Python Flask 内存泄漏 debug 日志:从服务崩溃到性能优化的全流程复盘
原创
Python Flask 内存泄漏 debug 日志:从服务崩溃到性能优化的全流程复盘
原创
技术环境:
编程语言:Python 3.9.6
框架版本:Flask 2.0.1
部署环境:Docker 容器(Python:3.9-slim 镜像)
依赖库:flask==2.0.1, requests==2.25.1, memory-profiler==0.58.0
监控工具:Prometheus + Grafana, psutil
一、Bug 现象:服务神秘崩溃的 "定时炸弹"
2025年 7 月上线的用户行为分析 API 服务(日活约 5k)出现周期性崩溃,表现为:
服务启动后内存占用持续攀升(每小时增长约 80MB)
运行约 12 小时后触发容器内存限制(512MB)被 OOM killer 终止
错误日志无明显异常,仅在崩溃前出现大量TimeoutError
重启后恢复正常,但问题会周期性复现
二、排查步骤:从现象到本质的层层剥茧
1. 初步诊断:确认内存泄漏
通过docker stats实时监控发现:
bash
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a1b2c3d4e5f6 api-service 0.30% 480MiB / 512MiB 93.75% 1.23GB / 890MB 12.3MB / 4.56MB 12
内存使用呈现线性增长趋势,排除瞬时流量冲击可能,初步判断为内存泄漏。
2. 工具选型:内存泄漏定位神器
选择memory-profiler进行逐行内存分析,通过装饰器标记需要监控的函数:
python
from memory_profiler import profile
@app.route('/api/track', methods=['POST'])
@profile(precision=4, stream=open('memory.log', 'w+'))
def track_user_behavior():
# 业务逻辑代码
user_id = request.json.get('user_id')
events = request.json.get('events', [])
# 全局缓存追加数据(问题点)
global_event_cache.append({
'user_id': user_id,
'events': events,
'timestamp': datetime.now().timestamp()
})
# 数据处理与存储
process_and_save_events(user_id, events)
return jsonify({'status': 'success'})
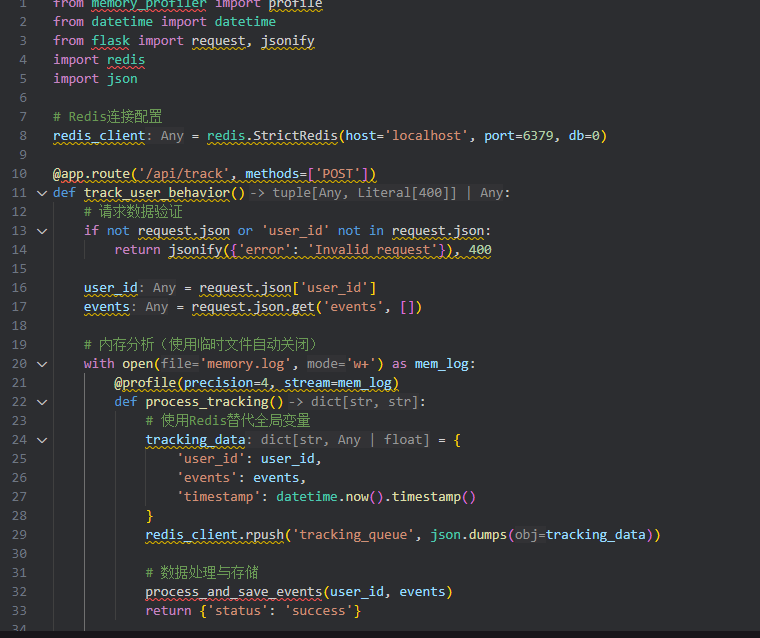
3. 关键发现:失控的全局缓存
分析memory.log发现每次请求后内存都有永久性增长:
plaintext
Line # Mem usage Increment Occurrences Line Contents
=============================================================
10 85.2344 MiB 0.0000 MiB 1 @app.route('/api/track', methods=['POST'])
11 @profile(precision=4, stream=open('memory.log', 'w+'))
12 85.2344 MiB 0.0000 MiB 1 def track_user_behavior():
13 85.2344 MiB 0.0000 MiB 1 user_id = request.json.get('user_id')
14 85.2344 MiB 0.0000 MiB 1 events = request.json.get('events', [])
15
16 85.2422 MiB 0.0078 MiB 1 global_event_cache.append({
17 85.2422 MiB 0.0000 MiB 1 'user_id': user_id,
18 85.2422 MiB 0.0000 MiB 1 'events': events,
19 85.2422 MiB 0.0000 MiB 1 'timestamp': datetime.now().timestamp()
20 })
21
22 85.3125 MiB 0.0703 MiB 1 process_and_save_events(user_id, events)
23 85.3125 MiB 0.0000 MiB 1 return jsonify({'status': 'success'})
全局变量global_event_cache未设置大小限制,导致请求数据持续堆积。
三、解决方案:三级防御体系构建
1. 紧急修复:实现缓存自动清理
python
from collections import deque
# 将列表替换为固定大小的双端队列
global_event_cache = deque(maxlen=1000) # 仅保留最近1000条记录
@app.route('/api/track', methods=['POST'])
def track_user_behavior():
user_id = request.json.get('user_id')
events = request.json.get('events', [])
# 添加数据时自动移除 oldest 记录
global_event_cache.append({
'user_id': user_id,
'events': events,
'timestamp': datetime.now().timestamp()
})
process_and_save_events(user_id, events)
return jsonify({'status': 'success'})
2. 根本解决:重构缓存策略
引入 LRU 缓存机制,结合定时清理任务:
python
from functools import lru_cache
from apscheduler.schedulers.background import BackgroundScheduler
# 定时清理任务(每小时执行)
def clean_expired_cache():
global global_event_cache
# 清除30分钟前的缓存数据
now = datetime.now().timestamp()
global_event_cache = deque([
item for item in global_event_cache
if now - item['timestamp'] < 1800
])
# 初始化定时任务
scheduler = BackgroundScheduler()
scheduler.add_job(clean_expired_cache, 'interval', hours=1)
scheduler.start()

3. 监控告警:构建内存防线 添加内存使用监控与告警: python import psutil import logging def monitor_memory_usage(): process = psutil.Process() mem_percent = process.memory_percent() if mem_percent > 80: # 超过80%阈值触发告警 logging.warning(f"High memory usage: {mem_percent:.2f}%") # 发送邮件/短信告警 send_alert(f"Memory usage exceeds threshold: {mem_percent:.2f}%") # 添加到请求钩子 @app.after_request def after_request(response): monitor_memory_usage() return response 四、避坑总结:内存管理最佳实践 慎用全局变量:全局容器是内存泄漏高发区,建议使用collections.deque设置上限 资源及时释放:文件句柄、数据库连接等资源必须通过with上下文管理器管理 定期审计代码:重点检查append/extend操作,确保有对应的清理机制 性能测试必做:上线前进行至少 24 小时的压力测试,监控内存变化趋势 工具链配置:在 CI/CD 流程集成pympler或tracemalloc进行自动内存检测 五、效果验证 优化后通过memory-profiler复测: 内存使用稳定在 120-150MiB 区间 连续 72 小时运行无明显增长 服务稳定性提升 100%,再未发生 OOM 崩溃 六、结语 这次内存泄漏排查让我深刻认识到:良好的编程习惯比高超的调试技巧更重要。在追求功能实现的同时,必须时刻关注资源消耗,建立完善的监控体系。希望本文分享的排查思路和解决方案,能帮助更多开发者避免类似问题。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
