IDC Redis如何基于云DTS实现云上容灾
原创IDC Redis如何基于云DTS实现云上容灾
原创
导读
本文为某A云厂商解决方案团队为陌陌IDC机房Redis实例实现云上灾备的定制方案(方案已脱敏)。针对 Redis 跨机房数据同步,行业普遍有两个非常常见的问题需要解决:
1. Redis 的复制风暴问题:为了提升主从同步的性能,Redis 在主节点中引入了环形复制缓冲区机制。主节点向从节点传输数据的同时,将相同的数据副本写入环形缓冲区,当从节点因网络抖动或其他异常情况断开连接并在后续重新连接时,主节点通过复制缓冲区将断连期间产生的增量数据传递给从节点实现断点续传避免全量同步。但是内存复制缓冲区一般来说不会太大(默认只有64M),从节点断点续传过程容易发生找不到offset而触发全量复制,从而触发主库所在宿主机复制风暴而OOM,导致整个集群不可用。
2. 非幂等指令(如incr)的数据同步的一致性问题:PSYNC 协议进行数据同步时,源节点通过 repl 字节流的 offset 值标识数据偏移,目标节点以 pipeline 方式写入数据,并定期(约 15 秒)持久化当前同步点位。然而,若任务因超时或重启中断,无法准确定位已完成的同步点位,可能导致点位回退。若回退范围内包含非幂等命令(如 incr 或 lpush),则可能造成目标端数据不一致。
本文从某A云厂商DTS的视角,通过结合在数据传输领域的技术积累和实践经验,针对上述两个问题提出了一套完整的解决方案,对企业Redis云上容灾有极大的参考价值。
1、陌陌Redis容灾需求调研
1.1、容灾项目背景
因为种种原因,陌陌在考虑基于云+IDC构建AZ级的容灾能力。
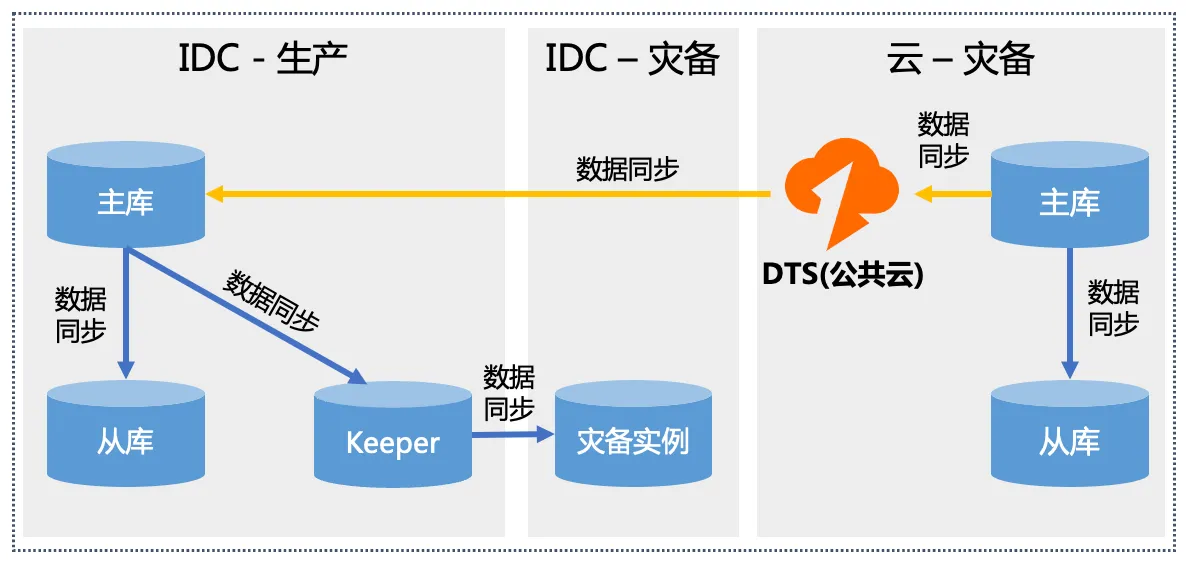
基于陌陌当前的容灾机房规划,预计容灾建设完成后,将存在生产IDC、灾备IDC、灾备云三类机房。机房间的容灾关系如下:
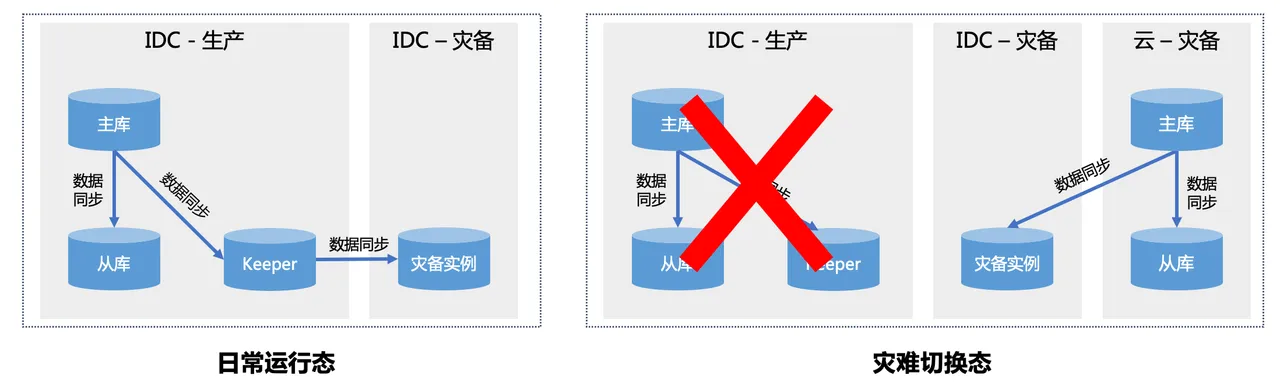
