【愚公系列】《Python网络爬虫从入门到精通》003-请求模块urllib
原创
【愚公系列】《Python网络爬虫从入门到精通》003-请求模块urllib
原创
标题 | 详情 |
|---|---|
作者简介 | 愚公搬代码 |
头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在进行网络编程和数据抓取的过程中,如何高效地发送请求和处理响应是每个开发者必须掌握的技能。而在Python中,urllib模块作为标准库的一部分,提供了强大而灵活的功能,让我们能够轻松地与互联网进行交互。
本文将深入探讨urllib模块的使用,包括如何构造URL、发送HTTP请求、处理响应数据,以及一些常见的应用场景。
🚀一、请求模块urllib
🔎1.urllib 简介
在 Python 2 中,有两个模块用于实现网络请求的发送:urllib 和 urllib2。这两个模块各有特色:
- urllib:只能接收一个 URL,不能伪装用户代理等字符串操作。
- urllib2:可以接收一个
Request对象,通过这种方式可以设置一个 URL 的Headers。
在 Python 3 中,将 urllib 和 urllib2 模块的功能进行了组合,并命名为 urllib。新的 urllib 模块包含了多个功能子模块,具体内容如下:
🦋1.1 urllib.request
用于实现基本 HTTP 请求的模块。通过这个模块可以发送 GET、POST 等请求。
示例代码:
import urllib.request
# 发送 GET 请求
response = urllib.request.urlopen('http://example.com')
html = response.read()
print(html)🦋1.2 urllib.error
异常处理模块。如果在发送网络请求时出现了错误,可以捕获异常进行有效处理。
示例代码:
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://example.com')
except urllib.error.URLError as e:
print(e.reason)🦋1.3 urllib.parse
用于解析 URL 的模块。可以拆分和构建 URL。
示例代码:
from urllib.parse import urlparse, urlencode
# 解析 URL
url = 'http://www.example.com/index.html;user?id=5#comment'
parsed_url = urlparse(url)
print(parsed_url)
# 构建 URL 参数
params = {'name': 'John', 'age': 25}
query_string = urlencode(params)
print(query_string)🦋1.4 urllib.robotparser
用于解析 robots.txt 文件,判断网站是否可以爬取信息。
示例代码:
import urllib.robotparser
rp = urllib.robotparser.RobotFileParser()
rp.set_url('http://www.example.com/robots.txt')
rp.read()
# 判断某个 URL 是否允许爬取
url = 'http://www.example.com/some-page'
is_allowed = rp.can_fetch('*', url)
print(is_allowed)通过对 urllib 模块的功能子模块的了解和使用,可以更加灵活地进行网络请求、错误处理、URL 解析以及网站爬取合法性判断。
🔎2.使用 urlopen() 方法发送请求
urllib.request 模块提供了 urlopen() 方法,用于实现最基本的 HTTP 请求,并接收服务器返回的响应数据。urlopen() 方法的语法格式如下:
urllib.request.urlopen(url, data=None, timeout, *, cafile=None, capath=None, cadefault=False, context=None)参数说明如下:
- url: 需要访问的网站的 URL 完整地址。
- data: 该参数默认值为
None,通过该参数确认请求方式。如果是None,表示请求方式为 GET,否则为 POST。在发送 POST 请求时,参数data需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据才可以实现 POST 请求。 - timeout: 以秒为单位,设置超时时间。
