Step-Audio:开箱即用的语音大模型
原创
阶跃最近还开箱了一个语音大模型 Step-Audio,实现了从语音理解到生成的 端到端整合,在多个关键维度展现出卓越优势:
- 情绪感知与理解 —— 识别语气、语调中的情绪信息,结合语境提供精准回应。
- 多语种与方言支持 —— 覆盖多语言、多方言,中英文交流可实现同声传译。
- 自然流畅的通话体验 —— 提供更低时延、个性化风格表达,通话更自然。
还记得 2024 年 5 月 14 日凌晨的那场直播吗?GPT-4o 横空出世,为 ChatGPT 带来了全新的实时语音通话能力,被业内誉为“震撼全球的发布”。然而,当这项功能全面上线后,实际体验却并未达到发布会演示时的惊艳程度。
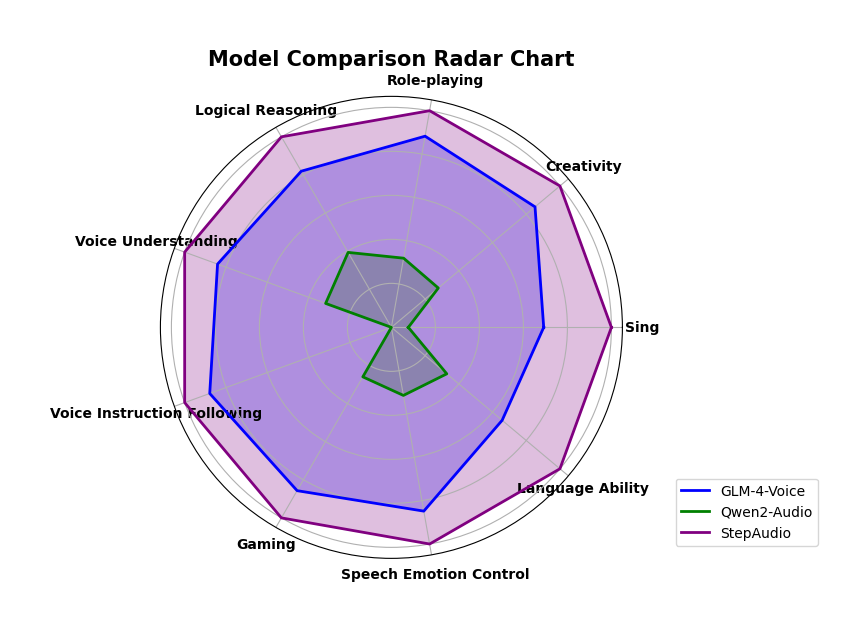
如今,轮到阶跃星辰发布的语音大模型震撼世界了。在正式上线前,内部团队围绕推理逻辑、创作能力、指令控制、语言能力、角色扮演、文字游戏、情感价值等多个维度进行了全面的评测。从评测效果上看,模型的能力雷达图超越了之前开源的GLM-4-Voice和Qwen2-Audio模型,取得了最好的成绩
1. 实际App体验效果测试
目前这个模型已经上线“跃问”APP上,普通用户也能够通过APP进行在线的语音对话。我们打开APP之后,可以看到一个打电话的按钮,点击之后就可以进行实时语音对话了
在进行实时语音对话的时候,可以进行随时打断,只要点击一下屏幕就可以了。就像和正常人说话一样。
在进行语音对话的时候,它能够模仿不同的人类语气,比如面对 500 万元彩票的,它能够表现出开心的语气出来
共情能力拿捏得恰到好处。当我们带着沮丧的情绪表达坏消息时,它会以平静而温暖的语气安慰我们。它不仅具备类人的情感响应能力,还能展现丰富的副语言特征,如语气词、迟疑和停顿,使交流更加自然流畅。
而在方言的识别上,能比较准备,这里我用了粤语和它进行对话,它虽然优点“笨拙”,但是已经能够大概理解我的意思
2.背后的是哪些技术
在语音AI相关领域的大模型训练的过程中,要训练初一个类似于真人级别的实时语音大模型,其技术难点有两个。
一个是需要尽量让大模型趋向于人类说话的自然度和流畅度。
从论文中,Step-Audio采用了一个端到端的多模态训练架构,其参数高达130B的多模态大模型。
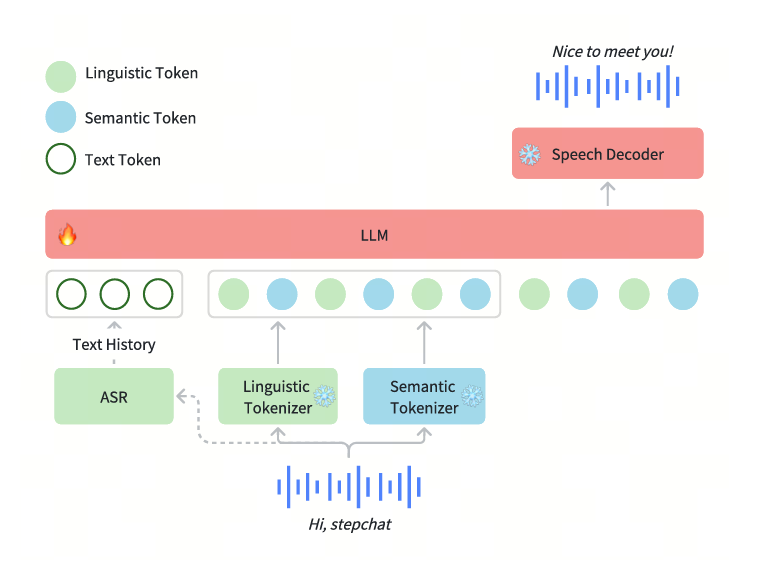
同时为了提升语音理解能力和情感上的表达,采用了Linguistic(语言)编码器和Semantic(语义)编码器共同学习,使语音表达更加流畅。
