[ibd2sql] mysql数据恢复案例001-- import tablespace失败之后怎么恢复数据?
原创[ibd2sql] mysql数据恢复案例001-- import tablespace失败之后怎么恢复数据?
原创
导读
使用ibd2sql来恢复数据的案例在网上并不多, 直接/间接找到我的也只有2位数; 另外一些是可能没遇到问题 或者 遇到问题自己解决了, 也可能还有些是遇到问题就换其它方法了; 我之前也没咋写这方面的案例.... 导致使用者可能不太了解这个工具,或者不太敢使用, 或者没听说过.
所以我尽量把后续相关案例放出来, 供后续使用者参考.
涉及到的表名,表数据等信息均打码, 只有数据库版本和ibd2sql版本,以及数据量之类的信息和部分字段类型(为了方便截图,不然就一坨码了...). 尽可能的保护数据隐式的同时也能给后续使用者参考.
我们这里主要是针对没有备份,且无法使用mysql自动恢复的情况, 或者由于某些原因只剩下ibd数据文件了的情况. 总之就是万策尽
ibd2sql简介
ibd2sql是使用python3编写的一款解析mysql数据文件(ibd)的工具. ibd file to sql statement
目前支持mysql 5.6, 5.7, 8.0, 8.4, 9.x版本, 已经迭代了10+个版本了,修复了若干个BUG了. 目前最新版本是v1.9 (2025.03.21).
功能: 解析ibd文件, 提取数据(SQL),或者表结构(DDL),被标记为delete的数据也是能够提取的, 也配有xfs文件系统恢复工具来恢复drop的表. 对于5.6, 5.7也能自动解析对应的frm文件从而得到元数据信息/DDL. 目前是支持所有mysql数据类型,所有mysql支持的字符集. 所以功能还是比较强大的.
开源: 使用的GPL3.0 license,项目位于github上的: https://github.com/ddcw/ibd2sql
也会衍生一些小功能: 比如使用浏览器查看ibd文件, 也可以修改mysql.ibd文件里面的lower_case_table_names参数
处理流程
通常我们优先使用import tablespace的方式来导入数据, 这个方法的前提是得知道相关的DDL, 好在我们之前有讲过几种提取DDL的方法,最简单的就是直接使用ibd2sql来提取DDL,然后再导入数据库.
python3 main.py xxx.ibd --ddl
上图为部分表结构信息, 实际使用时, 我们可以直接
python3 main.py xxx.ibd --ddl | mysql -h127.0.0.1 -P3400 -p123456导入数据库, 也可以搭配--schema来修改表对应的schema信息.
import tablespace
然后我们拷贝ibd文件到对应目录之后,就可以使用如下语句导入数据库
-- alter table xxx discard tablespace;
-- cp -ra xxx.ibd /PATH/xxx.ibd
alter table xxx import tablespace;但遇到了如下报错
ERROR 1817 (HY000): Index corrupt: Externally stored column(45) has a reference length of 0 in the cluster index PRIMARY
这个报错信息看起来是主键有问题, 或者表结构和ibd文件不完全匹配.
我们并不甘心(苦呀西), 于是再次导入, 并得到了一个其它报错
(root@127.0.0.1) [XXX]> alter table XXXX import tablespace;
ERROR 1815 (HY000) at line 1: Internal error: Cannot reset LSNs in table `XXX`.`XXXX` : Data structure corruption这个报错看起来是无法设置表里面的LSN信息, 可能是数据文件损坏. 但我们校验了下数据文件,并没有发现坏块.
重试多次后,依然是上诉报错信息, 估计很多同学到此就只能放弃了. 但我们还在继续
ibd2sql
这时,就得祭出我们的杀手锏 -- ibd2sql !!!
