得物自研DGraph4.0推荐核心引擎升级之路
原创
得物自研DGraph4.0推荐核心引擎升级之路
原创
用户10346649
发布于 2025-04-17 09:40:38
发布于 2025-04-17 09:40:38
一、前言
DGraph是得物自主研发的新一代推荐系统核心引擎,基于C++语言构建,自2021年启动以来,经过持续迭代已全面支撑得物社区内容分发、电商交易等核心业务的推荐场景。DGraph在推荐链路中主要承担数据海选和粗排序功能,为上层精排提供高质量候选集。
核心技术特性:
- 索引层 - 支持KV(键值)、KVV(键-多值)、INVERT(倒排)、DENSE-KV(稠密键值)等。索引存储支持磁盘 & 内存两种模式,在预发等延迟压力低场景,通过磁盘索引使用低规格服务器提供基本服务。线上场景使用内存索引保证服务稳定性,提供毫秒级延迟响应。索引更新支持双buff热更新【内存足够】、服务下线滚动更新【内存受限】、Kafka流式数据实时更新等三种模式。
- 查询层 - 支持向量检索IVF & HNSW、键值(KV)查询、倒排检索、X2I关联查询、图查询。对外提供JavaSDK & C++ SDK。
系统依赖架构:
- 索引全生命周期管理由得物索引平台DIP统一管控。
- 服务发现基于ZooKeeper(zk)。
- 集群资源调度基于得物容器平台,目前已经支持HPA。
服务规模:
- 目前在线100+集群,2024年双11在线突破了100W qps。