传统的语音 tokenization 方式通常分为两类:一个是基于理解的 tokenizer,主要侧重于提取语言学特征,例如音素、语法结构等,但忽略了音频的细节信息。另一个是基于生成的 tokenizer,主要关注音频合成过程中需要的语音特征,如音色、韵律和情感,但不能很好地表达语言信息。
这种方式导致理解和生成任务在信息提取上存在分裂,使得模型在执行语音任务时不能兼顾两者。
为了弥补传统 Tokenizer 的不足,Step-Audio 采用了一种 双码本(dual-codebook)语音 tokenizer 方案,包含了语言学(Linguistic)Tokenization和语义(Semantic)Tokenization。
其中语言学(Linguistic)Tokenization:
- 主要提取 音素级别和语言学特征,捕捉语音的结构性信息,确保语音的可理解性。
- 采用 Paraformer 编码器对输入语音进行特征提取,并以 16.7Hz 采样率进行量化。
- 码本大小为 1024,用于编码音素和结构信息
语义(Semantic)Tokenization:
- 主要关注 语音的语义内容和粗粒度的声学特征,保证音频合成时的质量和自然度。
- 采用 CosyVoice 语音编码器提取声学特征,以 25Hz 采样率进行量化。
- 码本大小为 4096,捕捉更丰富的音频细节,如音调、音色、韵律等。
另一个是需要大规模的采样语音数据,喂给大模型进行训练。
数据质量的高低和好坏,往往是一个模型成功的重要因素。如果像传统的方式那样,直接利用真人语音数据进行训练,难度较大。一方面难以获取大规模的数据集,另一方面也很难筛选出高质量的数据出来。
因此阶跃团队采用生成式语音数据引擎,无需依赖大量人工标注数据即可生成高质量语音。
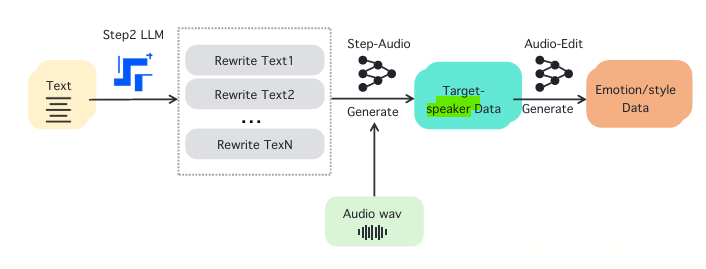
其本质就是采用 生成式数据增强 方法,通过文本重写 、说话人数据合成、音频编辑等步骤构建高质量 TTS 训练数据,克服传统 TTS 任务中高质量语音数据稀缺的问题:
- 文本重写 (Text Rewriting):由 Step2 LLM 生成多个语义丰富的改写文本,以提升多样性。
- 目标说话人数据合成 (Target Speaker Data Generation):结合重写文本和已有的音频数据 (wav),生成目标说话人的音频数据。
- 音频编辑 (Audio Editing):进一步调整语音数据,增强 情感 (喜怒哀乐)、风格 (正式、活泼、低沉) 等特征,确保语音合成的自然度和表达能力。
在整体的模型训练过程中,包含了四个过程。
