[ibd2sql] mysql数据恢复案例005 -- 5.7.30的一个json导致的报错
原创
[ibd2sql] mysql数据恢复案例005 -- 5.7.30的一个json导致的报错
原创
导读
有个mysql-5.7.30环境使用ibd2sql-v2.x恢复的时候报错:
Traceback (most recent call last):
File "/tmp/t20251024/ibd2sql-2.1/main.py", line 503, in <module>
IBD2SQL_SINGLE(table,x,opt,filename_pre,log,parser,FRAGMENT_FILENAME_PRE)
File "/tmp/t20251024/ibd2sql-2.1/ibd2sql/ibd2sql.py", line 433, in IBD2SQL_SINGLE
row += idx.get_sql(False)
File "/tmp/t20251024/ibd2sql-2.1/ibd2sql/innodb_page/index.py", line 138, in _get_sql_single
for data in self.get_all_rows(deleted):
File "/tmp/t20251024/ibd2sql-2.1/ibd2sql/innodb_page/index.py", line 170, in get_all_rows
row,pageid = self._read_row()
File "/tmp/t20251024/ibd2sql-2.1/ibd2sql/innodb_page/index.py", line 385, in _read_row_pk_leaf
row.update(self._read_field(the_rest_of_field,null_list,size_list))
File "/tmp/t20251024/ibd2sql-2.1/ibd2sql/innodb_page/index.py", line 428, in _read_field
data = col['decode'](data,*col['args'])
File "/tmp/t20251024/ibd2sql-2.1/ibd2sql/utils/b2data.py", line 344, in B2JSON
