[MYSQL] 新搭建个备库 却报错Last_SQL_Errno: 1396
原创
[MYSQL] 新搭建个备库 却报错Last_SQL_Errno: 1396
原创
背景
在mysql 5.7.x环境使用Mysqldump搭建一个从库, 然后主库修改个密码, 从库就报错如下:

分析
这个报错挺简单的, 就是从库回放ALTER USER 'u1'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9'的时候报错 1396, MySQL error code MY-001396 (ER_CANNOT_USER): Operation %s failed for %.256s
那么为啥会执行alter user失败呢?
我们知道alter修改密码时,除了修改mysql.user中的密码外, 还会刷新密码到缓存(类似flush privileges),
故推测: 如果缓存不存在这个用户,则会报错1396
那么我们新建的从库是没有这个账号的, 所以报错是很正常. 这就引入了两个新的思考:
- 如果从库之前就存在这么个账号,是不是就应该不会报错了呢?
- 为啥之前搭建从库后也修改过业务密码, 为啥没遇到这个问题呢?
我们还是先复现下问题, 然后再来看这2个思考.
问题复现与解决方法
问题复现
复现这个问题还是比较简单的, 我们只需要搭建2个5.7的环境, 然后在主库新建个业务账号, 并把数据导入到从库, 从库做change master. 主库修改业务账号密码, 从库查看复制状态
# 初始化2个实例
略
# 主库创建测试账号
mysql -h127.0.0.1 -P3308 -p123456 -e 'create user u1@"%" identified by "123456";'
# 主库导出数据
mysqldump -h127.0.0.1 -P3308 -p123456 --all-databases --single-transaction --master-data=2 > t20250410.sql
# 从库导入数据
mysql -h127.0.0.1 -uroot -P3406 -p123456 < t20250410.sql
# 搭建主从复制关系
mysql -h127.0.0.1 -uroot -P3406 -p123456 -e "change master to master_host='127.0.0.1',master_port=3308,master_user='repl',master_password='123456';start slave;"
# 主库修改密码
mysql -h127.0.0.1 -P3308 -p123456 -e 'alter user u1@"%" identified by "123456"'
# 从库查看复制状态
mysql -h127.0.0.1 -uroot -P3406 -p123456 -e "show slave status\G"于是我们就得到了文章开头的报错
(root@127.0.0.1) [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: repl
Master_Port: 3308
Connect_Retry: 60
Master_Log_File: m3308.001443
Read_Master_Log_Pos: 616
Relay_Log_File: relay.000002
Relay_Log_Pos: 316
Relay_Master_Log_File: m3308.001443
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1396
Last_Error: Error 'Operation ALTER USER failed for 'u1'@'%'' on query. Default database: ''. Query: 'ALTER USER 'u1'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9''
Skip_Counter: 0
Exec_Master_Log_Pos: 382
Relay_Log_Space: 747
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1396
Last_SQL_Error: Error 'Operation ALTER USER failed for 'u1'@'%'' on query. Default database: ''. Query: 'ALTER USER 'u1'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9''
Replicate_Ignore_Server_Ids:
Master_Server_Id: 414003308
Master_UUID: 6d650f1f-ba4e-11ed-99ab-000c2980c11e
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp: 250410 11:07:38
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 6d650f1f-ba4e-11ed-99ab-000c2980c11e:647128
Executed_Gtid_Set: 6d650f1f-ba4e-11ed-99ab-000c2980c11e:1-647127
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)问题修复
既然我们分析出来是由于从库缓存中没得u1@%账号, 那么我们可以使用flush privileges刷新下从库缓存即可.
-- 从库刷新缓存
flush privileges;
-- 从库再次启动复制进程.
