[数据分析]特征工程实战:如何为模型准备高质量的输入?
原创
[数据分析]特征工程实战:如何为模型准备高质量的输入?
原创
二一年冬末
修改于 2025-09-23 18:03:54
修改于 2025-09-23 18:03:54
代码可运行
运行总次数:0
代码可运行
I. 特征工程的核心价值与理论基础
1.1 特征工程的重要性
特征工程是将原始数据转换为更能代表预测模型的潜在问题的特征的过程,它直接影响模型的性能上限。根据实践经验,在机器学习项目中,特征工程通常占据整个项目时间的60%以上。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False1.2 特征工程与模型性能的关系
项目阶段 | 时间投入比例 | 对模型性能影响 | 关键活动 |
|---|---|---|---|
数据收集与清洗 | 20% | 15% | 数据获取、缺失值处理、异常值检测 |
特征工程 | 60% | 60% | 特征创建、转换、选择、降维 |
模型选择与调参 | 15% | 20% | 算法选择、超参数优化 |
模型部署与监控 | 5% | 5% | API开发、性能监控 |
1.3 特征工程知识体系

II. 数据预处理实战:构建高质量的数据基础
2.1 数据质量评估与清洗
数据质量是特征工程的基石,我们需要系统性地评估和处理数据质量问题。
class DataQualityAnalyzer:
"""数据质量分析器"""
def __init__(self):
self.quality_report = {}
def generate_sample_data(self):
"""生成包含各种数据质量问题的样本数据"""
np.random.seed(42)
n_samples = 5000
# 生成相对真实的数据集
data = {
'customer_id': range(1, n_samples+1),
'age': np.random.normal(35, 10, n_samples),
'income': np.random.lognormal(10.5, 0.8, n_samples),
'credit_score': np.random.normal(650, 100, n_samples),
'years_employed': np.random.exponential(5, n_samples),
'loan_amount': np.random.gamma(2, 5000, n_samples),
'education': np.random.choice(['高中', '本科', '硕士', '博士', '其他'],
n_samples, p=[0.3, 0.4, 0.2, 0.05, 0.05]),
'employment_type': np.random.choice(['全职', '兼职', '自由职业', '失业'],
n_samples, p=[0.7, 0.15, 0.1, 0.05]),
'marital_status': np.random.choice(['单身', '已婚', '离异', '丧偶'],
n_samples, p=[0.4, 0.4, 0.15, 0.05]),
'has_default': np.random.choice([0, 1], n_samples, p=[0.85, 0.15])
}
df = pd.DataFrame(data)
# 故意添加数据质量问题
self._introduce_data_quality_issues(df)
return df
def _introduce_data_quality_issues(self, df):
"""引入各种数据质量问题"""
n_samples = len(df)
# 1. 缺失值(5%的数据随机缺失)
missing_indices = np.random.choice(n_samples, size=int(n_samples*0.05), replace=False)
df.loc[missing_indices, 'income'] = np.nan
# 2. 异常值(3%的数据有极端值)
outlier_indices = np.random.choice(n_samples, size=int(n_samples*0.03), replace=False)
df.loc[outlier_indices, 'age'] = np.random.choice([-10, 150, 200], len(outlier_indices))
# 3. 不一致的数据(2%的数据类型错误)
inconsistent_indices = np.random.choice(n_samples, size=int(n_samples*0.02), replace=False)
df.loc[inconsistent_indices, 'credit_score'] = '未知'
# 4. 重复数据(1%的重复记录)
duplicate_indices = np.random.choice(n_samples, size=int(n_samples*0.01), replace=False)
df_duplicates = df.loc[duplicate_indices].copy()
df_duplicates['customer_id'] = range(n_samples+1, n_samples+1+len(duplicate_indices))
df = pd.concat([df, df_duplicates], ignore_index=True)
# 5. 数据输入错误
error_indices = np.random.choice(len(df), size=int(len(df)*0.02), replace=False)
df.loc[error_indices, 'employment_type'] = '全職' # 繁体字错误
return df
def comprehensive_quality_report(self, df):
"""生成全面的数据质量报告"""
report = {}
# 基本统计信息
report['shape'] = df.shape
report['data_types'] = df.dtypes.to_dict()
# 缺失值分析
missing_stats = df.isnull().sum()
missing_percentage = (missing_stats / len(df)) * 100
report['missing_values'] = pd.DataFrame({
'缺失数量': missing_stats,
'缺失比例%': missing_percentage
})
# 数值型变量统计
numerical_cols = df.select_dtypes(include=[np.number]).columns
numerical_stats = df[numerical_cols].describe()
report['numerical_stats'] = numerical_stats
# 类别型变量统计
categorical_cols = df.select_dtypes(include=['object']).columns
categorical_stats = {}
for col in categorical_cols:
categorical_stats[col] = {
'唯一值数量': df[col].nunique(),
'最常见值': df[col].mode().iloc[0] if not df[col].mode().empty else None,
'最常见值频率': df[col].value_counts().iloc[0] if not df[col].value_counts().empty else 0
}
report['categorical_stats'] = categorical_stats
# 数据质量问题检测
quality_issues = self._detect_quality_issues(df)
report['quality_issues'] = quality_issues
self.quality_report = report
return report
def _detect_quality_issues(self, df):
"""检测数据质量问题"""
issues = []
# 检测异常值(使用IQR方法)
numerical_cols = df.select_dtypes(include=[np.number]).columns
for col in numerical_cols:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df[col] < lower_bound) | (df[col] > upper_bound)]
if len(outliers) > 0:
issues.append({
'类型': '异常值',
'字段': col,
'问题描述': f'发现 {len(outliers)} 个异常值',
'严重程度': '高' if len(outliers) > len(df) * 0.05 else '中'
})
# 检测不一致的类别值
categorical_cols = df.select_dtypes(include=['object']).columns
expected_values = {
'education': ['高中', '本科', '硕士', '博士', '其他'],
'employment_type': ['全职', '兼职', '自由职业', '失业'],
'marital_status': ['单身', '已婚', '离异', '丧偶']
}
for col, expected in expected_values.items():
if col in categorical_cols:
unexpected = set(df[col].unique()) - set(expected)
