从⻘铜到王者系列:深⼊浅出理解DeepSeek 3FS (2)从内核到⽤⼾态⽂件系统的设计之路
原创
从⻘铜到王者系列:深⼊浅出理解DeepSeek 3FS (2)从内核到⽤⼾态⽂件系统的设计之路
原创
早起的鸟儿有虫吃
发布于 2025-03-26 22:36:48
发布于 2025-03-26 22:36:48
⼤家好,我是⼩王同学,本⽂希望帮你深⼊理解分布式存储系统3FS更进⼀步
昵称:20点下班就是⼀件很幸福事情愿景:让⼩孩都可以听得懂我在讲什么。我能提供什么:多问⾃⼰⼀次为什么这样⽤
作业 实现 hello world 的⽂件系统 ,并说出IO流程
参考答案
https://www.qiyacloud.cn/2021/05/2021-06-07/
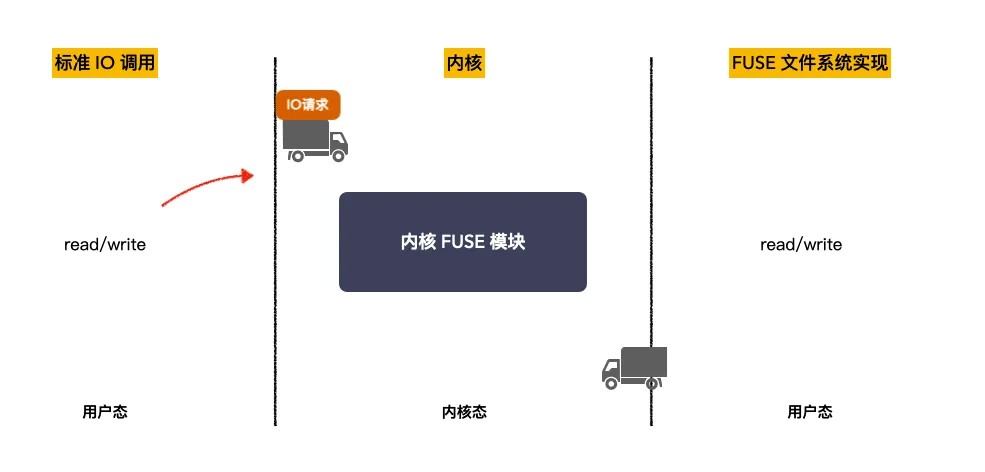
https://github.com/libfuse/libfuse/blob/master/example/hello.c 没有FUSE的IO流程⽰意图
带FUSE的IO流程⽰意图
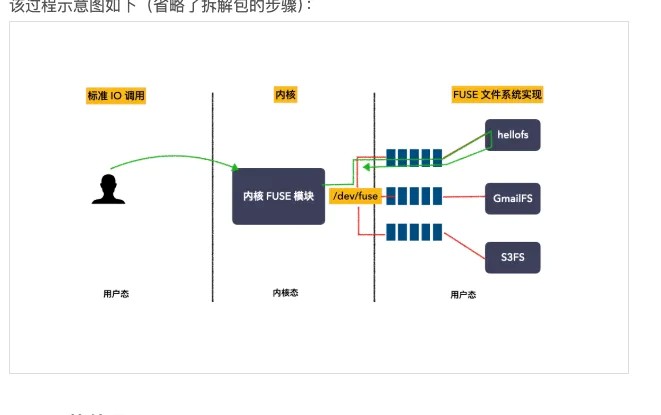
⼀、导读
从⻘铜到王者系列:深⼊浅出理解 DeepSeek 3FS(1)我整理 ⼤模型训练
在checkpoint时候对⼤的⽂件读写,在批量查询的时候对⼩⽂件读写
⽬前
⾕歌的GFS 适合 ⼤⽂件顺序读写,
Ceph mds 元数据 存在瓶颈 8k作⽤
幻⽅为什么要搞3FS?
AI训练与推理的业务需求,传统分布式⽂件系统已经难以满⾜:
- 海量数据顺序读(语料输⼊)
- 检查点(分步骤重算)
- 顺序写(模型参数保存);
- 随机读
因此重新实现⼀个新的⽂件系统
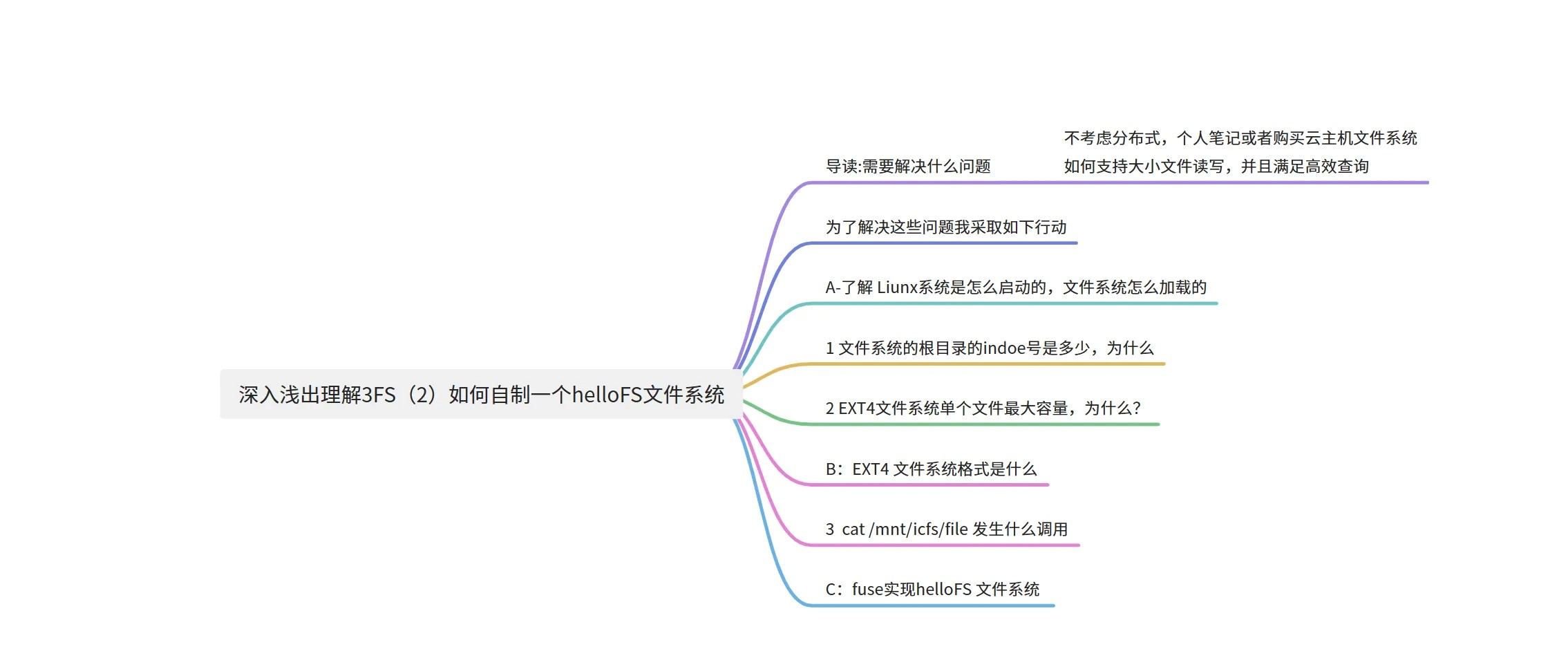
不考虑分布式,个⼈笔记或者购买云主机⽂件系统如何⽀持⼤⼩⽂件读写,并且满⾜⾼效查询提问:Linux 系统启动过程划重点:重点是⽂件系统部分,扩展虚拟机(KVM)与内核部分。
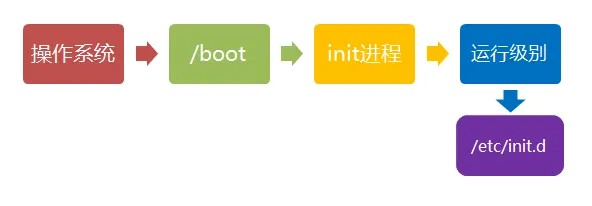
电脑通电后,加载主板上的BIOS(basic input output system)程序
BIOS是电脑启动时加载的第⼀个软件。
它是⼀组固化到计算机内主板上⼀个ROM芯⽚上的程序 boot:
虚拟机(KVM)如何设置引导硬盘顺序
什么是 KVM?