return repr(json.dumps(jsonob(data[1:],struct.unpack('<B',data[:1])[0]).init()))
struct.error: unpack requires a buffer of 1 bytes分析
从报错来看是json做解析的时候出问题的(通常是json格式没获取对), json类型我们很早就支持了的, 期间也没有报错过, 写2.x版本的时候,这部分代码是没有动过的. 虽然这是5.7的,而且有好几十个字段, 但我们之前已经修复这个screen的bug了. 难道说是玄学? 于是手动解析瞅瞅.
寻找叶子节点
使用如下python代码发现: root节点的子节点是 FIL_PAGE_TYPE_ALLOCATED = 0
import struct
f = open('test_yi_tuo_ming.ibd','rb')
f.seek(3*16384,0) # rootno
data = f.read(16384)
page_type, = struct.unpack('>H',data[24:26])
page_level,indexid = struct.unpack('>HQ',data[64:74])
print('PAGE LEVEL:',page_level)
# 子节点
offset = struct.unpack('>h',data[97:99])[0]+99
pk,pageno = struct.unpack('>QL',data[offset:offset+12])
f.seek(pageno*16384,0);data = f.read(16384)
# 子节点 页类型
data[24:26]
checksum,current_pageno,pre_pageno,next_pageno = struct.unpack('>4L',data[:16])
print(checksum,current_pageno,pre_pageno,next_pageno)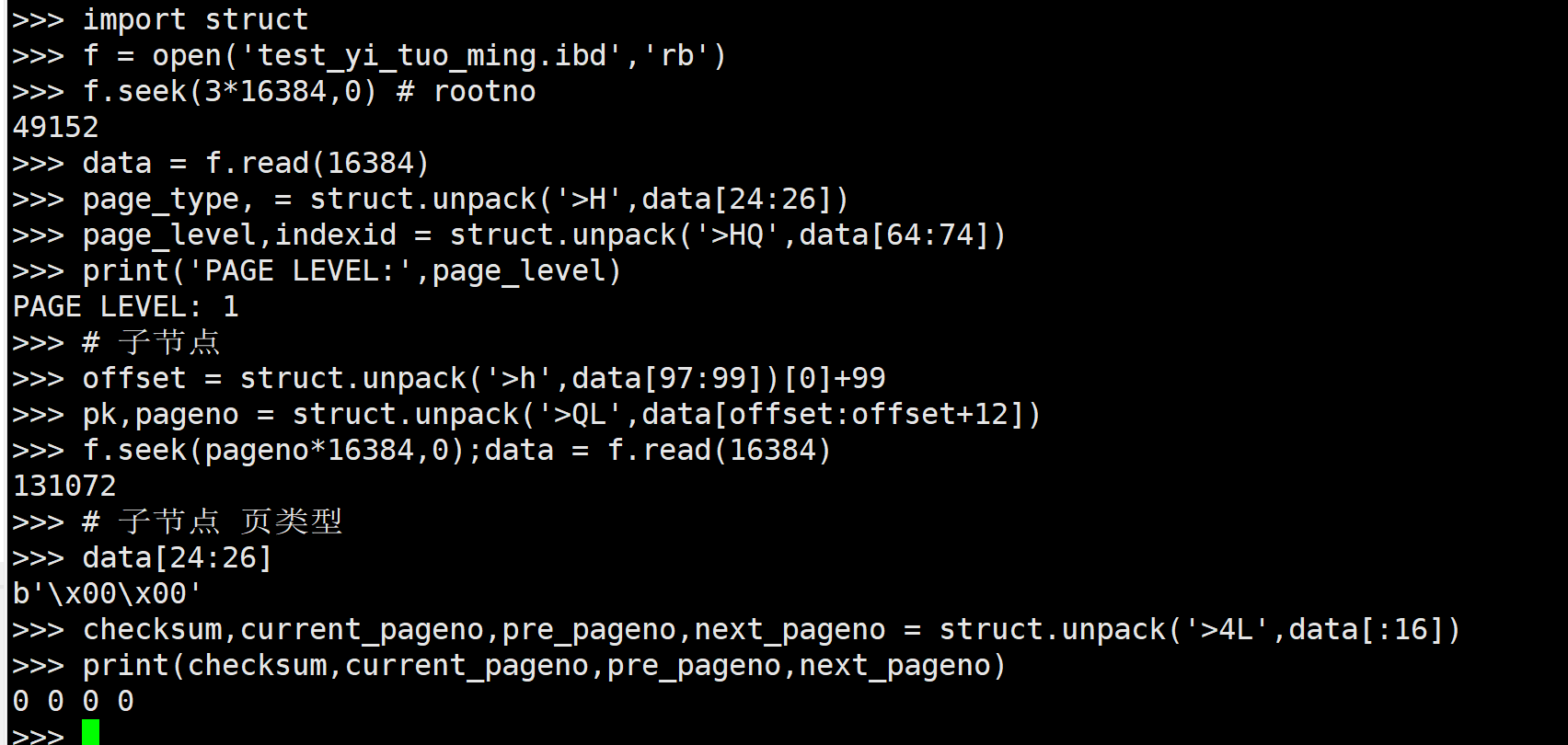
也就是如下的结构
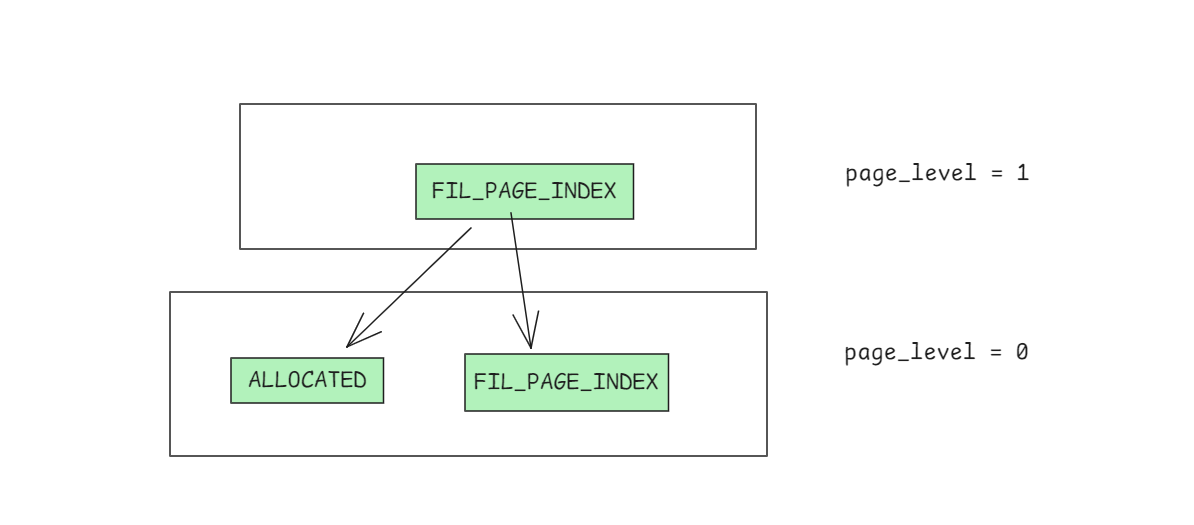
指定leafno后解析数据
我们寻找叶子节点只是为了拿到对应的indexid, 我们可以使用--set leafno=3 来手动指定叶子节点(虽然pageno=3并不是叶子节点)并获取indexid.