- cafile, capath: 指定一组 HTTPS 请求受信任的 CA 证书,
cafile指定包含 CA 证书的单个文件,capath指定证书文件的目录。 - cadefault: CA 证书默认值。
- context: 描述 SSL 选项的实例。
🦋2.1 发送 GET 请求
在使用 urlopen() 方法实现一个网络请求时,返回的是一个 http.client.HTTPResponse 对象。示例代码如下:
import urllib.request
# 发送网络请求
response = urllib.request.urlopen('https://www.baidu.com/')
print("响应数据类型为:", type(response))程序运行结果如下:
响应数据类型为: <class 'http.client.HTTPResponse'>在 HTTPResponse 对象中包含了许多获取信息的方法和属性,下面通过几个常用的方法与属性进行演示。代码如下:
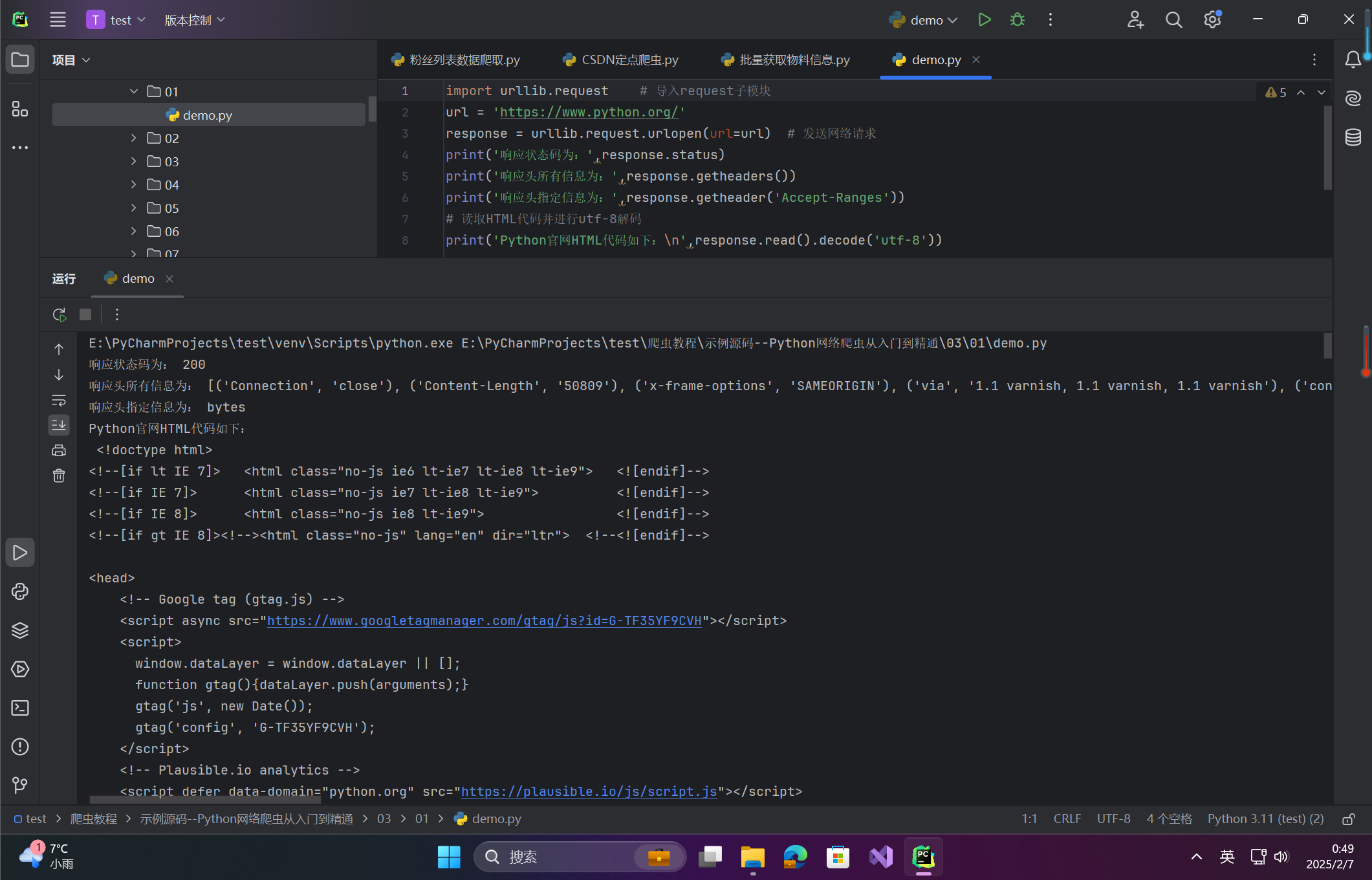
import urllib.request # 导入request子模块
url = 'https://www.python.org/'
response = urllib.request.urlopen(url=url) # 发送网络请求
print('响应状态码为:',response.status)
print('响应头所有信息为:',response.getheaders())
print('响应头指定信息为:',response.getheader('Accept-Ranges'))
# 读取HTML代码并进行utf-8解码
print('Python官网HTML代码如下:\n',response.read().decode('utf-8'))程序运行结果如下:
🦋2.2 发送 POST 请求
urlopen() 方法在默认情况下发送的是 GET 请求。在发送 POST 请求时,需要为其设置 data 参数,该参数是 bytes 类型,所以需要使用 bytes() 方法将参数值转换为字节类型的数据。示例代码如下:
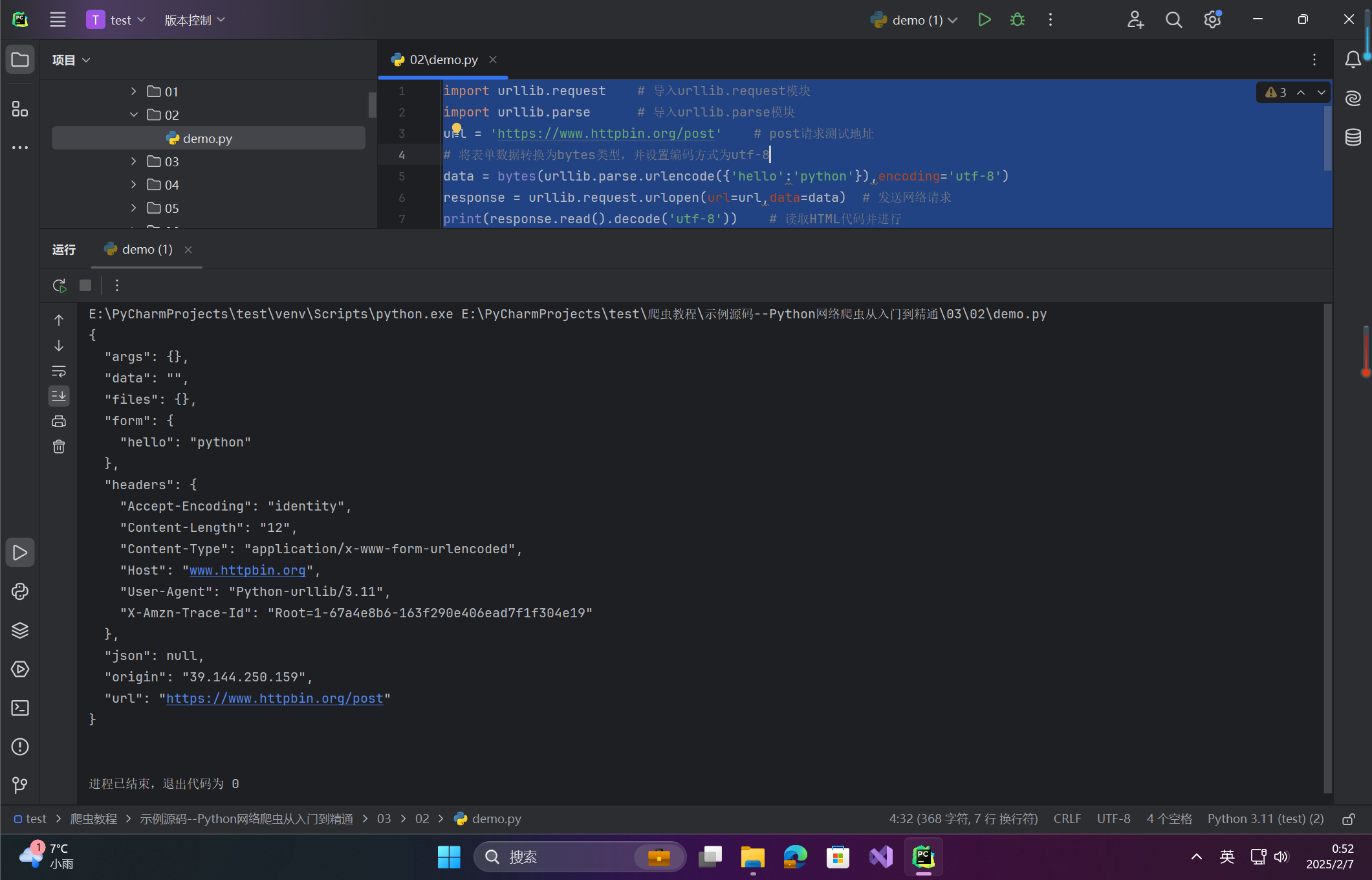
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url = 'https://www.httpbin.org/post' # post请求测试地址
# 将表单数据转换为bytes类型,并设置编码方式为utf-8
data = bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8')
response = urllib.request.urlopen(url=url,data=data) # 发送网络请求
print(response.read().decode('utf-8')) # 读取HTML代码并进行程序运行结果如下:
🦋2.3 设置网络超时
urlopen() 方法中的 timeout 参数用于设置请求超时,该参数以秒为单位,表示如果在请求时超出了设置的时间还没有得到响应,就会抛出异常。示例代码如下:
import urllib.request
url = 'https://www.python.org/'
# 发送网络请求,设置超时时间为 0.1 秒
response = urllib.request.urlopen(url=url, timeout=0.1)
# 读取 HTML 代码并进行 utf-8 解码
print(response.read().decode('utf-8'))由于以上示例代码中的超时时间设置为 0.1 秒,时间较短,所以将显示超时异常。
程序运行结果如下:
File "G:\Python\Python38\lib\http\client.py", line 917, in connect
self.sock = self._create_connection(
File "G:\Python\Python38\lib\socket.py", line 808, in create_connection
raise err
File "G:\Python\Python38\lib\socket.py", line 796, in create_connection
sock.connect(sa)
socket.timeout: timed out根据网络环境的不同,可以将超时时间设置为一个合理的时间,如 2 秒、3 秒等。
处理网络超时。在实际开发中可以将超时异常捕获,然后处理下面的爬虫任务。示例代码如下:
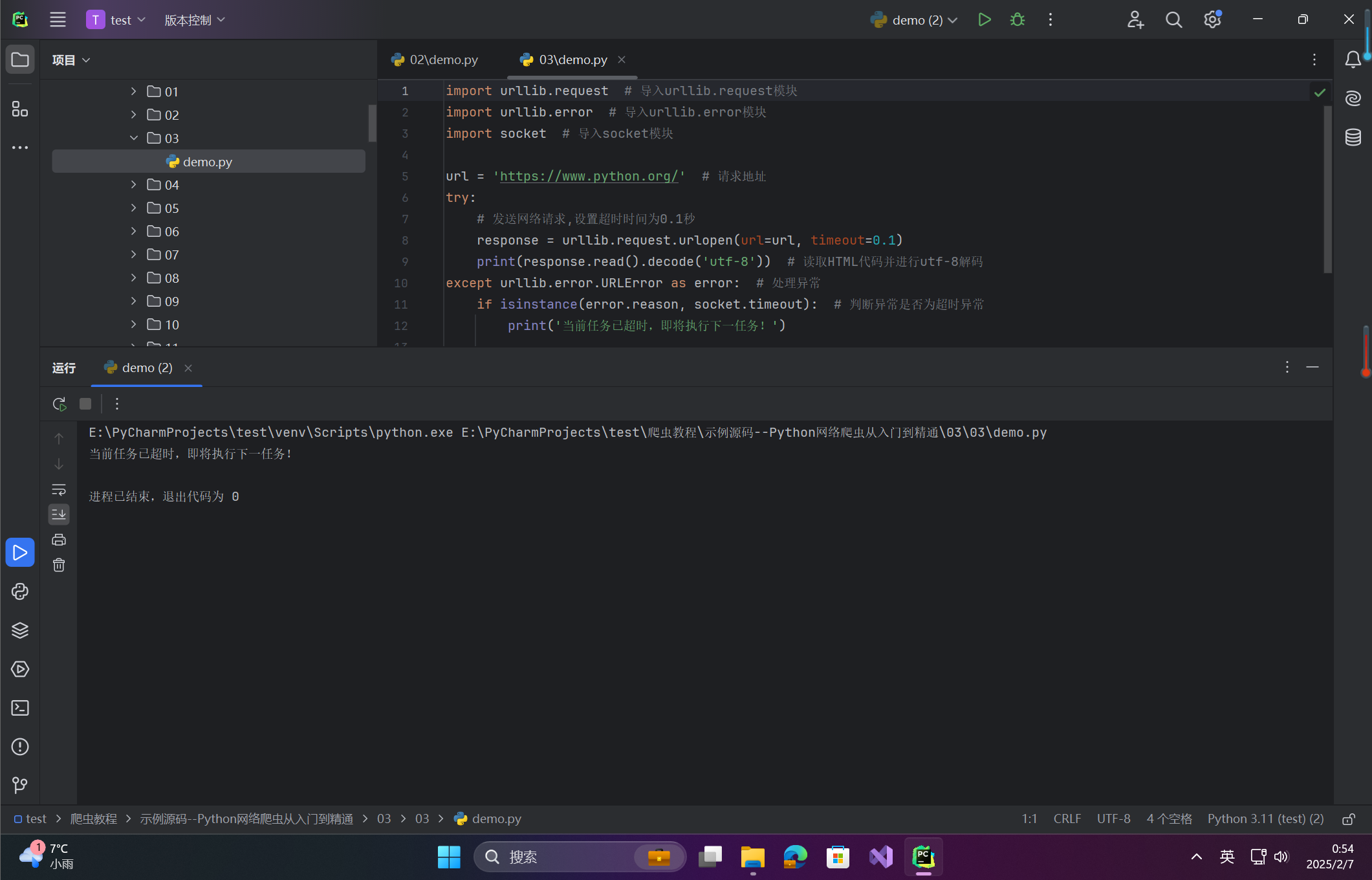
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
import socket # 导入socket模块
url = 'https://www.python.org/' # 请求地址
try:
# 发送网络请求,设置超时时间为0.1秒
response = urllib.request.urlopen(url=url, timeout=0.1)
print(response.read().decode('utf-8')) # 读取HTML代码并进行utf-8解码
except urllib.error.URLError as error: # 处理异常
if isinstance(error.reason, socket.timeout): # 判断异常是否为超时异常
print('当前任务已超时,即将执行下一任务!')程序运行结果如下:
🔎3.复杂的网络请求
我们了解了 urlopen() 方法可以发送最基本的网络请求,但要构建一个完整的网络请求,我们需要添加额外的内容,例如 Headers、Cookies、代理 IP 等。这样,才能更好地模拟一个浏览器所发送的请求。
为此,Request 类是一个非常有用的工具,它允许你构建一个功能更为强大的请求对象,支持更多的自定义设置。
Request 类的语法格式
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)参数说明:
- url: 需要访问的网站的 URL 完整地址。headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'} 这个
User-Agent字符串表示模拟 Google Chrome 浏览器进行网络请求。 - data: 该参数默认值为
None,通过该参数确认请求方式。如果为None,表示请求方式为 GET。如果有值,表示 POST 请求。在发送 POST 请求时,data参数需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据。 - headers: 设置请求头部信息,类型为字典。最常见的用法是通过修改
User-Agent来伪装成浏览器,从而避免被网站识别为爬虫。例如: - origin_req_host: 用于设置请求方的主机名或者 IP 地址。
- unverifiable: 用于设置网页是否需要验证,默认为
False。 - method: 设置请求方法(如
GET、POST等)。默认是GET。
🦋3.1 设置请求头
设置请求头是为了模拟浏览器向网页后台发送网络请求,从而避免服务器的反爬虫措施。在使用 urlopen() 方法发送网络请求时,默认并没有设置请求头参数。比如,当向 https://www.httpbin.org/post 发送请求时,返回的信息中 headers 会显示默认值。
默认 headers 信息:
{
"Accept-Encoding": "identity",
"Content-Length": "12",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Python-urllib/3.8",
"X-Amzn-Trace-Id": "Root=1-5ee08cb3-73b5e77881d4cce166711b50"
}☀️3.1.1 设置请求头
如果需要设置请求头信息,可以通过 Request 类来构造一个带有 headers 请求头信息的请求对象,然后将这个请求对象传递给 urlopen() 方法,进行网络请求的发送。示例代码如下:
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url = 'https://www.httpbin.org/post' # 请求地址
# 定义请求头信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
# 将表单数据转换为bytes类型,并设置编码方式为utf-8
data = bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8')
# 创建Request对象
r = urllib.request.Request(url=url,data=data,headers=headers,method='POST')
response = urllib.request.urlopen(r) # 发送网络请求
print(response.read().decode('utf-8')) # 读取HTML代码并进行utf-8解码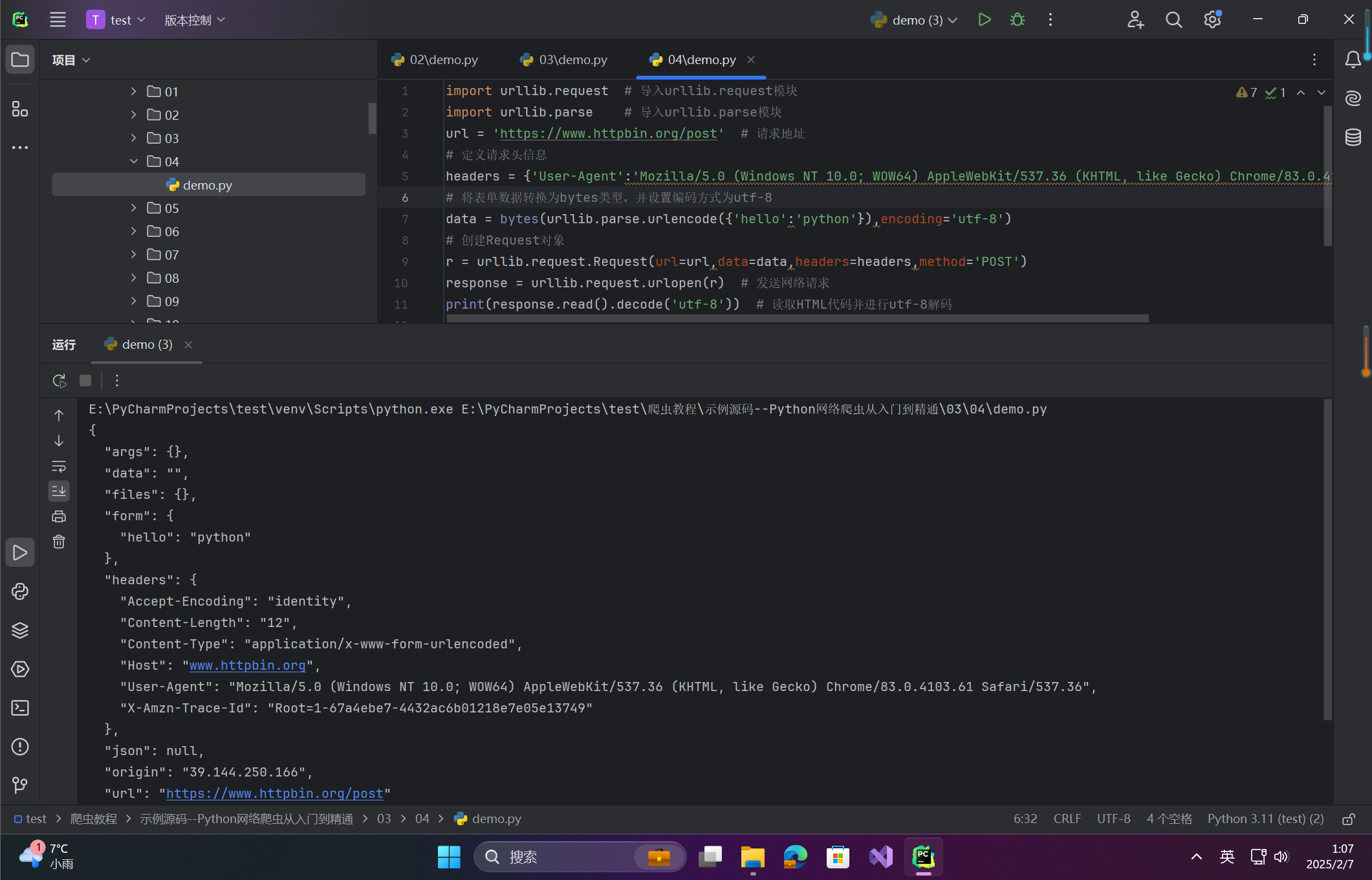