start slave;
-- 从库再次查看复制状态
show slave status\G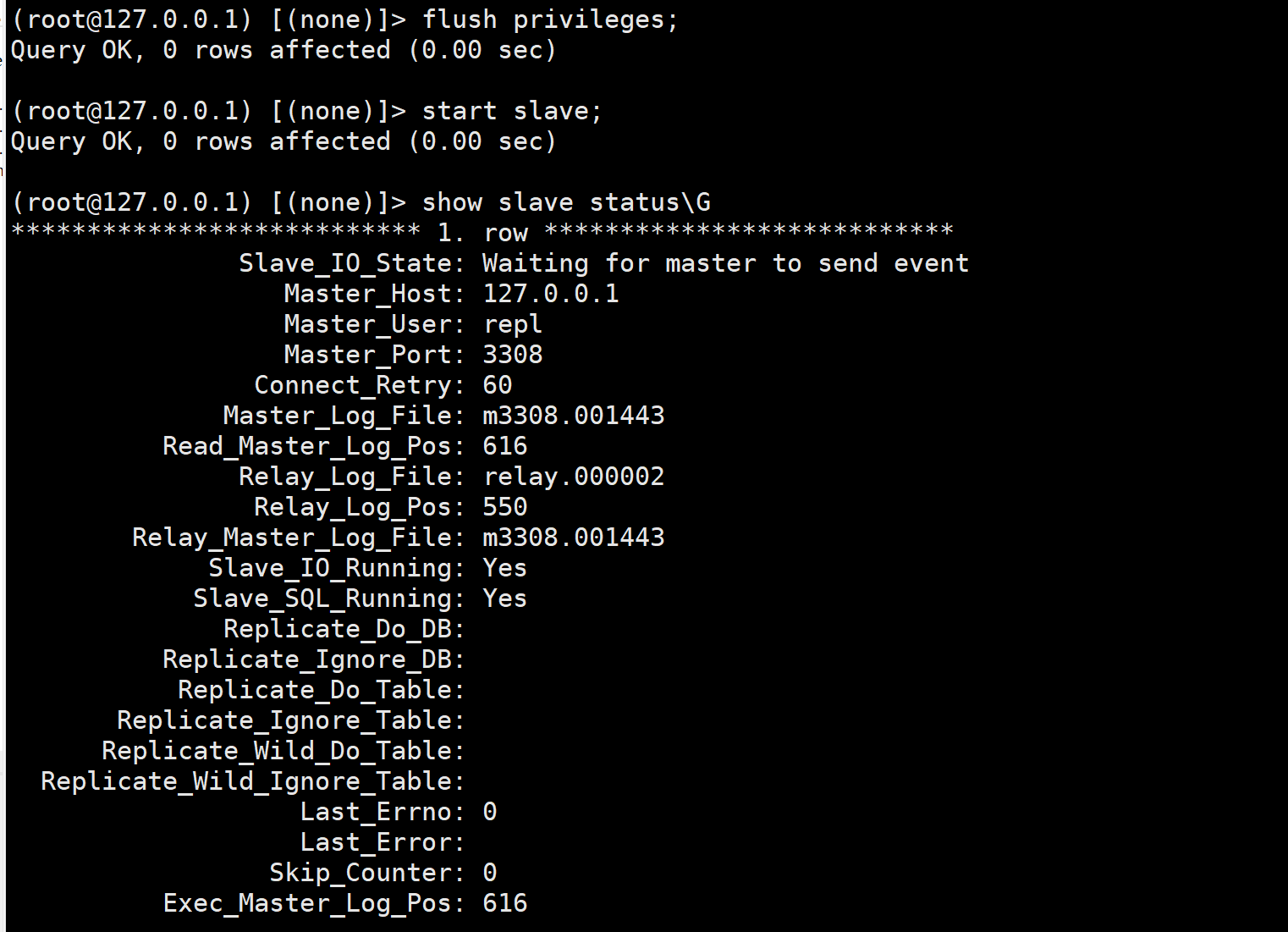
确实修复了这个问题, 也印证了我们的猜想.
思考1的验证
如果我们在从库提前创建好该用户, 然后再导入数据,并搭建主从关系是否就不会出现Last_SQL_Errno: 1396呢?
上面验证完之后, 我们从库就已经有了u1@%账号, 也就是我现在重新导入数据, 并配置主从关系, 看是否会报错即可验证.