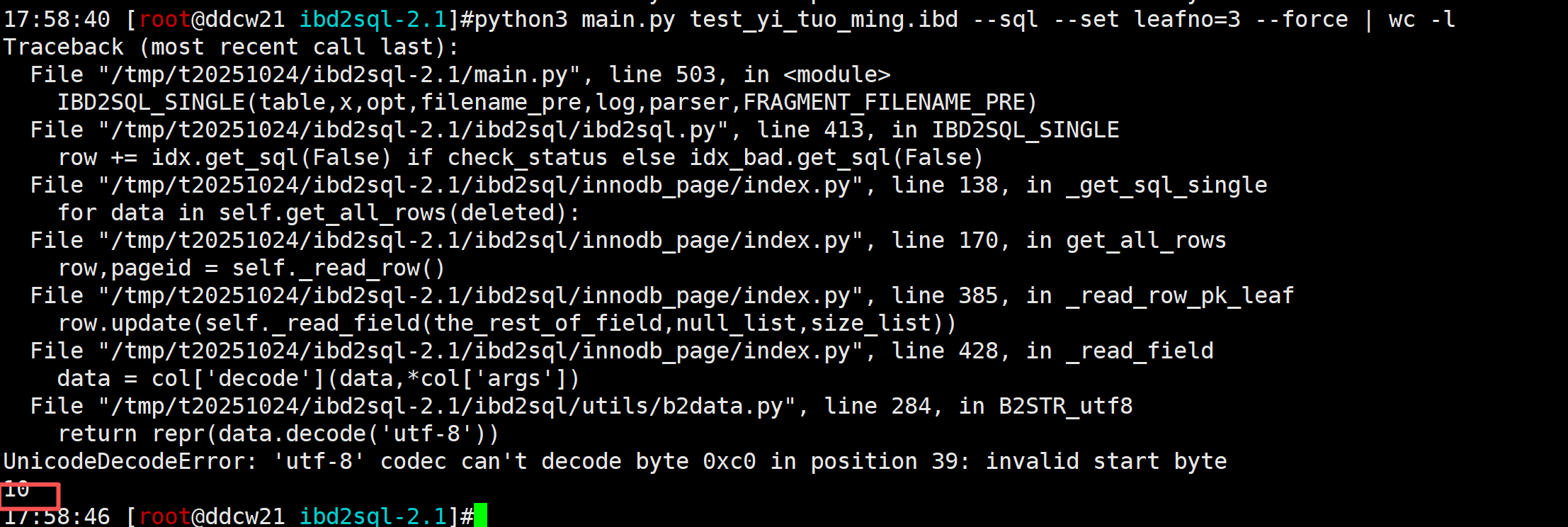
这次是解析了一部分数据之后才报错的, 这就比较有难度了.
找解析失败的page
我们可以使用 --log 来查看是解析哪一页的时候报错的, 然后再人工去解析该页.
python3 main.py test_yi_tuo_ming.ibd --sql --set leafno=3 --force --log >/dev/null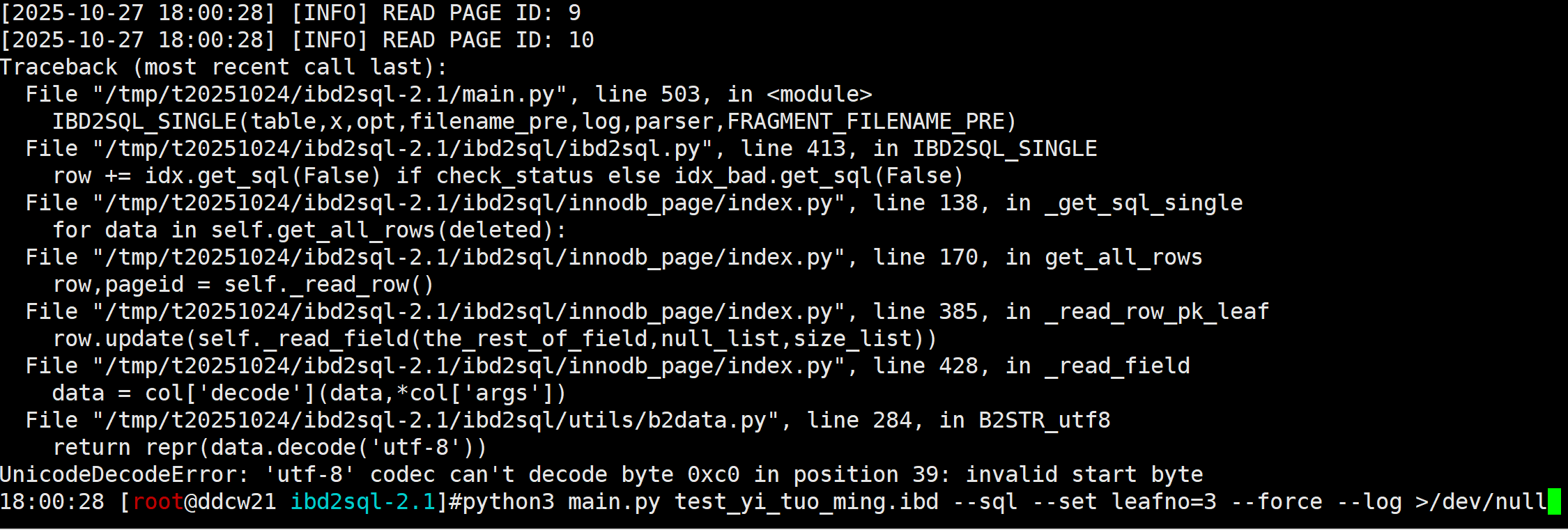