其中【IDC-生产】和【IDC-灾备】是常态存在的,而【云-灾备】按照当前的设计仅在故障发生时才会临时拉起。拉起后,生产流量将切换到云上运行。
临时搭建云上灾备看似是一种敏捷且低成本的容灾手段,但需要考虑临时搭建的云环境是否能正常承接流量,是否能正常运转。这里可能存在代码版本、上下游依赖缺失等种种问题导致业务主链路无法正常运转的情况,因此建议考虑针对核心业务构建云上常态化的容灾实例和同步链路。架构如下:
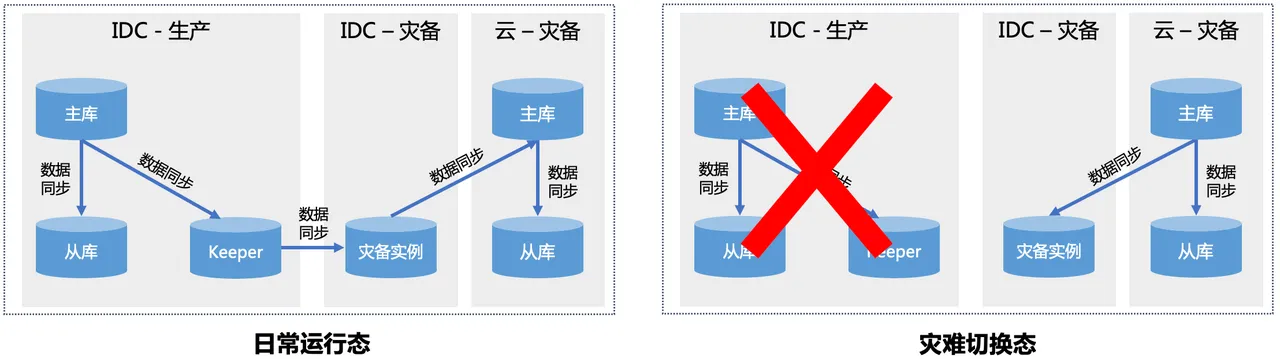
进一步讲,如果【云-灾备】的建设成本与【IDC-灾备】相差不大,甚至可以考虑去掉【IDC-灾备】,由云来承接对应角色,这也是当下更主流的云上云下容灾架构。从架构复杂度和实际应用价值来看,【IDC-灾备】仅仅是切换过渡态临时使用,意义看起来不大。
1.2、数据同步工具选择考虑
针对IDC之间以及IDC到云上如何实现数据同步的问题,因考虑到现有管控体系对云上数据库
实例的统一纳管能力,陌陌在云上的产品选型以IaaS+自建为主,初期考虑过基于原生复制
的同步方案,但考虑到IDC之间专线质量以及云上云下专线质量对Redis原生复制机制的影响
(RDB风暴问题),因此当前在数据同步方案上会有两种选型:
●基于DTS实现跨云同步
●基于开源XPipe的实现跨云同步
两种选型各有利弊,对于日常生产,从数据一致性、运维成本等角度对比如下:
DTS | XPipe | |
|---|---|---|
优势 | ●成熟的PaaS产品,具备完善的白屏化控制台和API接口●用户免运维●现网有超600+客户的Redis同步任务在跑,有标准SLA●对目标端实例无侵入,容灾切换时无需修改实例状态●IDC无需提供额外资源 | ●灵活部署,可部署到IDC内,规避专线质量问题●模拟Slaveof行为,数据一致性高 |
劣势 | ●抗网络抖动能力弱●极端情况下存在数据一致性问题 | ●产品应用案例有限,有运维成本,且需要用户自行兜底。●IDC有额外的资源消耗 |