# 从库环境清理
mysql -h127.0.0.1 -uroot -P3406 -p123456 -e "stop slave;reset slave all;reset master;"
# 从库导入数据
mysql -h127.0.0.1 -uroot -P3406 -p123456 < t20250410.sql
# 搭建主从复制关系
mysql -h127.0.0.1 -uroot -P3406 -p123456 -e "change master to master_host='127.0.0.1',master_port=3308,master_user='repl',master_password='123456',MASTER_LOG_FILE='m3308.001443', MASTER_LOG_POS=382;start slave;"主库不再需要修改密码了, 因为之前已经修改过了, 从库现在会从该事务(gtid)开始复制的. 狠一点,走位点也是可以的
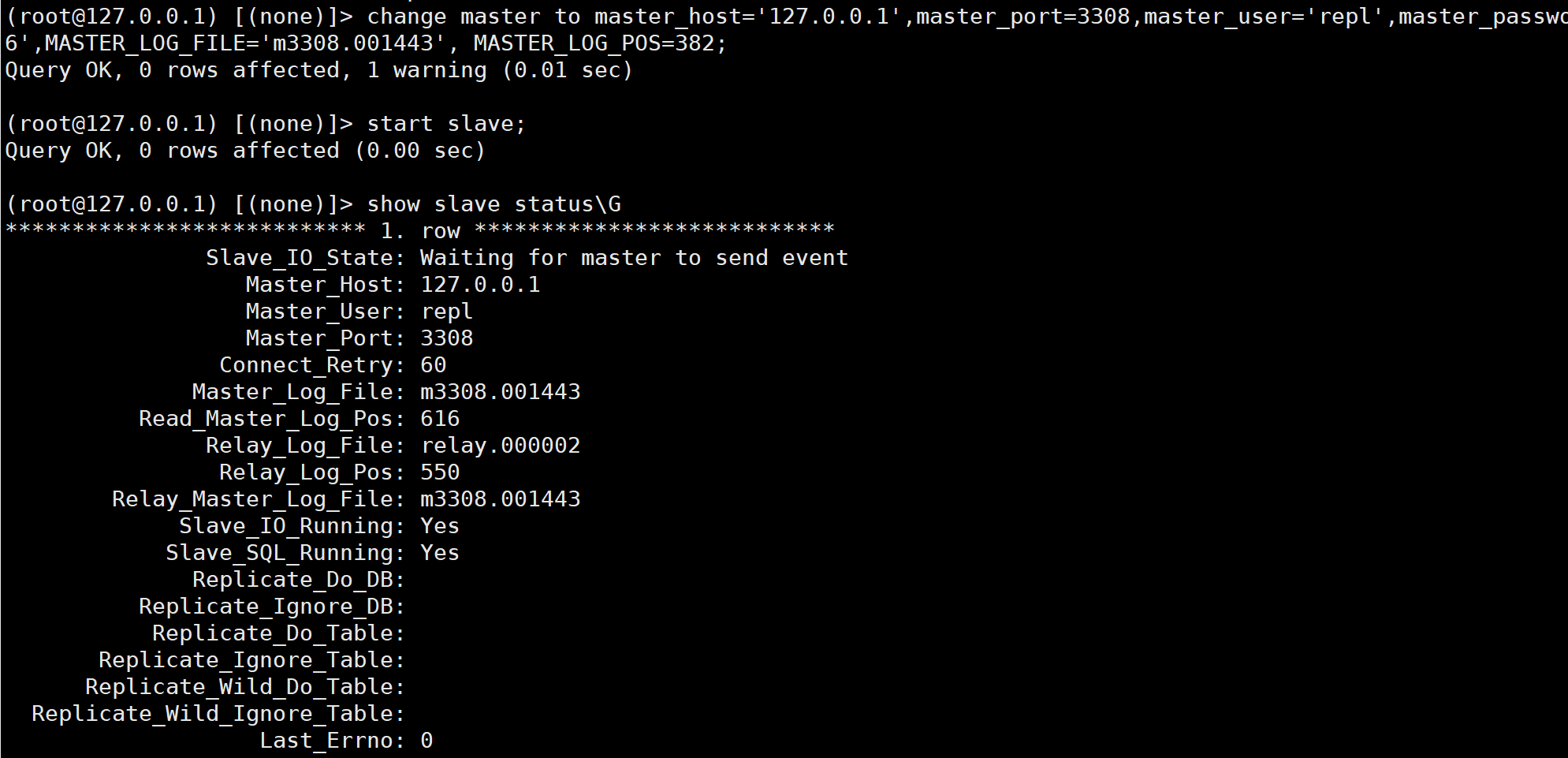
我们发现主从关系是主从的. 也再次印证了我们刚才的分析.
思考2的验证
刚才我们是使用flush privileges解决的, 那么重启数据库应该也是可以解决的, 毕竟启动的时候会自动将mysql.user刷新到缓存.
之前在内存修改用户密码的时候其实就是修改的缓存, 而非innodb buffer pool中的mysql.user表信息. 也可以佐证前面的猜想.