基于内核的虚拟机(KVM)是 Linux® 操作系统的⼀种开源虚拟化技术。借助
KVM,Linux 可作为虚拟机监控程序运⾏多个独⽴的虚拟机(VM)
BIOS--》boot
第1引导顺序:hard drive 硬盘第2引导顺序:cdrom 光驱 ----》安装系统第3引导顺序:removable device 可移动设备--》u盘,移动硬盘 --》安装系统第4引导顺序:Network --》从⽹络启动--》⽹络中安装服务器启动 --》安装
⽂件系统部分
启动流程:
- 内核加载完成
- 执⾏mount操作
挂载⽂件系统想要操作⽂件系统,第⼀件事情就是挂载⽂件系统
- 读取超级块
- 定位inode 2
- 将其挂载为根⽬录系统启动过程:
+----------------+ +---------------+ +------------------+
| 读取超级块 | --> | 定位inode 2 | --> | 挂载为根目录(/) |
+----------------+ +---------------+ +------------------+

在 Linux 启动过程中,加载 ext4 ⽂件系统主要经历以下⼏个阶段:
- 内核加载与初始化当系统通过 BIOS/UEFI 加载引导加载程序(如 GRUB)后,内核被加载到内存中。
内核初始化时,会建⽴ VFS(虚拟⽂件系统)核⼼数据结构,如 dentry 哈希表和 inode 哈希表,并加载必要的⽂件系统驱动(ext4 驱动可以是内置的或作为模块加载)。
- 挂载根⽂件系统内核根据启动参数(例如 root=/dev/sda1)确定根⽂件系统所在的设备。调⽤函数如 vfs_kern_mount()(进⼀步调⽤ ext4_mount())来挂载 ext4
⽂件系统。
在挂载过程中,ext4 驱动会读取设备上的超级块(superblock),验证
ext4 的魔数(magic number)和其它元数据,同时初始化 inode 表、⽇志(journal)等内部数据结构。
ext4 ⽂件系统的根⽬录在挂载时根据约定总是分配 inode 号 2。
- 切换根⽂件系统(pivot_root/switch_root)如果系统使⽤了 initrd 或 initramfs 作为临时根⽂件系统,内核会在加载完真正的 ext4 ⽂件系统后,通过 pivot_root 或 switch_root 将根⽬录切换到挂载的 ext4 ⽂件系统上。
此时,init(或 systemd)进程启动,⽤⼾空间接管并继续后续的初始化⼯作。
这样,整个过程确保了 ext4 ⽂件系统的元数据和数据块被正确加载,并最终成为系统的根⽂件系统,使⽤⼾和应⽤程序可以正常访问⽂件数据。
作业:为什么不同挂载点的inode号码都是2
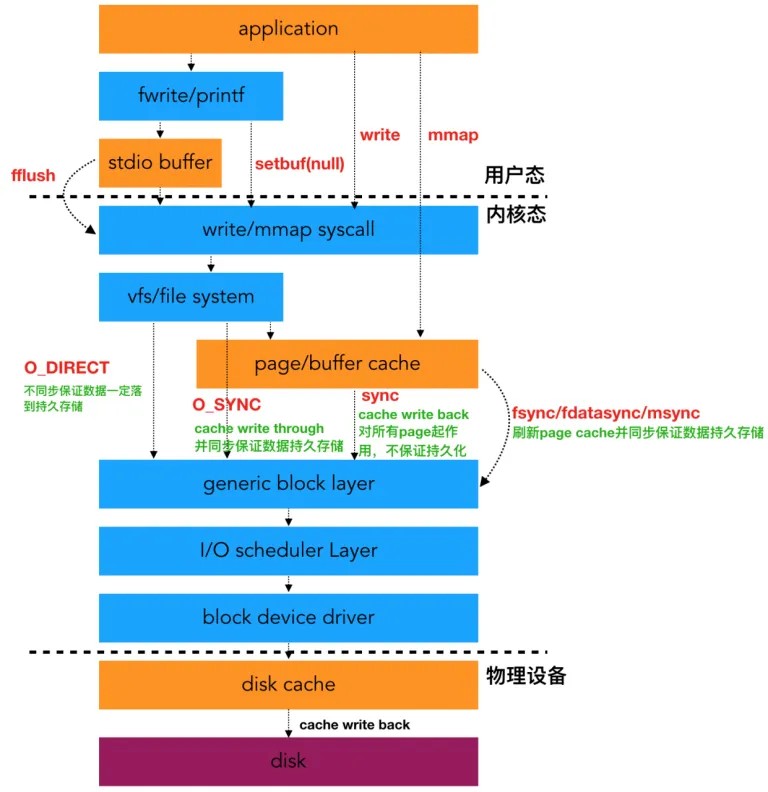
⼆、提问:Linux ⽂件系统是怎么⼯作的?
通过这张图,你可以看到,在 VFS 的下⽅,Linux ⽀持各种各样的⽂件系统,如
Ext4、XFS、NFS 等等。按照存储位置的不同,这些⽂件系统可以分为三类。
类是基于磁盘的⽂件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。
⻅的 Ext4、XFS、OverlayFS 等,都是这类⽂件系统。
类是基于内存的⽂件系统,也就是我们常说的虚拟⽂件系统。
类是⽹络⽂件系统,
也就是⽤来访问其他计算机数据的⽂件系统,⽐如 NFS、SMB、iSCSI 等。
⽹络⽂件系统 NFS:⾸次突破内核态
随着计算需求的增⻓,单台计算机的性能逐渐⽆法满⾜⽇益增⻓的计算和存储要求。
⼈们开始引⼊多台计算机,以分担负载并提⾼整体效率。
在这⼀场景下,⼀个应⽤程序往往需要访问分布在多台计算机上的数据。
为了解决这⼀问题,⼈们提出了在⽹络中引⼊虚拟存储层的概念,将远程计算机的⽂件系统(如某个⽬录)通过⽹络接⼝挂载到本地计算机的节点上。
这样做的⽬的是使本地计算机能够⽆缝地访问远程计算机的数据,就好像这些数据存储在本地⼀样

linux分析利刃之sar命令详解
参考:
https://www.cnblogs.com/zsql/p/11628766.html
sar -n DEV 1 1#统计⽹络信息 这个有⽤带宽统计查看进⾏哪些线程
