大模型多模态统一架构全景
原创

目前大模型在处理多模态的时候,都统一化成了 token 的形式进行处理。我们首先先来看看目前常规主流的大模型是怎么统一多模态的
MLLM模型常见架构
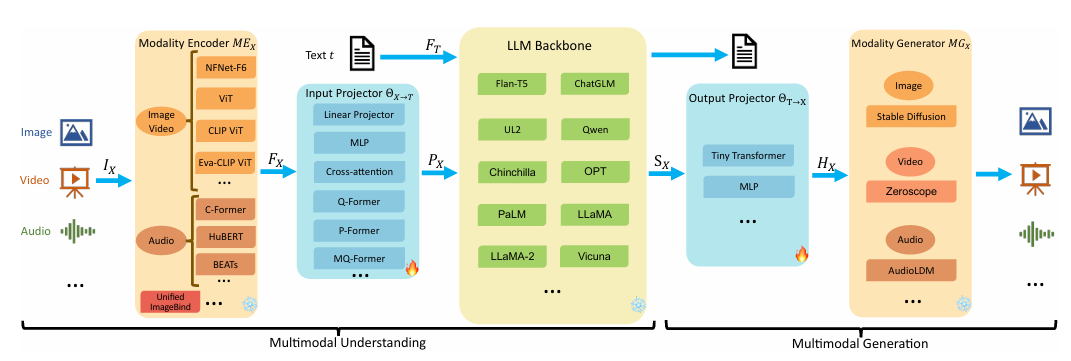
● 模态编码器(Modality Encoder):将多模态的数据编码成向量空间特征,该模块通常是单独进行预训练的,典型的方法有基于CNN的ResNET,基于Transformer的ViT等。
● 输入投影层(Input Projector):将模态编码器的输出映射到LLM的输入特征空间的适配层,一般模型结构比较简单,不同的多模态模型一般是随机初始化该模块的参数做冷启训练。典型的网络层:MLP,Cross-Attention等
● LLM主干网络(LLM Backbone):LLM是经过预训练的模型,一般还要串联多个模块继续做Post-Pretrain和微调,使得模型能识别多模态的特殊token和多模态的特征输入。
● 输出投影层(Output Projector):将LLM生成的数据,映射成Modality Generator 可理解的特征空间,一般是简单的Transformer层或MLP层。
● 模态生成器(Modality Generator):多模态的生成器,最终输出多模态的结果如图像、语音、视频等。模型基本都是基于LDM(Latent Diffusion Models)的衍生模型,如图片领域的Stable Diffusion方法。