环境清理:
# 从库清理业务用户并重启
mysql -h127.0.0.1 -uroot -P3406 -p123456 -e "drop user u1@'%'"
systemctl restart mysqld_3406
# 从库环境清理
mysql -h127.0.0.1 -uroot -P3406 -p123456 -e "stop slave;reset slave all;reset master;"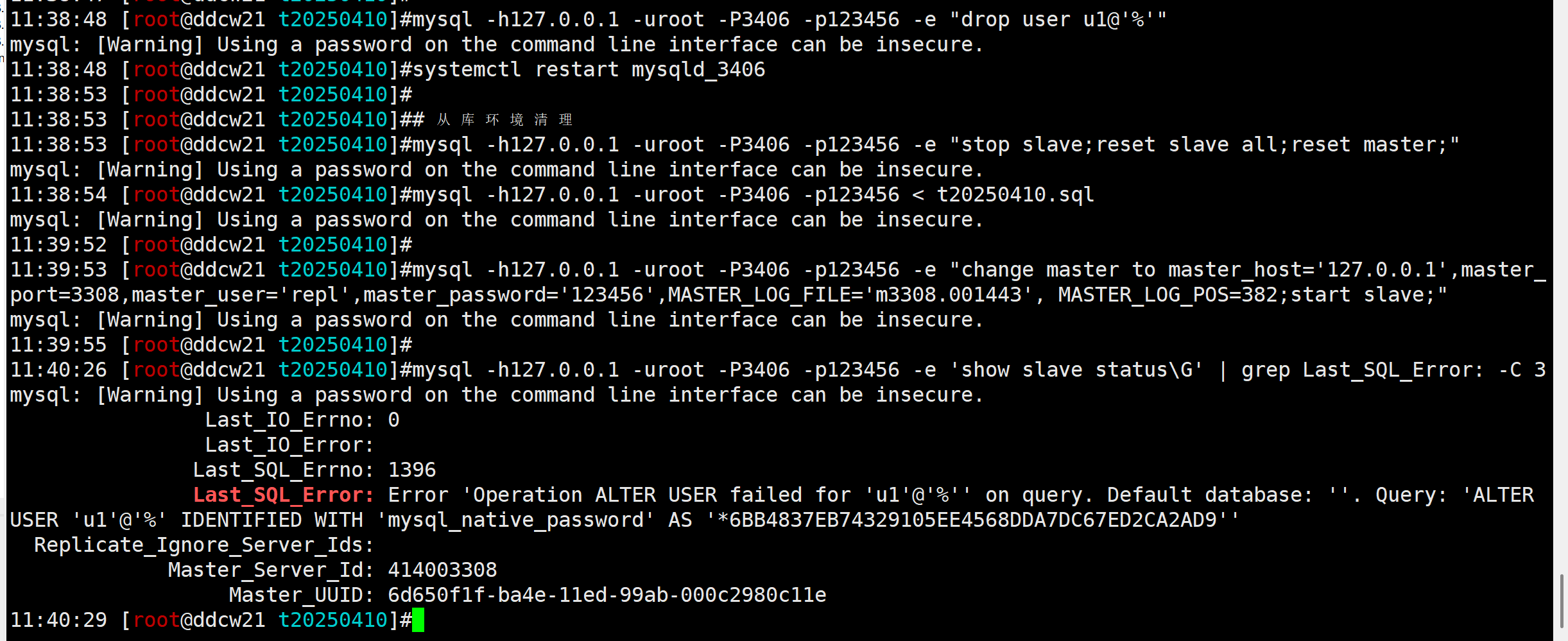
然后我们重启下数据库
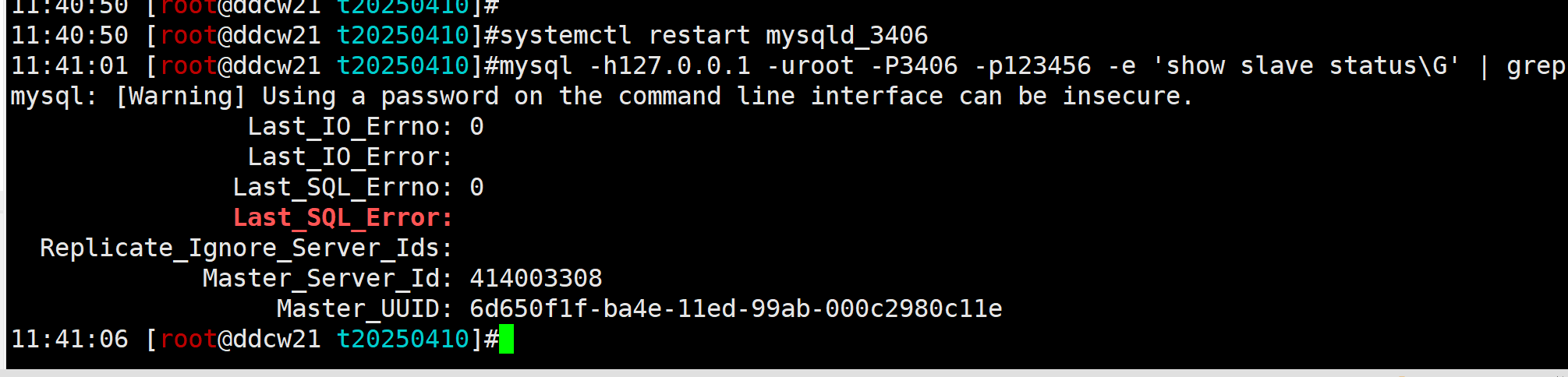
发现主从确实修复了. 再次印证前面的猜想.
