种策略,适合处理高并发场景。
https://github.com/alitto/pond/tree/v1
一、特点:
1.轻量级
pond 的代码库非常精简,它的V1版本仅有四个业务文件!因此它的体积小,加载速度快。
2.零依赖
只依赖于 Go 的标准库(如 sync、time 等),这个是它最大的特点,其实看代码就能看出来,基本上就是用的chan的封装,但是在这个基础上增加了动态设置的功能
3.稳定性高
因为依赖少,pond 不会因为第三方库的更新或兼容性问题而受到影响,稳定性更高。在复杂的项目环境中,零依赖的库更容易维护和调试
4.易于集成
pond基本可以无缝集成到任何 Go 项目中,无需担心依赖冲突或版本问题
二、场景:
1.嵌入式系统
在资源受限的嵌入式系统中,零依赖的库可以显著减少内存占用和二进制文件大小。
pond 的轻量级特性使其非常适合在嵌入式设备中管理并发任务。
2. 复杂框架
比如业界的负责RPC、HTTP框架,可以减少对原始框架的侵害
3. 微服务架构
在微服务架构中,每个服务通常需要独立部署和运行。零依赖的库可以避免引入不必要的依赖,减少部署复杂度。
pond 可以用于处理微服务中的高并发任务,如请求处理、数据同步等。
4. 高性能计算
在高性能计算场景中,零依赖的库可以减少额外的开销,提升计算效率。
pond 的 Goroutine 池机制可以高效管理并发任务,适合用于并行计算、数据处理等场景。
5. 库开发
如果你正在开发一个 Go 库,并且希望尽量减少对外部依赖的引入,pond 是一个理想的选择。
零依赖的特性可以确保你的库更加通用和易于集成。
三、功能:
1.动态设置 Goroutine 池的大小和工作线程:
package main
import (
"fmt"
"github.com/alitto/pond"
)
func main() {
// Create a buffered (non-blocking) pool that can scale up to 100 workers
// and has a buffer capacity of 1000 tasks
pool := pond.New(100, 1000)
// Submit 1000 tasks
for i := 0; i < 1000; i++ {
n := i
pool.Submit(func() {
fmt.Printf("Running task #%d\n", n)
})
}
// Stop the pool and wait for all submitted tasks to complete
pool.StopAndWait()
}这里例子里面设置了一个1000协程的任务池,并有100个工作线程来处理
我们看下pond的源代码:
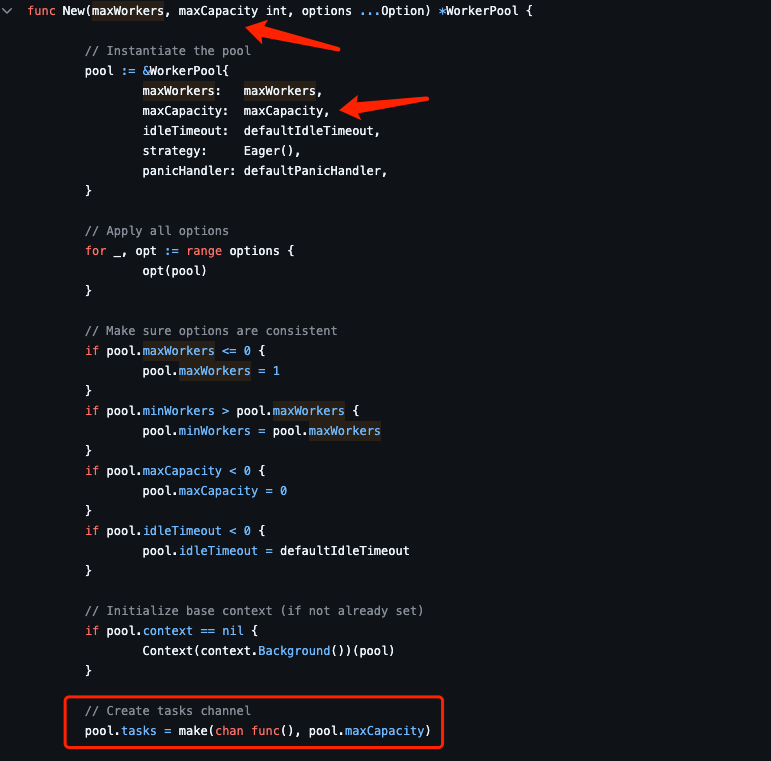
本质上就是创建了一个长度为1000的chan
而启动并执行工作线程的前提这里主要做一个“正在工作的线程”数目的比较,如果
runningWorkerCount大于等于设置的线程,或者还有空闲工作线程,则不再生成新的工作线程
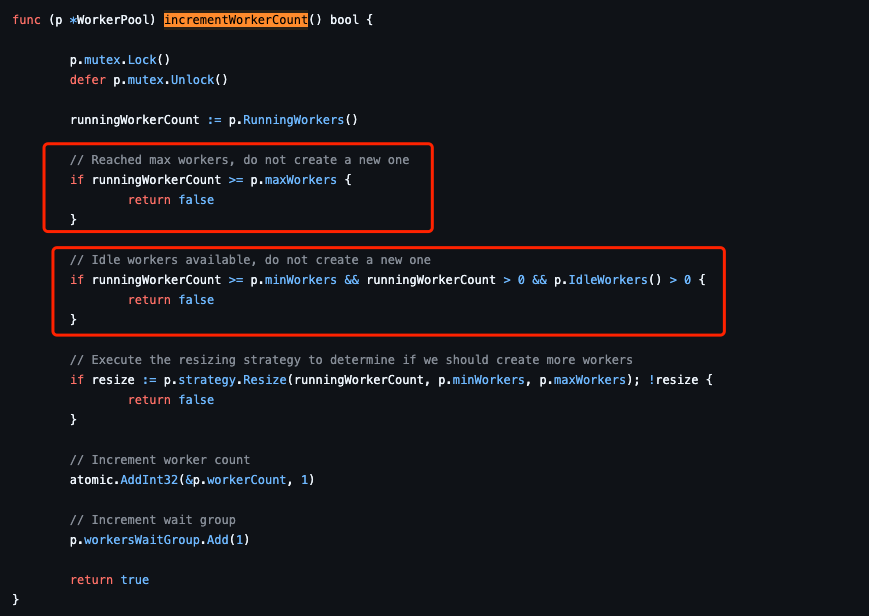