☀️3.1.2 设置请求头的好处:以百度为例
以上示例并没有直观地展示设置请求头的优势。为了更清楚地展示设置请求头的效果,我们以请求百度网站为例进行比较。
url = 'https://www.baidu.com/'
# 定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
# 创建 Request 对象
req = urllib.request.Request(url=url, headers=headers)
# 发送网络请求
response = urllib.request.urlopen(req)
# 读取 HTML 代码并进行 UTF-8 解码
print(response.read().decode('utf-8'))未设置请求头:
如果没有设置请求头,直接使用 urlopen() 方法向 https://www.baidu.com/ 地址发送网络请求,返回的 HTML 代码如下所示:
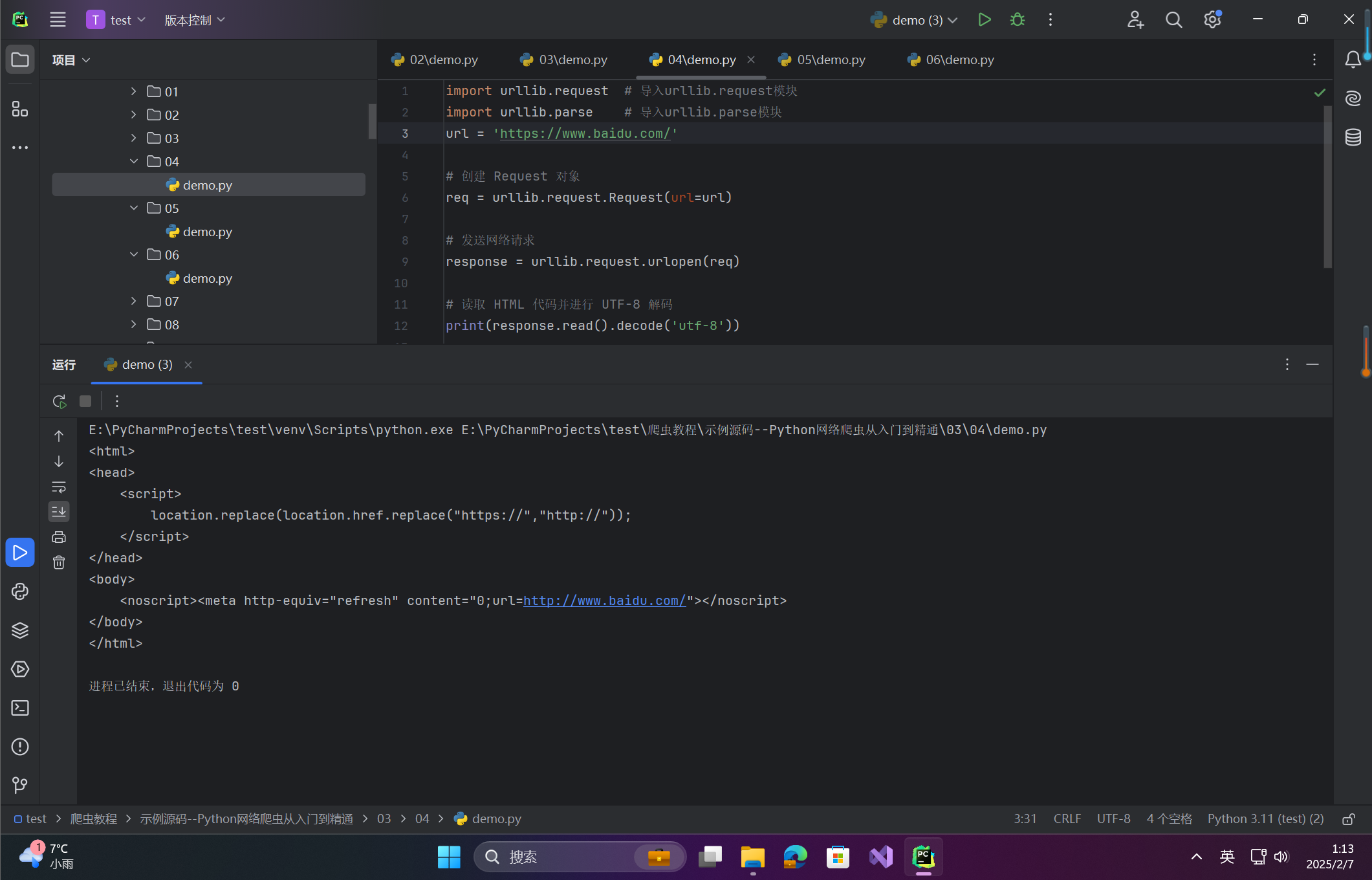
设置请求头:
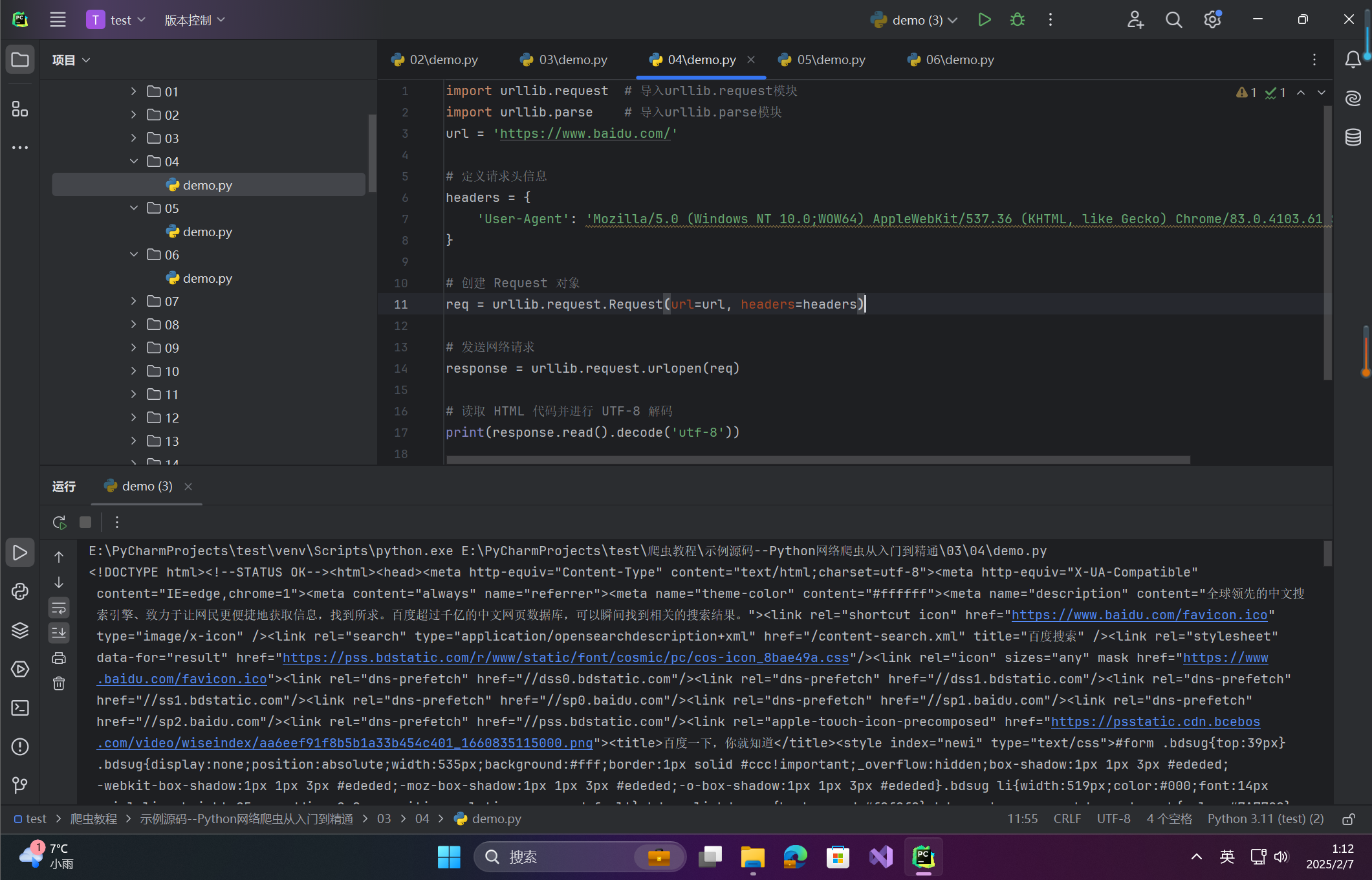
现在,创建一个具有请求头信息的 Request 对象,并向百度网站发送请求。
程序运行后,将返回正常的百度 HTML 页面,如图所示:
🦋3.2 Cookies的获取与设置
Cookies简介
Cookies是服务器向客户端返回响应数据时存储的一些信息。当客户端再次访问同一服务器时,会携带这些Cookies,服务器会根据这些Cookies的信息确认用户的身份。例如,在实现网页登录时,登录成功后,浏览器会将用户信息存储在Cookies中。当用户再次访问该网站时,浏览器会自动携带Cookies,服务器核对后确认用户身份。
在爬虫中,除了通过模拟登录的方式获取数据外,还可以通过获取登录后的Cookies,再利用这些Cookies进行身份验证,以便获取登录后的数据。
☀️3.2.1 模拟登录
首先,我们需要模拟登录操作,并获取登录验证的请求地址与表单数据。以下是模拟登录的步骤:
步骤
- 打开浏览器并访问登录页面(例如:http://site2.rikflm.com:666/)。点击页面中的“登录”按钮,弹出登录窗口。
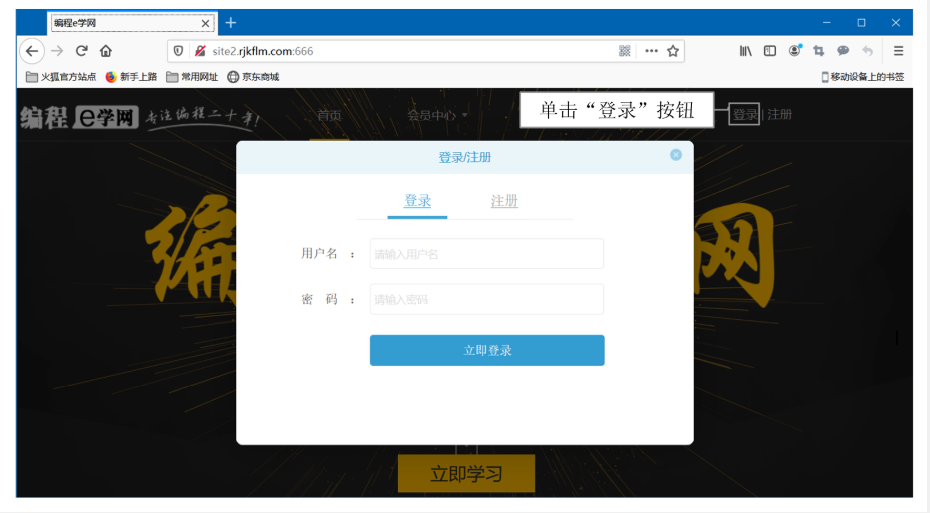 在这里插入图片描述
在这里插入图片描述 - 使用开发者工具(按 F12)打开“网络”选项,选中“持续记录”,然后输入用户名和密码,点击“立即登录”按钮。此时会发送一个网络请求(如
chklogin.html),我们可以通过这个请求获得登录验证的地址和表单数据。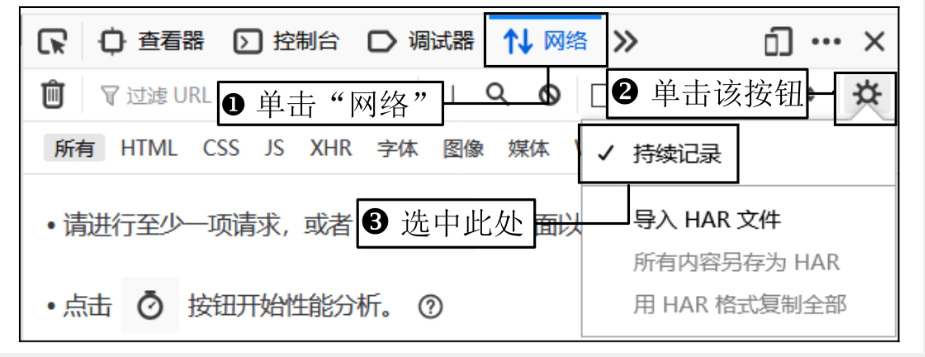 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述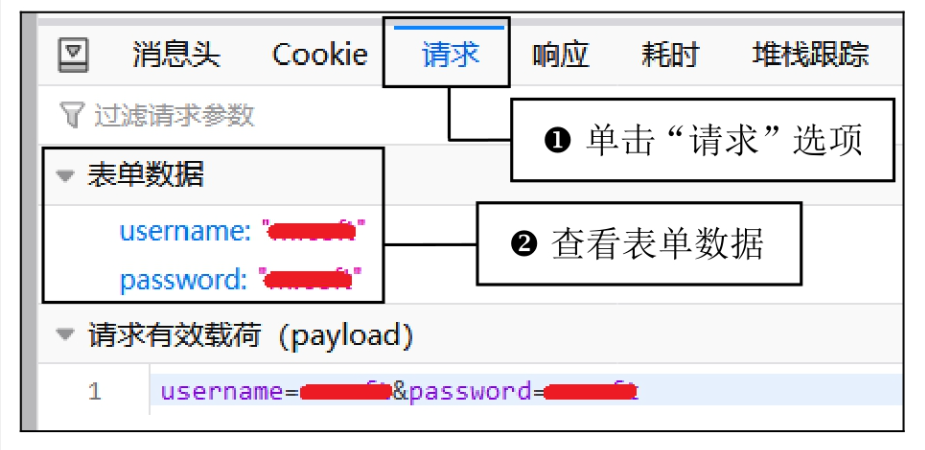 在这里插入图片描述
在这里插入图片描述 - 获取登录验证的请求地址和表单数据后,可以通过
urllib.request模块的 POST 请求方式模拟登录。
代码示例
import urllib.request
import urllib.parse
# 登录验证请求地址
url = 'http://site2.rikflm.com:666/index/index/chklogin.html'
# 将表单数据转换为 bytes 类型,并设置编码方式为 utf-8
data = bytes(urllib.parse.urlencode({'username': 'mrsoft', 'password': 'mrsoft'}), encoding='utf-8')
# 创建 Request 对象
req = urllib.request.Request(url=url, data=data, method='POST')
# 发送登录请求
response = urllib.request.urlopen(req)
# 输出登录结果
print(response.read().decode('utf-8'))程序运行结果
status: true, "msg": "登录成功!"☀️3.2.2 获取Cookies
在登录后,我们可以获取 Cookies 信息。首先需要创建一个 CookieJar 对象来存储 Cookies。以下是获取 Cookies 的实现步骤:
代码示例
import urllib.request
import urllib.parse
import http.cookiejar
import json