可以看到,不同模态都会经过一个编码器,然后输入到投影层中。这个投影层最开始其实是来源于 Blip 架构。它提出的是一个图像、文本对齐的方式。可以看到其框架是利用了一个 Q-Former 架构,然后把图像 token、文本 token 投影到这个架构中,进行有效对齐。
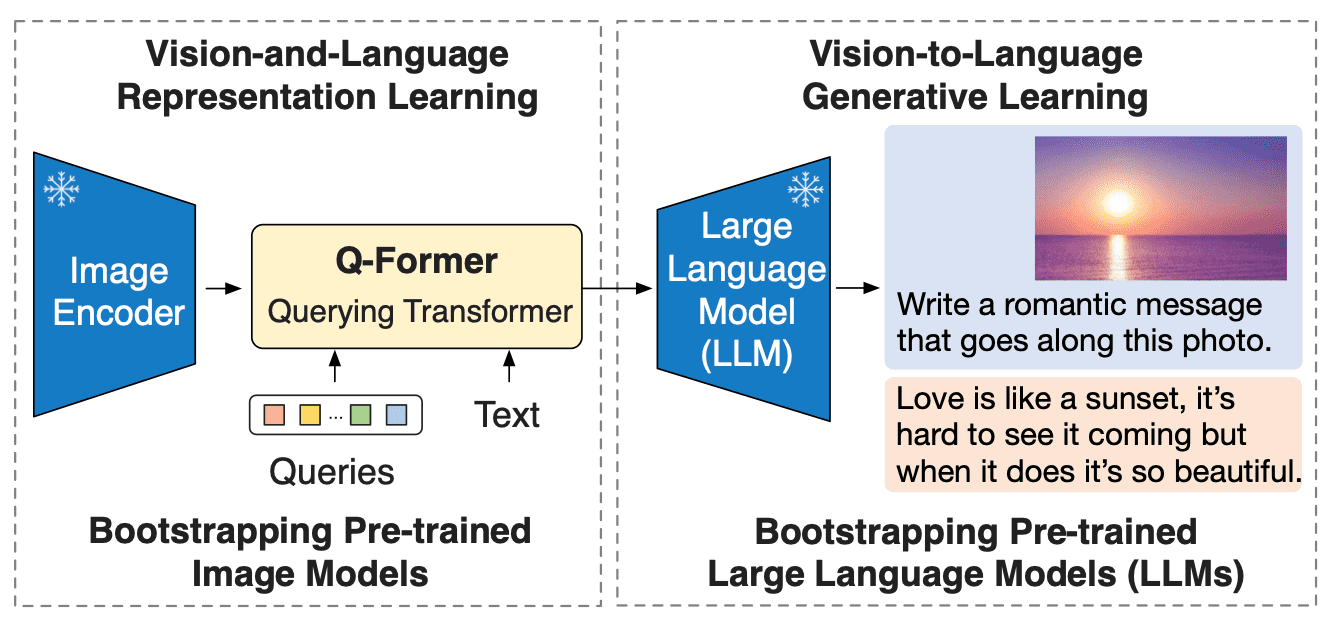
这样做不仅能够统一多模态之前的差异性,更能够把 token 进行有效压缩,使得模型在提升效果的同时、其 token 不至于过大,保证了一定的推理速度。
慢慢的,就演变成主流的大模型基本都是用这一套类似的架构进行有效的对齐和压缩。
比如qwen-vl 模型的训练,用的也是类似的架构,然后采用了多步进行多模态对齐。
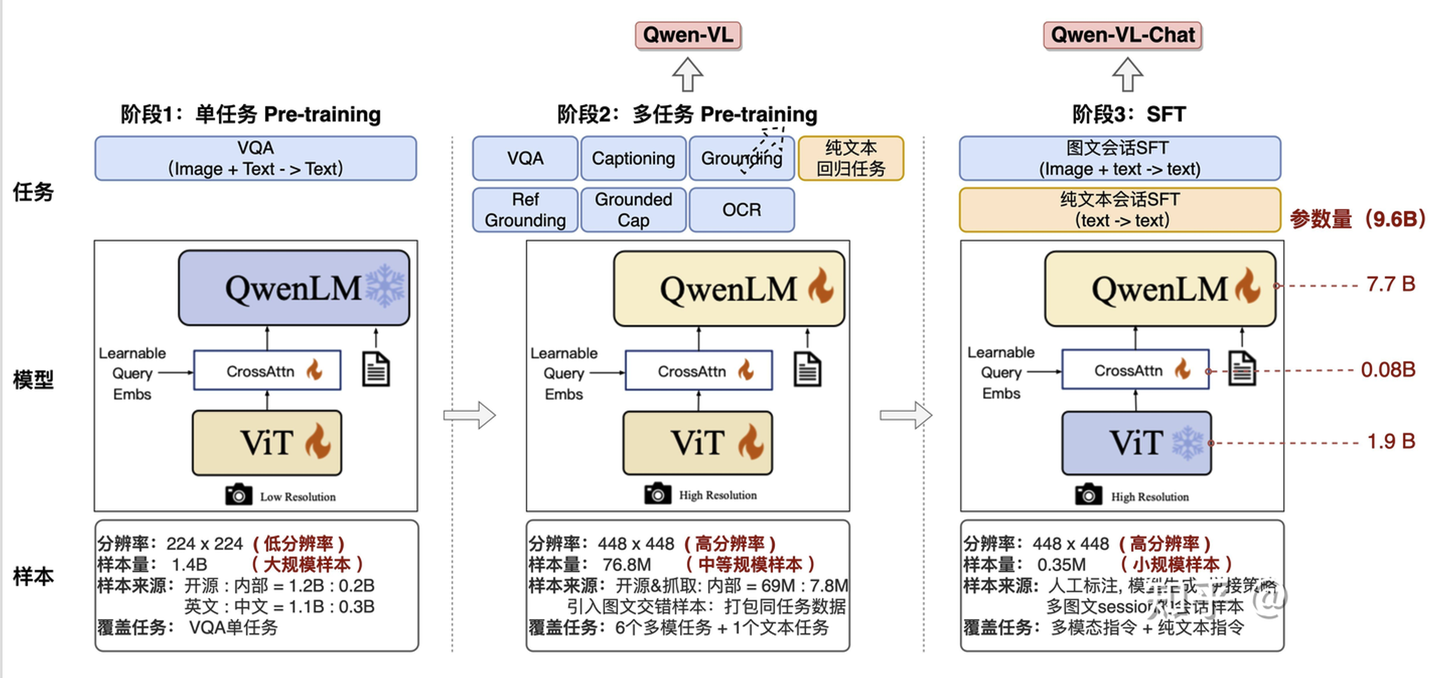
阶段 1:单任务 Pre-training
- 任务:纯粹的 VQA,能够有效学习视觉模态编码器 VIT
- 模型结构:
- ViT(低分辨率 224×224 输入,图中带❄️表示此时 ViT 权重仅少量更新或冻结)
- Cross-Attention 层(Learnable Query Embeddings)
- QwenLM(语言模型头)
阶段 2:多任务 Pre-training
- 包含了多重不同模态的任务:VQA、Captioning(图文描述)、Ref Grounding、Grounded Caption、OCR 以及“纯文本自回归”
- 模型结构:
- ViT(高分辨率 448×448 输入,图中带 表示此时 ViT 权重全部参与训练)
- 同样的 Cross-Attention + QwenLM
阶段 3:做最后的微调SFT(Supervised Fine-Tuning)→ 生成 Qwen-VL-Chat