当然这里还有一个策略问题后面会讲到
2.动态设置 Goroutine 池的大小和工作线程及最小的工作协程数:
package main
import (
"fmt"
"github.com/alitto/pond"
)
func main() {
// Create an unbuffered (blocking) pool with a fixed
// number of workers
pool := pond.New(10, 0, pond.MinWorkers(10))
// Submit 1000 tasks
for i := 0; i < 1000; i++ {
n := i
pool.Submit(func() {
fmt.Printf("Running task #%d\n", n)
})
}
// Stop the pool and wait for all submitted tasks to complete
pool.StopAndWait()
}这样设置确保池中始终至少有 10 个 Goroutine,即使没有任务需要处理。当任务到来时,这些 Goroutine 可以立即处理任务,而不需要等待新的,这种设置适合的场景为:
1. 高并发场景:
如果你的应用需要处理大量并发任务,设置 MinWorkers 可以确保有足够的 Goroutine 来处理任务,避免任务堆积。
2. 低延迟场景:
如果你的应用对响应速度要求较高,设置 MinWorkers 可以减少任务处理的时间,提高整体性能。
3. 资源敏感场景:
如果你的应用需要严格控制资源使用,设置 MinWorkers 可以确保 Goroutine 的数量不会低于某个阈值,从而避免资源不足的问题
其中,这里有一个很好的设计模式,设计模式:函数式选项模式(Functional Options Pattern)
看下源码:
func New(maxWorkers, maxCapacity int, options ...Option) *WorkerPool {
// Instantiate the pool
pool := &WorkerPool{
maxWorkers: maxWorkers,
maxCapacity: maxCapacity,
idleTimeout: defaultIdleTimeout,
strategy: Eager(),
panicHandler: defaultPanicHandler,
}
// Apply all options
for _, opt := range options {
opt(pool)
}
...
}func MinWorkers(minWorkers int) Option {
return func(pool *WorkerPool) {
pool.minWorkers = minWorkers
}
}可以看出来New方法这里传参都是函数式的,并通过opt进行执行
这样就是典型的函数式选项模式(Functional Options Pattern)
这种模式的核心思想是:
·通过传递函数来配置对象,而不是直接传递参数
·每个函数负责设置对象的一个特定属性
为什么使用函数式选项模式?
