【自动化办公】批量一键移除PDF电子签名+支持windows系统
原创
【自动化办公】批量一键移除PDF电子签名+支持windows系统
原创
背景痛点
移除pdf签名的工具市面上已经存在, 只是大批量一键移除pdf签名的工具还寥寥无几。 我是一名程序员, 前阵子xx公司有一批签了名的PDF , 需要批量移除上面的电子签名,如下图所示:
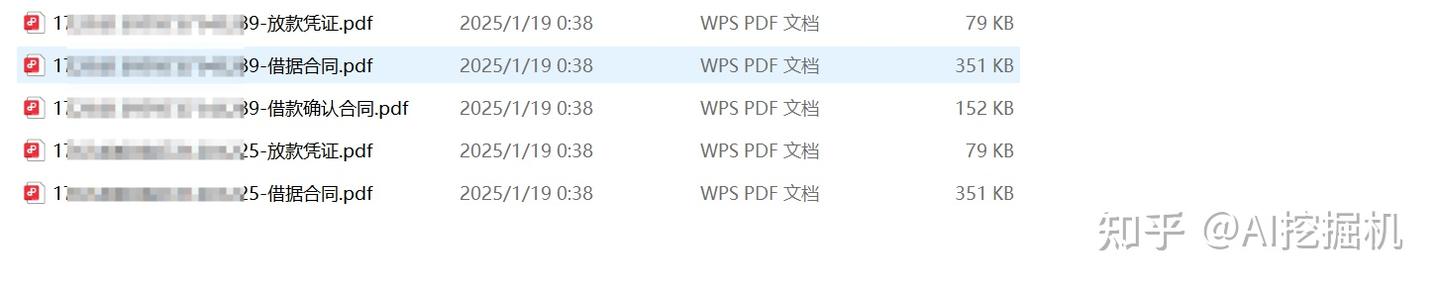
文件远远不止这么多, 这里截图了一部分。
移除前的一个PDF签名的效果展示:

移除后的PDF效果展示:
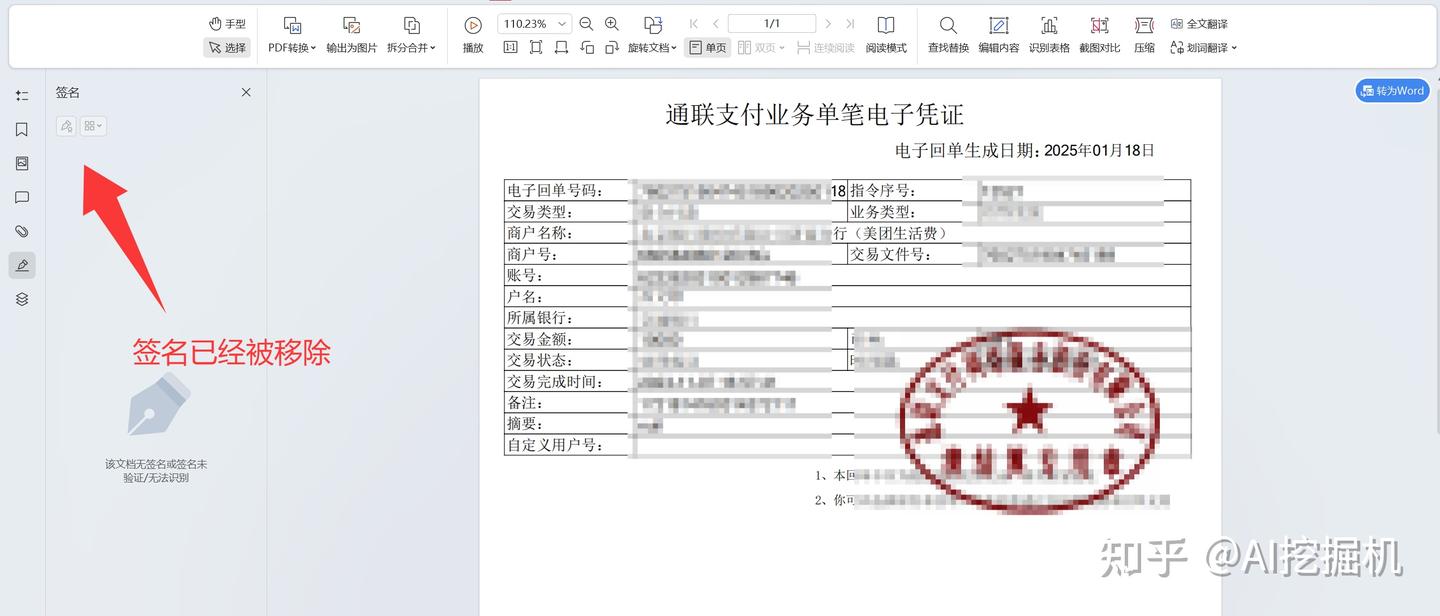
移除后,不会改变源pdf的格式。
视频演示
功能用法介绍
功能概述
我们可以将一批签了名的pdf进行移除电子签名, 当然您用来作任何业务都与软件无关!
