【DEBUG MCP SERVER】
原创
【DEBUG MCP SERVER】
原创
TOC
💬 前言
但在没有大模型以前,我们的代码是怎么Debug以及修复bug的呢?或者说遇到程序报错时,我们第一时间想到的是什么呢?那就是红极一时的CSDN社区,在这上面有着大量程序员上传的各种各样的报错问题以及解决方案,包括但不限于基础语法错误,环境安装报错、库依赖关系问题等等。即使现在的大模型技术已经可以很好的帮助我们调试代码,修改代码,优化代码。但是,在部分问题上,大模型没有足够的经验知识来调整错误。因此,在本次文章,笔者将协同codex制作一个CSDN_DEBUG的MCP服务。
在本项目中,主要是构建一个CSDN_DEBUG的MCP服务,听起来似乎很简单,因为只需要搜集到文章数据,拼接到prompt喂给大模型似乎就能解决,但是!大模型的上下文长度限制无法让我们把所有的文章拼接到prompt中。我们知道在各大平台上的文章,重复度非常高,我们如何压缩、利用其中的信息呢?我要怎么验证压缩算法的有效性呢?为此,本项目会构建一个数据集来量化数据,从不同的指标上来客观评价算法的有效性。
🔥 本项目已经同步到github仓库:https://github.com/Yirzzzz/CSDN_DUBUG,欢迎大家使用以及star⭐️⭐️⭐️!!!
一、初始代码生成
由于MCP服务的本质还是调用函数,为了方便debug,我们首先生成可用的函数并进行测试
- 首先生成csdn搜索函数以及文章内容获取函数
<u>prompt</u>:我想生成一个csdn搜索函数,通过必应搜索,目的是可以返回文章的内容。例如我输入no module:cv2.可以返回相关的文章以及文章内容
search_with_provider.py
def _search_with_provider(
query: str,
sites: list[str],
limit: int,
*,
freshness: str | None = None, # "Day" | "Week" | "Month" | "Year"
mkt: str = "zh-CN",
provider: str | None = None # 可显式指定: "bing" | "ddg"
) -> list[dict[str, Any]]:
"""
统一检索入口:
- 优先走 Bing(若提供 BING_KEY 或 provider="bing")
- 否则走 duckduckgo_search(无钥,类似 websearch 的用法)
返回: [{title, url, snippet, source}]
"""
provider = (provider or os.getenv("SEARCH_PROVIDER") or ("bing" if BING_KEY else "ddg")).lower()
q = f"{query} " + " ".join(f"site:{s}" for s in sites if s)
results: list[dict[str, Any]] = []
# -------------------- 分支 A:Bing Web Search API --------------------
if provider == "bing":
if not BING_KEY:
raise RuntimeError("BING_KEY 未设置;若要无钥检索,请把 provider 改为 'ddg' 或不传。")
count = max(1, min(int(limit or 1), 50))
with _http() as client:
params = {
"q": q,
"count": count,
"mkt": mkt,
"responseFilter": "Webpages",
"safeSearch": "Off",
}
if freshness:
params["freshness"] = freshness # Day/Week/Month
r = client.get(
"https://api.bing.microsoft.com/v7.0/search",
params=params,
headers={"Ocp-Apim-Subscription-Key": BING_KEY},
)
r.raise_for_status()
data = r.json()
for item in (data.get("webPages", {}).get("value") or []):
results.append({
"title": item.get("name", "") or "",
"url": item.get("url", "") or "",
"snippet": item.get("snippet", "") or "",
"source": "bing",
})
# -------------------- 分支 B:duckduckgo_search(无钥) --------------------
else:
if DDGS is None:
raise RuntimeError("未安装 duckduckgo_search,请先执行: pip install duckduckgo_search")
# freshness 映射到 DDG 的 timelimit:d/w/m/y
tl_map = {"Day": "d", "Week": "w", "Month": "m", "Year": "y"}
timelimit = tl_map.get(freshness or "", None)
# 地区用 'wt-wt' 更通用;safesearch 可选: "off"/"moderate"/"strict"
max_results = max(1, int(limit or 1)) * 2 # 稍多取一些,便于去重
with DDGS(timeout=15) as ddgs:
for item in ddgs.text(q, region="wt-wt", safesearch="moderate",
timelimit=timelimit, max_results=max_results):
# item: {'title':..., 'href':..., 'body':...}
url = item.get("href") or ""
if not url:
continue
results.append({
"title": item.get("title", "") or "",
"url": url,
"snippet": item.get("body", "") or "",
"source": "ddg",
})
# -------------------- 去重 & 截断 --------------------
seen: set[str] = set()
deduped: list[dict[str, Any]] = []
for it in results:
u = (it.get("url") or "").split("#")[0]
if u and u not in seen:
seen.add(u)
deduped.append(it)
if len(deduped) >= limit:
break
return deduped✅ 初步测试,可以正确获取文章内容的正确信息,接着,我们需要进一步通过url获取文章内容
def test_stacktrace_rank():
err = """Traceback (most recent call last):
File "x.py", line 1, in <module>
import cv2
ModuleNotFoundError: No module named 'cv2'"""
hits = server._search_with_provider(err, server.DEFAULT_SITES + ["csdn.net",], 8)
for i, it in enumerate(hits):
tgt = f"{it.get('title','')} {it.get('snippet','')}"
print(f"第{i+1}条:{it.get('snippet','')}")
<u>prompt</u>: 根据已有的url,获取文章内容
def _extract_article(html_text: str, url: str) -> dict[str, Any]:
soup = BeautifulSoup(html_text, "lxml")
title_node = soup.select_one("h1, .title-article, .article-title, title")
title = title_node.get_text(" ", strip=True) if title_node else ""
author_node = soup.select_one('meta[name="author"]')
author = author_node["content"] if (author_node and author_node.has_attr("content")) else ""
date_node = soup.select_one('meta[property="article:published_time"], time, .time, .date')
published = (
date_node["content"] if (date_node and date_node.has_attr("content"))
else (date_node.get_text(strip=True) if date_node else "")
)
content_node = soup.select_one("#content_views, .blog-content-box, article, .markdown-body")
