从 ClickHouse 到 StarRocks 存算分离: 携程 UBT 架构升级实践
原创
从 ClickHouse 到 StarRocks 存算分离: 携程 UBT 架构升级实践
原创
StarRocks
发布于 2025-10-18 19:27:40
发布于 2025-10-18 19:27:40

作者:魏宁 携程大数据平台开发专家
导读: 在携程庞大的数据体系中,UBT(User Behavior Tracking,用户行为追踪系统)承担着核心的用户行为采集与分析任务,日新增数据量高达 30 TB。为应对不断增长的业务与性能需求,携程技术团队将 UBT 从 ClickHouse 迁移至 StarRocks 存算分离架构。 迁移后,系统实现了查询性能从秒级到毫秒级的跨越——平均查询耗时由 1.4 秒降至 203 毫秒,P95 延迟仅 800 毫秒;同时,存储量减少一半,节点数由 50 个降至 40 个。本文将介绍携程如何借助 StarRocks,在性能与成本之间实现高效平衡。
UBT 架构
UBT 的核心功能是对用户行为进行埋点追踪,并基于埋点数据进行查询与分析,例如系统是否发生报错等。它主要面向多端应用场景,包括 Android、iOS 和 NodeJS 等,通过调用 SDK,将埋点数据进行初步处理和过滤后发送至下游系统进行进一步加工。
该系统广泛应用于排障统计和监控等场景,日均新增数据量约 30 TB,数据一般保留 30 天,部分表则会保留长达 一年。典型的查询场景包括基于 UID 或 VID 结合时间范围的日志明细查询,以及一些常见的聚合统计分析。
下图展示了 UBT 的整体架构。最上层为客户端,例如移动端 App、Web 端和 PC 端。
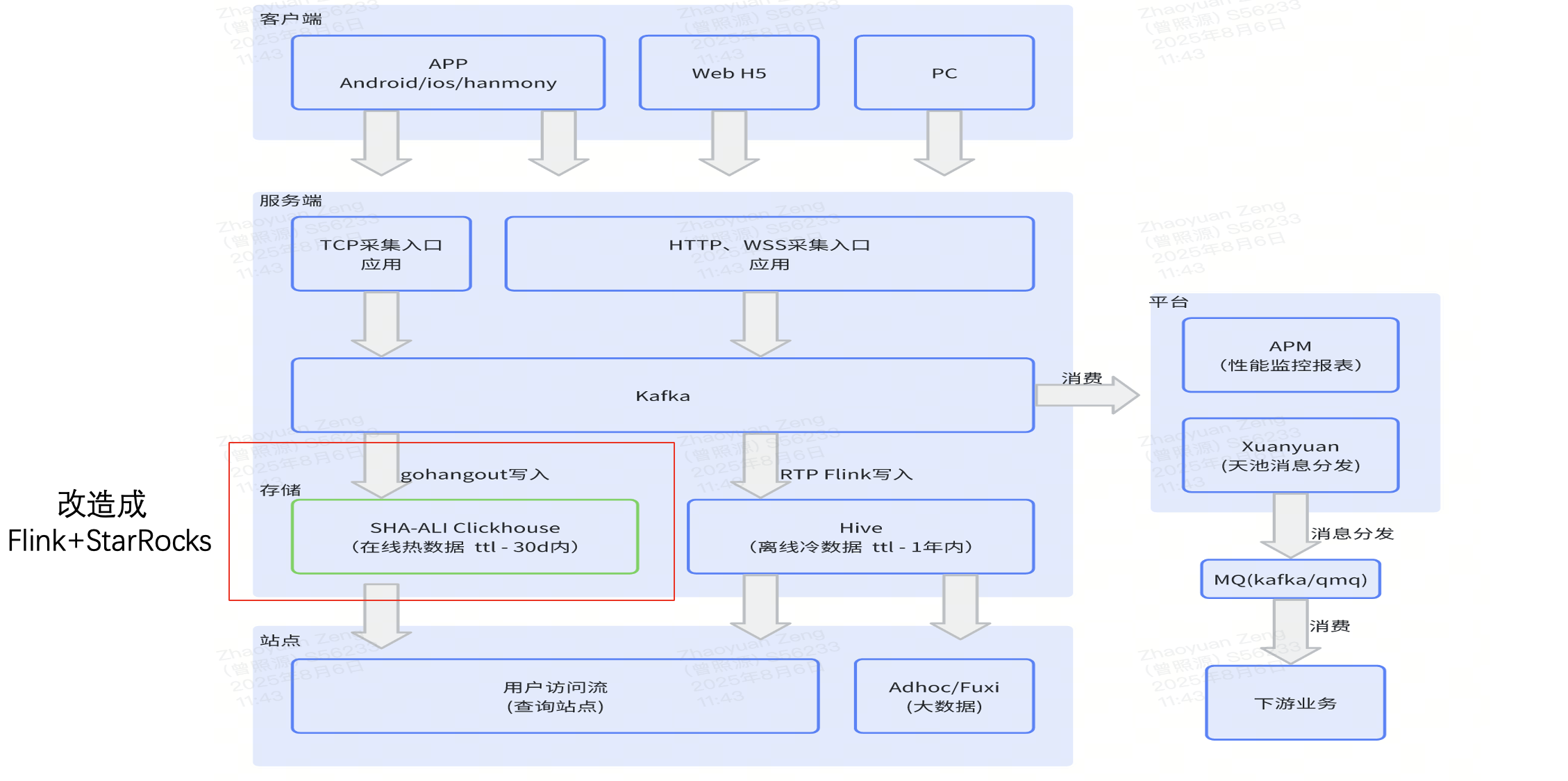