可扩展性
如果直接在 New 函数中传递参数,当需要新增配置选项时,必须修改 New 函数的签名,这会导致破坏性变更(Breaking Change)。
使用函数式选项模式,可以通过新增函数来扩展配置选项,而无需修改 New 函数的签名。
灵活性
函数式选项模式允许用户只设置需要的选项,而忽略其他选项。
例如,pond.New 可以接受任意数量的配置函数,用户可以根据需求选择性地传递这些函数。
可读性
通过函数式选项模式,代码的可读性更高。每个配置函数都有一个明确的名称,可以直观地表达其作用。
例如,pond.MinWorkers(10) 比直接传递一个 10 更容易理解。
默认值
函数式选项模式可以方便地为配置选项提供默认值。如果用户没有传递某个配置函数,则使用默认值。
3.动态设置 Goroutine 池的大小和工作线程及任务组和上下文:
单独创建组:
package main
import (
"fmt"
"github.com/alitto/pond"
)
func main() {
// Create a pool
pool := pond.New(10, 1000)
defer pool.StopAndWait()
// Create a task group
group := pool.Group()
// Submit a group of tasks
for i := 0; i < 20; i++ {
n := i
group.Submit(func() {
fmt.Printf("Running group task #%d\n", n)
})
}
// Wait for all tasks in the group to complete
group.Wait()
}创建组及设置组内上下文:
package main
import (
"context"
"fmt"
"net/http"
"github.com/alitto/pond"
)
func main() {
// Create a worker pool
pool := pond.New(10, 1000)
defer pool.StopAndWait()
// Create a task group associated to a context
group, ctx := pool.GroupContext(context.Background())
var urls = []string{
"https://www.golang.org/",
"https://www.google.com/",
"https://www.github.com/",
}
// Submit tasks to fetch each URL
for _, url := range urls {
url := url
group.Submit(func() error {
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
resp, err := http.DefaultClient.Do(req)
if err == nil {
resp.Body.Close()
}
return err
})
}
// Wait for all HTTP requests to complete.
err := group.Wait()
if err != nil {
fmt.Printf("Failed to fetch URLs: %v", err)
} else {
fmt.Println("Successfully fetched all URLs")
}
}此功能为共同任务的子任务提供同步、错误传播和上下文取消功能。类似于 golang.org/x/sync/errgroup 软件包中的 errgroup.Group,并发性受 Worker 池约束。
这里主要是便于业务管理
4. 一些灵活的设置:
比如这是工作线程的自动销毁,为闲时降低工作负载
// This will create a pool that will remove workers 100ms after they become idle
pool := pond.New(10, 1000, pond.IdleTimeout(100 * time.Millisecond))比如做一些panic的收集
// Custom panic handler function
panicHandler := func(p interface{}) {
fmt.Printf("Task panicked: %v", p)
}
// This will create a pool that will handle panics using a custom panic handler
pool := pond.New(10, 1000, pond.PanicHandler(panicHandler)))5. 工作线程策略:
这里是一个比较有意思的地方
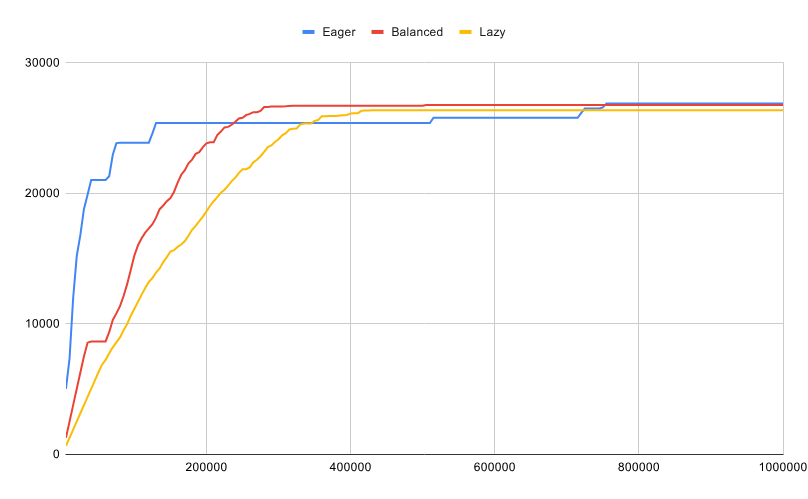
池大小调整策略:预设了三种常见场景的策略:进取型、均衡型和懒惰型
进取型:以提高资源使用率为代价最大化响应速度,在某些情况下可能会降低吞吐量。该策略适用于在大部分时间内以小部分容量运行,偶尔会收到突发任务的工人池。这是默认策略。
均衡型:试图在响应速度和吞吐量之间找到平衡。它适用于一般用途的工作池,或那些大部分时间都以接近 50%的容量运行的工作池。
懒惰型:以牺牲响应速度为代价最大化吞吐量。这种策略适用于大部分时间都将以接近最大容量运行的工人池。
默认是Eager
下图说明了随着提交任务数量的增加,不同池大小调整策略的行为。每条线代表池中工作进程的数量(池规模),X 轴代表已提交任务的数量(累计)。
我们看看源码实现:
var maxProcs = runtime.GOMAXPROCS(0)
// Preset pool resizing strategies
var (
// Eager maximizes responsiveness at the expense of higher resource usage,
// which can reduce throughput under certain conditions.