本文主要介绍DGraph系统在2024年的一些重要改进点。主要包括两次架构调整 + 性能优化 + 用户体验提升方面的一些工作。
二、架构升级
2.1 垂直拆分业务集群支持
在2023年前,DGraph系统始终采用单一集群架构提供服务。该架构模式在平台发展初期展现出良好的经济性和运维便利性,但随着业务规模扩张,单集群架构在系统层面逐渐显露出三重刚性约束:
- 存储容量瓶颈 - 单节点内存上限导致数据规模受限;
- 网络带宽瓶颈 - 单物理机Pod共享10Gbps带宽,实际可用带宽持续承压,推荐引擎业务中部分核心集群200余张数据表(单表需20分钟级更新)的实时处理需求已遭遇传输瓶颈;
- 计算能力瓶颈 - 单实例最大64核的算力天花板,难以支撑复杂策略的快速迭代,核心场景响应时效与算法复杂度形成显著冲突;
- 稳定性 - 大规格集群对于容器调度平台不友好,在扩容、集群故障、集群发布时耗时较久;基于得物平台推荐数据量增长和算法迭代需求,我们实施业务垂直拆分的多集群架构升级,通过资源解耦与负载分离,有效突破了单节点资源约束,为复杂算法策略的部署预留出充足的技术演进空间。
系统改进点是在DGraph中增加了访问了其他DGraph集群 & FeatureStore特征集群的能力(图1)。为了成本考虑,我们复用了之前系统的传输协议flatbuffers,服务发现仍基于ZooKeeper。
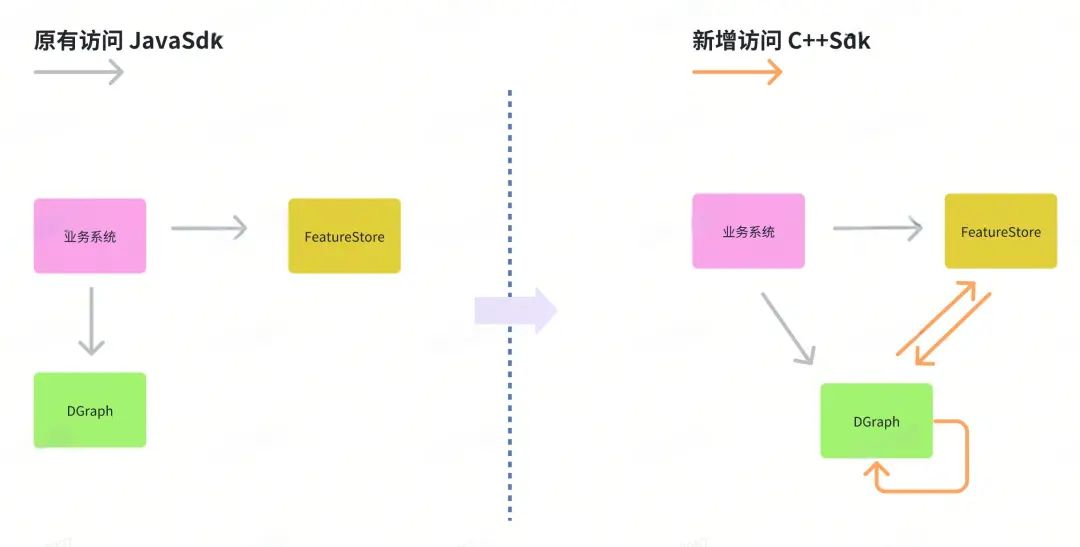
图 1 DGraph 访问架构改进
改造的难点在图化集群!