if unexpected:
issues.append({
'类型': '不一致数据',
'字段': col,
'问题描述': f'发现异常值: {list(unexpected)}',
'严重程度': '中'
})
# 检测重复记录
duplicates = df[df.duplicated(subset=df.columns.difference(['customer_id']))]
if len(duplicates) > 0:
issues.append({
'类型': '重复数据',
'字段': '多字段',
'问题描述': f'发现 {len(duplicates)} 条重复记录',
'严重程度': '高'
})
return issues
def visualize_quality_issues(self, df):
"""可视化数据质量问题"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 缺失值热力图
plt.subplot(2, 3, 1)
sns.heatmap(df.isnull(), cbar=True, yticklabels=False, cmap='viridis')
plt.title('缺失值分布热力图')
# 数值变量分布
numerical_cols = df.select_dtypes(include=[np.number]).columns
if len(numerical_cols) > 0:
plt.subplot(2, 3, 2)
df[numerical_cols].boxplot(ax=plt.gca())
plt.title('数值变量分布(检测异常值)')
plt.xticks(rotation=45)
# 类别变量分布
categorical_cols = df.select_dtypes(include=['object']).columns
if len(categorical_cols) > 0:
for i, col in enumerate(categorical_cols[:2]):
plt.subplot(2, 3, 3+i)
df[col].value_counts().plot(kind='bar')
plt.title(f'{col}分布')
plt.xticks(rotation=45)
# 相关性热力图
plt.subplot(2, 3, 5)
numerical_df = df.select_dtypes(include=[np.number])
if len(numerical_df.columns) > 1:
correlation_matrix = numerical_df.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0, ax=plt.gca())
plt.title('数值变量相关性')
plt.tight_layout()
plt.show()
# 使用数据质量分析器
analyzer = DataQualityAnalyzer()
sample_data = analyzer.generate_sample_data()
quality_report = analyzer.comprehensive_quality_report(sample_data)
print("数据质量分析报告:")
print(f"数据集形状: {quality_report['shape']}")
print(f"\n缺失值统计:")
print(quality_report['missing_values'])
print(f"\n数据质量问题:")
for issue in quality_report['quality_issues']:
print(f"- {issue['类型']} ({issue['字段']}): {issue['问题描述']}")
# 可视化数据质量问题
analyzer.visualize_quality_issues(sample_data)2.2 系统化的数据清洗流程
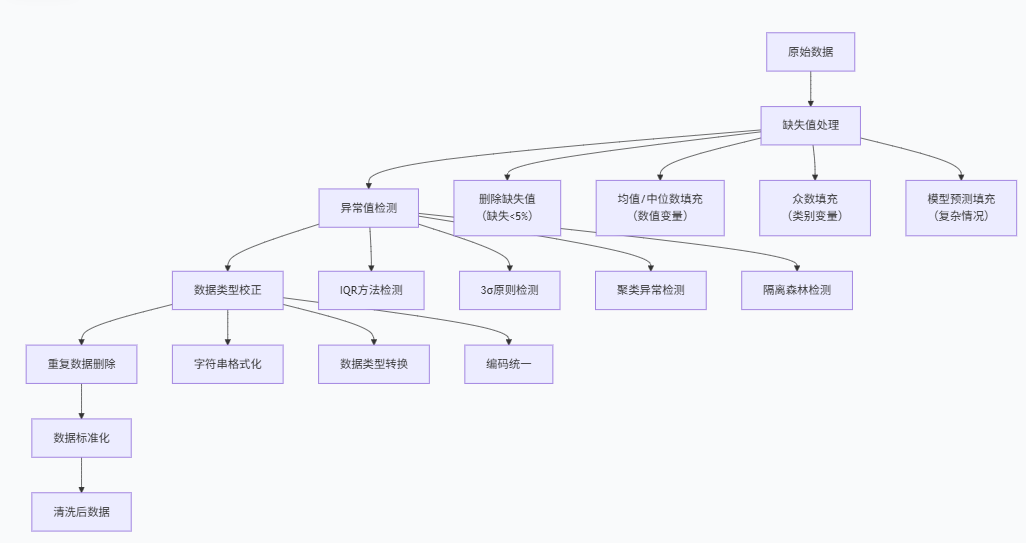
class DataCleaner:
"""数据清洗器"""
def __init__(self):
self.cleaning_strategies = {}
self.imputation_models = {}
def comprehensive_cleaning(self, df, target_col=None):
"""综合数据清洗流程"""
df_clean = df.copy()
# 记录清洗步骤
cleaning_log = []
# 步骤1: 处理重复数据
initial_shape = df_clean.shape
df_clean = self._remove_duplicates(df_clean)
final_shape = df_clean.shape
cleaning_log.append(f"删除重复记录: {initial_shape[0]} -> {final_shape[0]}")
# 步骤2: 处理缺失值
missing_before = df_clean.isnull().sum().sum()
df_clean = self._handle_missing_values(df_clean, target_col)
missing_after = df_clean.isnull().sum().sum()
cleaning_log.append(f"处理缺失值: {missing_before} -> {missing_after}")
# 步骤3: 处理异常值
outlier_count_before = self._count_outliers(df_clean)
df_clean = self._handle_outliers(df_clean)
outlier_count_after = self._count_outliers(df_clean)
cleaning_log.append(f"处理异常值: {outlier_count_before} -> {outlier_count_after}")
# 步骤4: 数据标准化和格式化
df_clean = self._standardize_data(df_clean)
cleaning_log.append("完成数据标准化")
# 步骤5: 特征类型转换
df_clean = self._convert_feature_types(df_clean)
cleaning_log.append("完成特征类型转换")
return df_clean, cleaning_log
def _remove_duplicates(self, df):
"""删除重复记录"""
# 基于业务逻辑确定唯一标识字段
key_columns = [col for col in df.columns if col != 'customer_id']
return df.drop_duplicates(subset=key_columns)
def _handle_missing_values(self, df, target_col=None):
"""智能处理缺失值"""
df_clean = df.copy()
for col in df_clean.columns:
if df_clean[col].isnull().sum() > 0:
missing_ratio = df_clean[col].isnull().sum() / len(df_clean)
# 根据缺失比例和数据类型选择策略
if missing_ratio > 0.3:
# 缺失过多,考虑删除字段
if missing_ratio > 0.5:
df_clean.drop(columns=[col], inplace=True)
continue
if df_clean[col].dtype in ['int64', 'float64']:
# 数值型变量
if missing_ratio < 0.05:
# 缺失较少,删除记录
df_clean = df_clean.dropna(subset=[col])
else:
# 使用中位数填充(对异常值更稳健)
df_clean[col].fillna(df_clean[col].median(), inplace=True)
else:
# 类别型变量
if missing_ratio < 0.05:
df_clean = df_clean.dropna(subset=[col])
else:
# 使用众数填充
mode_value = df_clean[col].mode()
if len(mode_value) > 0:
df_clean[col].fillna(mode_value[0], inplace=True)
else:
df_clean[col].fillna('未知', inplace=True)
return df_clean
def _count_outliers(self, df):
"""统计异常值数量"""
outlier_count = 0
numerical_cols = df.select_dtypes(include=[np.number]).columns
for col in numerical_cols:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df[col] < lower_bound) | (df[col] > upper_bound)]
outlier_count += len(outliers)
return outlier_count
def _handle_outliers(self, df):
"""处理异常值"""
df_clean = df.copy()
numerical_cols = df.select_dtypes(include=[np.number]).columns
for col in numerical_cols:
# 使用IQR方法检测异常值
Q1 = df_clean[col].quantile(0.25)
Q3 = df_clean[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 将异常值缩放到边界值
df_clean[col] = np.where(df_clean[col] < lower_bound, lower_bound, df_clean[col])
df_clean[col] = np.where(df_clean[col] > upper_bound, upper_bound, df_clean[col])
return df_clean
def _standardize_data(self, df):
"""数据标准化处理"""
df_clean = df.copy()
# 统一文本格式
categorical_cols = df_clean.select_dtypes(include=['object']).columns
for col in categorical_cols:
df_clean[col] = df_clean[col].astype(str).str.strip().str.replace('全職', '全职')
return df_clean
def _convert_feature_types(self, df):
"""特征类型转换"""
df_clean = df.copy()
# 将明显是数值的字符串转换为数值
for col in df_clean.columns:
if df_clean[col].dtype == 'object':
# 尝试转换为数值
try:
df_clean[col] = pd.to_numeric(df_clean[col], errors='ignore')
except:
pass
return df_clean
# 应用数据清洗
cleaner = DataCleaner()
cleaned_data, cleaning_log = cleaner.comprehensive_cleaning(sample_data)
print("数据清洗日志:")
for log_entry in cleaning_log:
print(f"- {log_entry}")
print(f"\n清洗后数据形状: {cleaned_data.shape}")
print(f"清洗后缺失值总数: {cleaned_data.isnull().sum().sum()}")III. 高级特征工程技术详解
3.1 特征构建与变换
特征构建是特征工程的核心,通过创建新特征来提升模型的表达能力。
特征类型 | 构建方法 | 适用场景 | 优势 | 注意事项 |
|---|---|---|---|---|
数值变换 | 对数、平方根、多项式 | skewed 数据、非线性关系 | 改善分布、捕捉非线性 | 注意定义域、可解释性 |
分箱处理 | 等宽分箱、等频分箱 | 连续变量离散化 | 减少噪声、处理异常值 | 信息损失、边界处理 |
交互特征 | 乘积、比值、组合 | 特征间相互作用 | 捕捉特征交互效应 | 维度爆炸、过拟合风险 |
时间特征 | 周期编码、时间差 | 时间序列数据 | 捕捉时间模式 | 季节性、趋势处理 |
文本特征 | TF-IDF、词嵌入 | 自然语言处理 | 提取语义信息 | 维度高、计算成本大 |
class AdvancedFeatureEngineer:
"""高级特征工程师"""
def __init__(self):
self.feature_operations = {}
self.encoders = {}
def create_comprehensive_features(self, df, target_col=None):
"""创建综合性特征集"""
df_features = df.copy()
# 记录特征创建过程
feature_creation_log = []
# 1. 基础数值特征变换
df_features = self._create_numeric_transformations(df_features)
feature_creation_log.append("完成数值特征变换")
# 2. 分箱特征
df_features = self._create_binning_features(df_features)
feature_creation_log.append("完成分箱特征创建")
# 3. 交互特征
df_features = self._create_interaction_features(df_features)
feature_creation_log.append("完成交互特征创建")
# 4. 多项式特征
df_features = self._create_polynomial_features(df_features)
feature_creation_log.append("完成多项式特征创建")
# 5. 领域知识特征
df_features = self._create_domain_knowledge_features(df_features)
feature_creation_log.append("完成领域知识特征创建")
# 6. 类别特征编码
df_features = self._encode_categorical_features(df_features, target_col)
feature_creation_log.append("完成类别特征编码")
return df_features, feature_creation_log
def _create_numeric_transformations(self, df):
"""数值特征变换"""
df_transformed = df.copy()
numerical_cols = df.select_dtypes(include=[np.number]).columns
for col in numerical_cols:
# 避免对ID类变量进行变换
if 'id' not in col.lower() and 'customer' not in col.lower():
# 对数变换(处理偏态分布)
if (df_transformed[col] > 0).all():
df_transformed[f'{col}_log'] = np.log1p(df_transformed[col])
# 平方根变换
if (df_transformed[col] >= 0).all():
df_transformed[f'{col}_sqrt'] = np.sqrt(df_transformed[col])
# 平方变换
df_transformed[f'{col}_square'] = df_transformed[col] ** 2
# 标准化变换
df_transformed[f'{col}_zscore'] = (
df_transformed[col] - df_transformed[col].mean()
) / df_transformed[col].std()
return df_transformed
def _create_binning_features(self, df):
"""创建分箱特征"""
df_binned = df.copy()
numerical_cols = df.select_dtypes(include=[np.number]).columns
for col in numerical_cols:
if 'id' not in col.lower() and 'customer' not in col.lower():
# 等宽分箱
df_binned[f'{col}_bin_equal_width'] = pd.cut(
df_binned[col], bins=5, labels=False, duplicates='drop'
)
# 等频分箱
df_binned[f'{col}_bin_equal_freq'] = pd.qcut(
df_binned[col], q=5, labels=False, duplicates='drop'
)
# 基于业务知识的分箱
if 'age' in col.lower():
# 年龄分组
bins = [0, 25, 35, 45, 55, 65, 100]
labels = ['青年', '中青年', '中年', '中老年', '老年', '高龄']
df_binned[f'{col}_age_group'] = pd.cut(
df_binned[col], bins=bins, labels=labels
)
if 'income' in col.lower():
# 收入分组
income_quantiles = df_binned[col].quantile([0.2, 0.4, 0.6, 0.8])
bins = [0] + income_quantiles.tolist() + [df_binned[col].max()]
labels = ['低收入', '中低收入', '中等收入', '中高收入', '高收入']
df_binned[f'{col}_income_group'] = pd.cut(
df_binned[col], bins=bins, labels=labels
)
return df_binned
def _create_interaction_features(self, df):
"""创建交互特征"""
df_interaction = df.copy()
numerical_cols = df.select_dtypes(include=[np.number]).columns
# 选择最重要的几个数值特征进行交互
if len(numerical_cols) >= 2:
main_features = numerical_cols[:3] # 取前3个主要特征
# 创建两两交互特征
for i, feat1 in enumerate(main_features):
for j, feat2 in enumerate(main_features):