总结下来,DTS需要解决如下几个关键问题,才能实现稳定可靠的跨云同步:
●问题1:针对大规模云上云下同步,增强抗网络抖动能力,避免RDB风暴问题。
●问题2:增强数据一致性保障能力,对齐和原生复制一样的数据位点保护机制。
2、DTS如何实现陌陌Redis云上容灾
2.1、基于DTS同步的容灾架构
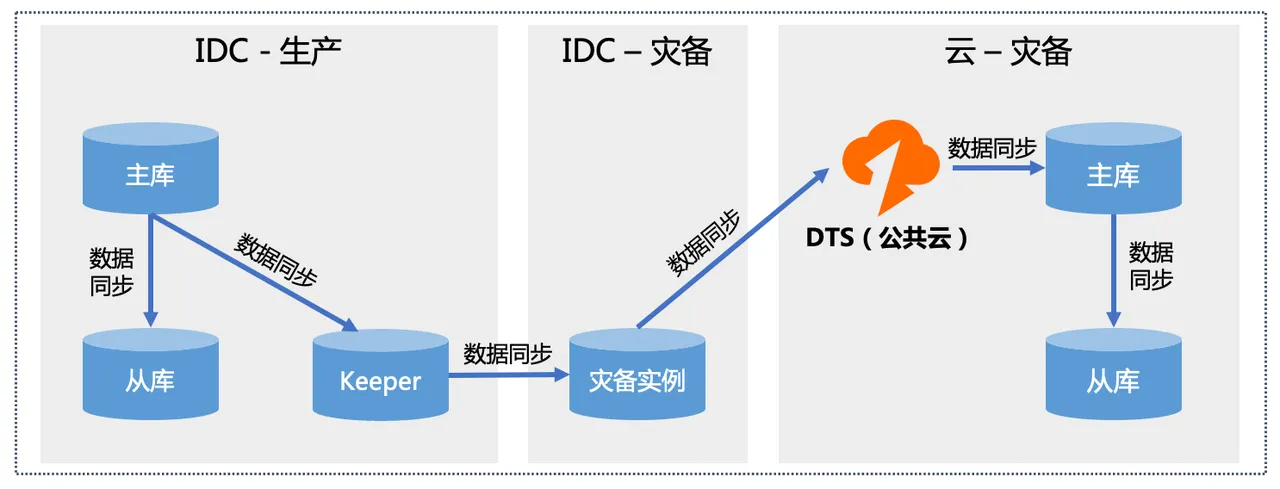
●当【IDC-生产】故障发生时,借助云上的弹性资源,基于公共云DTS临时拉取灾备实例的全量+增量数据到云上,构建云上的生产实例。如果针对核心业务要构建云上常态的容灾实例亦可采用此架构。
●同时aliyun在评估DTS是否可以在【IDC-生产】实现脱云输出,如果可行,则可以替换掉云下的XPipe,实现【IDC-生产】->【IDC-灾备】和【IDC-灾备】->【云-灾备】的同步方案统一。
2.2、关键问题的技术方案
2.2.1 Redis Exactly Once
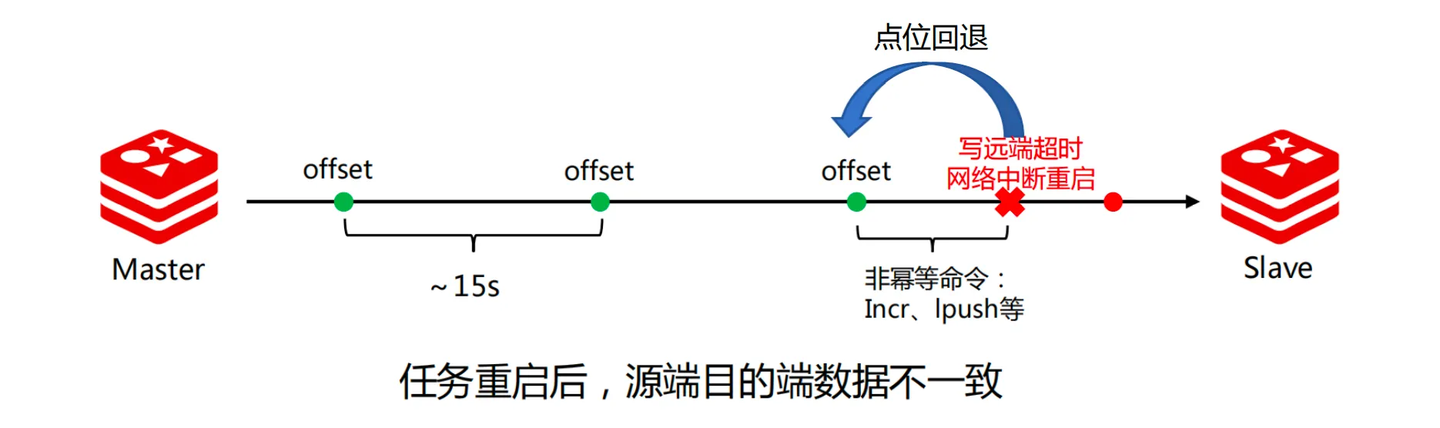
●背景问题:非幂等命令回退问题
使用数据同步工具同步社区 Redis 时,往往使用社区的 PSYNC 复制协议拉取源节点的数据,然后以客户端的形式写入目标节点。PSYNC 协议的增量阶段以 repl 字节流的 offset 值来表示当前的数据偏移,当同步任务进行时,一般对目的端以 pipeline 的方式写入数据,同步任务会定时(~15s)将当前同步的 offset 进行持久化。如果同步过程中任务写远端超时甚至任务重启,那么无法精确地知道目前已完成的点位,那么一旦出现点位回退,回退范围内存在非幂等的 Redis 命令(比如 incr/lpush 等)就会造成目的端数据不一致
●整体方案
为了解决上述问题,DTS引入Redis Exactly Once技术来实现位点的实时推进和与库内数据库的一致性保障。
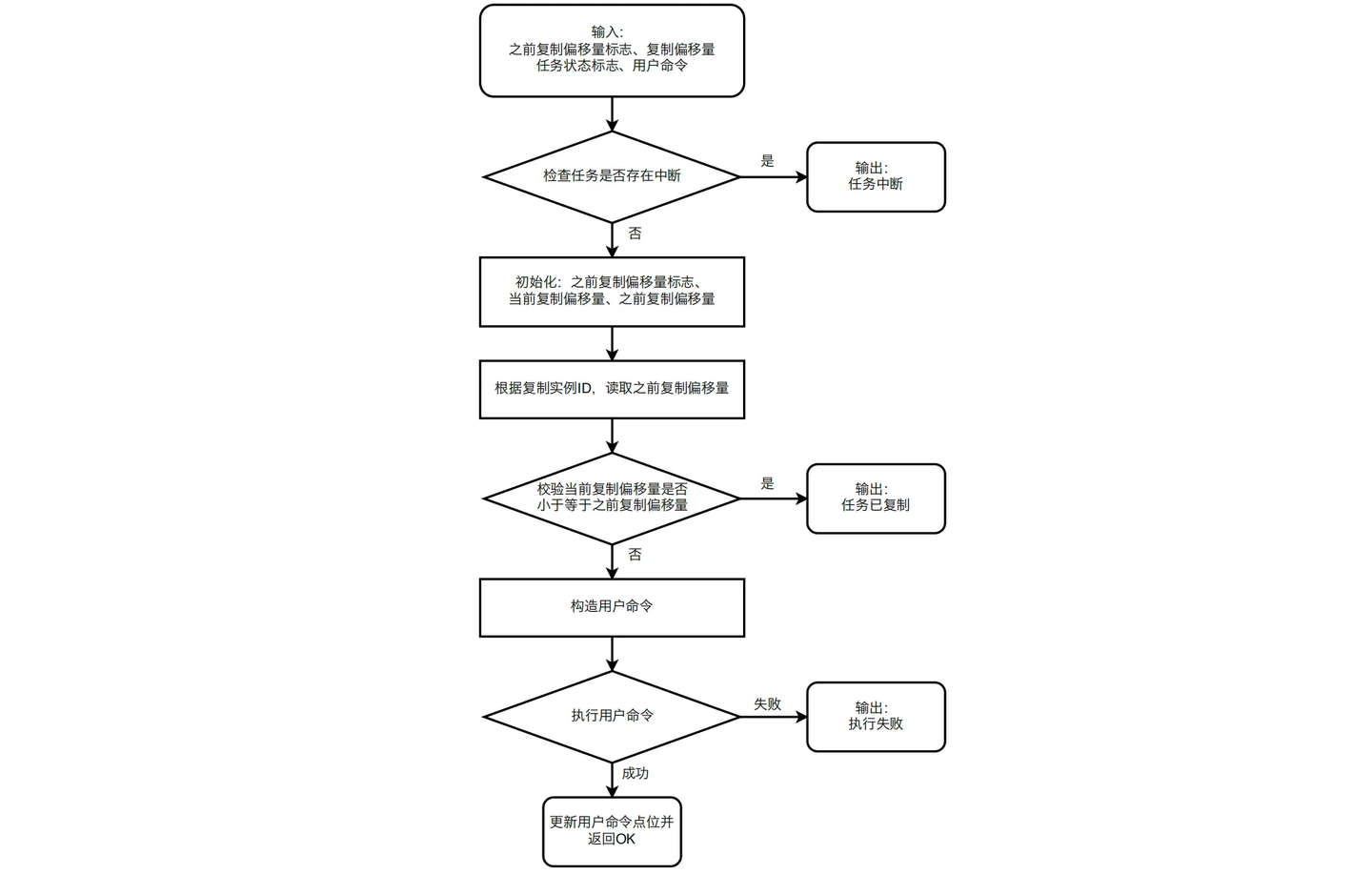
