Step系列大模型—两款多模态大模型详细介绍
原创
1. 背景概述
DeepSeek-R1 的发布引发了全网热议,持续霸榜热搜,各大社交媒体、技术论坛以及新闻平台纷纷讨论其突破性的技术创新和超强的推理能力。其卓越的逻辑推理和任务泛化能力,使其迅速成为开源社区的焦点,并在业内引起广泛关注。
然而,DeepSeek-R1 主要聚焦于思维链和推理任务,在多模态能力方面仍存在一定局限。目前,它无法进行多模态任务的识别,因为其本质上仍是一个文本大模型(LLM),核心优势集中在文本生成、逻辑推理和长上下文建模,而非跨模态融合。
如果用户希望体验 DeepSeek 级别的模型,同时拥有多模态能力,可以尝试阶跃最新发布的 Step-Video 和 Step-Audio。Step-Video 在视频生成和视频理解领域取得了突破,而 Step-Audio 则在语音识别与合成任务上展现了领先的技术实力。

2.Step-Video-T2V:全球最强开源视频生成
Step-Video-T2V 是当前开源领域最强的视频生成模型之一,支持文本到视频(T2V)转换,并已上线官网免费使用。其主要特点包括:
- 领先的文本到视频生成能力
- 在运动流畅度、物理合理性、指令遵循性方面表现优异。
- 可生成 8-10 秒的长视频,远超现有开源模型。

- 采用 3D 动画风格
- 具备高度可控的视频生成能力,如特定场景和指令的精准执行。
- 示例视频展现了“Year of Snake, 2025”字样和动态卡通蛇,展现了细腻的光影效果和节日氛围。

- 支持中英文输入,生成效果逼真
- 采用双语文本编码器,原生支持中英文输入。
- 能够准确模拟物理规律,如狗在水中游泳时的水花动态。
2.1 技术解析
论文中将视频生成模型划分为两类:
- Level-1(翻译级):如 Sora、Veo,基于扩散模型,适用于 T2V、风格转换等任务,但难以建模复杂动作和物理规律。
- Level-2(可预测级):具备因果推理能力,可模拟物理世界,但目前尚无成熟模型。
Step-Video-T2V 仍处于 Level-1,但在可控性、物理一致性和长时序建模能力上有所突破。

