CodeBuddy 编程助手-算法生成+api接口实现
原创
CodeBuddy 编程助手-算法生成+api接口实现
原创
“我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴”
参考
关于CodeBuddy 编程助手
智能代码助手简介
代码助手可以快速的帮我们补充代码,修改代码,添加注释,翻译中英文,起变量函数名字等操作,十分的友好,这类代码助手现阶段有较多的产品,比如:
CodeBuddy 编程助手
MarsCode编程助手
Baidu Comate智能代码助手
GitHub Copilot
通义灵码
Bito
本文主要基于腾讯云代码助手 CodeBuddy进行高效代码编程体验,let's go!!!
腾讯云代码助手 CodeBuddy简介
腾讯云代码助手是由腾讯云自研的一款开发编程提效辅助工具,开发者可以通过插件的方式将腾讯云代码助手安装到编辑器中辅助编程工作(VS Code 或者 JetBrians 系列 IDE);
而腾讯云代码助手插件将提供:自动补全代码、根据注释生成代码、代码解释、生成测试代码、转换代码语言、技术对话等能力。通过腾讯云代码助手,开发者可以更高效地解决实际编程问题,提高编程效率和代码质量。。
本地 IDE 中快速安装及使用
在 Visual Studio Code 中安装
快速安装:
1.单击连接:腾讯云代码助手
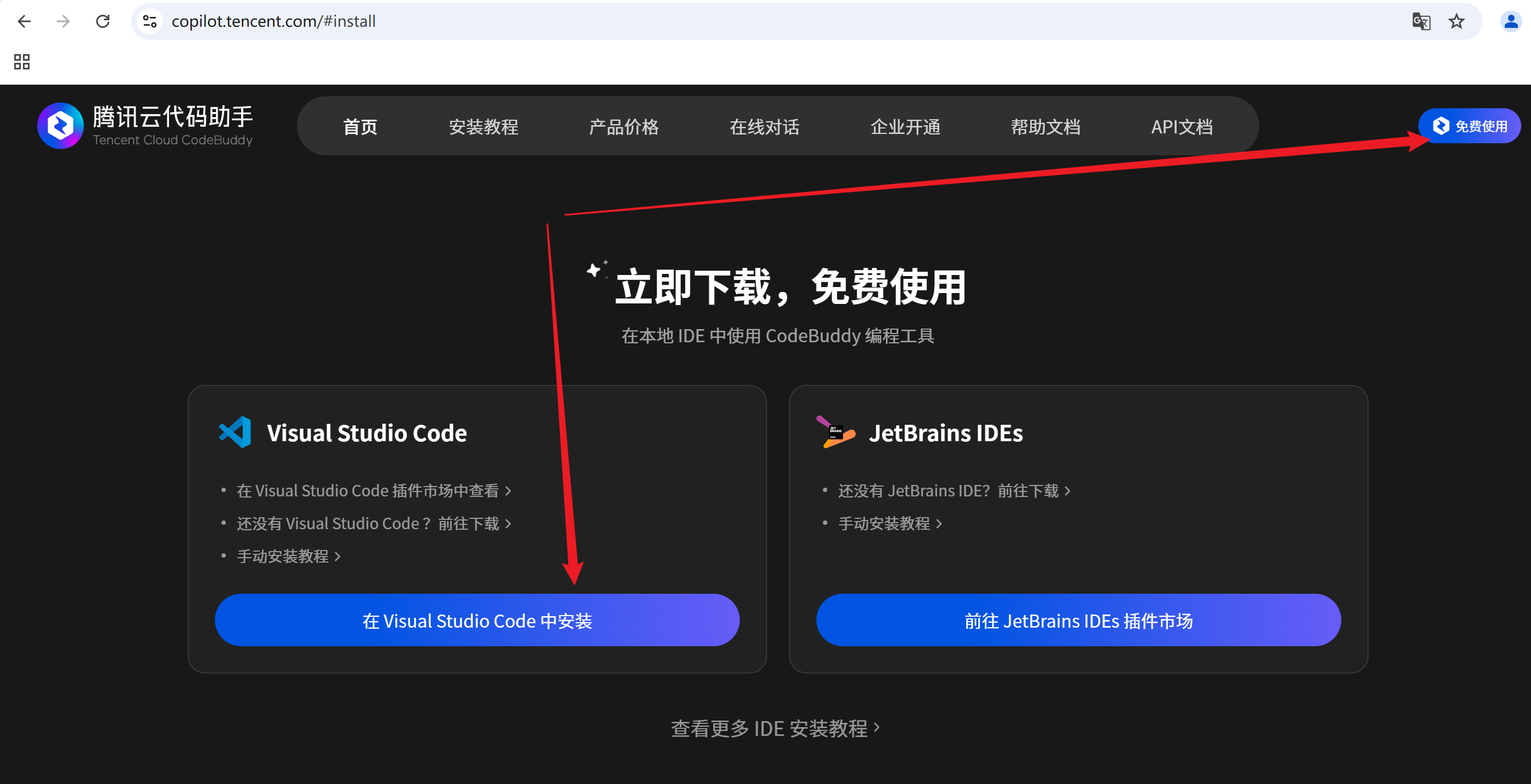
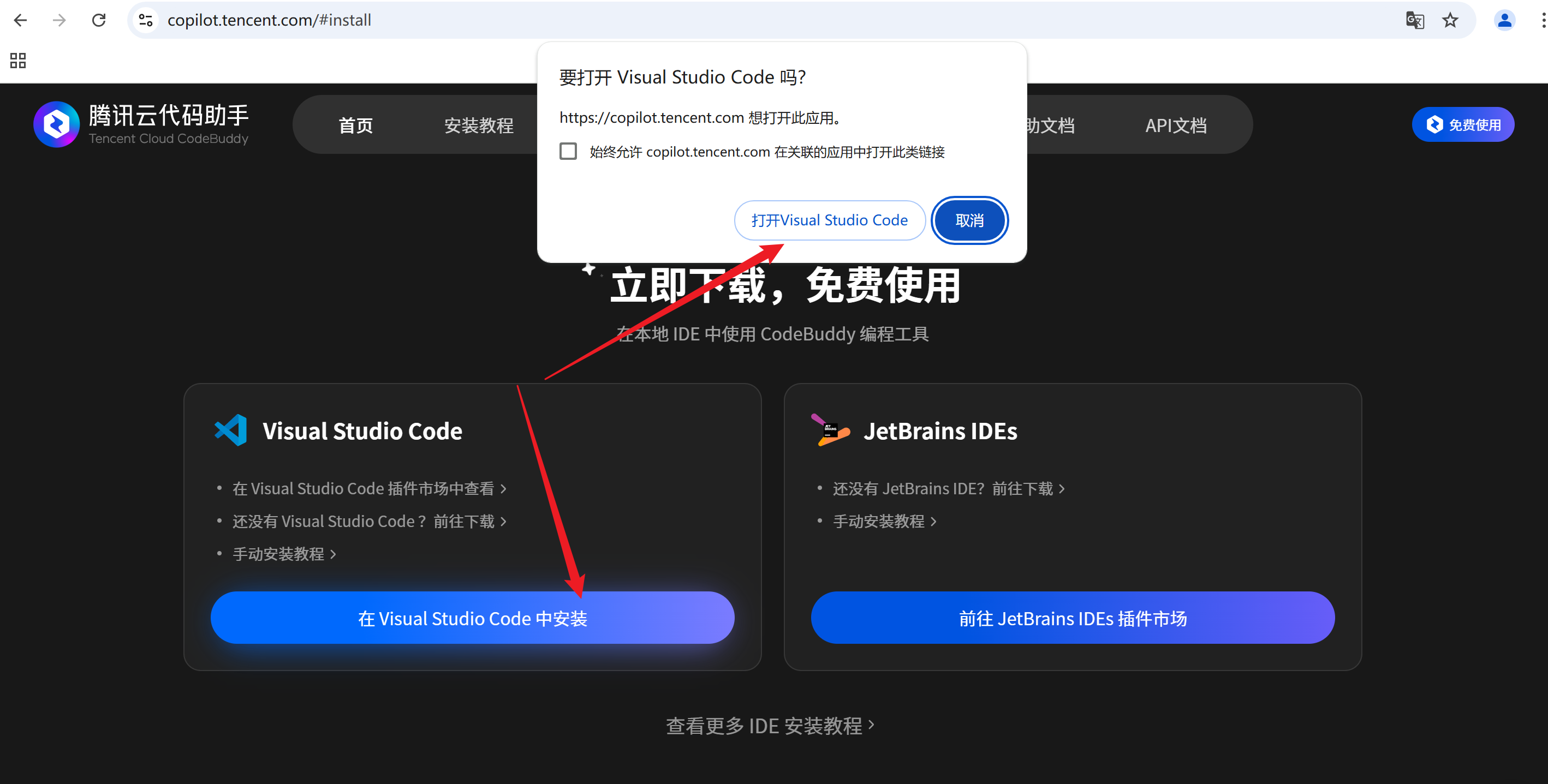
2.单击在 Visual Studio Code中安装,弹出的提示框中选择打开Visual Stidio Code,
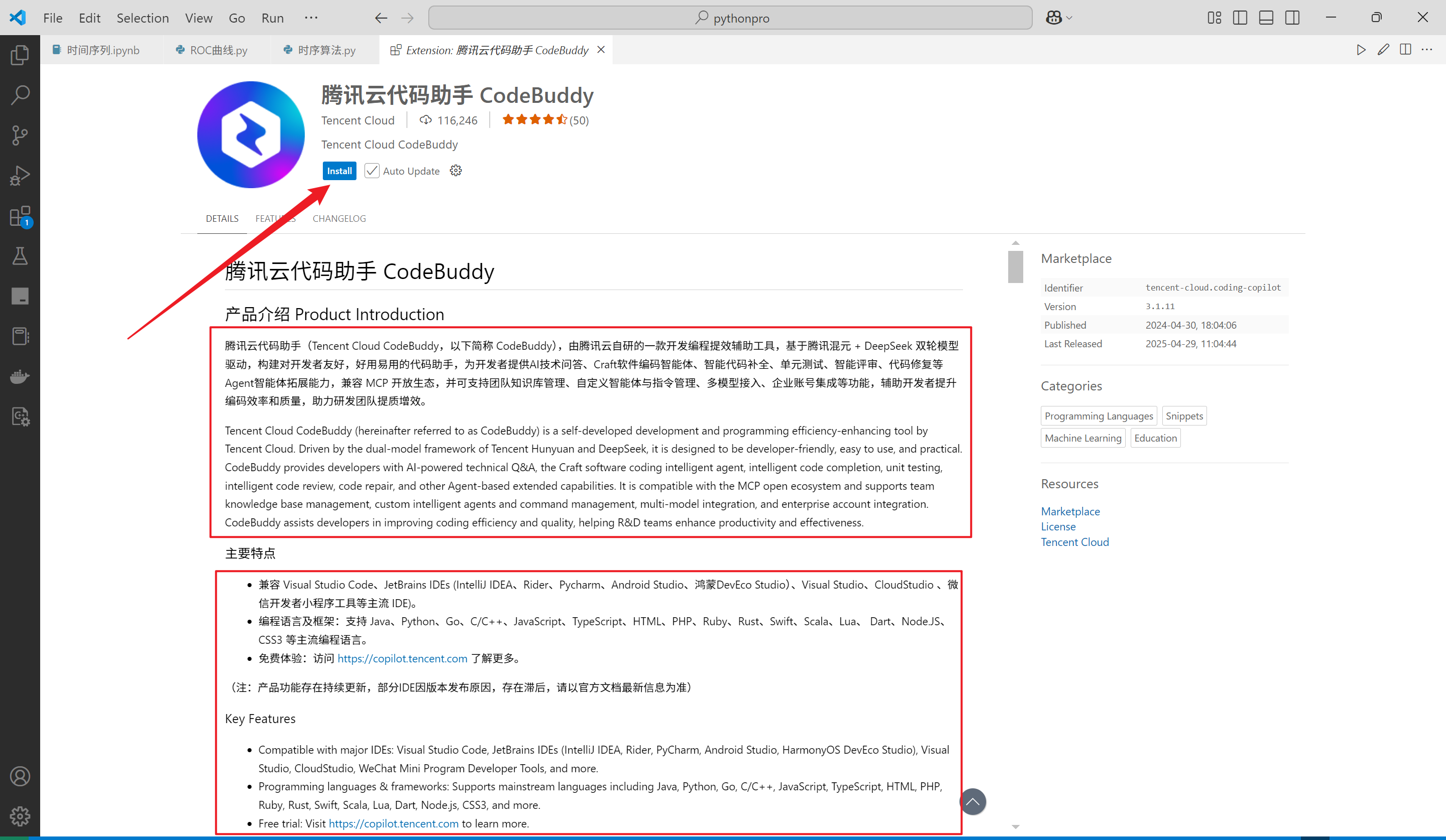
3.在打开的Visual Studio Code中单击Install 安装,并按照VScode的要求,选择信任即可
4.单击login登录,弹出登录页面
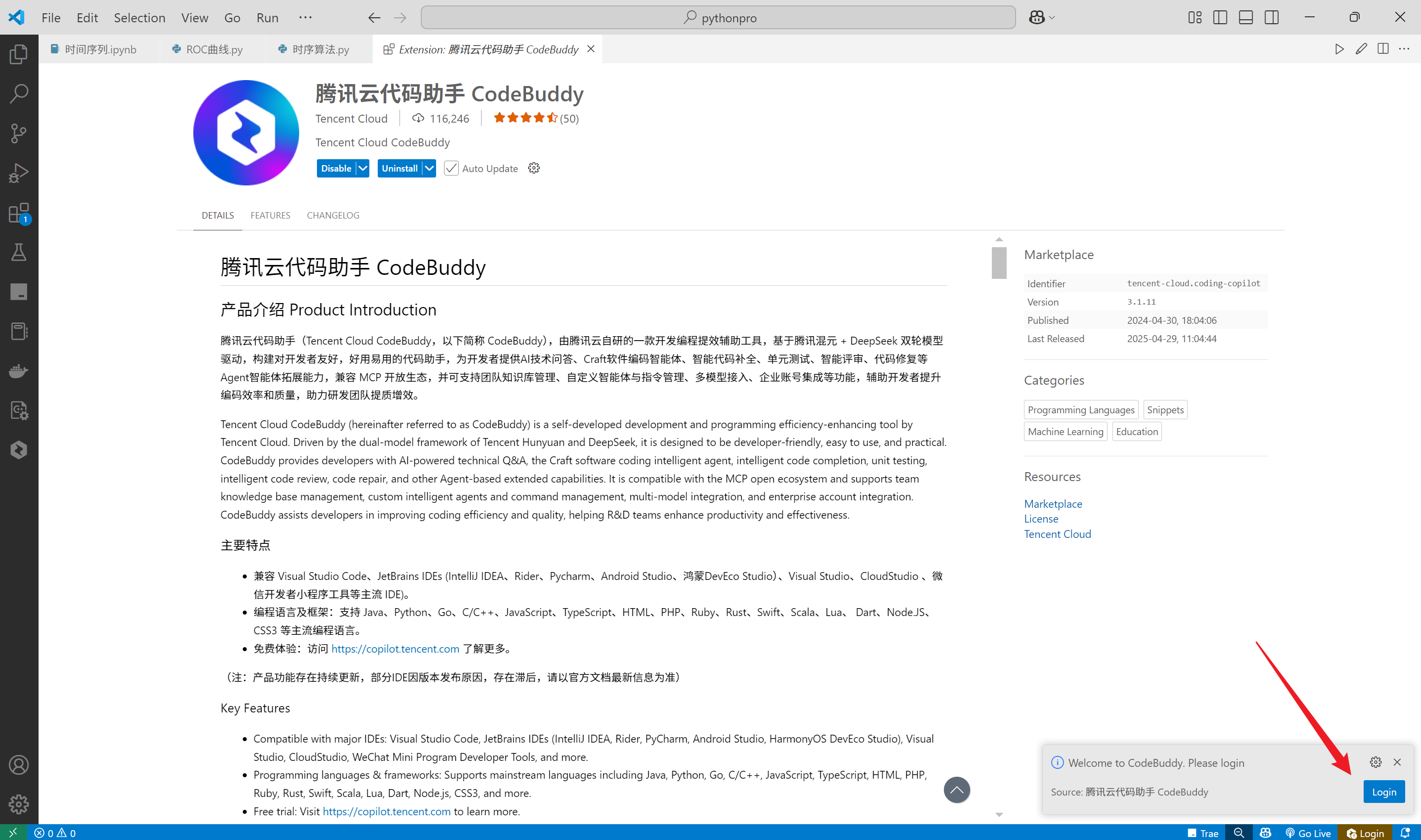
登录页面
5.在该页面登录即可,然后单击打开IDE继续使用
6.登录后的页面如下
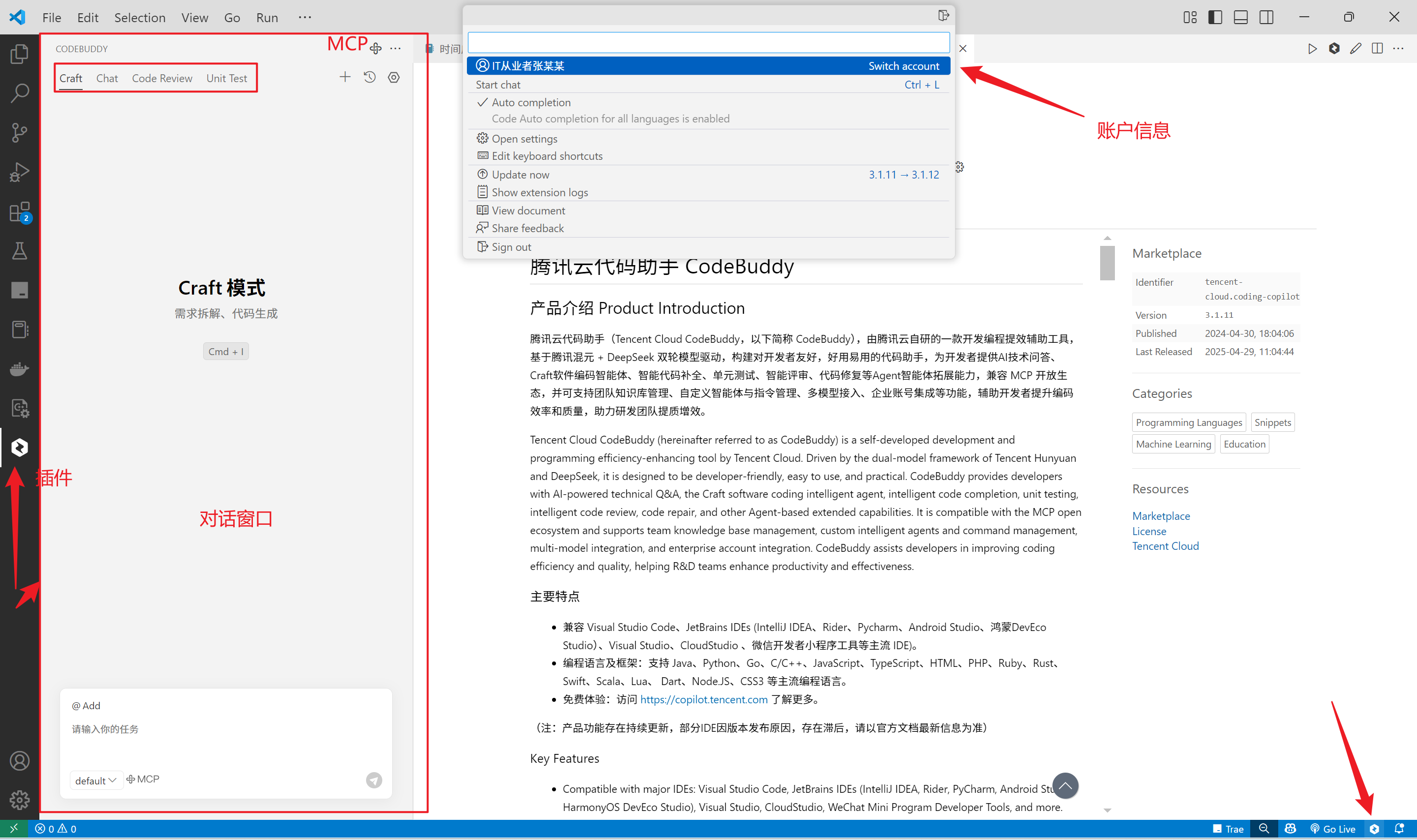
插件功能入门
更多功能请参考插件功能入门参考,本文不一一展开,接下来从3个方面使用CodeBuddy ,看看对工作效率的提升。
CodeBuddy提供的一系列的对话快捷指令
在对话输入框中,输入 / 或 @ 调用预置的快捷指令: /clear:清空当前会话。
/comments:为所选的代码添加文档注释。
/new-notebook:创建一个新的 Jupyter 笔记本。 /explain:解释所选代码的工作原理。 /fix:针对所选代码中的问题提出修复方案。 /tests:为所选代码生成单元测试。 /name-var:变量命名。 /cr:为所选代码和本地提交的 Diff 提出评审方案。 /help:查看使用指南。 @vscode:询问 VS Code。 @terminal:询问如何在终端中执行某些操作。 @workspace:询问您的工作空间,将自动引用当前代码。
开发一个贝叶斯算法的案例
在Craft模式下,输入如下问题
写一个基于sklearn的贝叶斯算法的案例,适合计算机专业大三同学学习的,要求包括导入依赖,数据集加载,拆分数据集,数据集探索,数据集处理,实例化三种贝叶斯算法,并分别基于三种贝叶斯算法完成模型训练,模型验证,模型评估,模型预测,模型保存,模型加载。
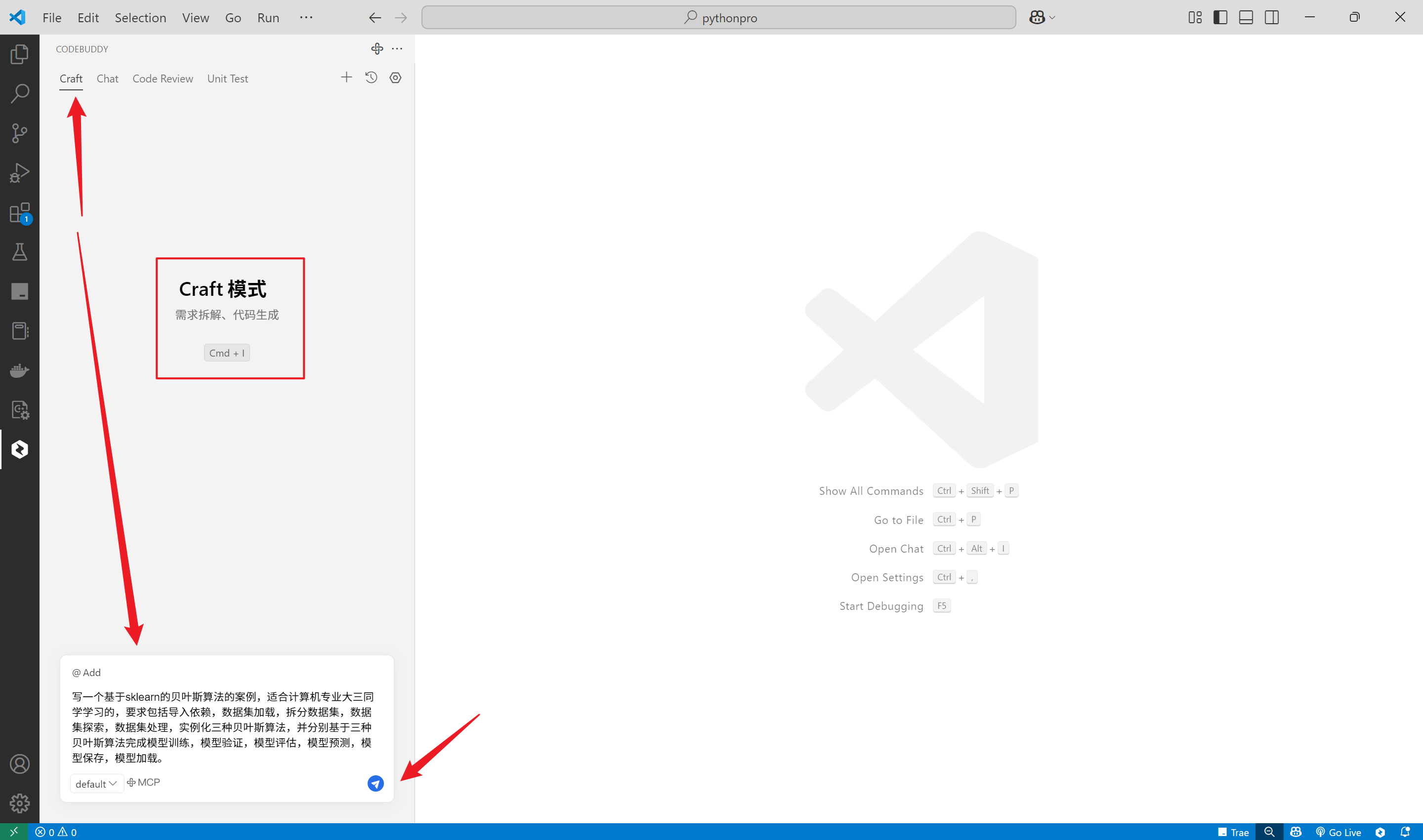
可以看到CodeBuddy的思考过程和检索本地文件的过程,基于此,会生成一个代码并保存在文件中。
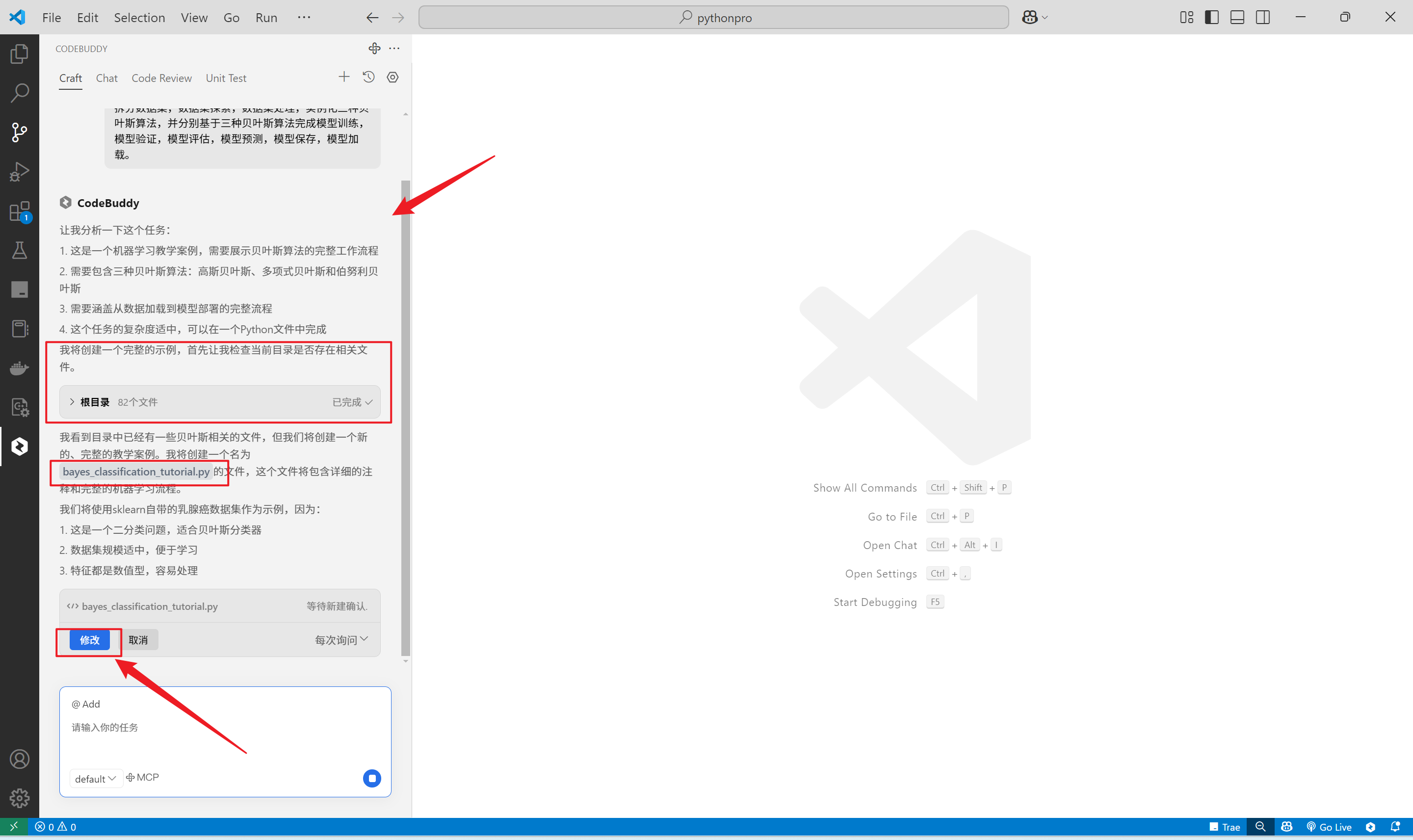
单击修改,即可查看到新创建的文件。这个过程比较丝滑,比较解压,5s生成175行代码。
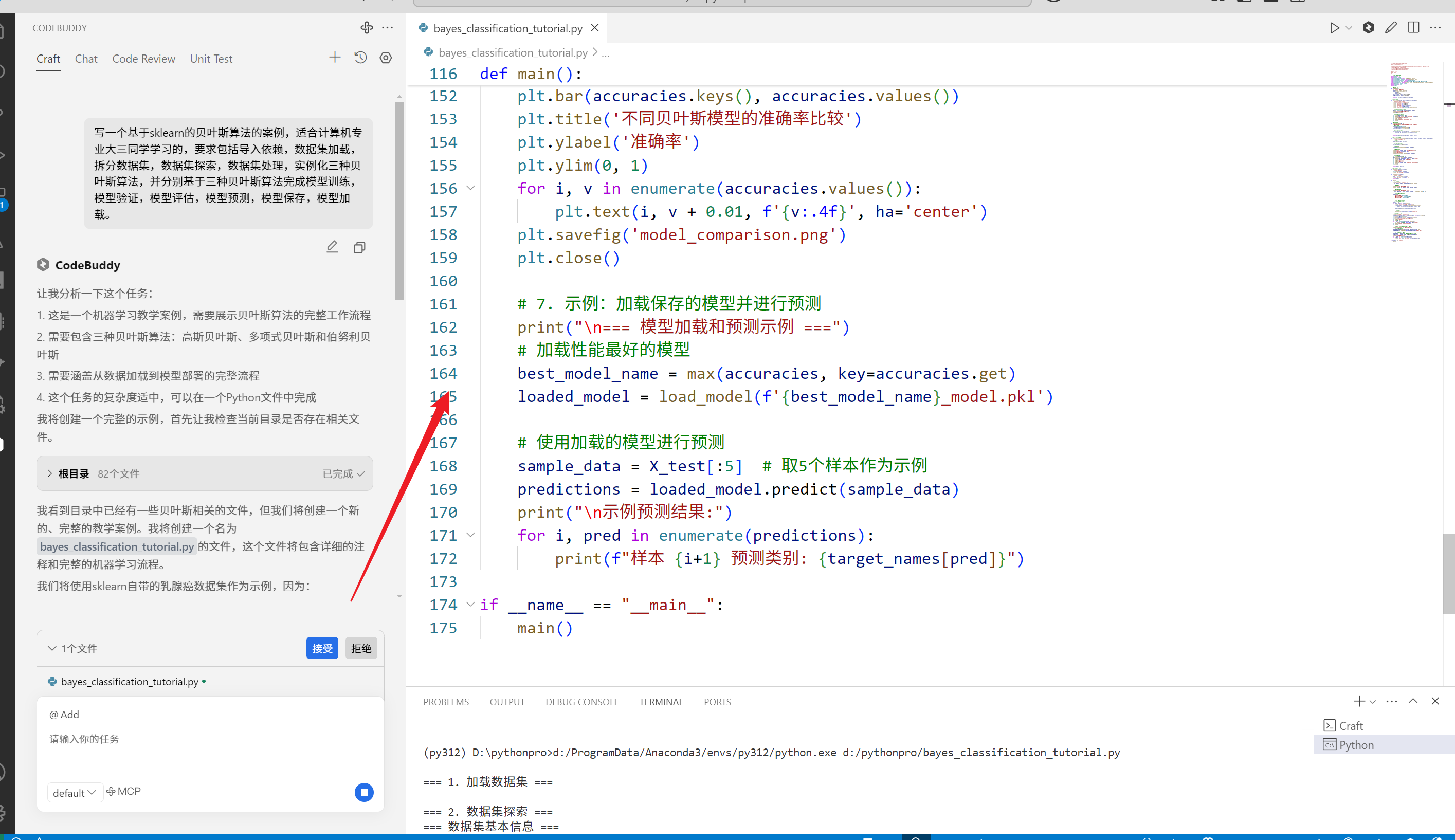
完整的代码如下
"""
基于sklearn的贝叶斯算法教学案例
适合计算机专业大三同学学习
本案例使用乳腺癌数据集,展示了使用三种贝叶斯分类器进行机器学习的完整流程:
1. 高斯朴素贝叶斯 (GaussianNB)
2. 多项式朴素贝叶斯 (MultinomialNB)
3. 伯努利朴素贝叶斯 (BernoulliNB)
Author: Craft
Date: 2024
"""
# 1. 导入所需的依赖
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import joblib
