[MYSQL] 尽可能的从坏块中提取数据 (实战篇)
原创
[MYSQL] 尽可能的从坏块中提取数据 (实战篇)
原创
导读
上一章我们讲了mysql的数据存储结构,分析了各模块如果损坏能否恢复 的理论. 本次我们就来将伦理实践下.
对于加密和压缩的page数据本身就是"加密"的, 坏了就彻底gg了, 就算很熟悉对应的加密算法也是很难恢复的. 我就更无能为力了.
回顾下理论
先说结论: 是可以恢复的, 但可能数据会"多/少",也可能不多不少. 表结构越简单,则"多/少"更明显.
先来简单回顾下上一章的内容: 分析了index page各结构的坏块的影响, 也简单设计了下应该怎么尽可能的提取出剩余的数据.
通常当前行会指向下一行的数据位置, 就这样串一串.

但中间某个row挂了(实际上无法判断是否损坏), 就不能这样"串串"找到后面的row了. 但还可以从page-directory中找.
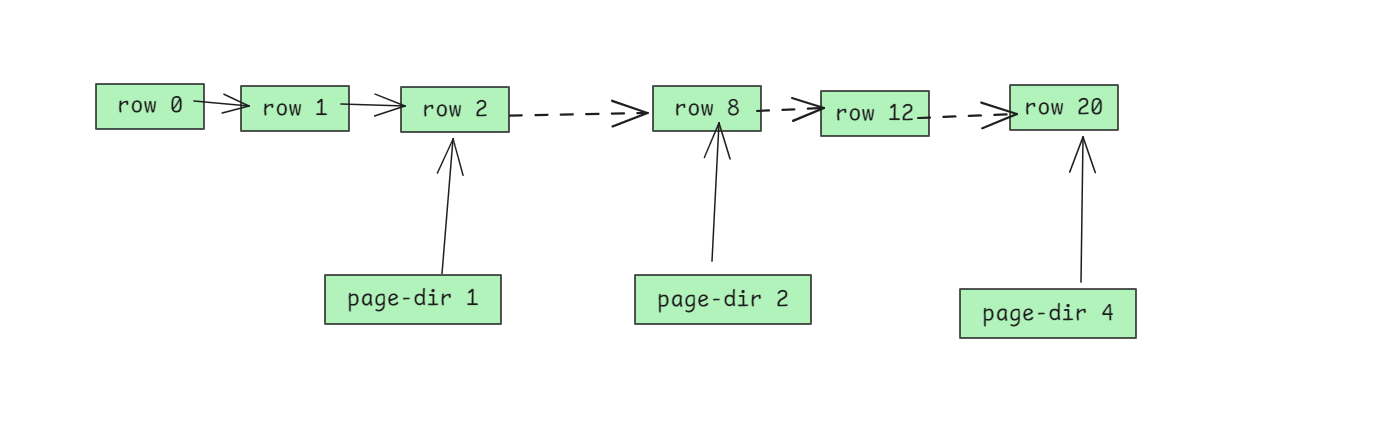
但如果page-directory也不准呢? 那我们还可以1字节1字节的强制解析.

当然这种做法, 可能会生成很多不存在的数据, 但优点是不会丢未损坏的数据.(宁可错杀不可放过)
实际每个page dir对应的slot是4-8行, 我这里就不管这些细节了.
实际实现的话, 我们就选最后2种就行. 具体要使用哪种得看使用者.