# 登录验证请求地址
url = "http://site2.rikflm.com:666/index/index/chklogin.html"
# 将表单数据转换为 bytes 类型,并设置编码方式为 utf-8
data = bytes(urllib.parse.urlencode({'username': 'mrsoft', 'password': 'mrsoft'}), encoding='utf-8')
# 创建 CookieJar 对象
cookie = http.cookiejar.CookieJar()
# 创建 cookie 处理器
cookie_processor = urllib.request.HTTPCookieProcessor(cookie)
# 创建 opener
opener = urllib.request.build_opener(cookie_processor)
# 发送登录请求
response = opener.open(url, data=data)
# 解析返回的 JSON 数据
response_data = json.loads(response.read().decode('utf-8'))['msg']
# 打印登录成功后的 Cookies 信息
if response_data == '登录成功!':
for cookie_item in cookie:
print(cookie_item.name + '=' + cookie_item.value)程序运行结果
PHPSESSID=8nar8gefd30o9vcmlki3kavf76☀️3.2.3 保存Cookies
为了在后续请求中使用相同的 Cookies,可以将其保存为文件。我们可以使用 LWPCookieJar 来保存 Cookies 为 LWP 格式文件。
代码示例
import urllib.request
import urllib.parse
import http.cookiejar
import json
# 登录验证请求地址
url = "http://site2.rikflm.com:666/index/index/chklogin.html"
# 将表单数据转换为 bytes 类型,并设置编码方式为 utf-8
data = bytes(urllib.parse.urlencode({'username': 'mrsoft', 'password': 'mrsoft'}), encoding='utf-8')
# 保存 cookie 文件路径
cookie_file = 'cookie.txt'
# 创建 LWPCookieJar 对象
cookie = http.cookiejar.LWPCookieJar(cookie_file)
# 创建 cookie 处理器
cookie_processor = urllib.request.HTTPCookieProcessor(cookie)
# 创建 opener 对象
opener = urllib.request.build_opener(cookie_processor)
# 发送登录请求
response = opener.open(url, data=data)
# 解析返回的 JSON 数据
response_data = json.loads(response.read().decode('utf-8'))['msg']
# 如果登录成功,则保存 Cookies
if response_data == '登录成功!':
cookie.save(ignore_discard=True, ignore_expires=True)程序运行结果
运行完后,会在指定的路径 cookie.txt 中生成 Cookies 文件,文件内容类似:
#LWP-Cookies-2.0
Set-Cookie3: PHPSESSID=8nar8gefd30o9vcmlki3kavf76; path="/"; domain="site2.rikflm.com"; path_spec; discard; version=0☀️3.2.4 使用Cookies
将保存的 Cookies 文件加载并用于后续请求。通过 cookie.load() 方法可以读取保存的 Cookies 文件,然后通过发送请求来获取登录后的页面信息。
代码示例
import urllib.request
import http.cookiejar
# 登录后页面的请求地址
url = "http://site2.rikflm.com:666/index/index/index.htm"
# 保存的 cookie 文件路径
cookie_file = 'cookie.txt'