DTS在消费增量数据时,通过将写操作包装到Lua脚本中来实现操作的原子性。脚本内增加记录实时offset和offset比较功能。同时会有任务状态的一系列判断操作。
同步的流程为:
- 在目的端 Redis 上Load一个DTS专用的Lua脚本,脚本内封装了任务状态判断、位点 记录、位点比较、命令执行等一系列操作。
- 开始使用 evalsha pipeline 发送请求即可。(当前demo版本对待同步的写操作未做幂等性区分,所有操作均走lua脚本执行,因此会有写放大。后续版本会仅对非幂等操作走lua脚本执行。)
●方案技术建议(可选):增强断点续传能力
同步前调大源节点的repl-backlog-size 配置,以增强断点续传能力。
2.2.2 基于Task Group大规模迁移RDB协同方案
●背景问题:大规模RDB重传全局流控问题
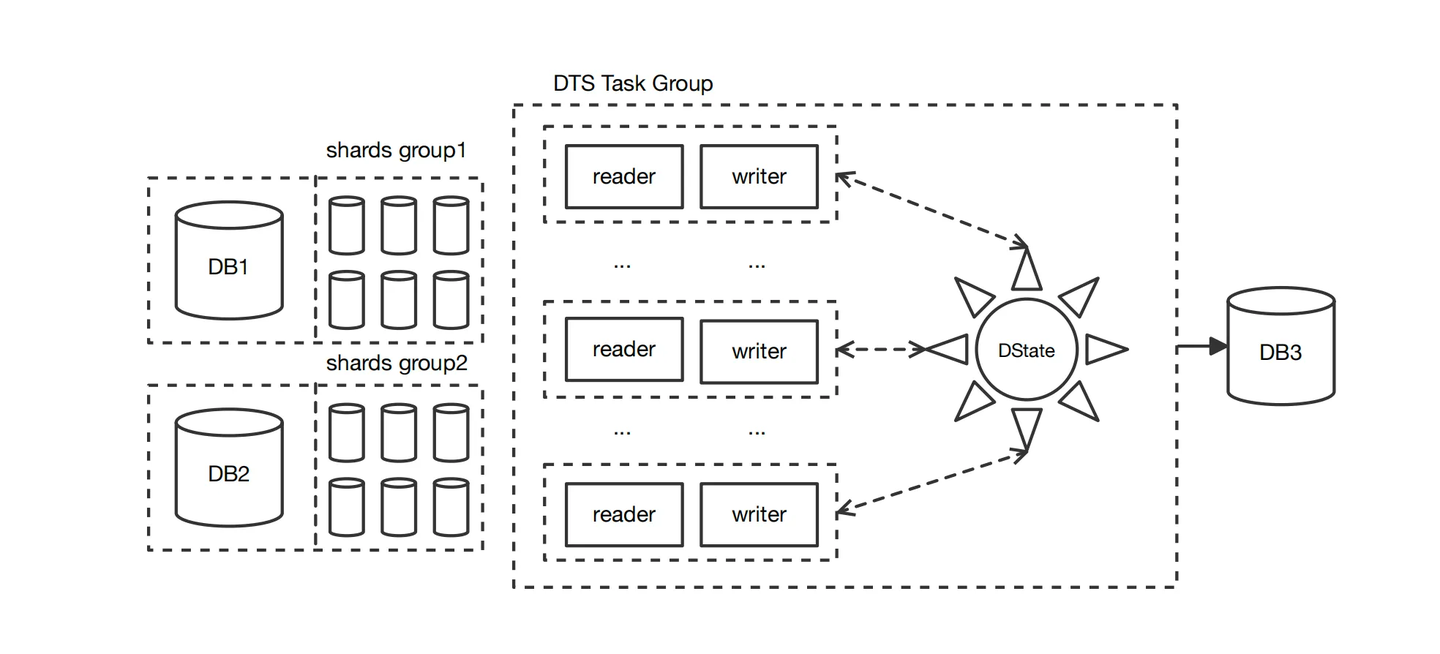
当用户业务非常庞大时,所需要的Redis集群将会比较庞大,如果要迁移这种大规模集群,一个值得注意的问题是:当对源库执行PSYNC后,源Redis会bgsave,需要fork出一个子进程去生成RDB快照(如下图所示),可能会导致master达到毫秒或秒级的卡顿抖动,以及大量内存占用,可能会对源库的业务造成影响。所以在DTS迁移时,就要控制对源库同时PSYNC的数量。

为了解决上述问题,利用DTS Task Group协调大规模RDB重传,方案的主要技术点如下:
●整体方案
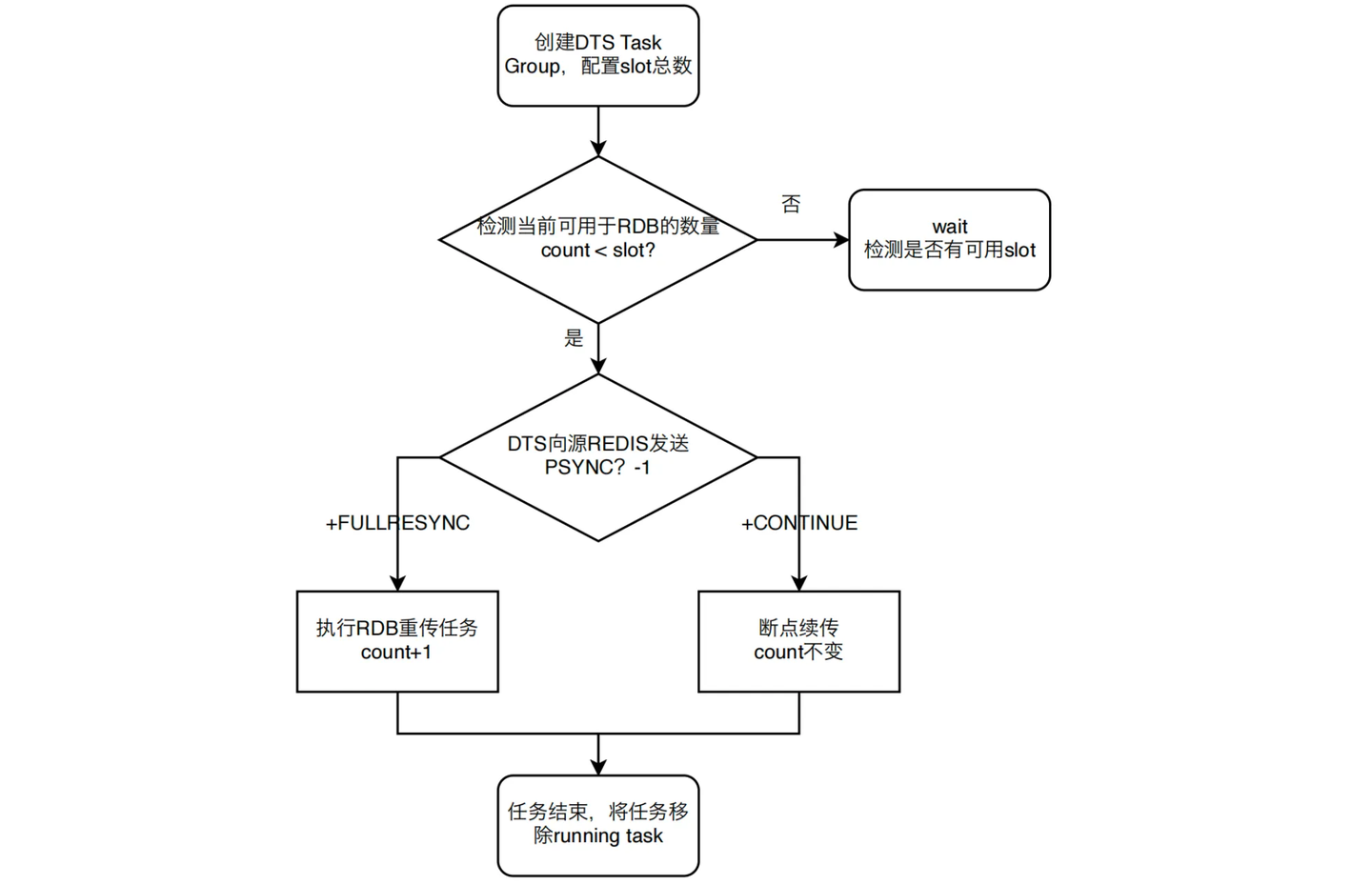
基于Task Group大规模迁移RDB协同方案整体流程如下图所示。首先,判断是否存在可
用slot,若存在则DTS 向源Redis发送PSYNC ?-1命令,若Redis返回+FULLRESYNC,加入
running task,count+1,如果回应是+CONTINUE,count不变。rbb完成,进入增量阶段,