目前推荐业务的核心场景都进行了图化改造,图化查询是把多路召回、打散、融合、粗排等策略打包到一个DAG图中一次发送到DGraph,DGraph的算子调度模块根据DAG的描述查询索引数据 & 执行算子最终把结果返回给业务系统,但这些DAG图规模都很大,部分业务DAG图涉及300+算子,因此如何在垂直拆分业务中把这些DAG图拆分到不同的DGraph集群中是一个非常复杂的问题,我们主要做了三方面改进:
- DAG管理 - 集群分主集群和从集群【多个】,DAG图部署在存在主集群中,DIP平台会分析DAG的拓步结构并把属于从集群的部分复制出来分发给从集群,为了保证DAG的一致性,只允许从主集群修改DAG图;
- 集群划分 - 通常按召回划分,比如Embedding召回、X2I召回、实验召回可以分别部署在不同的集群,另外也可以把粗排等算力需求大的部分单独放在一个集群,具体根据业务场景调整;
- 性能优化 - 核心表多个集群存放,减少主集群和从集群间数据交换量。
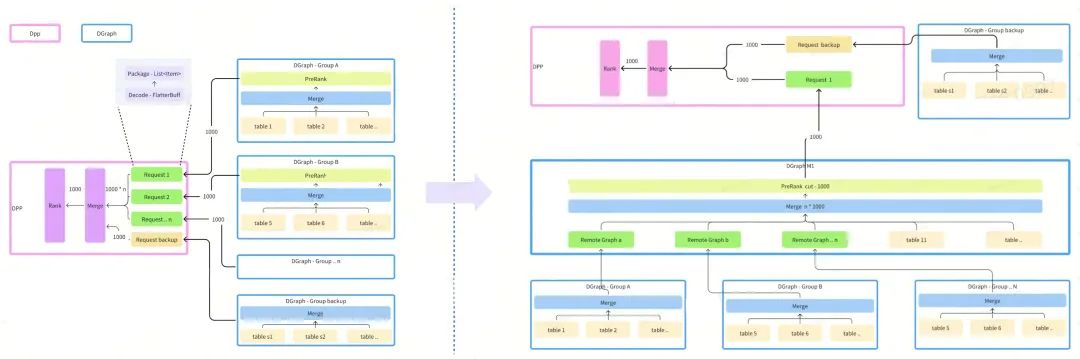
图 2 DGraph业务垂直拆分集群
2.2 分布式能力支持
垂直拆分集群,虽然把推荐N路召回分散到了M个集群,但是每个集群中每个表依然是全量。随着得物业务的发展,扩类目、扩商品,部分业务单表的数据量级已经接近单集群的存储瓶颈。因此需要DGraph中引入数据水平拆分的能力。
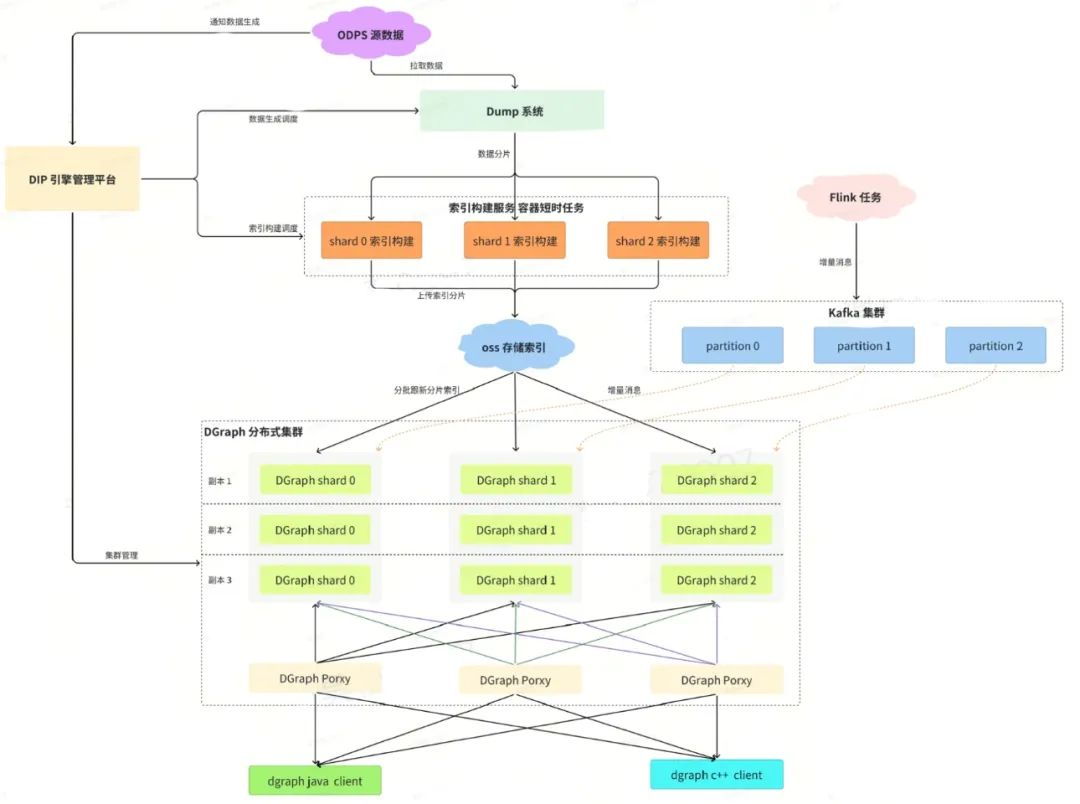
图 3 DGraph 分布式集群架构图
在DGraph分布式架构设计中,重点考虑了部署成本优化与业务迁移工作量:
- 分布式集群采用【分片数2】×【双活节点2】×【数据副本数2】的最小拓扑结构,理论上需要8台物理节点保障滚动更新与异常容灾时的稳定性。针对CPU负载较轻的场景,为避免独立Proxy集群带来的额外资源开销,DGraph将Proxy模块和DGraph引擎以对称架构部署到所有节点,通过本地优先的智能路由策略(本地节点轮询优先于跨节点访问)实现资源利用率与访问效率的平衡;
- 在业务兼容性方面,基础查询接口(KV检索、倒排索引、X2I关联查询)保持完全兼容以降低迁移成本,而DAG图查询需业务侧在查询链路中明确指定Proxy聚合算子的位置以发挥分布式性能优势。数据链路层面,通过DIP平台实现索引无缝适配,支持DataWorks原有任务无需改造即可对接分布式集群,同时增量处理模块内置分片过滤机制,可直接复用现有Flink实时计算集群进行数据同步。
三、性能优化
3.1 算子执行框架优化
在DGraph中,基于DGraph DAG图(参考图9)的一次查询就是图查询,内部简称graphSearch。在一个DAG图中,每个节点都是一个算子(简称Op),算子通过有向边连接其他算子,构成一个有向无环图,算子执行引擎按DAG描述的关系选择串行或者并发执行所有算子,通过组合不同算子DAG图能在推荐场景中灵活高效的完成各种复杂任务。