# 创建 LWPCookieJar 对象
cookie = http.cookiejar.LWPCookieJar()
# 读取 cookie 文件内容
cookie.load(cookie_file, ignore_expires=True, ignore_discard=True)
# 创建 cookie 处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 创建 opener 对象
opener = urllib.request.build_opener(handler)
# 发送请求
response = opener.open(url)
# 输出登录后页面的 HTML 代码
print(response.read().decode('utf-8'))程序运行结果
在控制台中查看返回的 HTML 代码,并查找注册的用户名。例如,找到如下标签:
<div class="login">mrsoft 退出</div>🦋3.3 设置代理IP
反爬虫技术有很多种,其中常见的方式是通过判断客户端的IP来识别是否为爬虫。如果在短时间内,某个IP频繁访问服务器大量的数据,服务器可能会将该IP视为爬虫,并对其进行临时或永久禁用。这样,当爬虫再次访问时,服务器会拒绝其请求,从而无法获取数据。
解决方法
为了规避这种反爬虫机制,可以通过设置代理IP来隐藏爬虫的真实IP。最好在每发送一次请求时更换代理IP,这样服务器永远无法知道哪个IP在持续访问其数据资源。通过使用代理IP,可以绕过对IP的限制。
以下是如何使用 urllib 模块来设置代理IP的示例代码:
import urllib.request
# 设置目标 URL
url = 'https://www.httpbin.org/get'
# 创建代理 IP 字典
proxy_handler = urllib.request.ProxyHandler({
'https': '58.220.95.114:10053' # 代理IP和端口号
})
# 创建 opener 对象
opener = urllib.request.build_opener(proxy_handler)
# 发送网络请求
response = opener.open(url, timeout=2)
# 打印返回内容
print(response.read().decode('utf-8'))解释:
ProxyHandler:这里设置了代理IP'58.220.95.114:10053',您可以更改为您自己的代理IP。build_opener(proxy_handler):用代理IP创建一个新的 opener 对象。opener.open(url, timeout=2):通过opener对象发送 GET 请求,timeout参数是设置请求超时的时间,单位为秒。response.read().decode('utf-8'):读取返回的响应内容,并将其解码为字符串。
程序运行结果
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "www.httpbin.org",
"User-Agent": "Python-urllib/3.7",
"X-Amzn-Trace-Id": "Root=1-5ee472f5-4a1852c4d31178ff8223cdfb"
},
"origin": "58.220.95.114", # 服务器将识别您的代理IP
"url": "https://www.httpbin.org/get"
}注意事项:
- 免费代理IP通常存活时间较短,因此要定期更换代理IP。
- 如果代理IP不可用,或者服务器检测到代理IP存在问题,可能会导致请求失败。
- 推荐使用稳定的代理服务,或者定期更新代理池,避免代理IP被封锁。
通过这种方式,可以有效地避免IP被封,持续获取需要的数据。
🔎4.异常处理
在实现网络请求时,可能会遇到各种异常错误。Python 的 urllib 模块中的 urllib.error 子模块包含了两个重要的异常类:URLError 和 HTTPError。这两个异常类可以帮助我们处理在进行网络请求时可能遇到的错误。
🦋4.1 URLError 异常
URLError 类通常用于处理一般的网络问题,例如无法连接到目标地址、DNS 解析失败等。当遇到这种错误时,URLError 提供了 reason 属性,可以帮助我们了解错误的具体原因。
示例 1: 处理 URLError 异常
import urllib.request
import urllib.error
# 向一个不存在的网络地址发送请求
try:
response = urllib.request.urlopen('http://site2.rjkflm.com:666/123index.htm!')