- 任务:
- 图文对话 SFT(Image + Text → Text)
- 纯文本对话 SFT(Text → Text)
通过这样逐步从“大规模单一任务”→“中等规模多任务”→“小规模高质量指令调教”,Qwen-VL 不仅在视觉理解和图文生成上打下坚实基础,也最终能胜任“图文对话”场景,形成 Qwen-VL-Chat。
这种多阶段训练方法,大部分主流的大模型基本都是这样做出来的。其优点其实很明显:
- 泛化能力强:通过大规模图文对进行训练,具备较强的图文统一建模能力,能处理丰富的跨模态生成任务,如图像描述、图像问答、图像改写、图文对话等。
- 任务统一性:通常采用统一的 Transformer 编码/解码结构,可在单模型内同时处理识别类与生成类任务(如 BLIP-2)。
- 对下游任务迁移能力好:预训练后可少量微调迁移至多种任务(零样本/少样本 VQA、图文匹配、图文生成等)。
- 与语言大模型天然融合:可对接 LLM,支持图文联动理解与复杂推理,增强语义一致性。
当然,不同大模型也有自己的对于多模态融合的方法,像 Qwen-VL 中使用的是 M-Rope 位置编码,能够把图像、视频、文本进行统一编码。

Qwen2-VL 中的多模态设计有多个优点:
1)采用原生动态分辨率:单一分辨率 -> 任意分辨率, Qwen-VL模型输入只接受单一分辨率的图片,Qwen2-VL可输入不同分辨率的图像,避免了Vision数据适配单一分辨率而导致的失真问题。
2)Vision Encoder位置编码:绝对位置编码 -> 相对位置编码,从二维三角位置编码升级到二维RoPE位置编码,RoPE对长序列有更好的泛化能力,有利于提升对长序列Vision特征的建模能力