当埋点数据被服务端采集后,会首先写入 Kafka。Kafka 的数据有两条消费路径:
- 路径一:通过 gohangout 消费并写入 ClickHouse。这一路链路承载实时数据,主要用于用户排查与简单统计。
- 路径二:通过 Flink 将数据写入 Hive,作为冷存储,用于更复杂的业务分析。
此外,右侧还有多个业务平台基于这些数据进行消费和处理。
本次改造的重点在于上图中红色框标注部分——即 gohangout + ClickHouse,最终将其替换为 Flink + StarRocks。
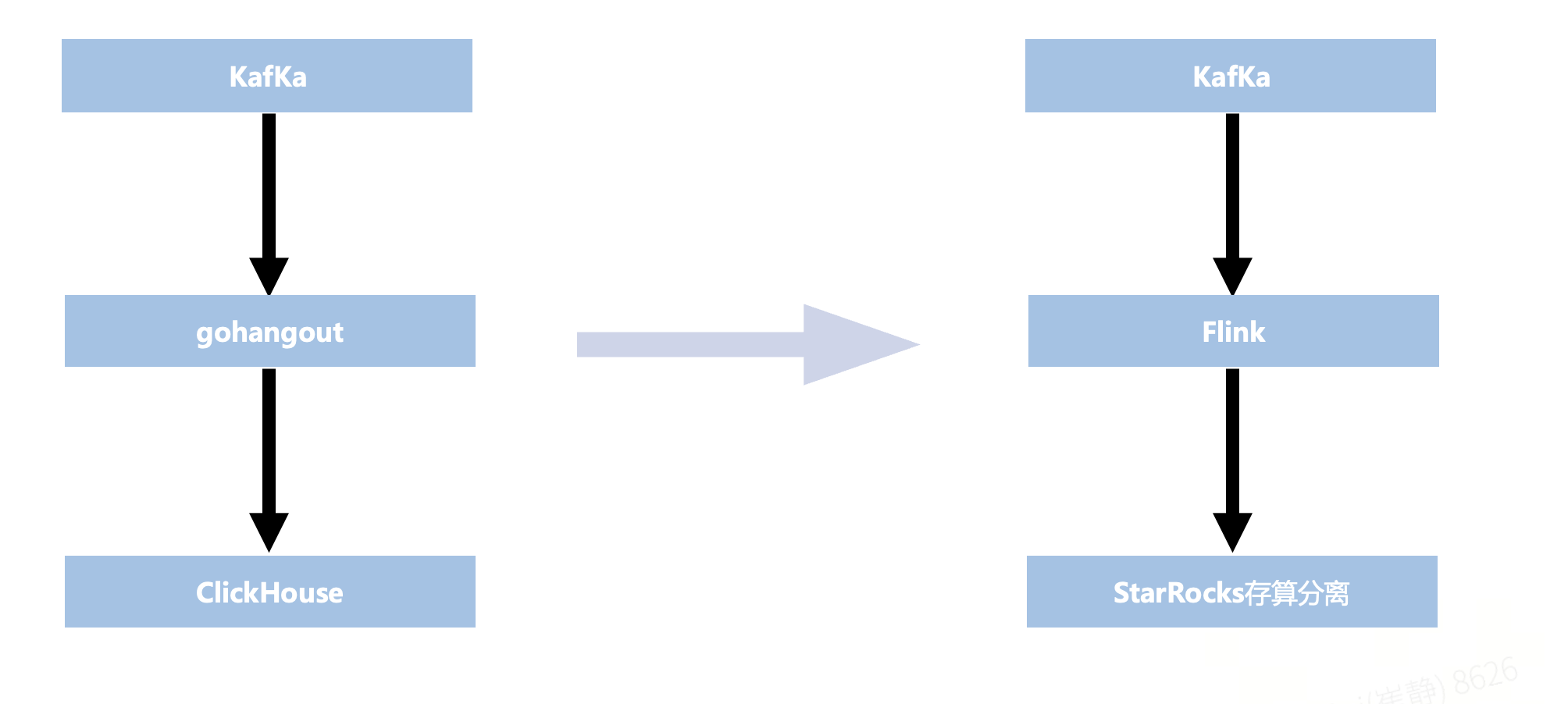
UBT 目前遇到的问题
推动此次改造的主要原因,是在使用 ClickHouse 过程中遇到了一些难以解决的问题。
- 写入问题:
- 在写入 UBT 数据时,ClickHouse 出现了数据丢失和消费积压的情况。究其原因,主要在于 UBT 除了写入实时数据,还涉及一定量的历史数据回补。
- 这类历史数据通常覆盖时间跨度较大,容易引发历史分区的压缩操作,从而导致集群的 CPU 与 I/O 资源消耗过高,系统整体负载显著上升。
- 水平扩展:
- ClickHouse 采用存算一体架构,扩容时不可避免地涉及数据迁移,过程复杂且对集群稳定性带来影响,扩展弹性不足。
- 面对海量数据,ClickHouse 对存储与硬件机型的要求较高,不仅配置特殊、难以适配,而且为了保证数据可靠性往往需要设置三副本,存储开销随之成倍增加。
- 性能问题:在大时间跨度的查询场景中,ClickHouse 的 SQL 响应速度偏慢,难以满足实时分析的需求。这一问题在高并发和海量数据场景下尤为突出。
另外使用gohangout也存在一些问题。
- 稳定性:gohangout 仅为单进程,依赖外部重试机制,稳定性不足。而Flink 具备分布式架构,支持自动 failover 和自动扩缩容,能够确保高可用性
