weibo_comment_pc_tool: 微博评论采集软件工具,指定帖子链接爬评论
原创
weibo_comment_pc_tool: 微博评论采集软件工具,指定帖子链接爬评论
原创
一、软件开发背景与功能概述
作为国内主流社交媒体平台,微博具有内容传播快、用户活跃度高的特点,其评论区更是公众观点表达的重要窗口。通过分析评论数据,可实现情绪趋势追踪、公众诉求挖掘、热点话题捕捉等研究价值。

基于此,本文介绍一款用Python开发的“爬微博评论软件”,支持根据帖子链接批量采集评论(含二级评论),并提供数据存储与分析功能。
二、软件界面与操作说明
2.1 界面布局
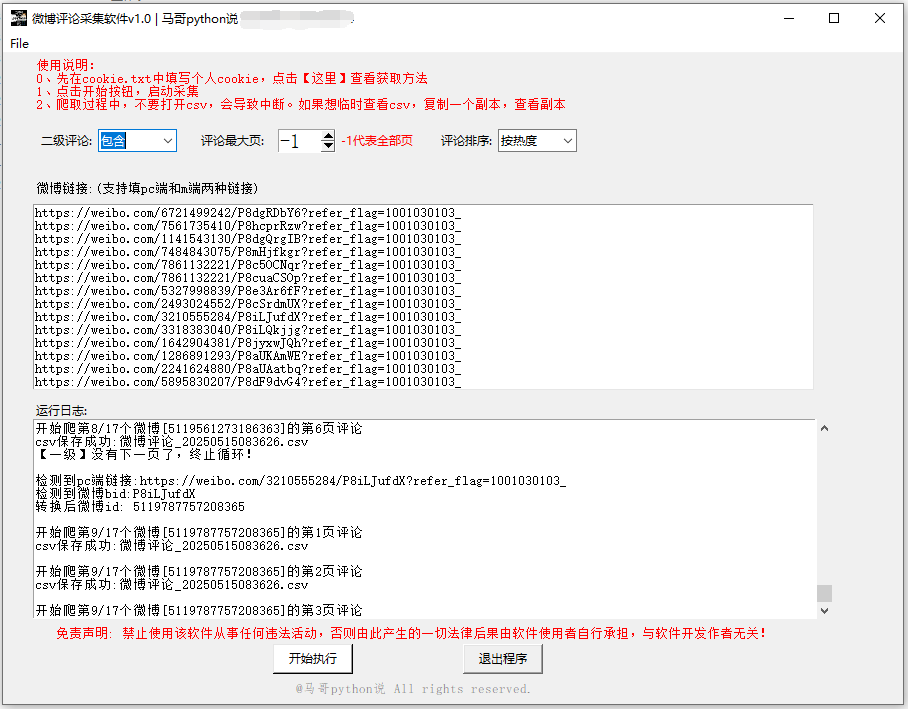
主要功能区包括:
- 参数设置:支持选择是否包含二级评论、设置评论最大页数(-1代表全部页)、按热度/时间排序评论。
- 链接输入:可批量粘贴PC端或移动端微博链接(示例:
https://weibo.com/...)。 - 运行日志:实时显示爬取进度、CSV保存状态及异常提示。
- 操作按钮:包含“开始执行”“退出程序”等功能键,底部标注版权信息。
2.2 使用流程
1、填写Cookie:
首次使用需在cookie.txt文件中填入个人微博Cookie(获取方法:通过浏览器开发者工具抓取微博请求中的Cookie字段,具体步骤见软件内说明)。
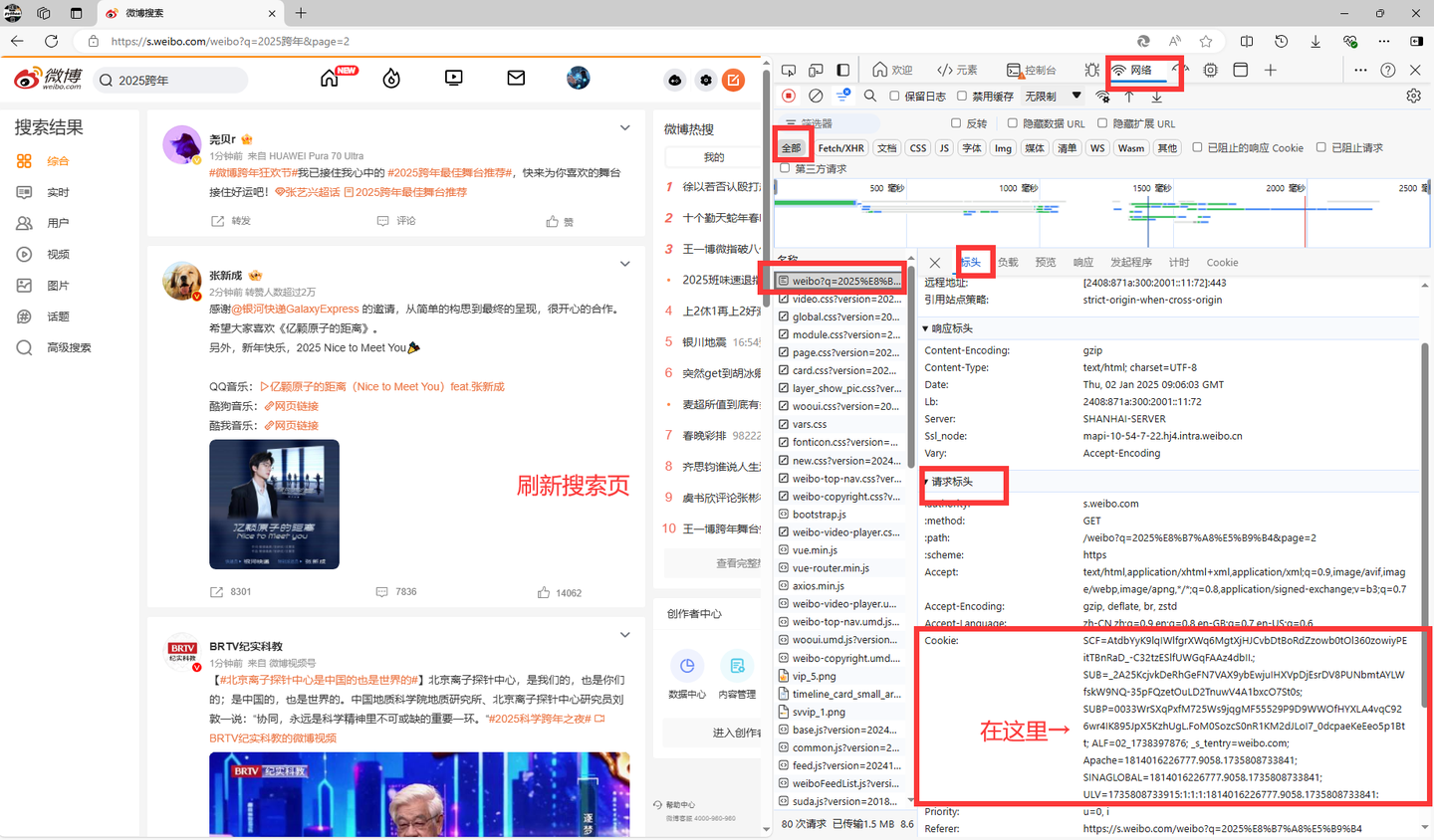
2、配置采集参数:
根据需求勾选二级评论、设置页码范围及排序方式,粘贴目标微博链接(支持多链接换行输入)。
3、启动采集:
点击“开始执行”,软件将按顺序爬取数据,每完成一页自动保存为CSV文件(避免中断丢失数据),日志区同步显示进度。
三、数据采集结果与格式
3.1 输出字段
采集结果包含14个维度数据,存储为CSV文件(示例字段如下):
微博链接 | 微博ID | 页码 | 评论者昵称 | 粉丝数 | 关注数 | 主页链接 | 性别 | 签名 | 评论时间 | 点赞数 | 内容IP属地 | 评论级别 | 评论内容 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 511956... | 6 | 用户名 | 30 | 626 |
| 女 | 个人签名 | 2025-01-07 07:51 | 0 | 河南 | 一级 | 评论内容文本 |
