Firecrawl MCP 实战 | 在 Cursor 中实现网页爬取、结构分析与信息提取
原创
Firecrawl MCP 实战 | 在 Cursor 中实现网页爬取、结构分析与信息提取
原创
前言
最近热衷于找一些好玩的MCP,集成在cursor中,给大模型外挂许多有趣的功能,在开发的代码的同时,在IDE中可以获得更多的乐趣。例如:
- 什么是MCP?本地如何开发MCP Server
- MCP实战 | cursor 如何一句话操作 gitHub 代码库
- cursor 如何调用 MCP server 实现天气查询
- 自定义 MCP Server,在 cursor 中连接本地 MySQL 实现了统计分析
- Pages MCP Server + cursor,一句话完成旅游出行规划
- MCP实战 | cursor 中如何掌握股市动态
- Playwright MCP Server 使用指南:让 Cursor 拥有浏览器自动化能力
今天要分享的 mcp server:Firecrawl,为各种LLM客户端(如Cursor和Claude)提供强大的网页抓取功能。
配置
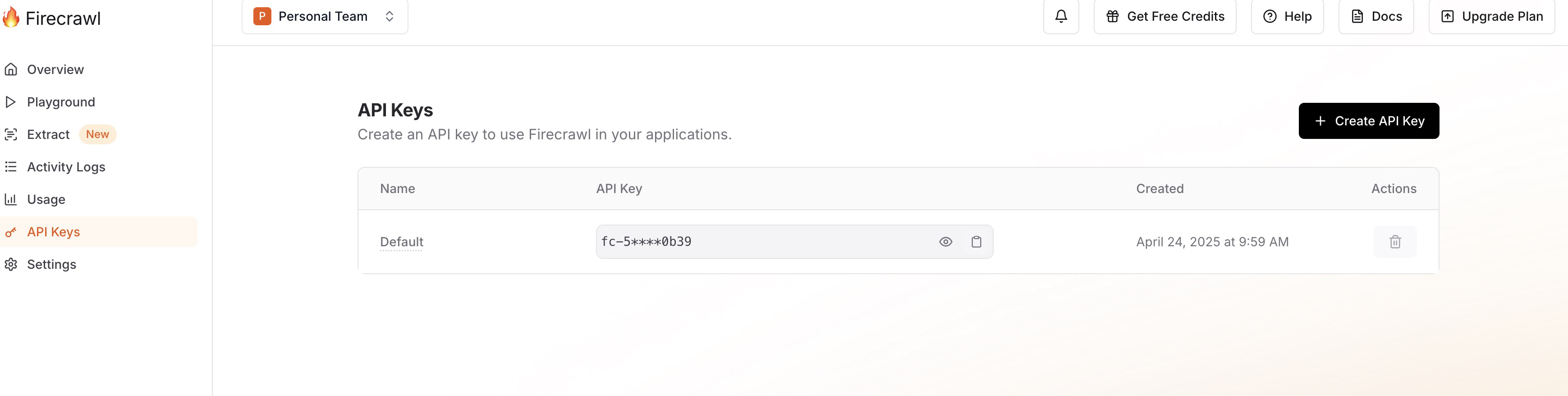
首先我们要获取 Firecrawl-API-KEY,登录网站找到 API keys,然后复制。
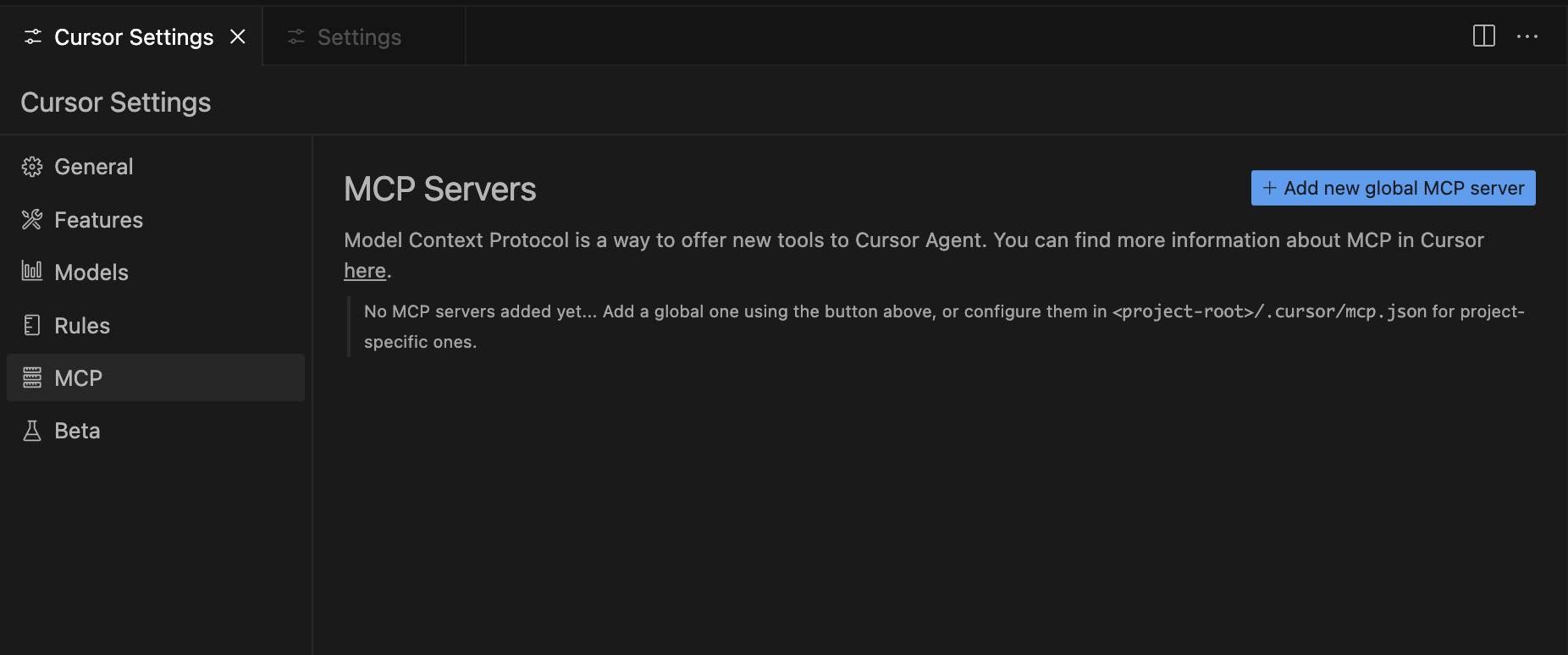