- 便利性:在使用体验上,gohangout 的配置语法相对繁琐,业务人员在日常使用时需要投入额外的学习和维护成本,增加了操作难度。实时团队基于 Flink 构建了 RTP(Flink 管理平台)。用户可以在平台上直接编写 Flink SQL,将 Kafka 数据进行过滤、转换等处理,实现完全自主的配置与可视化管理,大幅提升了易用性。
从 ClickHouse 到 StarRocks
基于以上痛点,团队决定引入 StarRocks。早期 StarRocks 采用存算一体架构,计算与存储紧密耦合,本地数据访问带来极快的查询性能,通常可实现毫秒级返回。但这种模式也存在资源利用僵化、扩展负担过重、存储副本冗余带来高成本等问题。
因此,StarRocks 进一步演进为存算分离架构:计算节点无状态化,仅保留计算引擎,能够根据业务需求灵活调度;存储则托管于远端对象存储(OSS/S3),实现计算与存储的彻底解耦,另外为了保证查询速度,计算节点可以打开 DataCache。该架构既提升了资源利用率,避免资源浪费,又显著降低了存储成本,同时也保证了查询速度。例如,相比存算一体架构下的三副本冗余,存算分离模式仅需一份本地副本即可保障可靠性。
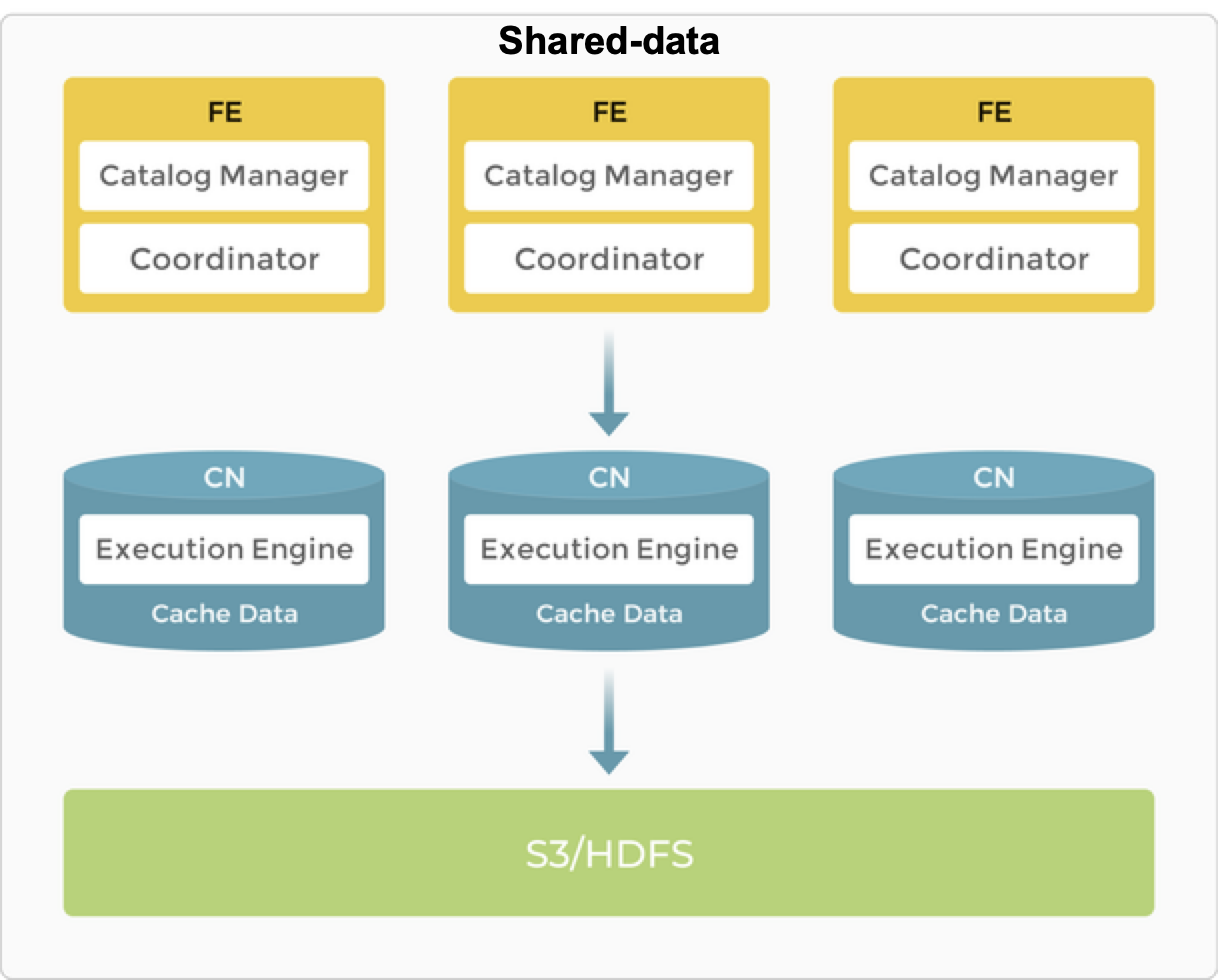
StarRocks 存算分离架构下,计算节点扩缩容不涉及实际数据的迁移,因此可以秒级完成,极致灵活,且对业务无任何干扰。在实际生产环境中,UBT 的一次扩缩容仅耗时约 5 秒。
稳定性与调优
存储设计

UBT 系统总数据量约为 1PB,其中最大的单表规模达到 400TB,包含 1.8 万亿行数据。写入压力巨大:整体写入速率约为每秒 300 万行 / 10GB,其中单表最大写入量达到每秒 100 万行 / 3.5GB。
