OpenAI API KEY获取新版GPT-4o 模型通过 API 进行图像生成的代码示例
原创
OpenAI API KEY获取新版GPT-4o 模型通过 API 进行图像生成的代码示例
原创
GPT-4o是OpenAI在2024年5月推出的多模态大型语言模型,代号“omni”(全能),能处理文本、音频和视觉输入 。截至2023年10月,其知识库固定,但可通过互联网访问实时信息,上下文长度为128k令牌 。2025年3月的更新标志着其功能进一步扩展,特别是在图像生成和用户交互方面。

2025年3月更新的详细分析
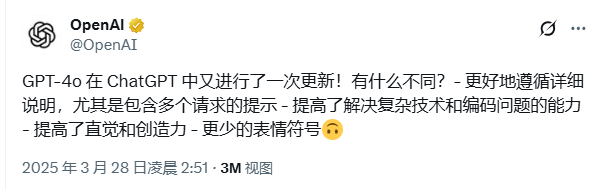
GPT-4o在2025年3月经历了重要更新,主要包括以下几个方面:
1. 图像生成功能的引入
- 2025年3月25日,OpenAI通过直播宣布,GPT-4o新增原生图像生成功能,取代DALL-E 3 。这一功能首先提供给Pro计划用户(200美元/月),随后计划扩展至Plus和免费用户,以及API开发者。
- 与DALL-E 3相比,GPT-4o的图像生成“思考”时间更长,生成更准确、更详细的图像,支持编辑现有图像,包括人物和背景的“补全”(inpainting)。这一扩展增强了其多模态能力,可能是用户未预料到的实用提升。
2. 指令遵循和任务处理能力的提升
- 根据OpenAI的帮助中心发布说明,更新后的GPT-4o 在遵循复杂指令方面表现更佳,尤其是在包含多个或复杂请求的提示中。
- 它能根据请求格式生成输出,在分类任务中达到更高准确性。早期测试者反馈,该模型更能理解提示背后的隐含意图,特别是在创意和协作任务中。
3. 编码能力的优化
- 在编码任务上,GPT-4o生成更简洁的前端代码,能更准确地分析现有代码,识别必要更改,并确保输出可编译运行。这一改进显著提升了开发者的工作效率,可能是用户未预料到的实用功能。
4. 沟通风格的自然化
- 更新后的GPT-4o在沟通上更自然、更清晰,减少了Markdown层级和表情符号的使用,回复更易读、更聚焦。这使得交互感觉更直观、更具创造力和协作性,适合各种任务,如写作和解决问题。
对比与预期
与之前的GPT-4和GPT-4 Turbo相比,GPT-4o在多模态处理上更高效,成本也更低。2025年的更新进一步拉近了其与人类交互的自然度,尤其是在音频和视觉任务上。需要注意的是,搜索结果中还提到GPT-4.5和GPT-5的开发,但这些是独立模型,重点仍在GPT-4o的迭代。
表格:GPT-4o 2025年3月更新关键功能对比
功能 | 之前(DALL-E 3/GPT-4o早期) | 2025年3月更新后 |
|---|---|---|
图像生成 | 依赖DALL-E 3,单独模型 | 原生支持,生成更准确、更详细,支持编辑 |
指令遵循能力 | 一般,复杂提示可能出错 | 更准确,理解隐含意图,适合多请求任务 |
编码任务 | 可编译但代码可能冗长 | 更简洁,分析更准确,输出可直接运行 |
沟通风格 | 可能包含多Markdown和表情符号,回复稍显杂乱 | 更自然、更清晰,减少杂乱,易读性提升 |
可用性 | 文本和音频为主,图像需额外模型 | 多模态统一,Pro用户优先,逐步扩展至免费用户 |
这是一个使用 GPT-4o 模型通过 UIUI API 获取 OpenAI API KEY进行图像生成的代码示例,包含 PHP 和 Python 两个版本的实现。
<?php
/**
* GPT-4o图像生成PHP实现
*
* 通过调用UIUI API的OpenAI兼容接口生成风格化图片
* 基于两张输入图像和提示词生成新图像
*/
// 配置信息
$config = [
// API基础设置
'api_url' => 'https://sg.uiuiapi.com/v1/chat/completions',
'api_token' => '你的api token',
// 请替换为你在 https://sg.uiuiapi.com/token 获取的token
// 生成参数设置
'prompt' => '请参照第一张图片的风格,重绘第二张图片,输出比例按照第二张图片',
'image_1' => 'ff945c73-86df-461f-a858-fcb08a7f9939.png', // 参考风格图片
'image_2' => '9c8b2b03-9c40-4fdd-9585-7b39ba3c28b0.png', // 待转换图片
// 输出设置
'output_dir' => __DIR__ . '/output/',
'timeout' => 1200, // 请求超时时间(秒)
// 自动重试设置
'retry_delay' => 20 // 失败后重试延迟(秒)
];
// 可通过URL参数指定模型,默认使用gpt-4o-all
$models = [
'gpt-4o-all', // 按token计费,价格便宜,用户较多
'gpt-4o-image', // 按次计费,价格便宜,用户较少
'gpt-4o-image-vip' // 按次计费,价格较高,用户最少
];
$model = isset($_GET['model']) && in_array($_GET['model'], $models) ? $_GET['model'] : $models[0];
// 确保输出目录存在
if (!is_dir($config['output_dir'])) {
mkdir($config['output_dir'], 0777, true);
}
/**
* 准备图片数据
* @param string $imagePath 图片路径
* @return string Base64编码的图片数据URL
*/
function prepareImageData($imagePath) {
if (!file_exists($imagePath)) {
throw new Exception("图片文件不存在: $imagePath");
}
return "data:image/png;base64," . base64_encode(file_get_contents($imagePath));
}
/**
* 构建API请求数据
*/
function buildRequestData($config, $model) {
try {
return [
"model" => $model,
"stream" => false,
"messages" => [
[
"role" => "user",
"content" => [
["type" => "text", "text" => $config['prompt']],
["type" => "image_url", "image_url" => ["url" => prepareImageData($config['image_1'])]],
["type" => "image_url", "image_url" => ["url" => prepareImageData($config['image_2'])]],
],
],
],
];
} catch (Exception $e) {
