基于 StarRocks + Iceberg,TRM Labs 构建 PB 级数据分析平台实践
原创
基于 StarRocks + Iceberg,TRM Labs 构建 PB 级数据分析平台实践
原创
StarRocks
发布于 2025-06-02 16:57:42
发布于 2025-06-02 16:57:42

作者:Vijay Shekhawat:TRM Labs 数据平台团队核心成员,精通实时流处理、数据湖仓架构及构建安全、高吞吐的数据分析管道,在推动 PB 级数据处理能力方面发挥了关键作用。
Andrew Fisher:TRM Labs 资深软件工程师,擅长大规模批处理数据加载与数据湖仓方案,为应对加密欺诈提供坚实的数据基础和分析能力。
导读:开源无国界,在本期“StarRocks 全球用户精选案例”专栏中,我们将介绍区块链情报公司 TRM Labs 的数据平台演进实践。
作为一家致力于打击加密金融犯罪的技术公司,TRM Labs 为全球金融机构、加密企业与政府部门提供链上数据分析与情报支持。其平台需处理来自 30 多条区块链的 PB 级数据,并以亚秒级响应支撑每分钟超过 500 次的查询请求。
最初,TRM 构建于分布式 Postgres 与 BigQuery 之上,并通过持续优化应对业务增长。但随着本地化部署与多环境需求的兴起,现有架构面临性能与成本的双重挑战。
为此,TRM 转向开源生态,基于 Apache Iceberg 与 StarRocks 构建新一代数据湖仓架构,用于支撑面向用户的分析业务。
本文主要围绕该方案的选型思路、架构设计与性能验证展开分享,并结合真实经验探讨为何这套体系值得更多团队参考与借鉴。在本系列的下一篇中,将聚焦架构的具体落地实践,包括如何基于对象存储部署 Apache Iceberg,以及如何优化 StarRocks 以支持本地部署等多环境需求。