在读取场景中,主要分为两类:一类是基于 VID 等字段的明细查询,另一类是常见的 聚合分析。其中,约 90% 的查询集中在 7 天内的数据,因此在存储设计时,需要重点围绕这一特征进行优化。
因此在设计上需要围绕读写两方面进行考虑。
- 分区键设计上,StarRocks采用 系统时间 分区,每次只写入当前分区,有效解决了写入过程中的数据碎片与稳定性问题;而 ClickHouse 使用的是 业务时间 分区,每次写入近三天分区,分区跨度大,容易产生大量碎片,导致写入不够稳定。
- 表设计上采用小时级分区。由于写入量极大,小时分区能够有效控制每次Compaction 时的数据量。同时,将 Bucket 数设置为 128,以提升并发写入能力。在压缩格式方面,选择了 zlib 替代 LZ4,能够在保证性能的前提下节省约 30% 的存储空间,显著降低总体存储成本。
- 在 DataCache 设计上,缓存大小规划为可支持 7 天的数据扫描量。由于超过 90% 的查询集中在 7 天内的数据,这一配置使得大部分查询均可通过缓存加速。
Compaction
在 Compaction 优化上,主要从三个方面入手:
- 合理控制 Compaction 的参数,包括文件个数及线程数量;
- 通过小时分区与合理的 Bucket 数,降低 Compaction 频次与资源消耗;
- 写入过程中启用 MergeCommit,将小版本数据合并为大版本,从而减少存储碎片。
在 Compaction 的管理方面,团队也设计了相应的监控机制,以便及时发现并优化潜在问题。
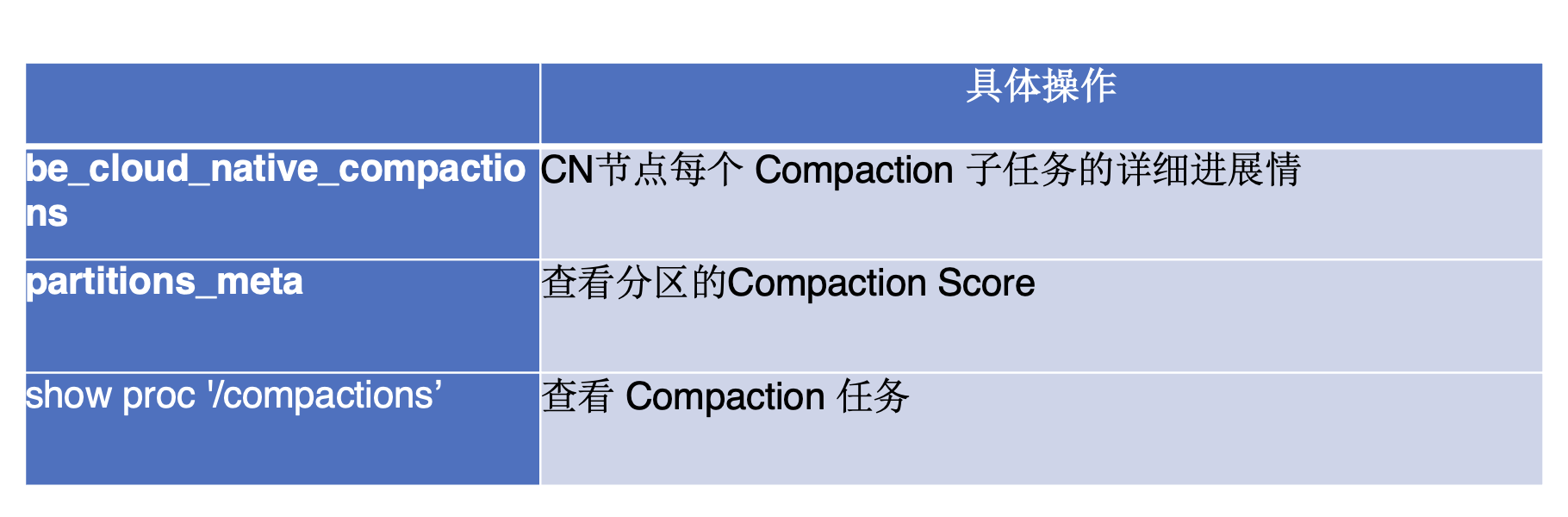
首先,可以通过 native_compactions 表查看 CN 节点中每个 Compaction 子任务的详细进展情况,从而识别出负载较高、拖慢整体任务执行的节点。