except urllib.error.URLError as error:
# 捕获异常并打印异常原因
print(error.reason)程序运行结果:
Not Found在上面的代码中,我们向一个不存在的网络地址发送了请求,捕获到了 URLError 异常,并通过 error.reason 属性输出了错误的原因。
🦋4.2 HTTPError 异常
HTTPError 是 URLError 的子类,专门用于处理 HTTP 请求相关的异常。它具有以下三个重要属性:
code:HTTP 状态码reason:错误原因headers:HTTP 请求头信息
HTTPError 类通常用于处理与 HTTP 状态码相关的错误,比如 404(找不到页面)、500(服务器错误)等。
示例 2: 处理 HTTPError 异常
import urllib.request
import urllib.error
# 向一个不存在的网络地址发送请求
try:
response = urllib.request.urlopen('http://site2.rjkflm.com:666/123index.htm!')
print(response.status)
except urllib.error.HTTPError as error:
# 捕获 HTTPError 异常并打印状态码、异常信息和请求头
print("状态码为:", error.code)
print("异常信息为:", error.reason)
print("请求头信息如下:\n", error.headers)程序运行结果:
状态码为: 404
异常信息为: Not Found
请求头信息如下:
Date: Mon, 15 Jun 2020 07:01:05 GMT
Server: Apache/2.4.37
X-Powered-By: PHP/7.0.1
Vary: Accept-Encoding, User-Agent
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8在此示例中,我们向一个不存在的网络地址发送请求,捕获到了 HTTPError 异常。通过 error.code 获取了 HTTP 状态码(404),error.reason 获取了异常原因(Not Found),并且通过 error.headers 打印了返回的请求头信息。
🦋4.3 双重异常捕获
由于 HTTPError 是 URLError 的子类,有时我们可能会遇到无法通过 HTTPError 捕获的异常。例如,在请求超时的情况下,HTTPError 无法捕获,但 URLError 能捕获这种情况。因此,为了增加代码的健壮性,我们可以先捕获 HTTPError 异常,再捕获 URLError 异常,这样可以起到双重保险的作用。
示例 3: 双重异常捕获
import urllib.request
import urllib.error
try:
# 向一个无法访问的网址发送请求,并设置超时时间
response = urllib.request.urlopen('https://www.python.org/', timeout=0.1)
except urllib.error.HTTPError as error:
# 捕获 HTTPError 异常
print("HTTPError 状态码为:", error.code)
print("HTTPError 异常信息为:", error.reason)
print("HTTPError 请求头信息如下:\n", error.headers)
except urllib.error.URLError as error:
# 捕获 URLError 异常
print("URLError 异常信息为:", error.reason)程序运行结果:
URLError 异常信息为: timed out在这个例子中,我们设置了超时时间为 0.1 秒,故请求会超时并抛出 URLError 异常。通过捕获 URLError 异常,我们输出了错误信息 timed out,说明请求由于超时失败。
🔎5.解析链接
Python 的 urllib 模块中的 parse 子模块用于解析 URL,可以实现 URL 的拆分和组合。它支持多种协议的 URL 处理,如 http、https、ftp、file 等。
🦋5.1 拆分 URL
☀️5.1.1urlparse() 方法
urlparse() 方法用于将 URL 分解成不同的部分,返回 ParseResult 对象,包含以下 6 个部分:
scheme:协议netloc:域名path:路径params:参数query:查询字符串fragment:片段标识符
语法格式:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring:必填,待拆分的 URL。scheme:可选,默认协议(若 URL 无协议,可指定)。allow_fragments:可选,是否解析fragment片段。
示例代码:
import urllib.parse
url = 'https://docs.python.org/3/library/urllib.parse.html'
parse_result = urllib.parse.urlparse(url)
print(type(parse_result)) # 打印类型
print(parse_result) # 打印拆分结果运行结果:
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='https', netloc='docs.python.org', path='/3/library/urllib.parse.html', params='', query='', fragment='')获取各部分值:
print('scheme:', parse_result.scheme)
print('netloc:', parse_result.netloc)
print('path:', parse_result.path)
print('params:', parse_result.params)
print('query:', parse_result.query)
print('fragment:', parse_result.fragment)☀️5.1.2 urlsplit() 方法
urlsplit() 方法与 urlparse() 类似,但不会单独拆分 params,而是合并到 path 中,返回 SplitResult 对象,包含 5 部分:
scheme:协议netloc:域名path:路径(含params)query:查询字符串fragment:片段标识符
示例代码:
import urllib.parse
url = "https://docs.python.org/3/library/urllib.parse.html"
print(urllib.parse.urlsplit(url)) # 使用 urlsplit() 拆分 URL
print(urllib.parse.urlparse(url)) # 使用 urlparse() 拆分 URL运行结果:
SplitResult(scheme='https', netloc='docs.python.org', path='/3/library/urllib.parse.html', query='', fragment='')
ParseResult(scheme='https', netloc='docs.python.org', path='/3/library/urllib.parse.html', params='', query='', fragment='')获取各部分值:
urlsplit = urllib.parse.urlsplit(url)
print(urlsplit.scheme) # 方式 1
print(urlsplit[0]) # 方式 2🦋5.2 组合 URL
☀️5.2.1 urlunparse() 方法
urlunparse() 用于将 6 个部分重新组合成完整的 URL。
语法格式:
urllib.parse.urlunparse(parts)parts:可迭代对象,必须包含 6 个元素。
示例代码:
import urllib.parse
list_url = ['https', 'docs.python.org', '/3/library/urllib.parse.html', '', '', '']
tuple_url = ('https', 'docs.python.org', '/3/library/urllib.parse.html', '', '', '')
dict_url = {'scheme': 'https', 'netloc': 'docs.python.org', 'path': '/3/library/urllib.parse.html', 'params': '', 'query': '', 'fragment': ''}
print("组合列表类型的 URL:", urllib.parse.urlunparse(list_url))
print("组合元组类型的 URL:", urllib.parse.urlunparse(tuple_url))
print("组合字典类型的 URL:", urllib.parse.urlunparse(dict_url.values()))运行结果:
组合列表类型的 URL: https://docs.python.org/3/library/urllib.parse.html
组合元组类型的 URL: https://docs.python.org/3/library/urllib.parse.html