一、第一代数据平台
TRM 的第一代数据平台采用分布式 Postgres(Citus Data)集群,支持快速点查与小规模预聚合。当查询负载超出集群承载能力时,大型查询和临时聚合任务则转交 BigQuery 处理。
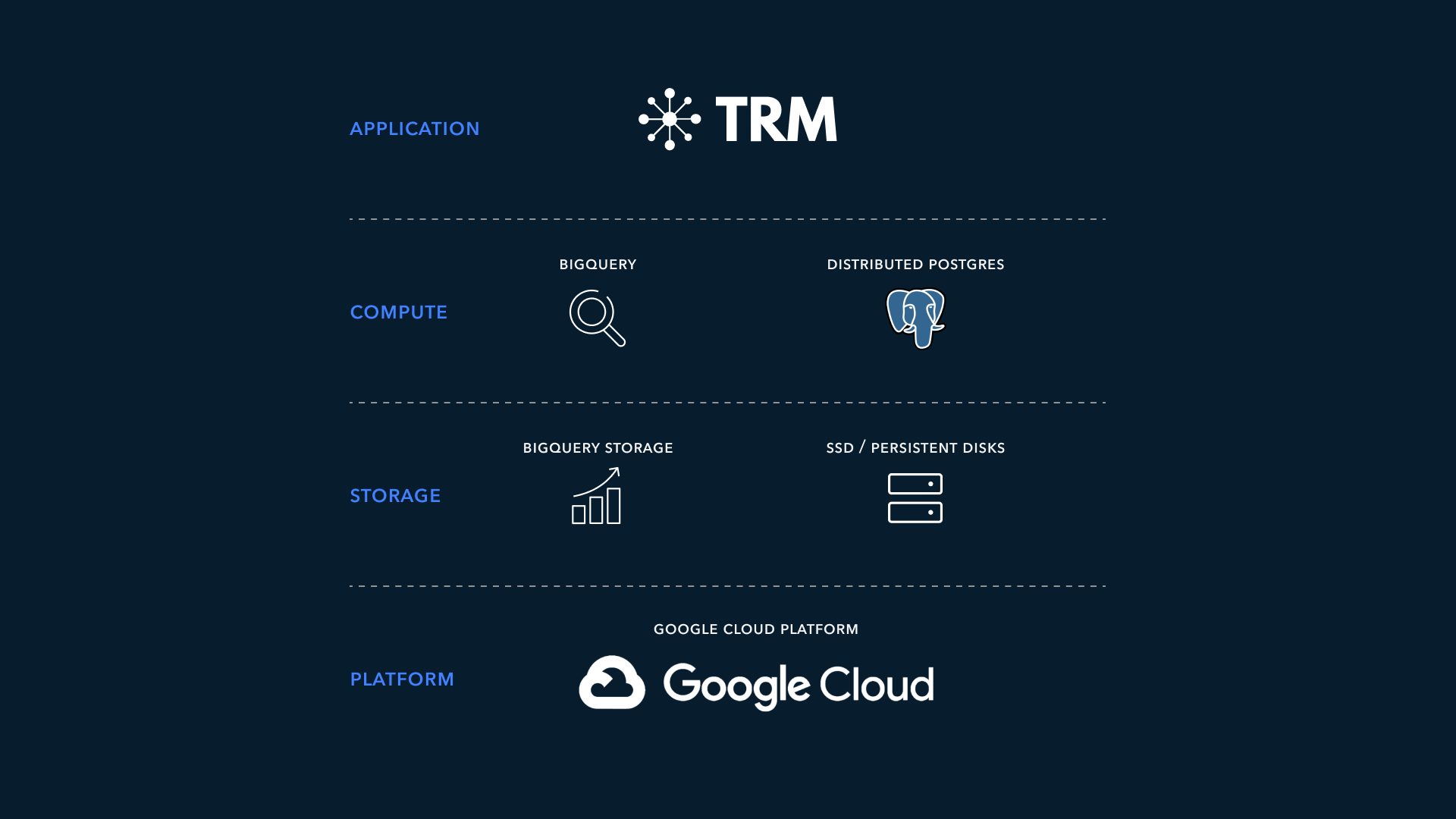
(图 1,展示了 TRM 第一代数据平台如何处理面向用户的分析,并通过 Postgres 和 BigQuery 路由查询)
二、从 BigQuery 迈向新一代开放式数据湖仓
尽管 BigQuery 多年来在客户分析场景中表现稳定,但随着平台向多环境部署(包括本地部署)扩展,其局限性日益显现。
我们需要在多个站点之间共享区块链分析数据,而 BigQuery 作为托管服务,并不适合这一需求。同时,面向用户的查询工作负载也需要全新的扩展方式。
2.1 架构转型背后的关键需求
- 多站点部署:平台需要在多个本地环境中部署,并保持数据共享能力,这要求我们采用可在 Kubernetes 上运行的开源解决方案。
- 可扩展性与性能:最大的面向客户的查询负载超过 115 TB,且每月增长 2~3%。相关查询通常包含复杂的多层级 Join,以及基于时间和数组的过滤条件。在高并发场景下,仅靠 BigQuery 实现 P95 延迟低于 3 秒,需要投入大量计算资源。而将这类负载迁移至分布式 Postgres,仅存储成本就非常高。
因此,我们的新一代数据平台必须兼顾数据湖的灵活性与数仓的性能与可靠性。我们基于 Apache Iceberg 构建现代化数据湖仓架构,借助其开放规范实现与多种查询与计算引擎的良好互通性。经过多轮对比测试后,我们最终选择 StarRocks 作为查询引擎。
Iceberg 与 StarRocks 的组合不仅满足了多站点部署和性能要求,也为平台的长期演进打下了坚实基础。