⽂件系统的格式
来源:
https://zh.wikipedia.org/wiki/Ext4
第四代扩展⽂件系统(英语:Fourth extended filesystem,缩写为ext4)是Linux 系统下的⽇志⽂件系统
⽂件系统(六):⼀⽂看懂linux ext4⽂件系统⼯作原理
ext4它突出的特点有:数据分段管理、多块分配、延迟分配、持久预分配、⽇志校验、⽀持更⼤的⽂件系统和⽂件⼤⼩。
ext4⽂件系统的具体实现⽐较复杂,本⽂尝试⽤⽐较简单的⽅式⽤⼀篇⽂章的篇幅来简单地介绍⼀下它的⼯作原理。
命令:dumpe2fs /dev/loop0
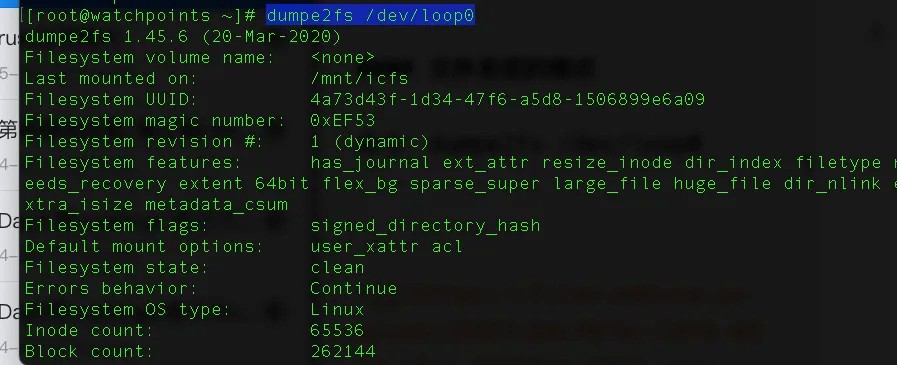
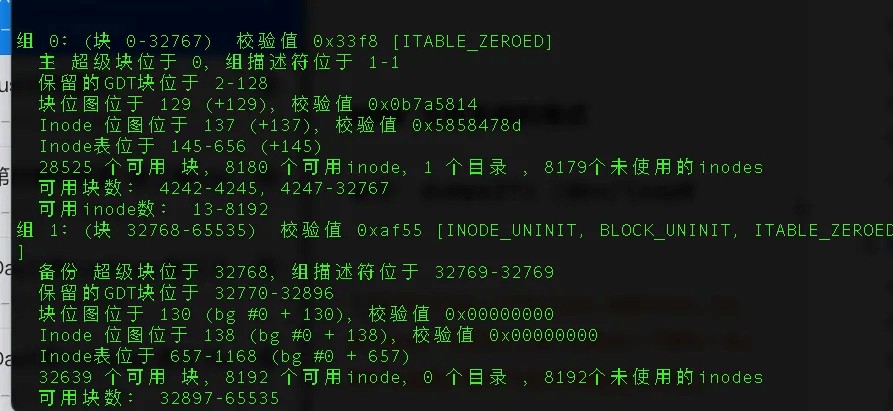
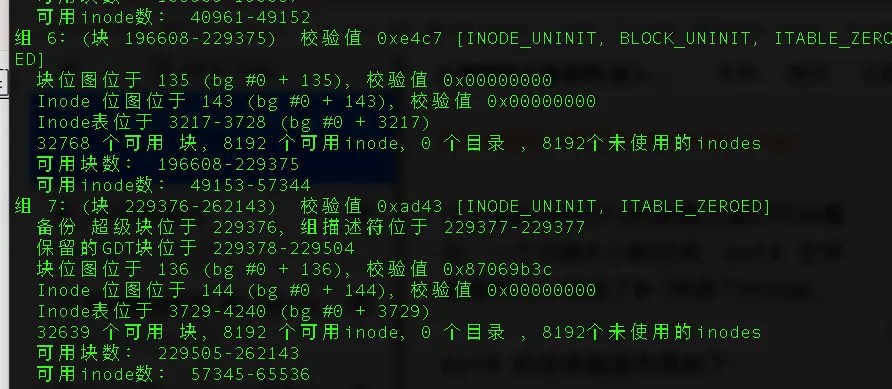
从上⾯dumpe2fs的数据上我们可以看出,⼀个1GB⼤⼩的空间,ext4 ⽂件系统将它分隔成了0~7的8个Group。
其中,每个Group中⼜有superblock、Group descriptors、bitmap、Inode table、
usrer data、还有⼀些保留空间,细分之后的空间布局如下: ext4 的总体磁盘布局如下:
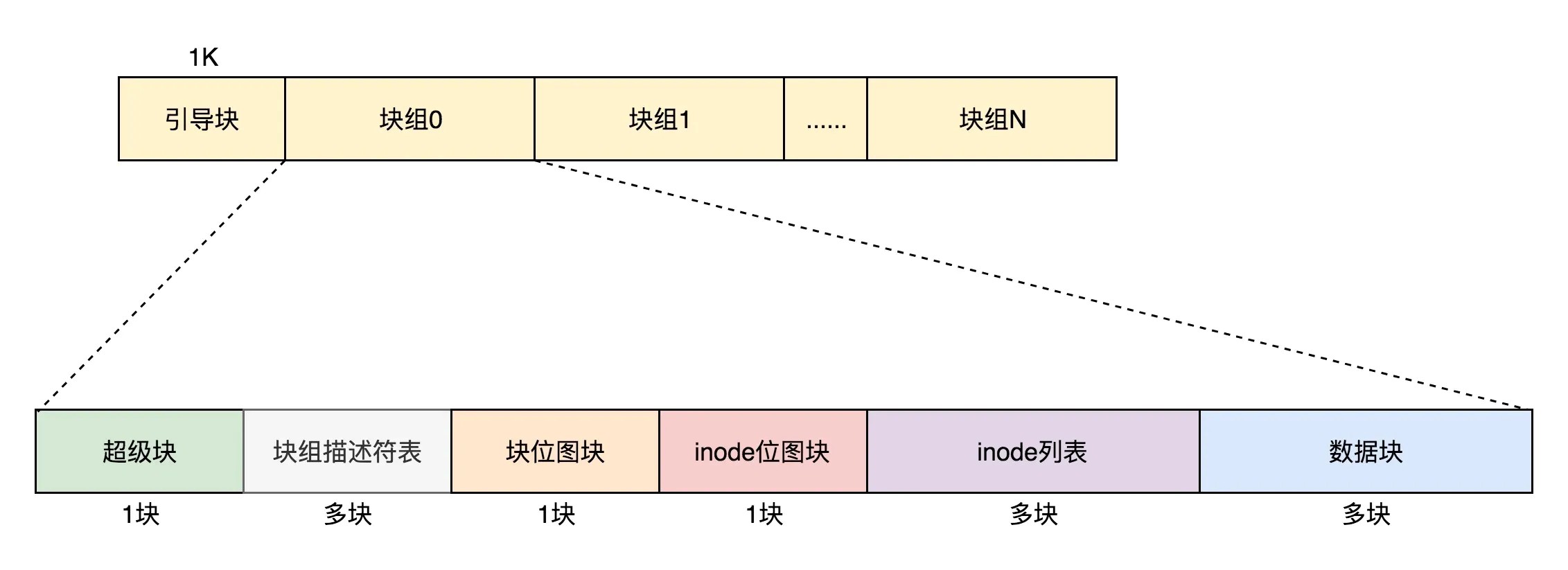
具体含义内:
ext4⽂件系统信息表
从上⾯《1.1 ext4⽂件系统信息表》中可以知道Primary superblock在第0号 block,每个block的⼤⼩为4096Byte
⽂件系统信息、块⼤⼩和块组信息、Inode 相关信息、⽂件系统⼤⼩和使⽤情况、⽇志相关信息、挂载信息、校验和和备份信息。
这⾥⾯我还需要重点说⼀下,超级块和块组描述符表都是全局信息,⽽且这些数据很重要。
如果这些数据丢失了,整个⽂件系统都打不开了,这⽐⼀个⽂件的⼀个块损坏更严重。所以,这两部分我们都需要备份,但是采取不同的策略。默认情况下,超级块和块组描述符表都有副本保存在每⼀个块组⾥⾯
其实使⽤dumpe2fs命令查看的ext4⽂件系统信息就是从superblock上的数据解析
⽽来。
除了Primary superblock,还在不同的group中有备份superblock,其内容与
Primary superblock原始数据相同,Primary superblock损坏的时候可以从备份区恢复回来
回顾:
在 Linux 内核挂载 ext4 ⽂件系统时,挂载流程⼤致如下:
- 系统调⽤ mount() 启动挂载流程当⽤⼾或内核启动参数(如 root=/dev/sda1)触发挂载时,会调⽤通⽤的 mount 系统调⽤,进⽽进⼊ VFS 层的挂载流程。
- 进⼊ ext4 挂载⼊⼝ ext4_mount()
ext4 ⽂件系统在内核中注册为⼀种⽂件系统类型,其挂载⼊⼝函数通常为 ext4_mount()(定义在 fs/ext4/super.c 中)。
在该函数中,会调⽤ ext4_fill_super(),⽤来读取磁盘上的超级块
(superblock)并验证 ext4 ⽂件系统的完整性。
- 解析超级块与加载根 inode ext4_fill_super() 会从设备上读取超级块数据,然后填充超级块结构体。在超级块中保存了⽂件系统全局信息,其中就包括 ext4 ⽂件系统的根⽬录 inode 的固定编号(EXT4_ROOT_INO 定义为 2,⻅ fs/ext4/ext4.h)。紧接着,内核通过 ext4_iget()(或相关函数)加载 inode 2,这个 inode 就代表了⽂件系统的根⽬录。
- 构造根⽬录 dentry 并完成挂载加载根 inode 后,内核会创建相应的 dentry(⽬录项),并将该根 dentry 作为挂载点的根,最终将整个⽂件系统挂载为根⽬录(/)。
相关源码主要分布在内核源代码的 fs/ext4/ ⽬录下,具体可以查看 ext4_mount()、ext4_fill_super() 以及 ext4_iget() 等函数。
ext4 ⽂件系统特点的
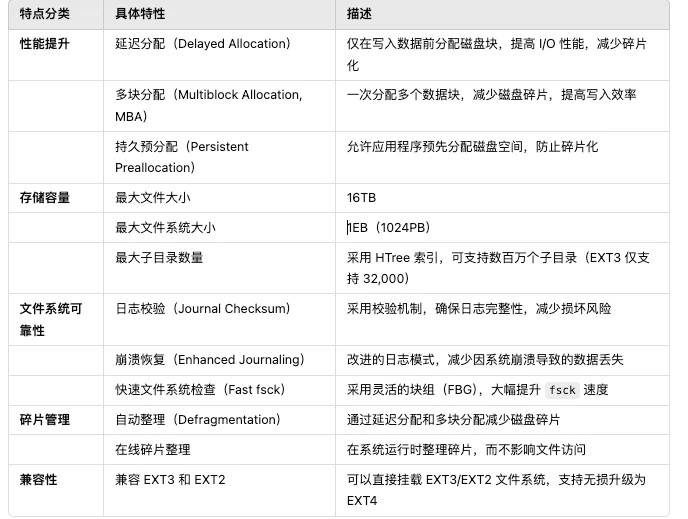
具体如何保存的呢?