将任务移除running task。
判断流程:
2.3、技术方案验证
●用例1:ExactlyOnce一致性验证
验证场景:
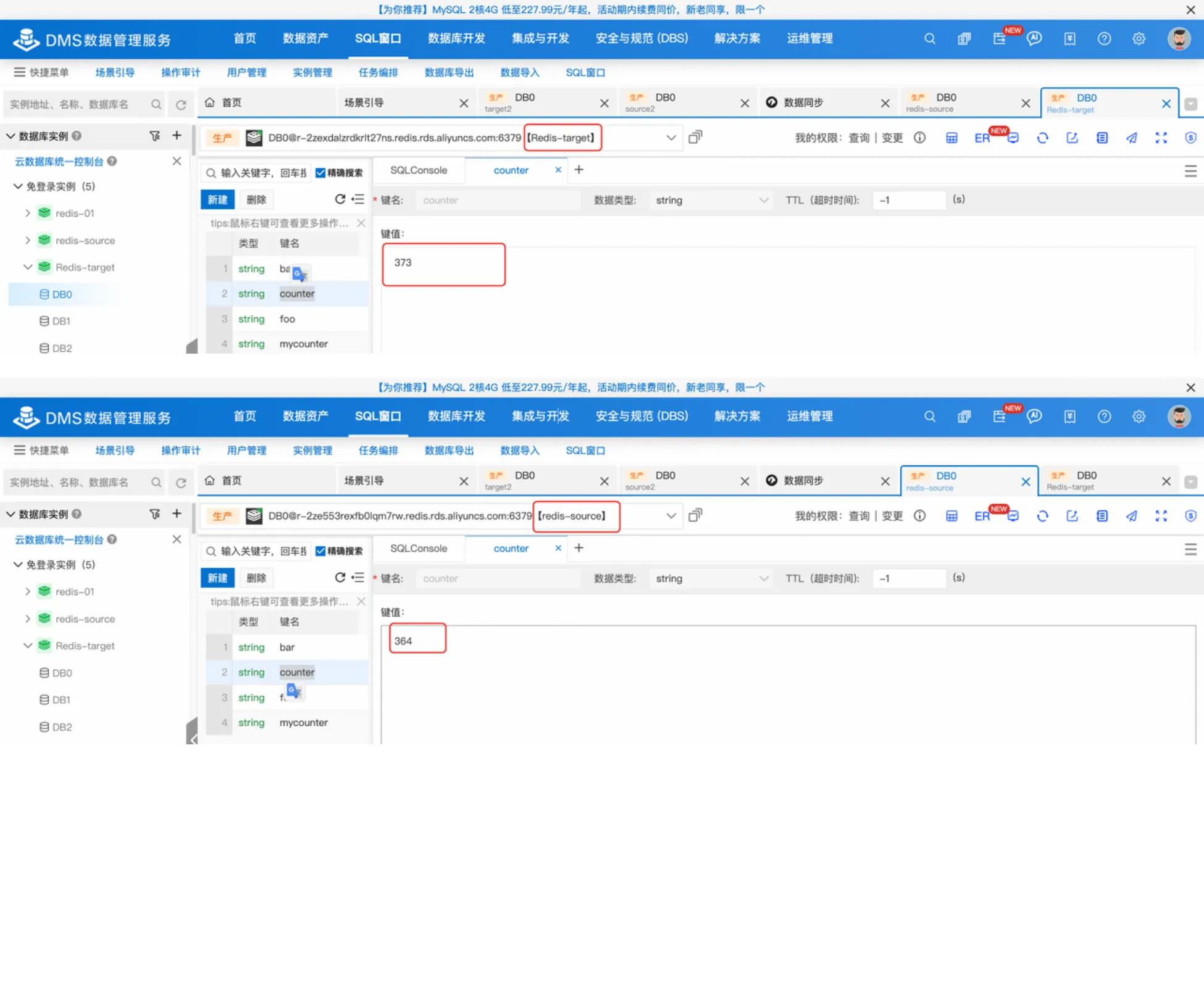
创建两个aliyun开源版Redis5.0 标准版,在DMS控制台开启两个实例的DTS数据同步任务;将其中一个Redis作为源端数据库Redis-source,将另外一个座位目的端数据库Redis-target,在本地设备上登录源端数据库。在本地设备中编写脚本,每一秒钟往源端数据库中进行一次incr操作,运行脚本。主要验证以下两个场景。
- DTS数据同步:暂停数据同步任务60s,重启数据同步任务,停止运行脚本,检查源端和 目的端数据库的数据一致性。
2. Redis Exacutly Once:修改数据同步配置,暂停数据同步任务60s,重启数据同步任 务,停止运行脚本,检查源端和目的端数据库的数据一致性。
开启ExactlyOnce前结果:
可以看出,断点续传后,出现了点位回退,重复执行了incr操作,导致目的端value为373,源端value为364,目标端和源端数据不一致。
**** | key | value |
|---|---|---|
目标端 | counter | 373 |
源端 | counter | 364 |
开启ExactlyOnce后结果:
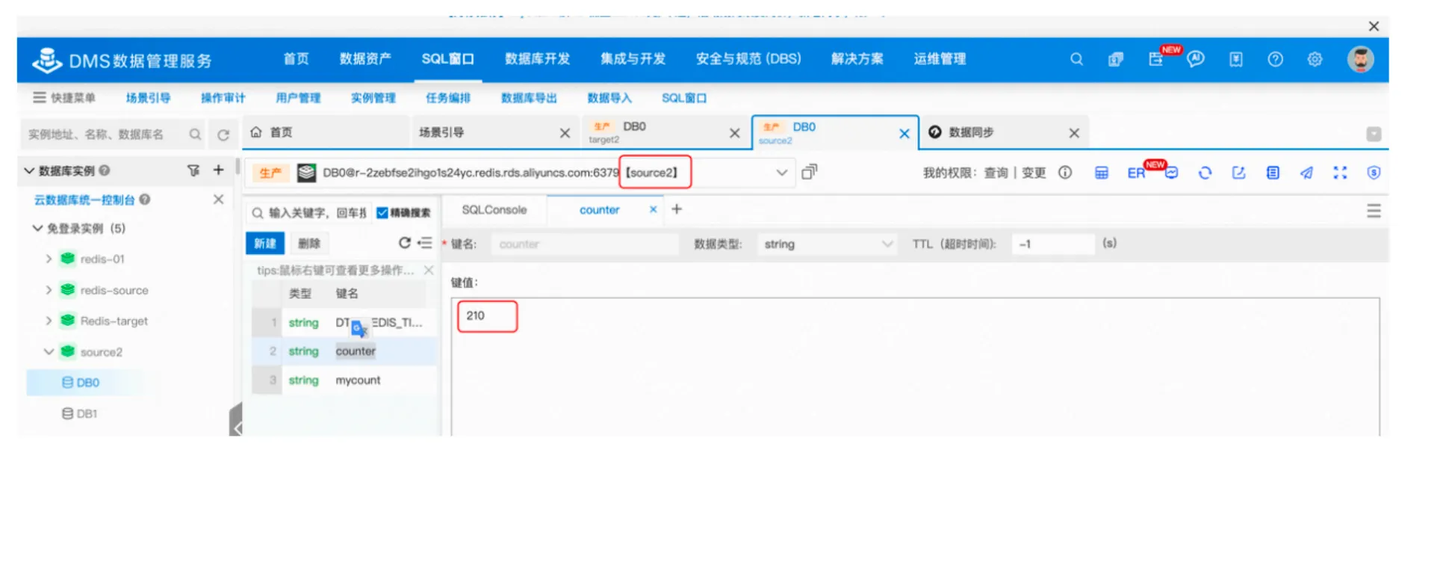
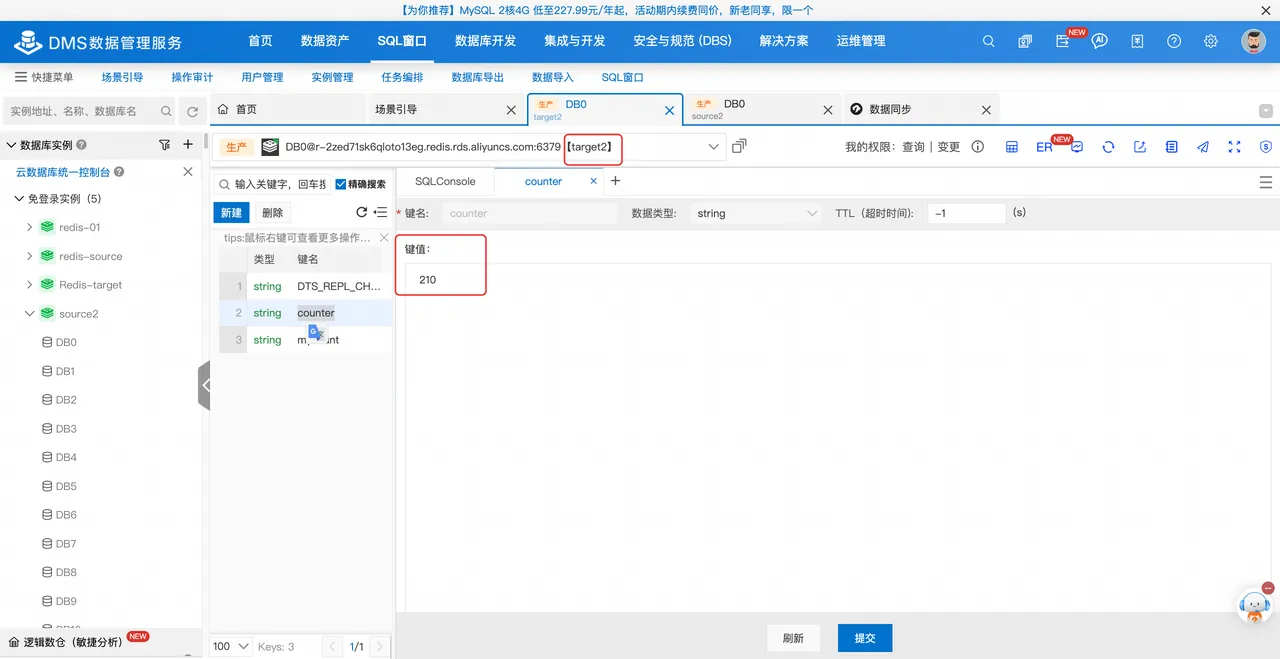
修改DTS同步任务的配置,开启Redis Exactly Once功能,得到修改配置后的结果如下,断点续传后,目的端和源端的counter值均为210,验证了Redis Exactly Once技术方案有效地保证了断点续传目标端和源端的数据一致性。
**** | key | value |
|---|---|---|
目标端 | counter | 210 |