我们看到在"READ PAGE ID: 10"的时候报错了的. (实际上是pageno=11,这里由于是先打印的pageno导致比实际结果小1,小坑, 不影响)
人工解析太麻烦了, 我们直接修改脚本ibd2sql/innodb_page/index.py 在431行添加print(col['name'],col['type_name'],data) 来验证数据
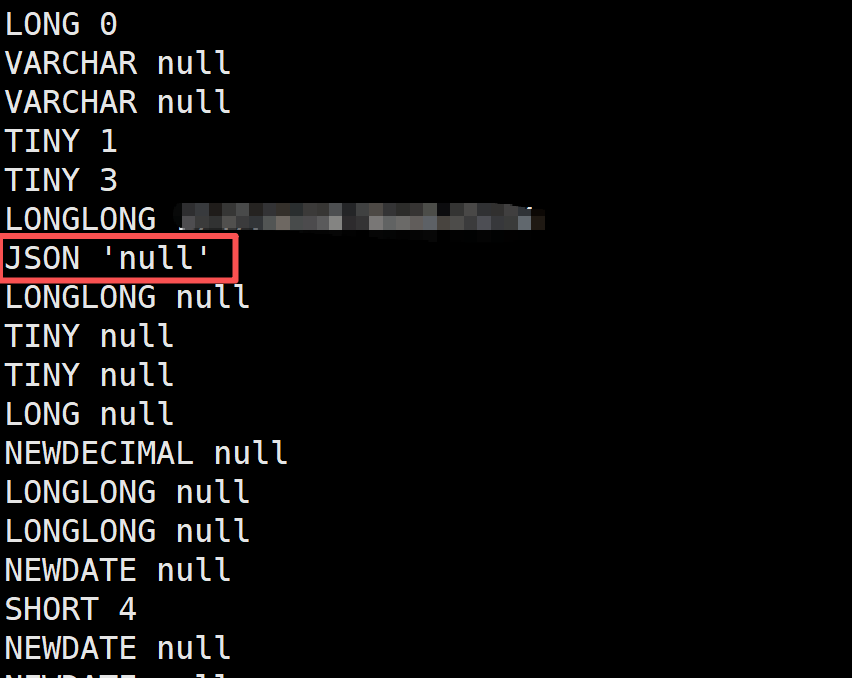
发现有个JSON解析出错.解析的结果是'null', 也就是大概率是解析json的时候出错的, 然后就可以把问题丢给作者了.