在实际应用场景中受DAG图规模 & 超时时间(需要控制在100ms内)限制,算子执行框架的效率非常重要。在最开始的版本中我们使用过Omp & 单队列线程池,集群在CPU负载低于30%时表现尚可,但在集群CPU负载超过30%后,rt99表现糟糕。在降本增效的背景下,我们重点对算子执行框架进行了优化,引入了更高效的线程池 & 减少了调度过程中锁的使用。优化后目前DGraph 在CPU压力超过60%依然可以提供稳定服务。
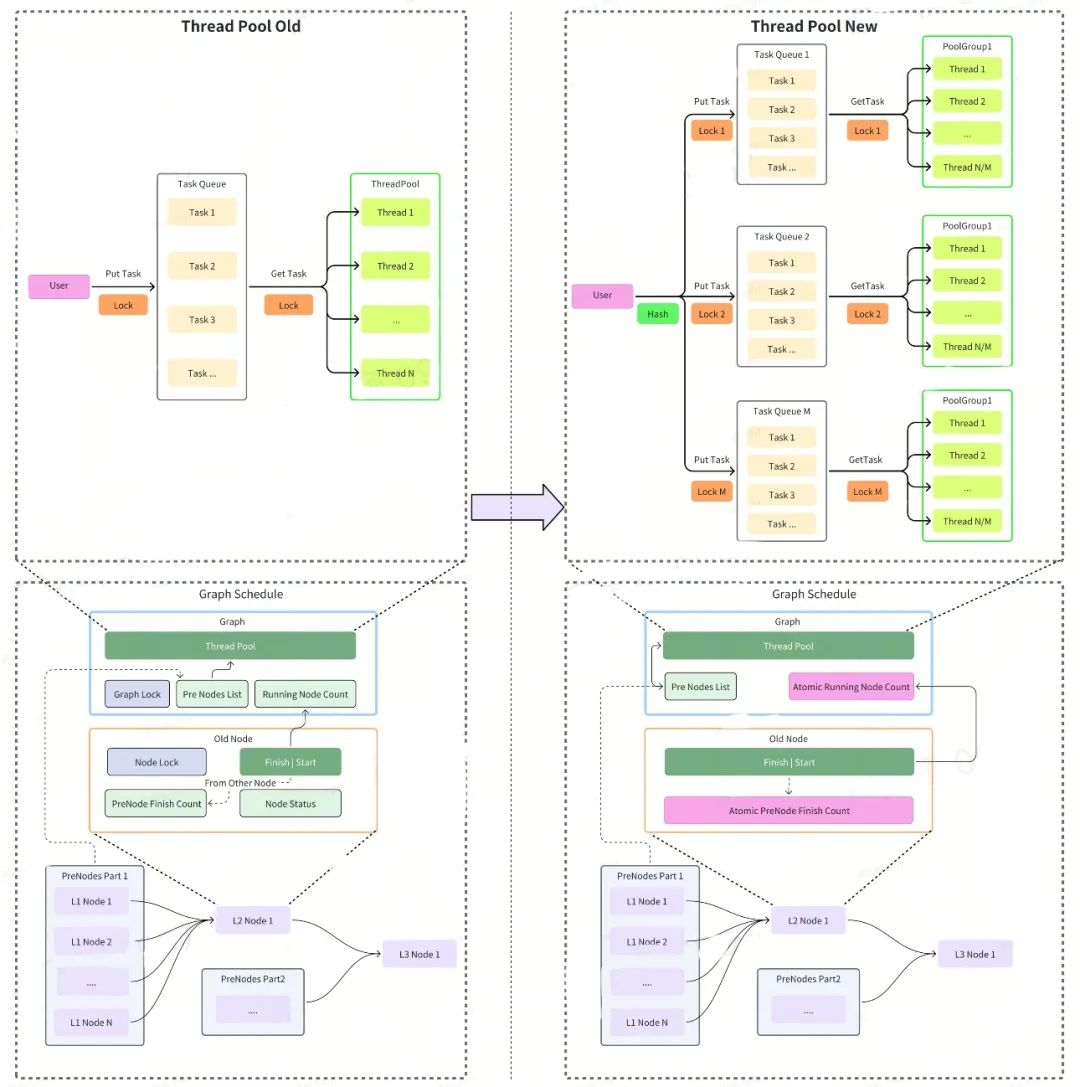
图4 DGraph算子执行框架优化
线程池优化:将原1:N 的线程池-队列架构调整为M:N 分组模式。具体实现为将N个工作线程划分为M个执行组(每组N/M线程),各组配备独立任务队列。任务提交采用轮询分发机制至对应组队列,通过资源分区有效降低线程调度时的锁竞争强度。
调度器优化:在DAG调度过程中存在两个典型多写场景
- 前驱算子节点完成时需并行更新后继节点标记;
- DAG全局任务计数器归零判断。原方案通过全局锁(Graph锁+Node锁)保障原子性,但在高负载场景引发显著锁竞争开销,影响线程执行效率。经分析发现这两个状态变更操作符合特定并发模式:所有写操作均为单调增减操作,因此可将锁机制替换为原子变量操作。针对状态标记和任务计数场景,分别采用原子变量的FetchAdd和FetchSub指令即可实现无锁化同步,无需引入CAS机制即满足线程安全要求。
3.2 传输协议编码解码优化
优化JavaSDK - DGraph数据传输过程:在DGraph部分场景,由于请求引擎返回的数据量很大,解码编码耗时占整个请求20%以上。