【AI 进阶笔记】SSD 改进:DSSD
原创
【AI 进阶笔记】SSD 改进:DSSD
原创
繁依Fanyi
发布于 2025-04-02 23:13:19
发布于 2025-04-02 23:13:19
1. 开篇:SSD 的进化之路
如果你是目标检测领域的新人,可能听过 SSD(Single Shot MultiBox Detector),这是一种非常高效的目标检测算法。它比传统的 R-CNN、Faster R-CNN 更快,因为它直接从图片中预测多个目标的类别和位置,而不用像 R-CNN 那样做一堆复杂的区域提取。
但 SSD 也有一个痛点——它对小目标的检测能力较弱。这就像是戴着一副老花镜去看远方的蚂蚁,模糊不清。DSSD(Deconvolutional Single Shot Detector)就是为了解决这个问题而生的。它的核心改进点在于 引入了反卷积(Deconvolution)层,增强了小目标的检测能力。
那么,DSSD 究竟是如何改进 SSD 的呢?我们从头捋一遍,深入浅出地剖析它的设计原理。
2. DSSD 论文精讲
2.1 DSSD 结构解析
DSSD 的架构可以拆成三大块:
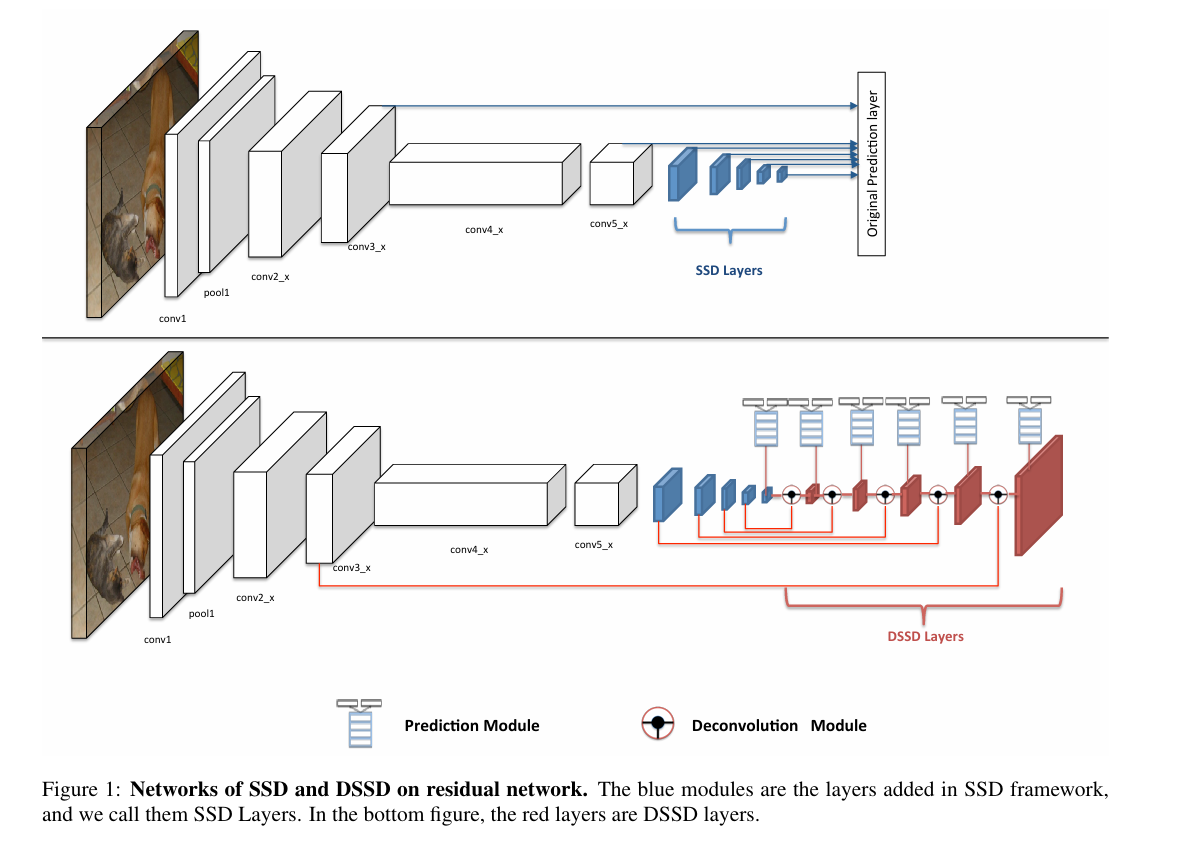
在这里插入图片描述
- ResNet-101 作为骨干网络(Backbone)
- 负责提取特征,比 SSD 里用的 VGG 更强大。
- 额外的 Feature Layers(Extra Layers)
- 这部分和 SSD 类似,但加了一点改进。
- 反卷积模块(Deconvolution Module)
- 这才是 DSSD 的灵魂!