if i < j: # 避免重复和自交互
# 乘积交互
df_interaction[f'{feat1}_x_{feat2}'] = (
df_interaction[feat1] * df_interaction[feat2]
)
# 比值交互(避免除零)
if (df_interaction[feat2] != 0).all():
df_interaction[f'{feat1}_div_{feat2}'] = (
df_interaction[feat1] / (df_interaction[feat2] + 1e-8)
)
# 创建三个特征的交互
if len(main_features) >= 3:
feat1, feat2, feat3 = main_features[:3]
df_interaction[f'{feat1}_x_{feat2}_x_{feat3}'] = (
df_interaction[feat1] * df_interaction[feat2] * df_interaction[feat3]
)
return df_interaction
def _create_polynomial_features(self, df):
"""创建多项式特征"""
from sklearn.preprocessing import PolynomialFeatures
df_poly = df.copy()
numerical_cols = df.select_dtypes(include=[np.number]).columns
if len(numerical_cols) >= 2:
# 选择主要特征
main_features = numerical_cols[:2]
poly = PolynomialFeatures(degree=2, include_bias=False, interaction_only=False)
poly_features = poly.fit_transform(df_poly[main_features])
poly_feature_names = poly.get_feature_names_out(main_features)
# 添加到数据框
for i, name in enumerate(poly_feature_names):
if name not in df_poly.columns: # 避免重复
df_poly[name] = poly_features[:, i]
return df_poly
def _create_domain_knowledge_features(self, df):
"""基于领域知识创建特征"""
df_domain = df.copy()
# 金融领域特征示例
if all(col in df.columns for col in ['income', 'loan_amount', 'years_employed']):
# 债务收入比
df_domain['debt_to_income_ratio'] = (
df_domain['loan_amount'] / (df_domain['income'] + 1e-8)
)
# 收入稳定性指标
df_domain['income_stability'] = df_domain['years_employed'] / (
df_domain['age'] - 18 + 1e-8 # 假设18岁开始工作
)
# 信用评分调整
if 'credit_score' in df.columns:
df_domain['credit_income_interaction'] = (
df_domain['credit_score'] * df_domain['income'] / 10000
)
# 客户价值相关特征
if 'age' in df.columns and 'income' in df.columns:
# 生命周期价值初步估算
df_domain['estimated_lifetime_value'] = (
df_domain['income'] * (65 - df_domain['age']) # 简化计算
)
return df_domain
def _encode_categorical_features(self, df, target_col=None):
"""类别特征编码"""
df_encoded = df.copy()
categorical_cols = df.select_dtypes(include=['object', 'category']).columns
for col in categorical_cols:
if df_encoded[col].nunique() <= 10: # 低基数变量使用one-hot
# One-Hot编码
dummies = pd.get_dummies(df_encoded[col], prefix=col)
df_encoded = pd.concat([df_encoded, dummies], axis=1)
df_encoded.drop(columns=[col], inplace=True)
else:
# 高基数变量使用目标编码(如果有目标变量)
if target_col and target_col in df_encoded.columns:
# 目标编码
target_mean = df_encoded.groupby(col)[target_col].mean()
df_encoded[f'{col}_target_encoded'] = df_encoded[col].map(target_mean)
df_encoded.drop(columns=[col], inplace=True)
else:
# 频率编码
freq_encoding = df_encoded[col].value_counts(normalize=True)
df_encoded[f'{col}_freq_encoded'] = df_encoded[col].map(freq_encoding)
df_encoded.drop(columns=[col], inplace=True)
return df_encoded
# 应用高级特征工程
feature_engineer = AdvancedFeatureEngineer()
enhanced_data, feature_log = feature_engineer.create_comprehensive_features(
cleaned_data, target_col='has_default'
)
print("特征工程完成日志:")
for log_entry in feature_log:
print(f"- {log_entry}")
print(f"\n特征工程后数据形状: {enhanced_data.shape}")
print(f"特征数量: {len(enhanced_data.columns)}")
print(f"前10个新特征: {list(enhanced_data.columns[:10])}")3.2 特征选择与降维
过多的特征会导致维度灾难,需要通过特征选择来优化特征集。
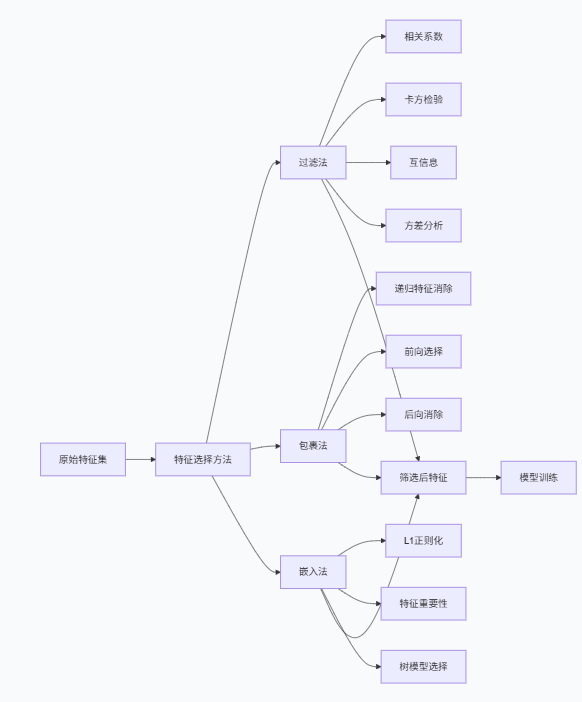
class FeatureSelector:
"""特征选择器"""
def __init__(self):
self.selection_results = {}
self.important_features = {}
def comprehensive_feature_selection(self, X, y, methods=['all']):
"""综合特征选择"""
if 'all' in methods:
methods = ['variance', 'correlation', 'mutual_info', 'rfe', 'embedded']
selection_summary = {}
# 确保X是DataFrame
if not isinstance(X, pd.DataFrame):
X = pd.DataFrame(X)
# 方法1: 方差阈值选择
if 'variance' in methods:
variance_selected = self._variance_threshold_selection(X)
selection_summary['variance'] = variance_selected
# 方法2: 高相关特征过滤
if 'correlation' in methods:
correlation_selected = self._correlation_feature_selection(X)
selection_summary['correlation'] = correlation_selected
# 方法3: 互信息选择
if 'mutual_info' in methods:
mutual_info_selected = self._mutual_information_selection(X, y)
selection_summary['mutual_info'] = mutual_info_selected
# 方法4: 递归特征消除
if 'rfe' in methods:
rfe_selected = self._recursive_feature_elimination(X, y)
selection_summary['rfe'] = rfe_selected
# 方法5: 嵌入式选择
if 'embedded' in methods:
embedded_selected = self._embedded_feature_selection(X, y)
selection_summary['embedded'] = embedded_selected
# 综合所有方法的结果
final_features = self._consensus_feature_selection(selection_summary, X.columns)