# 2. 数据集加载
def load_data():
"""加载乳腺癌数据集"""
data = load_breast_cancer()
X = data.data
y = data.target
feature_names = data.feature_names
target_names = data.target_names
return X, y, feature_names, target_names
# 3. 数据集探索
def explore_data(X, y, feature_names, target_names):
"""探索数据集的基本信息"""
print("=== 数据集基本信息 ===")
print(f"样本数量: {X.shape[0]}")
print(f"特征数量: {X.shape[1]}")
print(f"特征名称: {feature_names}")
print(f"目标类别: {target_names}")
print(f"类别分布:\n{pd.Series(y).value_counts()}")
# 创建特征数据的DataFrame
df = pd.DataFrame(X, columns=feature_names)
print("\n=== 特征统计描述 ===")
print(df.describe())
# 绘制特征相关性热力图
plt.figure(figsize=(12, 8))
sns.heatmap(df.corr(), cmap='coolwarm', center=0)
plt.title('特征相关性热力图')
plt.tight_layout()
plt.savefig('feature_correlation.png')
plt.close()
# 4. 数据集处理
def preprocess_data(X, y):
"""数据预处理:标准化特征并划分训练集和测试集"""
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test, scaler
# 5. 模型训练和评估
def train_and_evaluate_model(model, X_train, X_test, y_train, y_test, model_name):
"""训练模型并评估其性能"""
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 打印评估报告
print(f"\n=== {model_name} 模型评估报告 ===")
print(f"准确率: {accuracy:.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{model_name} 混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.savefig(f'{model_name}_confusion_matrix.png')
plt.close()
return model, accuracy
# 6. 模型保存和加载
def save_model(model, filename):
"""保存模型到文件"""
joblib.dump(model, filename)
print(f"模型已保存到: {filename}")
def load_model(filename):
"""从文件加载模型"""
model = joblib.load(filename)
print(f"模型已从 {filename} 加载")
return model
def main():
# 1. 加载数据
print("\n=== 1. 加载数据集 ===")
X, y, feature_names, target_names = load_data()
# 2. 探索数据
print("\n=== 2. 数据集探索 ===")
explore_data(X, y, feature_names, target_names)
# 3. 数据预处理
print("\n=== 3. 数据预处理 ===")
X_train, X_test, y_train, y_test, scaler = preprocess_data(X, y)
# 4. 创建三种贝叶斯模型
models = {
'GaussianNB': GaussianNB(),
'MultinomialNB': MultinomialNB(),
'BernoulliNB': BernoulliNB()
}