分析已有的解码编码模块,引擎在编码阶段会把待传输数据编码到一个FlatBuffer中,然后通过rpc协议发送到业务侧的JavaSDK,sdk 解码FlatBuffer封装成List<map> 返回给业务代码,业务代码再把List<map> 转化成 List<业务Object>。过程中没有并发 & sdk侧多了一层冗余转换。
优化方案如下:
- 串行编码调整为根据文档数量动态调整编码块数量。各子编码块可以并发编码解码,加快编码&解码速度,提升整体传输性能;
- sdk 侧由 Doc -> Map -> JavaObject 的转化方式调整为 Doc -> JavaObject,减少解码端算力开销。
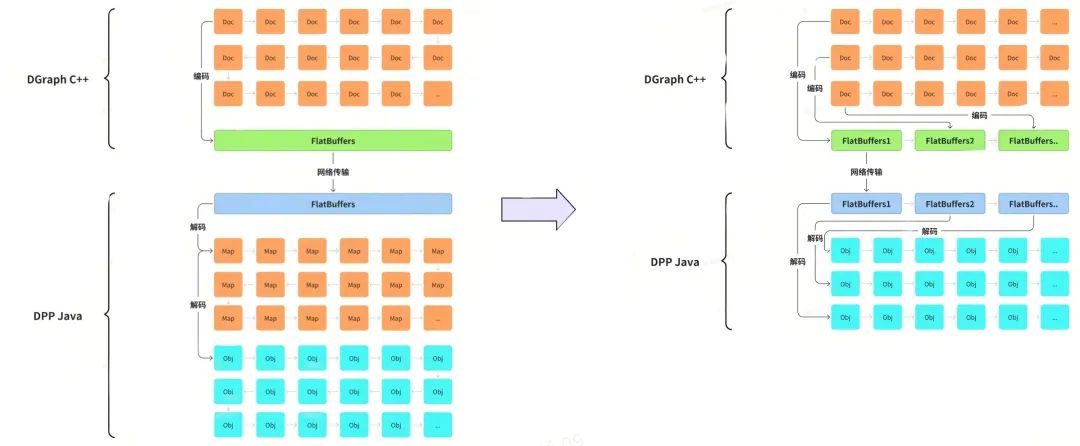
图5 DGraph 传输编码解码过程优化
四、用户体验优化
4.1 DAG图调试功能优化
目前我们已经把DGraph DAG图查询的调试能力集成到DIP平台。其原理是:DGraph 的算子基类实现了执行结果输出,由于算子的中间结果数据量极大,当调试模块发现调试标志后会先把当前算子的中间结果写入日志中,数据按TraceID + DAGID+ NodeID 组织,最终这些数据被采集到SLS日志平台。
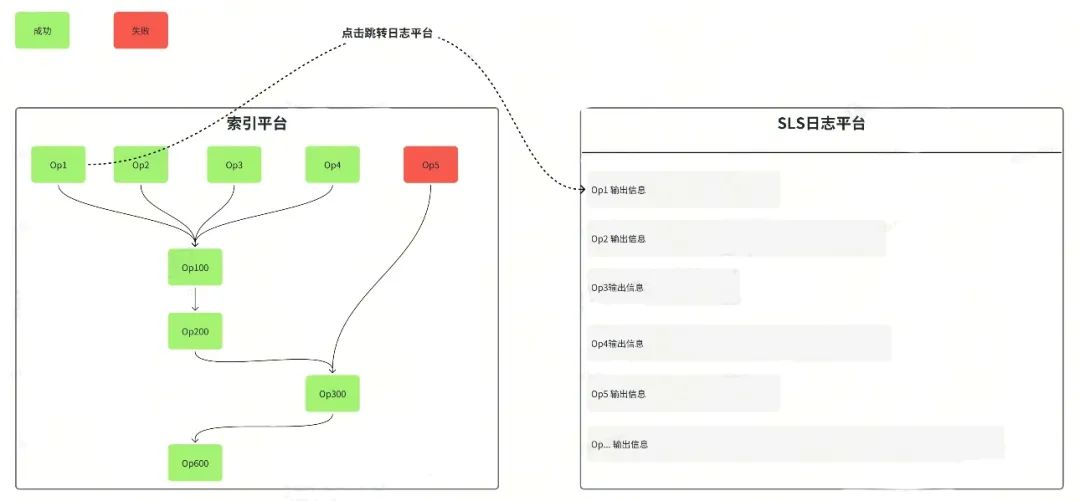
图6 DGraph DAG图查询调试
从DIP平台调试DAG图请求,首先通过DGraph JavaSDK的调试入口拿到DAG图请求json,填入DIP平台图请求调试入口,发起请求。索引平台会根据请求体自动关联DAG图并结合最终执行结果通过页面的方式展示。