self.selection_results = selection_summary
self.important_features = final_features
return final_features, selection_summary
def _variance_threshold_selection(self, X, threshold=0.01):
"""方差阈值特征选择"""
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=threshold)
selector.fit(X)
selected_features = X.columns[selector.get_support()].tolist()
return {
'selected_features': selected_features,
'variance_threshold': threshold,
'features_removed': len(X.columns) - len(selected_features)
}
def _correlation_feature_selection(self, X, threshold=0.95):
"""高相关特征过滤"""
corr_matrix = X.corr().abs()
# 选择上三角矩阵(不含对角线)
upper_triangle = corr_matrix.where(
np.triu(np.ones_like(corr_matrix, dtype=bool), k=1)
)
# 找到相关性高于阈值的特征对
high_corr_features = [
column for column in upper_triangle.columns
if any(upper_triangle[column] > threshold)
]
# 保留一个特征从每个高相关对中
features_to_keep = list(set(X.columns) - set(high_corr_features))
return {
'selected_features': features_to_keep,
'correlation_threshold': threshold,
'features_removed': len(high_corr_features)
}
def _mutual_information_selection(self, X, y, k=10):
"""互信息特征选择"""
from sklearn.feature_selection import mutual_info_classif, SelectKBest
# 计算互信息
mi_scores = mutual_info_classif(X, y, random_state=42)
# 选择Top K特征
selector = SelectKBest(score_func=mutual_info_classif, k=min(k, len(X.columns)))
selector.fit(X, y)
selected_features = X.columns[selector.get_support()].tolist()
return {
'selected_features': selected_features,
'mi_scores': dict(zip(X.columns, mi_scores)),
'top_k': k
}
def _recursive_feature_elimination(self, X, y, n_features=20):
"""递归特征消除"""
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
estimator = RandomForestClassifier(n_estimators=100, random_state=42)
selector = RFE(estimator, n_features_to_select=min(n_features, len(X.columns)))
selector.fit(X, y)
selected_features = X.columns[selector.support_].tolist()
return {
'selected_features': selected_features,
'feature_ranking': selector.ranking_,
'n_features_selected': n_features
}
def _embedded_feature_selection(self, X, y, threshold='mean'):
"""嵌入式特征选择"""
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
estimator = RandomForestClassifier(n_estimators=100, random_state=42)
estimator.fit(X, y)
selector = SelectFromModel(estimator, threshold=threshold)
selector.fit(X, y)
selected_features = X.columns[selector.get_support()].tolist()
return {
'selected_features': selected_features,
'feature_importances': dict(zip(X.columns, estimator.feature_importances_)),
'threshold': threshold
}
def _consensus_feature_selection(self, selection_summary, all_features):
"""共识特征选择(综合多种方法)"""
feature_votes = {feature: 0 for feature in all_features}
# 统计每个特征被选择的方法数量
for method, result in selection_summary.items():
if 'selected_features' in result:
for feature in result['selected_features']:
feature_votes[feature] += 1
# 选择被多数方法认可的特征
max_votes = max(feature_votes.values())
consensus_threshold = max(1, max_votes // 2) # 至少被一半方法选择
consensus_features = [
feature for feature, votes in feature_votes.items()
if votes >= consensus_threshold
]
# 如果共识特征太少,选择得票最多的前20个特征
if len(consensus_features) < 10:
sorted_features = sorted(feature_votes.items(), key=lambda x: x[1], reverse=True)
consensus_features = [feature for feature, votes in sorted_features[:20]]
return consensus_features
def visualize_feature_selection(self, X, y):
"""可视化特征选择结果"""
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# 特征重要性图
if 'embedded' in self.selection_results:
importances = self.selection_results['embedded']['feature_importances']
top_features = sorted(importances.items(), key=lambda x: x[1], reverse=True)[:15]
features, scores = zip(*top_features)
plt.subplot(2, 2, 1)
plt.barh(range(len(features)), scores)
plt.yticks(range(len(features)), features)
plt.xlabel('特征重要性')
plt.title('Top 15特征重要性')
# 互信息得分
if 'mutual_info' in self.selection_results:
mi_scores = self.selection_results['mutual_info']['mi_scores']
top_mi = sorted(mi_scores.items(), key=lambda x: x[1], reverse=True)[:15]
features, scores = zip(*top_mi)
plt.subplot(2, 2, 2)
plt.barh(range(len(features)), scores)
plt.yticks(range(len(features)), features)
plt.xlabel('互信息得分')
plt.title('Top 15互信息特征')
# 特征选择方法一致性
methods = list(self.selection_results.keys())
feature_counts = []
for method in methods:
if 'selected_features' in self.selection_results[method]:
feature_counts.append(
len(self.selection_results[method]['selected_features'])
)
plt.subplot(2, 2, 3)