其次,借助 partitions_metas 表,能够监控各表的 Compaction Score,从而判断是否存在分区设计或转换策略不合理的情况。
此外,利用 show proc compactions 命令,可以获取具体的 Compaction 任务信息,包括任务的开始与结束时间、总执行时长,以及本地与远端数据的扫描量。例如,当远端数据的扫描量偏高时,往往提示需要检查 DataCache 的配置是否过小,从而为性能优化提供参考。
最后,团队将相关监控指标接入 Grafana,并通过 SQL 图表进行可视化展示。一般而言,当 Compaction Score 维持在 100 以下时,系统处于较为理想的状态。

存量补数
在数据写入方面,整体可以分为两部分。第一部分是存量数据的迁移与补数。在此次改造中,团队需要从 ClickHouse 迁移约 300TB 的存量数据。这部分数据在 HDFS 中也有备份,因为在原有架构下,数据同时写入了 ClickHouse 和 Hive。
针对这一场景,团队最终选择了 SparkLoad 作为导入方案(Hive->StarRocks)。在做出决策前,对三种常见的数据导入方式进行了对比:
- StreamLoad:适用于 GB 级别的小规模数据导入,通常用于实时日志写入。
- BrokerLoad:支持 TB 级别的数据导入,通常以分钟级完成,适合每日批量离线导入。
- SparkLoad:能够支持 TB 级以上的数据导入,对集群影响相对较小。其优势在于,数据首先由 Spark 任务完成清洗与处理,并落地到 HDFS,随后 StarRocks 的 CN 节点直接从 HDFS 拉取已处理好的数据写入存储。
这一机制绕过了 MemoryStore 向磁盘写入的过程,显著减少了 Compaction 的开销,对集群整体影响轻微。因此,SparkLoad 是大规模数据迁移的理想选择,能够高效完成 Hive 存量数据向 StarRocks 的平稳过渡。