源端 | counter | 210 |
● 用例2:RDB重传全局流控
简要说明:以下是2个实例使用DTS同步,将这2个实例关联为同一个任务组
momo_dts_group,并设置同时RDB的个数为1
参数名 | 值 |
|---|---|
组名 (global.task.group.id) | momo_dts_group |
同时RDB的个数(any.source.redis.max.rdb.count) | 1 |
以下是具体测试情况:
源库Redis实例 | r-bp1ncuq4vybixfj7jr | r-bp1xdq22pk1kqkve |
|---|---|---|
DTS任务 | DTS任务2 | DTS任务1 |
DTS启动时间(几乎同时启动) | 2025-01-19 23:37:47 | 2025-01-19 23:37:49 |
RDB开始时间(精确的DTS LOG) | 2025-01-19 23:38:06 | 2025-01-19 23:39:48 |
结束时间(精确的DTS LOG) | 2025-01-19 23:39:47 | 2025-01-19 23:41:30 |
可以看到第一个任务2首先2025-01-19 23:38:06开始RDB同步,在期间任务1等待,任务2RDB于2025-01-19 23:39:47完成后,任务1迅速于2025-01-19 23:39:48开始RDB,于2025-01-19 23:41:30结束。另外从Redis数据库监控进一步验证主从复制的流量起始时间与DTS任务相吻合,符合预期,至此DTS实现了防止源库集群RDB风暴的能力,提升了任务的可控性。
●用例3:RPS性能压力测试
验证场景:
创建规格为4xlarge(参考性能上限68000RPS)的数据同步任务,利用resp_benchmark压测工具进行性能测试,往源端进行SET操作,不断提高源端写QPS,主要验证以下场景:
- 目标端相对于源端的写放大效果