验证
环境准备
验证之前我们得先模拟下坏块, 我就顺便写了如下python3脚本:
#!/usr/bin/env python
# write by ddcw @https://github.com/ddcw
# 模拟mysql坏块的, 此脚本非常危险, 是在原数据文件上修改(节省空间). 不要用于任何生产/测试.
# 为了保险期间, 每次操作都要输入一个随机数确认.
import struct
import sys
import os
import random
import argparse
def _argparse():
parser = argparse.ArgumentParser(add_help=True,description="模拟坏块的脚本.不要用于任何生产/测试")
parser.add_argument("--set",dest="SET_OPTIONS",action='append',help="options:fil_header,page_header,page_dir,random,pageno")
parser.add_argument(dest='FILENAME', help='将原地破坏这个ibd文件!!!!!', nargs='*')
parser = parser.parse_args()
return parser
# 破坏fil_header
def damage_fil_header(data):
return b'0xff'*38+data[38:]
# 破坏index page的page header
def damage_page_header(data):
return data[:38] + b'0xff'*56 + data[94:]
# 破坏page directory
def damage_page_dir(data,n=1):
return data[:-16] + b'0xff'*8 + data[-8:]
# 破坏user record, 随机行,随机位置
def damage_random(data,n=1):
start = random.randint(120,8000)
size = random.randint(10,200)
return data[:start] + b'0xff'*size + data[start+size:]
def main():
parser = _argparse()
opt = {}
if parser.SET_OPTIONS is not None:
for x in parser.SET_OPTIONS:
for y in x.split(';'):
for z in y.split(','):
kv = z.split('=')
if len(kv) == 2:
opt[kv[0]] = kv[1]
elif len(kv) == 1 and z != '':