分析json解析失败之因
我们还是修改下ibd2sql/innodb_page/index.py, 在数据前后加上便宜量信息:
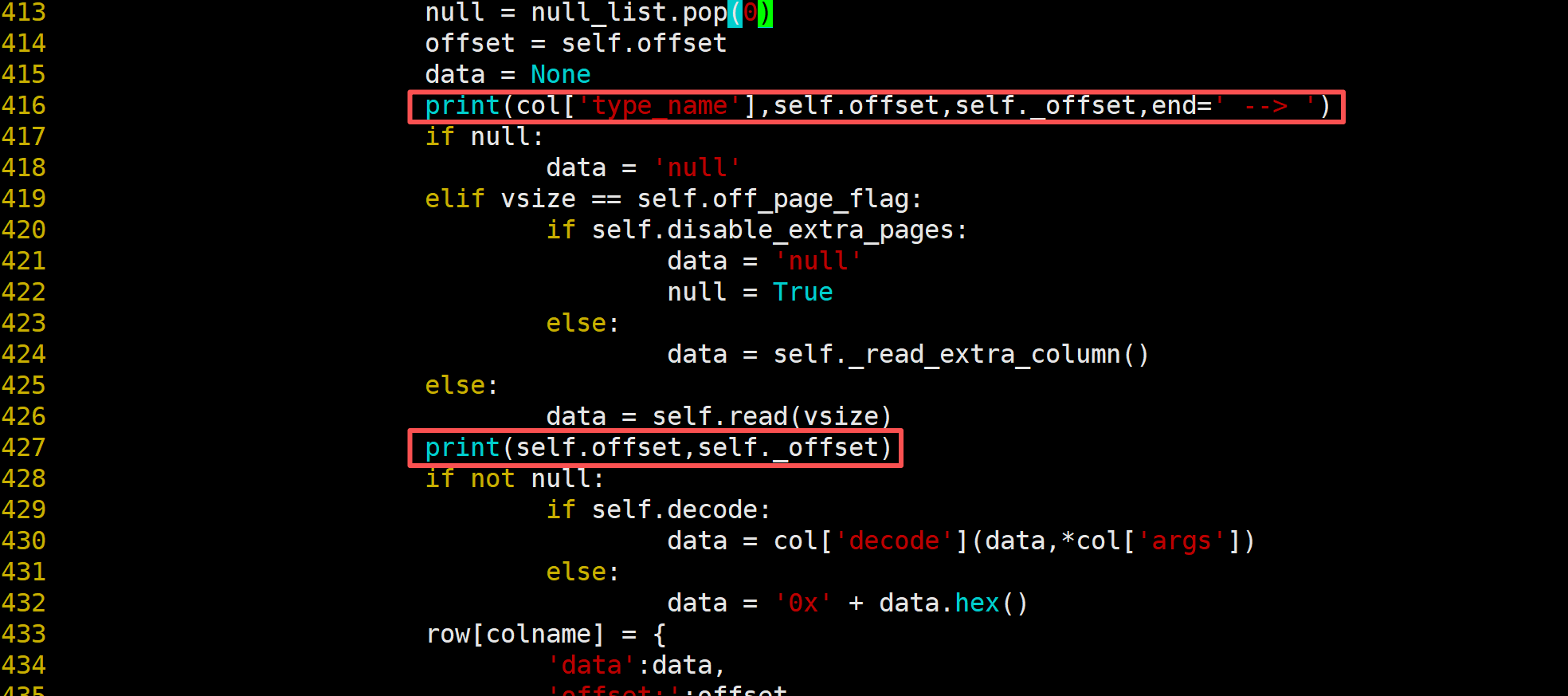
发现这个json居然是150字节,
150可能不算特殊, 但是对于大字段类型(超过255字节)来说, 是需要使用2字节来表示的, 也就是存储上应该是256*(128-128))+150
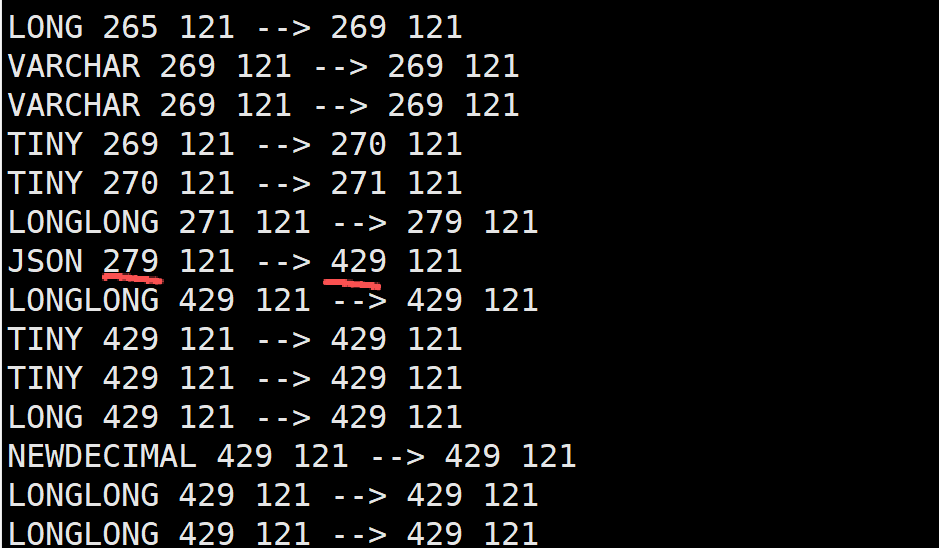
但解析varsize部分却未发现这个结构:(146是第一行数据的便宜量, 表字段太多, 截图截不全, 故简单说明一下)
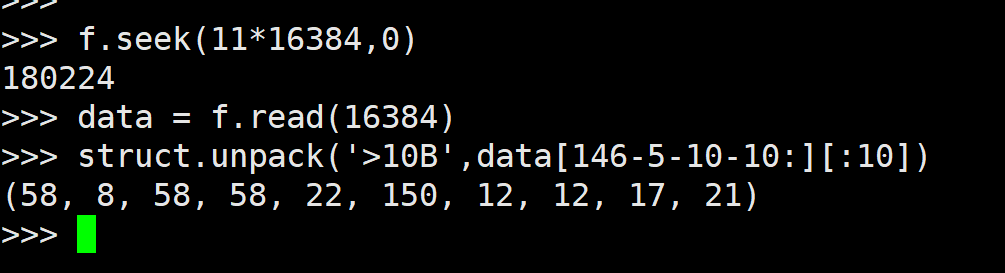
反而是发现了150的存在, 难道JSON被当作了小字段来解析?
验证
我们查看ibd2sql/innodb_page/table.py中对is_big的判断, 发现确实忘记写JSON了...