- DTS 4xlarge在低延迟情况下,最高RPS。
- 开启ExactlyOnce是否存在存储空间放大。
验证结果:
- 当前Demo版本目标端相对于源端写QPS的写放大为100%左右,后续对写入做幂等/非幂 等拆分后,可大幅收缩写放大比例(视业务中非幂等操作数量决定)。
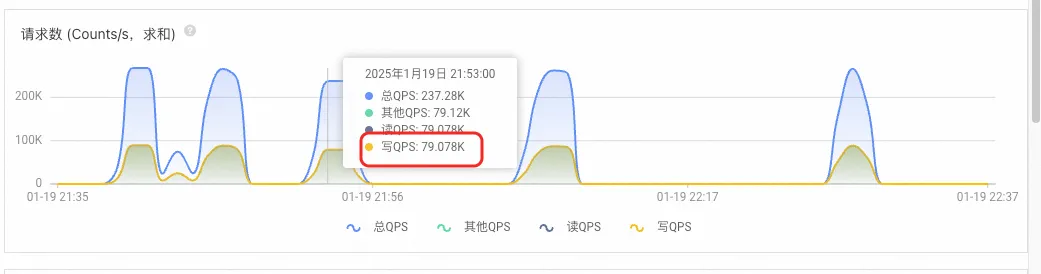
- DTS 4xlarge的极限RPS大概在44000左右(如下图所示),这是因为当前版本demo存在写命令和打标命令,因此写放大为100%,若对非幂等命令进行拆分,假设非幂等命令占比总操作数量的10%,在实际业务使用过程中DTS 4xlarge的极限RPS可以提升到83600。以下是DTS RPS的性能压测的具体测试结果,当RPS在40000左右,平均任务延迟为219.5ms左右,最大延迟为387.6ms;当RPS为44380左右,平均任务延迟为299.3ms,最大任务延迟为552.2ms;当RPS超过45000,延迟会显著增加。
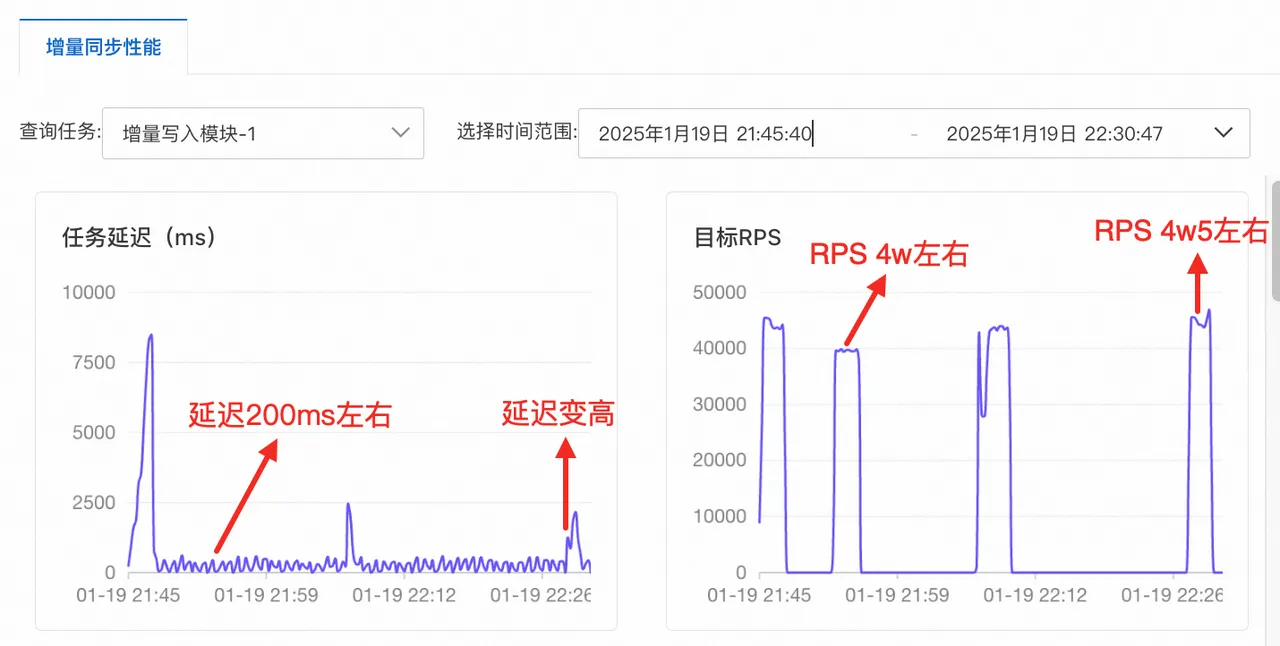
特别说明(数据同步任务延迟与DTS心跳的关系):任务延迟以DTS控制台性能监控数据为准,而监控中的任务延迟是基于DTS心跳进行判断,DTS心跳周期为300ms,所有期间发生的增量数据都通过夹逼的方式近似计算,并以当前时间减去心跳时间作为延迟,故即使在真实无延迟状态下,延迟仍然会在0~300ms波动右的任务延迟是正常数据同步情况。实际同步延迟为50ms,50ms为攒批时间,该值可调。
源数据库写QPS
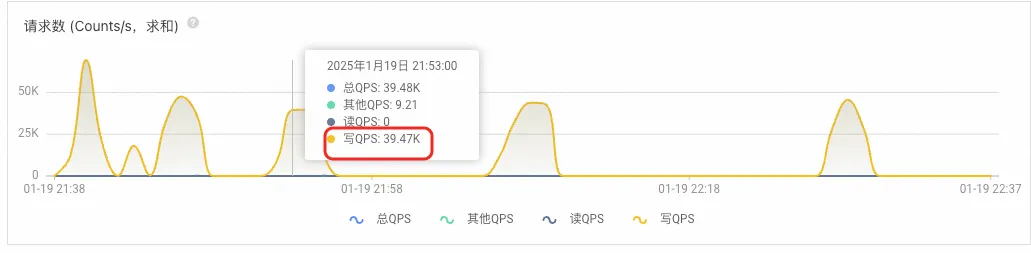
目标数据库写QPS
3. 针对开启ExactlyOnce后存储空间是否有放大的问题,ExactlyOnce功能在目标实例上会保存一个lua脚本和一个用于记录offset的key,单节点仅有一个key,集群版最多有16384个slot,每一个slot一个key,因此即便是集群版,其存储放大不会超过500KB,主备版不会超过100KB。如下是压测前后的存储空间对比。