text = ""
if content_node:
for bad in content_node.select(".hide-article-box, .csdn-toolbar, script, style"):
bad.decompose()
text = content_node.get_text("\n", strip=True)
return {
"url": url,
"title": title,
"author": author,
"published": published,
"excerpt": _shorten(text, 800),
}✅ 继续测试,可以发现文章的内容基本可以获取,就是还有个小bug显示了"HTTP/1.1 200 OK"

logging.getLogger("httpx").disabled = True
logging.getLogger("httpcore").disabled = True
logging.getLogger("ddgs").disabled = True
✔️ 没有显示的都是付费文章,至此,初步的文章获取代码已经建成。
二、语料库构建
在我们的目标是“让大模型融合 CSDN 知识库给出更佳答案”的 RAG 方案里,第一步就是获取与筛选文章知识。但很多帖子又长又杂:正文、楼中楼、代码块、环境截图混在一起,一股脑塞进上下文既浪费预算也会稀释相关性。为此,需要——对长文做结构化抽取、语义切片、分层检索与压缩重排,只把对当前报错有用的证据段喂给模型。
首先我们通过一个简单的相似度代码去召回向量,观察向量
from rapidfuzz import fuzz
scored = []
for i, it in enumerate(hits):
url = it.get('url')
with server._http() as client:
r = client.get(url)
r.raise_for_status()
content = server._extract_article(r.text, url)
# print(f"第{i+1}条:_{it.get('url')}:{content['excerpt']}")
print(content['excerpt'])
it["_score"] = fuzz.token_set_ratio(key, content['excerpt'])
scored.append(it)
scored.sort(key=lambda x: x["_score"], reverse=True)
print("\n[rank] top-3:")
for i, it in enumerate(scored[:10], 1):
print(f" {i}. [{it['_score']}] {it['title'][:70]} -> {it['url']}")- 结果如下所示,可以发现,召回的向量虽然合理,但是完全不是我们想要的,因为我们想要的是解决方案,而不是和问题一样的向量

✔️ 转变思路:先召回相关标题,再把文章内容全部召回,因为文章内容大部分情况下都是解决方案,
for i, it in enumerate(hits):
url = it.get('url')
with server._http() as client:
r = client.get(url)
r.raise_for_status()
content = server._extract_article(r.text, url)
it["_content"] = fuzz.token_set_ratio(key, content['excerpt'])
it["_score"] = fuzz.token_set_ratio(key, content['title'])
scored.append(it)
scored.sort(key=lambda x: x["_score"], reverse=True)
print("\n[rank] top-10:")
for i, it in enumerate(scored[:10], 1):
print(f" {i}. [{it['_score']}] {it['title'][:70]} -> {it['url']}")1️⃣ 首先对标题进行相似度召回

2️⃣ 将Top-10向量加入语料库
✔️ 至此,我们可以获取到解决问题的知识库方案了。
2.1 问题生成
把所有的向量进行召回再喂给模型,本质上可以达到最好的效果,但是由于大模型上下文的限制,且很多帖子又长又杂:正文、楼中楼、代码块、环境截图混在一起,一股脑塞进上下文既浪费预算也会稀释相关性,毕竟存在着许多复制粘贴的贴子。为此解决这一问题,还需要对语料库的向量进行压缩处理。因此,我首先需要去建立一个常见问题数据库,来量化压缩的指标以及问题是否得以解决。同样的,我们先让不同的coding agent给我们生成csdn,谷歌,知乎等平台常见的代码问题,在本次研究中通过codex, codebuddy生成问题。