2.2 数据湖仓选型的优势
- 开放标准:Apache Iceberg 支持模式演进、Time Travel 和高效元数据管理,天然适配对象存储,便于在本地多站点环境中部署,满足跨地域区块链分析数据共享的需求。
- 高性能数据湖体验:StarRocks 具备全向量化执行引擎与高效缓存机制,提供超低延迟与高并发能力。结合 Iceberg 使用,既保留了数据湖的灵活性,也具备了数据仓库级的查询性能。
- 查询引擎解耦:Iceberg 的开放格式带来极强的查询引擎适配能力,使平台能够灵活接入如 Trino、DuckDB、ClickHouse 等多种引擎。过去一年,我们已观察到查询引擎领域的快速进化,后续也将持续评估更优方案,保持架构的技术前沿性与成本可控性。
- 显著的成本优化潜力:得益于 Iceberg 在对象存储上的高效布局,我们发现部分高读写负载可以从原有分布式 Postgres 集群中迁移至湖仓体系,从而显著降低对 SSD 存储的依赖。
三、为什么选择 Apache Iceberg + StarRocks
随着多环境部署(包括本地部署)成为核心需求,我们需要为面向客户的分析(customer-facing analytics)使用场景找到一个替代方案。
基于使用 BigQuery 和 Postgres 的经验,总结出以下几点关键观察:
- 查询时尽量减少数据读取量至关重要,可通过数据压缩、聚簇与分区优化扫描效率;
- 传统的 B-tree 索引在 PB 级别数据下效率低下;
- 向量化 CPU 执行(如 SIMD)能显著提升查询处理速度;
- 横向扩展能够在保持成本可控的同时,实现高并发处理能力
- 计算与存储解耦可灵活切换或组合查询引擎,无需复制数据,即可实现最佳负载性能。