于是我们使用ibd2sql解析数据并导入数据库
python3 main.py xxx.ibd --sql --ddl --schema db1 --multi-value | mysql -h127.0.0.1 -P3398 -p123456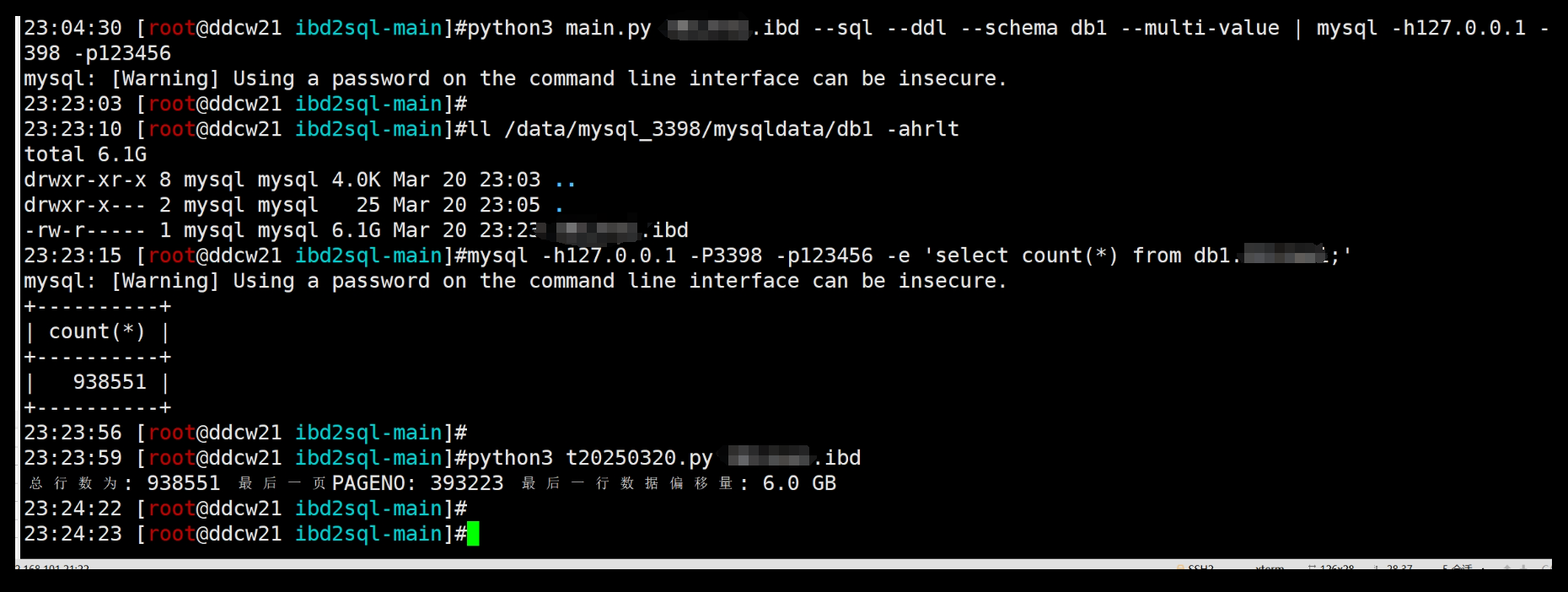
数据成功导入, 我们再验证了下数据量也是能够对得上的.
上图为昨晚测试的图. 这是其中一个遇到BUG的表(已修复). 6GB文件, 约100W行数据, 从解析到导入完成 耗时20分钟. 速度还算可以, 但还有很大的提升空间, 解析过程的时候看了下, 主要耗时不是在IO,而是在CPU, 也就是还可以使用并发来提高速度, 即reader-->worker这种结构, 那对于加密或者压缩的表是worker来做还是reader来做呢? 这些都是后续在考虑的了. 上述使用管道的方法,可能也会降低一些速度(比如mysql来不及写数据), 也可能会提升一些速度(比如解析的数据不需要落盘就直接导入数据库), 具体是怎样,我就不验证了, 有兴趣的同学自行验证.
至此,我们就顺利的使用ibd2sql恢复了该表的数据!
总结
当然我们使用ibd2sql解析数据文件时,也不一定能一帆风顺;
可能会遇到各种BUG, 比如同一批表, 有的能解析,有的解析会报错, 或者解析数据为空.
可能是mysql的, 也可能是ibd2sql的, 也可能是使用者的, 还可能就是单纯的时机不对(玄学!).
这时候该怎么办呢? 当然是找作者啊!
你可以在如下网站联系我:
github: https://github.com/ddcw/ibd2sql
腾讯云社区: https://cloud.tencent.com/developer/user/1130242
墨天轮社区: https://www.modb.pro/u/17942
B站: https://space.bilibili.com/448260423
微信公众号: 大大刺猬
为了提高沟通效率, 联系的时候, 建议附带如下信息:
- 数据库版本
- ibd2sql版本
- DDL语句(脱敏的即可)
- 报错信息
- 数据文件大小
- 能有稳定复现的方法最好 (能提供测试的数据文件也行, 但注意数据安全!!! 不要直接把数据文件或地址放到评论区)
联系之前, 请先自己尝试解决相关问题. 最后一点: 备份很重要!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