首先我们选择签了名的pdf的路径:
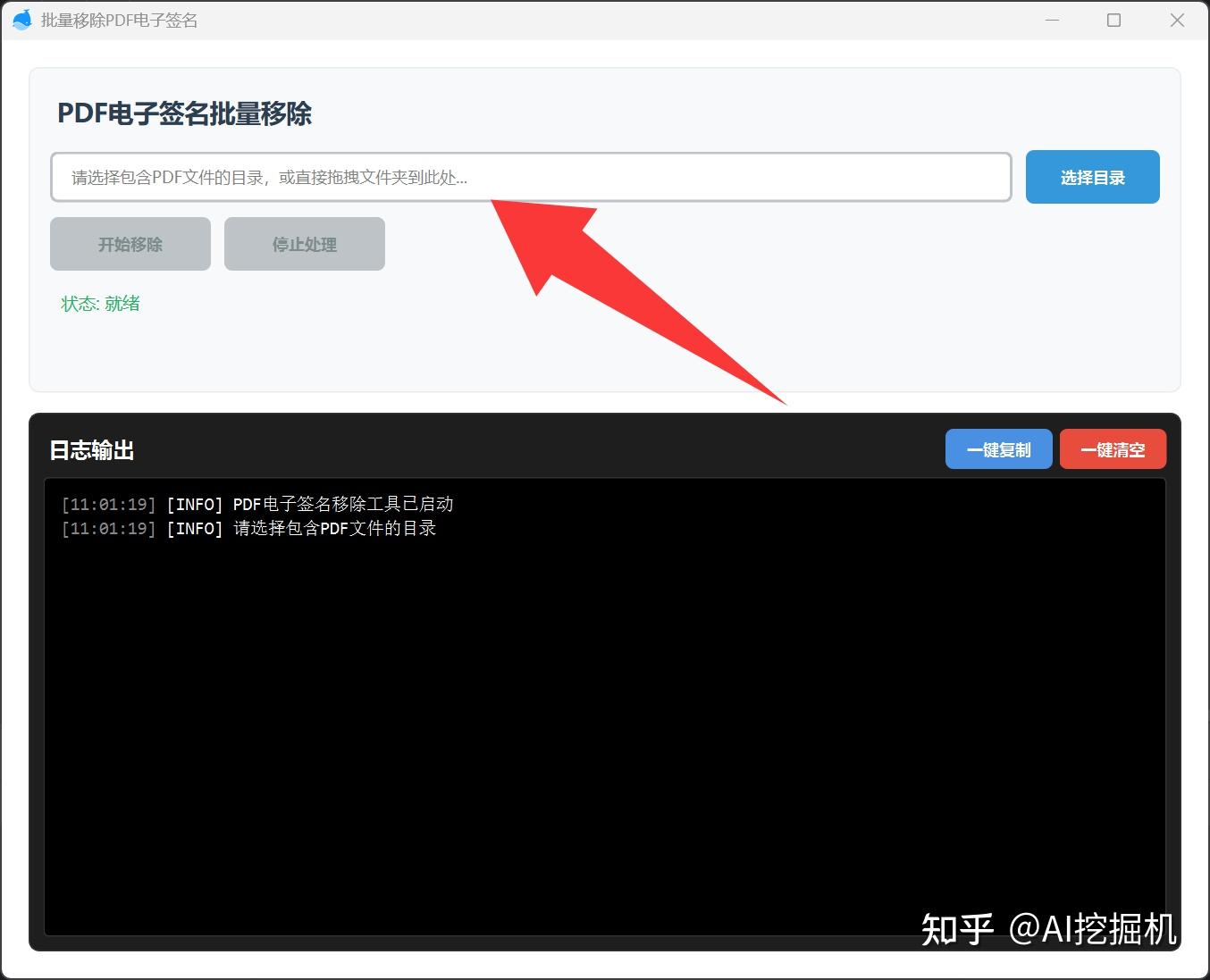
选择好之后,点击开始移除:
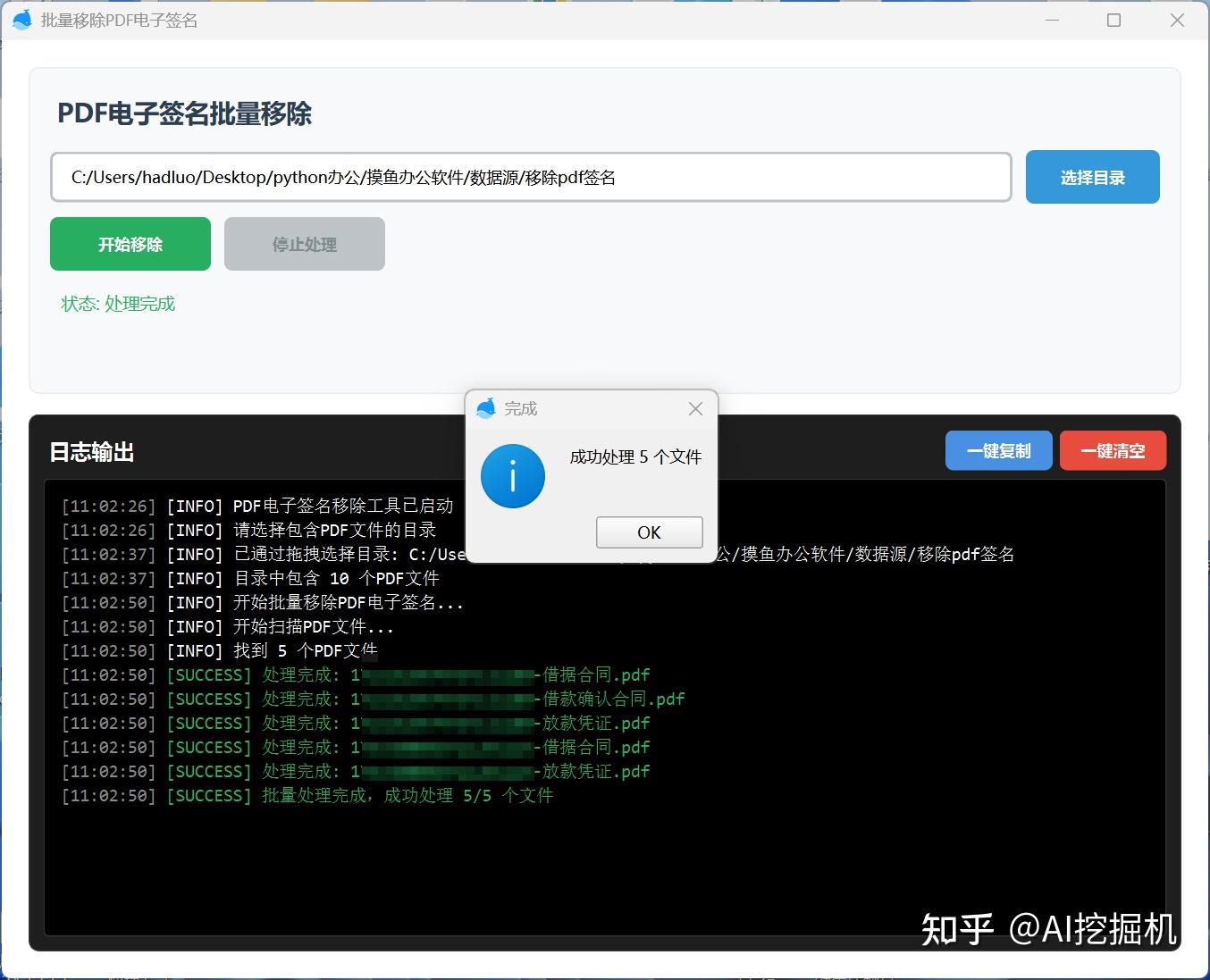
移除的结果文件会在源目录生成一个out目录, 里面就是去了电子签名的pdf文件。
如果移除失败,会生成一个error目录,里面存储的是移除失败的pdf。 如果源pdf格式没问题,基本上就不会失败。
如果您有疑问可以一起来探讨,功能就介绍到 这里 ,希望能帮助大家,感谢!!!