plt.bar(methods, feature_counts)
plt.xlabel('特征选择方法')
plt.ylabel('选择特征数量')
plt.title('各方法选择特征数量对比')
plt.xticks(rotation=45)
# 最终选择特征展示
plt.subplot(2, 2, 4)
final_count = len(self.important_features)
original_count = len(X.columns)
plt.pie([final_count, original_count - final_count],
labels=['选择特征', '淘汰特征'], autopct='%1.1f%%')
plt.title(f'特征选择结果: {final_count}/{original_count}')
plt.tight_layout()
plt.show()
# 应用特征选择
# 准备数据
X = enhanced_data.drop('has_default', axis=1, errors='ignore')
y = enhanced_data['has_default'] if 'has_default' in enhanced_data.columns else pd.Series([0]*len(enhanced_data))
# 确保y是整数类型
y = y.astype(int)
selector = FeatureSelector()
selected_features, selection_summary = selector.comprehensive_feature_selection(X, y)
print("特征选择结果汇总:")
for method, result in selection_summary.items():
if 'selected_features' in result:
print(f"{method}: 选择了 {len(result['selected_features'])} 个特征")
print(f"\n最终共识特征数量: {len(selected_features)}")
print(f"特征减少比例: {(1 - len(selected_features)/len(X.columns))*100:.1f}%")
# 可视化特征选择结果
selector.visualize_feature_selection(X, y)IV. 特征工程效果验证与模型性能对比
4.1 特征工程效果评估框架
为了验证特征工程的效果,我们需要建立系统的评估框架。
class FeatureEngineeringValidator:
"""特征工程效果验证器"""
def __init__(self):
self.validation_results = {}
def comprehensive_validation(self, original_data, engineered_data, target_col, test_size=0.3):
"""综合验证特征工程效果"""
validation_results = {}
# 准备数据
X_original = original_data.drop(target_col, axis=1)
y = original_data[target_col]
X_engineered = engineered_data.drop(target_col, axis=1)
# 确保特征名称一致性
X_original = X_original.select_dtypes(include=[np.number])
X_engineered = X_engineered.select_dtypes(include=[np.number])
# 1. 基础模型性能对比
baseline_performance = self._compare_model_performance(
X_original, X_engineered, y, test_size
)
validation_results['model_performance'] = baseline_performance
# 2. 特征质量评估
feature_quality = self._evaluate_feature_quality(X_original, X_engineered, y)
validation_results['feature_quality'] = feature_quality
# 3. 计算效率对比
efficiency_comparison = self._compare_computational_efficiency(
X_original, X_engineered, y
)
validation_results['efficiency'] = efficiency_comparison
# 4. 稳定性测试
stability_test = self._test_model_stability(X_original, X_engineered, y)
validation_results['stability'] = stability_test
self.validation_results = validation_results
return validation_results
def _compare_model_performance(self, X_original, X_engineered, y, test_size):
"""对比模型性能"""
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
models = {
'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42)
}
performance_comparison = {}
for model_name, model in models.items():
# 原始特征性能
X_train_orig, X_test_orig, y_train, y_test = train_test_split(
X_original, y, test_size=test_size, random_state=42, stratify=y
)
model_orig = model.fit(X_train_orig, y_train)
y_pred_orig = model_orig.predict(X_test_orig)
y_pred_proba_orig = model_orig.predict_proba(X_test_orig)[:, 1]
# 工程特征性能
X_train_eng, X_test_eng, y_train, y_test = train_test_split(
X_engineered, y, test_size=test_size, random_state=42, stratify=y
)
model_eng = model.fit(X_train_eng, y_train)
y_pred_eng = model_eng.predict(X_test_eng)
y_pred_proba_eng = model_eng.predict_proba(X_test_eng)[:, 1]
# 计算指标
metrics_orig = {
'accuracy': accuracy_score(y_test, y_pred_orig),
'precision': precision_score(y_test, y_pred_orig),
'recall': recall_score(y_test, y_pred_orig),
'f1': f1_score(y_test, y_pred_orig),
'roc_auc': roc_auc_score(y_test, y_pred_proba_orig)
}
metrics_eng = {
'accuracy': accuracy_score(y_test, y_pred_eng),
'precision': precision_score(y_test, y_pred_eng),
'recall': recall_score(y_test, y_pred_eng),
'f1': f1_score(y_test, y_pred_eng),
'roc_auc': roc_auc_score(y_test, y_pred_proba_eng)
}
# 计算提升比例
improvement = {
metric: (metrics_eng[metric] - metrics_orig[metric]) / metrics_orig[metric] * 100
for metric in metrics_orig.keys()
}
performance_comparison[model_name] = {
'original': metrics_orig,
'engineered': metrics_eng,
'improvement_%': improvement
}
return performance_comparison
def _evaluate_feature_quality(self, X_original, X_engineered, y):
"""评估特征质量"""
from sklearn.feature_selection import mutual_info_classif
from scipy.stats import spearmanr
quality_metrics = {}
# 特征与目标的相关性
if len(X_original.columns) > 0:
orig_corr = X_original.apply(lambda x: abs(spearmanr(x, y).correlation)).mean()
else:
orig_corr = 0
engineered_corr = X_engineered.apply(lambda x: abs(spearmanr(x, y).correlation)).mean()