EXT4_N_BLOCKS 有如下的定义,计算下来⼀共有 15 项。在 ext2 和 ext3 中,其中前 12 项直接保存了块的位置,也就是说,我们可以通过 i_block[0-11],直接得到保存⽂件内容的块。
如果⼀个⽂件⽐较⼤,12 块放不下 i_block[12]指向⼀个块,这个块⾥⾯不放数据块,⽽是放数据块的位置,这个块我们称为间接块。
也就是说,我们在 i_block[12]⾥⾯放间接块的位置,通过 i_block[12]找到间接块后,间接块⾥⾯放数据块的位置,通过间接块可以找到数据块。如果⽂件再⼤⼀些,i_block[13]会指向⼀个块,我们可以⽤⼆次间接块【指针的指针】
如果⽂件再⼤⼀些,i_block[14]会指向三次间接块
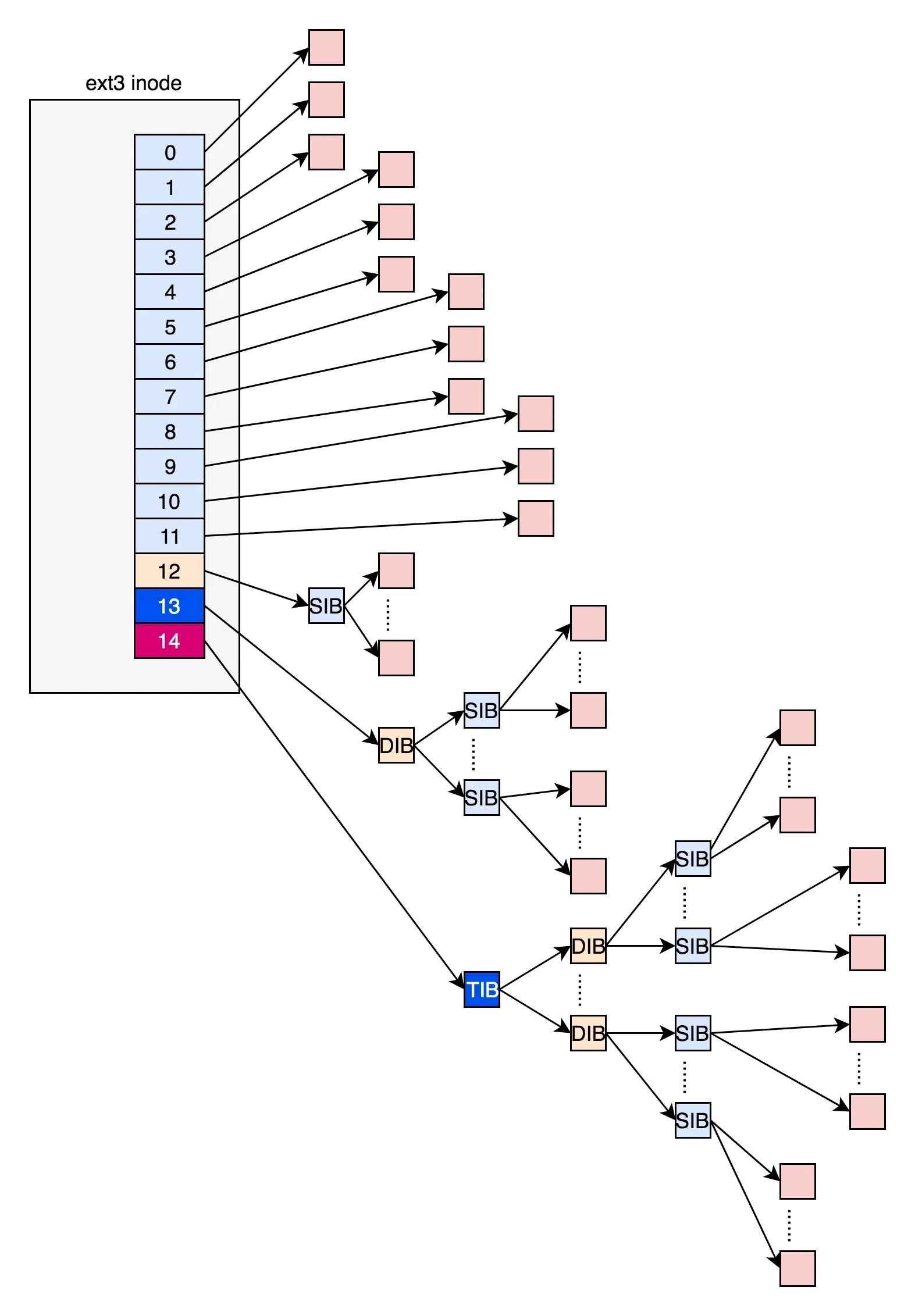
EXT4 ⽂件系统采⽤ 索引节点(inode)结构 来管理⽂件,其中 inode 结构中包含 15 个指针,⽤于定位⽂件数据块。 EXT4 Inode 结构中的 15 个指针
指针类型 | 数量 | 说明 |
|---|---|---|
直接块指针(Direct Block) | 12 | 直接指向数据块,每个指针可寻址 1 个数据块。 |
⼀次间接指针(Singly Indirect) | 1 | 指向⼀个块,该块内存储多个直接块指针。 |
⼆次间接指针(Doubly Indirect) | 1 | 指向⼀个块,该块内的指针指向多个⼀次间接块。 |
三次间接指针(Triply Indirect) | 1 | 指向⼀个块,该块内的指针指向多个⼆次间接块。 |
单个⽂件最⼤⽀持⼤⼩计算
假设 块⼤⼩(block size)为 4KB(EXT4 常⽤设置),计算单个⽂件最⼤⼤⼩:
- 直接块存储数据:
12 个直接指针 × 4KB = 48KB
- ⼀次间接块存储数据:
- 个指针块存储 1024 个指针(4KB / 4B = 1024)
1024 × 4KB = 4MB
- ⼆次间接块存储数据:
- 个指针块存储 1024 个⼀次间接指针
1024 × 4MB = 4GB
- 三次间接块存储数据:
- 个指针块存储 1024 个⼆次间接指针
1024 × 4GB = 4TB
最终计算(最⼤单个⽂件⼤⼩)
直接块:48KB
⼀次间接块:4MB ⼆次间接块:4GB 三次间接块:4TB
总计 ≈ 4TB + 4GB + 4MB + 48KB ≈ 4TB
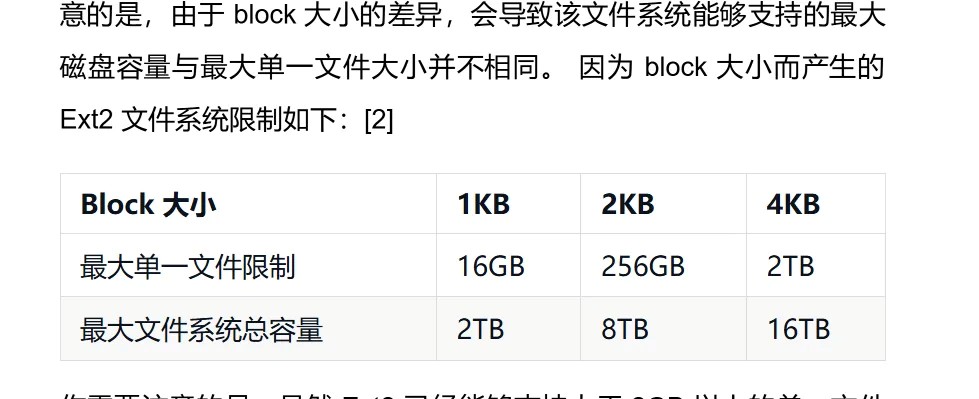
结论
EXT4 单个⽂件最⼤可达 16TB(如果启⽤了 更⼤的 block size,⽐如
64KB)。
在 4KB 块⼤⼩下,单个⽂件最⼤ ≈ 4TB(由于索引结构限制)。
相⽐ EXT3(单⽂件最⼤ 2TB),EXT4 更适合⼤⽂件存储。