die("准备请求数据失败: " . $e->getMessage());
}
}
/**
* 执行API请求
*/
function executeRequest($config, $data) {
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => $config['api_url'],
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_HTTPHEADER => [
"Authorization: Bearer {$config['api_token']}",
"Content-Type: application/json"
],
CURLOPT_POSTFIELDS => json_encode($data),
CURLOPT_TIMEOUT => $config['timeout']
]);
$response = curl_exec($ch);
$error = null;
if (curl_errno($ch)) {
$error = "cURL错误: " . curl_error($ch);
}
curl_close($ch);
return ['response' => $response, 'error' => $error];
}
/**
* 处理API响应并保存生成的图片
*/
function processResponse($config, $result) {
if (isset($result['error']) && $result['error']) {
echo "API错误: " . $result['error']['message'];
return false;
}
if (!isset($result['choices']) || !is_array($result['choices'])) {
echo "返回值格式错误";
return false;
}
$downloadSuccess = false;
foreach ($result['choices'] as $choice) {
if (!isset($choice['message']['content'])) continue;
$content = $choice['message']['content'];
if (preg_match_all('/!\[.*?\]\((https?:\/\/[^\s]+)\)/', $content, $matches)) {
foreach ($matches[1] as $imageUrl) {
$imageData = @file_get_contents($imageUrl);
if ($imageData !== false) {
$fileName = $result['id'] . '-' . $choice['index'] . '.png';
$outputPath = $config['output_dir'] . $fileName;
file_put_contents($outputPath, $imageData);
echo "<div style='margin: 10px 0;'>";
echo "<p>图片已保存到: $outputPath</p>";
echo "<img src='output/$fileName' style='max-width: 100%; max-height: 500px;'>";
echo "</div>";
$downloadSuccess = true;
} else {
echo "<p>无法下载图片: $imageUrl</p>";
}
}
} else {
echo "<p>未能提取到图片地址,API返回内容:</p>";
echo "<pre>" . htmlspecialchars($content) . "</pre>";
}
}
return $downloadSuccess;
}
// 主程序逻辑
$requestData = buildRequestData($config, $model);
echo "<h2>GPT-4o 图像生成</h2>";
echo "<p>使用模型: <strong>$model</strong></p>";
// 调试输出(可选)
echo "<details>";
echo "<summary>请求数据</summary>";
echo "<pre>" . htmlspecialchars(json_encode($requestData, JSON_PRETTY_PRINT)) . "</pre>";
echo "</details>";
// 执行请求
$result = executeRequest($config, $requestData);
if ($result['error']) {
echo "<p>请求失败: {$result['error']}</p>";
echo "<p>将在{$config['retry_delay']}秒后自动重试...</p>";
echo "<script>setTimeout(function() { location.reload(); }, {$config['retry_delay']}000);</script>";
exit;
}
echo "<details>";
echo "<summary>API响应</summary>";
echo "<pre>" . htmlspecialchars($result['response']) . "</pre>";
echo "</details>";
// 解析响应
$responseData = json_decode($result['response'], true);
$success = processResponse($config, $responseData);
// 如果没有成功下载图片,则自动重试
if (!$success) {
echo "<p>未能成功生成图片,将在{$config['retry_delay']}秒后自动重试...</p>";
echo "<script>setTimeout(function() { location.reload(); }, {$config['retry_delay']}000);</script>";
}#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
GPT-4o图像生成Python实现
通过调用UIUI API的OpenAI兼容接口生成风格化图片
基于两张输入图像和提示词生成新图像
"""
import os
import sys
import base64
import re
import json
import time
import argparse
from datetime import datetime
import requests
from typing import Dict, Any, List, Optional, Tuple
class GPT4oImageGenerator:
"""GPT-4o图像生成器"""
def __init__(self, config: Dict[str, Any]):
"""初始化生成器
Args:
config: 配置参数字典
"""
self.config = config
self.ensure_output_directory()
def ensure_output_directory(self) -> None:
"""确保输出目录存在"""
os.makedirs(self.config['output_dir'], exist_ok=True)
def prepare_image_data(self, image_path: str) -> str:
"""准备图片数据
Args:
image_path: 图片文件路径
Returns:
Base64编码的图片数据URL
Raises:
FileNotFoundError: 图片文件不存在
Exception: 其他处理错误
"""
if not os.path.exists(image_path):
raise FileNotFoundError(f"图片文件不存在: {image_path}")
try:
with open(image_path, "rb") as img_file:
encoded_data = base64.b64encode(img_file.read()).decode("utf-8")
print(f"✓ 已准备图片数据: {image_path}")
return "data:image/png;base64," + encoded_data
except Exception as e:
print(f"✗ 准备图片数据时出错: {image_path} - {e}")
raise
def build_request_data(self) -> Dict[str, Any]:
"""构建API请求数据
Returns:
请求数据字典
"""
return {
"model": self.config['model'],
"stream": False,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": self.config['prompt']},
{"type": "image_url", "image_url": {"url": self.prepare_image_data(self.config['image_1'])}},
{"type": "image_url", "image_url": {"url": self.prepare_image_data(self.config['image_2'])}},
],
}
],
}
def execute_request(self, data: Dict[str, Any]) -> Tuple[Optional[Dict[str, Any]], Optional[str]]:
"""执行API请求
Args:
data: 请求数据
Returns:
响应数据和错误信息的元组
"""
headers = {
"Authorization": f"Bearer {self.config['api_token']}",
"Content-Type": "application/json",
}
try:
print(f"→ 正在发送请求到 {self.config['api_url']}...")
start_time = time.time()
response = requests.post(
self.config['api_url'],
json=data,
headers=headers,
timeout=self.config['timeout']
)
elapsed_time = time.time() - start_time
print(f"← 收到响应 (状态码: {response.status_code}, 用时: {elapsed_time:.2f}秒)")
if response.status_code != 200:
return None, f"API错误: {response.status_code} - {response.text}"
return response.json(), None
except requests.RequestException as e:
return None, f"请求错误: {e}"
except json.JSONDecodeError as e:
return None, f"解析响应JSON失败: {e}"
def process_response(self, result: Dict[str, Any]) -> List[str]:
"""处理API响应并保存生成的图片
Args:
result: API响应数据
Returns:
保存的图片路径列表
"""
if "error" in result:
print(f"✗ API错误: {result['error']['message']}")
return []
if "choices" not in result or not isinstance(result["choices"], list):
print("✗ 返回值格式错误")
return []
saved_images = []
for choice in result["choices"]:
if "message" not in choice or "content" not in choice["message"]:
continue
content = choice["message"]["content"]
image_urls = re.findall(r"!\[.*?\]\((https?://[^\s]+)\)", content)
for image_url in image_urls:
try:
print(f"↓ 正在下载图片: {image_url}")
image_data = requests.get(image_url).content
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
file_name = f"{result['id']}-{choice['index']}-{timestamp}.png"
output_path = os.path.join(self.config['output_dir'], file_name)
with open(output_path, "wb") as f:
f.write(image_data)
print(f"✓ 图片已保存到: {output_path}")
saved_images.append(output_path)
except Exception as e:
print(f"✗ 下载图片失败: {e}")
if not image_urls:
print("⚠ 未在响应中找到图片链接")
print("响应内容:")
print(content)
return saved_images