# 5. 训练和评估每个模型
results = {}
for name, model in models.items():
print(f"\n=== 训练和评估 {name} ===")
trained_model, accuracy = train_and_evaluate_model(
model, X_train, X_test, y_train, y_test, name
)
results[name] = (trained_model, accuracy)
# 保存模型
save_model(trained_model, f'{name}_model.pkl')
# 6. 比较模型性能
print("\n=== 模型性能比较 ===")
accuracies = {name: acc for name, (_, acc) in results.items()}
plt.figure(figsize=(10, 6))
plt.bar(accuracies.keys(), accuracies.values())
plt.title('不同贝叶斯模型的准确率比较')
plt.ylabel('准确率')
plt.ylim(0, 1)
for i, v in enumerate(accuracies.values()):
plt.text(i, v + 0.01, f'{v:.4f}', ha='center')
plt.savefig('model_comparison.png')
plt.close()
# 7. 示例:加载保存的模型并进行预测
print("\n=== 模型加载和预测示例 ===")
# 加载性能最好的模型
best_model_name = max(accuracies, key=accuracies.get)
loaded_model = load_model(f'{best_model_name}_model.pkl')
# 使用加载的模型进行预测
sample_data = X_test[:5] # 取5个样本作为示例
predictions = loaded_model.predict(sample_data)
print("\n示例预测结果:")
for i, pred in enumerate(predictions):
print(f"样本 {i+1} 预测类别: {target_names[pred]}")
if __name__ == "__main__":
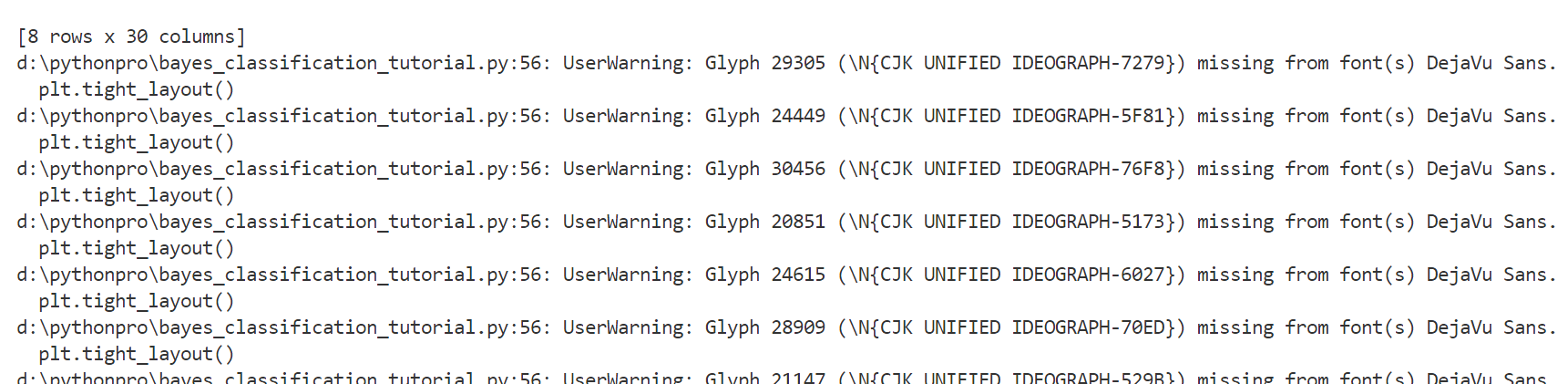
main()运行下文件,提示如下警告
这个问题,会导致生成的图片中文为方框
和
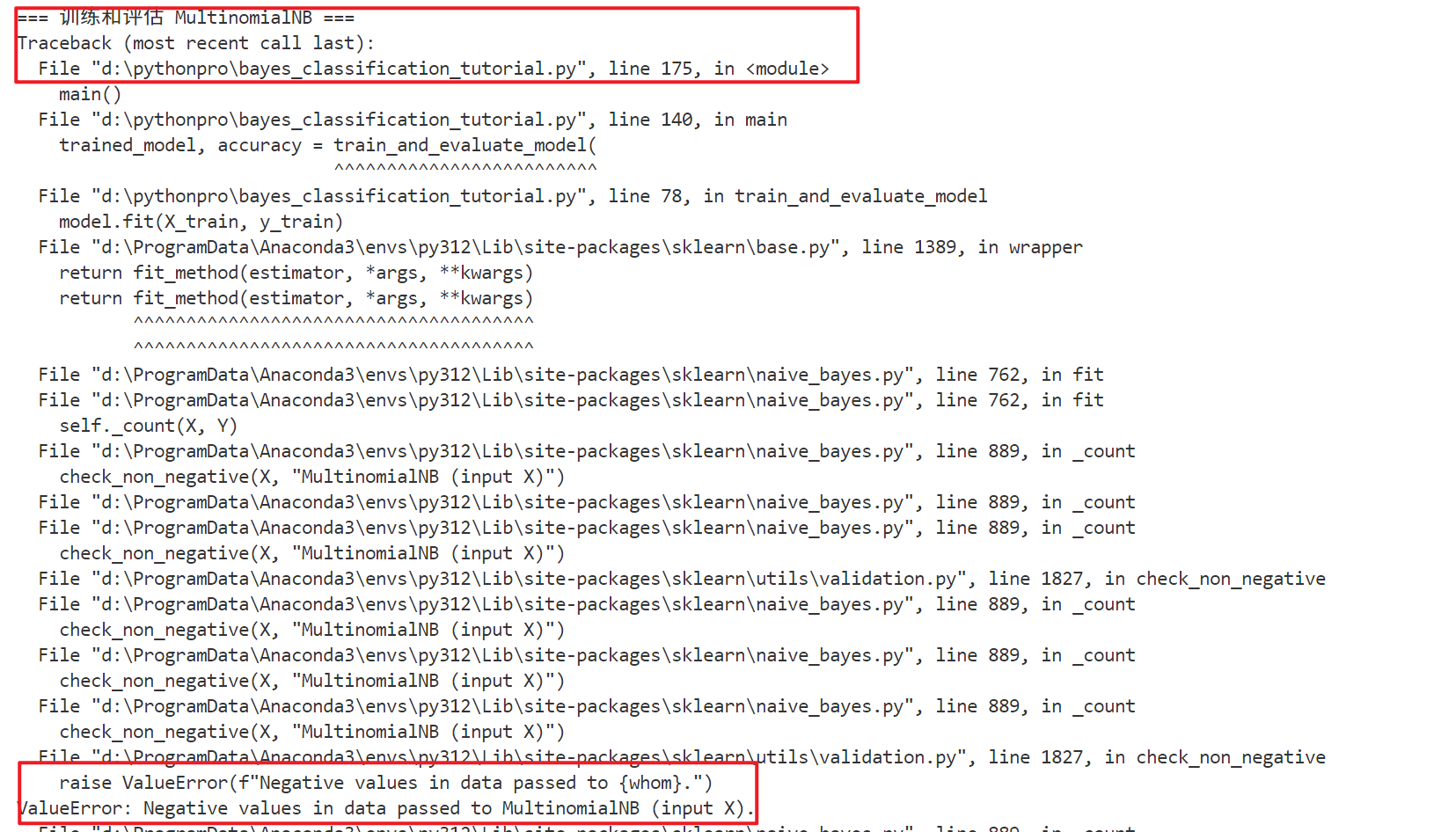
单击chat模式,该模式用于工程理解和技术问答。
修复问题,在对话框输入/fix
/fix
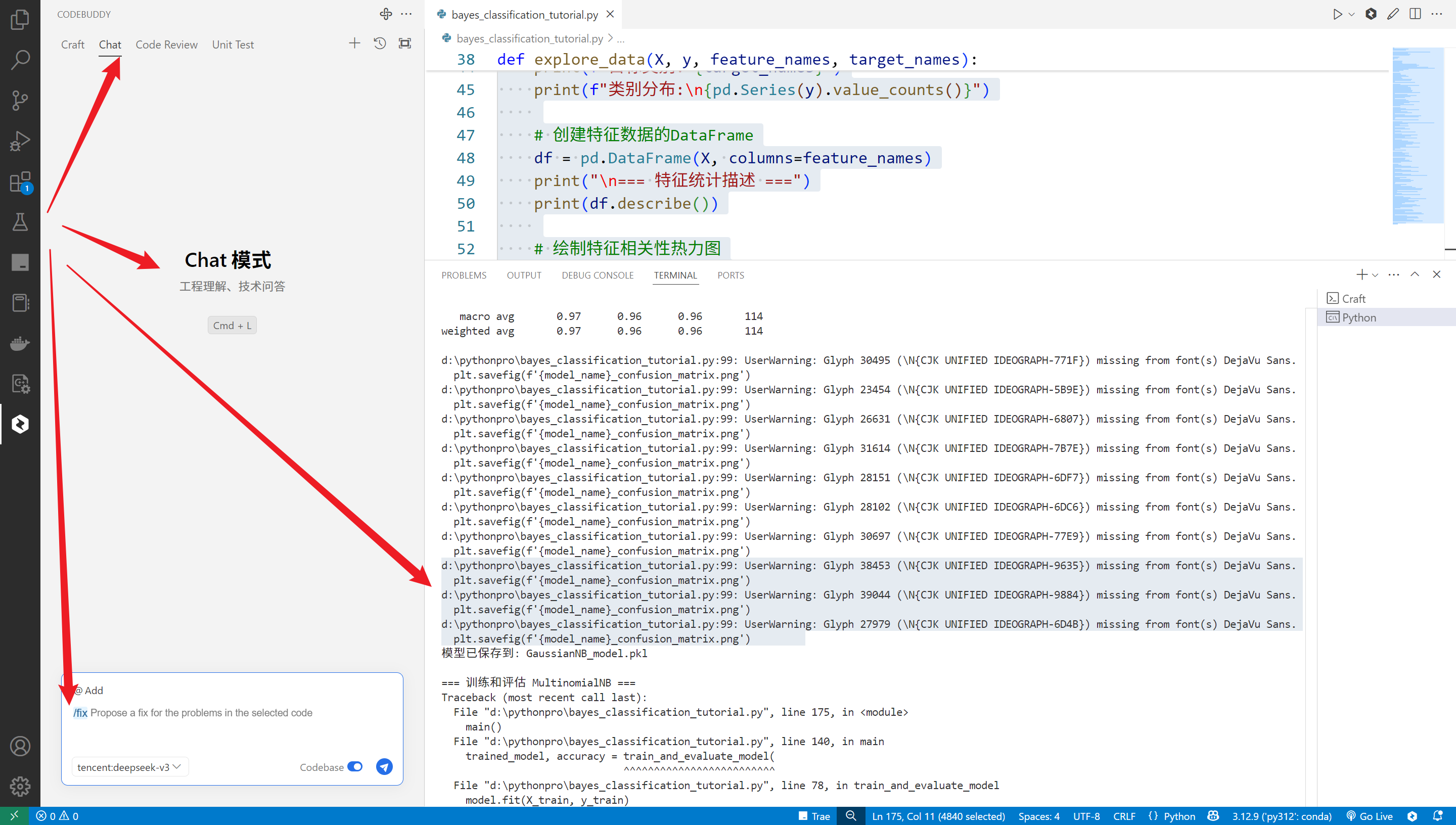
按照要求,把错误给入对话框
d:\pythonpro\bayes_classification_tutorial.py:99: UserWarning: Glyph 38453 (\N{CJK UNIFIED IDEOGRAPH-9635}) missing from font(s) DejaVu Sans.
plt.savefig(f'{model_name}_confusion_matrix.png') d:\pythonpro\bayes_classification_tutorial.py:99: UserWarning: Glyph 39044 (\N{CJK UNIFIED IDEOGRAPH-9884}) missing from font(s) DejaVu Sans.
plt.savefig(f'{model_name}_confusion_matrix.png') d:\pythonpro\bayes_classification_tutorial.py:99: UserWarning: Glyph 27979 (\N{CJK UNIFIED IDEOGRAPH-6D4B}) missing from font(s) DejaVu Sans.
plt.savefig(f'{model_name}_confusion_matrix.png')

输出如下:
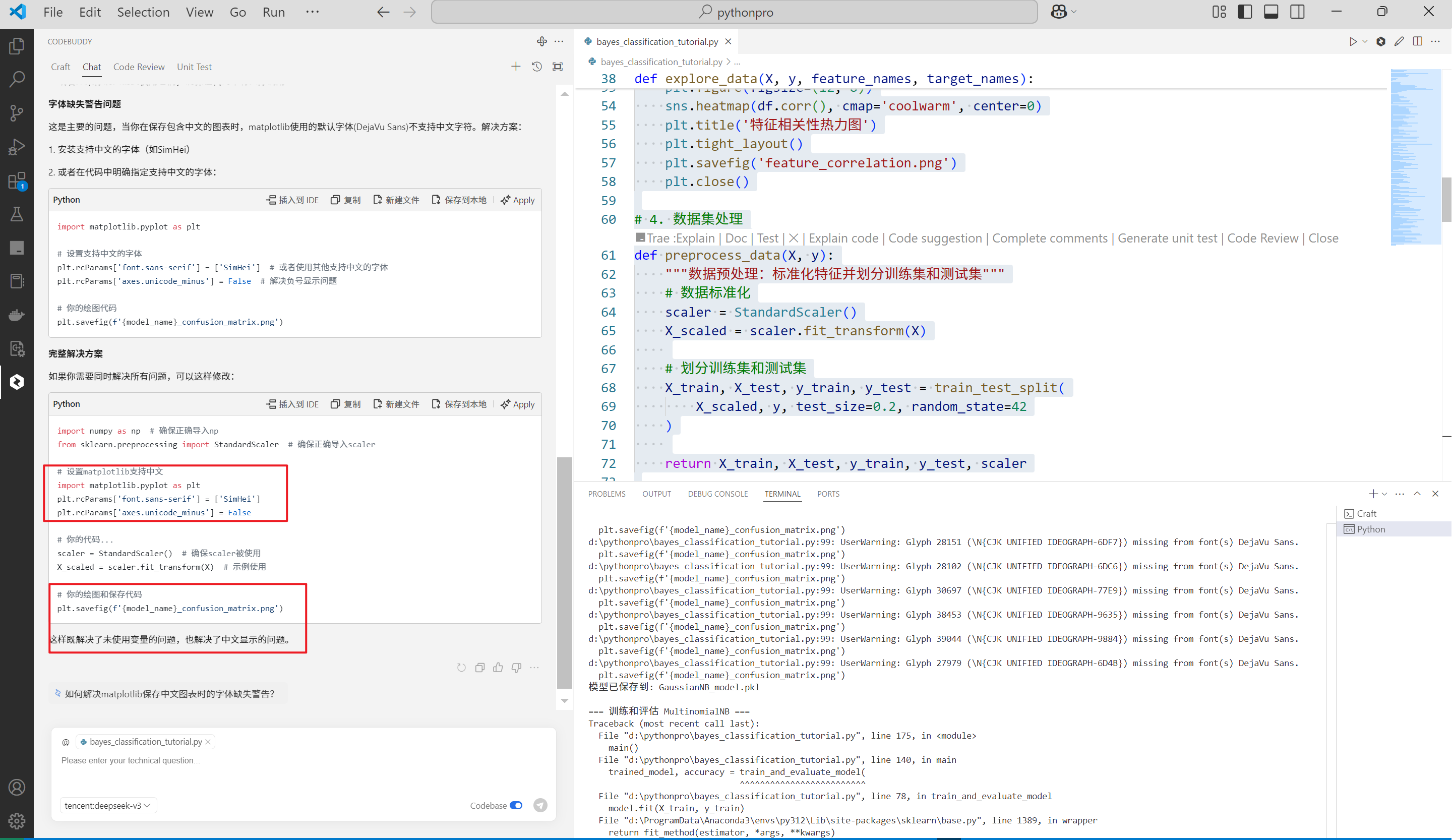
单击Apply,既可以完成代码的初步修改,同时会在修改的地方显示颜色对比(红色为源代码绿色为修改后的代码)与是否接收
再次运行,可以看到中文乱码问题被修复
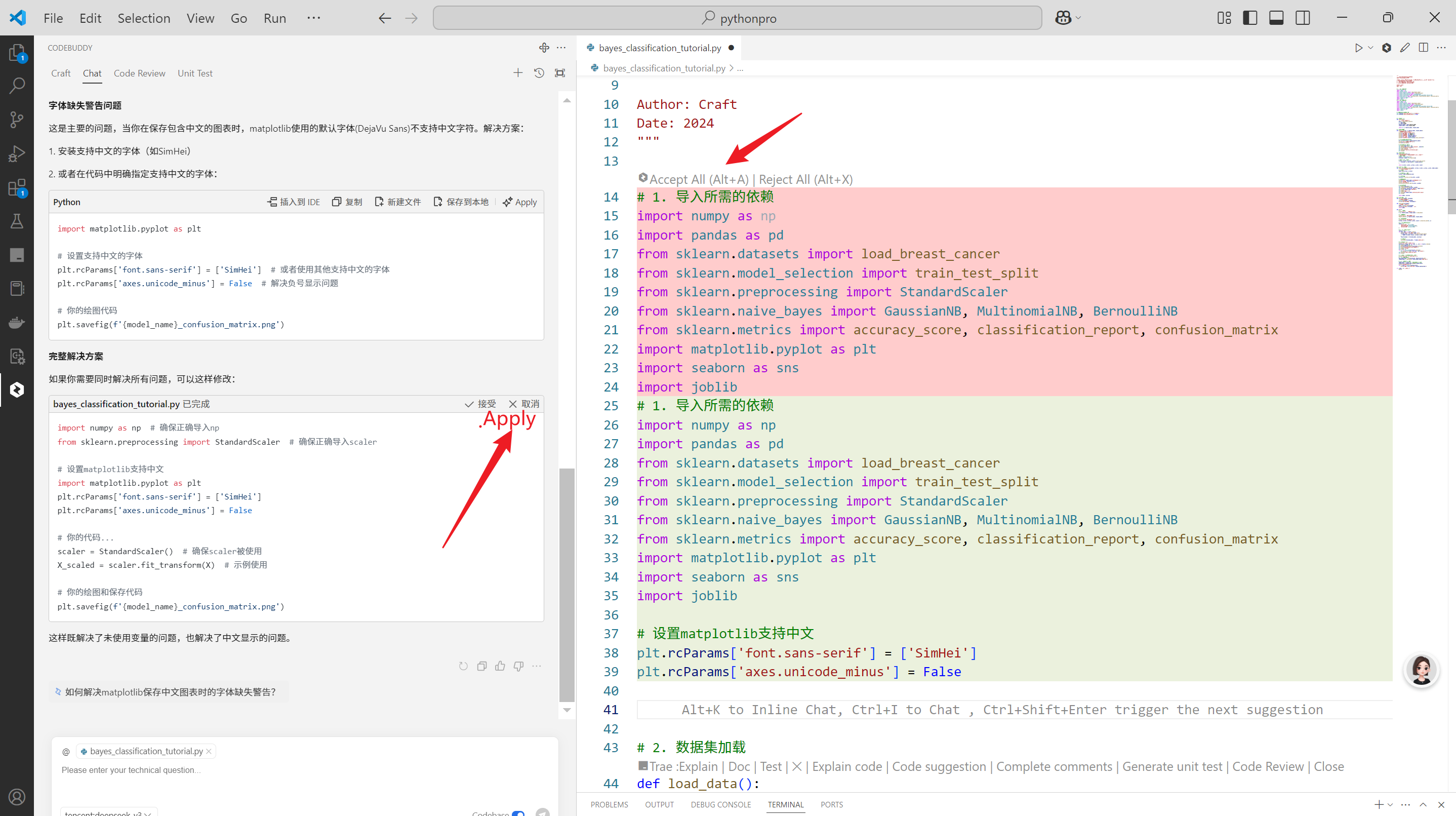