总结
解决方案:
- 从库执行flush privileges
- 重启从库
建议是搭建完从库之后重启下从库.
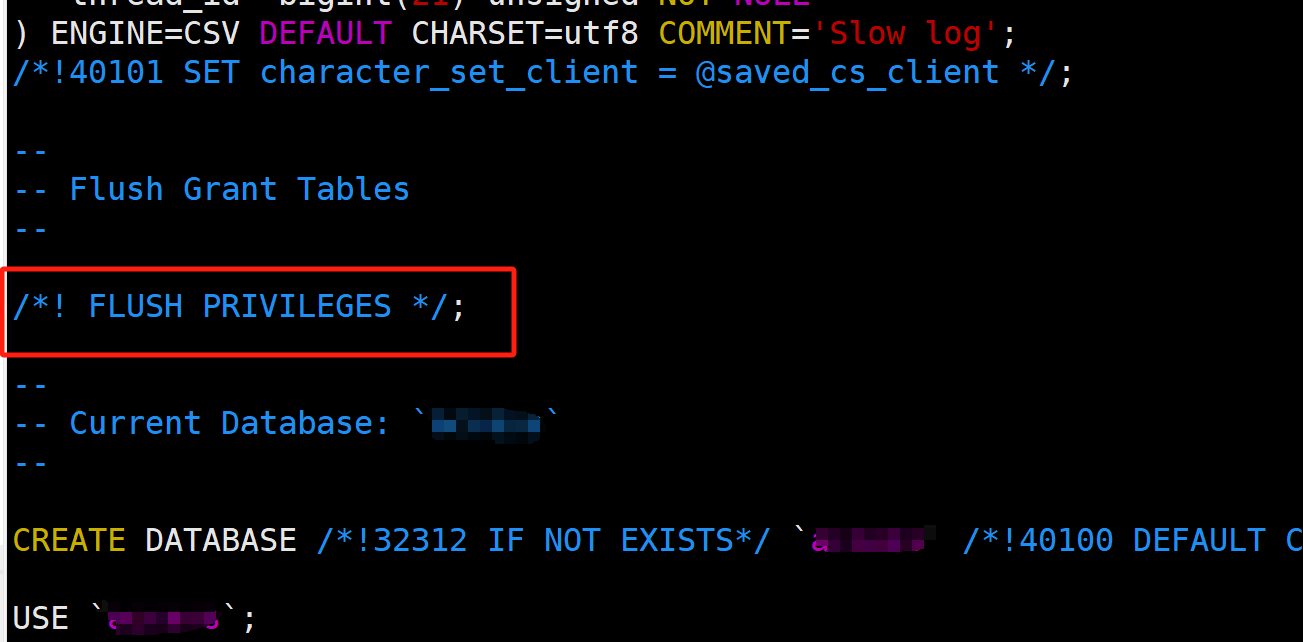
这么坑的问题,mysqldump是否有啥参数可以提前避免呢?
别说, 还真有: --flush-privileges
--flush-privileges Emit a FLUSH PRIVILEGES statement after dumping the mysql
database. This option should be used any time the dump
contains the mysql database and any other database that
depends on the data in the mysql database for proper
restore加上这个参数之后, mysqldump导完mysql库之后就有个/*! FLUSH PRIVILEGES */;
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