2.2 模型架构
Step-Video-T2V 采用 高压缩 Video-VAE、双语文本编码器、3D 全注意力扩散 Transformer 和基于人类反馈的视频优化(Video-DPO) 组合策略,实现端到端的视频生成。
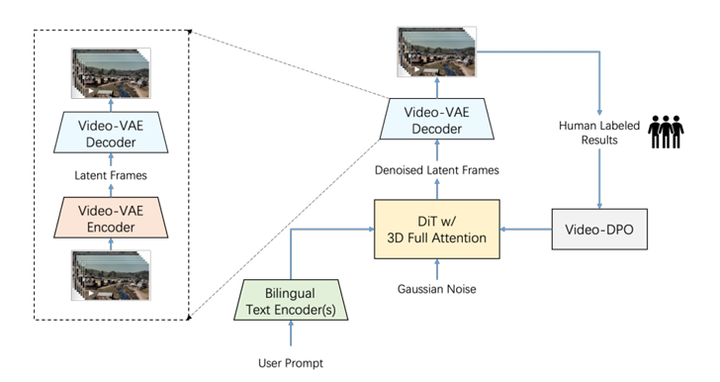
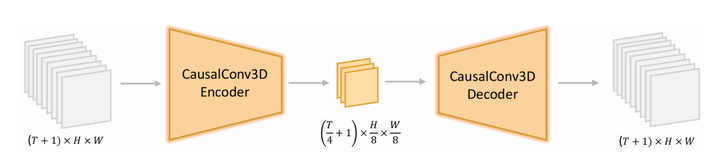
- Video-VAE:高效压缩视频数据,减少计算量。在以前的一些视频生成模型里, 像HunyuanVideo和CogVideoX这些,通常采用的是变分自动编码器(VAE)进行空间-时间降采样。这种模型通常将降采样因子设置成为 4×8×8 或 8×8×8。同时为了进一步减少 token 数量,通常使用 Patch 分组技术,将 2×2×1 的潜在 Patch 组合成单独的 token。
- 双语文本编码器:同时支持中文和英文输入,提升跨语言理解能力。
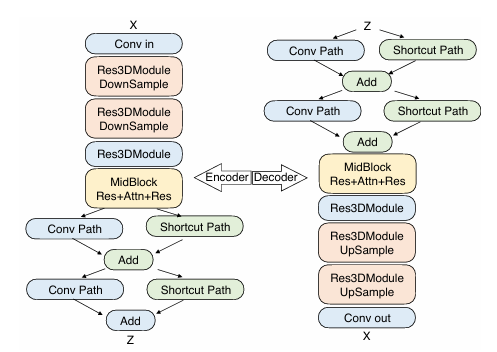
- 3D 全注意力 Diffusion Transformer:基于 Flow Matching 训练,将噪声转化为高质量视频帧。在编码器部分,包含两个Res3DModule和相应的降采样层。随后,MidBlock 结合卷积层与注意力机制,以进一步优化压缩表示。为了支持联合图像与视频建模,同时采用时间因果 3D 卷积
- Video-DPO:利用人类反馈优化视频,减少伪影,提高画面平滑度和真实性。DPO(直接偏好优化)是一种无需强化学习的偏好优化方法,最早用于大语言模型(LLM)的对齐训练,例如 ChatGPT 的 RLHF 过程。它通过直接优化偏好排序,避免了强化学习中的奖励建模。
DPO 训练包括三个核心环节:数据收集、偏好优化和训练优化。在数据收集阶段,使用 Step-Video-T2V 生成多种文本提示对应的视频,并由人工标注,筛选出清晰、流畅、无伪影且符合文本描述的优选样本,同时标记质量较低的视频作为反例(non-preferred sample)。