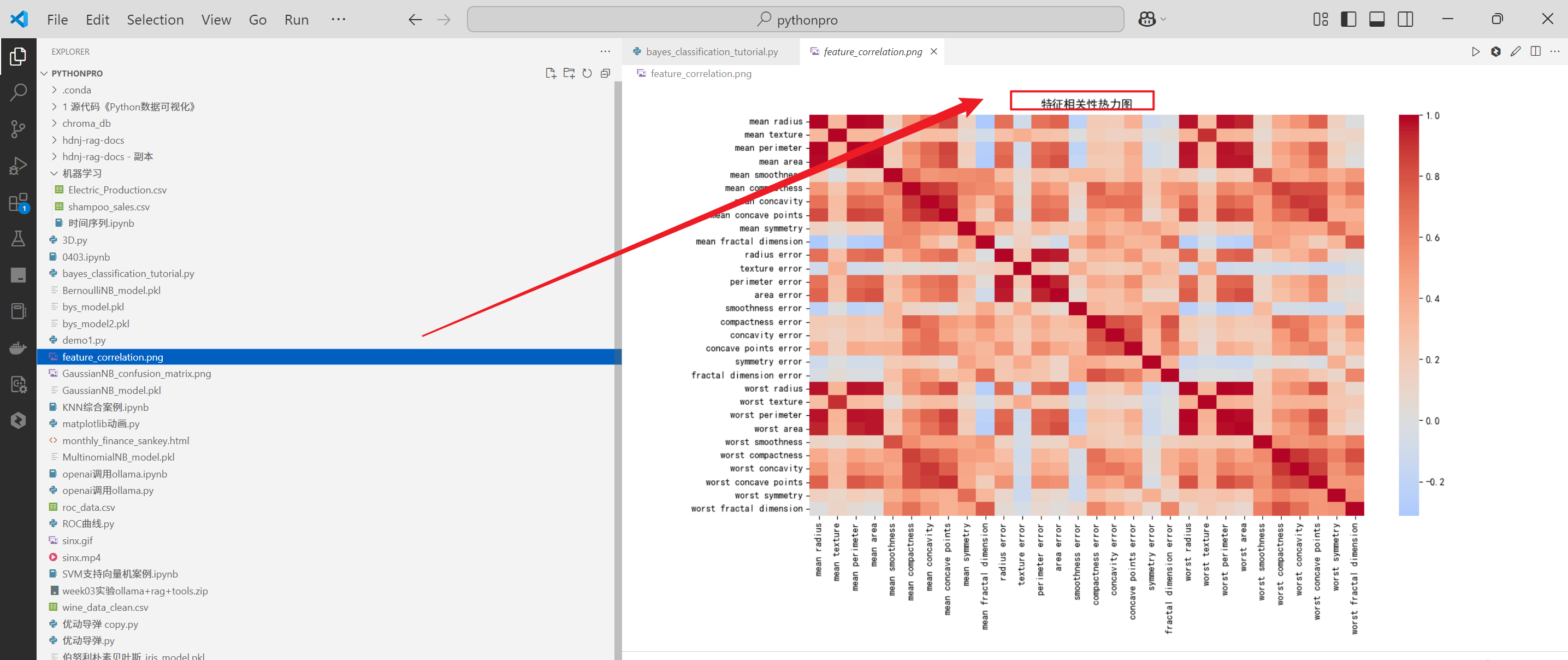
再次修复第2个问题
提问如下
输出如下
给出了原因的同时,也给出了解决方案,很友好,单击Apply看一下

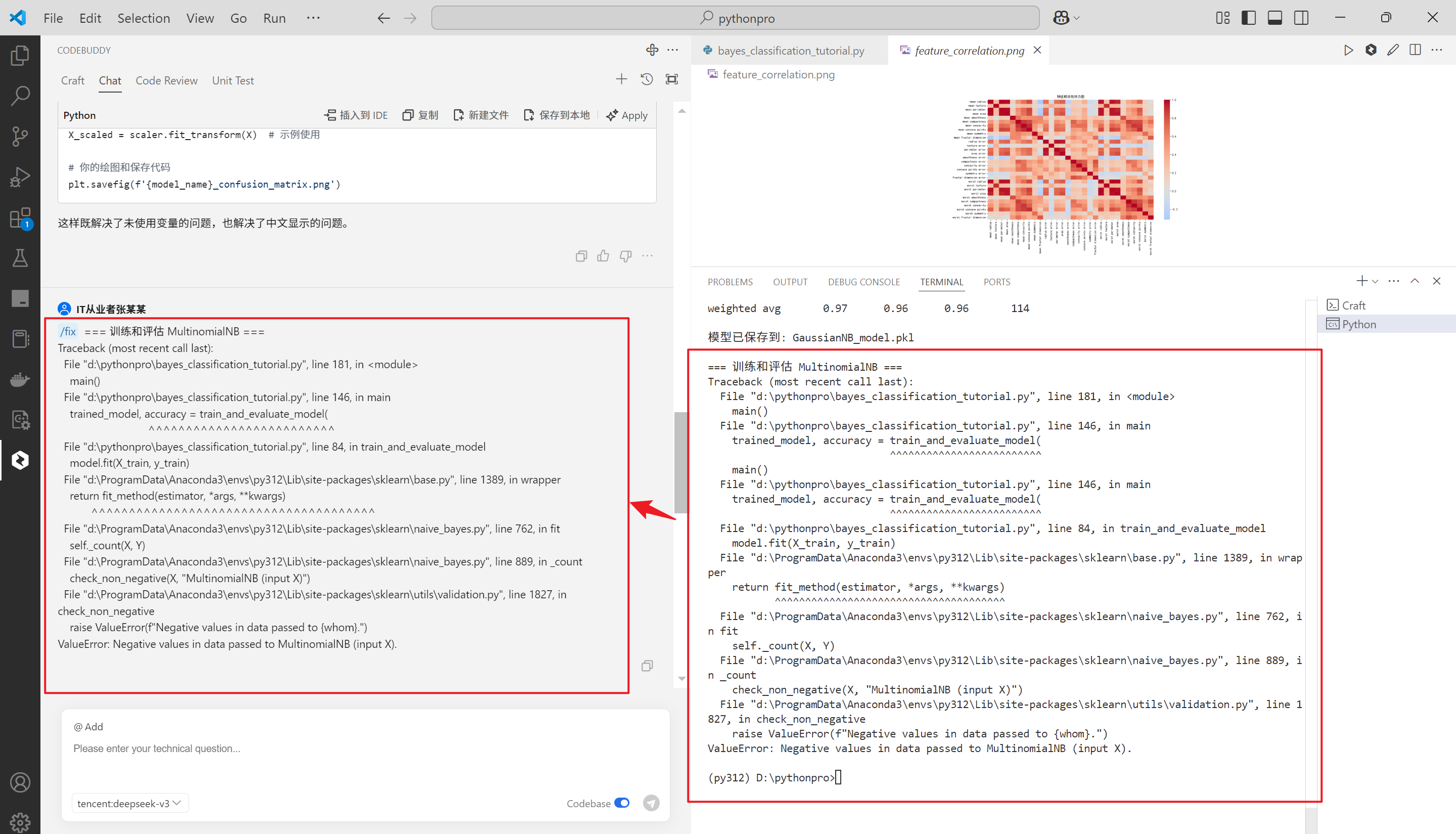
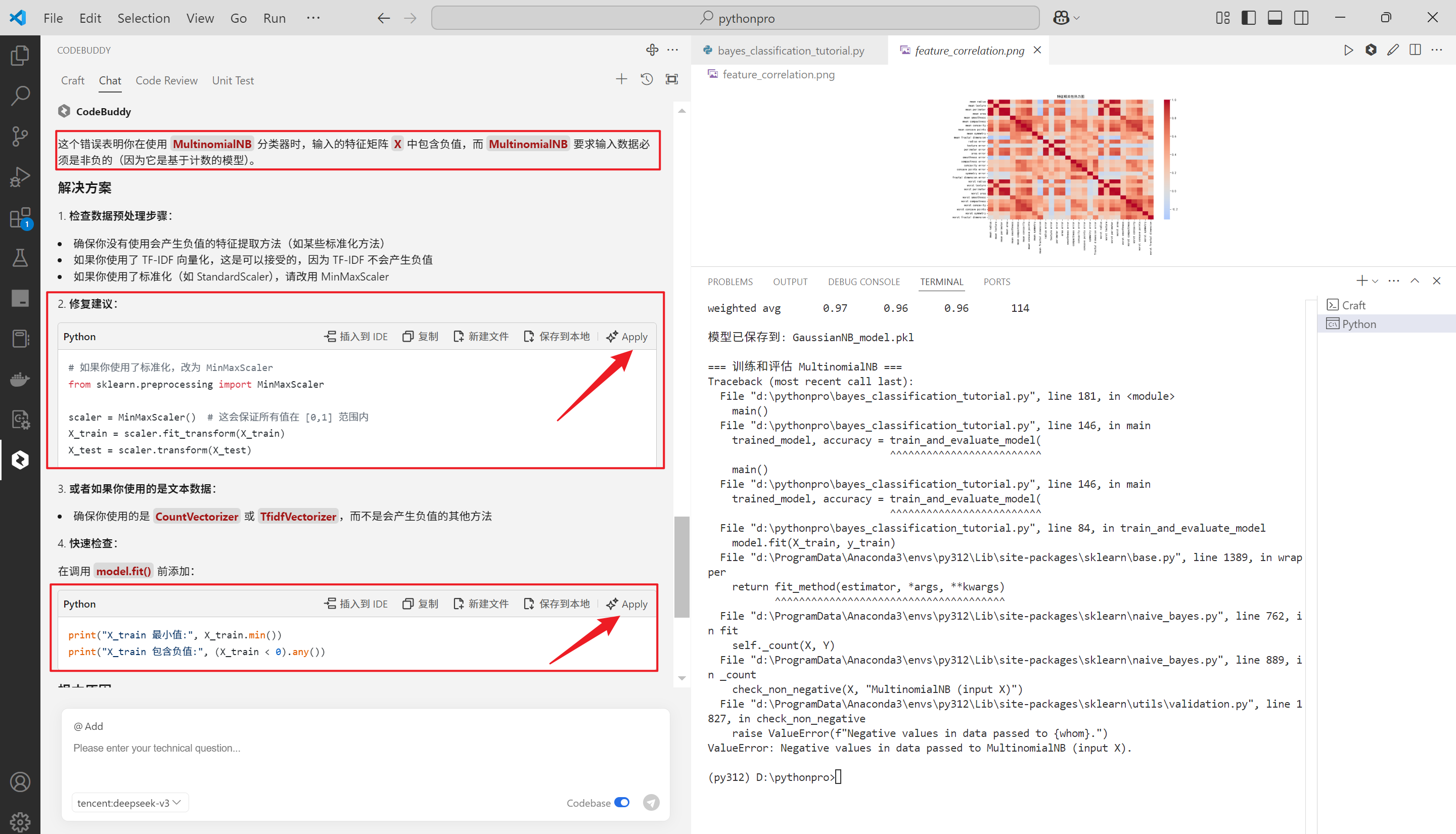
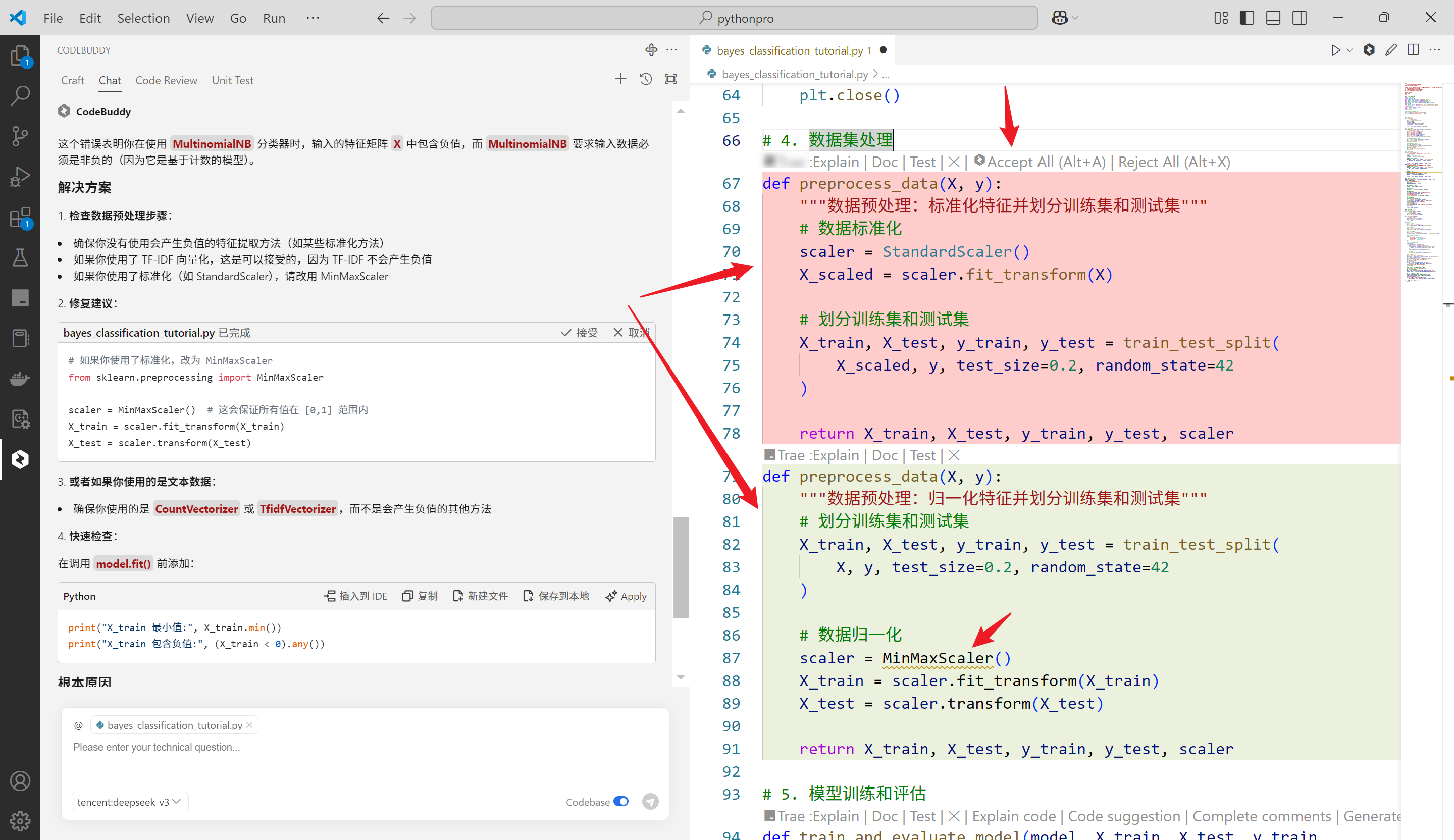
再次运行,没有毛病,完美
到此这个代码就已经完成了,完整的代码如下
"""
基于sklearn的贝叶斯算法教学案例
适合计算机专业大三同学学习
本案例使用乳腺癌数据集,展示了使用三种贝叶斯分类器进行机器学习的完整流程:
1. 高斯朴素贝叶斯 (GaussianNB)
2. 多项式朴素贝叶斯 (MultinomialNB)
3. 伯努利朴素贝叶斯 (BernoulliNB)
Author: Craft
Date: 2024
"""
# 1. 导入所需的依赖
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import joblib
# # 设置matplotlib支持中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 2. 数据集加载
def load_data():
"""加载乳腺癌数据集"""
data = load_breast_cancer()
X = data.data
y = data.target
feature_names = data.feature_names
target_names = data.target_names
return X, y, feature_names, target_names
# 3. 数据集探索
def explore_data(X, y, feature_names, target_names):
"""探索数据集的基本信息"""
print("=== 数据集基本信息 ===")
print(f"样本数量: {X.shape[0]}")
print(f"特征数量: {X.shape[1]}")
print(f"特征名称: {feature_names}")
print(f"目标类别: {target_names}")
print(f"类别分布:\n{pd.Series(y).value_counts()}")
# 创建特征数据的DataFrame
df = pd.DataFrame(X, columns=feature_names)
print("\n=== 特征统计描述 ===")
print(df.describe())
# 绘制特征相关性热力图
plt.figure(figsize=(12, 8))
sns.heatmap(df.corr(), cmap='coolwarm', center=0)
plt.title('特征相关性热力图')
plt.tight_layout()
plt.savefig('feature_correlation.png')
plt.close()
# 4. 数据集处理
def preprocess_data(X, y):
"""数据预处理:归一化特征并划分训练集和测试集"""
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 数据归一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
return X_train, X_test, y_train, y_test, scaler
# 5. 模型训练和评估
def train_and_evaluate_model(model, X_train, X_test, y_train, y_test, model_name):
"""训练模型并评估其性能"""
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 打印评估报告
print(f"\n=== {model_name} 模型评估报告 ===")
print(f"准确率: {accuracy:.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{model_name} 混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.savefig(f'{model_name}_confusion_matrix.png')