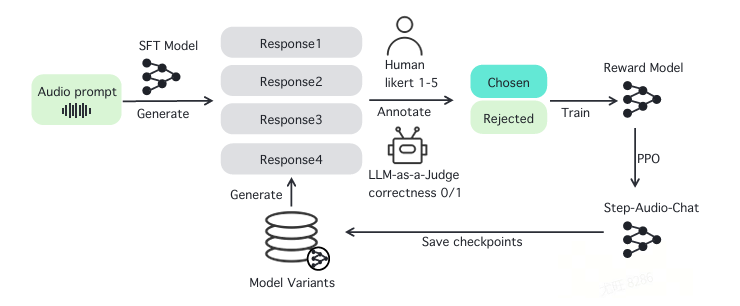
第一阶段,进行SFT模型后,收集多版本模型的多个响应。在同一轮训练中,使用不同版本的模型(例如 SFT 版本、微调版本等)生成多个候选响应。这些响应可能包含不同风格、表达方式或回答准确性不同的内容。
第二阶段,人工评分与 LLM 评分。由人工标注员对生成的多个候选响应进行评分,评估标准包括:指令遵循度、自然流畅度、安全性。另外,采用 LLM 评审(LLM-as-a-Judge) 方法,让大语言模型对候选响应进行评分,自动判断回答的正确性和质量。
第三阶段,构建高质量数据对。通过人工评分和 LLM 评分的结合,筛选出高质量的 "Chosen"(优选)和 "Rejected"(淘汰) 响应对。这些数据对用于训练 奖励模型(Reward Model),使其学习区分优秀和劣质回答的特征。
第四阶段,使用 PPO算法优化最终模型。以奖励模型为基础,采用 PPO 强化学习算法 训练最终的 Step-Audio-Chat 模型。通过 KL 惩罚机制(KL Penalty)防止生成结果偏离人类偏好。
当然,这次阶跃团队还创新的加入了支持工具调用的能力。能够通过语音进行控制,查询对应的天气、播放音乐等功能,进一步提升其在Agents和复杂任务中的表现。
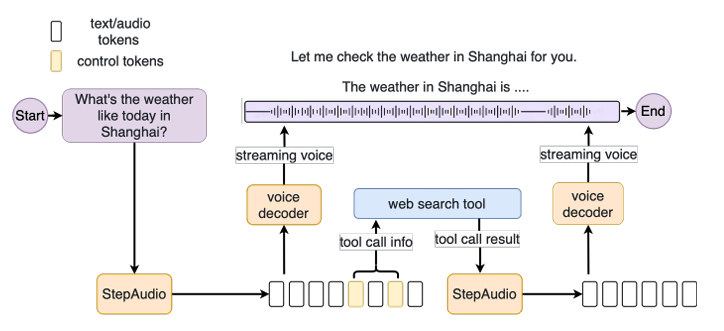
具体的,Step-Audio 采用了一种 解耦(Decoupled) 的工具调用架构:
- 文本处理线程:责处理工具调用请求,并执行外部服务查询(如知识检索、天气查询等)。
- 音频生成线程:负责同步语音流的生成,确保用户不会因为工具调用而等待语音输出。
整体的工具调用过程是像下面这样进行的:
第一步用户通过语音输入问题。例如:“请查询当前的天气,并用粤语告诉我。”
第二步语音转文本。Step-Audio 的 自动语音识别(ASR)模块 将语音转换为文本。
第三步触发工具调用。语言模型(LLM)分析用户请求,识别出需要调用外部工具(如天气 API)。工具调用管理器(ToolCall Manager) 负责处理外部 API 调用,同时保持与音频生成的同步。
第四步并行执行。工具调用线程 发送请求给外部 API,获取天气数据。音频生成线程 继续生成对话中的固定部分
第五步结果返回和语音输出。工具调用线程完成查询,返回数据(如“当前温度 25°C,晴天”)。Step-Audio 生成最终语音回复,并按照用户指令(如粤语)进行输出“现在的天气是 25°C,晴天。”
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