在 Cursor 的 Cursor Settings 中找到 MCP。
点击右侧上方的 Add new global MCP server 按钮,便自动打开 .local 目录下的 mcp.json 文件,替换 Firecrawl-API-KEY, 并 将 mcp server 的json信息粘贴进去.
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}在MCP页面就可以看到配置的 mcp server 信息。
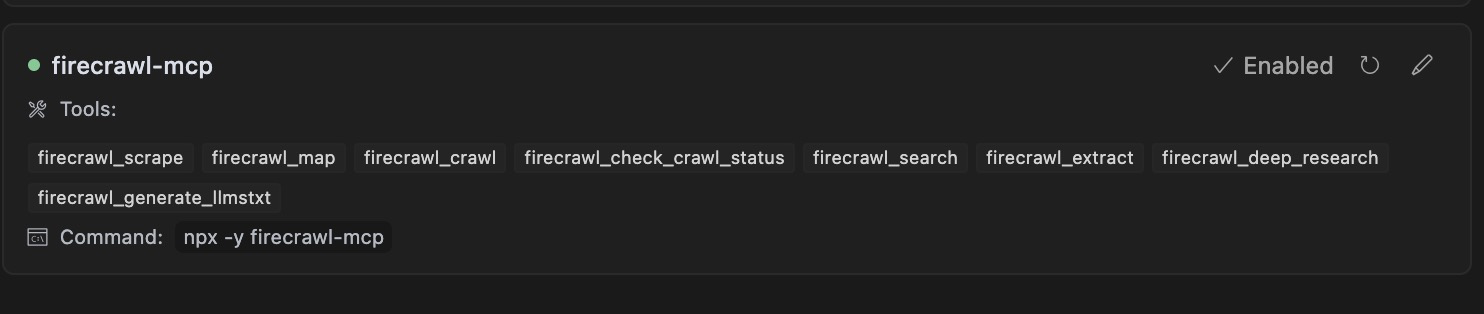
可以看到 Firecrawl 的一些tool,列表如下:
- firecrawl_scrape:抓取指定网页的主要内容,支持提取文本、HTML、Markdown 等格式。
- firecrawl_map:生成指定网站的结构地图,可用于了解页面间链接关系,常用于网站结构分析。
- firecrawl_crawl:执行多层级网页爬取任务,可发现并递归抓取内部链接,实现深度爬取。
- firecrawl_check_crawl_status:查询当前爬取任务的状态,包括进度、成功/失败记录等。
- firecrawl_search:支持在搜索引擎上发起查询请求,并抓取结果页面内容。
- firecrawl_extract:使用大模型能力从页面中抽取结构化数据,如产品信息、联系人、文章摘要等。
- firecrawl_deep_research:针对某一主题执行深度搜索与多页面整合分析,适用于研究与情报收集。
- firecrawl_generate_llmstxt:将爬取内容自动转换为适合 LLM 使用的 prompt 格式文本(如:摘要、指令式文本等),便于 AI 模型消费。
应用
正常情况下,我们在输入一个url的时候,大模型其实可以不调用 mcp server 就可以帮助我们抓取信息。
1. 提取 url
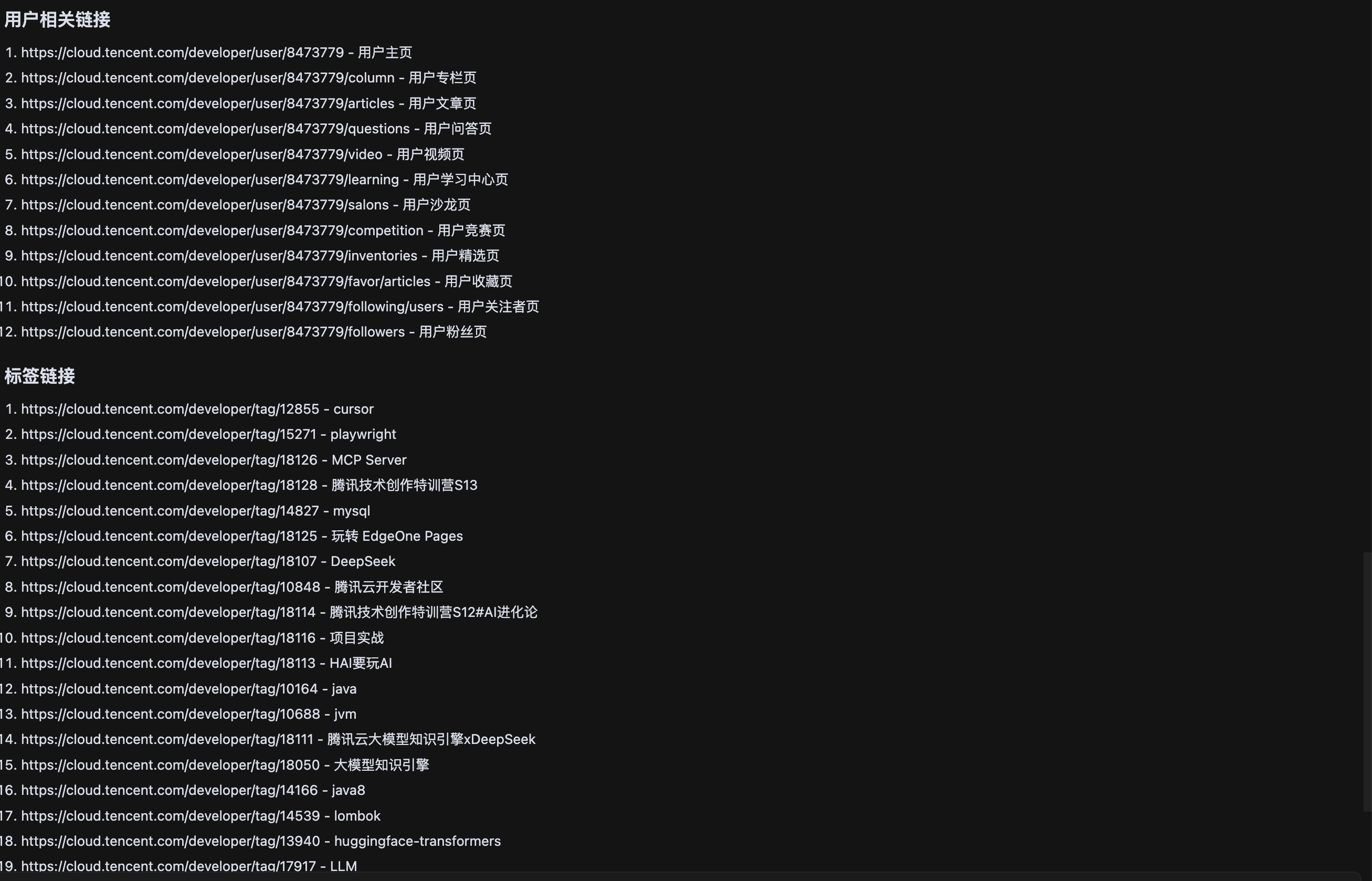
但是却无法提取网页中包含的url,而 Firecrawl 可以帮助我们提取其中包含的url。

并且将不同的 url 进行分类整理。