plt.close()
return model, accuracy
# 6. 模型保存和加载
def save_model(model, filename):
"""保存模型到文件"""
joblib.dump(model, filename)
print(f"模型已保存到: {filename}")
def load_model(filename):
"""从文件加载模型"""
model = joblib.load(filename)
print(f"模型已从 {filename} 加载")
return model
def main():
# 1. 加载数据
print("\n=== 1. 加载数据集 ===")
X, y, feature_names, target_names = load_data()
# 2. 探索数据
print("\n=== 2. 数据集探索 ===")
explore_data(X, y, feature_names, target_names)
# 3. 数据预处理
print("\n=== 3. 数据预处理 ===")
X_train, X_test, y_train, y_test, scaler = preprocess_data(X, y)
# 4. 创建三种贝叶斯模型
models = {
'GaussianNB': GaussianNB(),
'MultinomialNB': MultinomialNB(),
'BernoulliNB': BernoulliNB()
}
# 5. 训练和评估每个模型
results = {}
for name, model in models.items():
print(f"\n=== 训练和评估 {name} ===")
trained_model, accuracy = train_and_evaluate_model(
model, X_train, X_test, y_train, y_test, name
)
results[name] = (trained_model, accuracy)
# 保存模型
save_model(trained_model, f'{name}_model.pkl')
# 6. 比较模型性能
print("\n=== 模型性能比较 ===")
accuracies = {name: acc for name, (_, acc) in results.items()}
plt.figure(figsize=(10, 6))
plt.bar(accuracies.keys(), accuracies.values())
plt.title('不同贝叶斯模型的准确率比较')
plt.ylabel('准确率')
plt.ylim(0, 1)
for i, v in enumerate(accuracies.values()):
plt.text(i, v + 0.01, f'{v:.4f}', ha='center')
plt.savefig('model_comparison.png')
plt.close()
# 7. 示例:加载保存的模型并进行预测
print("\n=== 模型加载和预测示例 ===")
# 加载性能最好的模型
best_model_name = max(accuracies, key=accuracies.get)
loaded_model = load_model(f'{best_model_name}_model.pkl')
# 使用加载的模型进行预测
sample_data = X_test[:5] # 取5个样本作为示例
predictions = loaded_model.predict(sample_data)
print("\n示例预测结果:")
for i, pred in enumerate(predictions):
print(f"样本 {i+1} 预测类别: {target_names[pred]}")
if __name__ == "__main__":
main()Vibe Coding 请提供一个api服务吧
还不够,我想基于这个训练好的模型,提供一个基于flask的接口,走起!!
修改数据集为一个容易填充的数据集,就iris吧
切换到craft模式,输入:
修改数据集为iris数据,其它代码不变
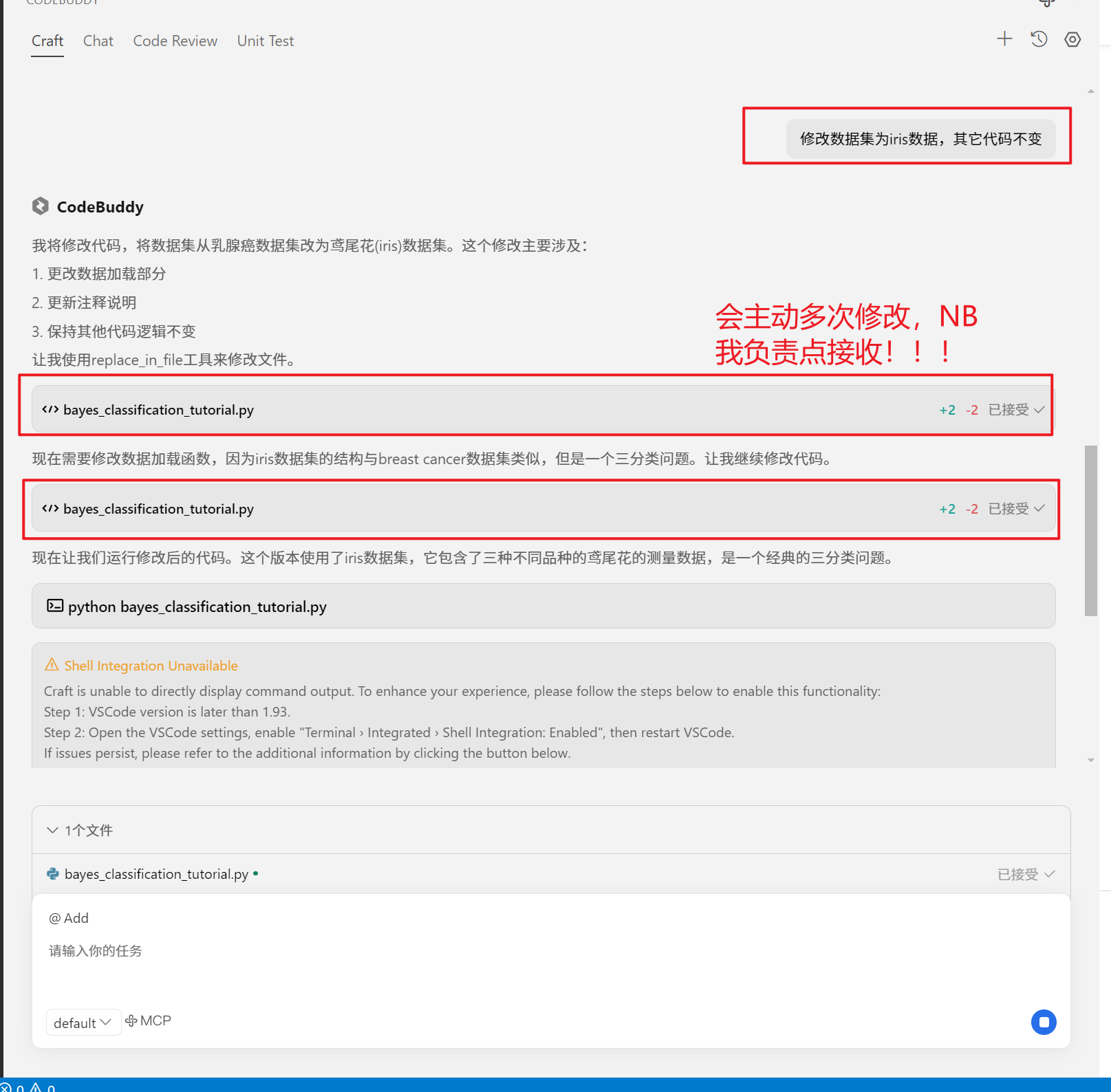
亮点:主动解析结果
对于运行结果,CodeBuddy 编程助手会主动给出解释,这点很给力。
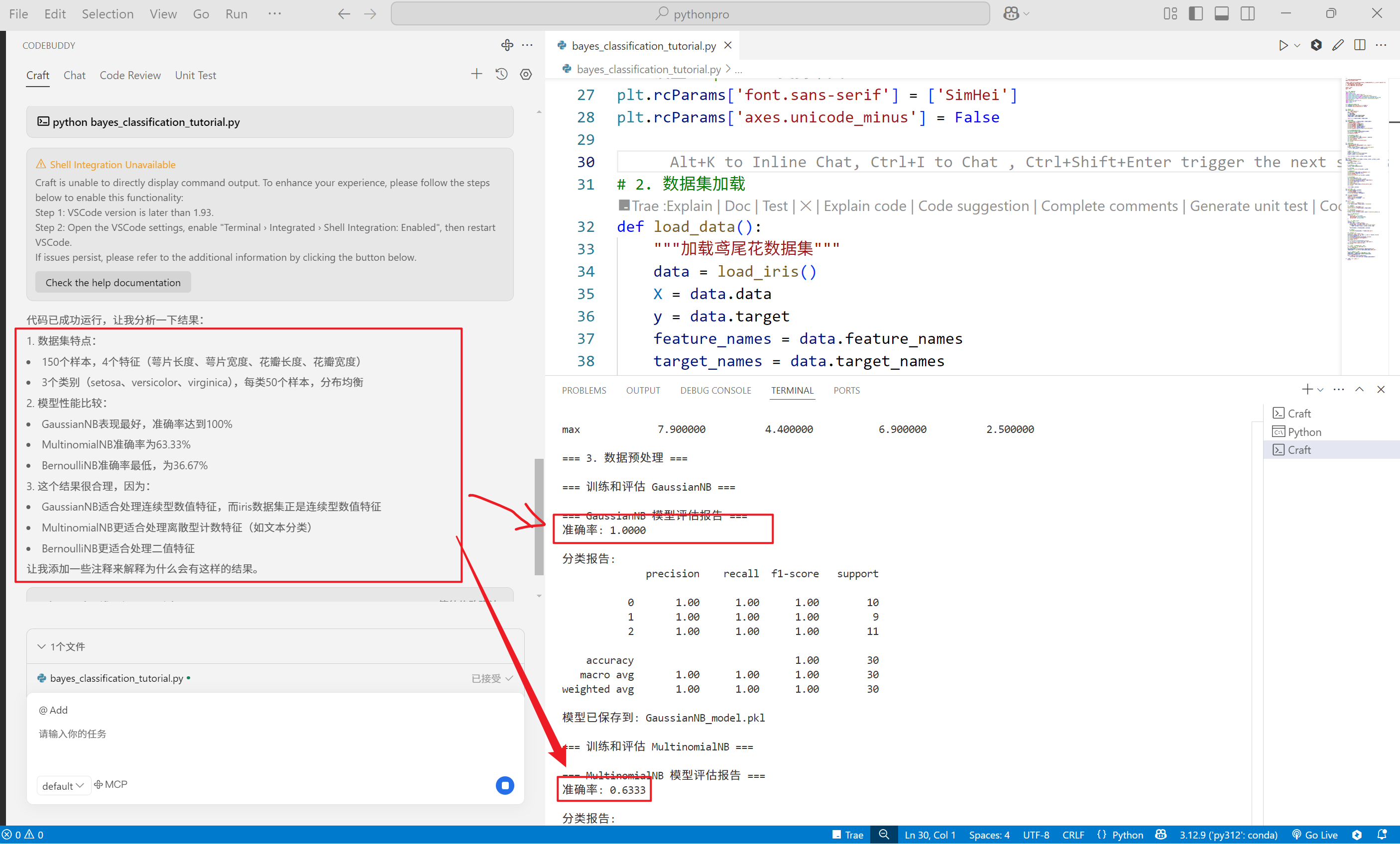