opt[kv[0]] = True
filename = parser.FILENAME[0]
flag = str(random.randint(1000,9999))
if 'skip' not in opt:
print('输入如下数字表示开始破坏文件xxx',flag,'\n我的输入: ',end='')
user_input = sys.stdin.readline()
if user_input[:-1] != flag:
print('输错了, 就没有后续了')
sys.exit(1)
else:
print('既然你已求死, 那便整起!')
pages = os.path.getsize(filename)//16384
pageno = random.randint(4,pages) if 'pageno' not in opt else int(opt['pageno'])
pageno = min(pages,pageno)
print('BAD PAGE:',pageno)
with open(filename,'r+b') as f:
f.seek(16384*pageno,0)
data = f.read(16384)
if 'fil_header' in opt:
data = damage_fil_header(data)
if 'page_header' in opt:
data = damage_page_header(data)
if 'page_dir' in opt:
data = damage_page_dir(data)
if 'random' in opt:
data = damage_random(data)
f.seek(16384*pageno,0)
f.write(data)
if __name__ == '__main__':
main()然后准备下数据, 我这里就使用以前的测试数据, 懒得新建了.
# 备份下
cp -ra /data/mysql_3314/mysqldata/db1/sbtest2.ibd /tmp/sbtest2.ibd
# 记录下正常的数据
python3 main.py /tmp/sbtest2.ibd --ddl --sql > /tmp/sbtest2.sql
# 随机破坏下(可以多整几次, 怕万一没坏到关键处.)
python3 mysql_ibd_corruption_danger.py /tmp/sbtest2.ibd --set random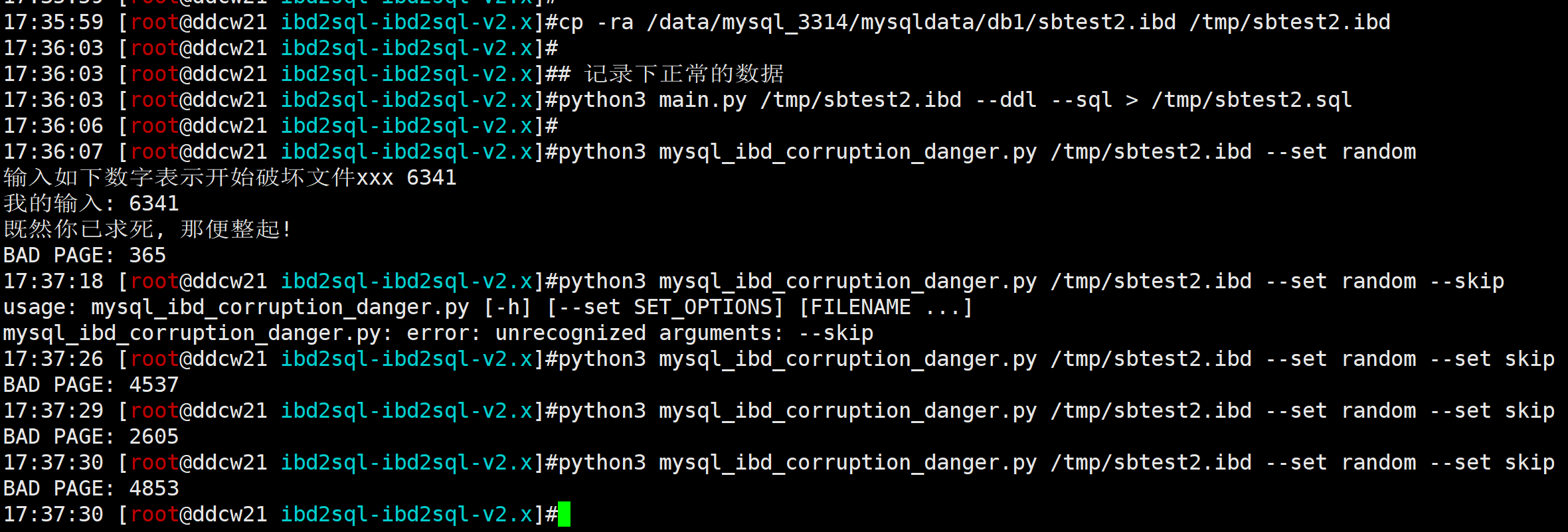
验证
然后我们先正常解析下
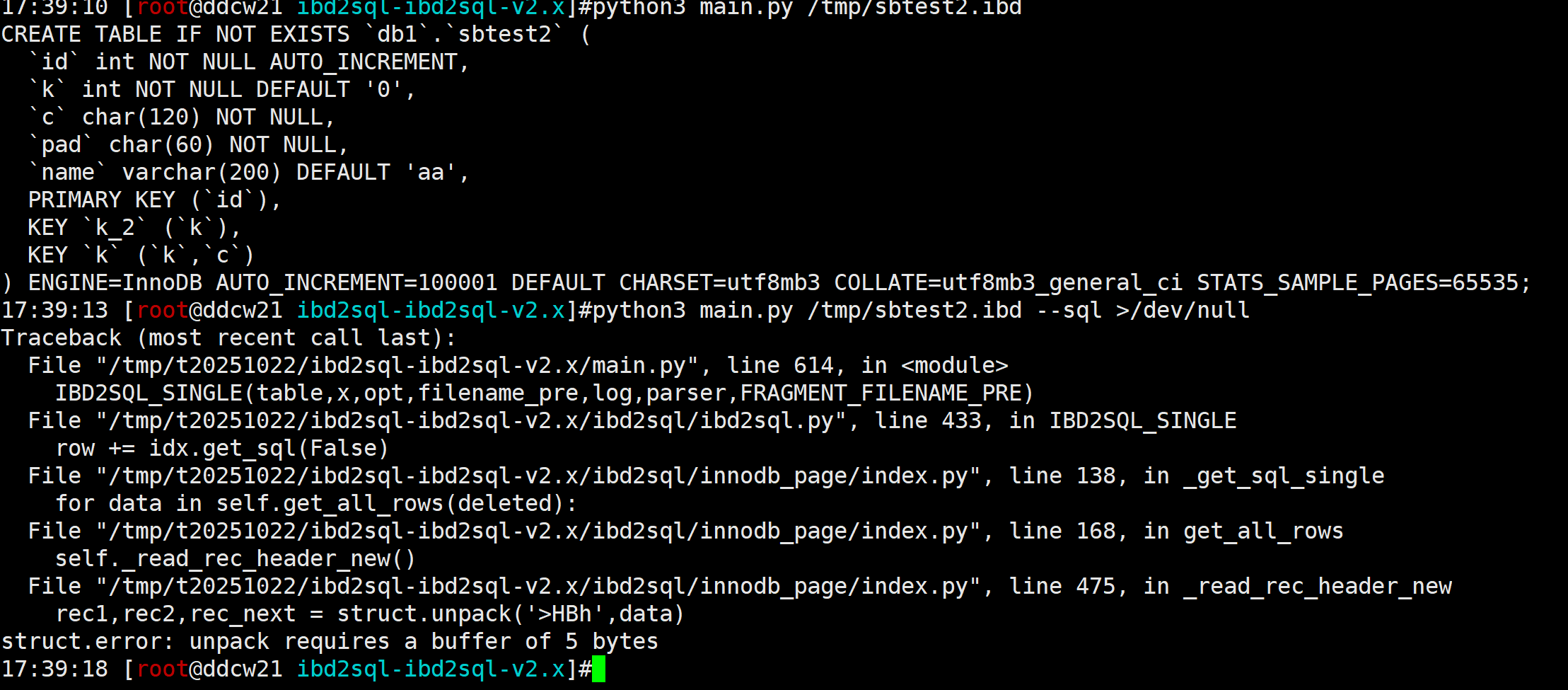
果不其然,报错了...
fast 模式
我们再使用下FAST模式: 根据page-dir来解析.