实时增量
在实时增量写入方面,团队主要通过 Flink 写入 StarRocks 的方式实现,并开启了 MergeCommit 功能。与传统 Commit 模式相比,MergeCommit 在写入机制和整体性能上有显著优化。
在传统 Commit 模式下,n 个小请求会产生 n 次提交,从而生成 n 个新版本,导致版本数量庞大。而 MergeCommit 将 n 个小请求合并为一次提交,最终只生成一个新版本。这一机制有效减少了版本数量,降低了元数据的管理负担。
在 Compaction 层面,传统模式由于提交频繁,容易产生大量 KB 或 MB 级的小文件,频繁触发 Compaction,导致系统开销偏高。MergeCommit 模式下,每次提交生成的基本为 MB 级的大文件,从而显著降低文件数量和 Compaction 频率。
在 I/O 性能方面,传统写入以小文件为主,属于随机写入模式,读取时需要频繁打开大量小文件,效率低下。而 MergeCommit 将写入转化为批量的顺序写入,读取时文件数量更少,并且能够利用顺序读优化,显著降低 IOPS 和延迟。
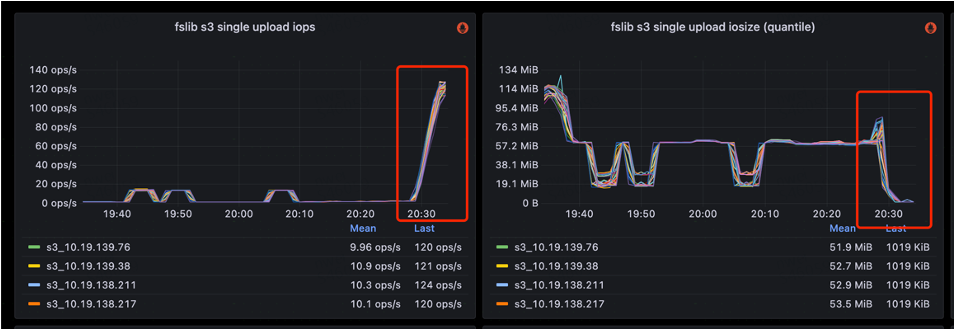
在写入吞吐上,传统模式以高频的小批次写入为主,吞吐有限;而 MergeCommit 通过聚合形成大批次写入,大幅提升了整体吞吐能力。实际对比显示,在关闭 MergeCommit 的情况下,StarRocks 的 IOPS 通常在 140 左右;而开启 MergeCommit 后,合并了大量写入,IOPS 可降低到 10以下。实现近 10 倍提升,写入的 I/O Size 也提升约 10 倍。
查询
在查询优化方面,UBT 的典型场景主要分为明细查询与聚合查询。