2. 深度爬取
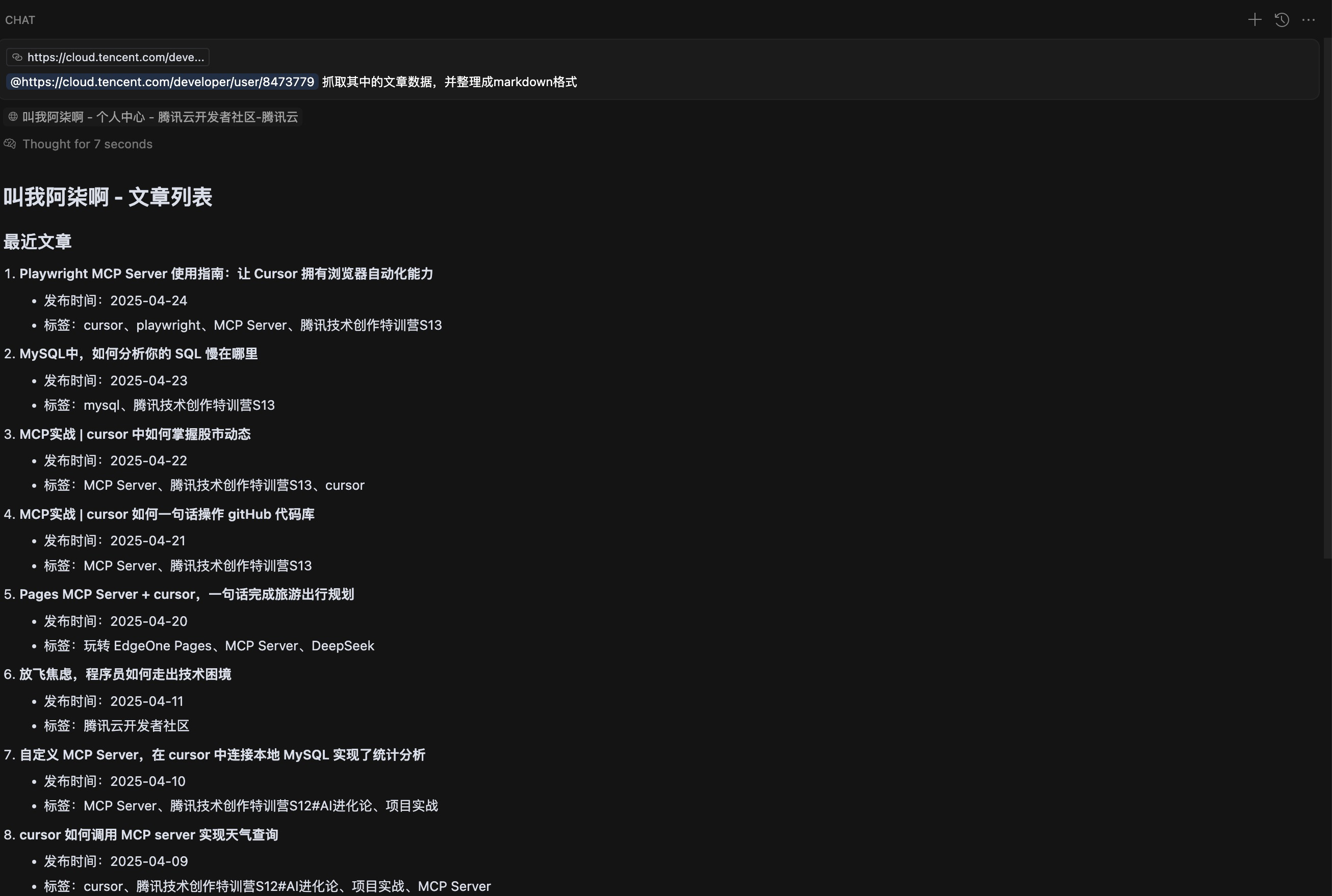
初次之外,Firecrawl 还能进行深度爬取,例如我们打开专栏页面。
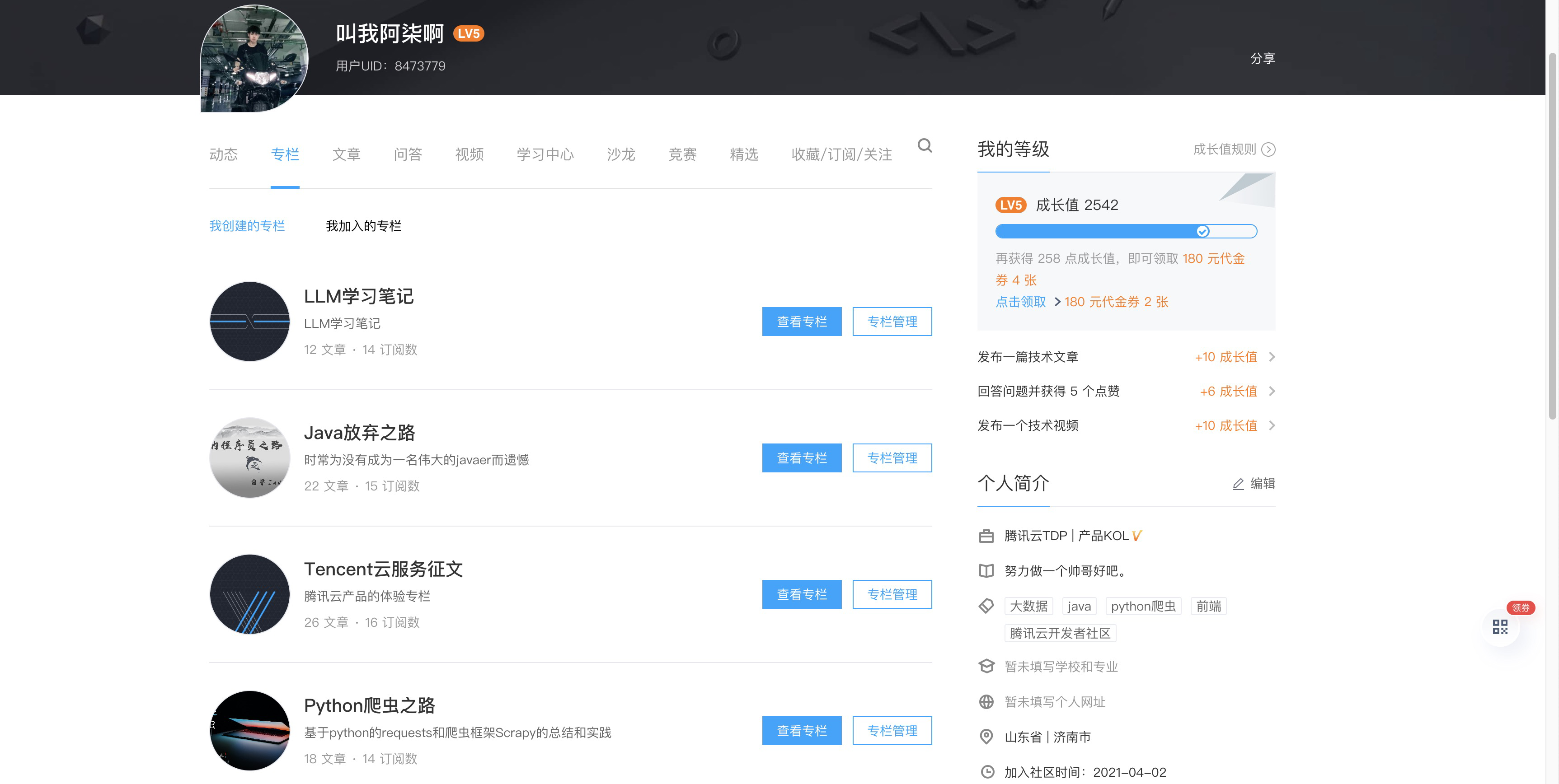
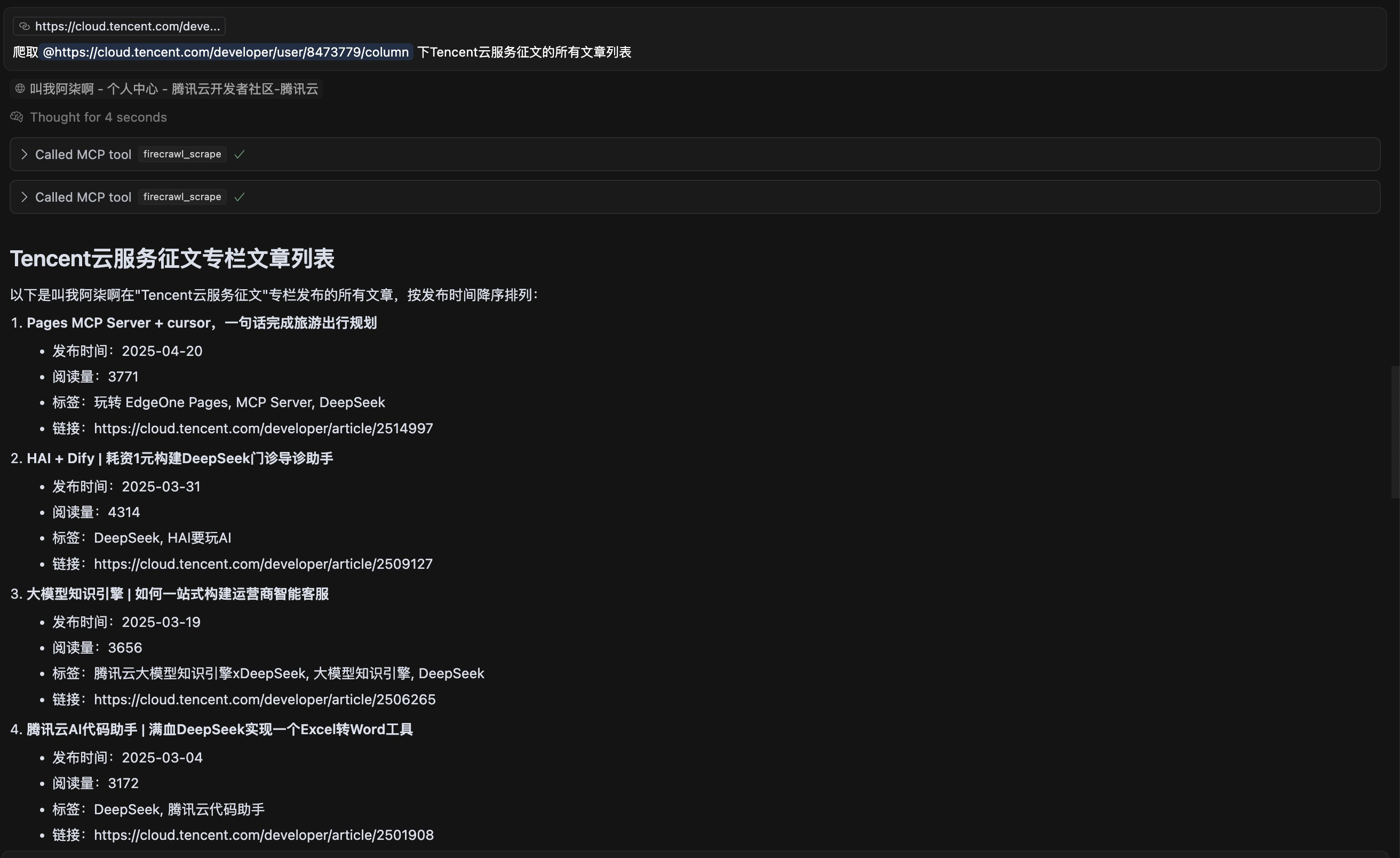
如果我们想要获取某个专栏中的文章列表,第一步需要从这个页面点击进入专栏,第二步爬取网页内容。 我们可以通过提示词直接调用 Firecrawl 实现这两步。
爬取@https://cloud.tencent.com/developer/user/8473779/column 