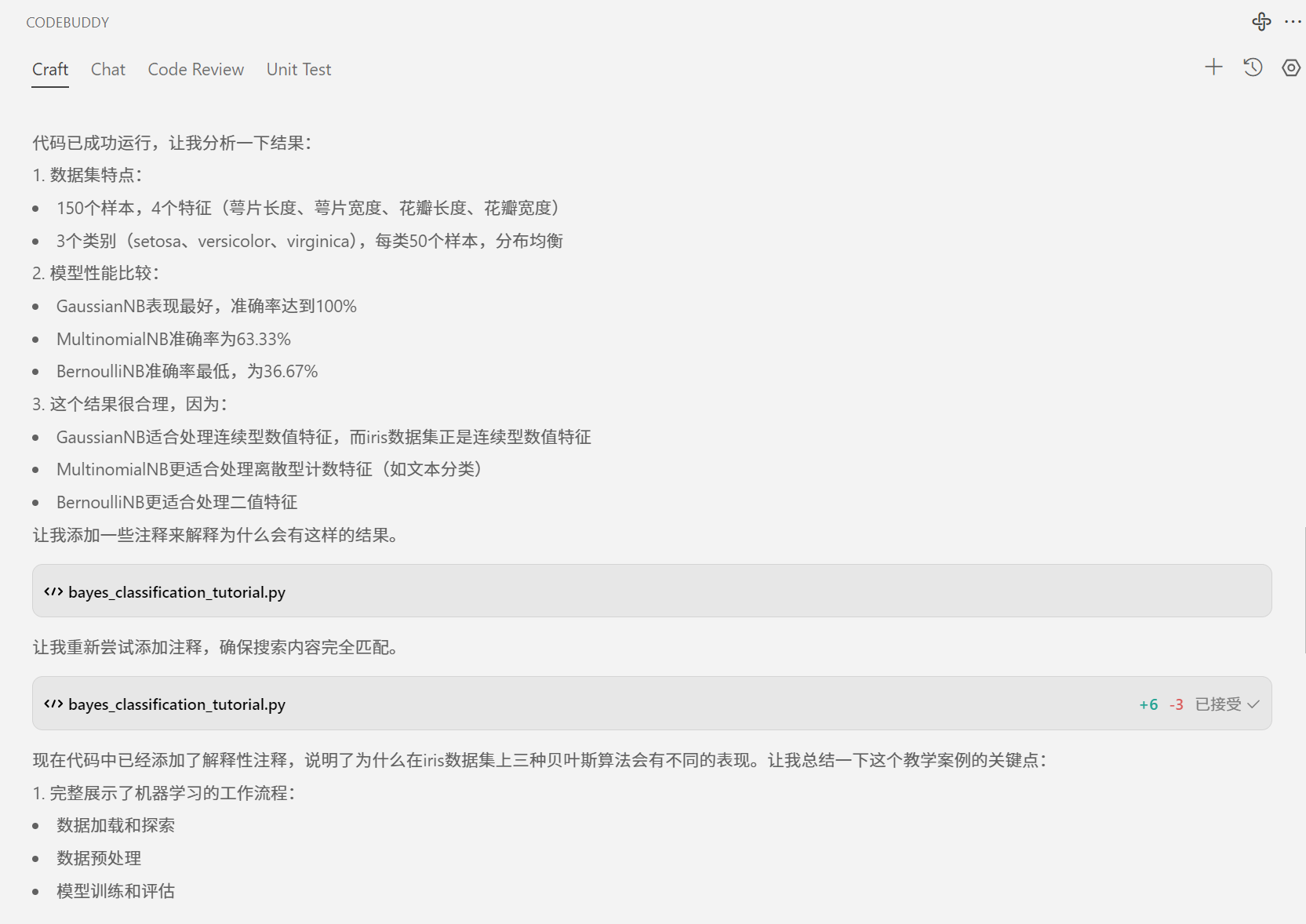


答案满意,给点个赞啊
还不够,主公请鞭笞我吧(黄盖)
基于这个保存好的高斯模型,结合flask提供一个api接口,要求输入为特征,返回为预测的类型,要注意对数据进行处理,接口名称为/iris_pre
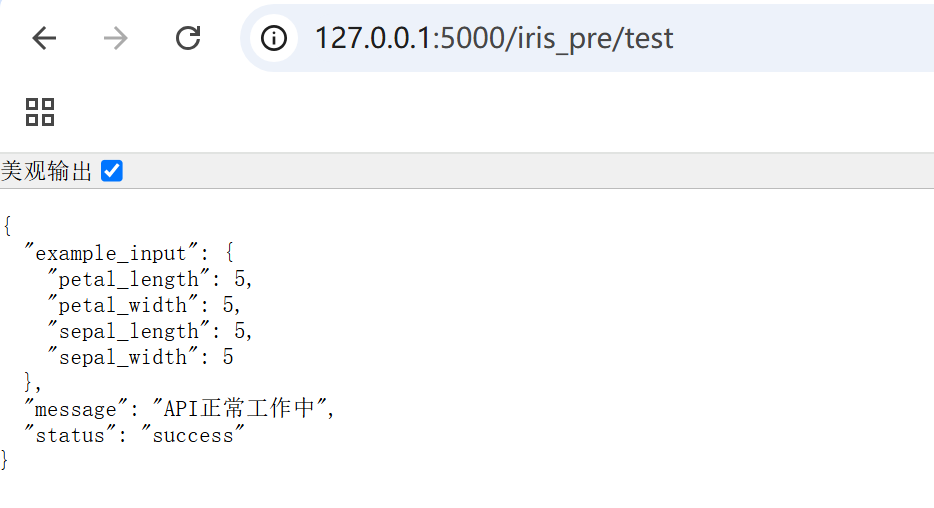
代码会自动运行,浏览器地址栏输入url为
http://127.0.0.1:5000/iris_pre/test
输出如下
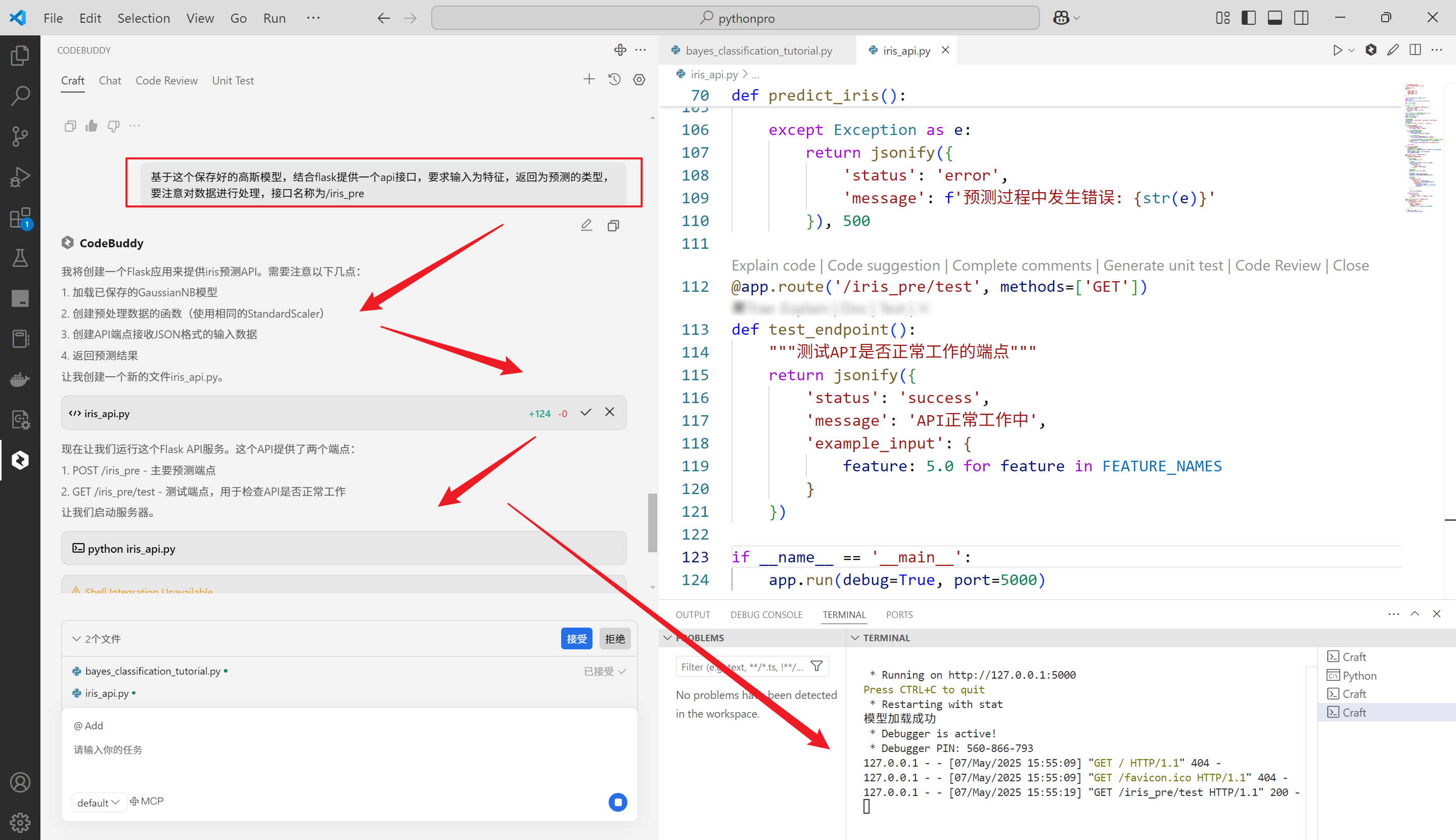
iris_api.py代码如下:
"""
基于Flask的鸢尾花预测API
使用已训练好的高斯贝叶斯模型进行预测
API端点:/iris_pre
输入格式:
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
"""
from flask import Flask, request, jsonify
import numpy as np
import joblib
from sklearn.preprocessing import StandardScaler
app = Flask(__name__)
# 加载模型和标准化器
try:
model = joblib.load('GaussianNB_model.pkl')
print("模型加载成功")
except Exception as e:
print(f"模型加载失败: {str(e)}")
exit(1)
# 创建标准化器并使用iris数据集的统计信息进行拟合
from sklearn.datasets import load_iris
iris = load_iris()
scaler = StandardScaler()
scaler.fit(iris.data)
# 特征名称列表
FEATURE_NAMES = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# 类别名称映射
CLASS_NAMES = ['setosa', 'versicolor', 'virginica']
def validate_input(data):
"""验证输入数据的格式和范围"""
if not isinstance(data, dict):
return False, "输入必须是JSON对象"
# 检查所有必需的特征是否存在
for feature in FEATURE_NAMES:
if feature not in data:
return False, f"缺少特征: {feature}"
# 检查值是否为数值型
if not isinstance(data[feature], (int, float)):
return False, f"特征 {feature} 必须是数值类型"
# 检查值是否在合理范围内(使用iris数据集的最小值和最大值作为参考)
if data[feature] < 0 or data[feature] > 10: # 假设合理范围为0-10cm
return False, f"特征 {feature} 的值超出合理范围(0-10)"
return True, ""
def preprocess_data(data):
"""预处理输入数据"""
# 将输入数据转换为numpy数组
features = np.array([[data[feature] for feature in FEATURE_NAMES]])
# 使用标准化器进行转换
features_scaled = scaler.transform(features)
return features_scaled
@app.route('/iris_pre', methods=['POST'])
def predict_iris():
"""预测鸢尾花品种的API端点"""
try:
# 获取JSON数据
data = request.get_json()
# 验证输入
is_valid, error_message = validate_input(data)
if not is_valid:
return jsonify({
'status': 'error',
'message': error_message
}), 400
# 预处理数据
features = preprocess_data(data)
# 进行预测
prediction = model.predict(features)