<u>prompt</u>:帮我生成常见的python报错,包括但不限于基础语法报错,安装库报错,库依赖相关性报错等等。尽可能丰富,然后把问题生成放在一个json文件中,json文件每个样本需要包括问题、以及回答列表,回答列表先用一个空列表。
1️⃣ codebuddy`的问题输出结果,基本符合我的需求;
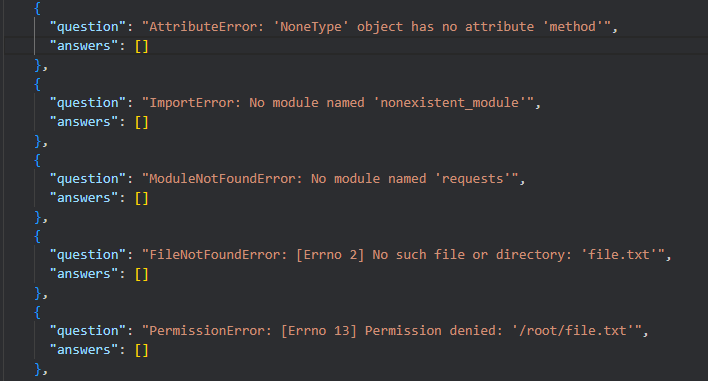
2️⃣ codex结果:
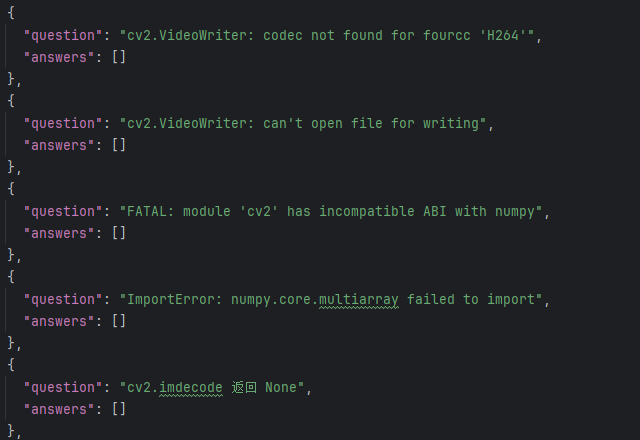
2.2 问题去重
在从不同的
coding agent中获取到问题后,还需要对问题进行处理,可能存在:① 问题重复 ② 问题幻觉 ③ 类别不平衡
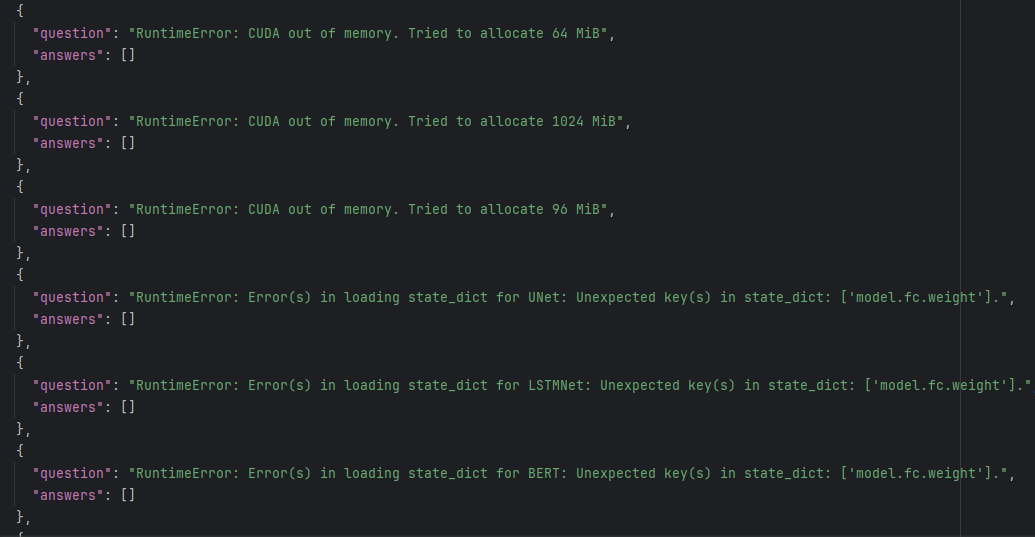
当我把所有问题考虑进去时,发现向量只剩下20个,幻觉去重以及不平衡类别的去重让数据丧失了多样性。因此,我采用精确和近似去重的算法,对问题数据进行预处理,最终剩下509个样本。

- 近似去重(精确去重无法发现)
- 幻觉去重和不平衡类别去重目前会把一些特殊的报错去除,实际上并不是幻觉,因此保留
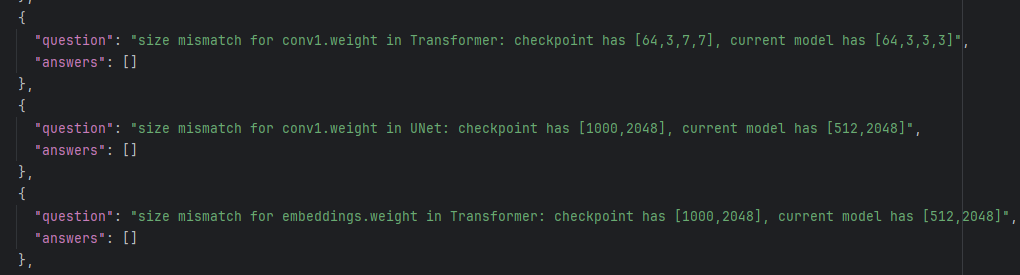
除了,语义的去重,我们也可以尝试直接通过coding agent辅助我们去重。
2.3 答案生成
本次答案生成是通过调用密钥获取不同文章的内容数据,每个问题查询25篇文章并记录。
2.4 答案压缩
step1 : 文档去重
step2 : 逐文档整篇级摘要(文内压缩),做句子级抽取式摘要(不是按段落切片)。
- 评分 = 文内“中心性”(TextRank 风格)×0.6 + 与问题的相关性(TF-IDF 余弦)×0.4。
- 用 MMR 保多样性,控制每文token 上限与句数上限(如每文 360 tokens、≤8 句)。
- 产出:每文 1 份“整篇摘要”,准备跨文档融合。
step3 : 跨文档融合(全局压缩)
- 把 25 份“整篇摘要”的句子拿出来,做相似句聚类(TF-IDF 余弦、贪心聚类)。
- 对每个簇挑“代表句”,并统计它被多少来源支持(同一来源重复只计一次)。
- 全部句子都带来源引用,如
[A3,A7,A12]
三、MCP服务
在我们写好文章获取、向量压缩的代码后,就可以将其封装为MCP服务了。例如,文章语料库获取的mcp服务如下,我们只需注解为mcp工具即可
@mcp.tool()
def search_csdn(query: str, limit: int = 8, include_sites: list[str] | None = None) -> list[str]:
"""
站内检索:默认 site:csdn.net;可通过 include_sites 扩展站群(如 'juejin.cn')。
返回: [[content]]
"""
sites = include_sites or DEFAULT_SITES
articles = _search_with_provider(query, sites, limit)
key = " ".join([ln.strip() for ln in query.splitlines() if ln.strip()][:3])
from rapidfuzz import fuzz
scored = []
corpus = []
with _http() as client:
for i, art in enumerate(articles):
time.sleep(random.randint(1, 5))
url = art.get('url')
r = client.get(url)
r.raise_for_status()
content = _extract_article(r.text, url)
art["_content"] = content['excerpt']
art["_score"] = fuzz.token_set_ratio(key, content['title'])
scored.append(art)
scored.sort(key=lambda x: x["_score"], reverse=True)
for i, it in enumerate(scored[:int(0.8*len(scored))], 1):
corpus.append(it['_content'])
return corpus
✔️ 成功搭建MCP服务
四、总结
本项目的问题数据都是由大模型生成的,很多问题其实由大模型就能解决,但是现实实践中,确实会存在着一些问题大模型解决不了,是通过csdn得以解决的。因此,欢迎各位投稿一些大模型解决不了的问题一起搭建CSDN_DEBUG MCP!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