DIP平台拿到结果后,在DAG图中成功的算子节点标记为绿色,失败的节点标记为红色(图6)。点击任意节点可以跳转到日志平台查看该节点的中间结果输出。可用于分析DAG图执行过程中的各种细节,提升业务排查业务问题效率。
4.2 DAG图支持TimeLine分析
基于Chrome浏览器中的TimeLine构建,用于DGraph DAG图查询时算子性能分析优化工作。TimeLine功能集成在算子基类中,启动时会记录每个算子的启动时间、等待时间、完成时间、执行线程pid等信息,这些信息首先输出到日志,然后被SLS日志平台采集。用户可以使用查询时的TraceID在日志平台搜索相关的TimeLine信息。
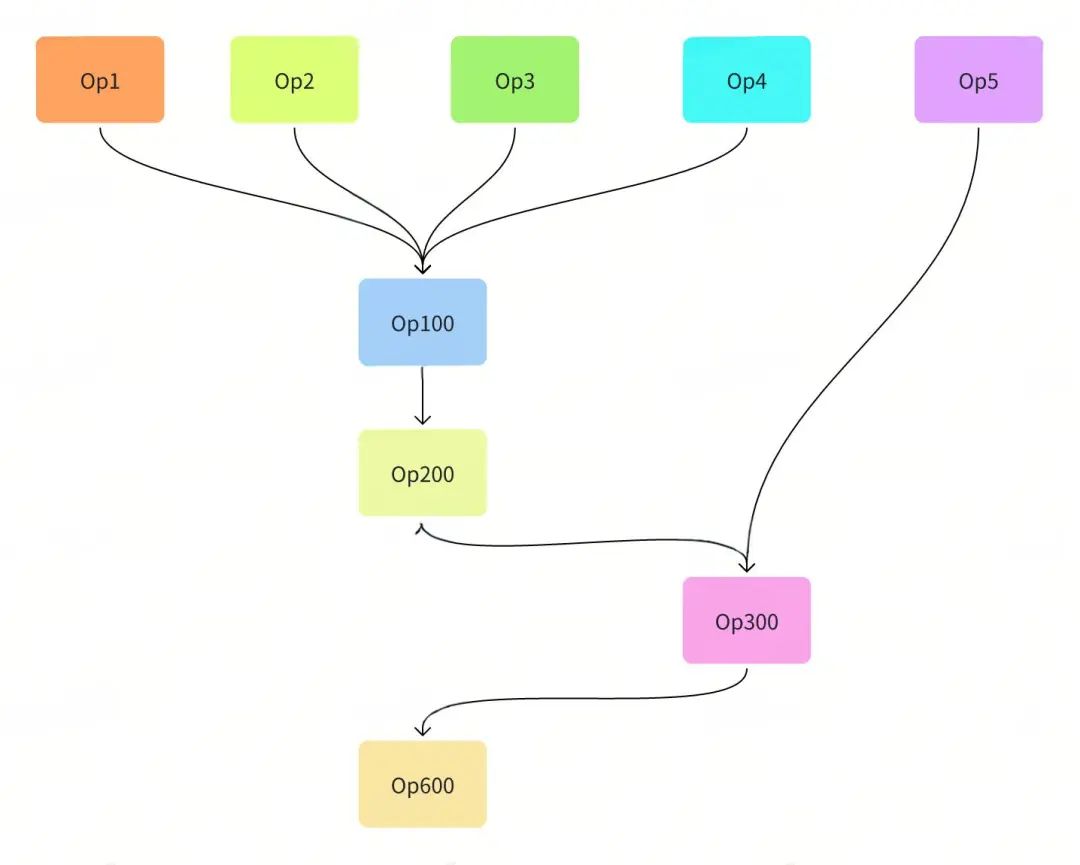
图7 DGraph DAG图例子
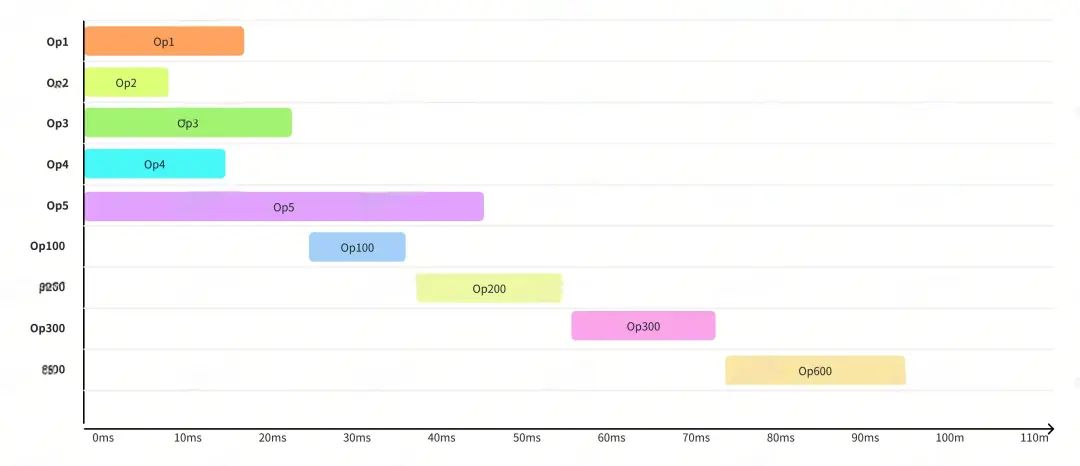
图8 使用浏览器查看DGraph DAG图 TimeLine
当我们拿到请求的TimeLine信息后,通过浏览器加载可以通过图形化的方式分析DAG执行过程中耗时分布。图7是一个DAG 请求,它有9个算子节点,图8是它的一次请求的TimeLine。通过分析这些算子的耗时,可以帮助我们定位当前DAG图查询的瓶颈点在哪里,从而精准去解决性能方面的问题。
4.3 DAG图支持动态子图