如果需要存储超过 4TB 的单个⽂件,可以:
- 使⽤更⼤的块⼤⼩(如 64KB,最⼤ 16TB)。
- 考虑使⽤其他⽂件系统(如 XFS、Btrfs、ZFS)。
对⽐:
为了解决这个问题,ext4 做了⼀定的改变。
它引⼊了⼀个新的概念,叫做 Extents。
我们来解释⼀下 Extents。
⽐⽅说,⼀个⽂件⼤⼩为 128M,如果使⽤ 4k ⼤⼩的块进⾏存储,需要 32k 个块。
如果按照 ext2 或者 ext3 那样散着放,数量太⼤了。
但是 Extents 可以⽤于存放连续的块,也就是说,我们可以把 128M 放在⼀个
Extents ⾥⾯。
这样的话,对⼤⽂件的读写性能提⾼了,⽂件碎⽚也减少了。
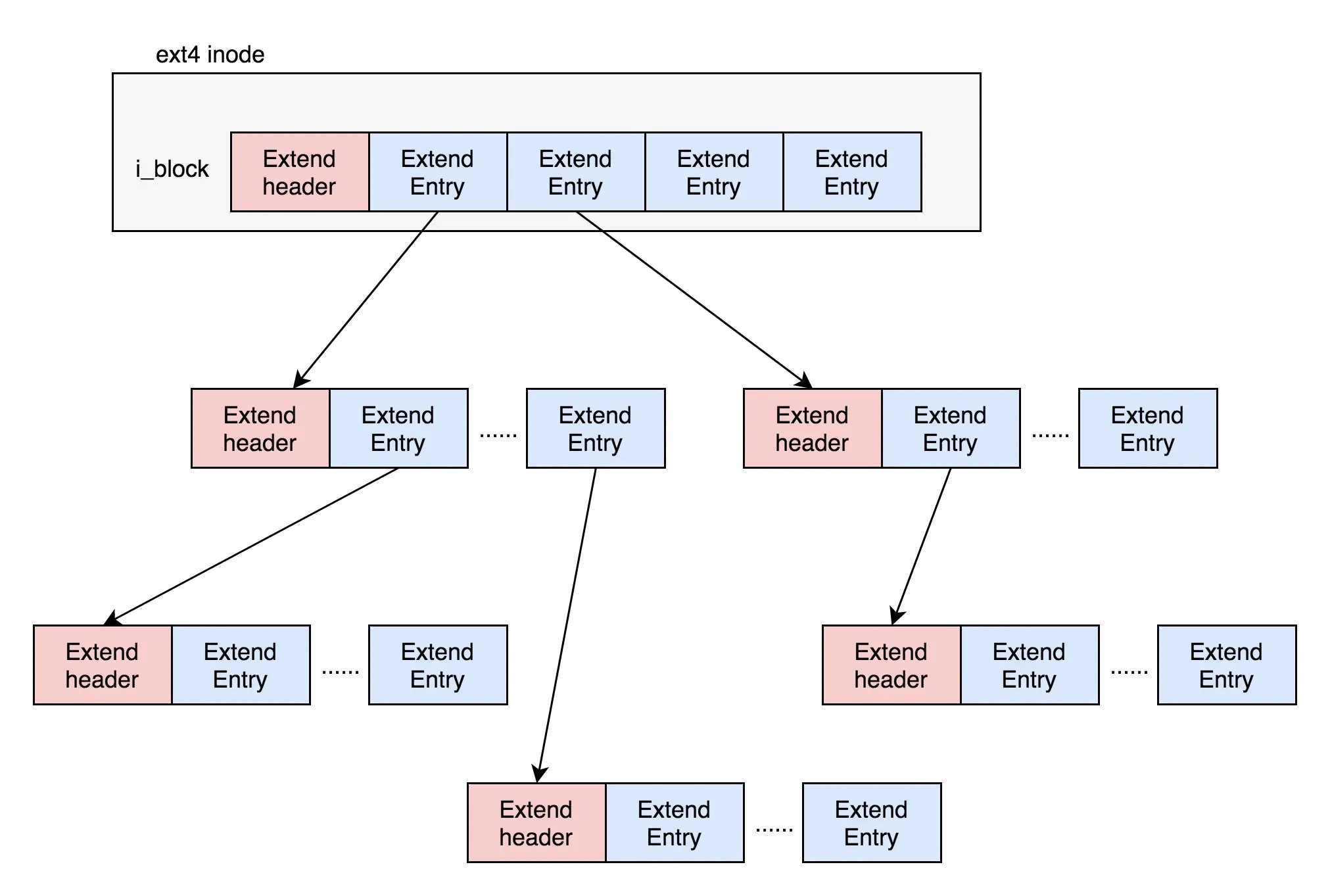
除了根节点,其他的节点都保存在⼀个块4k⾥⾯,4k扣除ext4_extent_header的 12个byte,剩下的能够放340项,每个extent最⼤能表⽰128MB的数据,340个 extent会使你的表⽰的⽂件达到42.5GB。
三、ext4⽂件系统为例⼦ cat /mnt/icfs/fileA 判断⽂件fileA是否存在
✅前置条件:
在 Linux 中,⽂件系统(如 ext4)通常只能在块设备(block device)上创建和操
作,例如:
物理磁盘 (/dev/sda, /dev/nvme0n1) 磁盘分区 (/dev/sda1, /dev/nvme0n1p1) 虚拟块设备(如 LVM 逻辑卷 /dev/mapper/vg-lv)
如果 没有额外的磁盘,但你仍然需要:
👉 你可以使⽤ Loop 设备(/dev/loopX)将普通⽂件当作块设备
📌 例⼦:⽤ Loop 设备模拟⼀个 ext4 ⽂件系统

提问 cat /mnt/icfs/file 查找过程是什么
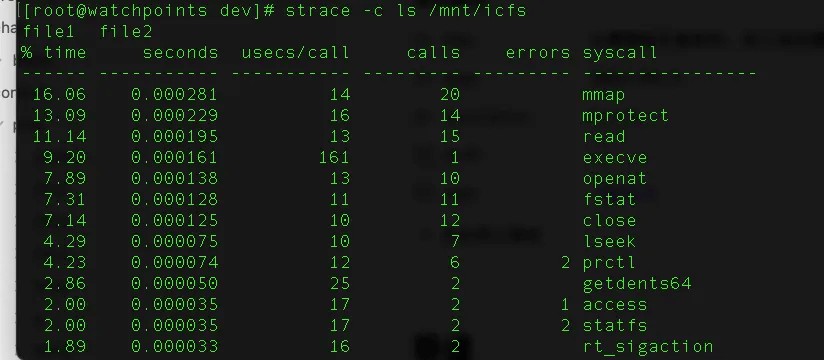
准备:
strace 作为⼀种动态跟踪⼯具,strace 底层使⽤内核的 ptrace 特性来实现其功能
,ptrace可以让⼀个进程监视和控制另⼀个进程的执⾏,并且修改被监视进程的内
存、寄器等,主要应⽤于断点调试和系统调⽤跟踪,strace和gdb⼯具就是基于 ptrace编写的
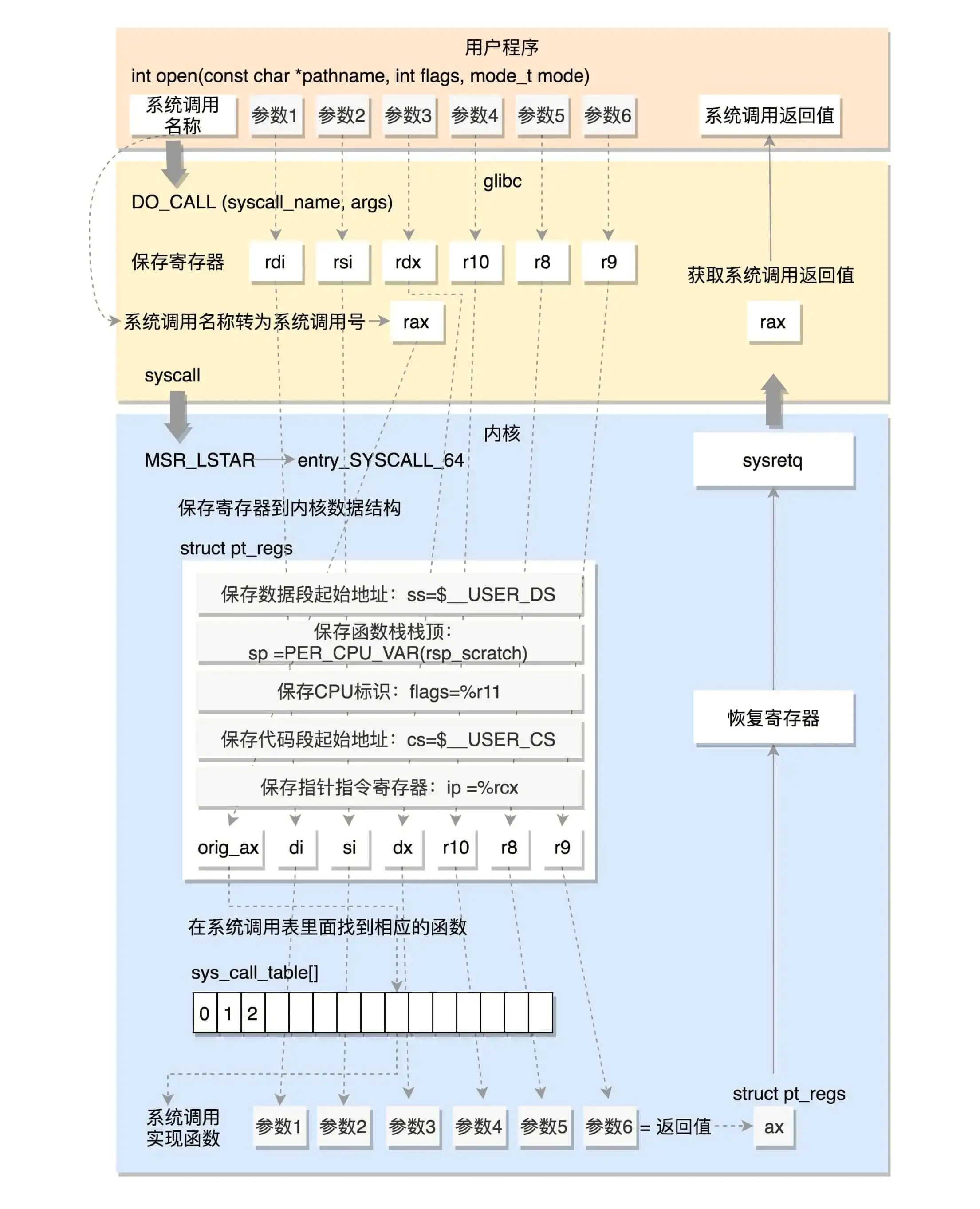
Open 系统调⽤说起
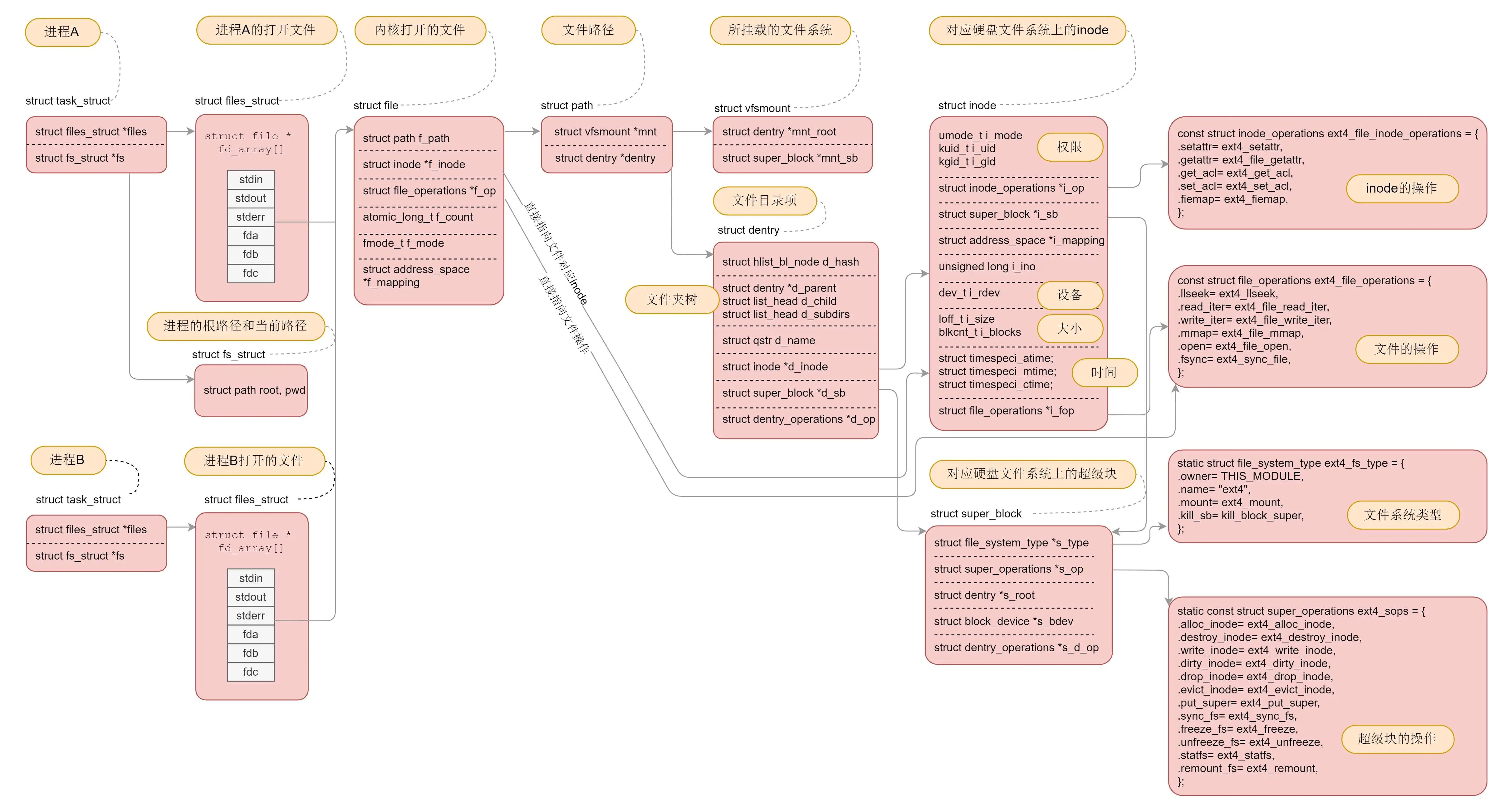
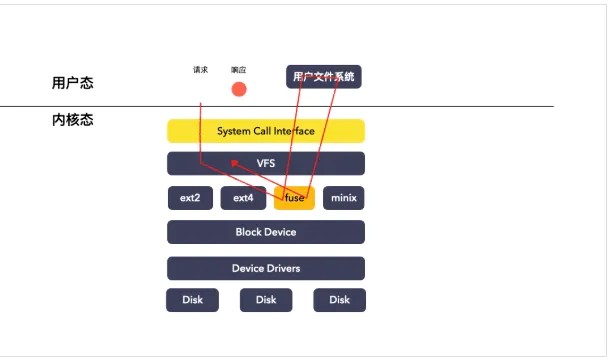
这张图⼗分重要,⼀定要掌握。因为我们后⾯的字符设备、块设备、管道、进程间通信、⽹络等等,全部都要⽤到这⾥⾯的知识。希望当你再次遇到它的时候,能够⻢上说出各个数据结构之间的关系从mount到fuse客⼾端