如果您有疑问可以一起来探讨,功能就介绍到 这里 ,希望能帮助大家,感谢!!!
技术实现原理
软件是基于Python开发的现代化办公自动化软件,主要使用了如下技术架构:
1. PySide6 (Qt6) - 现代化GUI界面框架:
2. PyPDF2库:这是PDF签名移除的核心技术。使用 PdfReader 读取PDF文件,使用 PdfWriter 写入处理后的PDF文件,通过操作PDF内部对象结构来移除签名。
3. 文件处理:os.walk() - 递归遍历目录结构。
部分代码解析
项目的 开始移除 按钮,会开启一个QThread线程去处理,首先是获取移除目录, 然后通过os.walk遍历目录获取到所有pdf文件,然后一个一个进行移除,代码如下:
class PdfSignatureRemovalThread(QThread):
"""PDF签名移除处理线程"""
# 信号定义
log_signal = Signal(str, str) # 日志信号(消息, 级别)
progress_signal = Signal(int, int) # 进度信号(当前, 总数)
finished_signal = Signal(bool, str) # 完成信号(成功, 消息)
def __init__(self, pdf_directory):
super().__init__()
self.pdf_directory = pdf_directory
self.is_running = True
self.user_api = UserAPI()
def run(self):
"""执行PDF签名移除任务"""
try:
self.log_signal.emit("开始扫描PDF文件...", "INFO")
# 获取目录下所有PDF文件
pdf_files = []
for root, dirs, files in os.walk(self.pdf_directory):
# 跳过out.error目录
if "out" in dirs:
dirs.remove("out")
if "error" in dirs:
dirs.remove("error")
for file in files:
if file.lower().endswith('.pdf'):
pdf_files.append(os.path.join(root, file))
if not pdf_files:
self.log_signal.emit("未找到PDF文件", "WARNING")
self.finished_signal.emit(False, "未找到PDF文件")
return
# 试用用户
if global_state.get_user_info() is None:
self.log_signal.emit("未登录,请返回主界面登录", "ERROR")
self.finished_signal.emit(False, "未登录,请返回主界面登录")
return
if global_state.get_user_type() == 0 and len(pdf_files) > 10:
self.log_signal.emit("试用用户最多10条", "ERROR")
self.finished_signal.emit(False, "试用用户最多10条")
return
## 消耗 次数
res = self.user_api.get_and_decr()
if res.get('code') != 0:
self.log_signal.emit(res.get('msg'), "ERROR")
self.finished_signal.emit(False, res.get('msg'))
return
if len(pdf_files) > 500:
self.log_signal.emit("数据量大于500条,请分批执行", "ERROR")
self.finished_signal.emit(False, "数据量大于500条,请分批执行")
return
self.log_signal.emit(f"找到 {len(pdf_files)} 个PDF文件", "INFO")
## 创建out目录
out_directory, error_directory = RemovePdfService.mk_out_dir(self.pdf_directory)
# 处理每个PDF文件
success_count = 0
for i, pdf_file in enumerate(pdf_files):
if not self.is_running:
break
self.progress_signal.emit(i + 1, len(pdf_files))
file_name, file_ext = os.path.splitext(os.path.basename(pdf_file))
output_file = os.path.join(out_directory, file_name + "." + file_ext)
filename = os.path.basename(pdf_file)
try:
## 开始处理 移除签名
RemovePdfService.do_handle(pdf_file, output_file)
success_count += 1
self.log_signal.emit(f"处理完成: {filename}", "SUCCESS")
except Exception as e:
self.log_signal.emit(f"处理失败 {os.path.basename(pdf_file)}: {str(e)}", "ERROR")
shutil.copy2(pdf_file, error_directory)
if self.is_running:
self.log_signal.emit(f"批量处理完成,成功处理 {success_count}/{len(pdf_files)} 个文件", "SUCCESS")
self.finished_signal.emit(True, f"成功处理 {success_count} 个文件")
else:
self.log_signal.emit("任务已取消", "WARNING")
self.finished_signal.emit(False, "任务已取消")
except Exception as e:
self.log_signal.emit(f"处理过程中发生错误: {str(e)}", "ERROR")
self.finished_signal.emit(False, f"处理失败: {str(e)}")
def stop(self):
"""停止处理"""
self.is_running = False
如果您有疑问可以一起来探讨,今天就介绍到 这里 ,希望能帮助大家,感谢!!!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