在DAG图召回中,业务的召回通常都带有一些固定模式,比如一个业务在一个DAG图召回中有N路召回,每一路召回都是:① 查找数据;② 关联可推池;③ 打散; 它们之间的区别可能仅仅是召回数据表名不同或者传递的参数不同。通常我们业务调整或者算法实验调整只需要增加或者减少部分召回,原有模式下这些操作需要去新增或者修改DAG图,加上算法实验很多,业务维护DAG图的成本会非常高。
DAG动态子图的引入就是为了解决这类问题,首先我们在DAG图中配置一个模板子图,它仅仅描述一个行为模式,代表会涉及几个算子,算子之间的关系如何,实际的参数以及召回路的数量则由业务方在发起请求时动态决定。子图的执行和主图的执行共用同一套调度框架,共享运行时资源以降低运行开销。
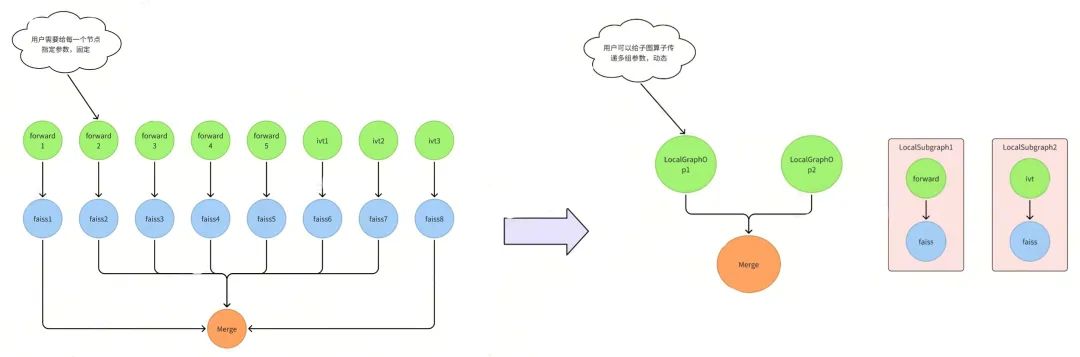
图9 DGraph 子图
图9是一个DAG召回使用DAG子图后的变化,它有8路召回,一个Merge节点,这些召回分为两类,一类是基于KV表(ForwardSearch)触发的向量召回,另外一类是基于KVV表(IvtSearch)触发的向量召回。引入DAG子图后,在主图中节点数量由17个降为3个。
五、展望未来
过去四年,DGraph聚焦于实现得物推荐引擎体系从0到1的突破,重点完成了核心系统架构搭建、算法策略支持及业务迭代空间拓展,取得多项基础性成果。基于2024年底的用户调研反馈结合DGraph当前的发展,后续将重点提升产品易用性、开发与运维效能及用户体验,同时在系统稳定性、可扩展架构和平台化建设方面持续深化。
文 / 寻风
关注得物技术,每周一、三更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号