基于上述洞察,我们不再局限于传统 OLAP 存储方案(如 ClickHouse),而是开始探索更具潜力的 Data Lakehouse 架构。重点关注两个方面:存储格式的选型,以及查询引擎的选择。
3.1 存储格式
随着高吞吐区块链的不断出现,TRM 的存储需求每年呈指数级增长。为支持更多区块链接入,必须确保存储系统具备良好的性能和成本可控性。
从成本出发,首先明确了需要从 SSD 迁移到对象存储——即便是最昂贵的对象存储,其价格也仅为最便宜 SSD 的四分之一。
在确定采用对象存储后,我们对当前构建数据湖仓最主流的三种表格式进行了评估。
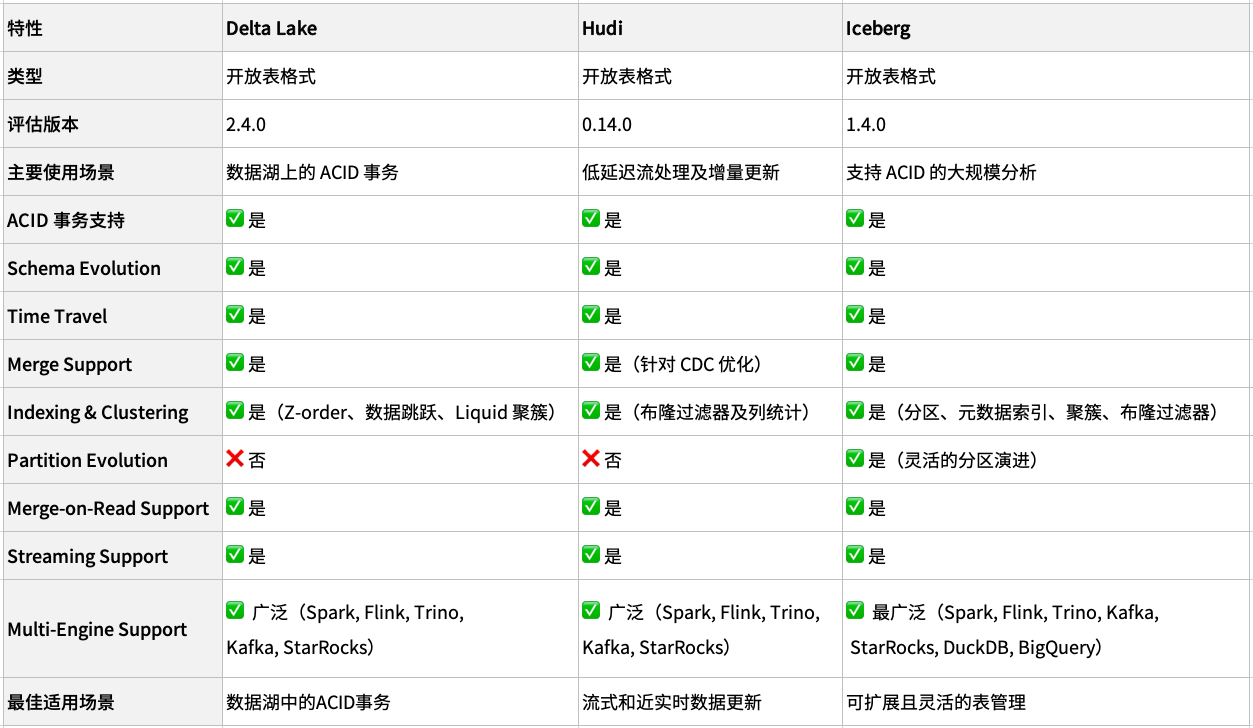
尽管 Delta Lake 在功能和性能上表现不错,但由于不支持分区演进,且在大规模分析与批处理场景中与 Iceberg 重叠较多,最终未被采纳。
随后测试了 Apache Hudi,即使在最佳配置下,查询性能仍比 Iceberg 慢约三倍。
综合考虑性能、生态与兼容性,我们最终选择了 Apache Iceberg:读取效率出色,社区活跃,且能良好适配各种元数据目录与查询引擎。
3.2 查询引擎
确定表格存储格式后,我们对多款支持 Iceberg 的开源查询引擎进行了基准测试,最终聚焦评估 Trino、StarRocks 和 DuckDB 三款引擎。测试结果显示,StarRocks 在多个维度上的表现始终优于其他引擎(见下方图 2)。
- Trino:一款开源的分布式查询引擎,设计用于处理超大规模数据集的查询任务。
- StarRocks:一款开源的高性能分析型查询引擎,支持数据湖仓内外的分析场景。
- DuckDB:开源的内嵌式分析型 SQL 查询引擎。
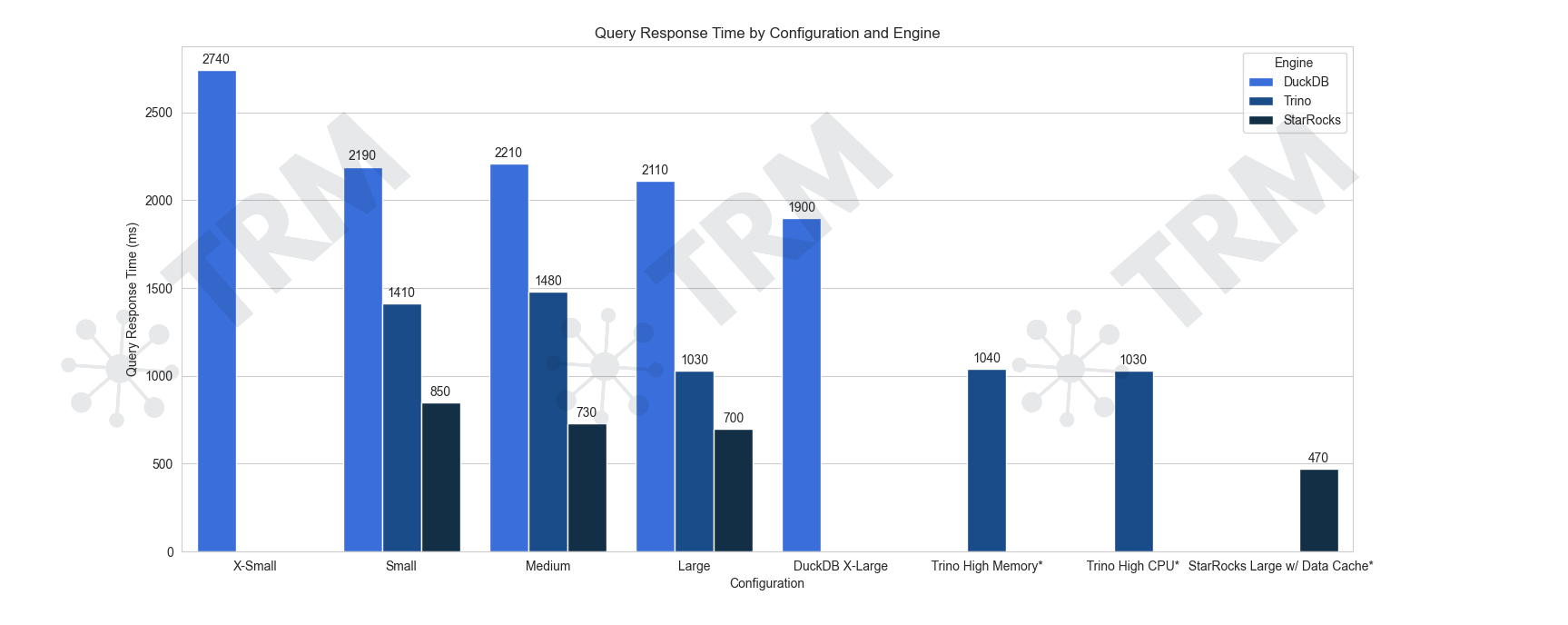