python3 main.py /tmp/sbtest2.ibd --ddl --sql --force --set bad-pages=fast > /tmp/sbtest2_fast.sql
看起来是没报错, 数据行数也没啥问题, 甚至更多了...
我们可以和之前的比较下, 看多了多少,少了多少
# 少了的数据
diff /tmp/sbtest2_fast.sql /tmp/sbtest2.sql | grep '^>' | wc -l
# 多了的数据
diff /tmp/sbtest2_fast.sql /tmp/sbtest2.sql | grep '^<' | wc -l
我们发现少了146条数据,这部分就算坏块所在页的.
多了595条数据. 得要开发确认这部分具体是哪些了.(我这里是因为有之前的记录,方便比较的, 实际上我们是无法确认多了/少了多少的)
try模式
fast模式丢得有丢丢多, 我们还可以选择try模式, 这是能恢复最多的数据的模式, 但性能会更低,而且会多出来更多的数据... 用法就是吧fast换成try即可.
python3 main.py /tmp/sbtest2.ibd --ddl --sql --force --set bad-pages=try > /tmp/sbtest2_try.sql
看起来也没得问题, 我们再看看哪些"倒霉蛋"处于刚才的坏块中:

看起来实际上只丢了75条数据. 但多了11394条'unknown'.....
skip 模式
我们还有种选择, 就是不要坏块. 整个坏块的都丢掉. 这样性能最高.
python3 main.py /tmp/sbtest2.ibd --ddl --sql --force --set bad-pages=skip > /tmp/sbtest2_skip.sql
发现和fast模式一样. 这说明那几个坏块使用page-dir去遍历啥也没捞着... 最大的可能就是page-dir相关的信息有问题.
总结
相关代码请下载最新版ibd2sql查看: https://github.com/ddcw/ibd2sql/archive/refs/heads/ibd2sql-v2.x.zip
对于坏块不能使用叶子节点间的记录,只能一页页的遍历, 故要求加上--force才生效. 当然我们还可以专门把坏块导出到某个文件, 然后再去慢慢解析, 然后再由开发去慢慢捞数据.
skip模式: 最快,但坏块的数据一条都没有. 冷漠.jpg
fast模式: 不算快也不算慢, 坏块的数据可能有,也可能没有. 全看缘分.jpg
try模式: 速度最慢, 但坏块里面没坏的数据都在. 尽全力.jpg
只要有 --set bad-pages=xx 就会校验坏块. 如果mysql版本比较旧的话, 得使用老一点的校验算法, 也就是使用的时候加上选项--set check-table-old即可.

参考:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