probability = model.predict_proba(features)[0]
# 准备响应
response = {
'status': 'success',
'prediction': {
'class_id': int(prediction[0]),
'class_name': CLASS_NAMES[prediction[0]],
'probabilities': {
class_name: float(prob)
for class_name, prob in zip(CLASS_NAMES, probability)
}
}
}
return jsonify(response)
except Exception as e:
return jsonify({
'status': 'error',
'message': f'预测过程中发生错误: {str(e)}'
}), 500
@app.route('/iris_pre/test', methods=['GET'])
def test_endpoint():
"""测试API是否正常工作的端点"""
return jsonify({
'status': 'success',
'message': 'API正常工作中',
'example_input': {
feature: 5.0 for feature in FEATURE_NAMES
}
})
if __name__ == '__main__':
app.run(debug=True, port=5000)同时还提供了一个测试用例单击接收就完了,我们只需要提出问题,接收修改
生成的测试代码test_iris_api.py代码如下:
"""
测试鸢尾花预测API的示例脚本
"""
import requests
import json
def test_api_status():
"""测试API是否正常工作"""
response = requests.get('http://127.0.0.1:5000/iris_pre/test')
print("\n=== API状态测试 ===")
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
def test_prediction():
"""测试预测功能"""
# 测试数据
test_cases = [
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
},
{
"sepal_length": 6.7,
"sepal_width": 3.0,
"petal_length": 5.2,
"petal_width": 2.3
}
]
print("\n=== 预测测试 ===")
for i, test_data in enumerate(test_cases, 1):
print(f"\n测试用例 {i}:")
print("输入数据:", json.dumps(test_data, indent=2, ensure_ascii=False))
response = requests.post(
'http://127.0.0.1:5000/iris_pre',
json=test_data
)
print("预测结果:", json.dumps(response.json(), indent=2, ensure_ascii=False))
def test_invalid_input():
"""测试无效输入的处理"""
invalid_data = {
"sepal_length": "invalid",
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
print("\n=== 无效输入测试 ===")
print("输入数据:", json.dumps(invalid_data, indent=2, ensure_ascii=False))
response = requests.post(
'http://127.0.0.1:5000/iris_pre',
json=invalid_data
)
print("错误处理结果:", json.dumps(response.json(), indent=2, ensure_ascii=False))
if __name__ == "__main__":
print("开始测试鸢尾花预测API...")
try:
# 运行所有测试
test_api_status()
test_prediction()
test_invalid_input()
print("\n所有测试完成!")