下Tencent云服务征文的所有文章列表输入提示词,调用了两次 firecrawl_scrape 就完成了进入专栏、爬取专栏文章数据的工作。
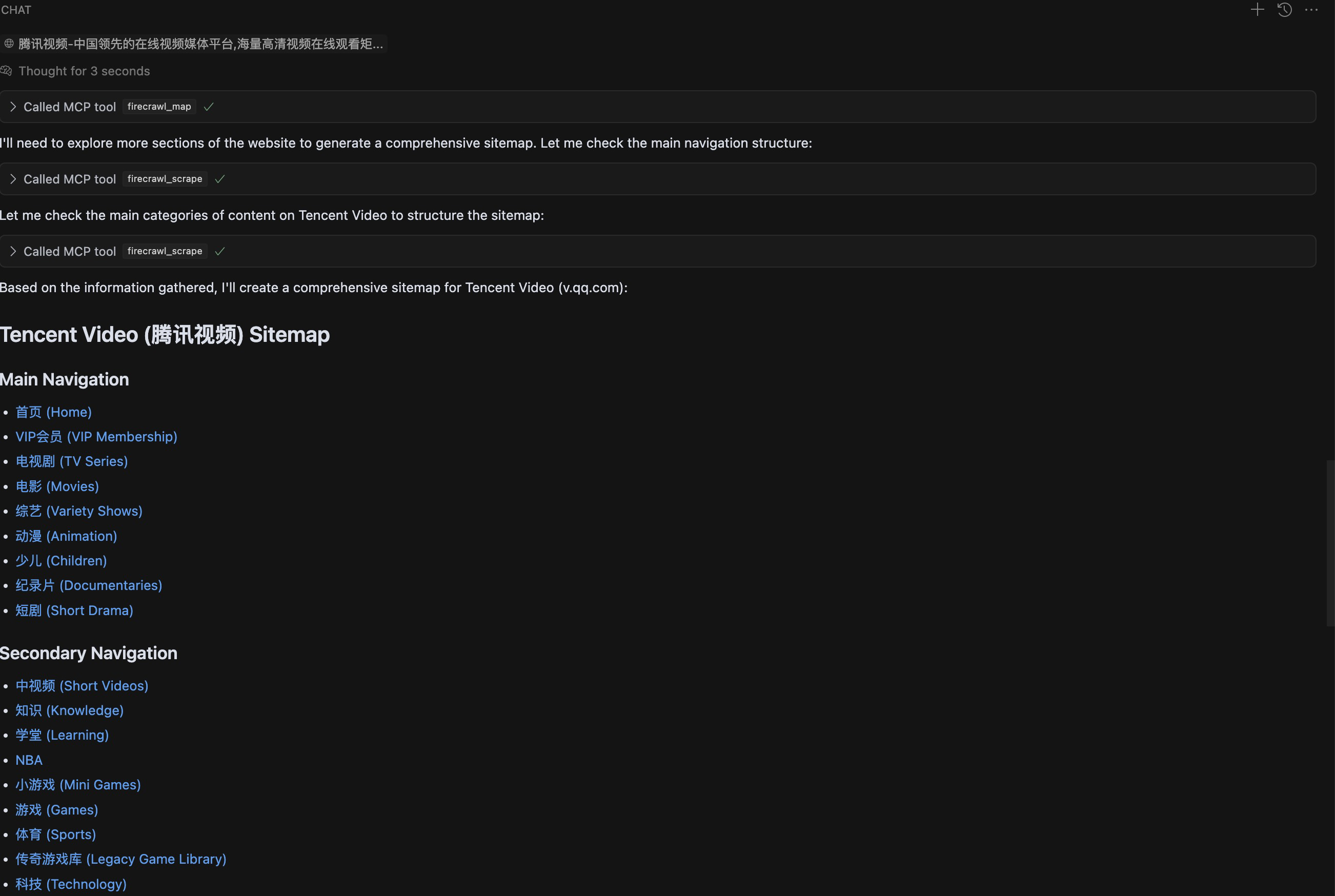
3. 网站map
如果我们想要了解一个网站的页面间链接关系,可以通过生成网站map的方式,通过提示词调用 firecrawl_map 就可以生成网站的链接关系。
结语
本篇文章主要使用 Firecrawl mcp server 来爬取一些数据,除了上面几个简单的应用场景,其他的tool也可以自行尝试复杂场景。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