(图 2,展示了三款查询引擎在 2.57 TB 区块链分析数据集上,执行查找与过滤操作的性能对比。无论配置如何,StarRocks 的响应时间始终优于其他引擎,表现最为稳定出色。)
3.3 实验结果
测试聚焦于两类核心查询场景:带过滤条件的点查(point-lookup)和复杂聚合查询。通过 JMeter 进行负载压测,评估各查询引擎在高并发下的性能稳定性。
3.3.1 点查 / 过滤的实验探索
图 2 展示了在该类负载下的测试结果:对 2.57 TB 数据集执行点查与范围查找(range lookup)操作,评估查询子集的响应性能。结果如下:
- StarRocks:在所有配置中表现最优,启用数据缓存后响应时间最低可达 470 毫秒。
- Trino:响应时间在 1,410 毫秒至 1,030 毫秒之间,受集群规模影响较大。
- DuckDB:在高配单节点上表现尚可,查询时间为 2~3 秒。但由于当前对 Iceberg 表支持有限,测试在此阶段暂停。期待其未来支持谓词下推后,进行进一步评估。
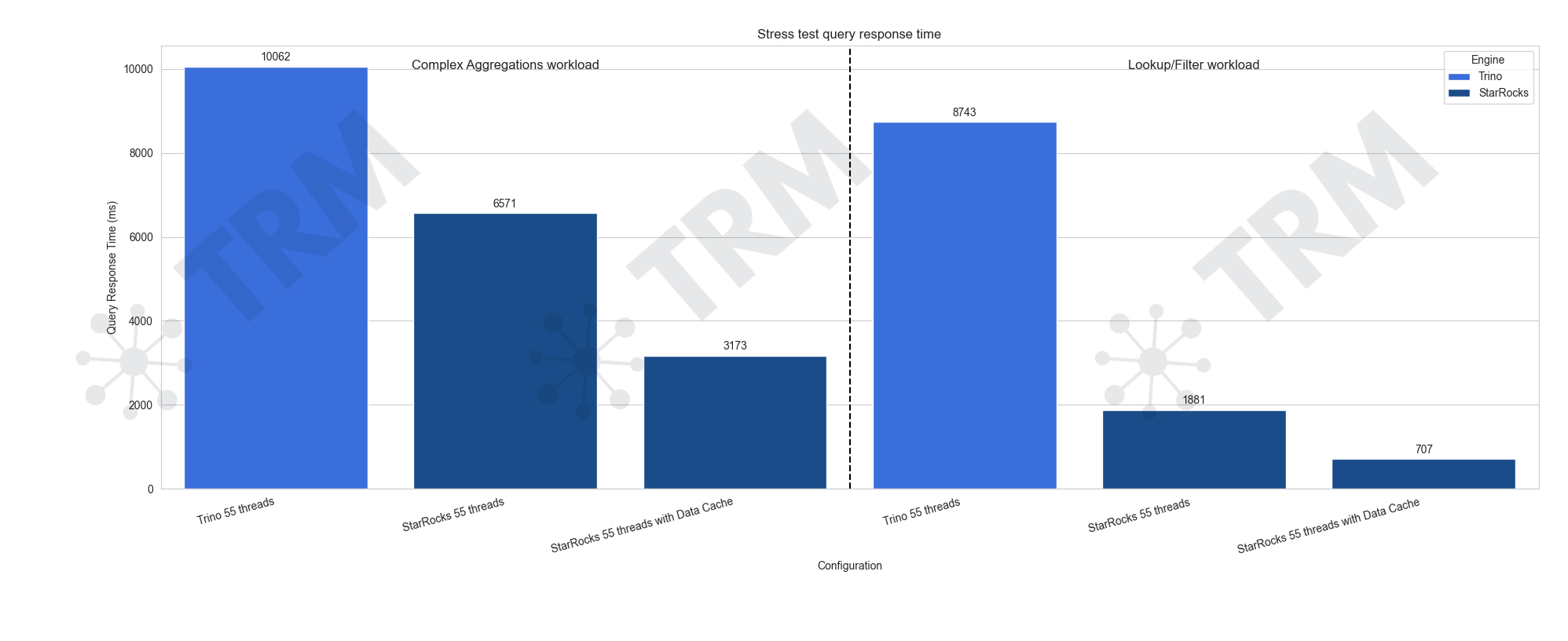
3.3.2 复杂聚合的实验探索
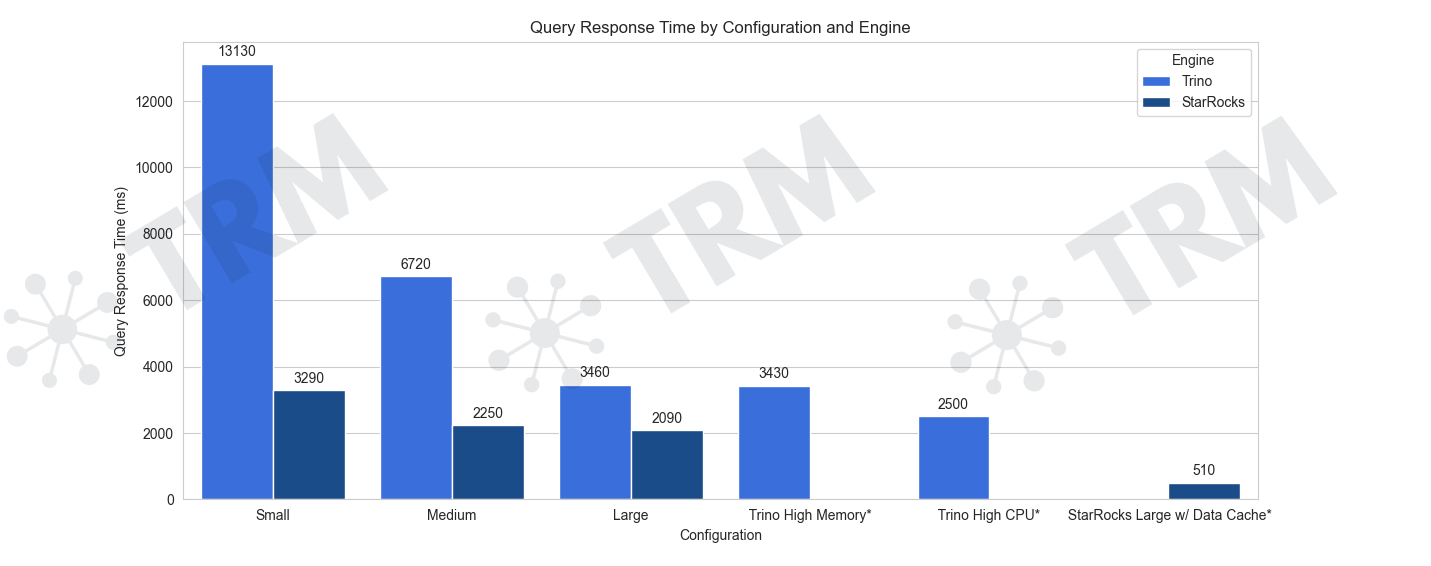
(图 3,在复杂聚合查询场景中,Trino 与 StarRocks 在不同集群配置下的基准测试对比结果。)
在本轮测试中,数据集扩展至 2.85 TB,查询包含 SUM、COUNT、GROUP BY 等聚合操作,并叠加数组与日期范围过滤条件。测试结果如下:
- StarRocks:在复杂聚合负载下表现出色。最大规模集群中,未启用缓存时延迟约 2 秒,启用缓存后最低降至 500 毫秒。
- Trino:随着集群扩容,性能有所提升,但整体仍存在瓶颈,查询延迟难以突破 2.5 秒。
3.3.3 压力测试