1. FUSE 是什么?
Linux内核官⽅⽂档对 FUSE 的解释如下:
What is FUSE?
FUSE is a userspace filesystem framework.
It consists of a kernel module (fuse.ko), a userspace library (libfuse.*)
and a mount utility (fusermount).
思考问题:内核的 fuse.ko 模块,还有 libfuse 库。这两个⻆⾊是的作⽤?
这两个模块⼀个位于内核,⼀个位于⽤⼾态,是配套使⽤的,最核⼼的功能是协议封装和解析。
举给例⼦,内核 fuse.ko ⽤于承接 vfs 下来的 io 请求,然后封装成 FUSE 数据包,转发给⽤⼾态。
这个时候,⽤⼾态⽂件系统收到这个 FUSE 数据包,它如果想要看懂这个数据
包,就必须实现⼀套 FUSE 协议的代码,这套代码是公开透明的,属于 FUSE 框架的公共的代码
,这种代码不能够让所有的⽤⼾⽂件系统都重复实现⼀遍,于是 libfuse ⽤⼾库就诞⽣了。
划重点:FUSE 是⼀个⽤来实现⽤⼾态⽂件系统的框架
⽤⼾态⽂件系统是区别于内核⽂件系统的,在⽤⼾态⽂件系统没有出现之前,常⻅的⽂件系统如Ext2、Ext4等都是在内核中直接实现的。
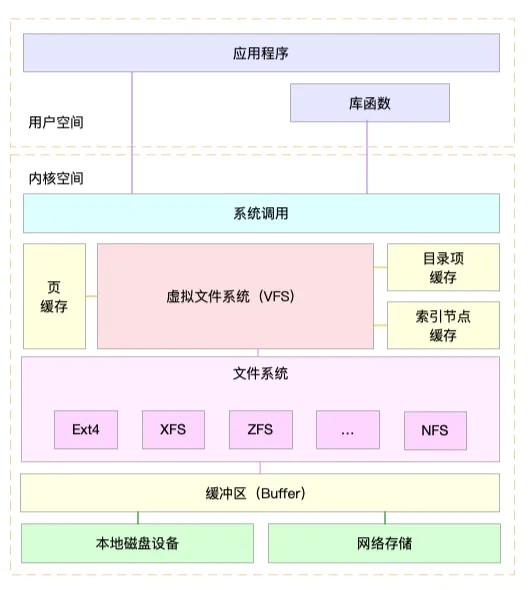
通过这张图,你可以看到,在 VFS 的下⽅,Linux ⽀持各种各样的⽂件系统,如
Ext4、XFS、NFS 等等。按照存储位置的不同,这些⽂件系统可以分为三类。
类是基于磁盘的⽂件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。
⻅的 Ext4、XFS、OverlayFS 等,都是这类⽂件系统。
类是基于内存的⽂件系统,也就是我们常说的虚拟⽂件系统。
类⽂件系统,不需要任何磁盘分配存储空间,但会占⽤内存。我们经常⽤到的
/proc ⽂件系统
类是⽹络⽂件系统,
也就是⽤来访问其他计算机数据的⽂件系统,⽐如 NFS、SMB、iSCSI 等。
2. FUSE 原理是什么
代码:
https://github.com/libfuse/libfuse/blob/master/example/hello.c
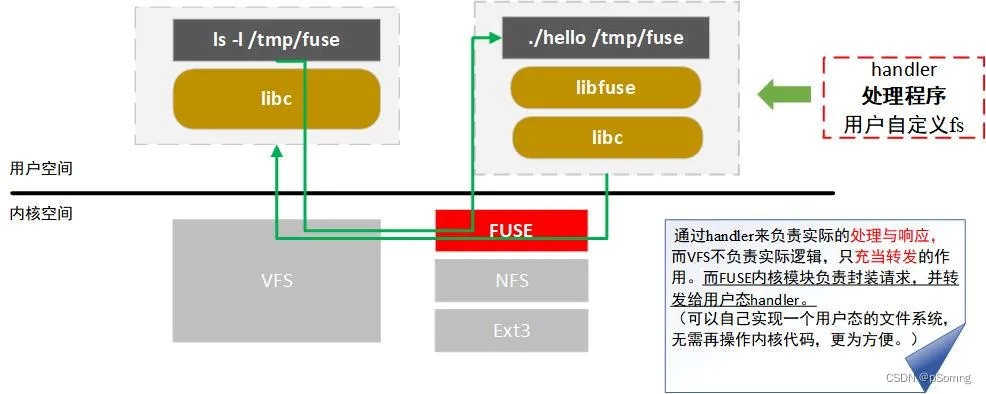
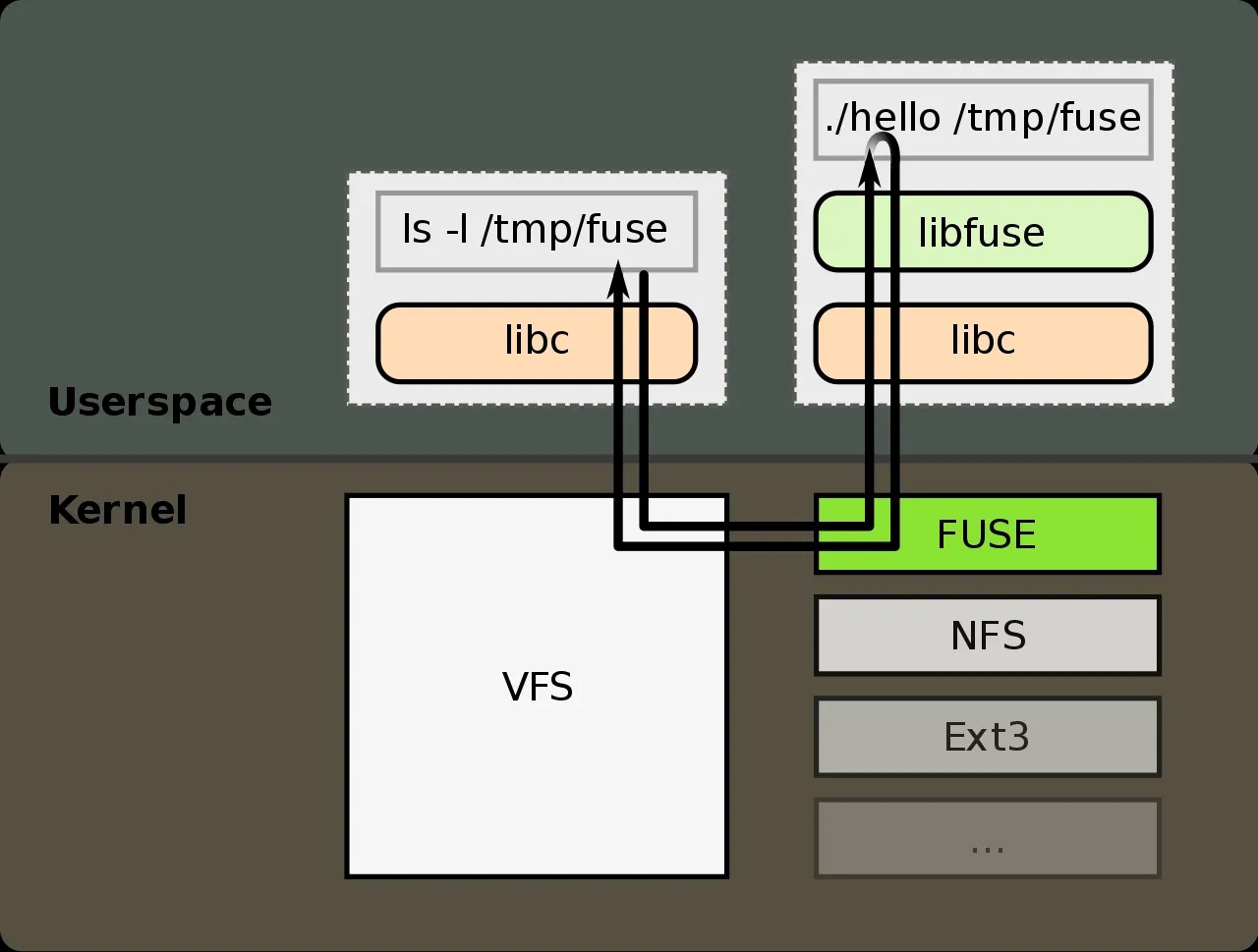
这个图的意思是:
背景:⼀个⽤⼾态⽂件系统,挂载点为 /tmp/fuse ,⽤⼾⼆进制程序⽂件为 ./hello