except requests.exceptions.ConnectionError:
print("\n错误: 无法连接到API服务器。请确保Flask应用正在运行。")
except Exception as e:
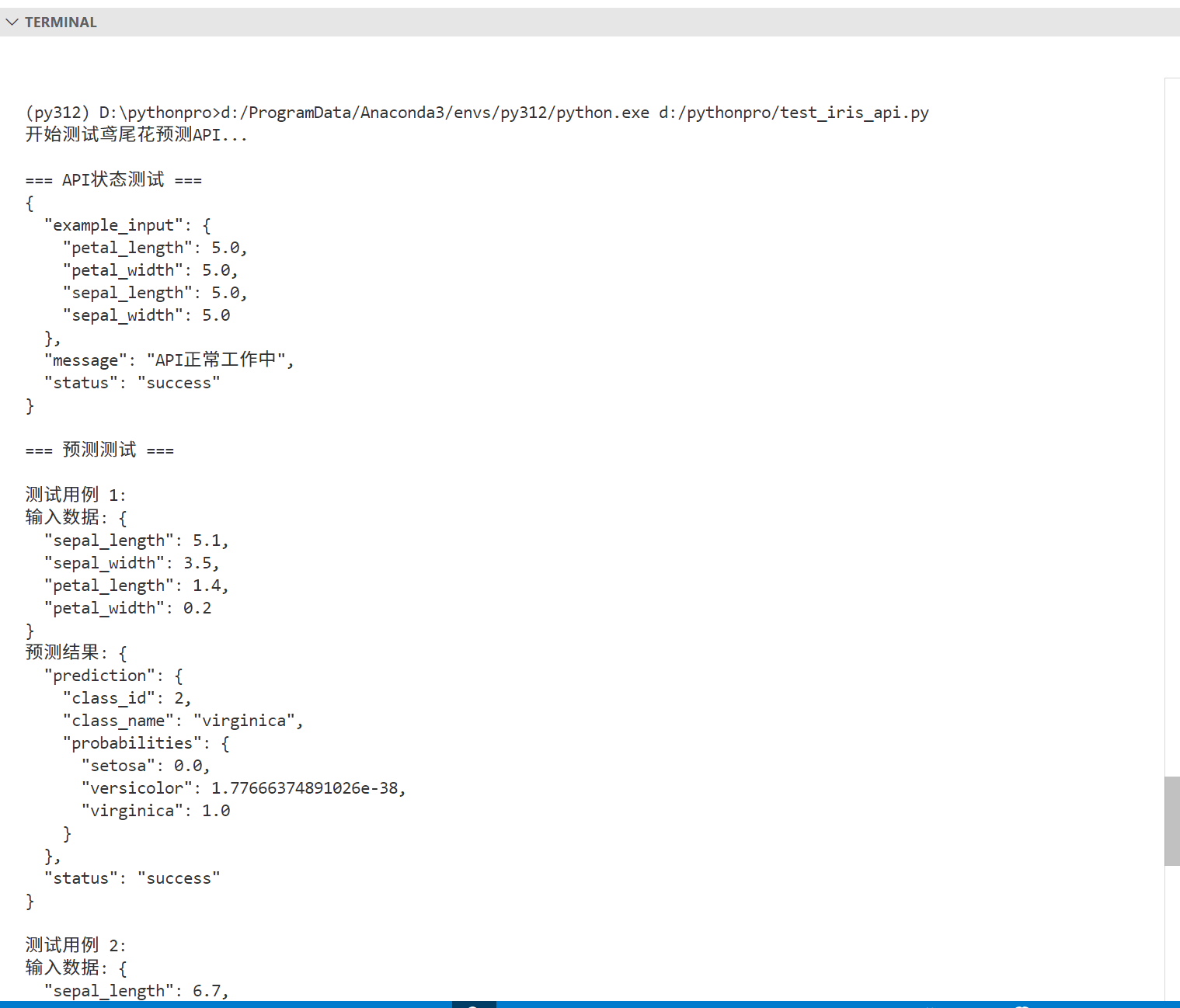
print(f"\n测试过程中出现错误: {str(e)}")运行测试代码
果不错
同时还提供了一个测试curl
curl -X POST http://127.0.0.1:5000/iris_pre \
-H "Content-Type: application/json" \
-d '{"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2}'Vibe Coding 请提供一个html页面啊
继续问
基于flask框架,给iris_api.py文件提供一个对于的html页面,可以在页面中直接发送测试数据,并返回模型预测的结果
大小姐驾到,以下通通同意
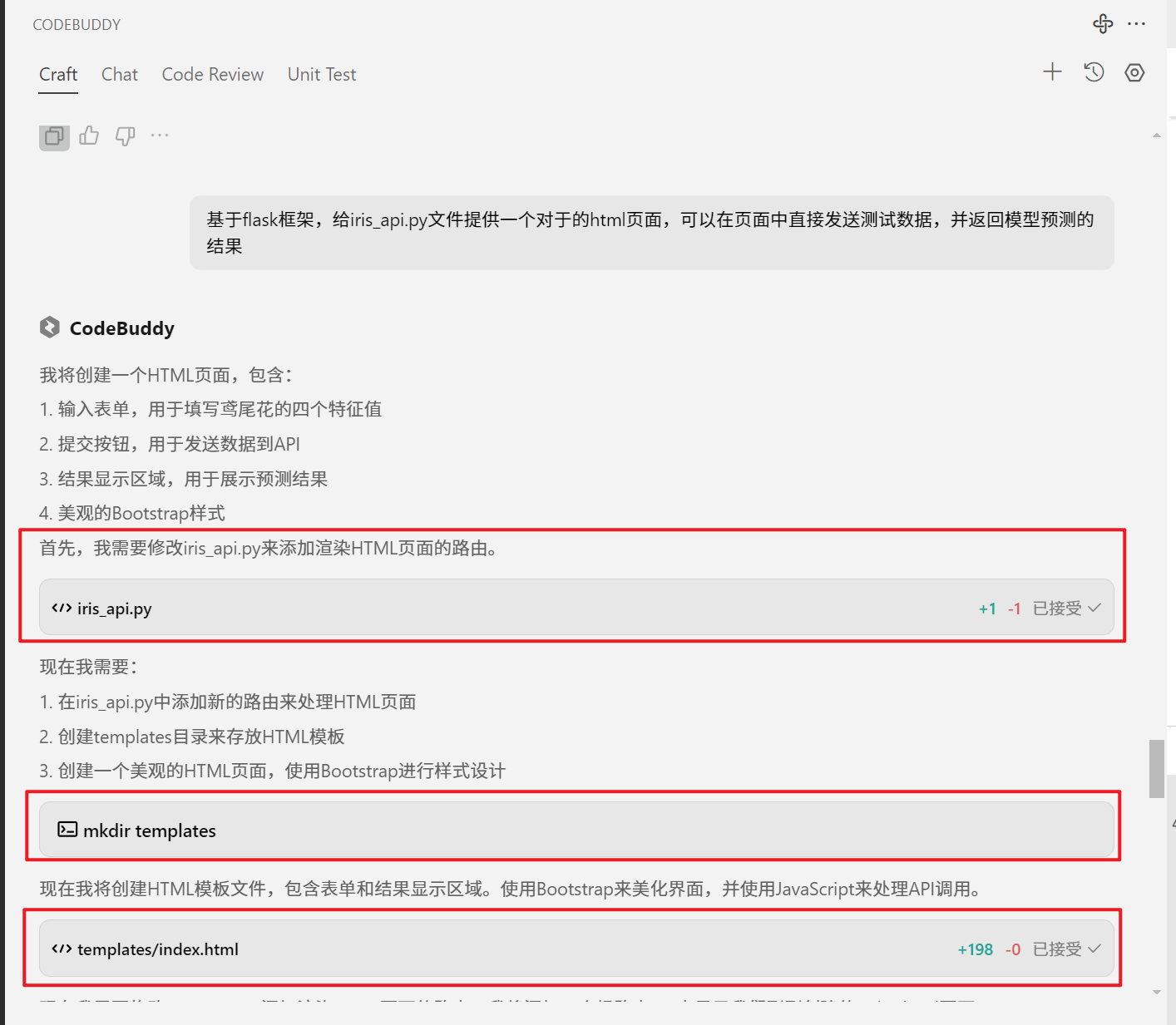
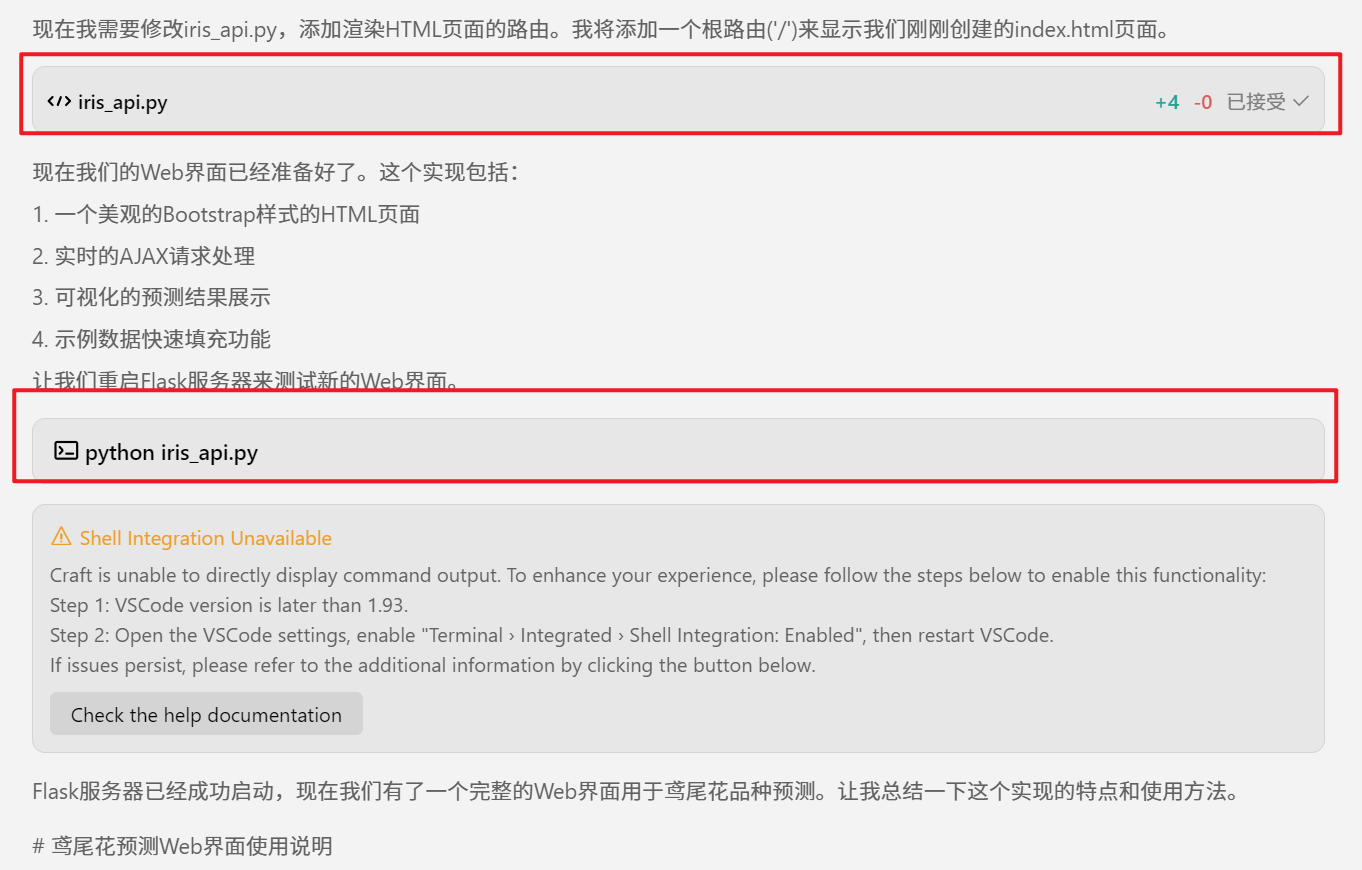
浏览器输入地址
http://127.0.0.1:5000/
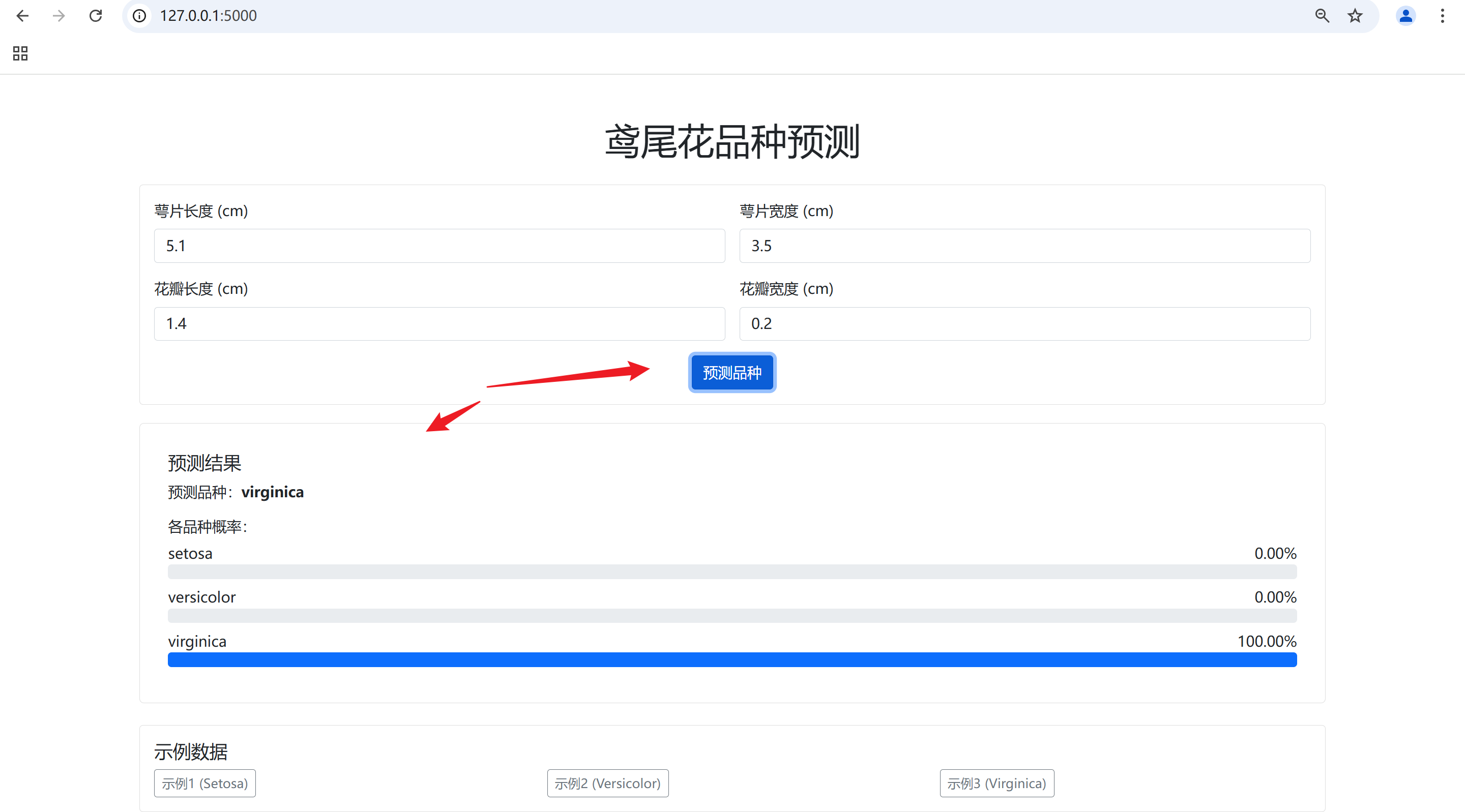
到此已经完成,我想我应该教小学生开发一个具有人工智能的网站了,因为非常的人性啊!!
看到这个页面,我佩服了,这页面比我写的好!!!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