压测前存储大小:

压测后存储大小:
3、容灾切换方案
如果基于DTS构建容灾架构,在故障发生时的切换方案大致如下:
阶段一:切流前
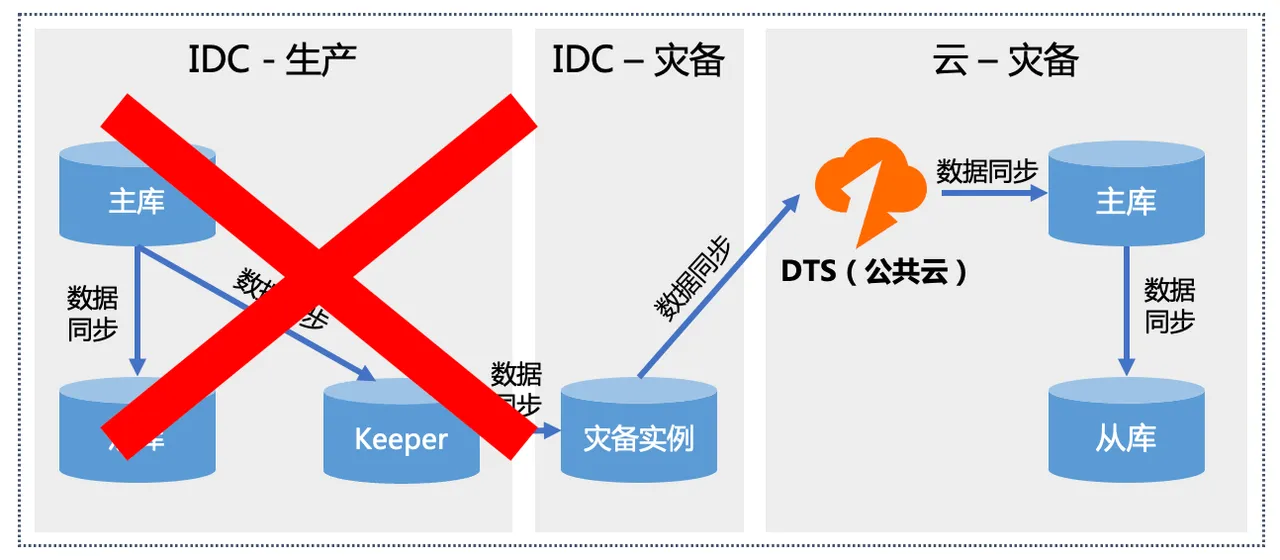
1、生产IDC故障,决策要做机房切换
2、云上创建资源和空实例,通过API新建 DTS任务进行数据迁移。(如云上资源是 常态存在的可省略此步)
3、生产IDC实施禁写,防止脑裂。 (Redis6.0以下版本无禁写能力,需要应 用层面实现禁写)
4、检查DTS任务同步状态,确保要切换 的实例没有处于【全量】阶段的。(全量 阶段会flushall目标库,此时切流目标端数 据严重缺失)
阶段二:切流中
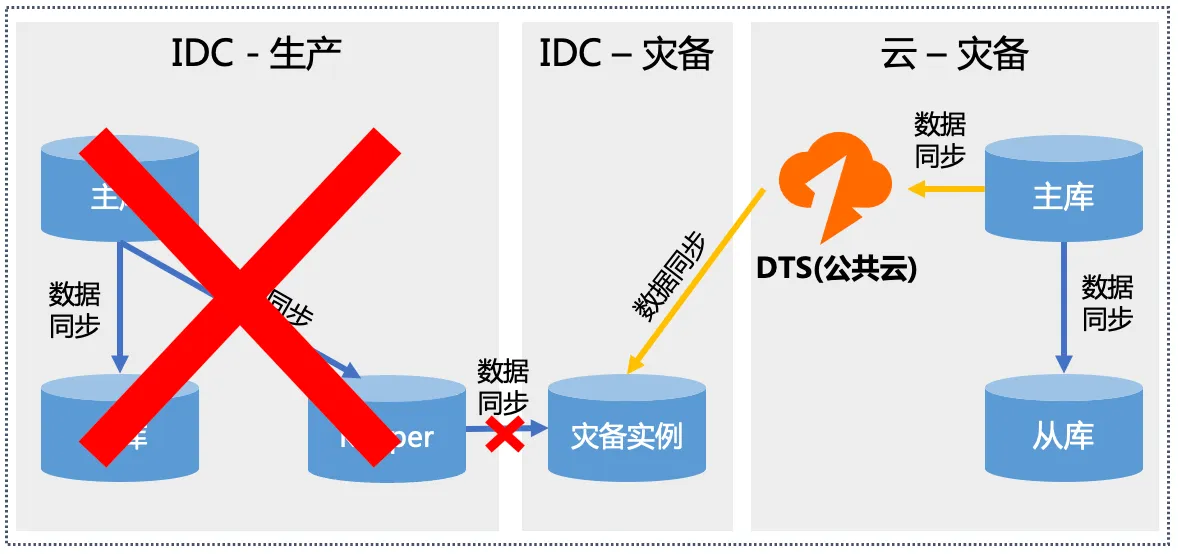
1、停止灾备实例从Keeper拉取增量。将 灾备实例提升为可写状态。业务需保持进 行状态。
2、停止DTS正向同步任务,避免极端情 况下DTS任务执行RDB拉取而flush目标实例
3、通过API建立DTS反向同步任务(云 - IDC灾备,需要开启RDB流控)
4、将业务流量切换到云上
阶段三:切流后
1、生产IDC恢复后,新建DTS任务恢复 IDC内数据库(云->IDC生产,需要开启 RDB流控)
2、云上业务实施禁写,准备进行回切
3、检查DTS同步状态,确保没有处于 【全量】阶段的
4、停止DTS同步任务(云->IDC-生产)
5、将业务流量回切到生产IDC 6、灾备实例重新建立到Keeper的同步
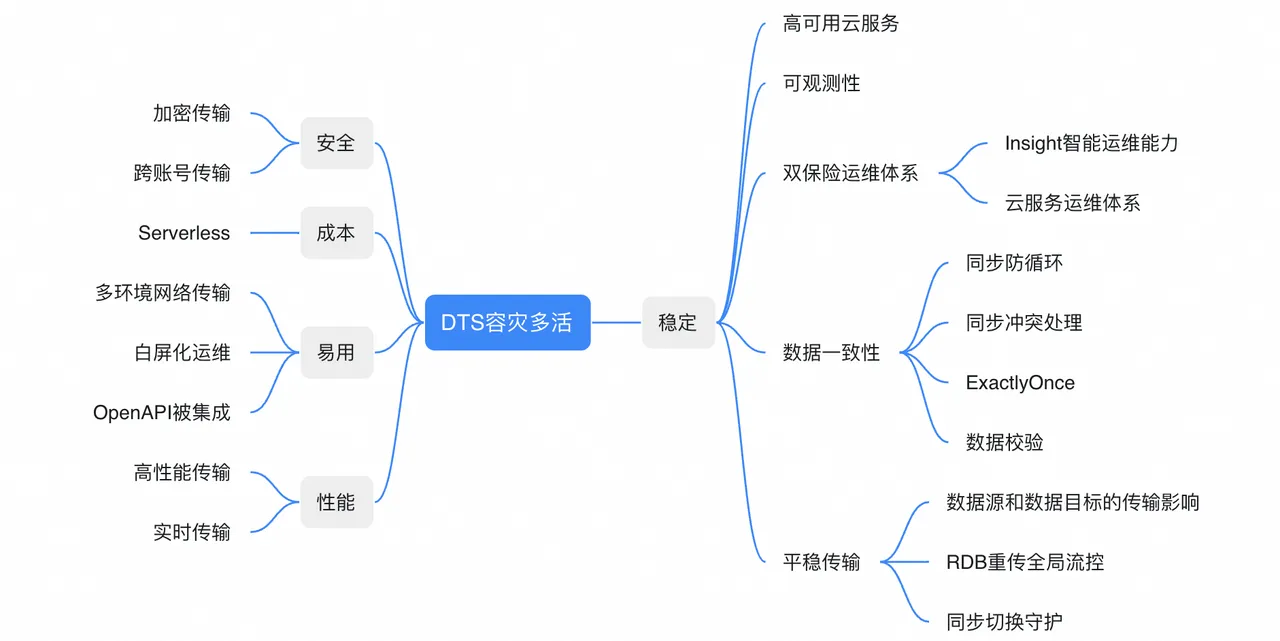
4、跨云容灾需要构建的生态能力
DTS围绕跨云容灾构建的能力概览如下,这些也是跨云容灾场景有必要建设的能力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