;
当执⾏ ls -l /tmp/fuse 命令的时候,
流程如下:
IO 请求先进内核,经 vfs 传递给内核 FUSE ⽂件系统模块;
内核 FUSE 模块把请求发给到⽤⼾态,由 ./hello 程序接收并且处理。
处理完成之后,响应原路返回;划重点:
实现了 FUSE 的⽤⼾态⽂件系统有⾮常多的例⼦,⽐如,GlusterFS,SSHFS,
CephFS,Lustre,GmailFS,EncFS,S3FS
应⽤:JuiceFS :FUSE ⽤⼾态分布式⽂件系统
收益:
FUSE 通过将⽤⼾空间与内核空间解耦,为开发者提供了在⽤⼾空间实现⽂件系统的巨⼤灵活性和便利性。特别是在云计算和分布式存储等现代计算环境中,FUSE 使得构建和维护复杂的存储系统变得更加⾼效、可定制和易于扩展。
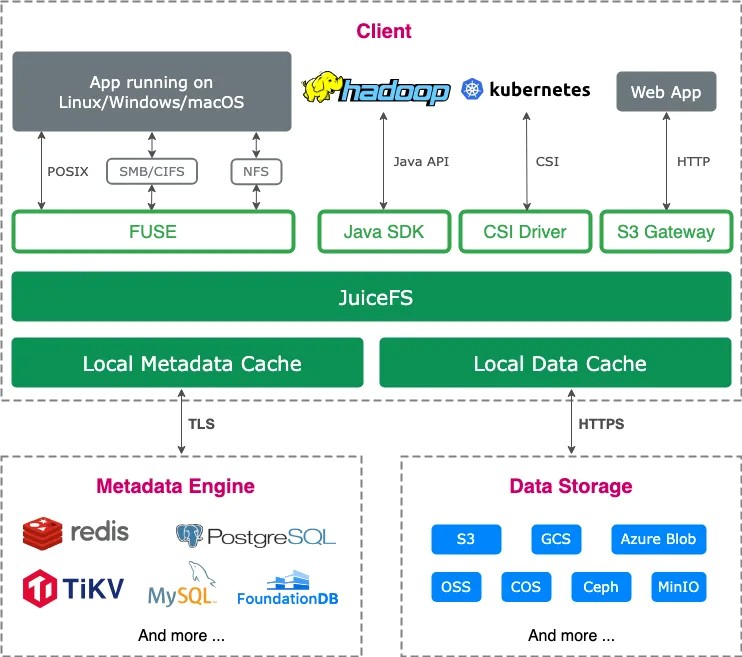
以⽤⼾挂载 JuiceFS 后,open 其中⼀个⽂件的流程为例。
请求⾸先通过内核 VFS,然后传递给内核的 FUSE 模块,经过 /dev/fuse 设备与
JuiceFS 的客⼾端进程通信。
具体步骤如下:
当 JuiceFS mount 后,JuiceFS 内部的 go-fuse 模块会 open /dev/fuse 获取 mount fd,并启动⼏个线程读取内核的 FUSE 请求; 具体步骤如下:
- JuiceFS mount 后,JuiceFS 内部的 go-fuse 模块会 open /dev/fuse 获取 mount fd,并启动⼏个线程读取内核的 FUSE 请求;
- ⽤ open 函数,通过 C 库和系统调⽤进⼊ VFS 层,VFS 层再将请求转给内核的 FUSE 模块;
- FUSE 模块根据协议将 open 请求放⼊ JuiceFS mount 的 fd 对应的队列中,并唤醒 go-fuse 的读请求线程,等待处理结果;
- 的 go-fuse 模块读取 FUSE 请求并在解析请求后调⽤ JuiceFS 的对应实现;
- fuse 将本次请求的处理结果写⼊ mount fd,即放⼊ FUSE 结果队列,然后唤醒业务等待线程;
- 程被唤醒,得到本次请求的处理结果,然后再返回到上层。
应⽤: 将 Ceph ⽂件系统挂载为 FUSE 客⼾端
参考代码:
src\ceph_fuse.cc
基本⽤法:
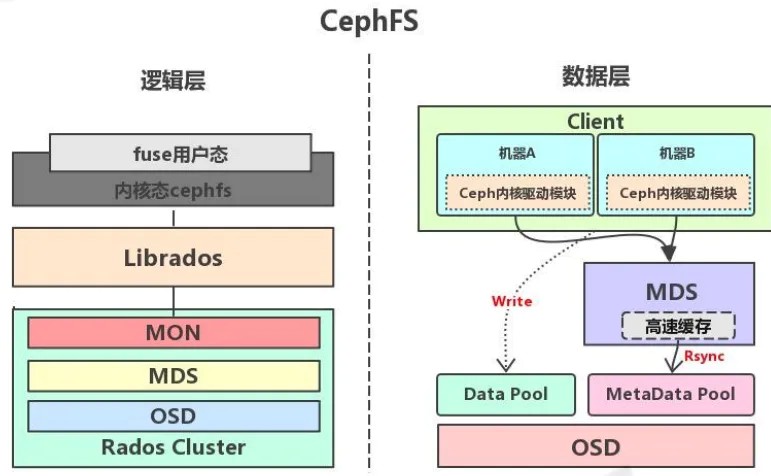
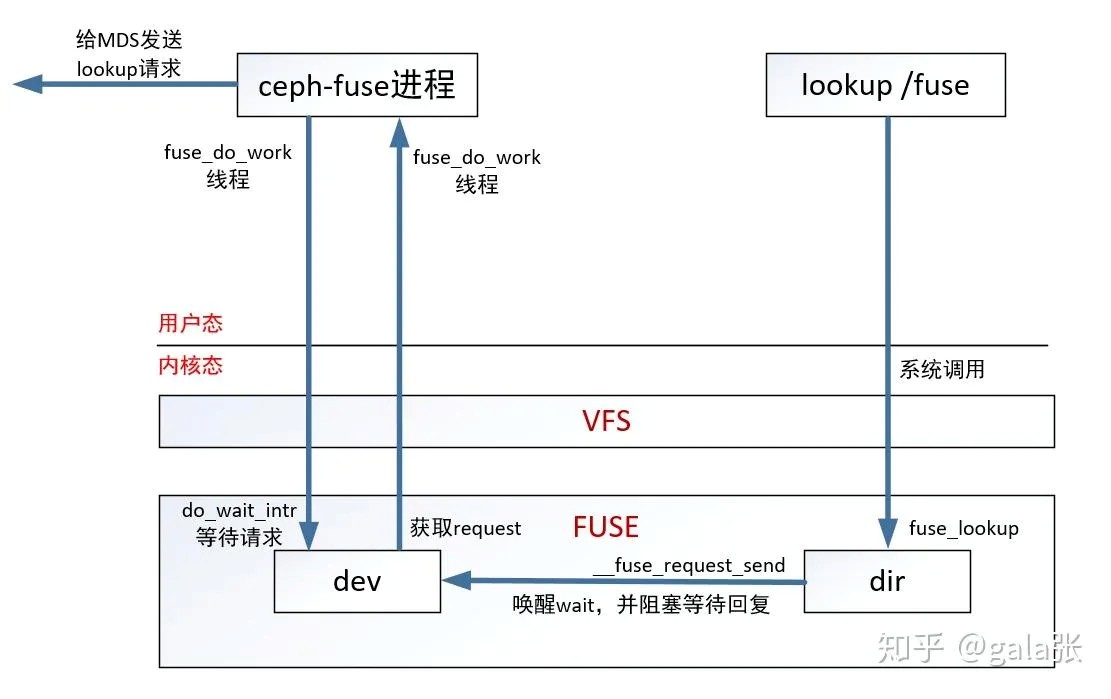