3.2 存储机制
- 每爬取一页自动保存一次CSV,文件以时间戳命名(如
微博评论_20250515083626.csv),便于追溯。 - 爬取过程中若需查看数据,需复制CSV副本,避免直接打开导致程序中断。
四、技术实现与模块架构
4.1 开发语言与工具
软件基于Python开发,核心模块包括:
- Tkinter:构建GUI界面,实现参数输入与交互。
- Requests:发送HTTP请求,获取微博评论数据接口响应。
- JSON:解析JSON格式的返回数据,提取评论内容及用户信息。
- Pandas:处理数据并保存为CSV文件,支持增量写入。
- Logging:记录运行日志,包含时间、文件、函数名及操作信息,便于故障排查。
4.2 关键代码示例
出于版权保护,仅展示部分代码:
# 发送请求与数据解析
r = requests.get(url, headers=h1, params=params)
json_data = r.json()
for data in json_data['data']:
text = data['text_raw'] # 提取评论内容
text_list.append(text)
# 保存数据至CSV
df = pd.DataFrame({
'微博链接': weibo_url,
'评论内容': text_list,
# 其他字段映射...
})
df.to_csv('结果文件.csv', mode='a+', index=False, encoding='utf_8_sig')五、软件特性与使用须知
5.1 核心优势
跨平台兼容:Windows 用户可直接运行 EXE 程序,无需 Python 环境。
稳定性强:经测试支持长时间运行,自动处理反爬机制(请求间隔 1-2 秒)。
灵活性高:支持多链接串行爬取、自定义采集范围及排序方式。
5.2 免责声明
本软件仅限学术研究与技术交流使用,严禁用于非法活动或商业用途。
因违规使用导致的法律风险,由使用者自行承担,与开发者无关。
六、文末声明
软件首发于公号 “老男孩的平凡之路”,如需技术交流或问题反馈,可与开发者 @马哥 python说(10 年 Python 开发经验,持续分享技术干货)联系。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