3)LLM主体模型位置编码:1D->3D RoPE,引入多模态旋转位置编码技术(M-RoPE),刻画多模态(时序、高、宽)三维数据。进一步提升对时空数据的建模能力。
4)统一多模态数据: 单图片 -> 统一图片和视频,统一框架处理图片和视频数据,进一步提升对真实世界认知和理解能力训练数据: 1.4B -> 1.4T,数据量提升了3个量级,同时数据覆盖了多领域任务。
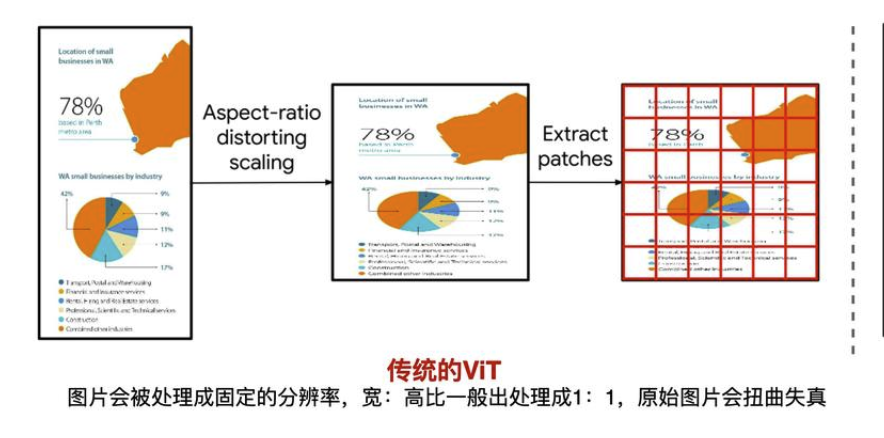
Qwen-VL使用的视觉编码器是标准的ViT,这要求输入的图片要统一处理成单一的、固定的分辨率,才能feed到模型进行处理。一般标准的预训练好的ViT,通常是将图片处理成正方形(长:宽=1:1)。
也可以像Video-ChatGPT那样,在空间、时序上做pooling,类似于3D卷积的操作也是可以的
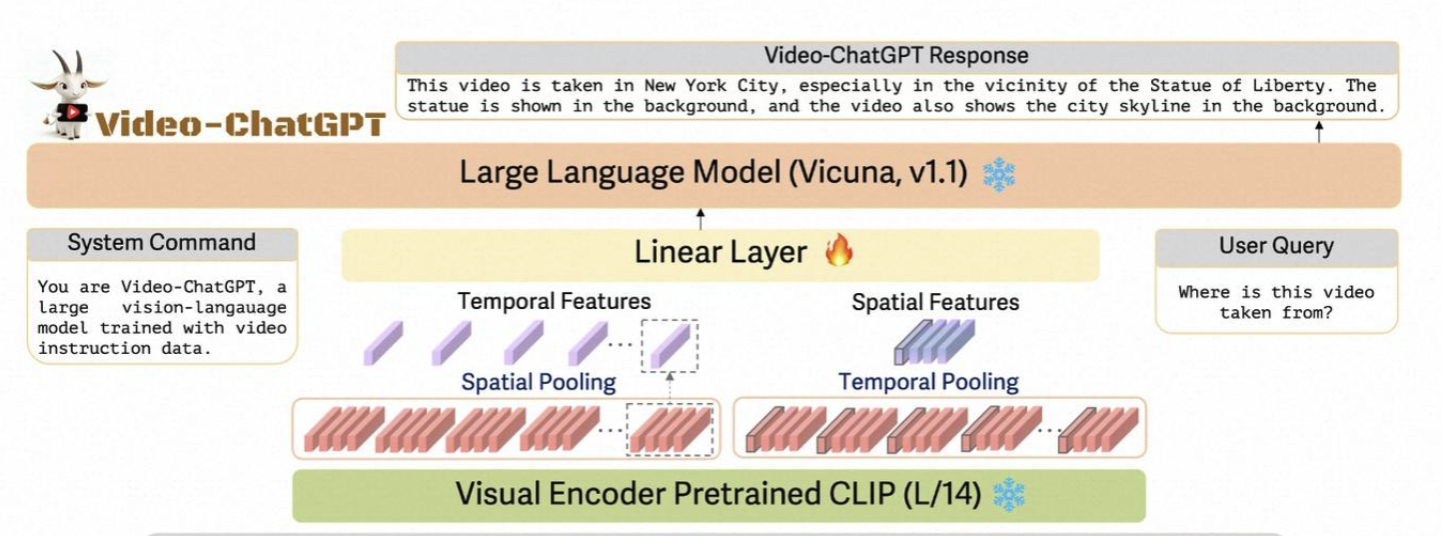
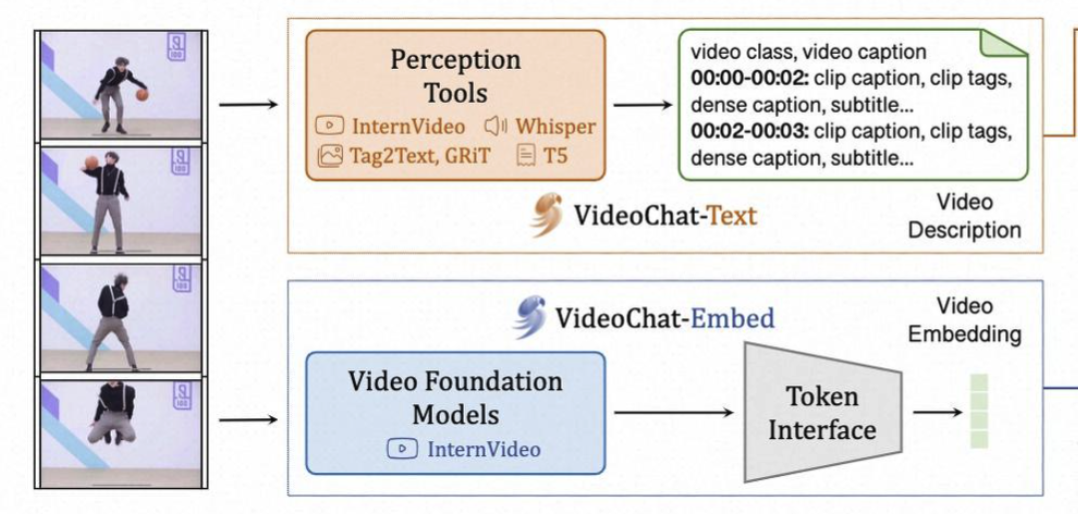
或者进一步通过输入任务改造:引入更加详细的关键帧信息,让LLM学习精细化特征。(VideoChat)
比如得到每一帧的图像描述,包括动作、位置坐标等等,然后构造不同任务让LLM进行学习
当然要说哪种方法好,我感觉模型达到了一定参数量下,不管采用哪些方法都是有效的。最后还是要看你用大模型做什么,怎么适配专用领域的数据才是需要考虑的地方。
写在最后