// This strategy is meant for worker pools that will operate at a small percentage of their capacity
// most of the time and may occasionally receive bursts of tasks. It's the default strategy.
Eager = func() ResizingStrategy { return RatedResizer(1) }
// Balanced tries to find a balance between responsiveness and throughput.
// It's suitable for general purpose worker pools or those
// that will operate close to 50% of their capacity most of the time.
Balanced = func() ResizingStrategy { return RatedResizer(maxProcs / 2) }
// Lazy maximizes throughput at the expense of responsiveness.
// This strategy is meant for worker pools that will operate close to their max. capacity most of the time.
Lazy = func() ResizingStrategy { return RatedResizer(maxProcs) }
)
// ratedResizer implements a rated resizing strategy
type ratedResizer struct {
rate uint64
hits uint64
}
// RatedResizer creates a resizing strategy which can be configured
// to create workers at a specific rate when the pool has no idle workers.
// rate: determines the number of tasks to receive before creating an extra worker.
// A value of 3 can be interpreted as: "Create a new worker every 3 tasks".
func RatedResizer(rate int) ResizingStrategy {
if rate < 1 {
rate = 1
}
return &ratedResizer{
rate: uint64(rate),
}
}
func (r *ratedResizer) Resize(runningWorkers, minWorkers, maxWorkers int) bool {
if r.rate == 1 || runningWorkers == 0 {
return true
}
r.hits++
return r.hits%r.rate == 1
}可以看到三种策略的本质实现是:基于当前可以运行的CPU核数来判断的
1.进取型默认为一,即主要需要工作线程,就增加
2.均衡型为CPU核数的一半,即如果在一个16核的机器上,每增加8个任务,增加一个工作线程
3.懒惰型为CPU核数,即如果在一个16核的机器上,每增加16个任务,增加一个工作线程
这里就是为什么进取型适合前端页面API的类型,有时猛的过来一堆任务需要完成,但很多时候并不会有线程过来
6. 异步工作:
那提交任务是同步还是异步的?
答案是可以同步、也可以异步
分别是TrySubmit和Submit
func (p *WorkerPool) TrySubmit(task func()) bool {
return p.submit(task, false)
}
func (p *WorkerPool) submit(task func(), mustSubmit bool) (submitted bool) {
if task == nil {
return
}
if p.Stopped() {
// Pool is stopped and caller must submit the task
if mustSubmit {
panic(ErrSubmitOnStoppedPool)
}
return
}
// Increment submitted and waiting task counters as soon as we receive a task
atomic.AddUint64(&p.submittedTaskCount, 1)
atomic.AddUint64(&p.waitingTaskCount, 1)
p.tasksWaitGroup.Add(1)
defer func() {
if !submitted {
// Task was not sumitted to the pool, decrement submitted and waiting task counters
atomic.AddUint64(&p.submittedTaskCount, ^uint64(0))
atomic.AddUint64(&p.waitingTaskCount, ^uint64(0))
p.tasksWaitGroup.Done()
}
}()
// Start a worker as long as we haven't reached the limit
if submitted = p.maybeStartWorker(task); submitted {
return
}
if !mustSubmit {
// Attempt to dispatch to an idle worker without blocking
select {
case p.tasks <- task:
submitted = true
return
default:
// Channel is full and can't wait for an idle worker, so need to exit
return
}
}
// Submit the task to the tasks channel and wait for it to be picked up by a worker
p.tasks <- task
submitted = true
return
}通过源码可以知道:
异步和同步的区别在于,提交任务后,是否要等提交成功再返回
刚才说到pond本质上是一个chan,长度固定没,如果任务满了,再提交任务,chan会堵塞
所以如果是异步提交就不会堵塞
这里保证的服务不会卡在这里
在很多程序中推荐使用TrySubmit
6. 可观测
能看的数据:
pool.RunningWorkers() int: Current number of running workers
pool.IdleWorkers() int: Current number of idle workers
pool.MinWorkers() int: Minimum number of worker goroutines
pool.MaxWorkers() int: Maxmimum number of worker goroutines
pool.MaxCapacity() int: Maximum number of tasks that can be waiting in the queue at any given time (queue capacity)
pool.SubmittedTasks() uint64: Total number of tasks submitted since the pool was created
pool.WaitingTasks() uint64: Current number of tasks in the queue that are waiting to be executed
pool.SuccessfulTasks() uint64: Total number of tasks that have successfully completed their exection since the pool was created
pool.FailedTasks() uint64: Total number of tasks that completed with panic since the pool was created
pool.CompletedTasks() uint64: Total number of tasks that have completed their exection either successfully or with panic since the pool was created
所以虽然代码量很少,但依然有做指标监控,使用的时候可以做日志上报
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