组合字典类型的 URL: https://docs.python.org/3/library/urllib.parse.html注意:参数必须包含 6 个元素,否则会报错。
☀️5.2.2 urlunsplit() 方法
urlunsplit() 与 urlunparse() 类似,但用于组合 5 个部分,不包含 params。
语法格式:
urllib.parse.urlunsplit(parts)parts:可迭代对象,必须包含 5 个元素。
示例代码:
import urllib.parse
list_url = ['https', 'docs.python.org', '/3/library/urllib.parse.html', '', '']
tuple_url = ('https', 'docs.python.org', '/3/library/urllib.parse.html', '', '')
dict_url = {'scheme': 'https', 'netloc': 'docs.python.org', 'path': '/3/library/urllib.parse.html', 'query': '', 'fragment': ''}
print("组合列表类型的 URL:", urllib.parse.urlunsplit(list_url))
print("组合元组类型的 URL:", urllib.parse.urlunsplit(tuple_url))
print("组合字典类型的 URL:", urllib.parse.urlunsplit(dict_url.values()))运行结果:
组合列表类型的 URL: https://docs.python.org/3/library/urllib.parse.html
组合元组类型的 URL: https://docs.python.org/3/library/urllib.parse.html
组合字典类型的 URL: https://docs.python.org/3/library/urllib.parse.html🦋5.3 连接 URL
urljoin() 方法用于将相对 URL 连接到基础 URL,形成完整的 URL。
语法格式:
urllib.parse.urljoin(base, url, allow_fragments=True)base:基础链接(包含scheme、netloc、path)。url:新的链接(可以是相对路径或完整 URL)。allow_fragments:是否解析fragment片段。
示例代码:
import urllib.parse
base_url = 'https://docs.python.org'
# url 参数为相对路径
print(urllib.parse.urljoin(base_url, '3/library/urllib.parse.html'))
# url 参数为完整 URL
print(urllib.parse.urljoin(base_url, 'https://docs.python.org/3/library/urllib.parse.html#url-parsing'))运行结果:
https://docs.python.org/3/library/urllib.parse.html
https://docs.python.org/3/library/urllib.parse.html#url-parsing解析逻辑:
- 当
url是 相对路径,它会 自动追加 在base之后,并确保/符号正确。 - 当
url是 完整 URL,它会 直接返回url。
🦋5.4 URL的编码与解码
在 Web 开发中,URL 编码是将请求地址中的参数进行转义,特别是对于中文等非 ASCII 字符,常用于 GET 请求中的参数传递。urllib.parse 模块提供了几个方法来处理 URL 的编码和解码,包括 urlencode()、quote() 和 unquote() 方法。
☀️5.4.1 urlencode() 方法
urlencode() 方法用于将字典类型的请求参数编码为 URL 参数格式。
- 功能:将字典类型的请求参数转换为 URL 编码的查询字符串。
- 用途:常用于 GET 请求中,将字典形式的请求参数转为查询字符串(例如:
?name=Jack&country=中国&age=30)。
示例代码:
import urllib.parse
base_url = 'http://httpbin.org/get?'
params = {'name': 'Jack', 'country': '中国', 'age': 30}
url = base_url + urllib.parse.urlencode(params)
print("编码后的请求地址为:", url)输出:
编码后的请求地址为: http://httpbin.org/get?name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30说明:在 URL 中,%E4%B8%AD%E5%9B%BD 是 "中国" 经过编码后的字符串。
☀️5.4.2 quote() 方法
quote() 方法用于编码一个字符串,通常用于编码 URL 中的单个参数。
- 功能:将一个字符串进行 URL 编码。
- 用途:当你只需要编码一个字符串(而不是整个字典)时,使用
quote()方法。
示例代码:
import urllib.parse
base_url = 'http://httpbin.org/get?country='
url = base_url + urllib.parse.quote('中国')
print("编码后的请求地址为:", url)输出:
编码后的请求地址为: http://httpbin.org/get?country=%E4%B8%AD%E5%9B%BD说明:quote() 仅对单个字符串进行编码。
☀️5.4.3 unquote() 方法
unquote() 方法用于解码已编码的 URL 字符串,无论是通过 urlencode() 还是 quote() 编码的 URL 都可以使用该方法解码。
- 功能:将编码后的 URL 字符串进行解码,恢复原始字符串。
- 用途:将 URL 编码的查询参数解码为人类可读的格式。
示例代码:
import urllib.parse
u = urllib.parse.urlencode({'country': '中国'})
q = urllib.parse.quote('country=中国')
print('urlencode 编码后结果为:', u)
print('quote 编码后结果为:', q)
# 解码
print('对 urlencode 解码:', urllib.parse.unquote(u))
print('对 quote 解码:', urllib.parse.unquote(q))输出:
urlencode 编码后结果为: country=%E4%B8%AD%E5%9B%BD
quote 编码后结果为: country%3D%E4%B8%AD%E5%9B%BD
对 urlencode 解码: country=中国
对 quote 解码: country=中国说明:unquote() 用于解码编码后的字符串,恢复原始数据。
🦋5.5 URL参数的转换
在处理 URL 时,常常需要提取 URL 中的参数并进行解析。urllib.parse 模块提供了 parse_qs() 和 parse_qsl() 方法来帮助将 URL 中的查询字符串转换为字典或元组列表。
☀️5.5.1 parse_qs() 方法
parse_qs() 方法将 URL 查询字符串解析为字典类型的结果,每个参数的值都是一个列表。
示例代码:
import urllib.parse
url = 'http://httpbin.org/get?name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30'
query = urllib.parse.urlsplit(url).query # 获取 URL 中的查询部分
query_dict = urllib.parse.parse_qs(query) # 将查询字符串解析为字典
print("数据类型为:", type(query_dict))
print("转换后的数据:", query_dict)输出:
数据类型为: <class 'dict'>
转换后的数据: {'name': ['Jack'], 'country': ['中国'], 'age': ['30']}说明:parse_qs() 将查询字符串中的参数解析为字典,每个参数的值是一个列表。
☀️5.5.2 parse_qsl() 方法
parse_qsl() 方法将 URL 查询字符串解析为由元组组成的列表,每个元组包含一个键值对。
示例代码:
import urllib.parse
str_params = 'name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30'
list_params = urllib.parse.parse_qsl(str_params)
print("数据类型为:", type(list_params))
print("转换后的数据:", list_params)输出:
数据类型为: <class 'list'>
转换后的数据: [('name', 'Jack'), ('country', '中国'), ('age', '30')]说明:parse_qsl() 将查询字符串解析为一个包含元组的列表,每个元组包含一个键值对。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