采用 JMeter 对 Trino 与 StarRocks 在高并发场景下进行性能压力测试,结果如下:
- StarRocks:无论是点查还是聚合负载,在高并发下均优于 Trino,启用数据缓存后性能进一步提升。
- Trino:并发用户数增加时,性能下降明显。测试时(2024 年初)尚不支持数据湖表的缓存功能,该能力已在 Trino 版本 439 中加入,但尚未进行评估。
四、未来规划

(图5,面向用户分析场景的下一代数据平台架构)
在综合评估三种开源表格式及多款查询引擎后,我们最终选定 Apache Iceberg 与 StarRocks 作为核心组件,构建 TRM 的下一代数据平台,既满足多站点部署需求,又显著提升客户侧分析性能。
- 数据湖仓融合,兼顾灵活性与性能:采用 Data Lakehouse 架构,融合数据湖的灵活性与数据仓库的高性能,为客户提供稳定、敏捷的分析体验。
- Apache Iceberg:具备开放标准、强大的模式演进能力和高效的元数据管理,满足跨引擎兼容需求。
- StarRocks:通过优化 Iceberg 表的分区与聚簇设计、合理配置集群规模并启用缓存策略,实现低延迟、高并发。这些优化带来显著收益——P95 响应时间提升 50%,查询超时减少 54%,助力达成性能目标。
- 真实测试不可或缺:标准基准测试难以覆盖实际使用模式,唯有在真实工作负载中才能发现关键优化点。
在本系列的下一篇中,我们将聚焦架构落地实践,包括如何基于对象存储部署 Apache Iceberg,以及如何优化 StarRocks 实现多环境支持(如本地部署等)。
为便于阅读,本文删减了许多原文中对实验细节的详细描述。感兴趣的读者可参考原文了解更多信息:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号