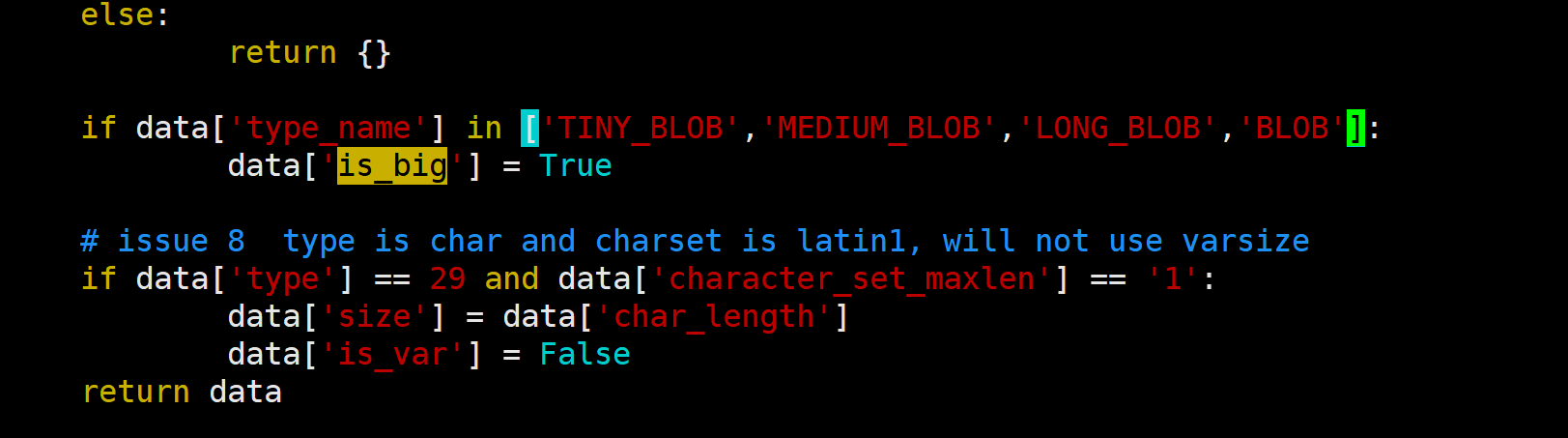
加上之后我们再次验证:

发现可以了

总结
虽然排查了这么多, 写了这么多, 但实际上修改的代码就几个字节而已.....
还被大佬发现个json中文的问题, 对于json.dumps中含有中文的时候可以使用
ensure_ascii=False不去转义. 以前测试案例都是英文, 还没注意到这个问题.
参考:
https://github.com/ddcw/ibd2sql
https://github.com/ddcw/ibd2sql/commit/50ab8ace91c7967740b7a2c56d33a511bd22751d
https://github.com/ddcw/ibd2sql/commit/5f81fb34db83604c2a549111a8e957a59bb30c4d
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