⽤⼾可以⽤ Ceph 提供的 ceph-fuse 挂载 CephFS 进⾏访问 ceph-fuse处理IO流程举个例⼦ lookup /fuse,从lookup /fuse到ceph-fuse的流程图如下
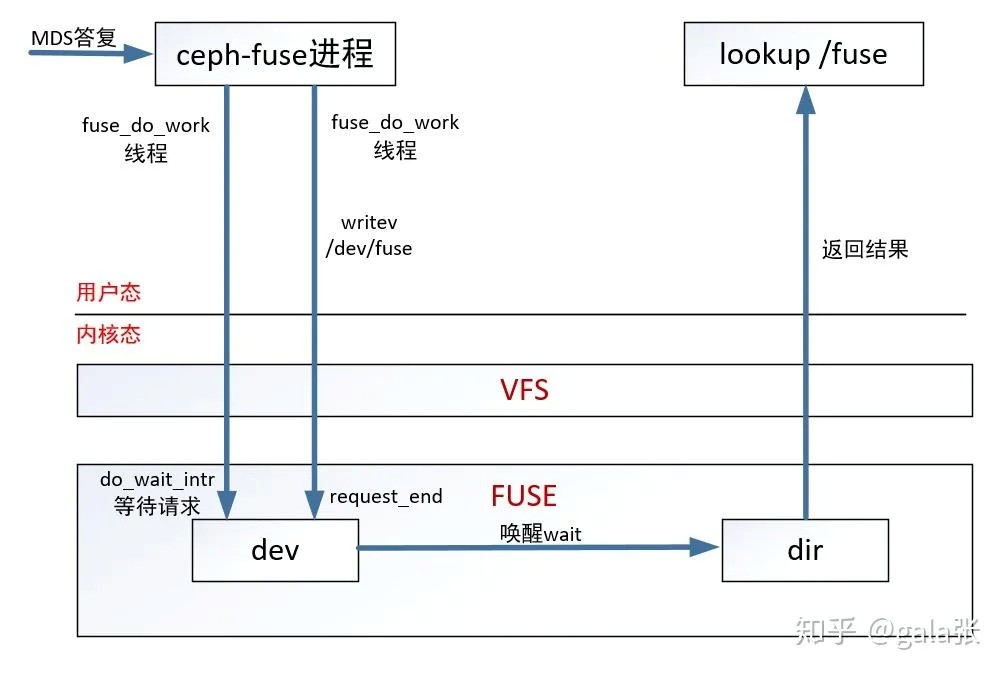
MDS返回结果给ceph-fuse进程。从ceph-fuse到lookup /fuse的流程图如下
cephfs:⽤⼾态客⼾端write 从fuse到cephfs客⼾端的函数流程如下
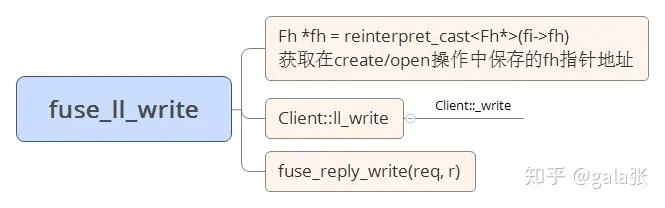
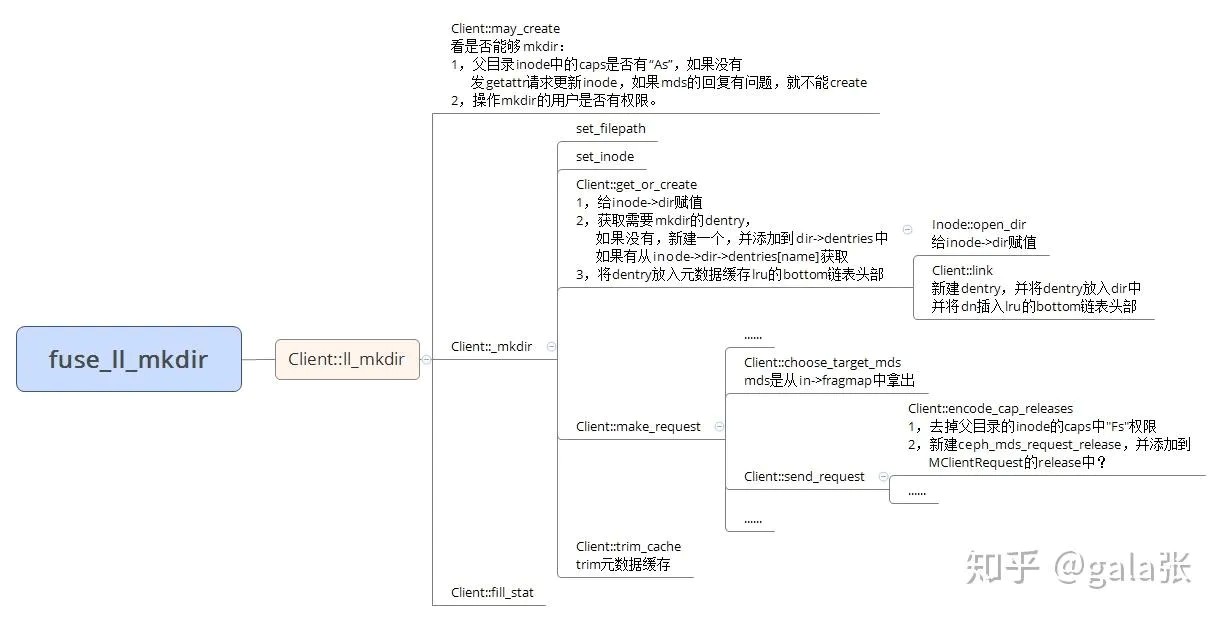
例⼦ mkdir /mnt/ceph-fuse/test
mkdir就是创建⽬录,客⼾端并不直接创建⽬录,⽽是将mkdir的请求(op为
CEPH_MDS_OP_MKDIR)发给MDS,然后MDS执⾏mkdir的操作,并返回创建的⽬录的元数据。
客⼾端⽆⾮就是发送请求和处理回复。
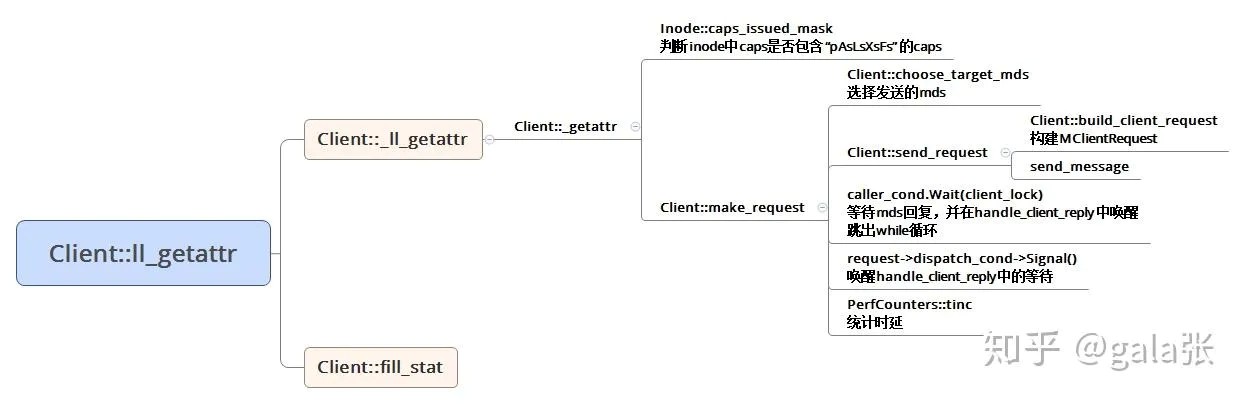
cephfs:⽤⼾态客⼾端getattr(1)从libfuse到cephfs⽤⼾态客⼾端的过程

cephfs⽤⼾态客⼾端是从fuse_ll_getattr开始,fuse_ll_getattr的作⽤是通过cfuse>client->ll_getattr获取inode,填充struct stat信息,并返回该stat信息。

cephfs:⽤⼾态客⼾端getattr(2)
客⼾端获得的inode来⾃于MDS(元数据服务器),所以当客⼾端缓存的某个inode 需要更新时,会向MDS发送op为CEPH_MDS_OP_GETATTR的请求。MDS回复的消息中带有最新的inode数据。这种情况下,就得了解发请求和处理请求的流程。
划重点:将 Ceph ⽂件系统挂载为内核客⼾端 这⾥不讨论
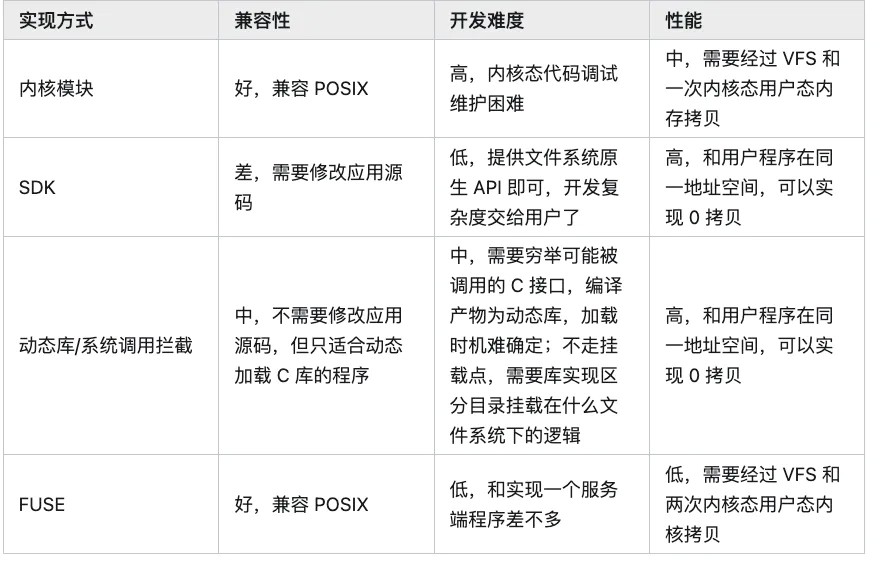
提问:s3fs-fuse

s3fs-fuse 是⼀个基于 FUSE(Filesystem in Userspace)的⽂件系统,允许 Linux、macOS 和 FreeBSD 系统通过 FUSE 挂载 Amazon S3 存储桶。
通过 s3fs-fuse,⽤⼾可以像操作本地⽂件系统⼀样操作 S3 存储桶中的⽂件和⽬录。该项⽬的主要编程语⾔是 C++。为什么使⽤fuse --⼩团队开发 简单为主
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号