# 互信息
if len(X_original.columns) > 0:
orig_mi = mutual_info_classif(X_original, y, random_state=42).mean()
else:
orig_mi = 0
engineered_mi = mutual_info_classif(X_engineered, y, random_state=42).mean()
# 特征间相关性(多重共线性)
if len(X_original.columns) > 1:
orig_corr_matrix = X_original.corr().abs()
np.fill_diagonal(orig_corr_matrix.values, 0)
orig_multicollinearity = orig_corr_matrix.max().max()
else:
orig_multicollinearity = 0
engineered_corr_matrix = X_engineered.corr().abs()
np.fill_diagonal(engineered_corr_matrix.values, 0)
engineered_multicollinearity = engineered_corr_matrix.max().max()
quality_metrics = {
'feature_target_correlation': {
'original': orig_corr,
'engineered': engineered_corr,
'improvement': engineered_corr - orig_corr
},
'mutual_information': {
'original': orig_mi,
'engineered': engineered_mi,
'improvement': engineered_mi - orig_mi
},
'multicollinearity': {
'original': orig_multicollinearity,
'engineered': engineered_multicollinearity,
'improvement': engineered_multicollinearity - orig_multicollinearity
}
}
return quality_metrics
def _compare_computational_efficiency(self, X_original, X_engineered, y):
"""比较计算效率"""
import time
from sklearn.ensemble import RandomForestClassifier
efficiency_metrics = {}
# 训练时间比较
model = RandomForestClassifier(n_estimators=50, random_state=42)
start_time = time.time()
if len(X_original.columns) > 0:
model.fit(X_original, y)
orig_training_time = time.time() - start_time
start_time = time.time()
model.fit(X_engineered, y)
engineered_training_time = time.time() - start_time
# 预测时间比较
start_time = time.time()
if len(X_original.columns) > 0:
model.predict(X_original)
orig_prediction_time = time.time() - start_time
start_time = time.time()
model.predict(X_engineered)
engineered_prediction_time = time.time() - start_time
efficiency_metrics = {
'training_time_seconds': {
'original': orig_training_time,
'engineered': engineered_training_time,
'ratio': engineered_training_time / orig_training_time if orig_training_time > 0 else 1
},
'prediction_time_seconds': {
'original': orig_prediction_time,
'engineered': engineered_prediction_time,
'ratio': engineered_prediction_time / orig_prediction_time if orig_prediction_time > 0 else 1
},
'feature_count': {
'original': len(X_original.columns),
'engineered': len(X_engineered.columns),
'ratio': len(X_engineered.columns) / len(X_original.columns) if len(X_original.columns) > 0 else 1
}
}
return efficiency_metrics
def _test_model_stability(self, X_original, X_engineered, y, n_iterations=10):
"""测试模型稳定性"""
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
stability_metrics = {}
model = RandomForestClassifier(n_estimators=50, random_state=42)
if len(X_original.columns) > 0:
orig_scores = cross_val_score(model, X_original, y, cv=5, scoring='f1')
orig_stability = orig_scores.std() # 标准差越小越稳定
else:
orig_stability = 0
engineered_scores = cross_val_score(model, X_engineered, y, cv=5, scoring='f1')
engineered_stability = engineered_scores.std()
stability_metrics = {
'cv_score_std': {
'original': orig_stability,
'engineered': engineered_stability,
'improvement': orig_stability - engineered_stability # 越小越好
},
'cv_score_mean': {
'original': orig_scores.mean() if len(X_original.columns) > 0 else 0,
'engineered': engineered_scores.mean(),
'improvement': engineered_scores.mean() - (orig_scores.mean() if len(X_original.columns) > 0 else 0)
}
}
return stability_metrics
def generate_validation_report(self):
"""生成验证报告"""
report = {}
if not self.validation_results:
print("请先运行验证过程")
return
# 模型性能总结
model_performance = self.validation_results['model_performance']
performance_summary = {}
for model_name, results in model_performance.items():
improvements = results['improvement_%']
avg_improvement = np.mean(list(improvements.values()))
performance_summary[model_name] = avg_improvement
report['performance_summary'] = performance_summary
# 特征质量总结
feature_quality = self.validation_results['feature_quality']
quality_summary = {
'correlation_improvement': feature_quality['feature_target_correlation']['improvement'],
'mi_improvement': feature_quality['mutual_information']['improvement']
}
report['quality_summary'] = quality_summary
# 效率总结
efficiency = self.validation_results['efficiency']
efficiency_summary = {
'training_time_ratio': efficiency['training_time_seconds']['ratio'],
'prediction_time_ratio': efficiency['prediction_time_seconds']['ratio'],
'feature_count_ratio': efficiency['feature_count']['ratio']