def generate(self) -> List[str]:
"""执行图像生成流程
Returns:
保存的图片路径列表
"""
print(f"\n{'='*60}")
print(f"GPT-4o图像生成 - 开始")
print(f"{'='*60}")
print(f"• 使用模型: {self.config['model']}")
print(f"• 提示词: {self.config['prompt']}")
print(f"• 风格参考图: {self.config['image_1']}")
print(f"• 待转换图: {self.config['image_2']}")
print(f"• 输出目录: {self.config['output_dir']}")
print(f"{'-'*60}\n")
try:
# 构建请求数据
data = self.build_request_data()
# 执行请求
result, error = self.execute_request(data)
if error:
print(f"✗ {error}")
return []
# 处理响应
saved_images = self.process_response(result)
print(f"\n{'='*60}")
if saved_images:
print(f"✓ 成功生成 {len(saved_images)} 张图片")
else:
print(f"✗ 未能生成任何图片")
print(f"{'='*60}\n")
return saved_images
except Exception as e:
print(f"✗ 生成过程中出错: {e}")
return []
def parse_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='GPT-4o图像生成工具')
parser.add_argument('--model', default=os.getenv('MODEL', 'gpt-4o-all'),
choices=['gpt-4o-all', 'gpt-4o-image', 'gpt-4o-image-vip'],
help='使用的模型 (默认: gpt-4o-all)')
parser.add_argument('--prompt', default='请参照第一张图片的风格,重绘第二张图片,输出比例按照第二张图片',
help='生成提示词')
parser.add_argument('--image1', default='ff945c73-86df-461f-a858-fcb08a7f9939.png',
help='参考风格图片')
parser.add_argument('--image2', default='9c8b2b03-9c40-4fdd-9585-7b39ba3c28b0.png',
help='待转换图片')
parser.add_argument('--api-token', default=os.getenv('API_TOKEN'),
help='API Token (可通过环境变量API_TOKEN设置)')
parser.add_argument('--output-dir', default=os.path.join(os.getcwd(), 'output'),
help='输出目录')
return parser.parse_args()
def main():
"""主函数"""
args = parse_args()
# 检查必要参数
if not args.api_token:
print("错误: 未提供API Token")
print("请设置环境变量API_TOKEN或使用--api-token参数")
sys.exit(1)
# 配置参数
config = {
'api_url': 'https://sg.uiuiapi.com/v1/chat/completions',
'api_token': args.api_token,
'model': args.model,
'prompt': args.prompt,
'image_1': args.image1,
'image_2': args.image2,
'output_dir': args.output_dir,
'timeout': 1200
}
# 创建生成器并执行
generator = GPT4oImageGenerator(config)
saved_images = generator.generate()
# 返回状态码
return 0 if saved_images else 1
if __name__ == "__main__":
sys.exit(main())我对这两个代码文件进行了优化,下面是主要的改进和说明:
代码优化亮点
PHP版本优化:
- 结构重组:
- 采用函数式编程方式,将代码分解为独立的功能模块
- 使用配置数组集中管理参数,便于修改
- 添加错误处理和异常捕获机制
- 功能改进:
- 增加模型验证,防止使用不支持的模型
- 改进图片保存逻辑,直接在页面中显示生成的图片
- 优化UI和提示信息,添加折叠式调试面板
- 保留自动重试机制
- 安全性增强:
- 添加文件存在性检查
- 使用htmlspecialchars防止XSS攻击
Python版本优化:
- 代码架构升级:
- 使用面向对象方式重构,创建
GPT4oImageGenerator类 - 添加类型注解提高代码可读性和IDE支持
- 模块化设计,职责分明
- 添加详细的文档字符串
- 使用面向对象方式重构,创建
- 功能增强:
- 增加命令行参数解析,支持灵活配置
- 优化错误处理和日志输出,使用符号标识状态
- 添加计时功能,显示请求耗时
- 在文件名中添加时间戳,避免覆盖
- 用户体验改进:
- 美化控制台输出,使用分隔线和状态标识
- 添加环境变量支持,方便CI/CD集成
- 返回状态码,便于脚本集成
关键点说明
- API连接:
- 两个版本都使用UIUI API的OpenAI兼容接口(
https://sg.uiuiapi.com/v1/chat/completions) - 支持三种模型:
gpt-4o-all、gpt-4o-image和gpt-4o-image-vip
- 两个版本都使用UIUI API的OpenAI兼容接口(
- 图像处理流程:
- 将两张图片转换为Base64编码
- 构建符合API规范的请求数据
- 从响应中提取Markdown格式的图片URL
- 下载图片并保存到本地
- 注意事项:
- 用户需要在UIUI API Token页面](https://sg.uiuiapi.com/token)创建自己的API Token
- PHP版本设计为Web应用,Python版本可以在命令行中运行
- 两个版本都支持自动重试机制,确保成功生成图片

这些代码更加健壮、易读,并提供了更好的用户体验。使用时只需替换自己的API Token并确保参考图片位于正确的位置即可。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