2.3 结论
Step-Video-T2V 在开源视频生成领域实现了重大进步,特别是在可控性、物理一致性和长时序建模方面。但目前仍处于 Level-1 阶段,未来的发展方向可能包括增强因果推理能力,迈向 Level-2 模型。
3.Step-Audio 语音大模型解析
3.1 介绍与核心特点
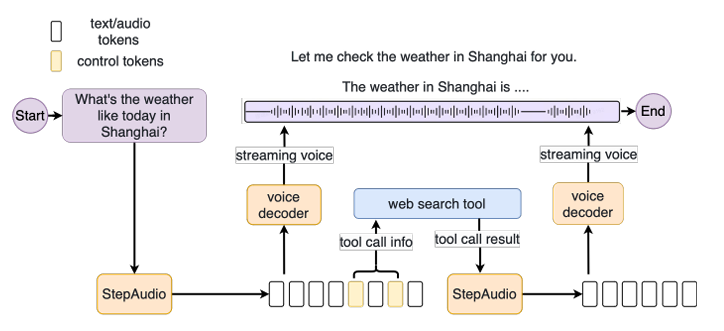
- 端到端整合:实现从语音理解到生成的一体化方案
- 情绪感知与理解:识别语气、语调中的情绪信息,结合语境提供精准回应
- 多语种与方言支持:支持多语言、多方言交流,中英文可实现同声传译
- 自然流畅的通话体验:低时延、个性化表达,使语音交互更自然
3.2 技术架构
- 核心难点:
- 提升语音的自然度和流畅度
- 依赖高质量大规模语音数据进行训练
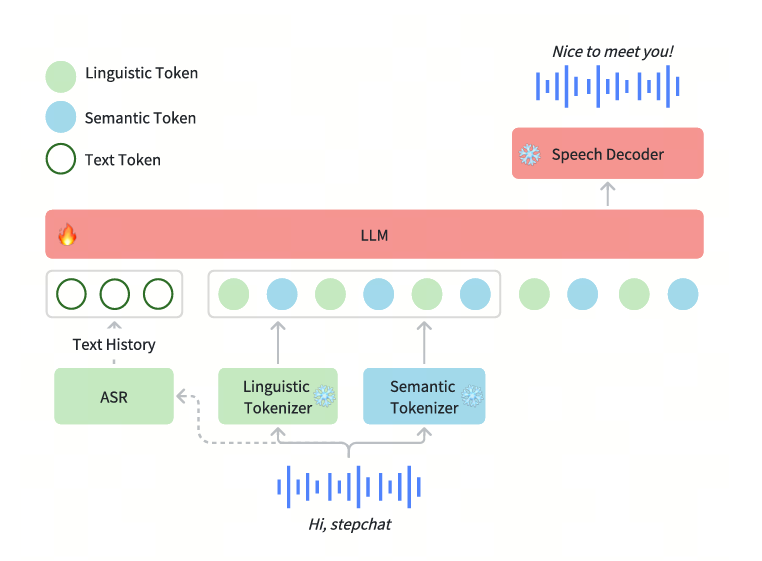
- 多模态训练架构:
- 采用 端到端多模态模型,参数规模达 130B
- 结合 Linguistic(语言)编码器 和 Semantic(语义)编码器,提升语音理解和表达能力
数据质量的高低和好坏,往往是一个模型成功的重要因素。如果像传统的方式那样,直接利用真人语音数据进行训练,难度较大。一方面难以获取大规模的数据集,另一方面也很难筛选出高质量的数据出来。
因此阶跃团队采用生成式语音数据引擎,无需依赖大量人工标注数据即可生成高质量语音。
- 双码本(dual-codebook)语音 tokenizer:
- 语言学(Linguistic)Tokenization
- 提取音素级别和语言学特征,确保可理解性
- 采用 Paraformer 编码器,16.7Hz 采样率,码本大小 1024
- 语义(Semantic)Tokenization
- 关注语义内容和声学特征,提升合成质量
- 采用 CosyVoice 语音编码器,25Hz 采样率,码本大小 4096
- 语言学(Linguistic)Tokenization
3.3 语音数据增强与训练
- 大规模数据挑战:传统真人语音数据难以获取、筛选
- 生成式语音数据引擎:通过数据增强技术生成高质量训练数据
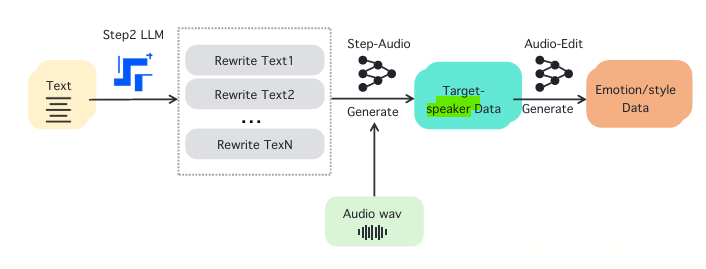
- 文本重写 (Text Rewriting):由 Step2 LLM 生成多样化语句
- 目标说话人数据合成 (Target Speaker Data Generation):结合已有音频生成目标说话人数据
- 音频编辑 (Audio Editing):调整音频情感、风格,提高自然度
3.4 结论
从整体架构来看,Step-Audio 采用了 130B 规模的多模态大模型,并在 Tokenization 和数据增强方面做出了创新突破,使得模型在语音理解、情绪表达、自然对话等方面有较强的竞争力。如果在方言支持、低资源语言建模方面继续优化,或许能进一步提升实际体验。
4.写在最后
随着 DeepSeek-R1 在文本推理方面的突破,Step-Video 和 Step-Audio 进一步扩展了多模态大模型的能力,使视频生成和语音交互进入了一个全新的阶段。Step-Video-T2V 在物理一致性和可控性方面的创新,使其成为当前最强的开源视频生成模型,而 Step-Audio 在多语言支持和情绪感知上取得了显著进展。未来,随着技术的不断发展,我们有望看到更加智能、可预测的 Level-2 级别模型,为多模态人工智能的发展打开更广阔的前景。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