}
report['efficiency_summary'] = efficiency_summary
return report
def visualize_validation_results(self):
"""可视化验证结果"""
if not self.validation_results:
print("请先运行验证过程")
return
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# 模型性能对比
model_performance = self.validation_results['model_performance']
models = list(model_performance.keys())
metrics = ['accuracy', 'precision', 'recall', 'f1', 'roc_auc']
metric_labels = ['准确率', '精确率', '召回率', 'F1分数', 'AUC']
improvement_data = []
for model in models:
improvements = [model_performance[model]['improvement_%'][metric] for metric in metrics]
improvement_data.append(improvements)
x = np.arange(len(metrics))
width = 0.35
plt.subplot(2, 2, 1)
for i, model in enumerate(models):
plt.bar(x + i*width, improvement_data[i], width, label=model)
plt.xlabel('评估指标')
plt.ylabel('性能提升 (%)')
plt.title('特征工程对模型性能的提升')
plt.xticks(x + width/2, metric_labels, rotation=45)
plt.legend()
plt.grid(True, alpha=0.3)
# 特征质量对比
feature_quality = self.validation_results['feature_quality']
quality_metrics = ['feature_target_correlation', 'mutual_information']
metric_labels = ['特征-目标相关性', '互信息']
original_quality = [feature_quality[metric]['original'] for metric in quality_metrics]
engineered_quality = [feature_quality[metric]['engineered'] for metric in quality_metrics]
plt.subplot(2, 2, 2)
x = np.arange(len(quality_metrics))
plt.bar(x - 0.2, original_quality, 0.4, label='原始特征', alpha=0.7)
plt.bar(x + 0.2, engineered_quality, 0.4, label='工程特征', alpha=0.7)
plt.xlabel('质量指标')
plt.ylabel('得分')
plt.title('特征质量对比')
plt.xticks(x, metric_labels)
plt.legend()
plt.grid(True, alpha=0.3)
# 计算效率对比
efficiency = self.validation_results['efficiency']
efficiency_metrics = ['training_time_seconds', 'prediction_time_seconds']
metric_labels = ['训练时间', '预测时间']
original_efficiency = [efficiency[metric]['original'] for metric in efficiency_metrics]
engineered_efficiency = [efficiency[metric]['engineered'] for metric in efficiency_metrics]
plt.subplot(2, 2, 3)
x = np.arange(len(efficiency_metrics))
plt.bar(x - 0.2, original_efficiency, 0.4, label='原始特征', alpha=0.7)
plt.bar(x + 0.2, engineered_efficiency, 0.4, label='工程特征', alpha=0.7)
plt.xlabel('效率指标')
plt.ylabel('时间 (秒)')
plt.title('计算效率对比')
plt.xticks(x, metric_labels)
plt.legend()
plt.grid(True, alpha=0.3)
# 稳定性对比
stability = self.validation_results['stability']
stability_metrics = ['cv_score_std', 'cv_score_mean']
metric_labels = ['CV标准差\n(越小越好)', 'CV平均分\n(越大越好)']
original_stability = [stability[metric]['original'] for metric in stability_metrics]
engineered_stability = [stability[metric]['engineered'] for metric in stability_metrics]
plt.subplot(2, 2, 4)
x = np.arange(len(stability_metrics))
plt.bar(x - 0.2, original_stability, 0.4, label='原始特征', alpha=0.7)
plt.bar(x + 0.2, engineered_stability, 0.4, label='工程特征', alpha=0.7)
plt.xlabel('稳定性指标')
plt.ylabel('得分')
plt.title('模型稳定性对比')
plt.xticks(x, metric_labels)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 运行特征工程效果验证
validator = FeatureEngineeringValidator()
# 准备对比数据(使用清洗后但未进行高级特征工程的数据)
original_features = cleaned_data.select_dtypes(include=[np.number])
if 'has_default' in original_features.columns:
original_features = original_features.drop('has_default', axis=1)
engineered_features = enhanced_data.select_dtypes(include=[np.number])
if 'has_default' in engineered_features.columns:
engineered_features = engineered_features.drop('has_default', axis=1)
# 确保目标变量一致
target = cleaned_data['has_default'] if 'has_default' in cleaned_data.columns else enhanced_data['has_default']
validation_results = validator.comprehensive_validation(
pd.concat([original_features, target], axis=1),
pd.concat([engineered_features, target], axis=1),
'has_default'
)
# 生成验证报告
validation_report = validator.generate_validation_report()
print("特征工程效果验证报告:")
print("\n模型性能提升总结:")
for model, improvement in validation_report['performance_summary'].items():
print(f"{model}: 平均提升 {improvement:.2f}%")
print("\n特征质量提升总结:")
print(f"特征-目标相关性提升: {validation_report['quality_summary']['correlation_improvement']:.4f}")
print(f"互信息提升: {validation_report['quality_summary']['mi_improvement']:.4f}")
print("\n计算效率总结:")
print(f"训练时间比率: {validation_report['efficiency_summary']['training_time_ratio']:.2f}")
print(f"特征数量比率: {validation_report['efficiency_summary']['feature_count_ratio']:.2f}")
# 可视化验证结果
validator.visualize_validation_results()原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