为什么需要反卷积?
在 SSD 里,我们会发现,高层特征(深层网络输出的特征)有很好的语义信息,能分清楚“猫”和“狗”,但定位精度不够。而低层特征虽然细节丰富,但缺乏高级语义。DSSD 试图用反卷积把高层特征“放大”,这样就能结合低层的细节,同时保留高层的语义信息,让检测效果更棒。
2.2 反卷积到底在干啥?
反卷积听起来很高端,其实可以理解成“放大”操作。比如,你用手机拍了一张模糊的照片,想放大某个区域,普通的上采样(Up-sampling)可能会让图像变得更糊,而反卷积能让它变清晰一些。
技术上来说,反卷积的作用就是:
- 在空间尺寸上放大特征图,恢复一些细节信息。
- 让高层特征和低层特征进行更好的融合,提高小目标检测能力。
用 PyTorch 实现一个反卷积层很简单:
import torch.nn as nn
deconv = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2)这行代码的作用就是把 512 通道的特征图放大 2 倍,并减少通道数,让它更容易融合低层特征。
2.3 如何提升小目标检测能力?
DSSD 主要采用了 “U 形结构”,结合高层和低层信息,类似于 UNet 这种网络。具体来说:
- 先用 ResNet-101 提取高层特征。
- 然后 通过反卷积逐步恢复分辨率。
- 结合低层特征,让模型更容易检测小目标。
如果 SSD 是直线型的检测架构,那么 DSSD 就像是一条“回环路线”,把高层的特征“倒流”回来,提高小目标检测效果。
2.4 DSSD 真的比 SSD 更好吗?
实验表明,在 COCO 和 PASCAL VOC 数据集上,DSSD 确实比 SSD 更强:
- 在 COCO 上,DSSD 比 SSD 高 2-3 个 mAP。
- 在小目标检测上,DSSD 明显比 SSD 更精准。
但 DSSD 也有一个问题,就是 计算量更大,速度比 SSD 慢。所以,后来有人提出了 FPN(Feature Pyramid Network)和 RetinaNet,进一步优化目标检测任务。
3. PyTorch 实现 DSSD
现在,我们用 PyTorch 一步步实现一个简化版的 DSSD。
3.1 实现 ResNet-101 作为 Backbone
import torch
import torch.nn as nn
import torchvision.models as models
class DSSDBackbone(nn.Module):
def __init__(self):
super(DSSDBackbone, self).__init__()
resnet = models.resnet101(pretrained=True)
self.feature_extractor = nn.Sequential(*list(resnet.children())[:-2]) # 去掉最后的全连接层
def forward(self, x):
return self.feature_extractor(x)
# 测试
x = torch.randn(1, 3, 300, 300)
backbone = DSSDBackbone()
out = backbone(x)
print(out.shape) # 输出特征图大小3.2 添加 Extra Layers
class ExtraLayers(nn.Module):
def __init__(self):
super(ExtraLayers, self).__init__()
self.conv1 = nn.Conv2d(2048, 1024, kernel_size=1)
self.conv2 = nn.Conv2d(1024, 512, kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x3.3 反卷积模块
class DeconvModule(nn.Module):
def __init__(self):
super(DeconvModule, self).__init__()
self.deconv1 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.deconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
def forward(self, x):
x = self.deconv1(x)
x = self.deconv2(x)
return x3.4 预测层
class DSSD(nn.Module):
def __init__(self):
super(DSSD, self).__init__()
self.backbone = DSSDBackbone()
self.extra_layers = ExtraLayers()
self.deconv = DeconvModule()
self.classifier = nn.Conv2d(128, 21, kernel_size=3, padding=1) # 21 类(含背景)
def forward(self, x):
x = self.backbone(x)
x = self.extra_layers(x)
x = self.deconv(x)
x = self.classifier(x)
return x4. 总结
DSSD 在 SSD 的基础上增加了反卷积层,让高层特征和低层特征进行更好的融合,提升了小目标检测能力。虽然 DSSD 计算量比 SSD 更大,但它的改进思路影响了后续很多检测算法,比如 FPN、RetinaNet 等。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号