对于明细查询,要求用户必须指定分区,并结合前缀索引使用。通过这种方式,可以显著减少扫描范围,提升查询效率。分区裁剪与前缀索引的结合,使得明细级别的日志分析具备较好的性能保障。
对于聚合查询,常见需求集中在基于小时分区的数据统计。针对这一场景,团队根据 SQL 的查询模型预先构建了 分区级物化视图(Partition MV),并在查询前完成聚合计算。由于分区 MV 每次仅刷新当前发生变化的分区,对集群整体的影响极小。
需要注意的是,在MV的每一次刷新过程中,会检查MV所有分区及其基表的所有分区,根据基表的分区变化来更新MV的分区。原算法是每个MV分区都会查询一下基表的所有分区,时间复杂度M*N。
通过优化,只查询一次基表所有分区,时间复杂度M+N。在分区数量达到万级以上时,这一改进的效果尤为显著:如果缺少这一优化,则FE响应时间会急剧拉长。
效果收益
通过上述一系列优化与改造,UBT 在性能与资源利用方面取得了显著收益。
从ClickHouse迁移至 StarRocks 后,由于采用了单副本机制,系统存储量由2.6PB(ClickHouse 2副本)降低至1.2PB(StarRocks 1副本),显著节省了存储成本。同时,节点数量从 50 个缩减至 40 个,资源利用率得到明显提升。查询性能方面,平均耗时由原来的 1.4 秒降至 203 毫秒,仅为之前的 1/7;P95 延迟由 8 秒缩短至 800 毫秒,达到原来的 1/10。下图展示了 UBT 写入 StarRocks 的数据曲线,写入速率稳定维持在 300 万行/秒,整体运行平稳。

展望未来,团队将继续推进存算一体集群向存算分离架构的迁移。同时,在湖仓查询层面,也将逐步从存算一体演进至存算分离,以进一步提升灵活性与扩展性。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号