从目前的研究与产业实践来看,多模态统一的核心目标,其实就是“如何把不同模态的信息最大化整合到一个语言模型里”。各家方案的底层逻辑非常一致:先对各模态进行编码,再通过投影与跨模态对齐层(如Q-Former、Cross-Attention),最终统一到LLM的token序列中进行融合计算。
但是,不同架构之间依然存在诸多细节差异:
- 输入侧差异: 有的模型采用固定分辨率ViT(如Qwen-VL),有的模型设计了动态输入分辨率(如Qwen2-VL),还有模型直接对视频输入进行3D卷积或者空间时序pooling(如Video-ChatGPT),以减少token数量,保证训练效率。
- 位置编码策略: 从最早的绝对位置编码,发展到相对位置编码(2D RoPE、3D M-RoPE),这些技术突破不仅提升了长序列输入的能力,也使多模态在空间、时序维度上的建模更为自然,减少了因位置嵌入差异带来的模态割裂感。
- 任务设计差异: 例如VideoChat通过为每帧生成详细图像描述、动作、目标位置坐标,结合不同任务设计(动作识别、目标检测、意图理解等),让LLM获得更精细的跨模态对齐能力,而不仅仅停留在单纯的Caption或VQA。
这些差异背后的核心,依旧是工程取舍与目标任务差异
就像Qwen-VL、Video-ChatGPT、CogVLM、InternVL这些多模态大模型的实践所证明的那样:
“没有最优架构,只有最适合当前任务和数据的架构。”
对于企业或研究团队来说,与其纠结于使用哪种特定的多模态融合方法,不如结合自身场景需求,找到最合理的输入模态组织、token压缩方式以及预训练任务设计,才是真正落地与产生价值的关键。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号